Publico el segundo informe de nuestro
primer mitap , que se realizó en septiembre. La última vez que pudo leer (y ver) sobre el
uso del Cónsul para escalar servicios con estado de Ivan Bubnov de BIT.GAMES, y hoy hablaremos sobre CICD. Más precisamente, nuestro administrador de sistemas Egor Panov informará sobre esto, quien es responsable de la disponibilidad de infraestructura y servicios en Pixonic. Bajo el corte - decodificación de la actuación.
Para empezar, la industria del juego es más arriesgada: nunca se sabe qué se hundirá exactamente en el corazón del jugador. Y así creamos muchos prototipos. Por supuesto, creamos prototipos en la rodilla de palos, cuerdas y otros materiales improvisados.
Parecería que con este enfoque, hacer algo que luego pueda ser apoyado es generalmente imposible. Pero incluso en esta etapa estamos aguantando. Nos aferramos a tres pilares:
- excelente experiencia de probadores;
- estrecha interacción con ellos;
- el tiempo que damos para las pruebas.
En consecuencia, si no construimos nuestros procesos, por ejemplo, implementación o CI (integración continua), tarde o temprano llegaremos a la conclusión de que la duración de la prueba aumentará y aumentará todo el tiempo. Y haremos todo lentamente y perderemos el mercado, o simplemente explotaremos en cada despliegue.
Pero construir un proceso CICD no es tan simple. Algunos dirán, bueno, sí, pondré a Jenkins, llamaré rápidamente a algo, ahora tengo listo el CICD. No, esto no es solo una herramienta, también es una práctica. Comencemos en orden.

El primero Muchos artículos escriben que todo debe mantenerse en un repositorio: código, pruebas, implementación e incluso el esquema de la base de datos y configuraciones IDE que son comunes a todos. Seguimos nuestro propio camino.
Hemos asignado diferentes repositorios: implementar en nuestro repositorio, pruebas en otro. Funciona mas rapido. Puede que no le convenga, pero para nosotros es mucho más conveniente. Debido a que hay un punto importante en este punto: debe crear un sistema simple y transparente para todos los flujos de visitas. Por supuesto, puede descargar el terminado en alguna parte, pero en cualquier caso, necesita ajustarlo usted mismo, mejorarlo. Para nosotros, por ejemplo, una implementación vive en su propio gitflow, que es más como un flujo de GitHub, y el desarrollo del servidor vive en su propio gitflow.
El siguiente párrafo. Necesita configurar una compilación completamente automática. Está claro que en la primera etapa, el desarrollador personalmente recopila el proyecto, luego lo implementa personalmente con la ayuda de SCP, lo lanza él mismo y lo envía a quien lo necesite. Esta opción no duró mucho, apareció un script bash. Bueno, dado que el entorno de los desarrolladores cambia constantemente, ha aparecido un servidor de compilación dedicado especial. Vivió mucho tiempo, durante este tiempo logramos aumentar hasta 500 en servidores, configurar configuraciones de servidor en Puppet, acumular legado en Puppet, rechazar Puppet, cambiar a Ansible, y este servidor de compilación continuó vivo.
Decidieron cambiar todo después de dos llamadas, no esperaron un tercero. La historia es clara: el servidor de compilación es un punto único de falla y, por supuesto, cuando necesitábamos implementar algo, el centro de datos se cayó completamente junto con nuestro servidor de compilación. Y la segunda llamada: necesitábamos actualizar la versión de Java: la actualizamos en el servidor de compilación, la instalamos en el escenario, todo es genial, todo es genial, y de inmediato necesitamos lanzar una pequeña corrección de errores en el producto. Por supuesto, olvidamos retroceder y todo se vino abajo.
Después de eso, reescribieron todo para que la compilación completa pudiera suceder en cualquier agente de TeamCity y lo reescribieron en Ansible, porque estaba configurado en Ansible, ¿por qué no usar la misma herramienta para la implementación también?
La siguiente regla: cuanto más cometas, mejor. Por qué Porque hay un cuarto: cada confirmación se recopila. Y de hecho, incluso más que cada commit. Ya dije que tenemos TeamCity, y le permite ejecutar un commit desde su IDE favorito (adivina a qué me refiero). En realidad, comentarios rápidos, todo es genial.
Una construcción rota se repara de inmediato. Tan pronto como configure la implementación automática, debe configurar la notificación automática en Slack. Todos sabemos muy bien que un desarrollador sabe cómo funciona su código solo en el momento en que lo escribe. Por lo tanto: la persona se enteró, inmediatamente reparada.
Probamos en el entorno repitiendo productos. Es simple, elegimos Ansible y AWX. Alguien podría preguntar, pero ¿qué pasa con Docker, Kubernetes, OpenShift, donde todos los problemas fuera de la caja se han resuelto durante mucho tiempo? Olvidé decir que tenemos componentes de Linux y Windows. Y, por ejemplo, el servidor Photon, que está en Windows, solo recientemente hemos podido empaquetar más o menos normalmente en un contenedor acoplable de 10 GB. En consecuencia, tenemos una aplicación de Windows que no empaqueta bien en un contenedor; Hay una aplicación en Linux (que está en Java), que está perfectamente empaquetada, pero no hay razón para hacerlo, funciona bien donde sea que la ejecute. Esto es Java
A continuación, elegimos entre Ansible y Chef. Ambos funcionan bien con Windows, pero Ansible resultó ser mucho más fácil para nosotros. Cuando ya instalamos AWX, en general, todo se convirtió en fuego. AWX tiene secretos, gráficos, historia. Puede mostrarle a una persona lejos de todo esto, él verá de inmediato todo y todo se aclarará.
