Hola a todos Como sabrán, solía escribir y hablar más sobre almacenamiento, Vertica, almacenamiento de big data y otras cosas analíticas. Ahora todas las demás bases de datos han caído en mi área de responsabilidad, no solo analítica, sino también OLTP (PostgreSQL) y NOSQL (MongoDB, Redis, Tarantool).
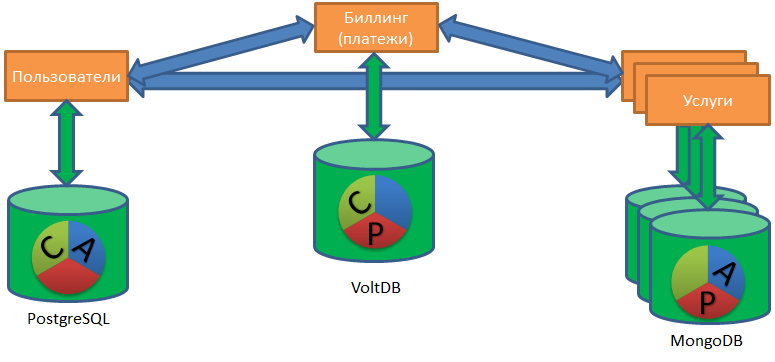
Esta situación me permitió ver una organización que tiene varias bases de datos como una organización que tiene una base de datos distribuida heterogénea (heterogénea). Una única base de datos heterogénea distribuida, que consta de un montón de PostgreSQL, Redis y Mong ... Y, posiblemente, una o dos bases de datos Vertica.
El trabajo de esta base distribuida única genera un montón de tareas interesantes. En primer lugar, desde el punto de vista empresarial, es importante que todo sea normal con los datos que se mueven a lo largo de dicha base. No uso específicamente el término integridad, consistencia, porque el término es complejo, y en diferentes matices de considerar un DBMS (teorema A C ID y C AP) tiene un significado diferente.
La situación con una base distribuida se agrava si una empresa intenta cambiar a una arquitectura de microservicio. Debajo del gato, hablo sobre cómo garantizar la integridad de los datos en una arquitectura de microservicio sin transacciones distribuidas y conectividad estrecha. (Y al final explico por qué elegí esta ilustración para el artículo).

Según Chris Richardson (uno de los evangelistas más famosos de la arquitectura de microservicios), esta arquitectura tiene dos enfoques para trabajar con bases de datos: base de datos compartida y base de datos por servicio.

La base de datos compartida es un buen primer paso, una gran solución para una empresa pequeña sin planes de crecimiento ambiciosos. Además, este patrón en sí mismo es un antipatrón desde el punto de vista de la arquitectura de microservicios, como dos servicios que comparten una base común no se pueden probar y escalar de forma independiente. Es decir más bien, estos servicios son uno que tiende a convertirse en un monolito.
El patrón de base de datos por servicio supone que cada servicio tiene su propia base de datos. Un servicio puede acceder a los datos de otro servicio solo a través de la API (en sentido amplio), sin una conexión directa a su base de datos.
El patrón de base de datos por servicio permite a los equipos de los servicios correspondientes seleccionar las bases de datos a su gusto. Alguien puede en MongoDB, alguien cree en PostgreSQL, alguien necesita Redis (el riesgo de pérdida de datos al cerrar es aceptable para este servicio), y alguien generalmente almacena datos en archivos CSV en el disco (y por qué, en realidad y no?
Trabajar con tal "zoológico" de bases de datos plantea la tarea de restaurar el orden en los datos a un nivel completamente nuevo de complejidad.
Arquitectura ACID y microservicio
Veamos la tarea de ordenar las cosas a través del prisma del clásico conjunto de requisitos de ACID basados en DBMS: ampliaremos la esencia de cada letra de la abreviatura e ilustraremos las dificultades con esta letra en la arquitectura de microservicios.
(A) CID - Atomicidad. Atomicidad: todo o nada.
De acuerdo con el requisito de Atomicidad, es imprescindible completar todos los pasos (con posibles repeticiones), si un paso importante falla, cancele los pasos completados.
