El tema de la conversación de hoy es lo que Python ha aprendido durante todos los años de su existencia al trabajar con imágenes. De hecho, además de los viejos tiempos de ImageMagick y GraphicsMagick de 1990, existen bibliotecas modernas y efectivas. Por ejemplo, Pillow y Pillow-SIMD más productivo. Su desarrollador activo Alexander Karpinsky (
homm ) en MoscowPython comparó diferentes bibliotecas para trabajar con imágenes en Python, presentó puntos de referencia y habló sobre características no obvias que siempre son suficientes. En este artículo, una transcripción del informe lo ayudará a elegir una biblioteca para su aplicación y a que funcione de la manera más eficiente posible.
Sobre el orador: Alexander Karpinsky trabaja en
Uploadcare y se dedica al servicio de modificación rápida de imágenes sobre la marcha. Está involucrado en el desarrollo de
Pillow , una biblioteca popular para trabajar con imágenes en Python, y está desarrollando su propia bifurcación de esta biblioteca,
Pillow-SIMD , que utiliza instrucciones modernas de procesador para obtener el máximo rendimiento.
Antecedentes
El servicio de modificación de imágenes de Uploadcare es un servidor que recibe una solicitud HTTP con un identificador de imagen y algunas operaciones que un cliente debe realizar. El servidor debe completar las operaciones y responder lo más rápido posible. El cliente más a menudo actúa como un navegador.
Todo el servicio se puede describir como un contenedor alrededor de la biblioteca de gráficos. La calidad de todo el proyecto depende de la calidad, el rendimiento y la usabilidad de la biblioteca de gráficos. Es fácil adivinar que Uploadcare usa Pillow como una biblioteca de gráficos.
Bibliotecas
Revisaremos brevemente qué tipo de bibliotecas de gráficos hay en general en Python para comprender mejor lo que se discutirá más adelante.
Almohada
Almohada - tenedor de PIL (Python Imaging Library). Este es un proyecto muy antiguo, lanzado en 1995 para Python 1.2. ¡Puedes imaginar cuántos años tiene! En algún momento, la biblioteca de imágenes de Python fue abandonada y su desarrollo se detuvo. Se hizo una bifurcación de Pillow para instalar y construir la Biblioteca de imágenes de Python en sistemas modernos. Gradualmente, la cantidad de cambios que las personas necesitaban en la Biblioteca de imágenes de Python creció, y salió Pillow 2.0, que agregó soporte para Python 3. Esto puede considerarse el comienzo de una vida separada del proyecto Pillow.
Pillow es un módulo nativo para Python, la mitad del código está escrito en C, la otra mitad en Python. Se admiten las versiones más diversas de Python: 2.7, 3.3+, PP, .
Pillow-SIMD
Este es mi tenedor de Pillow, que sale en mayo de 2016. SIMD son las siglas de Single Instruction, Multiple Data
- Un enfoque en el que el procesador puede realizar una mayor cantidad de acciones por ciclo utilizando instrucciones modernas.
Pillow-SIMD no es una bifurcación en el sentido clásico cuando un proyecto comienza a vivir su propia vida. Este es un reemplazo para Pillow, es decir, instala una biblioteca en lugar de otra, no cambia una línea en su código fuente y obtiene más rendimiento.
Pillow-SIMD se puede ensamblar con instrucciones SSE4 (predeterminado). Este es un conjunto de instrucciones que se encuentra en casi todos los procesadores x86 modernos. Pillow-SIMD también se puede ensamblar con el conjunto de instrucciones AVX2. Este conjunto de instrucciones es, comenzando con la arquitectura Haswell, es decir, aproximadamente desde 2013.
OpenCV
Otra biblioteca para trabajar con imágenes en Python de la que probablemente haya oído hablar es
OpenCV (Open Computer Vision). Ha estado trabajando desde 2000. El enlace de Python está incluido. Esto significa que el enlace es constantemente relevante, no hay sincronía entre la biblioteca en sí y el enlace.
Desafortunadamente, esta biblioteca aún no es compatible con PyPy, porque OpenCV se basa en numpy, y numpy solo recientemente comenzó a trabajar en PyPy, y PyC aún no es compatible con OpenCV.
VIPS
Otra biblioteca a la que vale la pena prestarle atención es VIPS. La idea principal de
VIPS es que no necesita cargar toda la imagen en la memoria para trabajar con la imagen. La biblioteca puede cargar algunas piezas pequeñas, procesarlas y guardarlas. Por lo tanto, para procesar imágenes de gigapíxeles, no necesita gastar gigabytes de memoria.
Esta es una biblioteca bastante antigua - 1993, pero superó su tiempo. Durante mucho tiempo se escuchó poco al respecto, pero recientemente comenzaron a aparecer carpetas de VIPS para varios idiomas, incluidos Go, Node.js, Ruby.