Y siempre necesita mantener la compilación rápida. No sé por qué, pero cada vez que inicias un nuevo proyecto, te olvidas por completo del servidor de compilación, de los agentes y seleccionas una computadora que estaba por ahí: este es nuestro servidor de compilación. No es deseable repetir este error, porque todo lo que estoy hablando (retroalimentación rápida, más) no será tan relevante si el ensamblaje comienza en su propia computadora portátil mucho más rápido que en algún tipo de granja de servidores.

7 puntos, y ya hemos construido algún tipo de proceso de CI. Genial El siguiente diagrama no es visible, pero todavía hay Graylog en el lateral. Quien lee nuestros artículos sobre Habré, que ya vio
cómo elegimos Graylog y
cómo instalarlo . En cualquier caso, ayuda a desviar si aún ocurre algún problema.
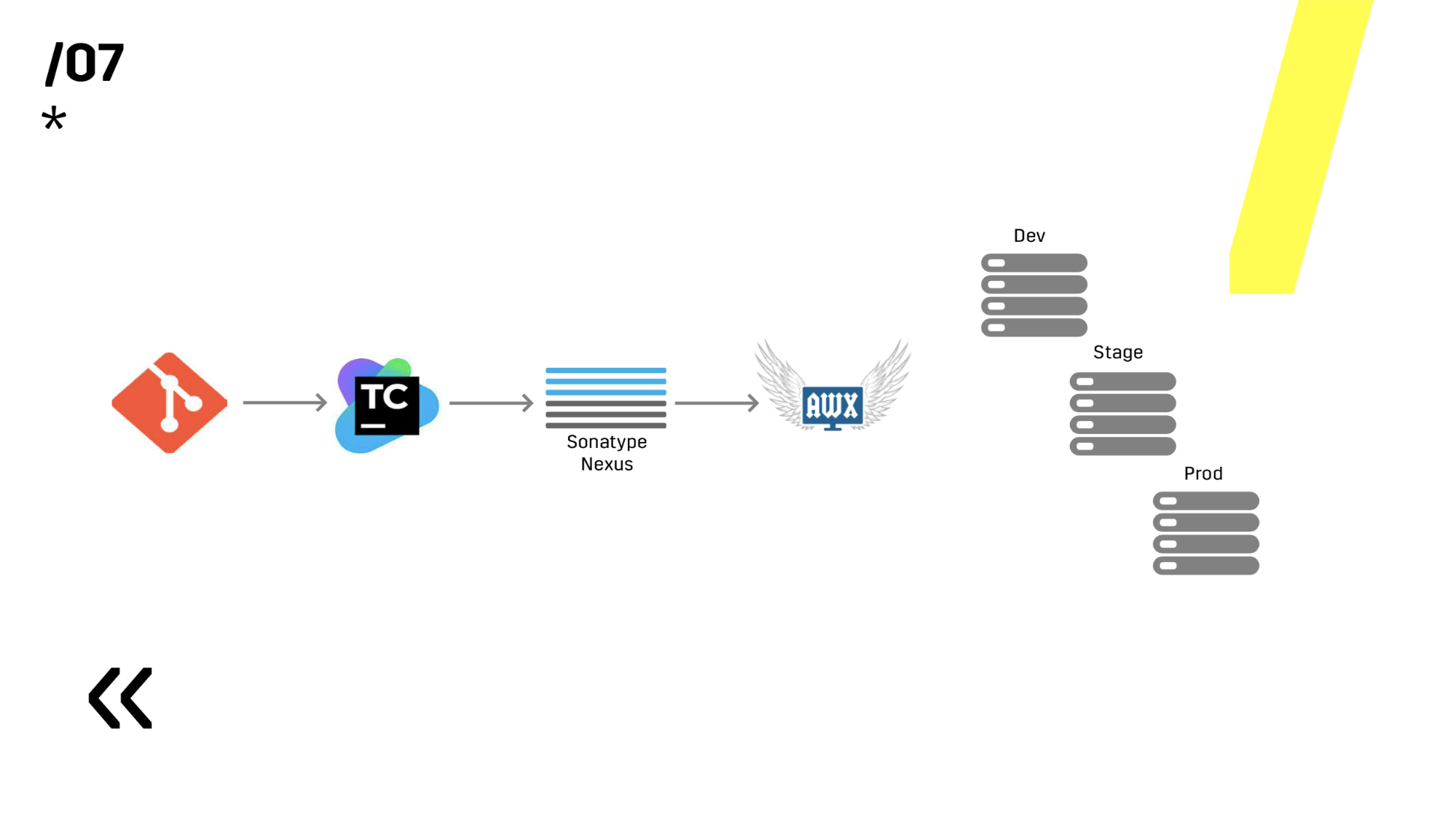
Ahora sobre esta base ya es posible proceder a la implementación.

