Casi todos los nuevos empleados de Yandex están sorprendidos por la magnitud del estrés que experimentan nuestros productos. Miles de hosts con cientos de miles de solicitudes por segundo. Y este es solo uno de los servicios. Al mismo tiempo, debemos responder a las solicitudes en una fracción de segundo. Incluso un ligero cambio en el producto puede tener un impacto significativo en el rendimiento, por lo que es importante probar y evaluar el impacto de su código en el servicio.
En nuestro servicio de tecnologías publicitarias, las pruebas funcionan en el marco de la metodología de integración continua, que discutiremos con más detalle sobre la organización del 25 de octubre en el evento Yandex desde adentro , y hoy compartiremos con los lectores de Habr la experiencia de automatizar la evaluación de métricas de productos importantes relacionadas con el rendimiento del servicio. Aprenderá cómo confiar el análisis a una máquina y no seguirlos en gráficos. Vamos!

No se trata de cómo probar el sitio. Hay muchas herramientas en línea para esto. Hoy hablaremos sobre un servicio interno de back-end altamente cargado, que es parte de un gran sistema y prepara información para un servicio externo. En nuestro caso, para páginas de resultados de búsqueda y sitios asociados. Si nuestro componente no tiene tiempo para responder, entonces la información de él simplemente no se le dará al usuario. Entonces, la compañía perderá dinero. Por lo tanto, es muy importante responder a tiempo.
¿Qué métricas importantes del servidor se pueden resaltar?
- Solicitud por segundo (RPS) . La felicidad de un usuario es, por supuesto, importante para nosotros. Pero qué pasa si no uno, sino que miles de usuarios vinieron a ti. ¿Cuántas solicitudes por segundo puede soportar su servidor y no caer?
- Tiempo por solicitud . El contenido del sitio debe mostrarse lo más rápido posible para que el usuario no se canse de esperar y no vaya a la tienda a comprar palomitas de maíz. En nuestro caso, no verá una parte importante de la información en la página.
- Tamaño de conjunto residente (RSS) . Asegúrese de controlar cuánto consume memoria su programa. Si el servicio consume toda la memoria, apenas es posible hablar de tolerancia a fallas.
- Errores HTTP
Así que vamos a ponerlo en orden.
Solicitud por segundo
A nuestro desarrollador, que ha estado lidiando con las pruebas de carga durante mucho tiempo, le gusta hablar sobre el recurso crítico del sistema. Veamos de qué se trata.
Cada sistema tiene sus propias características de configuración que determinan la operación. Por ejemplo, longitud de la cola, tiempo de espera de respuesta, grupo de subprocesos de trabajo, etc. Y puede suceder que la capacidad de su servicio se base en uno de estos recursos. Puedes realizar un experimento. Aumenta cada recurso por turno. Un recurso, cuyo aumento aumentará la capacidad de su servicio, será crítico para usted. En un sistema bien configurado, para aumentar la capacidad, tendrá que aumentar no un recurso, sino varios. Pero esto todavía se puede "sentir". Será genial si puede configurar su sistema para que todos los recursos funcionen con toda su fuerza y el servicio se ajuste dentro de los plazos establecidos.
Para estimar cuántas solicitudes por segundo resistirá su servidor, debe dirigirle un flujo de solicitudes. Como tenemos este proceso integrado en el sistema CI, utilizamos una "pistola" muy simple con funcionalidad limitada. Pero desde el software de código abierto Yandex.Tank es perfecto para esta tarea. Él tiene documentación detallada. Un regalo para Tank es un servicio para ver los resultados.
Un pequeño tope. Yandex.Tank tiene una funcionalidad bastante rica, no se limita a automatizar las solicitudes de bombardeo. También ayudará a recopilar métricas de su servicio, crear gráficos y ajustar el módulo con la lógica que necesita. En general, recomendamos conocerlo.
