La teoría de juegos es una disciplina matemática que considera modelar las acciones de los jugadores que tienen un objetivo, que es elegir las estrategias óptimas para el comportamiento en un conflicto. En Habré, este tema ya se ha
cubierto , pero hoy hablaremos sobre algunos de sus aspectos con más detalle y consideraremos ejemplos sobre Kotlin.
Entonces, una estrategia es un conjunto de reglas que determinan la elección de un curso de acción para cada movimiento personal, dependiendo de la situación. La estrategia óptima del jugador es la estrategia que asegura la mejor posición en un juego determinado, es decir. ganancia máxima Si el juego se repite varias veces y contiene, además de movimientos personales al azar, la estrategia óptima proporciona la ganancia máxima promedio.
La tarea de la teoría de juegos es identificar las estrategias óptimas para los jugadores. La suposición principal, en base a la cual se encuentran las estrategias óptimas, es que el oponente (u oponentes) no es menos inteligente que el propio jugador, y hace todo lo posible para lograr su objetivo. El cálculo de un oponente razonable es solo una de las posibles posiciones en el conflicto, pero en la teoría de los juegos es la base.
Hay juegos con la naturaleza en los que solo hay un participante que maximiza sus ganancias. Los juegos con la naturaleza son modelos matemáticos en los que la elección de la solución depende de la realidad objetiva. Por ejemplo, demanda del consumidor, estado de la naturaleza, etc. "Naturaleza" es un concepto generalizado de un adversario que no persigue sus propios objetivos. En este caso, se utilizan varios criterios para seleccionar la estrategia óptima.
Hay dos tipos de tareas en los juegos con la naturaleza:
- la tarea de tomar decisiones en condiciones de riesgo cuando se conocen las probabilidades con las que la naturaleza acepta cada uno de los estados posibles;
- tareas de toma de decisiones en condiciones de incertidumbre, cuando no es posible obtener información sobre las probabilidades de ocurrencia de estados de la naturaleza.
Brevemente sobre estos criterios se describe
aquí .
Ahora consideraremos los criterios de toma de decisiones en estrategias puras, y al final del artículo resolveremos el juego en estrategias mixtas por el método analítico.
ReservaNo soy especialista en teoría de juegos, pero en este trabajo utilicé Kotlin por primera vez. Sin embargo, decidí compartir mis resultados. Si observa errores en el artículo o desea dar consejos, por favor en PM.
Declaración del problema.
Analizaremos todos los criterios de toma de decisiones utilizando un ejemplo directo. La tarea es esta: el agricultor necesita determinar en qué proporciones sembrar su campo con tres cultivos, si el rendimiento de estos cultivos y, por lo tanto, el beneficio, depende de cómo será el verano: fresco y lluvioso, normal o cálido y seco. El agricultor calculó el beneficio neto de 1 hectárea de diferentes cultivos según el clima. El juego está determinado por la siguiente matriz:

Además presentaremos esta matriz en forma de estrategias:
U1=(0,2,5),U2=(2,3,1),U3=(4,3,−1)
La estrategia óptima deseada se denota por
uopt . Resolveremos el juego utilizando los criterios de Wald, optimismo, pesimismo, Savage y Hurwitz en condiciones de incertidumbre y los criterios de Bayes y Laplace en condiciones de riesgo.
Como se mencionó anteriormente, los ejemplos estarán en Kotlin. Observo que, en general, existen soluciones como Gambit (escrito en C), Axelrod y PyNFG (escrito en Python), pero montaremos nuestra propia bicicleta, montada en la rodilla, solo para pinchar un poco con estilo, moda y lenguaje de programación juvenil.
Para implementar mediante programación la solución del juego, presentaremos varias clases. Primero, necesitamos una clase que nos permita describir una fila o columna de una matriz de juego. La clase es extremadamente simple y contiene una lista de posibles valores (alternativas o estados de la naturaleza) y su nombre correspondiente. El campo
key se utilizará para la identificación, así como para la comparación, y será necesaria la comparación en la implementación de la dominación.
