
Vistas, o vistas, es uno de los conceptos de la plataforma CUBA, no el más común en el mundo de los marcos web. Comprenderlo significa salvarse de errores estúpidos cuando, debido a la carga incompleta de datos, la aplicación deja de funcionar de repente. Veamos qué son las representaciones (juego de palabras) y por qué es realmente conveniente.
El problema de los datos descargados
Tomemos un tema más simple y consideremos el problema usando su ejemplo. Supongamos que tenemos una entidad de Cliente que se refiere a una entidad de Tipo de Cliente en una relación de muchos a uno, en otras palabras, el comprador tiene un enlace a un cierto tipo que lo describe: por ejemplo, "vaca de efectivo", "pargo", etc. La entidad CustomerType tiene un atributo de nombre en el que se almacena el nombre del tipo.
Y, probablemente, todos los recién llegados (o incluso usuarios avanzados) en CUBA tarde o temprano recibieron este error:
IllegalStateException: Cannot get unfetched attribute [type] from detached object com.rtcab.cev.entity.Customer-e703700d-c977-bd8e-1a40-74afd88915af [detached].
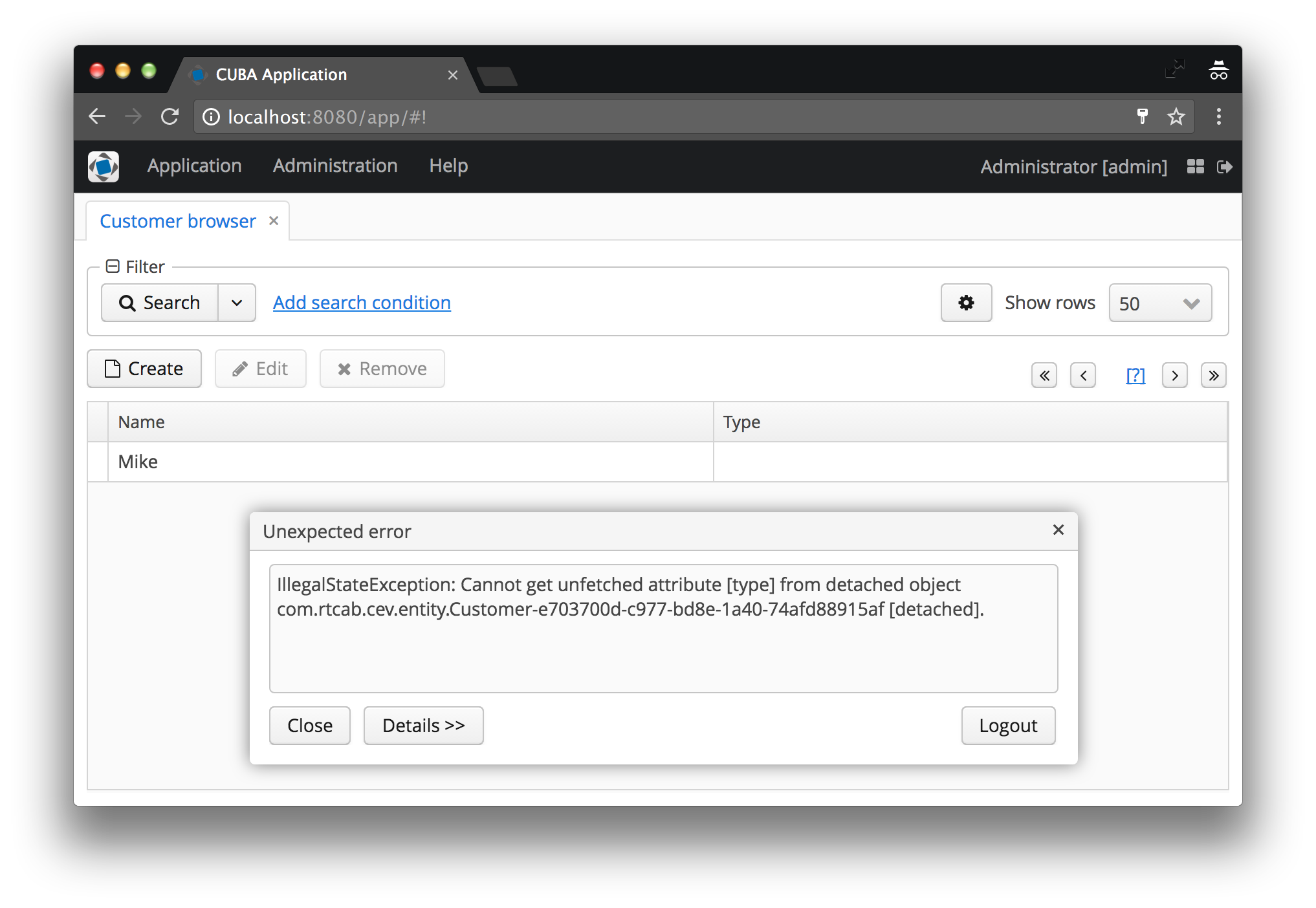
Admítelo, ¿también lo viste con tus propios ojos? Yo ... sí, en cien situaciones diferentes. En este artículo, examinaremos la causa de este problema, por qué existe y cómo resolverlo.
