Hola a todos!
Mientras
Leonid se está preparando para su primera
lección abierta en nuestro curso de
Administrador de Linux , seguimos hablando de cargar el kernel de Linux.
Vamos!
Comprender cómo funciona un sistema sin fallas: preparación para solucionar las averías inevitables
La broma más antigua en el campo de código abierto es la declaración de que "el código se documenta a sí mismo". La experiencia ha demostrado que leer el código fuente es como escuchar las previsiones meteorológicas: las personas inteligentes aún saldrán a mirar el cielo. A continuación se presentan sugerencias para verificar y examinar el arranque del sistema Linux utilizando herramientas de depuración familiares. Un análisis del proceso de arranque de un sistema que funciona bien prepara a los usuarios y desarrolladores para resolver fallas inevitables.
Por un lado, el proceso de descarga es sorprendentemente simple. El núcleo del sistema operativo (kernel) se ejecuta con un solo subproceso y sincrónicamente en un núcleo (núcleo), lo que puede parecer comprensible incluso para una mente humana patética. Pero, ¿cómo comienza el núcleo del sistema operativo? ¿Qué funciones hacen initrd (
un disco RAM para la inicialización inicial ) y los cargadores de arranque? Y espera, ¿por qué el LED en el puerto Ethernet siempre está encendido?

Siga leyendo para obtener respuestas a estas y algunas otras preguntas; El código para las demostraciones y ejercicios descritos también está disponible en
GitHub .
Inicio del arranque: estado desactivadoWake-on-LANUn estado de APAGADO significa que el sistema no tiene energía, ¿verdad? La aparente simplicidad es engañosa. Por ejemplo, el LED de Ethernet está encendido incluso en este estado, porque la activación en LAN (WOL, activación en [señal desde] red local) está activada en su sistema. Asegúrate escribiendo:
$# sudo ethtool <interface name>
Donde, en cambio, puede ser, por ejemplo, eth0 (ethtool está en paquetes Linux con el mismo nombre). Si el "Wake-on" en la salida muestra g, los hosts remotos pueden iniciar el sistema enviando
MagicPacket . Si no desea encender su sistema de forma remota y dar esta oportunidad a otros, desactive WOL en el menú del BIOS del sistema o use:
$# sudo ethtool -s <interface name> wol d
Un procesador que responde a MagicPacket puede ser un
controlador de administración de placa base (BMC) o parte de una interfaz de red.
Intel Management Engine, Platform Controller Hub y MinixBMC no es el único microcontrolador (MCU) que puede "escuchar" un sistema apagado nominalmente. Los sistemas X86_64 tienen el paquete de software Intel Management Engine (IME) para la administración remota de sistemas. Una amplia gama de dispositivos, desde servidores hasta computadoras portátiles, tienen tecnología que
tiene características como KVM Remote Control o Intel Capability Licensing Service. Según la
herramienta de Inte l,
IME tiene vulnerabilidades sin parches. La mala noticia es que deshabilitar IME es difícil. Trammell Hudson creó
el proyecto me_cleaner, que borra algunos de los componentes IME más atroces, como el servidor web incorporado, pero al mismo tiempo existe la posibilidad de que el uso del proyecto convierta el sistema en el que se está ejecutando.
El firmware IME y el programa de Modo de administración del sistema (SMM) que lo sigue en el arranque se basan en
el sistema operativo Minix y se ejecutan en un procesador Hub de controlador de plataforma separado, no en la CPU principal del sistema. Luego, SMM lanza el programa Universal Extensible Firmware Interface (UEFI) en el procesador principal, que se ha
escrito más de una vez . El grupo Coreboot lanzó un proyecto
de firmware reducido no extensible (NERF) espectacularmente ambicioso en Google, que tiene como objetivo reemplazar no solo UEFI, sino también los primeros componentes del espacio de usuario de Linux, como systemd. Mientras tanto, estamos esperando los resultados, los usuarios de Linux pueden comprar computadoras portátiles de Purism, System76 o Dell, en las que
IME está desactivado , además, podemos esperar computadoras portátiles con un
procesador ARM de 64 bits .