Matriz de juego fila o columna import java.text.DecimalFormat import java.text.NumberFormat open class GameVector(name: String, values: List<Double>, key: Int = -1) : Comparable<GameVector> { val name: String val values: List<Double> val key: Int private val formatter:NumberFormat = DecimalFormat("#0.00") init { this.name = name; this.values = values; this.key = key; } public fun max(): Double? { return values.max(); } public fun min(): Double? { return values.min(); } override fun toString(): String{ return name + ": " + values .map { v -> formatter.format(v) } .reduce( {f1: String, f2: String -> "$f1 $f2"}) } override fun compareTo(other: GameVector): Int { var compare = 0 if (this.key == other.key){ return compare } var great = true for (i in 0..this.values.lastIndex){ great = great && this.values[i] >= other.values[i] } if (great){ compare = 1 }else{ var less = true for (i in 0..this.values.lastIndex){ less = less && this.values[i] <= other.values[i] } if (less){ compare = -1 } } return compare } }
La matriz del juego contiene información sobre alternativas y estados de la naturaleza. Además, implementa algunos métodos, por ejemplo, encontrar el conjunto dominante y el precio neto del juego.
Matriz de juego open class GameMatrix(matrix: List<List<Double>>, alternativeNames: List<String>, natureStateNames: List<String>) { val matrix: List<List<Double>> val alternativeNames: List<String> val natureStateNames: List<String> val alternatives: List<GameVector> val natureStates: List<GameVector> init { this.matrix = matrix; this.alternativeNames = alternativeNames this.natureStateNames = natureStateNames var alts: MutableList<GameVector> = mutableListOf() for (i in 0..matrix.lastIndex) { val currAlternative = alternativeNames[i] val gameVector = GameVector(currAlternative, matrix[i], i) alts.add(gameVector) } alternatives = alts.toList() var nss: MutableList<GameVector> = mutableListOf() val lastIndex = matrix[0].lastIndex // , for (j in 0..lastIndex) { val currState = natureStateNames[j] var states: MutableList<Double> = mutableListOf() for (i in 0..matrix.lastIndex) { states.add(matrix[i][j]) } val gameVector = GameVector(currState, states.toList(), j) nss.add(gameVector) } natureStates = nss.toList() } open fun change (i : Int, j : Int, value : Double) : GameMatrix{ var mml = this.matrix.toMutableList() var rowi = mml[i].toMutableList() rowi.set(j, value) mml.set(i, rowi) return GameMatrix(mml.toList(), alternativeNames, natureStateNames) } open fun changeAlternativeName (i : Int, value : String) : GameMatrix{ var list = alternativeNames.toMutableList() list.set(i, value) return GameMatrix(matrix, list.toList(), natureStateNames) } open fun changeNatureStateName (j : Int, value : String) : GameMatrix{ var list = natureStateNames.toMutableList() list.set(j, value) return GameMatrix(matrix, alternativeNames, list.toList()) } fun size() : Pair<Int, Int>{ return Pair(alternatives.size, natureStates.size) } override fun toString(): String { return " :\n" + natureStateNames.reduce { n1: String, n2: String -> "$n1;\n$n2" } + "\n :\n" + alternatives .map { a: GameVector -> a.toString() } .reduce { a1: String, a2: String -> "$a1;\n$a2" } } protected fun dominateSet(gvl: List<GameVector>, list: MutableList<String>, dvv: Int) : MutableSet<GameVector>{ var dSet: MutableSet<GameVector> = mutableSetOf() for (gv in gvl){ for (gvv in gvl){ if (!dSet.contains(gv) && !dSet.contains(gvv)) { if (gv.compareTo(gvv) == dvv) { dSet.add(gv) list.add("[$gvv] [$gv]") } } } } return dSet } open fun newMatrix(dCol: MutableSet<GameVector>, dRow: MutableSet<GameVector>) : GameMatrix{ var result: MutableList<MutableList<Double>> = mutableListOf() var ralternativeNames: MutableList<String> = mutableListOf() var rnatureStateNames: MutableList<String> = mutableListOf() val dIndex = dCol.map { c -> c.key }.toList() for (i in 0 .. natureStateNames.lastIndex){ if (!dIndex.contains(i)){ rnatureStateNames.add(natureStateNames[i]) } } for (gv in this.alternatives){ if (!dRow.contains(gv)){ var nr: MutableList<Double> = mutableListOf() for (i in 0 .. gv.values.lastIndex){ if (!dIndex.contains(i)){ nr.add(gv.values[i]) } } result.add(nr) ralternativeNames.add(gv.name) } } val rlist = result.map { r -> r.toList() }.toList() return GameMatrix(rlist, ralternativeNames.toList(), rnatureStateNames.toList()) } fun dominateMatrix(): Pair<GameMatrix, List<String>>{ var list: MutableList<String> = mutableListOf() var dCol: MutableSet<GameVector> = dominateSet(this.natureStates, list, 1) var dRow: MutableSet<GameVector> = dominateSet(this.alternatives, list, -1) val newMatrix = newMatrix(dCol, dRow) var ddgm = Pair(newMatrix, list.toList()) val ret = iterate(ddgm, list) return ret; } protected fun iterate(ddgm: Pair<GameMatrix, List<String>>, list: MutableList<String>) : Pair<GameMatrix, List<String>>{ var dgm = this var lddgm = ddgm while (dgm.size() != lddgm.first.size()){ dgm = lddgm.first list.addAll(lddgm.second) lddgm = dgm.dominateMatrix() } return Pair(dgm,list.toList().distinct()) } fun minClearPrice(): Double{ val map: List<Double> = this.alternatives.map { a -> a?.min() ?: 0.0 } return map?.max() ?: 0.0 } fun maxClearPrice(): Double{ val map: List<Double> = this.natureStates.map { a -> a?.max() ?: 0.0 } return map?.min() ?: 0.0 } fun existsClearStrategy() : Boolean{ return minClearPrice() >= maxClearPrice() } }
Describimos la interfaz que cumple con los criterios.
Criterio interface ICriteria { fun optimum(): List<GameVector> }
Toma de decisiones bajo incertidumbre
Tomar decisiones ante la incertidumbre sugiere que el oponente razonable no se opone al jugador.
Criterio de Wald
El criterio de Wald maximiza el peor resultado posible:
uopt=maximinj[U]
Usar el criterio asegura contra el peor resultado, pero el precio de tal estrategia es la pérdida de la oportunidad de obtener el mejor resultado posible.
Considera un ejemplo. Para estrategias
U1=(0,2,5),U2=(2,3,1),U3=(4,3,−1) encuentra los mínimos y obtén los siguientes tres
S=(0,1,−1) . El máximo para el triple indicado será el valor 1, por lo tanto, de acuerdo con el criterio de Wald, la estrategia ganadora es la estrategia
U2=(2,3,1) correspondiente al cultivo de plantación 2.
La implementación del software del criterio de Wald es simple:
class WaldCriteria(gameMatrix : GameMatrix) : ICriteria { val gameMatrix: GameMatrix init{ this.gameMatrix = gameMatrix } override fun optimum(): List<GameVector> { val mins = gameMatrix.alternatives.map { a -> Pair(a, a.min()) } val max = mins.maxWith( Comparator { o1, o2 -> o1.second!!.compareTo(o2.second!!)}) return mins .filter { m -> m.second == max!!.second } .map { m -> m.first } } }
En aras de la claridad, por primera vez mostraré cómo se vería la solución como una prueba:
Prueba private fun matrix(): GameMatrix { val alternativeNames: List<String> = listOf(" 1", " 2", " 3") val natureStateNames: List<String> = listOf(" ", "", " ") val matrix: List<List<Double>> = listOf( listOf(0.0, 2.0, 5.0), listOf(2.0, 3.0, 1.0), listOf(4.0, 3.0, -1.0) ) val gm = GameMatrix(matrix, alternativeNames, natureStateNames) return gm; } } private fun testCriteria(gameMatrix: GameMatrix, criteria: ICriteria, name: String){ println(gameMatrix.toString()) val optimum = criteria.optimum() println("$name. : ") optimum.forEach { o -> println(o.toString()) } } @Test fun testWaldCriteria() { val matrix = matrix(); val criteria = WaldCriteria(matrix) testCriteria(matrix, criteria, " ") }
Es fácil adivinar que para otros criterios, la diferencia solo estará en la creación del objeto de
criteria .
Criterio de optimismo
Cuando se utiliza el criterio de un optimista, el jugador elige una solución que ofrezca el mejor resultado, mientras que el optimista supone que las condiciones del juego serán más favorables para él:
uopt=maximaxj[U]
La estrategia de un optimista puede tener consecuencias negativas cuando la oferta máxima coincide con la demanda mínima: la empresa puede recibir pérdidas al cancelar productos no vendidos. Al mismo tiempo, la estrategia del optimista tiene un cierto significado, por ejemplo, no necesita atender a clientes insatisfechos, ya que cualquier demanda posible siempre se satisface, por lo tanto, no es necesario mantener la ubicación de los clientes. Si se alcanza la máxima demanda, entonces la estrategia del optimista le permite obtener la máxima utilidad, mientras que otras estrategias conducirán a la pérdida de beneficios. Esto le da ciertas ventajas competitivas.