Ahora necesita alimentar las solicitudes al Tanque para que puedan disparar a nuestro servicio. Las solicitudes con las que va a utilizar el servidor pueden ser del mismo tipo, creadas y propagadas artificialmente. Sin embargo, las mediciones serán mucho más precisas si puede recopilar un conjunto real de solicitudes de los usuarios durante un cierto período de tiempo.
La capacidad se puede medir de dos maneras.
Modelo de carga abierta (prueba de esfuerzo)
Haga "usuarios", es decir, varios hilos que enviarán una solicitud a su sistema. La carga que no daremos es constante, sino que se acumula o incluso se alimenta en olas. Entonces nos acercará a la vida real. Aumentamos el RPS y detectamos el punto en el que el servicio descascarado "rompe" el SLA. Por lo tanto, puede encontrar los límites del sistema.
Para calcular el número de usuarios, puede usar la fórmula Little (puede leer sobre esto aquí ). Omitiendo la teoría, la fórmula se ve así:
RPS = 1000 / T * trabajadores, donde
• T: tiempo promedio de procesamiento de la solicitud (en milisegundos);
• trabajadores: el número de hilos;
• 1000 / T solicitudes por segundo: este valor será generado por un generador de un solo subproceso.
Modelo de carga cerrada (prueba de carga)
Tomamos un número fijo de "usuarios". Debe configurarlo para que la cola de entrada correspondiente a la configuración de su servicio esté siempre obstruida. Al mismo tiempo, no tiene sentido hacer que el número de subprocesos supere el límite de la cola, ya que descansaremos en este número y el servidor descartará las solicitudes restantes con un error 5xx. Observamos cuántas solicitudes por segundo podrá emitir el diseño. Tal esquema en el caso general no es similar al flujo real de solicitudes, pero ayudará a mostrar el comportamiento del sistema a la carga máxima y evaluar su rendimiento actual.
Para la gran mayoría de los sistemas (donde el recurso crítico no está relacionado con el procesamiento de conexiones), el resultado será el mismo. Al mismo tiempo, el modelo cerrado tiene menos ruido, porque el sistema está en el área de carga que nos interesa todo el tiempo de la prueba.
Al probar nuestro servicio, utilizamos un modelo cerrado. Después de disparar, el arma nos da cuántas solicitudes por segundo pudo emitir nuestro servicio. Yandex.Tank este indicador también es fácil de decir.
Tiempo por solicitud
Si volvemos al párrafo anterior, resulta obvio que con dicho esquema, no tiene sentido evaluar el tiempo de respuesta a una solicitud. Cuanto más fuerte carguemos el sistema, más se degradará y más tiempo responderá. Por lo tanto, para probar el tiempo de respuesta, el enfoque debe ser diferente.
Para obtener el tiempo de respuesta promedio, usaremos el mismo Yandex.Tank. Solo ahora estableceremos el RPS correspondiente al indicador promedio de su sistema en producción. Después del bombardeo, obtenemos tiempos de respuesta para cada solicitud. En función de los datos recopilados, se pueden calcular los percentiles de los tiempos de respuesta.
A continuación, debe comprender qué percentil consideramos importante. Por ejemplo, construimos sobre la producción. Podemos dejar el 1% de las solicitudes de errores, no respuestas, solicitudes de depuración que funcionen durante mucho tiempo, problemas con la red, etc. Por lo tanto, consideramos significativo el tiempo de respuesta, que acomoda el 99% de las solicitudes.
Tamaño de conjunto residente
Nuestro servidor trabaja directamente con archivos a través de mmap . Al medir el índice RSS, queremos saber cuánta memoria tomó el programa del sistema operativo durante la operación.
En Linux, el archivo / proc / PID / smaps está escrito: esta es una extensión basada en mapas que muestra el consumo de memoria para cada una de las asignaciones de procesos. Si su proceso usa tmpfs, entonces la memoria anónima y no anónima entrará en smaps. La memoria no anónima incluye, por ejemplo, archivos cargados en la memoria. Aquí hay una entrada de ejemplo en smaps. Se especifica un archivo específico y su parámetro Anónimo = 0kB.