Cargadores
¿Qué hace el firmware de arranque además de lanzar el presunto spyware? La tarea del gestor de arranque es proporcionar al procesador que se acaba de encender con los recursos necesarios para ejecutar un sistema operativo de propósito general como Linux. Durante el encendido, no solo hay memoria virtual, sino también DRAM hasta el momento de elevar su controlador. Luego, el cargador de arranque enciende las fuentes de alimentación y escanea los buses e interfaces para encontrar la imagen del núcleo y el sistema de archivos raíz. Los cargadores de arranque populares, como U-Boot y GRUB, admiten interfaces comunes como USB, PCI y NFS, así como otros dispositivos integrados más especializados, como NOR y NAND-flash. Los cargadores también interactúan con dispositivos de hardware de seguridad, como
Trusted Platform Module (TPM) , para establecer una cadena de confianza desde el inicio de la descarga.
 Ejecutando el cargador U-boot en el sandbox en el servidor de compilación.
Ejecutando el cargador U-boot en el sandbox en el servidor de compilación.El popular
cargador de arranque
U-Boot de código abierto es compatible con sistemas desde Raspberry Pi hasta dispositivos Nintendo, tableros de automóviles y Chromebooks. No hay registro del sistema, y si algo sale mal, puede que ni siquiera haya salida de consola. Para facilitar la depuración, el equipo de U-Boot proporciona un entorno limitado para probar parches en el host de compilación o incluso en el sistema de integración continua. En un sistema con herramientas de desarrollo comunes como Git y GNU Compiler Collection (GCC) instaladas, comprender el entorno limitado de U-Boot es fácil.
$# git clone git://git.denx.de/u-boot; cd u-boot $# make ARCH=sandbox defconfig $# make; ./u-boot => printenv => help
Eso es todo: lanzó U-Boot en x86_64 y puede probar características complicadas, por ejemplo, repartición de
dispositivos de almacenamiento ficticios , manipulación de claves secretas basadas en TPM y conexión en caliente de dispositivos USB. El entorno limitado U-Boot puede ser de una etapa dentro del depurador GDB. El desarrollo utilizando el sandbox es 10 veces más rápido que las pruebas sobrescribiendo el gestor de arranque en el tablero, además, el sandbox "ladrillo" se puede restaurar presionando Ctrl + C.
Lanzamiento de KernelSuministro de kernel de arranqueUna vez completadas sus tareas, el gestor de arranque cambiará al código del núcleo que cargó en la memoria principal y comenzará a ejecutarlo, pasando todos los parámetros de línea de comando que especificó el usuario. ¿Qué programa es el kernel? file / boot / vmlinuz muestra que esto es bzImage. El árbol fuente de Linux tiene
una herramienta extract-vmlinux que puede usar para extraer el archivo:
$# scripts/extract-vmlinux /boot/vmlinuz-$(uname -r) > vmlinux $# file vmlinux vmlinux: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), statically linked, stripped
El kernel es un archivo binario de
formato ejecutable y de enlace (ELF) , como los programas de espacio de usuario de Linux. Esto significa que podemos usar comandos binutils como readelf para aprenderlo. Compare, por ejemplo, las siguientes conclusiones:
$# readelf -S /bin/date $# readelf -S vmlinux
La lista de particiones en archivos binarios es en su mayor parte similar.
Entonces, el kernel debería lanzar otros binarios ELF de Linux ... ¿Pero cómo se ejecutan los programas de espacio de usuario? En la función
main() , ¿verdad? En realidad no
Antes de ejecutar la función
main() , los programas necesitan un contexto de ejecución, que incluye memoria heap- (heap) y stack- (stack), además de descriptores de archivo para
stdio ,
stdout y
stderr . Los programas de espacio de usuario obtienen estos recursos de la biblioteca estándar (
glibc para la mayoría de los sistemas Linux). Considere lo siguiente:
$# file /bin/date /bin/date: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 2.6.32, BuildID[sha1]=14e8563676febeb06d701dbee35d225c5a8e565a, stripped
Los archivos binarios ELF tienen un intérprete, al igual que los scripts de Bash y Python. ¡Pero no necesita especificarse a través de
#! como en los scripts, porque ELF es un formato nativo de Linux. El intérprete ELF proporciona al archivo binario todos los recursos necesarios llamando a
_start() , una función disponible en el
glibc fuente
glibc , que se puede aprender a través de
GDB . El núcleo, obviamente, no tiene un intérprete, y debería suministrarse de forma independiente, pero ¿cómo?