Considera un ejemplo. Para estrategias
U1=(0,2,5),U2=(2,3,1),U3=(4,3,−1) encontrar, encontrar el máximo y obtener los siguientes tres
S=(5,3,4) . El máximo para el triple indicado será el valor 5, por lo tanto, según el criterio de optimismo, la estrategia ganadora es la estrategia
U1=(0.2.5) correspondiente al cultivo de plantación 1.
La implementación del criterio de optimismo casi no es diferente del criterio de Wald:
class WaldCriteria(gameMatrix : GameMatrix) : ICriteria { val gameMatrix: GameMatrix init{ this.gameMatrix = gameMatrix } override fun optimum(): List<GameVector> { val mins = gameMatrix.alternatives.map { a -> Pair(a, a.min()) } val max = mins.maxWith( Comparator { o1, o2 -> o1.second!!.compareTo(o2.second!!)}) return mins .filter { m -> m.second == max!!.second } .map { m -> m.first } } }
Criterio de pesimismo
Este criterio está destinado a seleccionar el elemento más pequeño de la matriz del juego de sus elementos mínimos posibles:
uopt=miniminj[U]
El criterio del pesimismo sugiere que el desarrollo de los eventos será desfavorable para el tomador de decisiones. Al utilizar este criterio, el responsable de la toma de decisiones se guía por la posible pérdida de control sobre la situación, por lo tanto, trata de excluir los riesgos potenciales eligiendo la opción con una rentabilidad mínima.
Considera un ejemplo. Para estrategias
U1=(0,2,5),U2=(2,3,1),U3=(4,3,−1) encontrar, encontrar el mínimo y obtener los siguientes tres
S=(0,1,−1) . El mínimo para el triple indicado será el valor -1, por lo tanto, de acuerdo con el criterio de pesimismo, la estrategia ganadora es la estrategia
U3=(4.3,−1) correspondiente al cultivo de plantación 3.
Después de conocer los criterios y el optimismo de Wald, es fácil adivinar cómo se verá la clase del criterio de pesimismo:
class PessimismCriteria(gameMatrix : GameMatrix) : ICriteria { val gameMatrix: GameMatrix init{ this.gameMatrix = gameMatrix } override fun optimum(): List<GameVector> { val mins = gameMatrix.alternatives.map { a -> Pair(a, a.min()) } val min = mins.minWith( Comparator { o1, o2 -> o1.second!!.compareTo(o2.second!!)}) return mins .filter { m -> m.second == min!!.second } .map { m -> m.first } } }
Criterio salvaje
El criterio Salvaje (criterio de un pesimista arrepentido) implica minimizar las mayores ganancias perdidas, en otras palabras, minimizar el mayor arrepentimiento por las ganancias perdidas:
uopt=minimaxj[S]si,j=(max beginbmatrixu1,ju2,j...un,j endbmatrix−ui,j)
En este caso, S es la matriz de los arrepentimientos.
La solución óptima según el criterio de Savage debería dar el menor pesar de los arrepentimientos encontrados en el paso anterior. La solución correspondiente a la utilidad encontrada será óptima.
Las características de la solución obtenida incluyen una ausencia garantizada de las mayores decepciones y una disminución garantizada en las ganancias máximas posibles de otros jugadores.
Considera un ejemplo. Para estrategias
U1=(0,2,5),U2=(2,3,1),U3=(4,3,−1) hacer una matriz de arrepentimientos:
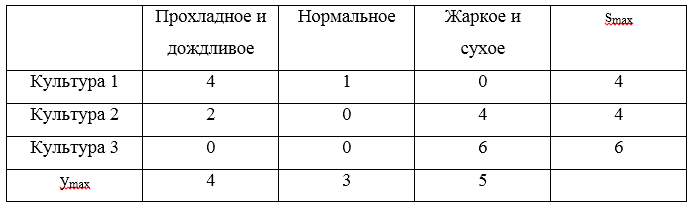
Tres arrepentimientos máximos
S=(4,4,6) . El valor mínimo de estos riesgos será un valor de 4, que corresponde a las estrategias.