La ilustración anterior muestra el proceso de prueba de comprar un servicio VIP: el dinero se reserva en la facturación (1), se activa un servicio de bonificación para un usuario (2), el tipo de usuario se cambia a Pro (3), el dinero reservado en la facturación se carga (4). Los cuatro pasos deben completarse o no completarse.
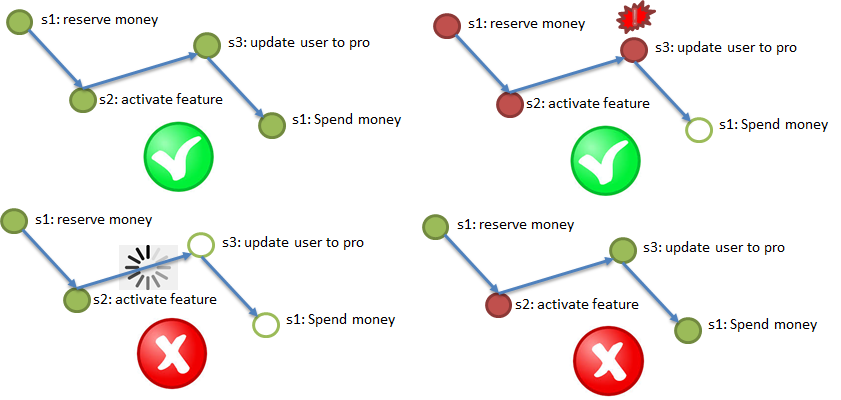
En este caso, no puede colgar en el medio del proceso, por lo tanto, es preferible la asincronía, en casos extremos, el sincronismo con el tiempo de espera incorporado.
A (C) ID - Consistencia. Consistencia: cada paso no debe contradecir las condiciones de contorno.
Ejemplos clásicos de condiciones para, por ejemplo, enviar dinero desde el cliente A en el servicio 1 al cliente B en el servicio 2: como resultado de ese envío, el dinero no debería ser menor (el dinero no debería perderse durante la transferencia) o más (es inaceptable enviar el mismo dinero a dos usuarios al mismo tiempo) Para cumplir con este requisito, debe codificar las condiciones en algún lugar y verificar los datos para las condiciones (idealmente, sin llamadas adicionales).

ACI (D) - Durabilidad. El requisito de durabilidad significa que los efectos de las operaciones no desaparecen.
Bajo las condiciones de persistencia de Polyglot, un servicio puede operar en una base de datos que regularmente puede "perder" los datos registrados en ella. Se puede obtener un truco similar incluso de bases de datos sólidas como PostgreSQL, si la replicación asincrónica está habilitada allí. La ilustración muestra cómo los cambios registrados en Master, pero que no llegaron a Slave a través de la replicación asincrónica, pueden destruirse quemando el servidor Master. Para garantizar los requisitos de durabilidad, es necesario poder diagnosticar y recuperar adecuadamente esas pérdidas.
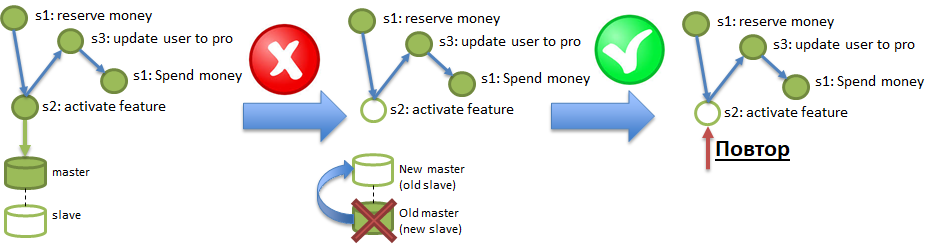
¿Y dónde estoy, preguntas?
Y en ninguna parte. El aislamiento en un entorno de varios servicios asincrónicos independientes es un requisito técnico. La investigación moderna ha demostrado que los procesos comerciales reales pueden implementarse sin aislamiento. El aislamiento simplifica el pensamiento al minimizar la concurrencia (el desarrollo de la computación paralela es más difícil para un programador), pero la arquitectura de microservicios es inherentemente paralela masiva, el aislamiento en dicho entorno es redundante.