Pero ya hablé sobre el despliegue en el segundo párrafo, por lo que no me detendré mucho en esto. Diré una cosa sobre la vida: si usa Ansible, asegúrese de agregar esta serie, que se encuentra en la diapositiva. Sucedió más de una vez que comienzas algo, y luego lo entiendes, pero lo comencé de forma incorrecta, incorrecta o incorrecta, y luego ves que este es solo un servidor. Y podemos perder fácilmente un servidor y usted simplemente lo vuelve a cargar, nadie lo notó.
Además, instalaron el repositorio de artefactos en Nexus: es un único punto de entrada para absolutamente todos, no solo para CI.
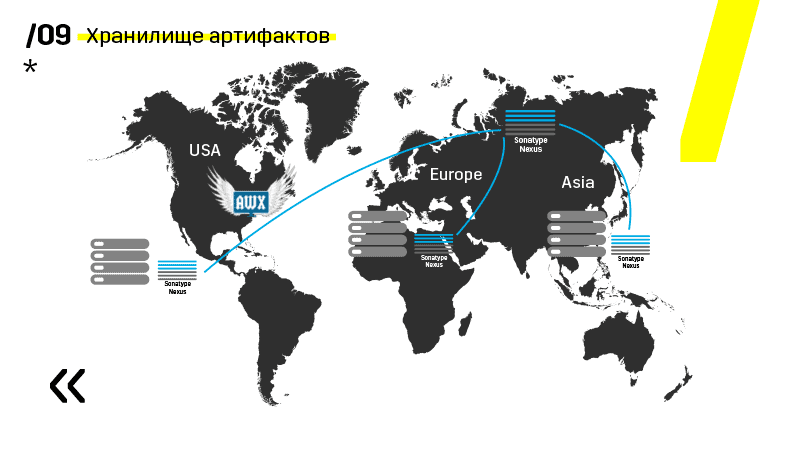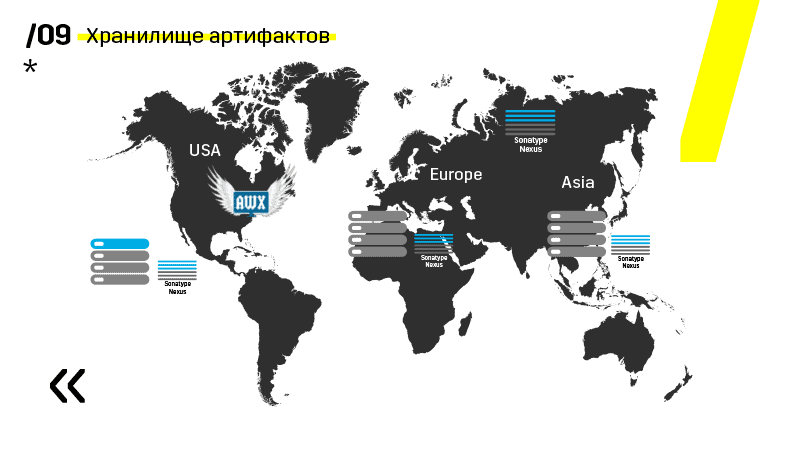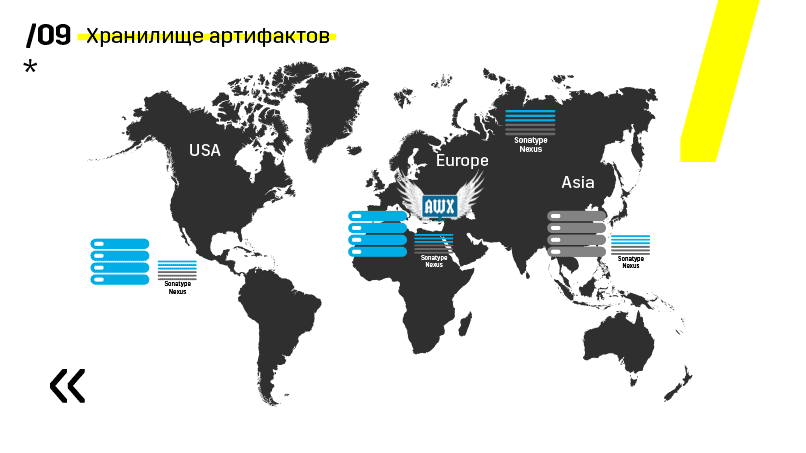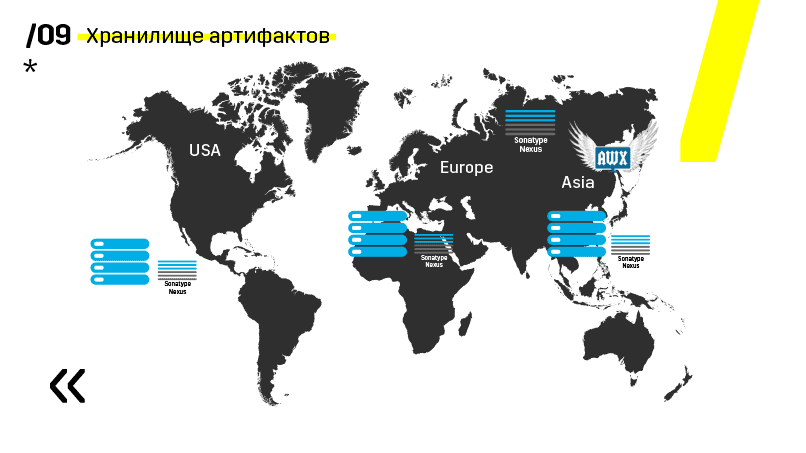
Y nos ayuda mucho para garantizar la repetibilidad. Bueno, dado que nexus puede funcionar como servicios proxy en diferentes regiones, aceleran la implementación, la instalación de paquetes rpm, imágenes de acoplador, cualquier cosa.