Para empezar, una pequeña introducción al concepto de puntos de vista.
¿Qué es una vista?
Una vista en CUBA es esencialmente una colección de columnas en una base de datos que deben cargarse juntas en una sola consulta.
Supongamos que queremos crear una interfaz de usuario con una tabla de clientes, donde la primera columna es el nombre del cliente, y la segunda es el nombre del tipo del atributo customerType (como en la captura de pantalla anterior). Es lógico suponer que en este modelo de datos tendremos dos tablas separadas en la base de datos, una para la entidad Cliente y la otra para CustomerType . La consulta SELECT * from CEV_CUSTOMER nos devolverá datos de una sola tabla ( name atributo, etc.). Obviamente, para obtener datos también de otras tablas, usaremos JOIN.
En el caso de usar consultas SQL clásicas usando JOIN, la jerarquía de asociaciones (atributos de referencia) se expande desde el gráfico a una lista plana.
Nota del traductor: en otras palabras, las relaciones entre las tablas se borran y el resultado se presenta en una única matriz de datos que representa la unión de las tablas.
En el caso de CUBA, se utiliza ORM, que no pierde información sobre las relaciones entre entidades y presenta el resultado de la consulta en forma de un gráfico integral de los datos solicitados. En este caso, JPQL, un objeto análogo de SQL, se utiliza como lenguaje de consulta.
Sin embargo, los datos aún deben descargarse de alguna manera de la base de datos y transformarse en un gráfico de entidad. Para esto, el mecanismo de mapeo relacional de objetos (que es JPA) tiene dos enfoques principales para las consultas a la base de datos.
Carga perezosa vs. búsqueda ansiosa
La carga diferida y la carga codiciosa son dos posibles estrategias para obtener datos de la base de datos. La diferencia fundamental entre los dos es cuando se cargan los datos de las tablas vinculadas. Un pequeño ejemplo para una mejor comprensión:
¿Recuerdas la escena del libro "El hobbit o viaje redondo", donde un grupo de gnomos en compañía de Gandalf y Bilbo están tratando de pedir pasar la noche en la casa de Beorn? Gandalf ordenó que los enanos aparecieran estrictamente por turno y solo después de que accedió cuidadosamente con Beorn y comenzó a presentarlos uno a la vez para no sorprender al propietario por la necesidad de acomodar a 15 invitados a la vez.

Entonces, Gandalf y los gnomos en la casa de Beorn ... Esto probablemente no sea lo primero que se les ocurra al pensar en descargas perezosas y codiciosas, pero definitivamente hay similitudes. Gandalf actuó sabiamente aquí, ya que era consciente de las limitaciones. Se puede decir que elige conscientemente la carga lenta de los gnomos, ya que entendió que descargar todos los datos a la vez sería una operación demasiado pesada para esta base de datos. Sin embargo, después del octavo gnomo, Gandalf cambió a una carga codiciosa y cargó un montón de los gnomos restantes, porque notó que los accesos demasiado frecuentes a la base de datos comienzan a ponerla nerviosa.