Existen muchos enfoques para lograr el cumplimiento de los requisitos anteriores. El algoritmo más ampliamente conocido de transacciones distribuidas proporcionado por el llamado compromiso de dos fases (2PC). Desafortunadamente, la implementación de confirmaciones de dos fases requiere reescribir todos los servicios involucrados. Y lo más grave: este algoritmo no es muy productivo. Las ilustraciones de estudios recientes muestran que este algoritmo muestra un cierto rendimiento en una base distribuida de dos servidores, pero con un aumento en el número de servidores, la productividad no crece linealmente ... O, mejor dicho, no crece en absoluto.

Una de las principales ventajas de la arquitectura de microservicios es la capacidad de aumentar linealmente el rendimiento simplemente agregando más y más servidores. Resulta que si usamos un compromiso de dos fases para garantizar la integridad distribuida, este proceso se convertirá en un cuello de botella, un limitador del crecimiento de la productividad, a pesar del aumento en el número de servidores.
¿Cómo puede garantizar la integridad distribuida (requisitos ACiD) sin compromisos de dos fases, con la capacidad de escalar linealmente en el rendimiento?
La investigación moderna (por ejemplo, An Evaluation of Distributed Concurrency Control. VLDB 2017 ) argumenta que el llamado "enfoque optimista" puede ayudar. La diferencia entre el compromiso de dos fases y el "enfoque optimista" generalizado puede ilustrarse con la diferencia entre la antigua tienda soviética (con un mostrador) y un supermercado moderno como Auchan. En una tienda con un mostrador, cada cliente se considera sospechoso y se le sirve con el máximo control. De ahí las líneas y los conflictos. Y en el supermercado, el comprador se considera honesto por defecto, le dan la oportunidad de acercarse a los estantes y llenar los carros. Por supuesto, existen herramientas de monitoreo para atrapar ladrones (cámaras, seguridad), pero la mayoría de los compradores nunca tienen que lidiar con ellas.
Por lo tanto, el supermercado se puede ampliar, ampliar, simplemente colocando más mesas de efectivo. Es similar con la arquitectura de microservicios: si la integridad distribuida se garantiza mediante un "enfoque optimista", cuando solo los procesos en los que algo salió mal se cargan adicionalmente con verificaciones. Y los procesos normales pasan sin controles adicionales.
Es importante El "enfoque optimista" incluye varios algoritmos. Me gustaría contarles sobre la saga, el algoritmo para mantener la integridad distribuida, recomendado por Chris Richardson.
Sagas - elementos del algoritmo
El algoritmo de hundimiento tiene dos opciones. Por lo tanto, al principio me gustaría describir universalmente los elementos requeridos del algoritmo para que la descripción sea adecuada para ambas opciones.
Elemento 1. Canal confiable y confiable de entrega de eventos entre servicios, garantizando "al menos una vez la entrega". Es decir Si el paso 2 del proceso se ha completado con éxito, entonces una notificación (evento) sobre esto debería llegar al paso 3 al menos una vez, las entregas repetidas son aceptables, pero no se debe perder nada. "Persistente" significa que el canal debe almacenar notificaciones durante un tiempo (2-3 días, una semana) para que un servicio que haya perdido los últimos cambios debido a la pérdida de la base de datos (vea el ejemplo de Durabilidad, en la ilustración, este es el paso 2), pueda restaurar estos cambios al reproducir eventos del canal.