Cuando crea un nuevo proyecto, es recomendable elegir componentes que sean fáciles de automatizar. Por ejemplo, no tuvimos éxito con el servidor Photon. En cualquier caso, fue la mejor solución en otros aspectos. Pero Cassandra, por ejemplo, está muy convenientemente actualizada y automatizada.
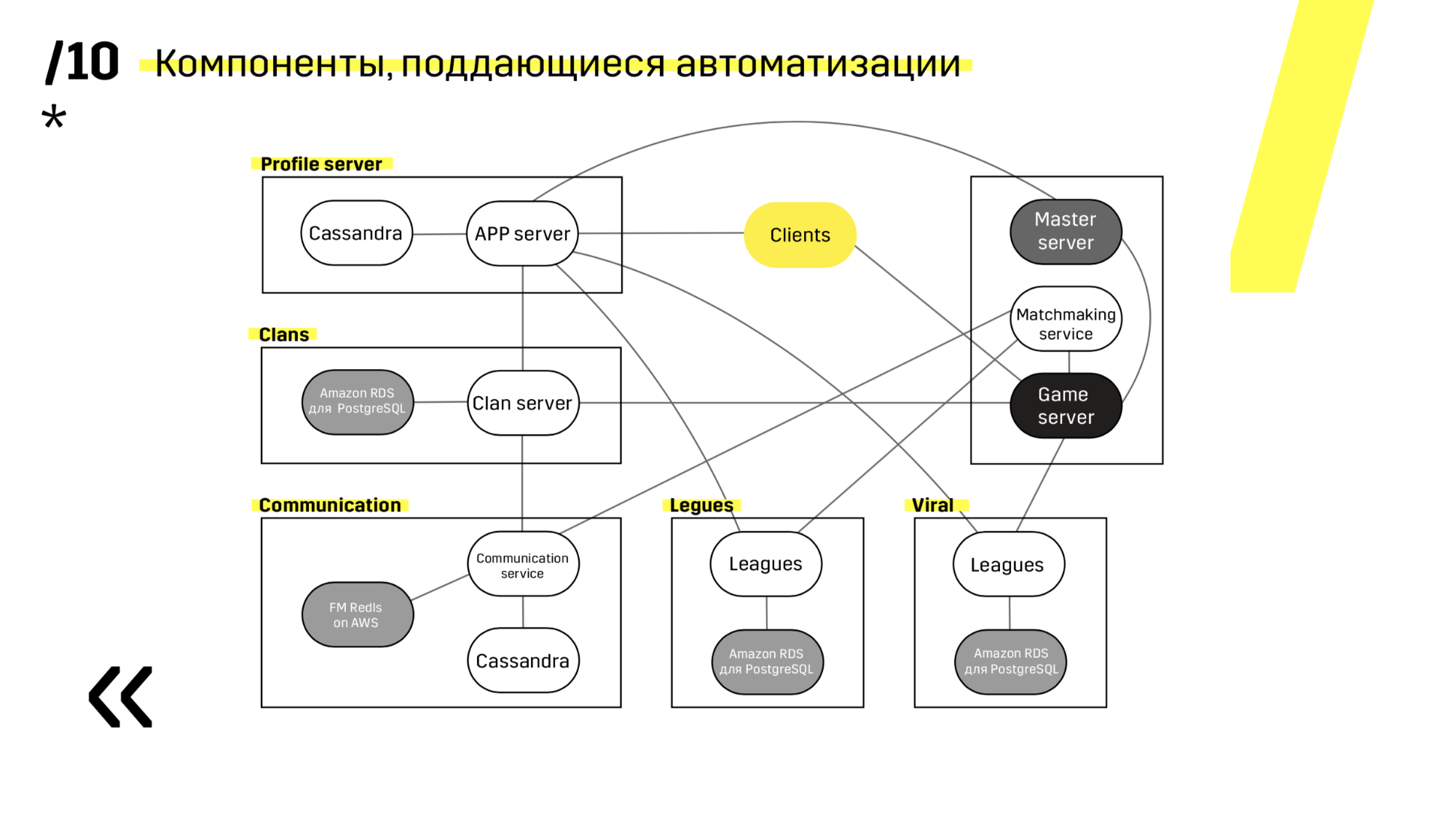
Aquí hay un ejemplo de uno de nuestros proyectos. El cliente acude al servidor de la APLICACIÓN, donde tiene un perfil en la base de datos de Cassandra, y luego va al servidor maestro, que con la ayuda del emparejamiento le da un servidor de juegos con algún tipo de espacio. Todos los demás servicios se realizan en forma de una "base de datos de aplicaciones" y se actualizan exactamente de la misma manera.