U1 y
U2 .
Programar la prueba Savage es un poco más difícil:
class SavageCriteria(gameMatrix: GameMatrix) : ICriteria { val gameMatrix: GameMatrix init { this.gameMatrix = gameMatrix } fun GameMatrix.risk(): List<Pair<GameVector, Double?>> { val maxStates = this.natureStates.map { n -> Pair(n, n.values.max()) } .map { n -> n.first.key to n.second }.toMap() var am: MutableList<Pair<GameVector, List<Double>>> = mutableListOf() for (a in this.alternatives) { var v: MutableList<Double> = mutableListOf() for (i in 0..a.values.lastIndex) { val mn = maxStates.get(i) v.add(mn!! - a.values[i]) } am.add(Pair(a, v.toList())) } return am.map { m -> Pair(m.first, m.second.max()) } } override fun optimum(): List<GameVector> { val risk = gameMatrix.risk() val minRisk = risk.minWith(Comparator { o1, o2 -> o1.second!!.compareTo(o2.second!!) }) return risk .filter { r -> r.second == minRisk!!.second } .map { m -> m.first } } }
Criterio de Hurwitz
El criterio de Hurwitz es un compromiso regulado entre el pesimismo extremo y el optimismo completo:
uopt=max( gamma×A(k)+A(0)×(1− gamma))
A (0) es la estrategia del pesimista extremo, A (k) es la estrategia del optimista completo,
gamma=1 - valor establecido del coeficiente de peso:
0 leq gamma leq1 ;
gamma=0 - pesimismo extremo,
gamma=1 - Completo optimismo.
Con una pequeña cantidad de estrategias discretas, establecer el valor deseado del coeficiente de peso
gamma , y luego redondea el resultado al valor más cercano posible, teniendo en cuenta la discretización realizada.
Considera un ejemplo. Para estrategias
U1=(0,2,5),U2=(2,3,1),U3=(4,3,−1) . Suponemos que el coeficiente de optimismo
gamma=$0. . Ahora haz una tabla:
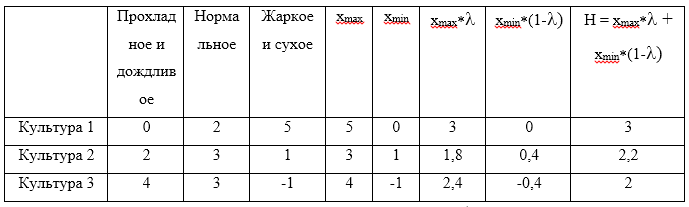
El valor máximo del H calculado será el valor 3, que corresponde a la estrategia.
U1 .
La implementación del criterio de Hurwitz ya es más voluminosa:
class HurwitzCriteria(gameMatrix: GameMatrix, optimisticKoef: Double) : ICriteria { val gameMatrix: GameMatrix val optimisticKoef: Double init { this.gameMatrix = gameMatrix this.optimisticKoef = optimisticKoef } inner class HurwitzParam(xmax: Double, xmin: Double, optXmax: Double){ val xmax: Double val xmin: Double val optXmax: Double val value: Double init{ this.xmax = xmax this.xmin = xmin this.optXmax = optXmax value = xmax * optXmax + xmin * (1 - optXmax) } } fun GameMatrix.getHurwitzParams(): List<Pair<GameVector, HurwitzParam>> { return this.alternatives.map { a -> Pair(a, HurwitzParam(a.max()!!, a.min()!!, optimisticKoef)) } } override fun optimum(): List<GameVector> { val hpar = gameMatrix.getHurwitzParams() val maxHurw = hpar.maxWith(Comparator { o1, o2 -> o1.second.value.compareTo(o2.second.value) }) return hpar .filter { r -> r.second == maxHurw!!.second } .map { m -> m.first } } }
Toma de decisiones en riesgo
Los métodos de toma de decisiones pueden basarse en criterios para la toma de decisiones en condiciones de riesgo, sujeto a las siguientes condiciones:
- falta de información confiable sobre las posibles consecuencias;
- la presencia de distribuciones de probabilidad;
- conocimiento de la probabilidad de resultados o consecuencias para cada decisión.
Si se toma una decisión en condiciones de riesgo, los costos de las decisiones alternativas se describen mediante distribuciones de probabilidad. En este sentido, la decisión se basa en el uso del criterio del valor esperado, según el cual se comparan soluciones alternativas en términos de maximizar las ganancias esperadas o minimizar los costos esperados.