Un estudio sobre cómo iniciar un núcleo con GDB proporciona una respuesta a esta pregunta. Para comenzar, instale el paquete de depuración del núcleo, que contiene la versión sin cortar de
vmlinux , por ejemplo,
apt-get install linux-image-amd64-dbg . O compile e instale su propio núcleo desde alguna fuente, por ejemplo, siguiendo las instrucciones del excelente
Manual del núcleo de Debian .
gdb vmlinux seguido de
info files muestra la sección ELF
init.text . Indique el inicio de la ejecución del programa en
init.text con
l *(address) , donde dirección es el inicio hexadecimal de
init.text . GDB indicará que el núcleo x86_64 se inicia en el
arch/x86/kernel/head_64.S , donde encontramos la función de compilación
start_cpu0() y el código que crea explícitamente la pila y descomprime zImage antes de llamar a
x86_64 start_kernel() . Los núcleos ARM de 32 bits tienen un
arch/arm/kernel/head.S. start_kernel() arch/arm/kernel/head.S. start_kernel() es independiente de la arquitectura, por lo que la función se encuentra en el núcleo
init/main.c Podemos decir que
start_kernel() es una función real
main() Linux.
De start_kernel () a PID 1Manifiesto del hardware del núcleo: tablas ACPI y árboles de dispositivosAl arrancar, el kernel necesita información sobre el hardware además del tipo de procesador para el que fue compilado. Las instrucciones en el código se complementan con datos de configuración, que se almacenan por separado. Hay dos métodos principales para almacenar datos:
árboles de dispositivos y
tablas ACPI . A partir de estos archivos, el kernel descubre qué equipo debe ejecutarse en cada arranque.
Para dispositivos integrados, el árbol de dispositivos (DU) es un manifiesto del equipo instalado. DU es un archivo que se compila al mismo tiempo que la fuente del núcleo y generalmente se encuentra en / boot junto con
vmlinux . Para ver qué hay en el árbol de dispositivos binarios en el dispositivo ARM, simplemente use el comando de
strings del paquete binutils en el archivo cuyo nombre corresponde a
/boot/*.dtb , ya que
dtb significa el archivo binario del árbol de dispositivos (Device-Tree Binary). Puede cambiar el control remoto editando los archivos similares a JSON en los que se compone y reiniciando el compilador dtc especial provisto con la fuente del núcleo. DU es un archivo estático cuya ruta generalmente se pasa al núcleo por los gestores de arranque en la línea de comando, pero en los últimos años se ha agregado una
superposición de árbol de dispositivos donde el núcleo puede cargar dinámicamente fragmentos adicionales en respuesta a eventos de conexión en caliente después de la carga.
La familia x86 y muchos dispositivos de nivel empresarial ARM64 utilizan el mecanismo alternativo de Interfaz avanzada de configuración y energía (
ACPI) . A diferencia del control remoto, la información ACPI se almacena en el sistema de archivos virtual
/sys/firmware/acpi/tables , que es creado por el núcleo al inicio al acceder a la ROM interna. Para leer las tablas ACPI, use el comando
acpica-tools paquete
acpica-tools . Aquí hay un ejemplo:
 Las tablas ACPI en las computadoras portátiles Lenovo están listas para Windows 2001.
Las tablas ACPI en las computadoras portátiles Lenovo están listas para Windows 2001.Sí, su sistema Linux está listo para Windows 2001 si desea instalarlo. ACPI tiene métodos y datos, en contraste con el control remoto, que es más como un lenguaje de descripción de hardware. Los métodos ACPI continúan activos después del arranque. Por ejemplo, si ejecuta el comando acpi_listen (desde el paquete apcid) y luego cierra y abre la tapa de la computadora portátil, verá que la funcionalidad ACPI continuó funcionando todo este tiempo. La
reescritura temporal y dinámica
de las tablas ACPI es posible, pero el cambio permanente requerirá la interacción con el menú del BIOS al arrancar o flashear la ROM. En lugar de tales complejidades, quizás debería simplemente
instalar coreboot , un reemplazo para el firmware de código abierto.