El segundo punto: debe proporcionar una arquitectura de implementación simple y poco acoplada. Hemos tenido éxito
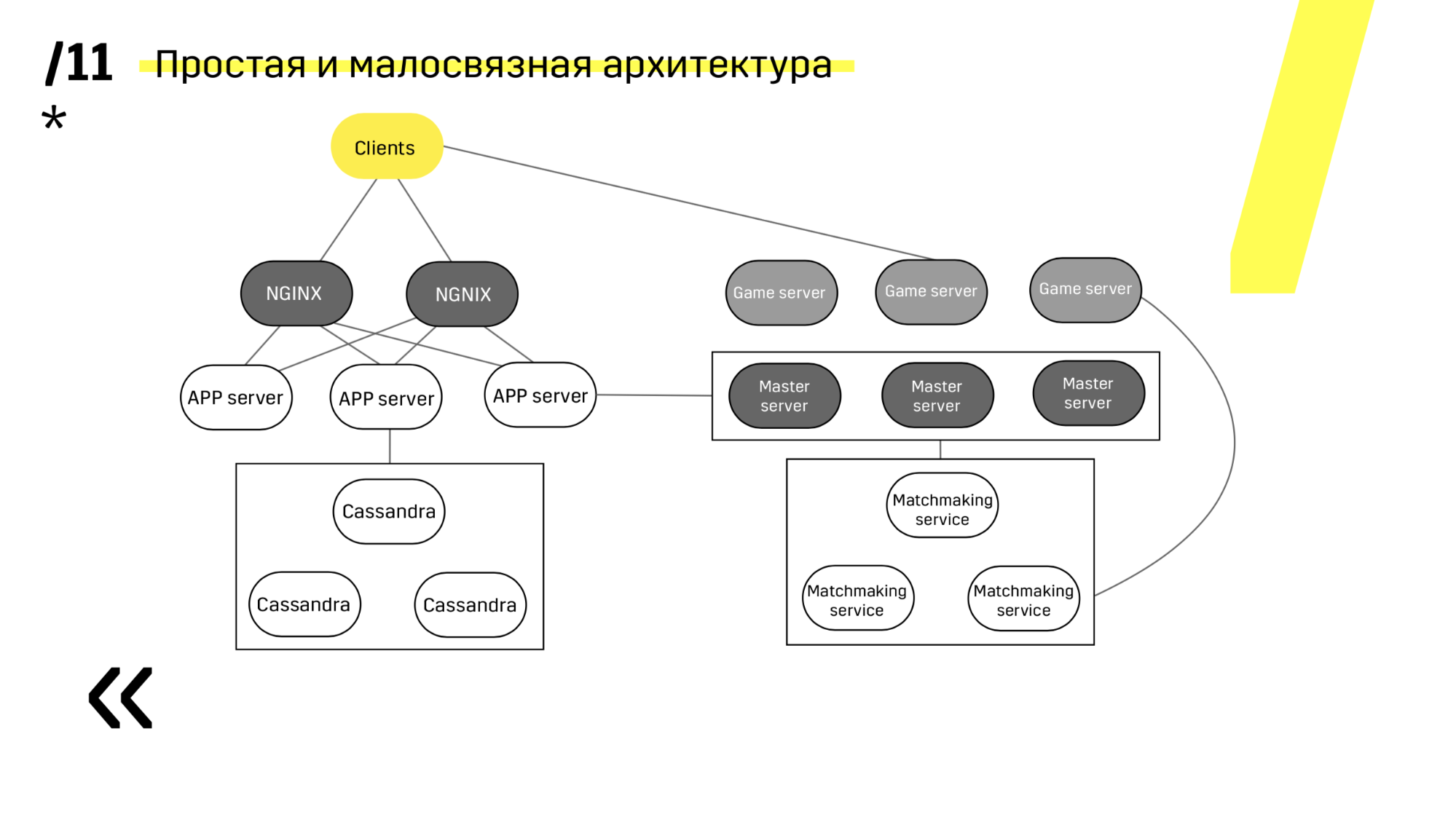
Consulte, actualizando, por ejemplo, el servidor de aplicaciones. Tenemos servicios de descubrimiento dedicados que reconfiguran el equilibrador, por lo que solo vamos al servidor de aplicaciones, lo extinguimos, se bloquea por el equilibrio, lo actualizamos todo. Y así con cada uno individualmente.
Los servidores maestros se actualizan casi de manera idéntica. El cliente hace ping a cada servidor maestro en la región y va al que tiene mejor ping. En consecuencia, si actualizamos el servidor maestro, entonces tal vez el juego vaya un poco más lento, pero se actualiza de manera fácil y sencilla.