La moraleja es que tanto la carga perezosa como la codiciosa tienen sus pros y sus contras. Usted decide qué aplicar en cada situación específica.
Solicitar problema N + 1
El problema de la consulta N + 1 a menudo surge si está utilizando sin pensar la carga diferida donde quiera que vaya. Para ilustrar, veamos un fragmento de código de Grails. Esto no significa que en Grails todo se cargue perezosamente (de hecho, usted elige el método de arranque). En Grails, una consulta a la base de datos por defecto devuelve instancias de entidad con todos los atributos de su tabla. Básicamente, se ejecuta SELECT * FROM Pet .
Si desea profundizar en las relaciones entre entidades, debe hacerlo después de factum. Aquí hay un ejemplo:
function getPetOwnerNamesForPets(String nameOfPet) { def pets = Pet.findAll(sort:"name") { name == nameOfPet } def ownerNames = [] pets.each { ownerNames << it.owner.name } return ownerNames.join(", ") }
El gráfico se it.owner.name aquí por una sola línea: it.owner.name . Propietario es una relación que no se cargó en la solicitud original ( Pet.findAll ). Por lo tanto, cada vez que se llama a esta línea, GORM hará algo como SELECT * FROM Person WHERE id='…' . Agua pura carga perezosa.
Si calcula el número total de consultas SQL, obtiene N (un propietario para cada llamada it.owner ) + 1 (para el Pet.findAll original). Si desea profundizar en el gráfico de entidades relacionadas, es probable que su base de datos encuentre rápidamente sus límites.
Como desarrollador, es poco probable que se dé cuenta de esto, porque desde su punto de vista simplemente está recorriendo el gráfico de objetos. Este anidamiento oculto en una línea corta causa dolor real a la base de datos y hace que la carga diferida sea a veces peligrosa.
Desarrollando una analogía de pasatiempo, el problema de N + 1 podría manifestarse de la siguiente manera: imagine que Gandalf no puede almacenar los nombres de gnomos en su memoria. Por lo tanto, presentando a los enanos uno por uno, se ve obligado a retroceder a su grupo y preguntarle al enano por su nombre. Con esta información, vuelve a Beorn y representa a Thorin. Luego repite esta maniobra para Bifur, Bofur, Fili, Kili, Dori, Nori, Ori, Oin, Gloyn, Balin, Dvalin y Bombur.

Es fácil imaginar que tal escenario sería improbable: ¿qué destinatario querría esperar la información solicitada durante tanto tiempo? Por lo tanto, no debe utilizar este enfoque sin pensar y confiar ciegamente en la configuración predeterminada de su mapeador de persistencia.
Resolviendo el problema de las consultas N + 1 usando vistas CUBA
En CUBA, lo más probable es que nunca encuentre el problema de consulta N + 1, ya que la plataforma decidió no utilizar la carga diferida oculta. En cambio, CUBA introdujo el concepto de representaciones. Las vistas son una descripción de qué atributos deben seleccionarse y cargarse junto con las instancias de entidad. Algo como
SELECT pet.name, person.name FROM Pet pet JOIN Person person ON pet.owner == person.id
Por un lado, la vista describe las columnas que deben cargarse desde la tabla principal ( Pet ) (en lugar de cargar todos los atributos a través de *), por otro lado, describe las columnas que deben cargarse desde las tablas c-JOIN.
Puede imaginar la vista CUBA como vista SQL para OR-Mapper: el principio de funcionamiento es aproximadamente el mismo.
En la plataforma CUBA, no puede invocar una consulta a través del DataManager sin usar view. La documentación proporciona un ejemplo:
@Inject private DataManager dataManager; private Book loadBookById(UUID bookId) { LoadContext<Book> loadContext = LoadContext.create(Book.class) .setId(bookId).setView("book.edit"); return dataManager.load(loadContext); }
Aquí queremos descargar el libro por su ID. El setView("book.edit") , al crear un contexto de carga, indica con qué vista se debe cargar el libro desde la base de datos. En caso de que no pase ninguna vista, el administrador de datos utiliza una de las tres vistas estándar que tiene cada entidad: la vista local . Local aquí se refiere a atributos que no hacen referencia a otras tablas, todo es simple.