7fea65a60000-7fea65a61000 r--s 00000000 09:03 79169191 /place/home/.../some.yabs Size: 4 kB Rss: 4 kB Pss: 4 kB Shared_Clean: 0 kB Shared_Dirty: 0 kB Private_Clean: 4 kB Private_Dirty: 0 kB Referenced: 4 kB Anonymous: 0 kB AnonHugePages: 0 kB Swap: 0 kB KernelPageSize: 4 kB MMUPageSize: 4 kB Locked: 0 kB VmFlags: rd mr me ms
Y este es un ejemplo de asignación de memoria anónima. Cuando un proceso (el mismo mmap) realiza una solicitud al sistema operativo para asignar un cierto tamaño de memoria, se le asigna una dirección. Mientras que el proceso solo ocupa memoria virtual. En este punto, aún no sabemos qué parte física de la memoria se asignará. Vemos un registro sin nombre. Este es un ejemplo de asignación de memoria anónima. Se solicitó al sistema el tamaño de 24572 kB, pero no lo usaron y en realidad solo se tomó RSS = 4 kB.
7fea67264000-7fea68a63000 rw-p 00000000 00:00 0 Size: 24572 kB Rss: 4 kB Pss: 4 kB Shared_Clean: 0 kB Shared_Dirty: 0 kB Private_Clean: 0 kB Private_Dirty: 4 kB Referenced: 4 kB Anonymous: 4 kB AnonHugePages: 0 kB Swap: 0 kB KernelPageSize: 4 kB MMUPageSize: 4 kB Locked: 0 kB VmFlags: rd wr mr mw me ac
Dado que la memoria no anónima asignada no irá a ninguna parte después de que se detenga el proceso, el archivo no se eliminará, no nos interesa dicho RSS.
Antes de comenzar a disparar al servidor, resumimos el RSS de / proc / PID / smaps, asignado para la memoria anónima, y lo recordamos. Realizamos bombardeos, similar al tiempo de prueba por solicitud. Después de terminar, considere RSS nuevamente. La diferencia entre el estado inicial y el final será la cantidad de memoria que utilizó su proceso durante la operación.
Errores HTTP
No olvide seguir los códigos de respuesta que el servicio devuelve durante las pruebas. Si algo salió mal al configurar una prueba o entorno, y el servidor devolvió errores 5xx y 4xx para todas sus solicitudes, entonces no había mucho sentido en dicha prueba. Estamos monitoreando la proporción de malas respuestas. Si hay muchos errores, la prueba se considera inválida.
Un poco sobre precisión de medición
Y ahora lo más importante. Volvamos a los párrafos anteriores. Resulta que los valores absolutos de las métricas calculadas por nosotros no son tan importantes para nosotros. No, por supuesto, puede lograr la estabilidad de los indicadores, teniendo en cuenta todos los factores, errores y fluctuaciones. Paralelamente, escriba un trabajo científico sobre este tema (por cierto, si alguien estaba buscando uno, esta podría ser una buena opción). Pero esto no es lo que nos interesa.
Es importante para nosotros que una confirmación particular afecte el código relativo al estado anterior del sistema. Es decir, la diferencia entre las métricas de commit a commit es importante. Y aquí es necesario establecer un proceso que compare esta diferencia y al mismo tiempo garantice la estabilidad del valor absoluto en este intervalo.
El entorno, las solicitudes, los datos, el estado del servicio: todos los factores disponibles para nosotros deben corregirse. Es este sistema el que funciona para nosotros como parte de la integración continua, proporcionándonos información sobre todo tipo de cambios que se han producido dentro de cada confirmación. A pesar de esto, no será posible arreglar todo, habrá ruido. Podemos reducir el ruido, obviamente, al aumentar la muestra, es decir, hacer varias iteraciones del rodaje. Además, después de disparar, digamos, 15 iteraciones, podemos calcular la mediana de la muestra resultante. Además, es necesario encontrar un equilibrio entre el ruido y la duración del disparo. Por ejemplo, nos decidimos por un error del 1%. Si desea elegir un método estadístico más complejo y preciso de acuerdo con sus requisitos, le recomendamos un libro que enumere las opciones con una descripción de cuándo y cuál se utiliza.