De start_kernel () al espacio de usuario
El código en
init/main.c es sorprendentemente fácil de leer y, curiosamente, todavía usa los derechos de autor originales de Linus Torvalds de 1991-1992. Líneas encontradas en
dmesg | head dmesg | head sistema en ejecución se origina básicamente en este archivo fuente. El sistema registra la primera CPU, las estructuras de datos globales se inicializan, una tras otra, se activan el planificador, los controladores de interrupciones (IRQ), los temporizadores y la consola. Todas las marcas de tiempo antes de ejecutar
timekeeping_init() son cero. Esta parte de la inicialización del núcleo es síncrona, es decir, la ejecución se produce en un solo subproceso. Las funciones no se ejecutan hasta que se completa y se devuelve la última. Como resultado, la salida de
dmesg será totalmente reproducible incluso entre los dos sistemas, siempre que tengan el mismo control remoto o tablas ACPI. Linux también se comporta como un sistema operativo en tiempo real (RTOS) que se ejecuta en una MCU, como QNX o VxWorks. Esta situación se almacena en la función
rest_init() , que es llamada por
start_kernel() en el momento de su finalización.
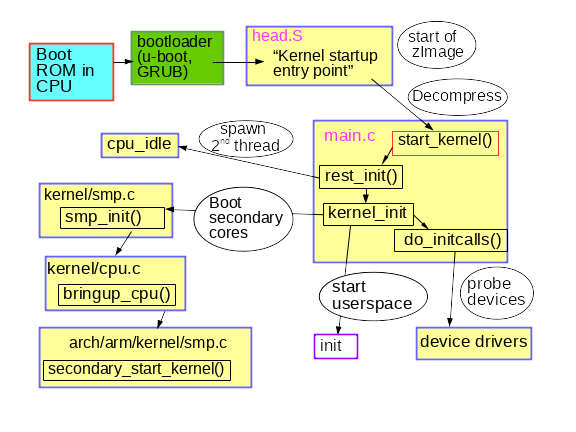 Una breve descripción del proceso inicial de arranque del kernel
Una breve descripción del proceso inicial de arranque del kernel
El modesto nombre
rest_init() crea un nuevo hilo que ejecuta
kernel_init() , que a su vez llama a
do_initcalls() . Los usuarios pueden monitorear la operación de
initcalls agregando
initcalls_debug a la línea de comando del kernel. Como resultado, obtendrá la entidad
dmesg cada vez que ejecute la función
initcall .
initcalls pasa por siete niveles consecutivos: temprano, núcleo, postcore, arch, subsys, fs, dispositivo y tarde. La parte más notable de
initcalls para los usuarios es la identificación e instalación de dispositivos periféricos del procesador: buses, red, almacenamiento, pantallas, etc., acompañados de la carga de sus módulos de kernel.
rest_init() también crea un segundo subproceso en el procesador de arranque, que comienza ejecutando
cpu_idle() mientras el programador distribuye su trabajo.
kernel_init() también configura el
multiprocesamiento simétrico (SMP). En los núcleos modernos, puede encontrar este momento en la salida de dmesg con la línea "Activando CPU secundarias ...". SMP luego realiza la conexión en caliente de la CPU, lo que significa que gestiona su ciclo de vida utilizando una máquina de estado condicionalmente similar a la utilizada en dispositivos como memorias USB con detección automática. El sistema de administración de energía del núcleo a menudo apaga los núcleos individuales (núcleos) y los activa según sea necesario para que el mismo código de CPU de conexión en caliente se llame repetidamente en una máquina desocupada. Eche un vistazo a cómo un sistema de administración de energía
offcputime.py CPU utilizando
una herramienta BCC llamada
offcputime.py .
Tenga en cuenta que el código en
init/main.c casi terminó de ejecutarse cuando se
smp_init() . El procesador de arranque completó la mayor parte de la inicialización única, que otros núcleos no necesitan repetir. Sin embargo, se deben crear subprocesos para cada núcleo para controlar las interrupciones (IRQ), la cola de trabajo, los temporizadores y los eventos de potencia en cada uno. Por ejemplo, observe los hilos del procesador que sirven softirqs y colas de trabajo con el comando
ps -o psr. psr
ps -o psr. $\
donde el campo PSR significa "procesador". Cada núcleo debe tener sus propios temporizadores y controladores de conexión en caliente cpuhp.
Y finalmente, ¿cómo se lanza el espacio de usuario? Hacia el final,
kernel_init() buscando un
initrd que pueda iniciar el proceso
init en su nombre. Si no, el núcleo ejecuta
init sí solo. ¿Por qué entonces se puede necesitar
initrd ?