Los servidores de juegos se actualizan de manera un poco diferente porque todavía hay un juego en curso. Vamos al emparejamiento, le pedimos que desequilibre un determinado servidor, vaya al servidor del juego, espere hasta que los juegos se vuelvan exactamente cero y actualice. Luego volvemos al equilibrio.
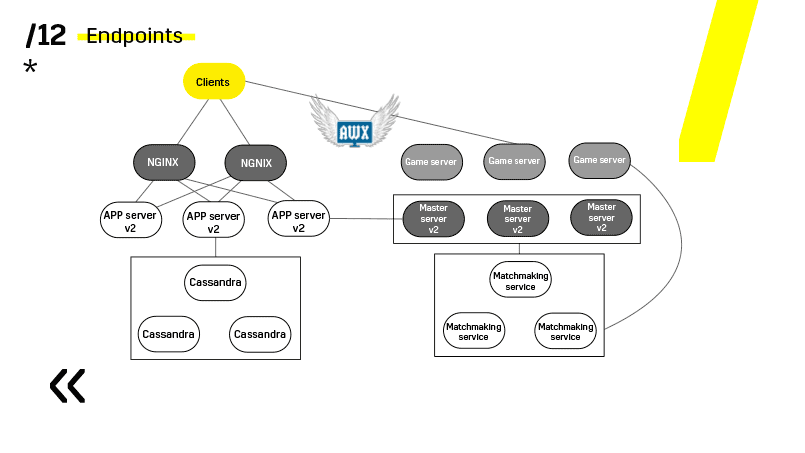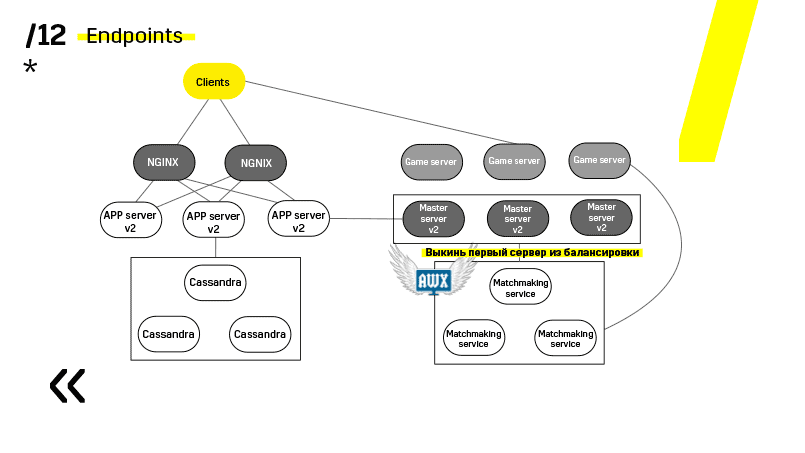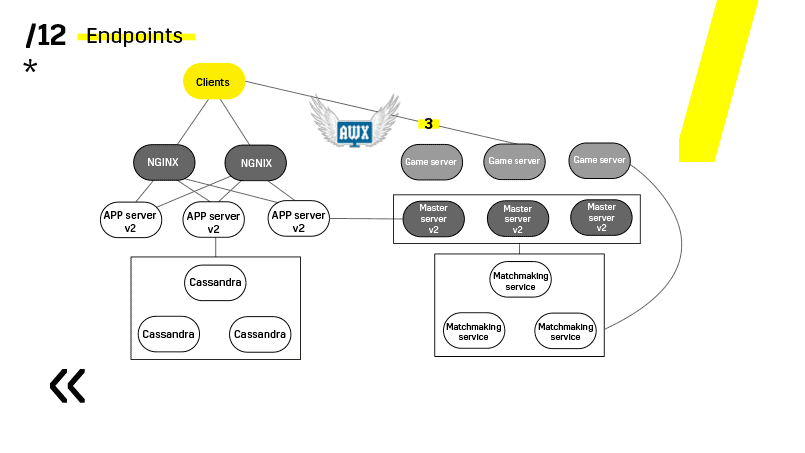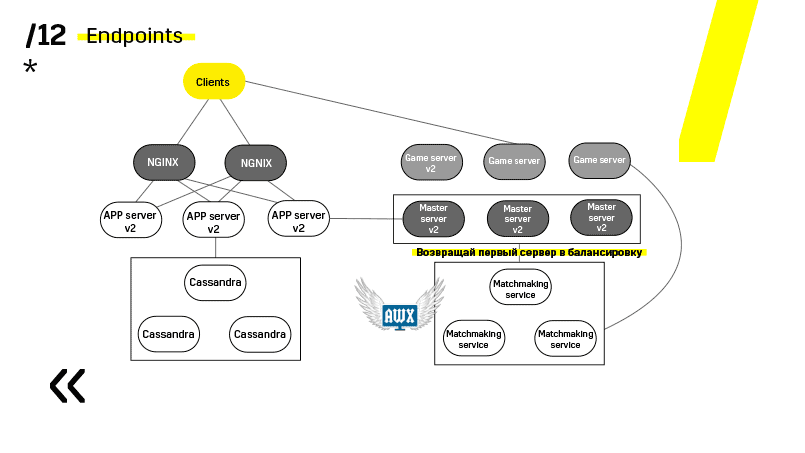
El punto clave aquí son los puntos finales que tiene cada uno de los componentes, y con los cuales es fácil y sencillo comunicarse. Si necesita un ejemplo, hay un clúster Elasticsearch. Usando solicitudes http regulares en JSON, puede comunicarse fácilmente con él. E inmediatamente en el mismo JSON da todo tipo de métricas diferentes e información de alto nivel sobre el clúster: verde, amarillo, rojo.