Durante mucho tiempo quise probar esta biblioteca, sentirla, pero no tuve éxito por una razón muy estúpida. No pude averiguar cómo instalar VIPS, porque el enlace era muy complicado. Pero ahora (en 2017) el autor del VIPS lanzó el enlace pyvips, con el que ya no hay problemas. Instalar y usar VIPS ahora es muy fácil. Compatible: Python 2.7, 3.3+, RuPu, RuPuZ.
ImageMagick & GraphicsMagick
Si hablamos de trabajar con gráficos, no podemos dejar de mencionar a las personas mayores: las bibliotecas
ImageMagick y
GraphicsMagick . Originalmente, este último era una bifurcación de ImageMagick con mayor rendimiento, pero ahora su rendimiento parece ser igual. Que yo sepa, no hay otras diferencias fundamentales entre ellos. Por lo tanto, puede usar cualquiera, más precisamente, el que prefiera usar.
Estas son las bibliotecas más antiguas que mencioné hoy (1990). Durante todo este tiempo, hubo varios aglutinantes para Python, y casi todos ya han muerto con seguridad. De los que se pueden usar, hay:
- Enlace de varita, que se basa en ctypes, pero que ya no se actualiza.
- El enlace pgmagick usa Boost.Python, por lo que se compila durante mucho tiempo y no funciona en PyPy. Pero, sin embargo, puedes usarlo, diría que es preferible a Wand.
Rendimiento
Cuando hablamos de trabajar con imágenes, lo primero que nos interesa (al menos para mí) es el rendimiento, porque de lo contrario podríamos escribir algo en Python con nuestras manos.
El rendimiento no es tan simple. No puedes decir que una biblioteca es más rápida que otra. Cada biblioteca tiene un conjunto de funciones, y cada función funciona a una velocidad diferente.
En consecuencia, es correcto decir solo que el rendimiento de una función es mayor o menor en una biblioteca particular. O tiene una aplicación que necesita un cierto conjunto de funcionalidades, y hace un punto de referencia específicamente para esta funcionalidad, y dice que tal y tal biblioteca funciona más rápido (más lento) para su aplicación.
Es importante verificar el resultado.
Cuando hace puntos de referencia, es muy importante observar el resultado obtenido. Incluso si a primera vista escribió el mismo código, esto no significa que sea el mismo.
Recientemente, en un artículo que compara el rendimiento de Pillow y OpenCV, me encontré con este código:
from PIL import Image, ImageFilter.BoxBlur im.filter(ImageFilter.BoxBlur(3)) ... import cv2 cv2.blur(im, ksize=(3, 3)) ...
Parece estar allí, y allí, BoxBlur, y allí, y allí, argumento 3, pero de hecho el resultado es diferente. Porque en Pillow (3) este es el radio de desenfoque, y en OpenCV ksize = (3, 3) es el tamaño del núcleo, es decir, en términos generales, el diámetro. En este caso, el valor correcto para OpenCV sería 3 * 2 + 1, es decir (7, 7).
Cual es el problema
¿Por qué el rendimiento generalmente es un problema cuando se trabaja con gráficos? Debido a que la complejidad de cualquier operación depende de varios parámetros, y la mayoría de las veces la complejidad crece linealmente con cada uno de ellos. Y si, por ejemplo, hay tres de estos factores, y la complejidad depende linealmente de cada uno, entonces se obtiene la complejidad en el cubo.
Ejemplo: desenfoque gaussiano en OpenCV.

A la izquierda hay un radio de 3, a la derecha 30. Como puede ver, la diferencia de velocidad es más de 10 veces.
Cuando me enfrenté a la tarea de agregar desenfoque gaussiano a mi aplicación, no estaba contento de que, hipotéticamente, se pudieran gastar 900 ms en una operación. Hay miles de tales operaciones por minuto en la aplicación, y pasar tanto tiempo en una no es práctico. Por lo tanto, estudié el problema e implementé el desenfoque gaussiano en Pillow, que funciona en tiempo constante en relación con el radio. Es decir, solo el tamaño de la imagen afecta el rendimiento del desenfoque gaussiano.
Pero lo principal aquí no es que algo funcione más rápido o más lento.
Quiero transmitir que cuando está creando algún tipo de sistema, es importante comprender de qué parámetros depende la complejidad de la salida. Entonces puede limitar estos parámetros o de otras maneras para lidiar con esta complejidad.
Probablemente, la operación más común que hacemos con las imágenes después de abrirlas es cambiar el tamaño.