El criterio del valor esperado se puede reducir para maximizar el beneficio esperado (promedio) o para minimizar los costos esperados. En este caso, se supone que el beneficio (costos) asociado con cada solución alternativa es una variable aleatoria.
La formulación de tales tareas suele ser la siguiente: una persona elige cualquier acción en una situación donde los eventos aleatorios influyen en el resultado de la acción. Pero el jugador tiene algún conocimiento sobre las probabilidades de estos eventos y puede calcular la combinación y secuencia más rentable de sus acciones.
Para continuar dando ejemplos, complementamos la matriz del juego con probabilidades:
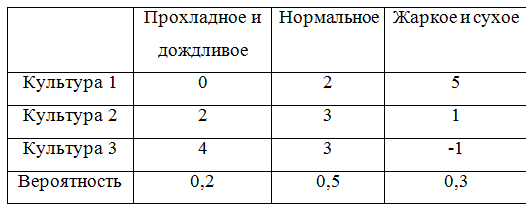
Para tener en cuenta las probabilidades, una clase que describa la matriz del juego tendrá que rehacerse ligeramente. Resultó, en verdad, no muy elegante, pero bueno.
Matriz de juego con probabilidades open class ProbabilityGameMatrix(matrix: List<List<Double>>, alternativeNames: List<String>, natureStateNames: List<String>, probabilities: List<Double>) : GameMatrix(matrix, alternativeNames, natureStateNames) { val probabilities: List<Double> init { this.probabilities = probabilities; } override fun change (i : Int, j : Int, value : Double) : GameMatrix{ val cm = super.change(i, j, value) return ProbabilityGameMatrix(cm.matrix, cm.alternativeNames, cm.natureStateNames, probabilities) } override fun changeAlternativeName (i : Int, value : String) : GameMatrix{ val cm = super.changeAlternativeName(i, value) return ProbabilityGameMatrix(cm.matrix, cm.alternativeNames, cm.natureStateNames, probabilities) } override fun changeNatureStateName (j : Int, value : String) : GameMatrix{ val cm = super.changeNatureStateName(j, value) return ProbabilityGameMatrix(cm.matrix, cm.alternativeNames, cm.natureStateNames, probabilities) } fun changeProbability (j : Int, value : Double) : GameMatrix{ var list = probabilities.toMutableList() list.set(j, value) return ProbabilityGameMatrix(matrix, alternativeNames, natureStateNames, list.toList()) } override fun toString(): String { var s = "" val formatter: NumberFormat = DecimalFormat("#0.00") for (i in 0 .. natureStateNames.lastIndex){ s += natureStateNames[i] + " = " + formatter.format(probabilities[i]) + "\n" } return " :\n" + s + " :\n" + alternatives .map { a: GameVector -> a.toString() } .reduce { a1: String, a2: String -> "$a1;\n$a2" } } override fun newMatrix(dCol: MutableSet<GameVector>, dRow: MutableSet<GameVector>) : GameMatrix{ var result: MutableList<MutableList<Double>> = mutableListOf() var ralternativeNames: MutableList<String> = mutableListOf() var rnatureStateNames: MutableList<String> = mutableListOf() var rprobailities: MutableList<Double> = mutableListOf() val dIndex = dCol.map { c -> c.key }.toList() for (i in 0 .. natureStateNames.lastIndex){ if (!dIndex.contains(i)){ rnatureStateNames.add(natureStateNames[i]) } } for (i in 0 .. probabilities.lastIndex){ if (!dIndex.contains(i)){ rprobailities.add(probabilities[i]) } } for (gv in this.alternatives){ if (!dRow.contains(gv)){ var nr: MutableList<Double> = mutableListOf() for (i in 0 .. gv.values.lastIndex){ if (!dIndex.contains(i)){ nr.add(gv.values[i]) } } result.add(nr) ralternativeNames.add(gv.name) } } val rlist = result.map { r -> r.toList() }.toList() return ProbabilityGameMatrix(rlist, ralternativeNames.toList(), rnatureStateNames.toList(), rprobailities.toList()) } } }
Criterio de Bayes
El criterio de Bayes (criterio de expectativa) se utiliza en problemas de toma de decisiones en condiciones de riesgo como una evaluación de la estrategia
ui Aparece la expectativa matemática de la variable aleatoria correspondiente. De acuerdo con esta regla, la estrategia óptima del jugador
uopt se encuentra a partir de la condición:
uopt=max1 leqi leqnM(ui)M(ui)=max1 leqi leqn summj=1ui,j cdoty0j
En otras palabras, un indicador de ineficiencia de la estrategia.