¿Qué más se puede hacer con el ruido?
Tenga en cuenta que el entorno en el que realiza las pruebas juega un papel importante en dichas pruebas. El banco de pruebas debe ser confiable, no debe ejecutar otros programas, ya que pueden provocar la degradación de su servicio. Además, los resultados pueden y dependerán del perfil de carga, el entorno, la base de datos y varias "tormentas magnéticas".
Como parte de una prueba de confirmación única, realizamos varias iteraciones en diferentes hosts. En primer lugar, si usa la nube, entonces puede pasar cualquier cosa allí. Incluso si la nube es especializada, como la nuestra, los procesos de servicio siguen funcionando allí. Por lo tanto, no puede confiar en el resultado de un host. Y si tiene un host de hierro, donde no hay, como en la nube, un mecanismo estándar para elevar el medio ambiente, incluso puede romperlo accidentalmente una vez y dejarlo así. Y él siempre te mentirá. Por lo tanto, manejamos nuestras pruebas en la nube.
Es cierto, otra pregunta surge de esto. Si sus mediciones se realizan cada vez en diferentes hosts, entonces los resultados pueden hacer un poco de ruido y debido a esto incluido. Entonces puede normalizar las lecturas al host. Es decir, según datos históricos, recopile el "coeficiente del host" y téngalo en cuenta al analizar los resultados.
El análisis de los datos históricos muestra que el hardware es diferente. La palabra "hardware" aquí incluye la versión del kernel y las consecuencias del tiempo de actividad (aparentemente, no objetos del kernel móviles en la memoria).
Por lo tanto, a cada "host" (al reiniciar, el host "muere" y aparece un "nuevo") asociamos una corrección por la cual multiplicamos el RPS antes de la agregación.
Consideramos y actualizamos las enmiendas de una manera extremadamente torpe, que recuerda sospechosamente alguna opción de entrenamiento de refuerzo.
Para un vector dado de correcciones posthost, consideramos la función objetivo:
- en cada prueba consideramos la desviación estándar de los resultados RPS "corregidos" obtenidos
- tomar el promedio de ellos con pesos iguales exp((testtimestamp−now)/tau) ,
- tenemos tau = 1 semana.
Luego fijamos una corrección (para el host con la mayor suma de estos pesos) en 1.0 y buscamos los valores de todas las otras correcciones que dan un mínimo de la función objetivo.
Con el fin de validar los resultados en los datos históricos, consideramos las correcciones en los datos antiguos, consideramos el resultado corregido en el fresco, en comparación con el no corregido.
Otra opción para ajustar los resultados y reducir el ruido es normalizar a "sintéticos". Antes de comenzar el servicio que se probará, ejecute un "programa sintético" en el host, desde el cual puede evaluar el estado del host y calcular el factor de corrección. Pero en nuestro caso, utilizamos correcciones basadas en el host, y esta idea ha seguido siendo una idea. Quizás a uno de ustedes le gustará.
A pesar de la automatización y todas sus ventajas, no se olvide de la dinámica de sus indicadores. Es importante asegurarse de que el servicio no se degrada con el tiempo. Es posible que no note pequeñas reducciones, pueden acumularse y, durante un largo período de tiempo, sus indicadores pueden ceder. Aquí hay un ejemplo de nuestros gráficos que estamos viendo en RPS. Muestra el valor relativo en cada confirmación marcada, su número y la capacidad de ver desde dónde se asignó la versión.