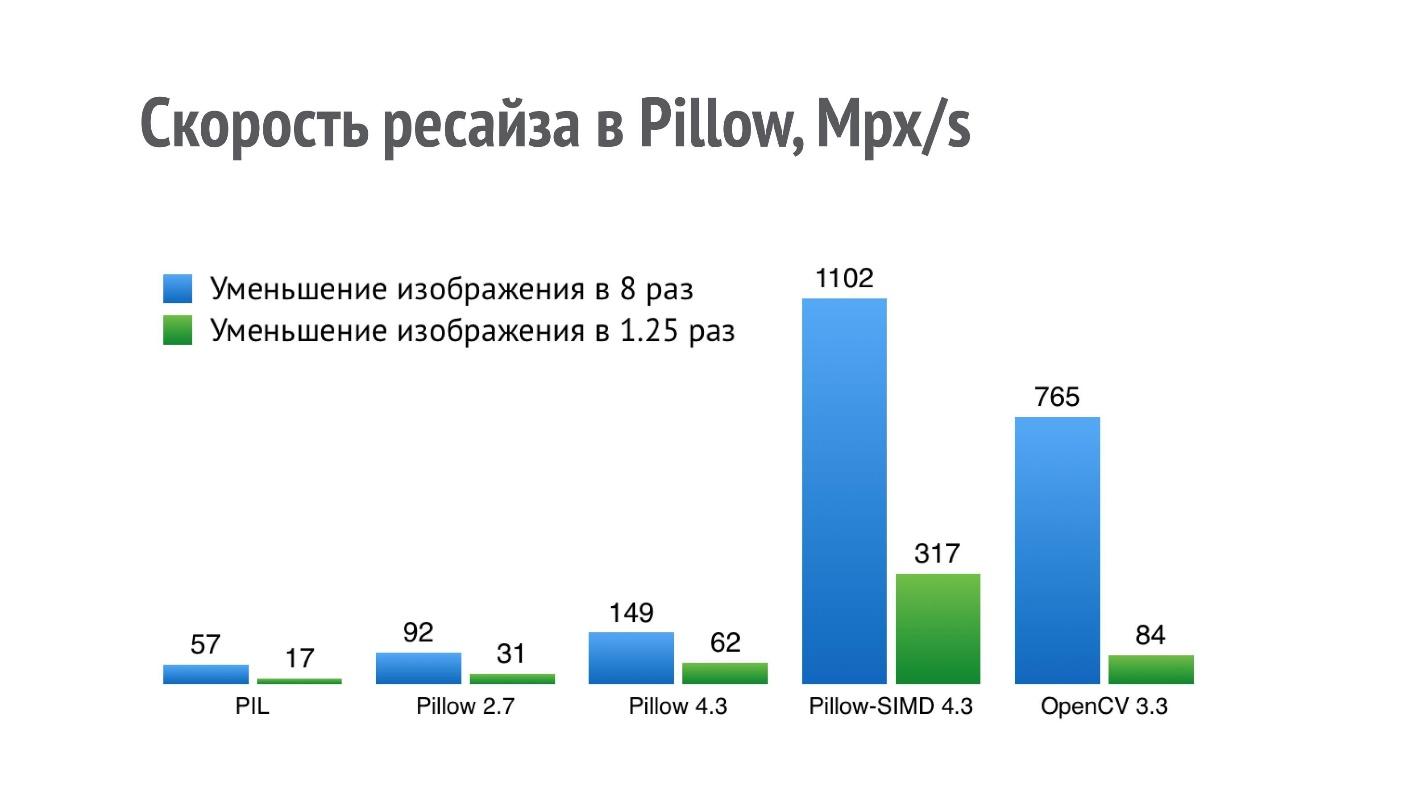
El gráfico muestra el rendimiento (más es mejor) de diferentes bibliotecas para la operación de reducir la imagen en 8 y 1,25 veces.
Para PIL, un resultado de 17 Mpx / s significa que la foto de un iPhone (12 Mpx) se puede reducir 1.25 veces un poco en menos de un segundo. Tal rendimiento no es suficiente para una aplicación seria que realiza muchas de estas operaciones.
Comencé a optimizar el rendimiento del cambio de tamaño, y en Pillow 2.7 logré lograr un doble aumento en la productividad, y en Pillow 4.3: tres veces (la versión de Pillow 5.3 es relevante actualmente, pero el rendimiento de cambio de tamaño es el mismo).
Pero la operación de cambio de tamaño es algo que encaja muy bien en SIMD. Se acerca a una sola instrucción, a múltiples datos y, por lo tanto, en la versión actual de Pillow-SIMD, logré
aumentar la velocidad de cambio de tamaño en 19 veces en comparación con la Biblioteca de imágenes Python original con los mismos recursos.
Esto es significativamente más alto que el rendimiento de cambio de tamaño de OpenCV. Pero la comparación no es del todo correcta, porque OpenCV utiliza un método de cambio de tamaño ligeramente menos de alta calidad con un filtro de caja, y en Pillow-SIMD, el cambio de tamaño se implementa mediante convoluciones.
