Hola a todos
Escribió una biblioteca para entrenar una red neuronal. A quién le importa, por favor.
Hace tiempo que quería convertirme en un instrumento de este nivel. C verano se puso manos a la obra. Esto es lo que sucedió:
- la biblioteca está escrita desde cero en C ++ (solo STL + OpenBLAS para el cálculo), interfaz C, win / linux;
- la estructura de red se especifica en JSON;
- capas base: totalmente conectadas, convolucionales, agrupación. Adicional: redimensionar, recortar ..;
- características básicas: batchNorm, abandono, optimizadores de peso - adam, adagrad ..;
- OpenBLAS se utiliza para calcular la CPU, CUDA / cuDNN para la tarjeta de video. También puso la implementación en OpenCL, para el futuro;
- para cada capa hay una oportunidad de establecer por separado qué considerar: CPU o GPU (y cuál);
- el tamaño de los datos de entrada no está rígidamente establecido, puede cambiar durante el trabajo / entrenamiento;
- hizo interfaces para C ++ y Python. C # vendrá más tarde también.
La biblioteca se llamaba SkyNet. (Todo es complicado con los nombres, otros eran opciones, pero algo no está bien ...)
Comparación con PyTorch usando el ejemplo MNIST:
PyTorch: precisión: 98%, tiempo: 140 segundos
SkyNet: Precisión: 95%, Tiempo: 150 segundos
Máquina: i5-2300, GF1060. Código de prueba
Arquitectura de software
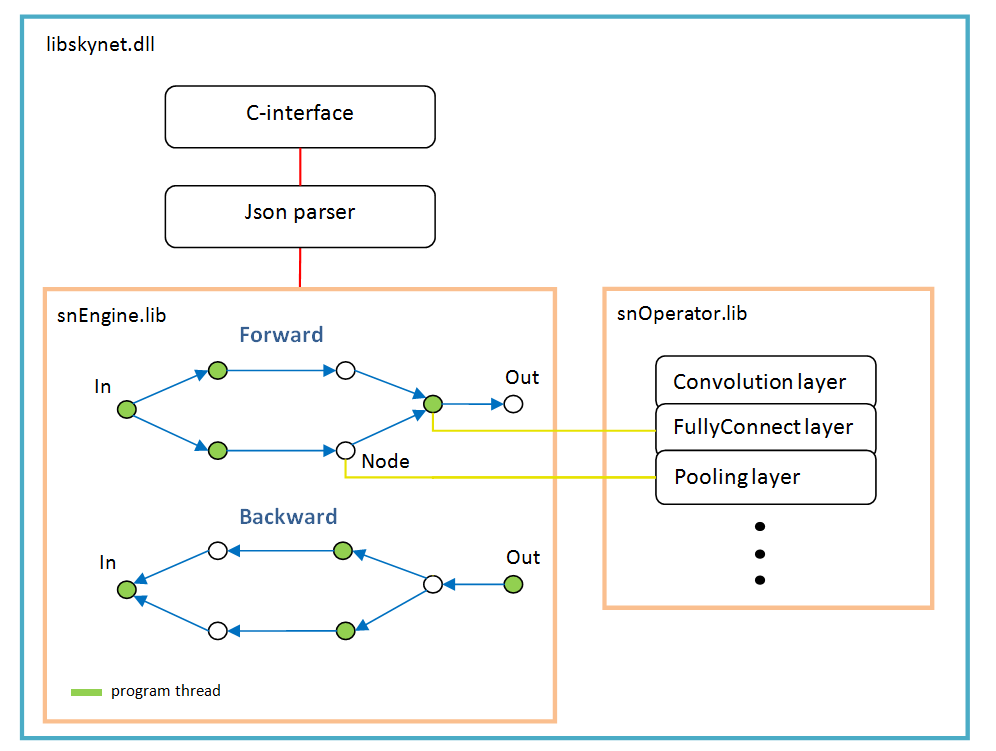
Se basa en un gráfico de operaciones que se crea dinámicamente una vez después de analizar la estructura de la red.