ui según el criterio de Bayes con respecto a los riesgos es el valor promedio (expectativa) de los riesgos de la i-ésima fila de la matriz
U cuyas probabilidades coinciden con las probabilidades de la naturaleza. Entonces lo óptimo entre las estrategias puras según el criterio de Bayes con respecto a los riesgos es la estrategia
uopt tener una ineficiencia mínima, es decir, un riesgo promedio mínimo. El criterio bayesiano es equivalente con respecto a las ganancias y relativo a los riesgos, es decir. si la estrategia
uopt es óptimo según el criterio de Bayes con respecto a las victorias, luego es óptimo según el criterio de Bayes con respecto a los riesgos, y viceversa.
Pasemos al ejemplo y calculemos las expectativas matemáticas:
M1=0 cdot0.2+2 cdot0.5+5 cdot0.3=2.5;M2=2 cdot0.2+3 cdot0.5+1 cdot0.3=2.2;M4=0 cdot0.2+3 cdot0.5+(−1) cdot0.3=2.0;
La expectativa matemática máxima es
M1 por lo tanto, una estrategia ganadora es una estrategia
U1 .
Implementación de software del criterio Bayes:
class BayesCriteria(gameMatrix: ProbabilityGameMatrix) : ICriteria { val gameMatrix: ProbabilityGameMatrix init { this.gameMatrix = gameMatrix } fun ProbabilityGameMatrix.bayesProbability(): List<Pair<GameVector, Double?>> { var am: MutableList<Pair<GameVector, Double>> = mutableListOf() for (a in this.alternatives) { var alprob: Double = 0.0 for (i in 0..a.values.lastIndex) { alprob += a.values[i] * this.probabilities[i] } am.add(Pair(a, alprob)) } return am.toList(); } override fun optimum(): List<GameVector> { val risk = gameMatrix.bayesProbability() val maxBayes = risk.maxWith(Comparator { o1, o2 -> o1.second!!.compareTo(o2.second!!) }) return risk .filter { r -> r.second == maxBayes!!.second } .map { m -> m.first } } }
Criterio de Laplace
El criterio de Laplace presenta una maximización simplificada de la expectativa matemática de utilidad cuando el supuesto de niveles iguales de probabilidad de demanda es válido, lo que elimina la necesidad de recopilar estadísticas reales.
En general, cuando se utiliza el criterio de Laplace, la matriz de utilidades esperadas y el criterio óptimo se determinan de la siguiente manera:
uopt=max[ overlineU] overlineU= beginbmatrix overlineu1 overlineu2... overlineun endbmatrix, overlineui= frac1n sumnj=1ui,j
Considere el ejemplo de la toma de decisiones según el criterio de Laplace. Calculamos la media aritmética para cada estrategia:
overlineu1= frac13 cdot(0+2+5)=2.3 overlineu2= frac13 cdot(2+3+1)=2.0 overlineu3= frac13 cdot(4+3−1)=$2.
Entonces la estrategia ganadora es la estrategia
U1 .
Implementación de software del criterio de Laplace:
class LaplaceCriteria(gameMatrix: GameMatrix) : ICriteria { val gameMatrix: GameMatrix init { this.gameMatrix = gameMatrix } fun GameMatrix.arithemicMean(): List<Pair<GameVector, Double>> { return this.alternatives.map { m -> Pair(m, m.values.average()) } } override fun optimum(): List<GameVector> { val risk = gameMatrix.arithemicMean() val maxBayes = risk.maxWith(Comparator { o1, o2 -> o1.second.compareTo(o2.second) }) return risk .filter { r -> r.second == maxBayes!!.second } .map { m -> m.first } } }
Estrategias mixtas. Método analítico
El método analítico le permite resolver el juego en estrategias mixtas. Para formular un algoritmo para encontrar una solución a un juego mediante un método analítico, consideramos algunos conceptos adicionales.
Estrategia
Ui domina la estrategia
Ui−1 si todo
u1..n∈Ui≥u1..n∈Ui−1 .