Esta es una lista incompleta de aquellas operaciones que se aceleran en Pillow-SIMD en comparación con Pillow normal.
- Cambiar el tamaño: 4 a 7 veces.
- Desenfoque: 2.8 veces.
- Aplicación del núcleo 3 × 3 o 5 × 5: 11 veces.
- Multiplicación y división por canal alfa: 4 y 10 veces.
- Composición alfa: 5 veces.
Ya he dicho que no se puede decir que alguna biblioteca funciona más rápido que otra, pero puede inventar un conjunto de operaciones que le interesen. Elegí un conjunto de operaciones que son interesantes en mi aplicación, hice un punto de referencia y obtuve tales resultados.

Resultó que Pillow-SIMD en este conjunto funciona 2 veces más rápido que Pillow. Al final está Wand (recuerde que esto es ImageMagick).
Pero estaba interesado en otra cosa: ¿por qué OpenCV y VIPS son tan pobres en resultados, porque estas son bibliotecas que también están diseñadas con vistas al rendimiento? Resultó que en el caso de OpenCV, el ensamblado binario de OpenCV que se instala utilizando pip se ensambló con un códec JPEG lento (se notificó al autor del ensamblaje, este problema ya se ha resuelto para 2018). Está construido con libjpeg, mientras que la mayoría de los sistemas, al menos basados en Debian, usan libjpeg-turbo, que es varias veces más rápido. Si compila OpenCV desde la fuente usted mismo, entonces el rendimiento será mayor.
En el caso de VIPS, la situación es diferente. Me puse en contacto con el autor del VIPS, le mostré este punto de referencia y nos mantuvimos en contacto durante mucho tiempo y fructíferamente. Después de eso, el autor de VIPS encontró varios lugares en el propio VIPS, donde la ejecución no estaba en la ruta óptima, y los corrigió.
Eso es lo que sucederá con el rendimiento si compila OpenCV desde las fuentes de la versión actual y VIPS desde el maestro, que ya está allí.
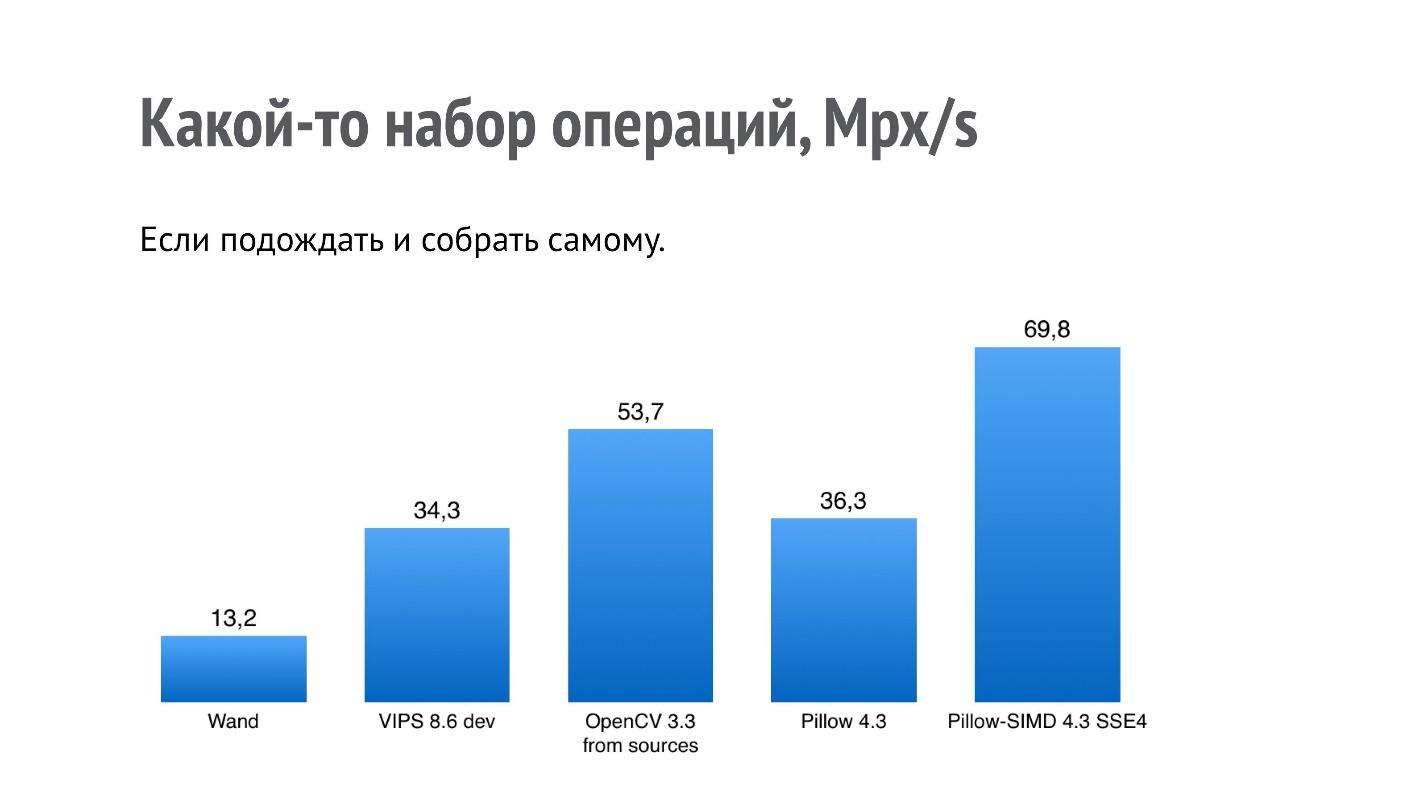
Incluso si encuentra algún tipo de punto de referencia, no es un hecho que todo funcione con esta velocidad exactamente en su máquina.