Resolviendo el problema con IllegalStateException a través de vistas
Ahora que conocemos un poco el concepto de representaciones, volvamos al primer ejemplo desde el comienzo del artículo e intentemos evitar que se produzca una excepción.
El mensaje IllegalStateException: No se puede obtener el atributo no recuperado [] del objeto separado solo significa que está intentando mostrar algún atributo que no está incluido en la vista con la que se carga la entidad.
Como puede ver, en el descriptor de la pantalla de navegación utilicé la vista local , y este es todo el problema:
<dsContext> <groupDatasource id="customersDs" class="com.rtcab.cev.entity.Customer" view="_local"> <query> <![CDATA[select e from cev$Customer e]]> </query> </groupDatasource> </dsContext>
Para deshacerse del error, primero debe incluir el tipo de cliente en la vista. Como no podemos cambiar la vista predeterminada de _local , podemos crear la nuestra. En Studio, esto se puede hacer, por ejemplo, de la siguiente manera (haga clic derecho en las entidades> crear vista):
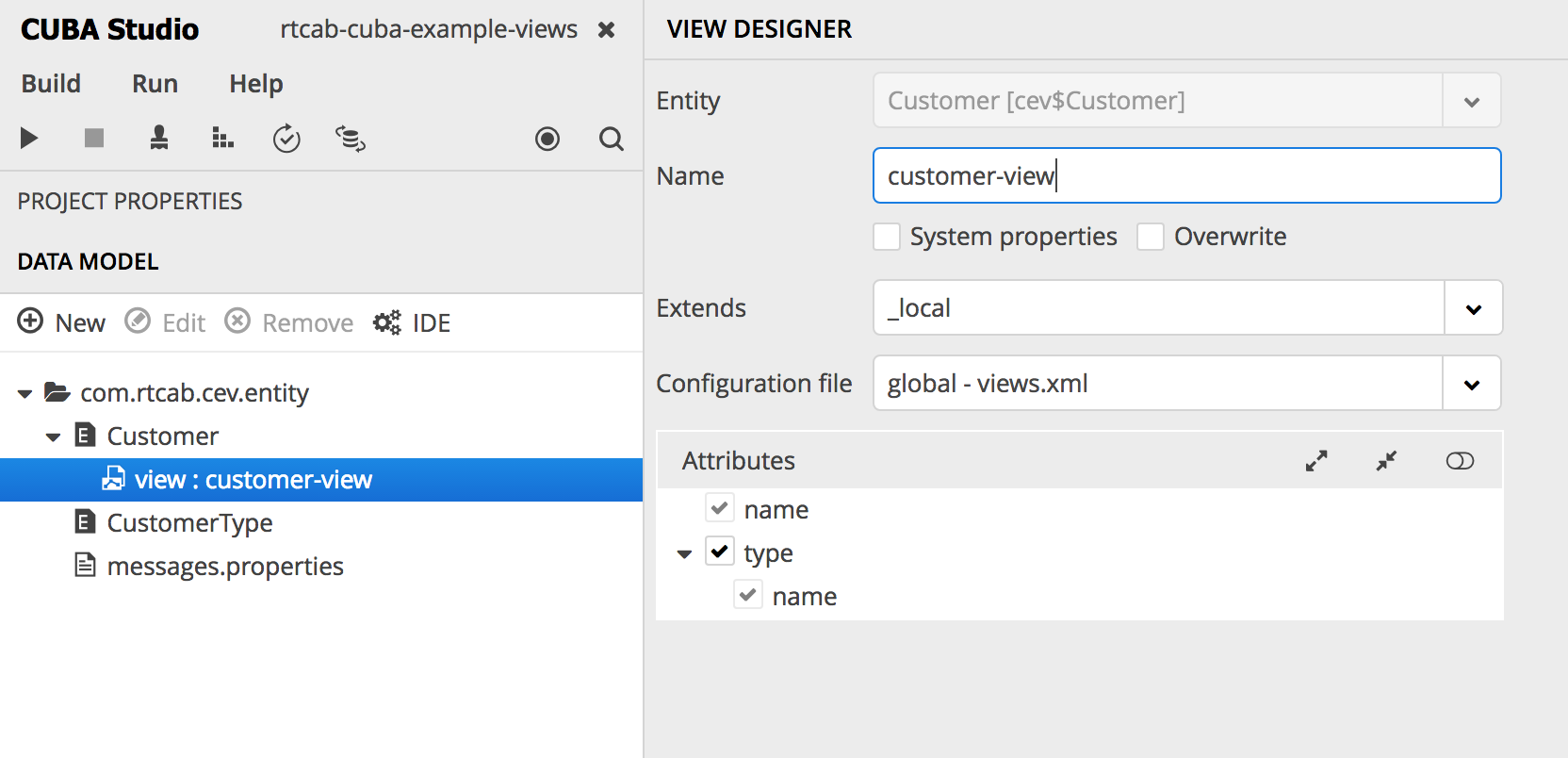
directamente en el descriptor views.xml de nuestra aplicación:
<view class="com.rtcab.cev.entity.Customer" extends="_local" name="customer-view"> <property name="type" view="_minimal"/> </view>