Después de completar estos 12 pasos, aumentamos la cantidad de entornos, comenzamos a probar más, la implementación se aceleró, la gente comenzó a recibir comentarios rápidos.

Lo que es muy importante es que obtuvimos la simplicidad y la velocidad de los experimentos. Y esto es muy importante, porque cuando hay muchos experimentos, podemos filtrar fácilmente las ideas erróneas y centrarnos en las correctas. Y no sobre la base de evaluaciones subjetivas, sino sobre la base de indicadores objetivos.
De hecho, ya no sigo cuando tenemos una implementación allí, cuando se lanza. No hay un "¡oh, suelta!" Sensación, todo se reunió y la piel de gallina. Ahora, esta es una operación tan rutinaria, veo periódicamente en una sala de chat que algo ha surgido, está bien. Esto es realmente genial. Los administradores de su sistema rugirán de alegría cuando lo haga.
Pero el mundo no se detiene, a veces rebota. Tenemos algo que mejorar. Por ejemplo, me gustaría poner los registros de la compilación también en Graylog. Esto requerirá un mayor refinamiento del registro, de modo que no haya una historia separada, pero claramente: así es como se ensambló la compilación, por lo que se probó, se implementó y se comporta en el producto. Y monitoreo continuo: esta es una historia más complicada.

Usamos Zabbix, y él no está listo para tales enfoques. La cuarta versión se lanzará pronto, descubriremos qué hay allí y, si todo está mal, encontraremos una solución diferente. Te diré cómo resultará en la próxima reunión.
Preguntas de la audiencia
¿Y qué sucede cuando arrojas algo de basura en la producción? Por ejemplo, no calculó algo de acuerdo con el rendimiento y todo está bien en la integración, pero en producción, mire, sus servidores comienzan a fallar. ¿Cómo retroceder? ¿Hay algún botón para guardarme?Intentamos hacer la automatización de reversión. Luego puede hablar en informes sobre lo genial que funciona, lo maravilloso que es todo. Pero primero, diseñamos para que las versiones sean compatibles con versiones anteriores y lo probamos. Y cuando hicimos esta cosa completamente automática, que verifica algo y lo revierte, y luego comenzamos a vivir con eso, nos dimos cuenta de que pusimos mucho más esfuerzo que si solo tomáramos la versión anterior con el mismo pedal .
Con respecto a la actualización automática de la implementación: ¿por qué realiza cambios en el servidor actual y no agrega uno nuevo y solo lo agrega al grupo objetivo o al equilibrador?Tan rápido
Por ejemplo, si necesita actualizar la versión de Java, cambia el estado de la instancia en Amazon, actualiza la versión de Java u otra cosa, ¿cómo retrocede en ese caso? ¿Estás haciendo cambios en el servidor de producción?Sí, cada componente funciona bien con la nueva versión y la anterior. Sí, es posible que deba volver a cargar el servidor.
Hay cambios de estado cuando son posibles grandes problemas ...Entonces explotar.
Simplemente me parece agregar un nuevo servidor y simplemente ponerlo en el grupo objetivo en el grupo objetivo, una tarea pequeña en complejidad y una práctica bastante buena.Estamos alojados en hardware, no en las nubes. Podemos agregar un servidor, es posible, pero un poco más que simplemente haciendo clic en la nube. Por lo tanto, tomamos nuestro servidor actual (no tenemos tal carga para que no podamos sacar algunas de las máquinas): sacamos algunas de las máquinas, las actualizamos, colocamos el tráfico de ventas allí, vemos cómo funciona, si todo está bien, continuaremos haciendo todo otros autos
Usted dice que si se recopila cada confirmación y si todo es malo, el desarrollador gobierna todo de inmediato. ¿Entiendes que todo es malo? ¿Qué compromisos se hacen?Naturalmente, al principio fue una especie de prueba manual, la retroalimentación es lenta. Luego, con algún tipo de pruebas automáticas en Appium, todo esto está cubierto, funciona y proporciona algún tipo de retroalimentación sobre si las pruebas cayeron o no.
Es decir Primero, cada commit se implementa y ¿los verificadores lo están viendo?Bueno, no todos, esto es práctica. Hicimos una práctica con estos 12 puntos: acelerada. De hecho, este es un trabajo largo y duro, tal vez durante el año. Pero lo ideal es que llegues a esto y todo funcione. Sí, necesitamos algún tipo de pruebas automáticas, al menos un conjunto mínimo, que funcione para usted.