Conjunto de puntos de referencia
Todos los puntos de referencia de los que hablé se pueden encontrar en
la página de resultados . Este es un mini-proyecto separado donde escribo puntos de referencia que yo mismo necesito para desarrollar Pillow-SIMD, ejecutarlos y publicar los resultados.
GitHub tiene un
proyecto con marcos de prueba donde todos pueden ofrecer sus propios puntos de referencia o corregir los existentes.
Trabajo paralelo
Hasta ahora he estado hablando de rendimiento puro, es decir, en un solo núcleo de procesador. Pero todos hemos tenido acceso a sistemas con más núcleos, y me gustaría deshacerme de ellos. Aquí tengo que decir que, de hecho, Pillow es la única biblioteca de todas que no utiliza la paralelización de tareas. Trataré de explicar por qué sucede esto. Todas las demás bibliotecas de una forma u otra lo usan.
Métricas de rendimiento
En términos de rendimiento, estamos interesados en 2 parámetros:
- Tiempo real de ejecución de una operación. Hay una operación (o una secuencia de operaciones), y usted se pregunta en qué tiempo real (reloj de pared) se ejecutará esta secuencia. Este parámetro es importante en el escritorio, donde hay un usuario que dio el comando y está esperando el resultado.
- Rendimiento de todo el sistema (flujo de trabajo). Cuando tiene un conjunto de operaciones en curso, o muchas operaciones independientes, y la velocidad de procesamiento de estas operaciones en su hardware es importante para usted. Esta métrica es más importante en un servidor donde hay muchos clientes y necesita atenderlos a todos. El tiempo que lleva servir a un cliente es importante, por supuesto, pero un poco menos que el ancho de banda total.
En base a estas dos métricas, consideramos diferentes formas de operación paralela.
Métodos de trabajo en paralelo
1.
A nivel de aplicación , cuando decide a nivel de aplicación que las operaciones se procesan en diferentes subprocesos. Al mismo tiempo, el tiempo de ejecución real de una operación no cambia, porque como antes, un núcleo está ocupado en una secuencia de operaciones. La capacidad del sistema aumenta en proporción al número de núcleos, es decir, muy bueno.
2.
En el nivel de las operaciones gráficas , eso es exactamente lo que se encuentra en la mayoría de las bibliotecas gráficas. Cuando una biblioteca gráfica recibe algún tipo de operación, crea la cantidad necesaria de subprocesos dentro de sí misma, divide una operación en varias más pequeñas y las realiza. Al mismo tiempo, se reduce el tiempo de ejecución real: una operación es más rápida. Pero el
rendimiento no crece linealmente con el número de núcleos. Hay operaciones que no son paralelas, y un ejemplo sorprendente es la decodificación de archivos PNG: no se puede paralelizar de ninguna manera. Además, hay gastos generales para crear subprocesos, dividir tareas, que tampoco permiten que el ancho de banda crezca linealmente.
3.
A nivel de comandos y datos del procesador . Preparamos los datos de una manera especial y utilizamos comandos especiales para que el procesador trabaje con ellos más rápido. Este es el enfoque SIMD, que, de hecho, se utiliza en Pillow-SIMD. El tiempo de ejecución en tiempo real está disminuyendo, el rendimiento está aumentando:
esta es
una opción de ganar-ganar .
Cómo combinar trabajo paralelo
Si queremos combinar de alguna manera el trabajo paralelo, SIMD funciona bien con la paralelización dentro de una operación, y SIMD funciona bien con la paralelización dentro de una aplicación.