En otras palabras, si en una fila de una matriz de pago todos los elementos son mayores o iguales que los elementos correspondientes de otra fila, entonces la primera fila domina a la segunda y se llama fila dominante. Y también si en alguna columna de la matriz de pago todos los elementos son menores o iguales que los elementos correspondientes de otra columna, entonces la primera columna domina a la segunda y se llama columna dominante.El precio más bajo del juego se llamaα = m a x i m i n j u i j .
El precio más alto del juego se llama β = m i n j m a x i u i j .
Ahora puedes formular un algoritmo para resolver el juego por el método analítico:- Calcular fondo α y superiorprecios de los juegos β . Siα = β , luego escriba la respuesta en estrategias puras; de lo contrario, continúe con la solución
- Eliminar filas dominantes columnas dominantes. Puede haber varios. En su lugar en la estrategia óptima, los componentes correspondientes serán 0
- Resuelve el juego matricial mediante programación lineal.
Para dar un ejemplo, debe dar una clase que describa la soluciónResolver class Solve(gamePriceObr: Double, solutions: List<Double>, names: List<String>) { val gamePrice: Double val gamePriceObr: Double val solutions: List<Double> val names: List<String> private val formatter: NumberFormat = DecimalFormat("#0.00") init{ this.gamePrice = 1 / gamePriceObr this.gamePriceObr = gamePriceObr; this.solutions = solutions this.names = names } override fun toString(): String{ var s = " : " + formatter.format(gamePrice) + "\n" for (i in 0..solutions.lastIndex){ s += "$i) " + names[i] + " = " + formatter.format(solutions[i] / gamePriceObr) + "\n" } return s } fun itersect(matrix: GameMatrix): String{ var s = " : " + formatter.format(gamePrice) + "\n" for (j in 0..matrix.alternativeNames.lastIndex) { var f = false val a = matrix.alternativeNames[j] for (i in 0..solutions.lastIndex) { if (a.equals(names[i])) { s += "$j) " + names[i] + " = " + formatter.format(solutions[i] / gamePriceObr) + "\n" f = true break } } if (!f){ s += "$j) " + a + " = 0\n" } } return s } }
Y la clase que realiza la solución por el método simplex. Como no entiendo las matemáticas, utilicé la implementación preparada de Apache Commons MathSolucionador open class Solver (gameMatrix: GameMatrix) { val gameMatrix: GameMatrix init{ this.gameMatrix = gameMatrix } fun solve(): Solve{ val goalf: List<Double> = gameMatrix.alternatives.map { a -> 1.0 } val f = LinearObjectiveFunction(goalf.toDoubleArray(), 0.0) val constraints = ArrayList<LinearConstraint>() for (alt in gameMatrix.alternatives){ constraints.add(LinearConstraint(alt.values.toDoubleArray(), Relationship.LEQ, 1.0)) } val solution = SimplexSolver().optimize(f, LinearConstraintSet(constraints), GoalType.MAXIMIZE, NonNegativeConstraint(true)) val sl: List<Double> = solution.getPoint().toList() val solve = Solve(solution.getValue(), sl, gameMatrix.alternativeNames) return solve } }
Ahora ejecutamos la solución por el método analítico. Para mayor claridad, tomamos otra matriz de juego:( 2 4 8 5 6 2 4 6 3 2 5 4 )
Hay un conjunto dominante en esta matriz:( 2 4 6 2 )
Solución val alternativeNames: List<String> = listOf(" 1", " 2", " 3") val natureStateNames: List<String> = listOf(" ", "", " ", "") val matrix: List<List<Double>> = listOf( listOf(2.0, 4.0, 8.0, 5.0), listOf(6.0, 2.0, 4.0, 6.0), listOf(3.0, 2.0, 5.0, 4.0) ) val gm = GameMatrix(matrix, alternativeNames, natureStateNames) val (dgm, list) = gm.dominateMatrix() println(dgm.toString()) println(list.reduce({s1, s2 -> s1 + "\n" + s2})) println() val s: Solver = Solver(dgm) val solve = s.solve() println(solve)
Solución de juego ( 0 , 33 ; 0 , 67 ; 0 ) con el precio del juego igual a 3.33En lugar de una conclusión
Espero que este artículo sea útil para aquellos que necesitan una primera aproximación con la solución de los juegos con la naturaleza. En lugar de conclusiones, un enlace a GitHub .Estaría agradecido por los comentarios constructivos!