Y la pregunta es más pequeña: hay un servidor de aplicaciones en la imagen y así sucesivamente, ¿eso es lo que me interesa allí? Dijiste que no pareces tener Docker, ¿qué es un servidor? ¿Java desnudo o qué?En algún lugar, esto es Photon en Windows (un servidor de juegos), el servidor de aplicaciones es una aplicación Java en Tomcat.
Es decir sin virtualoks, sin contenedores, nada?Bueno, Java es, se podría decir, un contenedor.
¿Y todo se implementa con Ansible?Si Es decir en cierto momento, simplemente no invertimos en orquestación, porque ¿por qué? Si, en cualquier caso, Windows debe administrarse por separado de la misma manera, y aquí absolutamente todo está cubierto con una herramienta.
¿Y cómo se implementa la base de datos? Dependencia de componente o servicio?Hay un esquema en el servicio en sí que se implementará cuando aparezca y deba desarrollarse para que no se elimine nada, pero solo se agrega algo y es compatible con versiones anteriores.
¿Su base también es de hierro o es la base en algún lugar de la nube en Amazon?La base más grande es el hierro, pero hay otros. Hay pequeños, RDS ya no es de hierro, virtual. Esos pequeños servicios que mostré: chats, ligas, chatear con Facebook, clanes, uno de ellos es RDS.
Servidor maestro: ¿cómo es?Este, de hecho, es el mismo servidor de juegos, solo con un signo del maestro y él es un equilibrador. Es decir el cliente hace ping a todos los maestros, luego recibe uno al que el ping es menor, y el servidor maestro que usa el emparejamiento recopila salas en los servidores del juego y envía al jugador.
Entiendo correctamente que por cada lanzamiento que escribe (si aparece alguna característica), ¿una migración para actualizar los datos? Dijiste que tomas artefactos viejos y los llenas, ¿qué pasa con los datos? ¿Estás escribiendo una migración para deshacer la base?Esta es una operación de reversión muy rara. Sí, escribes bolígrafos de migración, y qué hacer.
¿Cómo se sincroniza una actualización del servidor con las actualizaciones del cliente? Es decir necesitas lanzar una nueva versión del juego: ¿actualizarás primero todos los servidores y luego se actualizarán los clientes? ¿El servidor admite la versión anterior y la nueva?Sí, estamos desarrollando alternancia de características c y atenuación de características. Es decir Este es un mango especial, una palanca que le permite activar alguna función más adelante. Puede actualizar con absoluta calma, ver que todo funcione para usted, pero no incluya esta función. Y cuando ya haya dispersado al cliente, puede ajustar un 10% ajustando el fiddimming, ver que todo esté bien y luego al máximo.
Dice que ha almacenado partes del proyecto por separado en diferentes repositorios, es decir ¿Tienes algún tipo de proceso de desarrollo? Si cambia el proyecto en sí, sus pruebas deberían caer porque cambió el proyecto. Por lo tanto, las pruebas que se encuentran por separado deben repararse lo más rápido posible.Te conté sobre la "interacción estrecha de las ballenas con los probadores". Este esquema con diferentes repositorios funciona muy bien solo si hay alguna comunicación muy densa. Esto no es un problema para nosotros, todos se comunican fácilmente entre sí, hay una buena comunicación.
Es decir ¿los probadores admiten el repositorio de pruebas en su equipo? ¿Y las pruebas automáticas se encuentran por separado?Si Realizó alguna función y puede recopilar exactamente las pruebas automáticas que necesita del repositorio de probadores, y no verifica todo lo demás.
Tal enfoque, cuando todo se desarrolla rápidamente, puede darse el lujo de ir inmediatamente al producto para cada confirmación. ¿Sigues tales tácticas o compones algunos lanzamientos? Es decir una vez a la semana, no los viernes, ni los fines de semana, ¿tiene alguna táctica de lanzamiento o está lista la función? ¿Puedo lanzarla? Porque si haces una versión pequeña de características pequeñas, entonces es menos probable que todo se rompa, y si algo se rompe, entonces definitivamente sabes qué.Obligar a los usuarios del cliente a descargar una nueva versión cada cinco minutos o todos los días no es una idea de hielo. En cualquier caso, estará vinculado al cliente. Es genial cuando tienes un proyecto web en el que puedes actualizar al menos todos los días y no necesitas hacer nada. La historia es más complicada con el cliente, tenemos algún tipo de tácticas de lanzamiento y nos atenemos a ella.
Usted habló sobre la implementación de la automatización en los servidores de productos y (según tengo entendido) también existe la implementación de la automatización para una prueba: ¿qué pasa con los entornos de desarrollo? ¿Existe algún tipo de automatización implementada por los desarrolladores?Casi lo mismo. Lo único no son los servidores de hierro, sino en la máquina virtual, pero la esencia es casi la misma. Al mismo tiempo, en el mismo Ansible, escribimos (tenemos Ovirt) la creación de esta máquina virtual y el nudo en ella.
¿Tiene toda la historia almacenada en un proyecto junto con los productos Ansible y las configuraciones de prueba, o vive y se desarrolla por separado?Podemos decir que estos son proyectos separados. Dev (lo llamamos devbox) es una historia cuando todo está en un paquete, y en la producción es una historia distribuida.
Más conversaciones con Pixonic DevGAMM Talks