Pero la paralelización dentro de la aplicación y dentro de la operación no son compatibles entre sí. Si intentas hacer esto, obtendrás desventajas de ambos enfoques. El tiempo real de la operación será el mismo que en un núcleo, y el rendimiento del sistema aumentará, pero no linealmente con respecto al número de núcleos.
Multithreading
Si estamos hablando de hilos, todos escribimos en Python y sabemos que tiene un GIL que evita que dos hilos se ejecuten al mismo tiempo. Python es un lenguaje estrictamente de un solo subproceso.
Por supuesto, esto no es cierto, porque el GIL realmente evita que dos hilos se ejecuten en Python, y si el código está escrito en otro idioma y no usa estructuras internas de Python durante su operación, este código puede liberar el GIL y así liberar al intérprete para otras tareas
Muchas bibliotecas de gráficos lanzan GIL durante su trabajo, incluidas Pillow, OpenCV, pyvips, Wand. Solo un pgmagick no libera. Es decir, puede crear hilos de manera segura para realizar algunas operaciones, y esto funcionará en paralelo con el resto del código.
Pero surge la pregunta:
¿cuántos hilos crear?Si creamos un número infinito de subprocesos para cada tarea que tenemos, entonces simplemente ocupan toda la memoria y todo el procesador; no obtendremos ningún trabajo efectivo. Formulé una regla especial.
Regla N + 1
Para un trabajo productivo, debe crear no más de N + 1 trabajadores, donde N es el número de núcleos o subprocesos del procesador en la máquina, y el trabajador es el proceso o subproceso involucrado en el procesamiento.
Los procesos se utilizan mejor, porque incluso dentro del mismo intérprete hay cuellos de botella y gastos generales.
Por ejemplo, en nuestra aplicación, se utiliza Tornado de instancia N + 1, el equilibrio entre los cuales se lleva a cabo ngnix. Si se menciona Tornado, entonces hablemos de la operación asincrónica.
Operación asincrónica
El tiempo que la biblioteca gráfica hace realmente un trabajo útil (procesamiento de imágenes) puede y debe usarse para entrada / salida, si los tiene en la aplicación. Los marcos asincrónicos son muy relevantes aquí.
Pero hay un problema: cuando llamamos a algún tipo de procesamiento, se llama sincrónicamente. Incluso si la biblioteca libera el GIL en ese momento, el bucle de eventos todavía está bloqueado.
@gen.coroutine def get(self, *args, **kwargs): im = process_image(...) ...
Afortunadamente, este problema es muy fácil de resolver creando un ThreadPoolExecutor con un solo hilo en el que comienza el procesamiento de la imagen. Esta llamada ya está ocurriendo de forma asincrónica.
@run_on_executor(executor=ThreadPoolExecutor(1)) def process_image(self, ... @gen.coroutine def get(self, *args, **kwargs): im = yield process_image(...) ...
En esencia, aquí se crea una cola con un trabajador que realiza operaciones gráficas, y el bucle de eventos no se bloquea y se ejecuta silenciosamente en paralelo en otro subproceso.
Entrada / salida
Otro tema que me gustaría abordar en la discusión de las operaciones gráficas es la entrada / salida. El hecho es que rara vez creamos ningún tipo de imagen usando una biblioteca de gráficos. Muy a menudo, abrimos imágenes que nos han llegado los usuarios en forma de archivos codificados (JPEG, PNG, BMP, TIFF, etc.).
En consecuencia, la biblioteca de gráficos para construir una buena aplicación debería tener algunas ventajas para la entrada / salida de los archivos.
Carga perezosa
El primero de esos bollos es la carga perezosa. Si, por ejemplo, en Pillow abre una imagen, en este momento no se produce la decodificación de la imagen. Volverá con un objeto que parece que la imagen ya está cargada y funcionando. Puede ver sus propiedades y decidir sobre la base de las propiedades de esta imagen si está listo para trabajar con ella más y si el usuario ha cargado, por ejemplo, una imagen de gigapíxeles para interrumpir su servicio.
>>> from PIL import Image >>> %time im = Image.open() Wall time: 1.2 ms >>> im.mode, im.size ('RGB', (2152, 1345))
Si decide qué hacer a continuación, utilizando la llamada explícita o implícita para cargar, esta imagen se decodifica. Ya en este momento se asigna la cantidad necesaria de memoria.
>>> from PIL import Image >>> %time im = Image.open() Wall time: 1.2 ms >>> im.mode, im.size ('RGB', (2152, 1345)) >>> %time im.load() Wall time: 73.6 ms
Modo de imagen rota
El segundo bollo que se necesita cuando se trabaja con contenido generado por el usuario es el modo de imagen rota. Los archivos que recibimos de los usuarios a menudo contienen algunas inconsistencias con el formato en el que están codificados.