Espacio de usuario temprano: ¿quién ordenó initrd?Además del árbol de dispositivos, otra ruta de inicio al archivo, opcionalmente proporcionada por el núcleo en el arranque, pertenece a
initrd .
initrd menudo se encuentra en / boot junto con el archivo bzImage vmlinuz en x86, o con un árbol similar de imágenes y dispositivos para ARM. Se puede ver una lista de contenidos
intrd usando la herramienta
lsinitramfs , que es parte del paquete
initramfs-tools-core . La imagen de distribución initrd contiene los directorios mínimos
/bin ,
/sbin y
/etc , así como los módulos del núcleo y los archivos en
/scripts . Todo debería parecer más o menos familiar, ya que
initrd en su mayor parte similar al sistema simplificado de archivos raíz de Linux. Esta similitud es un poco engañosa, ya que casi todos los ejecutables en
/bin y
/sbin dentro de ramdisk son enlaces simbólicos al
binario BusyBox , lo que hace que los directorios / bin y / sbin sean 10 veces más pequeños que en
glibc .
¿Por qué intentar crear un
initrd si lo único que hace es cargar algunos módulos y ejecutar
init en un sistema de archivos raíz normal? Considere un sistema de archivos raíz encriptado. El descifrado puede depender de cargar el módulo del núcleo almacenado en
/lib/modules sistema de archivos raíz ... y, como se esperaba, en
initrd . El módulo criptográfico puede compilarse estáticamente en el kernel y no cargarse desde un archivo, pero hay varias razones para rechazar esto. Por ejemplo, la compilación estática de un núcleo con módulos puede hacer que sea demasiado grande para caber en el almacenamiento disponible, o la compilación estática puede violar los términos de la licencia de software. Como era de esperar, los controladores de almacenamiento, las redes y los HID (dispositivos de entrada humanos) también se pueden representar en
initrd , esencialmente cualquier código que no sea una parte necesaria del núcleo necesario para montar el sistema de archivos raíz. También en initrd, los usuarios pueden almacenar
su propio código ACPI para tablas .
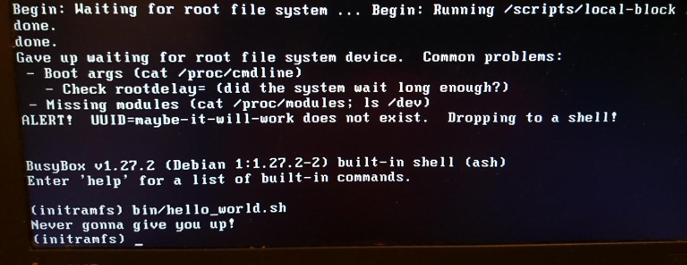 Diversión con shell de rescate e initrd personalizado.
Diversión con shell de rescate e initrd personalizado.initrd también
initrd ideal para probar sistemas de archivos y dispositivos de almacenamiento. Coloque las herramientas de prueba en
initrd y ejecute las pruebas desde la memoria, no desde el objeto de prueba.
Finalmente, cuando
init ejecutando, ¡el sistema se está ejecutando! Dado que los procesadores secundarios ya están en funcionamiento, la máquina se ha convertido en una criatura asíncrona, paginada, impredecible y de alto rendimiento que todos conocemos y amamos. De hecho,
ps -o pid,psr,comm -p indica que el proceso de
init espacio de usuario ya no se ejecuta en el procesador de arranque.
ResumenEl proceso de arranque de Linux parece prohibido, dada la cantidad de software afectado, incluso en un dispositivo integrado simple. Por otro lado, el proceso de arranque es bastante simple, ya que no hay una complejidad excesiva causada por el desplazamiento de multitarea, RCU y condiciones de carrera. Prestando atención solo al kernel y al PID 1, se puede pasar por alto el gran trabajo realizado por los cargadores de arranque y los procesadores auxiliares para preparar la plataforma para el lanzamiento del kernel. El kernel es ciertamente diferente de otros programas de Linux, pero el uso de herramientas para trabajar con otros binarios ELF ayudará a comprender mejor su estructura. Estudiar un proceso de arranque viable preparará para futuros bloqueos.
El fin
Estamos esperando sus comentarios y preguntas, como de costumbre, ya sea aquí o en nuestra
lección abierta donde Leonid quedará impresionado.