Esencia
Resulta que para esto es suficiente ejecutar tal conjunto de comandos:
git clone https://github.com/attardi/wikiextractor.git cd wikiextractor wget http://dumps.wikimedia.org/ruwiki/latest/ruwiki-latest-pages-articles.xml.bz2 python3 WikiExtractor.py -o ../data/wiki/ --no-templates --processes 8 ../data/ruwiki-latest-pages-articles.xml.bz2
y luego pulir un poco con un script para el procesamiento posterior
python3 process_wikipedia.py
El resultado es un archivo .csv terminado con su cuerpo.
Está claro que:
http://dumps.wikimedia.org/ruwiki/latest/ruwiki-latest-pages-articles.xml.bz2 se puede cambiar al idioma que necesita, más detalles aquí [4] ;- Toda la información sobre los parámetros de
wikiextractor se puede encontrar en el manual (parece que incluso el muelle oficial no se ha actualizado, a diferencia del mana);
Un script de procesamiento posterior convierte los archivos wiki en una tabla como esta:
| idx | article_uuid | sentencia | oración limpia | longitud de la oración limpia |
|---|
| 0 0 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | Jean I de Chatillon (Conde de Pentevre) Jean I de ... | jean i de châtillon conde de pentevre jean i de cha ... | 38 |
| 1 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | Estaba bajo la protección de Robert de Vera, conde O ... | fue custodiado por robert de vera graph oxford ... | 18 años |
| 2 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | Sin embargo, Henry de Gromont, gr ... | sin embargo, Henry de Gromon gras se opuso a esto ... | 14 |
| 3 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | El rey le ofreció otra característica importante como esposa ... | el rey le ofreció a su esposa otra persona importante de fili ... | 48 |
| 4 4 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | Jean fue liberado y regresó a Francia en 138 ... | jean liberado de nuevo francia año boda m ... | 52 |
article_uuid: una clave pseudo-única, el orden de la idea debe conservarse después de dicho preprocesamiento.
Porque
Quizás, en este momento, el desarrollo de las herramientas ML ha alcanzado un nivel tal [8] que literalmente un par de días es suficiente para construir un modelo / tubería de PNL que funcione. Los problemas surgen solo en ausencia de conjuntos de datos confiables / incrustaciones listas / modelos de lenguaje listos. El propósito de este artículo es aliviar un poco su dolor al mostrar que un par de horas es suficiente para procesar toda la Wikipedia (en teoría, el corpus más popular para entrenar incrustaciones de palabras en PNL). Después de todo, si un par de días es suficiente para construir un modelo simple, ¿por qué dedicar mucho más tiempo a obtener datos para este modelo?
El principio del guion
wikiExtractor guarda los artículos de Wiki como texto separado por bloques <doc> . En realidad, el script se basa en la siguiente lógica:
- Tome una lista de todos los archivos en la salida;
- Dividimos archivos en artículos;
- Elimine todas las etiquetas HTML restantes y caracteres especiales;
- Usando
nltk.sent_tokenize dividimos en oraciones; - Para que el código no crezca a un tamaño enorme y siga siendo legible, a cada artículo se le asigna su propio uuid;
Como preprocesamiento de texto, es simple (puede cortarlo usted mismo fácilmente):
- Eliminar caracteres que no sean letras;
- Eliminar palabras de parada;
Conjunto de datos es, ¿y ahora qué?
Aplicación principal
La mayoría de las veces, en la práctica, en PNL tiene que ocuparse de la tarea de construir incrustaciones.
Para resolverlo, usualmente use una de las siguientes herramientas:
- Vectores / incrustaciones de palabras listas para usar [6];
- Los estados internos de CNN entrenados en tareas tales como la determinación de oraciones falsas / modelado / clasificación del lenguaje [7];
- Una combinación de los métodos anteriores;
Además, se ha demostrado muchas veces [9] que, como buena línea de base para incrustar oraciones, también se pueden tomar vectores de palabras simplemente promediados (con un par de detalles menores, que omitiremos ahora).
Otros casos de uso
- Utilizamos oraciones aleatorias de Wiki como ejemplos negativos para la pérdida de triplete;
- Entrenamos codificadores para oraciones usando la definición de frases falsas [10];
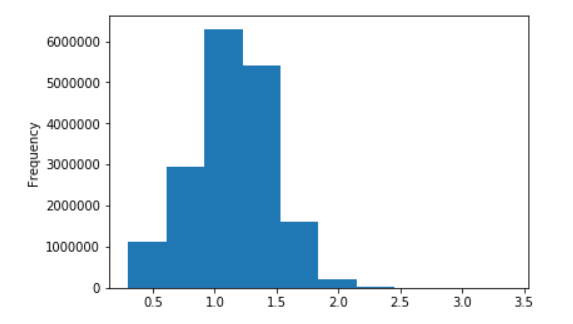
Algunos gráficos para la Wiki rusa
Distribución de longitud de oraciones para Wikipedia en ruso
Sin logaritmos (en el eje X, los valores están limitados a 20)
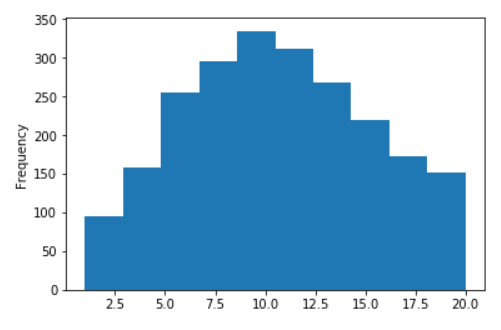
En logaritmos decimales
Referencias
- Vectores de palabras de texto rápido formados en una wiki;
- Modelos de texto rápido y Word2Vec para el idioma ruso;
- Impresionante biblioteca extractora de wiki para python;
- La página oficial con enlaces para Wiki;
- Nuestro script para postprocesamiento;
- Artículos principales sobre incrustaciones de palabras: Word2Vec , Fast-Text , tuning ;
- Varios enfoques actuales de SOTA:
- InferSent ;
- CNN pre-entrenamiento generativo;
- ULMFiT ;
- Enfoques contextuales para la representación de palabras (Elmo);
- ¿Momento de Imagenet en PNL ?
- Líneas de base para incluir propuestas 1 , 2 , 3 , 4 ;
- Definición de frases falsas para codificador de oferta;