Estas discrepancias ocurren por varias razones. A veces, estos son errores de transmisión a través de la red, a veces son solo una especie de códecs torcidos que codifican la imagen. Por defecto, Pillow, cuando ve imágenes que no se ajustan al formato hasta el final, solo lanza una excepción.
from PIL import Image Image.open('trucated.jpg').save('trucated.out.jpg') IOError: image file is truncated (143 bytes not processed)
Pero el usuario no tiene la culpa del hecho de que su imagen está rota, todavía quiere obtener el resultado. Afortunadamente, Pillow tiene un modo de imagen rota. Cambiamos una configuración, y Pillow intenta ignorar al máximo todos los errores de decodificación que están en la imagen. En consecuencia, el usuario ve al menos algo.
from PIL import Image, ImageFile ImageFile.LOAD_TRUNCATED_IMAGES = True Image.open('trucated.jpg').save('trucated.out.jpg')

Incluso una imagen recortada es mejor que nada, solo una página con un error.
Tabla resumen
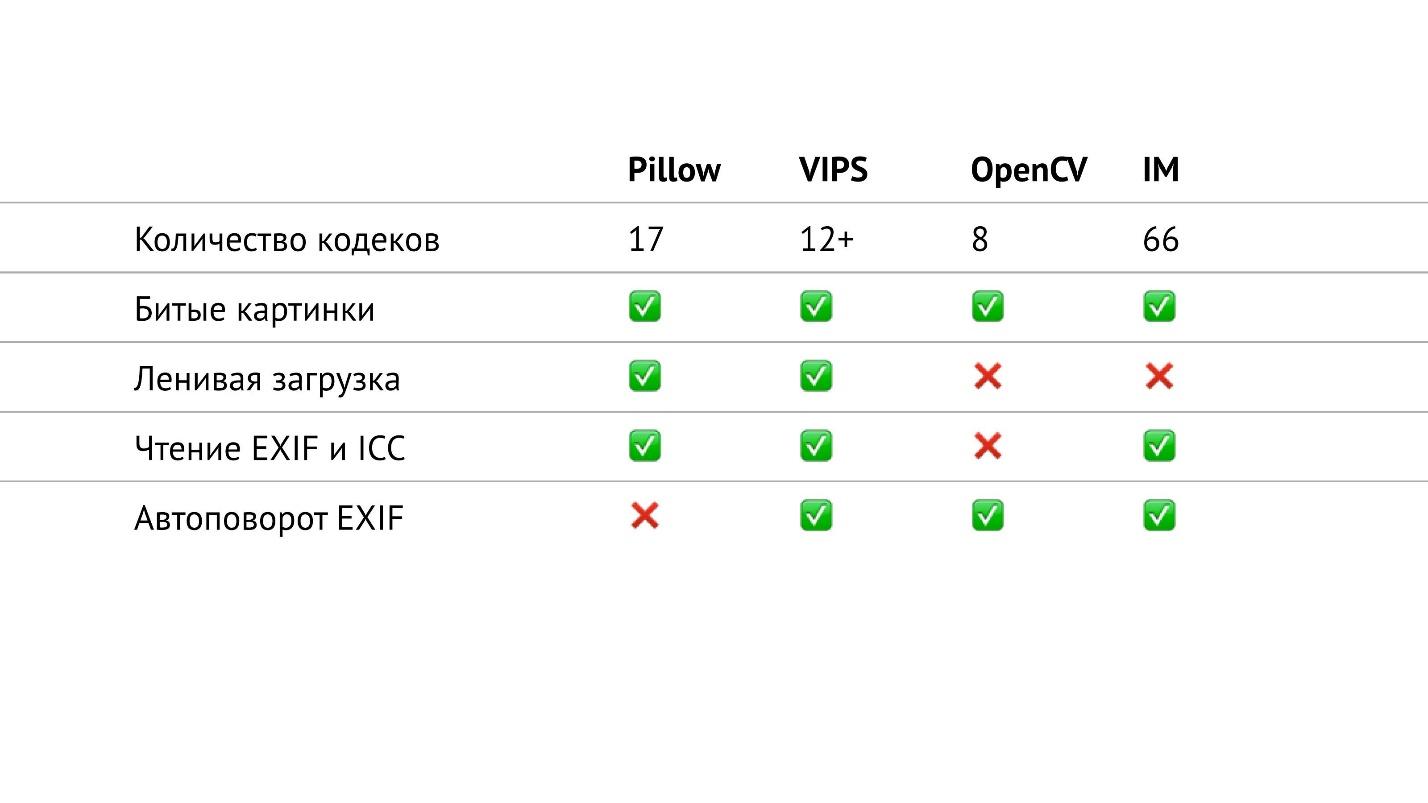
En la tabla anterior, he recopilado todo lo relacionado con la entrada / salida en las bibliotecas de las que estoy hablando. En particular, conté la cantidad de códecs de varios formatos que están en las bibliotecas. Resultó que en OpenCV son los menos, en ImageMagick, la mayoría. Parece que en ImageMagick puedes abrir cualquier imagen que encuentres. VIPS tiene 12 códecs nativos, pero VIPS puede usar ImageMagick como intermediario. No he probado cómo funciona esto, espero que sea perfecto.