Después de eso, cambiamos el enlace a la vista en la pantalla de exploración, así:
<groupDatasource id="customersDs" class="com.rtcab.cev.entity.Customer" view="customer-view"> <query> <![CDATA[select e from cev$Customer e]]> </query> </groupDatasource>
Esto resuelve completamente el problema, y ahora los datos del enlace se muestran en la pantalla de visualización del cliente.
_Vista mínima y nombre de instancia
Lo que vale la pena mencionar en el contexto de las vistas es la vista mínima . La vista local tiene una definición muy clara: incluye todos los atributos de la entidad, que son atributos directos de la tabla (que no son claves foráneas).
La definición de una representación mínima no es tan obvia, pero también bastante clara.
CUBA tiene el concepto de un nombre de instancia de entidad: nombre de instancia. El nombre de la instancia es el equivalente del método toString() en un buen Java antiguo. Esta es una representación de cadena de una entidad para mostrar en una interfaz de usuario y para usar en enlaces. El nombre de la instancia se establece utilizando la anotación de la entidad NamePattern .
Se usa así: @NamePattern("%s (%s)|name,code") . Tenemos dos resultados:
El nombre de la instancia define la asignación de la entidad a la IU
En primer lugar, el nombre de la instancia determina qué y en qué orden se mostrará en la interfaz de usuario si una entidad se refiere a otra entidad (como Cliente se refiere a CustomerType ).
En nuestro caso, el tipo de cliente se mostrará como el nombre de la instancia CustomerType , a la que se agrega el código entre paréntesis. Si no se establece el nombre de la instancia, se mostrará el nombre de la clase de entidad y el ID de la instancia específica; acuerde que esto no es lo que el usuario desea ver. Vea las capturas de pantalla de antes y después a continuación para ver ejemplos de ambos casos.
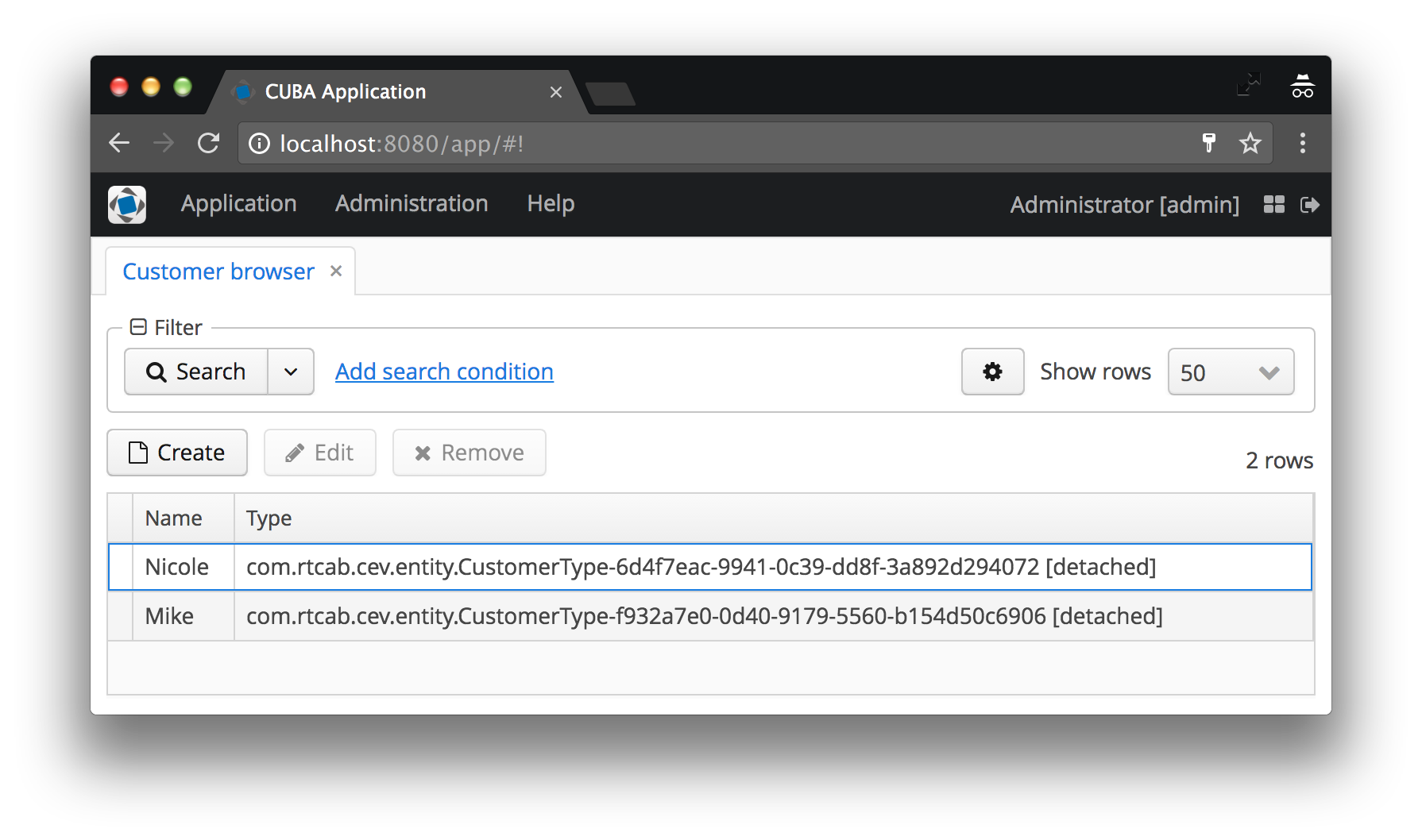
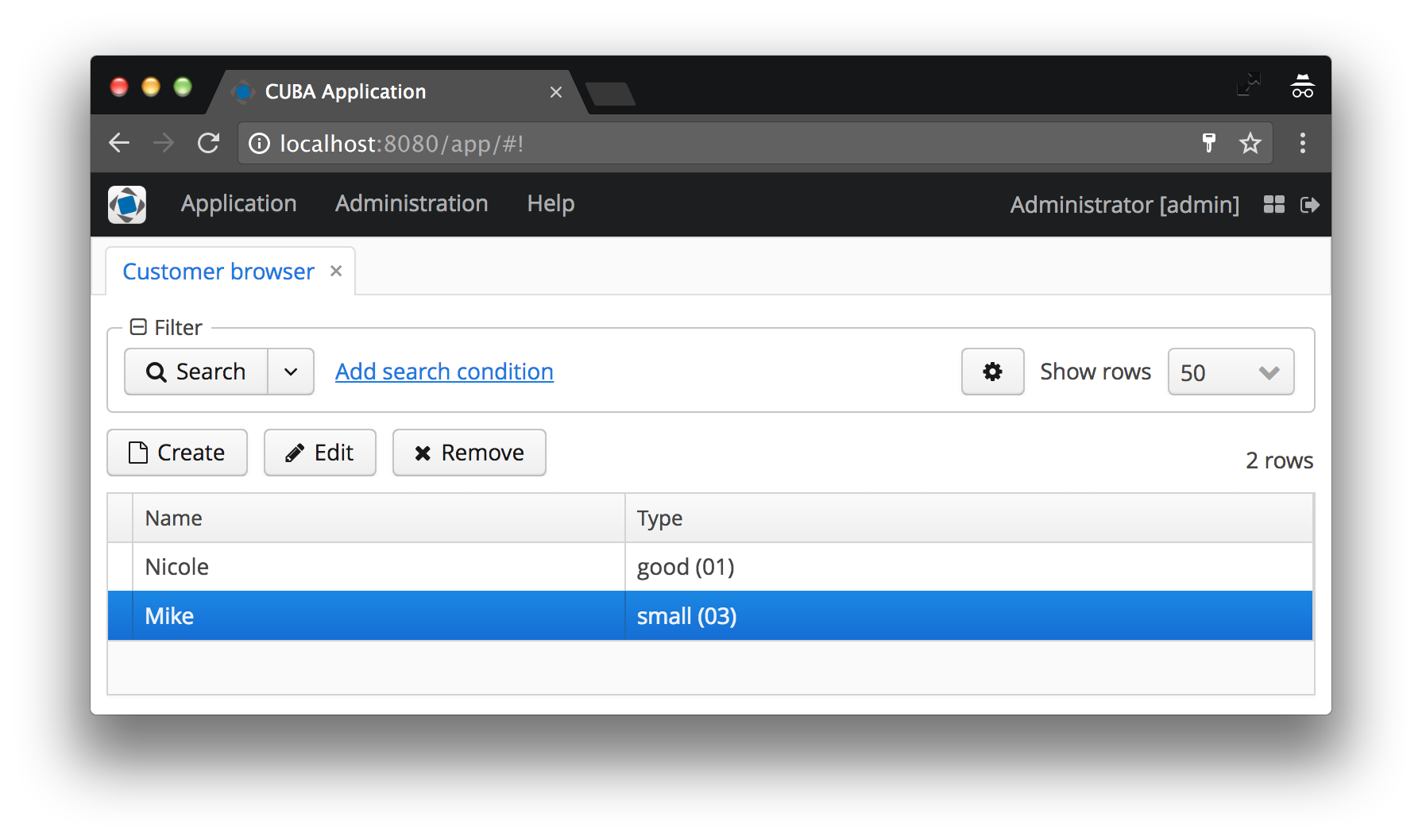
El nombre de instancia define los atributos mínimos de vista
La segunda cosa que afecta la anotación NamePattern es: todos los atributos especificados después de la barra vertical forman automáticamente una vista mínima . A primera vista, esto parece obvio, porque los datos de alguna forma deben mostrarse en la interfaz de usuario, lo que significa que primero debe descargarlos de la base de datos. Aunque, para ser sincero, rara vez pienso en este hecho.
Es importante señalar aquí que la representación mínima, si se compara con la local, puede contener referencias a otras entidades. Por ejemplo, para el comprador del ejemplo anterior, configuré un nombre de instancia, que incluye un atributo local de la entidad del Cliente ( name ) y un atributo de referencia ( type ):
@NamePattern("%s - %s|name,type")
La representación mínima se puede utilizar de forma recursiva: (Cliente [Nombre de instancia] -> Tipo de cliente [Nombre de instancia])
Nota del traductor: desde la publicación del artículo, ha aparecido otra vista del sistema: _base view, que incluye todos los atributos locales que no son del sistema y los atributos especificados en la anotación @NamePattern (es decir, realmente _minimal + _local ).
Conclusión
En conclusión, resumimos el tema más importante. Gracias a las vistas, en CUBA podemos indicar explícitamente qué se debe cargar desde la base de datos. Las vistas determinan qué se cargará con avidez, mientras que la mayoría de los otros frameworks realizan de forma encubierta la carga diferida.
Las representaciones pueden parecer un mecanismo engorroso, pero a la larga se justifican.
Espero haber logrado explicar de manera accesible cuáles son realmente estas misteriosas vistas. Por supuesto, hay escenarios más avanzados para su uso, así como dificultades para trabajar con representaciones en general y con representaciones mínimas en particular, pero de alguna manera escribiré sobre esto en una publicación separada.