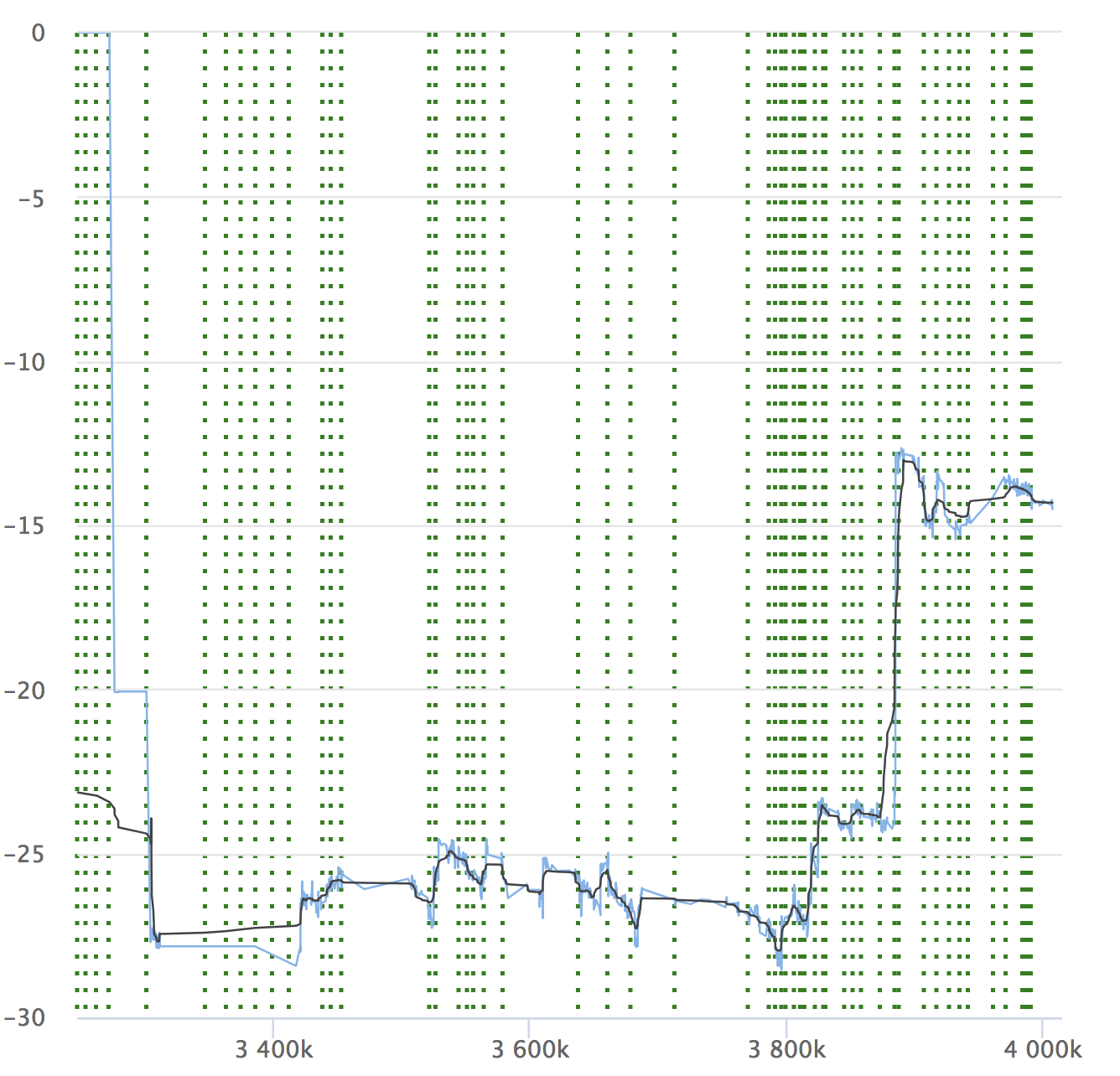
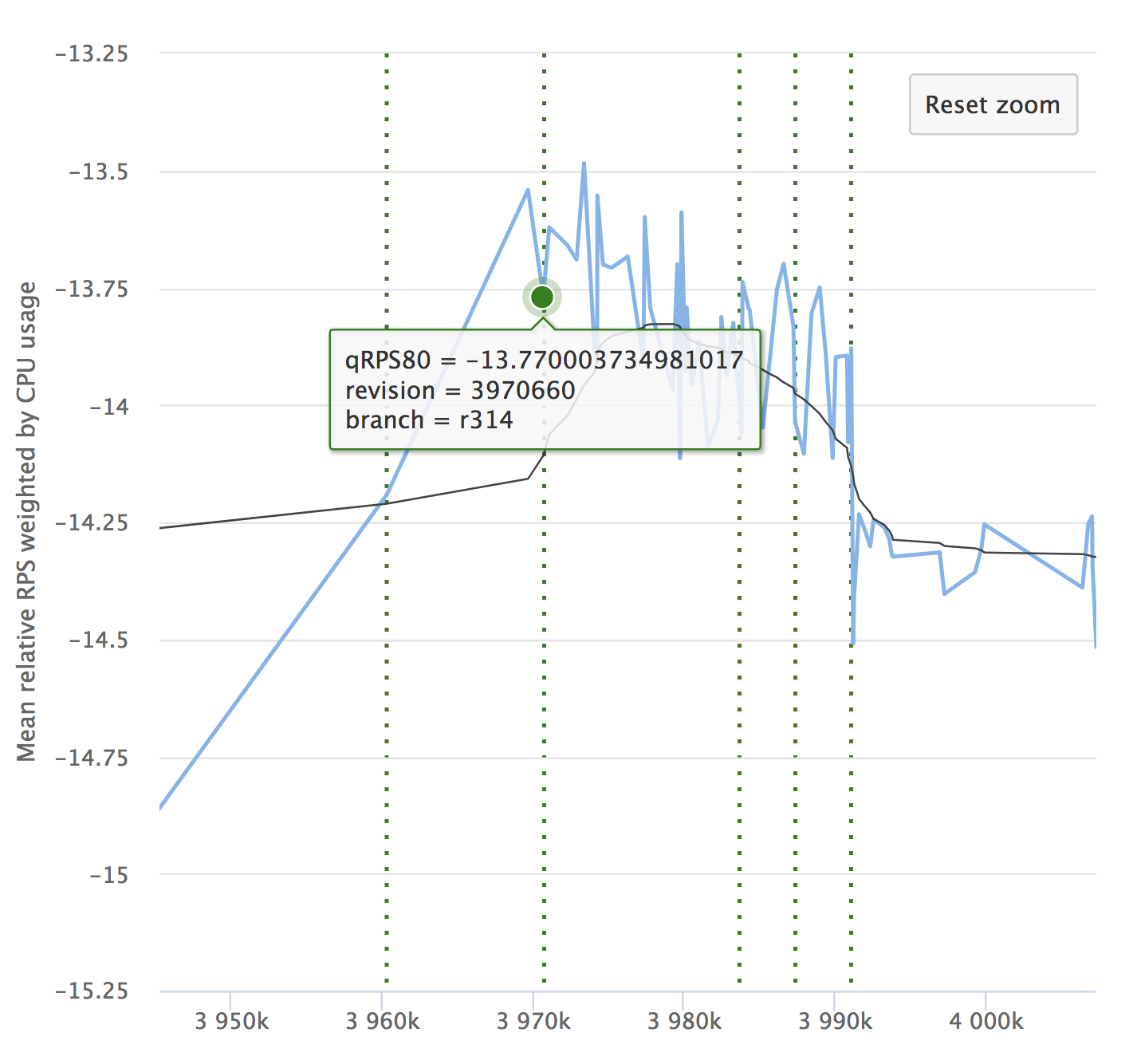
Si lees el artículo, definitivamente será interesante para ti ver un informe sobre Yandex.Tank y un análisis de los resultados de las pruebas de carga.
También le recordamos que con más detalle sobre la organización de la integración continua, hablaremos sobre el 25 de octubre en el evento Yandex desde adentro . Ven a visitarnos!