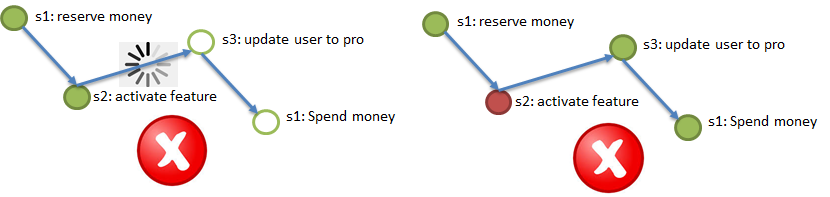
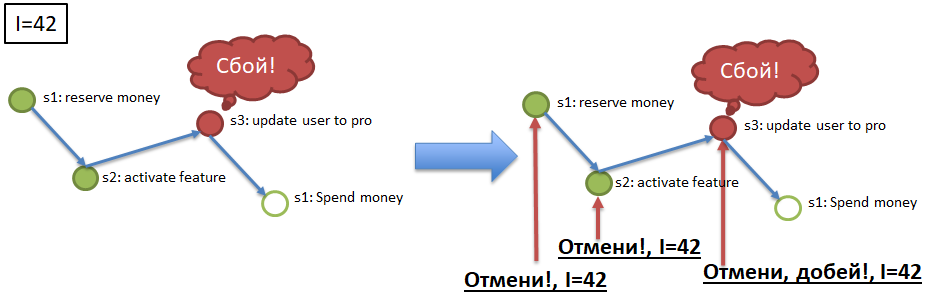
Elemento 2. Idempotencia de las llamadas de servicio mediante el uso de una clave de idempotencia única. Imagine que yo (el usuario) inicio el proceso de compra de un paquete VIP (vea el ejemplo de Atomicity). Al comienzo del proceso, se me da una clave única, la clave de idempotencia, por ejemplo, 42. Luego, la llamada a cada uno de los pasos (1 → 2 → 3 → 4) debe realizarse con la clave de idempotencia indicada. En el párrafo anterior, se menciona la posibilidad de la llegada repetida del mismo mensaje al servicio (en el paso). El servicio (paso) debería poder ignorar automáticamente la llegada repetida del evento procesado, verificando la repetición mediante la clave de idempotencia. Es decir, si todos los servicios (pasos del proceso) son idempotentes, para cumplir con los requisitos de Atomicidad y Durabilidad, es suficiente redirigir a los pasos correspondientes a los eventos desde los canales. Los pasos que omitieron eventos los ejecutarán, y los pasos que ya han completado eventos los ignorarán debido a la idempotencia.

Elemento 3. Cancelación de llamadas de servicio (pasos) por clave de idempotencia.
Para garantizar la Atomicidad (vea el ejemplo), si el proceso con la clave de idempotencia 42, por ejemplo, se detuvo / cayó en el paso 3, entonces es necesario cancelar la ejecución exitosa de los pasos 1 y 2 para la clave 42. Para esto, cada paso obligatorio del proceso debe tener un paso de "compensación" , Un método API que cancela la ejecución del paso requerido para la clave de idempotencia especificada (42). La implementación de llamadas compensatorias es un elemento difícil pero necesario en el refinamiento de los servicios como parte de la implementación del algoritmo de caída.
Los tres elementos enumerados anteriormente son relevantes para ambas versiones de la implementación de la "caída": orquestada y coreográfica.
Sagas Orquestadas
El algoritmo más simple y obvio para las sagas orquestadas es más fácil de entender e implementar. En un excelente artículo, kevteev describió el algoritmo y el proceso de implementación del mecanismo de sagas orquestadas en Avito. Su algoritmo supone la existencia de un servicio de control, "orquestando" las llamadas de servicio dentro del marco de los procesos comerciales atendidos. El mismo servicio de monitoreo puede tener su propia base de datos (por ejemplo, PostgreSQL), que actúa como un canal confiable de entrega de eventos persistentes (elemento 1).
Sagas Coreográficas
La saga coreográfica es más complicada. Aquí, un bus de datos que implemente los siguientes requisitos debe actuar como un canal confiable y persistente: publicación de disparar y olvidar, entrega de eventos de publicación-suscripción, al menos una vez entregada. Es decir cada paso de cada proceso debe recibir un comando para operar desde el bus, y enviar allí el mensaje sobre la finalización exitosa, sobre el inicio del siguiente paso, para que también lo lea desde el bus y continúe el proceso. Además, para cada mensaje puede haber varios suscriptores.