La almohada tiene 17 códecs. Esta es ahora la única biblioteca en la que no hay rotación automática EXIF. Pero ahora este es un pequeño problema, porque puede leer EXIF usted mismo y rotar la imagen de acuerdo con él. Se trata de un pequeño fragmento, que es fácilmente google y toma un máximo de 20 líneas.
Características de OpenCV
Si observa esta tabla con cuidado, puede ver que en OpenCV, de hecho, no todo es tan bueno con la entrada / salida. Tiene la menor cantidad de códecs, no tiene carga lenta y no puede leer EXIF y el perfil de color.
Pero eso no es todo. De hecho, OpenCV tiene más características. Cuando simplemente abrimos una imagen, la
cv2.imread(filename) gira los archivos JPEG de acuerdo con EXIF (vea la tabla), pero ignora el canal alfa de los archivos PNG, ¡un comportamiento bastante extraño!
Afortunadamente, OpenCV tiene una bandera:
cv2.imread(filename, flags=cv2.IMREAD_UNCHANGED) .
Si especifica el indicador IMREAD_UNCHANGED, OpenCV deja el canal alfa para los archivos PNG, pero deja de convertir los archivos JPEG de acuerdo con EXIF. Es decir, la misma bandera afecta a dos propiedades completamente diferentes. Como se puede ver en la tabla, OpenCV no tiene la capacidad de leer EXIF, y resulta que en el caso de este indicador es imposible rotar JPEG en absoluto.
¿Qué sucede si no sabe de antemano qué formato tiene su imagen y necesita tanto el canal alfa para PNG como la rotación automática para JPEG? Nada que hacer: OpenCV no funciona así.
La razón por la cual OpenCV tiene tales problemas radica en el nombre de esta biblioteca. Tiene mucha funcionalidad para la visión por computadora y el análisis de imágenes. De hecho, OpenCV está diseñado para trabajar con fuentes verificadas. Esta es, por ejemplo, una cámara de vigilancia para exteriores que toma imágenes una vez por segundo y lo hace durante 5 años en el mismo formato y la misma resolución. No hay necesidad de variabilidad en el problema de E / S.
Las personas que necesitan la funcionalidad OpenCV realmente no necesitan la funcionalidad del contenido del usuario.
Pero, ¿qué sucede si su aplicación aún necesita funcionalidad para trabajar con el contenido del usuario y, al mismo tiempo, necesita toda la potencia de OpenCV para el procesamiento y las estadísticas?

La solución es combinar bibliotecas. El hecho es que OpenCV se basa en numpy, y Pillow tiene todos los medios para exportar imágenes de Pillow a una matriz numpy. Es decir, exportamos la matriz numpy, y OpenCV puede continuar trabajando con esta imagen, como con la suya. Esto se hace muy fácilmente:
import numpy from PIL import Image ... pillow_image = Image.open(filename) cv_image = numpy.array(pillow_image)
Además, cuando hacemos magia usando OpenCV (procesamiento), llamamos a otro método Pillow e importamos la imagen de OpenCV nuevamente al formato Pillow. En consecuencia, se puede volver a utilizar E / S.
import numpy from PIL import Image ... pillow_image = Image.fromarray(cv_image, "RGB") pillow_image.save(filename)
Por lo tanto, resulta que usamos entrada / salida de Pillow, y el procesamiento de OpenCV, es decir, tomamos lo mejor de los dos mundos.
Espero que esto te ayude a construir una aplicación de gráficos cargada.
Puede aprender algunos otros secretos de desarrollo en Python, aprender de una experiencia invaluable ya veces inesperada, y lo más importante, puede discutir sus tareas muy pronto en Moscow Python Conf ++ . Por ejemplo, preste atención a dichos nombres y temas en la programación.
- Donald Whyte cuenta una historia sobre cómo hacer que las matemáticas sean 10 veces más rápidas utilizando bibliotecas populares, trucos y astucia, y el código es comprensible y compatible.
- Andrei Popov se trata de recopilar una gran cantidad de datos y analizarlos en busca de amenazas.
- Ephraim Matosyan en su informe "Haga que Python vuelva a ser rápido" le dirá cómo aumentar el rendimiento del demonio que procesa los mensajes desde el bus.
Una lista completa de lo que se discutirá para el 22 y 23 de octubre aquí , tiene tiempo para unirse.