Para cada rama, un nuevo hilo. Cada nodo de la red (Nodo) es una capa de cálculo.
Hay características del trabajo:
- función de activación, normalización por lote, abandono: todos se implementan como parámetros de capas específicas, en otras palabras, estas funciones no existen como capas separadas. Quizás batchNorm debería seleccionarse en una capa separada en el futuro;
- softMax tampoco es una capa separada; pertenece a la capa especial LossFunction. En el que se utiliza al elegir un tipo específico de cálculo de error;
- la capa "LossFunction" se usa para calcular automáticamente el error, obviamente no puede usar los pasos hacia adelante / hacia atrás (a continuación, un ejemplo de trabajo con esta capa);
- no hay una capa "Flatten", no es necesaria ya que la capa "FullyConnect" dibuja la matriz de entrada;
- el optimizador de peso debe configurarse para cada capa de peso; de manera predeterminada, 'adam' es utilizado por todos.
Ejemplos
Mnist

El código C ++ se ve así: El código completo está disponible
aquí . Se agregaron algunas imágenes al repositorio, ubicado al lado del ejemplo. Utilicé opencv para leer imágenes, no lo incluí en el kit.
Otra red del mismo plan, más complicada.

Código para crear dicha red: En los ejemplos que no es, puede copiar desde aquí.
En Python, el código también se ve // snet = snNet.Net() snet.addNode("Input", Input(), "C1 C2 C3") \ .addNode("C1", Convolution(15, 0, calcMode.CUDA), "P1") \ .addNode("P1", Pooling(calcMode.CUDA), "FC1") \ .addNode("C2", Convolution(12, 0, calcMode.CUDA), "P2") \ .addNode("P2", Pooling(calcMode.CUDA), "FC3") \ .addNode("C3", Convolution(12, 0, calcMode.CUDA), "P3") \ .addNode("P3", Pooling(calcMode.CUDA), "FC5") \ \ .addNode("FC1", FullyConnected(128, calcMode.CUDA), "FC2") \ .addNode("FC2", FullyConnected(10, calcMode.CUDA), "LS1") \ .addNode("LS1", LossFunction(lossType.softMaxToCrossEntropy), "Summ") \ \ .addNode("FC3", FullyConnected(128, calcMode.CUDA), "FC4") \ .addNode("FC4", FullyConnected(10, calcMode.CUDA), "LS2") \ .addNode("LS2", LossFunction(lossType.softMaxToCrossEntropy), "Summ") \ \ .addNode("FC5", FullyConnected(128, calcMode.CUDA), "FC6") \ .addNode("FC6", FullyConnected(10, calcMode.CUDA), "LS3") \ .addNode("LS3", LossFunction(lossType.softMaxToCrossEntropy), "Summ") \ \ .addNode("Summ", LossFunction(lossType.softMaxToCrossEntropy), "Output") .............
CIFAR-10

Aquí ya tenía que habilitar batchNorm. Esta cuadrícula aprende hasta un 50% de precisión en 1000 iteraciones, lote 100.
Este código resultó sn::Net snet; snet.addNode("Input", sn::Input(), "C1") .addNode("C1", sn::Convolution(15, -1, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "C2") .addNode("C2", sn::Convolution(15, 0, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "P1") .addNode("P1", sn::Pooling(sn::calcMode::CUDA), "C3") .addNode("C3", sn::Convolution(25, -1, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "C4") .addNode("C4", sn::Convolution(25, 0, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "P2") .addNode("P2", sn::Pooling(sn::calcMode::CUDA), "C5") .addNode("C5", sn::Convolution(40, -1, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "C6") .addNode("C6", sn::Convolution(40, 0, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "P3") .addNode("P3", sn::Pooling(sn::calcMode::CUDA), "FC1") .addNode("FC1", sn::FullyConnected(2048, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "FC2") .addNode("FC2", sn::FullyConnected(128, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "FC3") .addNode("FC3", sn::FullyConnected(10, sn::calcMode::CUDA), "LS") .addNode("LS", sn::LossFunction(sn::lossType::softMaxToCrossEntropy), "Output");
Creo que está claro que cualquier clase de imagen se puede sustituir.