La saga coreográfica también debe tener un servicio de control, un servicio de sagas, pero mucho más "ligero". El servicio debe conocer los procesos comerciales registrados en el sistema, la composición de los pasos incluidos en cada proceso. También debe escuchar el bus, monitorear la ejecución de cada proceso (cada clave de idempotencia), y solo si algo salió mal, ya sea lanzar "repeticiones" de pasos específicos, o lanzar "cancela", "compensaciones" por los pasos tomados.
Matices
Uno de los matices más importantes de las sagas que los distingue de las transacciones clásicas es la desviación de la linealidad, secuencia y obligación de cada paso. Una saga no es necesariamente una cadena lineal de eventos, puede ser un gráfico dirigido: un nuevo evento de registro de usuarios puede generar varios pasos en paralelo (enviar SMS, registrar un inicio de sesión, generar una contraseña, enviar un correo electrónico), algunos de los cuales pueden ser opcionales. En una primera aproximación, parece que en una saga tan "ramificada" con pasos opcionales es difícil determinar la finalización de la saga (proceso), pero, de hecho, todo es simple: la saga (proceso) se completa cuando se completan todos los pasos requeridos, en cualquier orden.

El segundo matiz, que es más típico para las sagas coreográficas, pero también posible para las orquestadas, es elegir un enfoque para registrar procesos comerciales, tipos de sagas en el servicio de sagas. El ejemplo de Atomicidad describe un proceso de cuatro pasos obligatorios consecutivos.
¿Quién registró este proceso, indicó todos los pasos, colocó las dependencias y los pasos obligatorios? La respuesta obvia, pero pasada de moda, es que el registro del proceso debe hacerse centralmente en el servicio de hundimiento. Pero esta respuesta no es muy consistente con la arquitectura de microservicios. En la arquitectura de microservicios, es más prometedor, más productivo y más rápido registrar procesos ascendentes. Es decir no para anotar todos los matices del proceso en el servicio de caída, sino para permitir que los servicios individuales "encajen" en los procesos existentes por sí mismos, indicando su naturaleza vinculante / opcional y sus predecesores obligatorios.
Es decir El proceso de registro de un usuario en el servicio SAG puede consistir inicialmente en tres pasos, y luego, durante el desarrollo del sistema, siete pasos más encajarán allí, y se escribirá un paso, y habrá nueve de ellos. Tal esquema "anarquista" y "descentralizado" es difícil de probar, implementar un proceso estricto y coordinado, pero es mucho más conveniente para los equipos Ágiles, para la evolución continua de productos multidireccionales.
De hecho, aquí. Con una presentación seria, creo que vale la pena terminarla, de lo contrario el artículo resultó ser demasiado extenso.
Aquí hay un enlace a la presentación de este material, hice un informe sobre este tema en Highload Siberia 2018.
UPD - y video de la conferencia:
Epílogo
Al final, me gustaría tratar de explicar todo lo anterior en un lenguaje más figurativo.
Después de todo, ¿qué es una saga desde el principio? Esta trama, esta aventura de la Edad Media ... O del Juego de Tronos. Se lleva a cabo un evento (una batalla, una boda, alguien muere), la noticia de esto vuela alrededor del mundo a través de mensajeros, palomas mensajeras, comerciantes. Cuando las noticias llegan a los interesados (en una semana, en un mes, en un año), reaccionan: envían ejércitos, declaran la guerra, ejecutan a alguien y vuelan nuevos mensajes.
No existe un organismo regulador que monitoree la secuencia de acciones. Sin transacciones, sin reversión, en el sentido de deshacer la acción, como si nunca hubiera sido. Todo de manera adulta, cada acción tiene lugar para siempre. Puede ser compensado, pero es precisamente acción (asesinato) y compensación (pagar por la cabeza, vira), y no la abolición de la muerte.
Los eventos toman mucho tiempo, provienen de diferentes fuentes, las acciones ocurren en paralelo y no estrictamente de forma secuencial. Y a menudo, nuevos participantes aparecen repentinamente en la trama, que deciden participar (llegan los dragones;)) ... y algunos de los antiguos participantes mueren repentinamente.
Tales cosas Parece un desastre y un caos, pero todo funciona, la coordinación interna del mundo no se rompe, la trama se está desarrollando y es consistente ... Aunque a veces es impredecible.