U-net tyni
Ultimo ejemplo U-Net nativa simplificada para demostración.

Permítanme explicar un poco: capas DC1 ... - convolución inversa, capas Concat1 ... - capas de adición de canales,
Rsz1 ...: se utilizan para acordar el número de canales en el paso opuesto, ya que el error de la suma de canales se remonta a la capa Concat.
Código C ++. sn::Net snet; snet.addNode("In", sn::Input(), "C1") .addNode("C1", sn::Convolution(10, -1, sn::calcMode::CUDA), "C2") .addNode("C2", sn::Convolution(10, 0, sn::calcMode::CUDA), "P1 Crop1") .addNode("Crop1", sn::Crop(sn::rect(0, 0, 487, 487)), "Rsz1") .addNode("Rsz1", sn::Resize(sn::diap(0, 10), sn::diap(0, 10)), "Conc1") .addNode("P1", sn::Pooling(sn::calcMode::CUDA), "C3") .addNode("C3", sn::Convolution(10, -1, sn::calcMode::CUDA), "C4") .addNode("C4", sn::Convolution(10, 0, sn::calcMode::CUDA), "P2 Crop2") .addNode("Crop2", sn::Crop(sn::rect(0, 0, 247, 247)), "Rsz2") .addNode("Rsz2", sn::Resize(sn::diap(0, 10), sn::diap(0, 10)), "Conc2") .addNode("P2", sn::Pooling(sn::calcMode::CUDA), "C5") .addNode("C5", sn::Convolution(10, 0, sn::calcMode::CUDA), "C6") .addNode("C6", sn::Convolution(10, 0, sn::calcMode::CUDA), "DC1") .addNode("DC1", sn::Deconvolution(10, sn::calcMode::CUDA), "Rsz3") .addNode("Rsz3", sn::Resize(sn::diap(0, 10), sn::diap(10, 20)), "Conc2") .addNode("Conc2", sn::Concat("Rsz2 Rsz3"), "C7") .addNode("C7", sn::Convolution(10, 0, sn::calcMode::CUDA), "C8") .addNode("C8", sn::Convolution(10, 0, sn::calcMode::CUDA), "DC2") .addNode("DC2", sn::Deconvolution(10, sn::calcMode::CUDA), "Rsz4") .addNode("Rsz4", sn::Resize(sn::diap(0, 10), sn::diap(10, 20)), "Conc1") .addNode("Conc1", sn::Concat("Rsz1 Rsz4"), "C9") .addNode("C9", sn::Convolution(10, 0, sn::calcMode::CUDA), "C10"); sn::Convolution convOut(1, 0, sn::calcMode::CUDA); convOut.act = sn::active::sigmoid; snet.addNode("C10", convOut, "Output");
El código completo y las imágenes están
aquí .
Matemáticas de código abierto como esta .
Probé todas las capas en MNIST; TF sirvió como estándar para evaluar errores.
Que sigue
La biblioteca no crecerá en ancho, es decir, no opencv, sockets, etc., para no inflarse.
La interfaz de la biblioteca no cambiará / expandirá, no lo diré en absoluto y nunca, pero por último, pero no menos importante.
Solo en profundidad: haré el cálculo en OpenCL, la interfaz para C #, la red RNN puede ser ...
MKL Creo que no tiene sentido agregar, porque la red es un poco más profunda: de todos modos, es más rápida en la tarjeta de video y la tarjeta de rendimiento promedio no es una escasez en absoluto.
Importación / exportación de pesos con otros marcos: a través de Python (aún no implementado). La hoja de ruta será si surge interés en las personas.
Quién puede soportar el código, por favor. Pero hay limitaciones para que la arquitectura actual no se rompa.
Puede expandir la interfaz para python hasta la imposibilidad, tal como se necesitan muelles y ejemplos.
Para instalar desde Python:
* pip install libskynet - CPU
* pip install libskynet-cu - CUDA9.2 + cuDNN7.3.1
Guía de usuario de Wiki.
El software se distribuye libremente, licencia MIT.
Gracias