
Cada uno de nosotros percibe los textos a nuestra manera, ya sean noticias en Internet, poesía o novelas clásicas. Lo mismo se aplica a los algoritmos y métodos de aprendizaje automático, que, por regla general, perciben textos en forma matemática, en forma de un espacio vectorial multidimensional.
El artículo está dedicado a la visualización utilizando t-SNE calculado por las representaciones de palabras multidimensionales de Word2Vec. La visualización permitirá una mejor comprensión del principio de Word2Vec y cómo interpretar la relación entre los vectores de palabras antes de su uso posterior en redes neuronales y otros algoritmos de aprendizaje automático. El artículo se centra en la visualización, no se consideran más investigaciones y análisis de datos. Como fuente de datos, utilizamos artículos de Google News y obras clásicas de L.N. Tolstoi Escribiremos el código en Python en el Jupyter Notebook.
Incrustación de vecinos estocásticos distribuidos en T
T-SNE es un algoritmo de aprendizaje automático para la visualización de datos basado en el método de reducción dimensional no lineal, que se describe en detalle en el artículo original [1] y en
Habré . El principio básico de la operación t-SNE es reducir las distancias por pares entre puntos mientras se mantiene su posición relativa. En otras palabras, el algoritmo asigna datos multidimensionales a un espacio de dimensión inferior, mientras mantiene la estructura de la vecindad de los puntos.
Representaciones vectoriales de palabras y Word2Vec
En primer lugar, debemos presentar las palabras en forma vectorial. Para esta tarea, elegí la utilidad semántica de distribución de Word2Vec, que está diseñada para mostrar el significado semántico de las palabras en el espacio vectorial. Word2Vec encuentra relaciones entre palabras suponiendo que las palabras relacionadas semánticamente se encuentran en contextos similares. Puede leer más sobre Word2Vec en el artículo original [2], así como
aquí y
aquí .
Como entrada, tomamos artículos de Google News y novelas de L.N. Tolstoi En el primer caso, utilizaremos los vectores previamente entrenados en el conjunto de datos de Google News (alrededor de 100 mil millones de palabras) publicados por Google
en la página del proyecto .
import gensim model = gensim.models.KeyedVectors.load_word2vec_format('GoogleNews-vectors-negative300.bin', binary=True)
Además de los vectores pre-entrenados usando la biblioteca Gensim [3], entrenaremos otro modelo en los textos de L.N. Tolstoi Dado que Word2Vec acepta una matriz de oraciones como entrada, utilizamos el modelo Punkt Sentence Tokenizer pre-entrenado del paquete NLTK para dividir automáticamente el texto en oraciones. El modelo para el idioma ruso se puede descargar
desde aquí .
import re import codecs def preprocess_text(text): text = re.sub('[^a-zA-Z--1-9]+', ' ', text) text = re.sub(' +', ' ', text) return text.strip() def prepare_for_w2v(filename_from, filename_to, lang): raw_text = codecs.open(filename_from, "r", encoding='windows-1251').read() with open(filename_to, 'w', encoding='utf-8') as f: for sentence in nltk.sent_tokenize(raw_text, lang): print(preprocess_text(sentence.lower()), file=f)
Luego, usando la biblioteca Gensim, entrenaremos el modelo Word2Vec con los siguientes parámetros:
- size = 200 - dimensión del espacio del atributo;
- ventana = 5 - el número de palabras del contexto que analiza el algoritmo;
- min_count = 5 : la palabra debe aparecer al menos cinco veces para que el modelo la tenga en cuenta.
import multiprocessing from gensim.models import Word2Vec def train_word2vec(filename): data = gensim.models.word2vec.LineSentence(filename) return Word2Vec(data, size=200, window=5, min_count=5, workers=multiprocessing.cpu_count())
Visualización de representaciones vectoriales de palabras usando t-SNE
T-SNE es extremadamente útil para visualizar similitudes entre objetos en un espacio multidimensional. A medida que aumenta la cantidad de datos, se hace cada vez más difícil construir un gráfico visual, por lo que, en la práctica, las palabras relacionadas se combinan en grupos para una mayor visualización. Tomemos, por ejemplo, algunas palabras de un diccionario del modelo Word2Vec previamente entrenado en Google News.
keys = ['Paris', 'Python', 'Sunday', 'Tolstoy', 'Twitter', 'bachelor', 'delivery', 'election', 'expensive', 'experience', 'financial', 'food', 'iOS', 'peace', 'release', 'war'] embedding_clusters = [] word_clusters = [] for word in keys: embeddings = [] words = [] for similar_word, _ in model.most_similar(word, topn=30): words.append(similar_word) embeddings.append(model[similar_word]) embedding_clusters.append(embeddings) word_clusters.append(words)
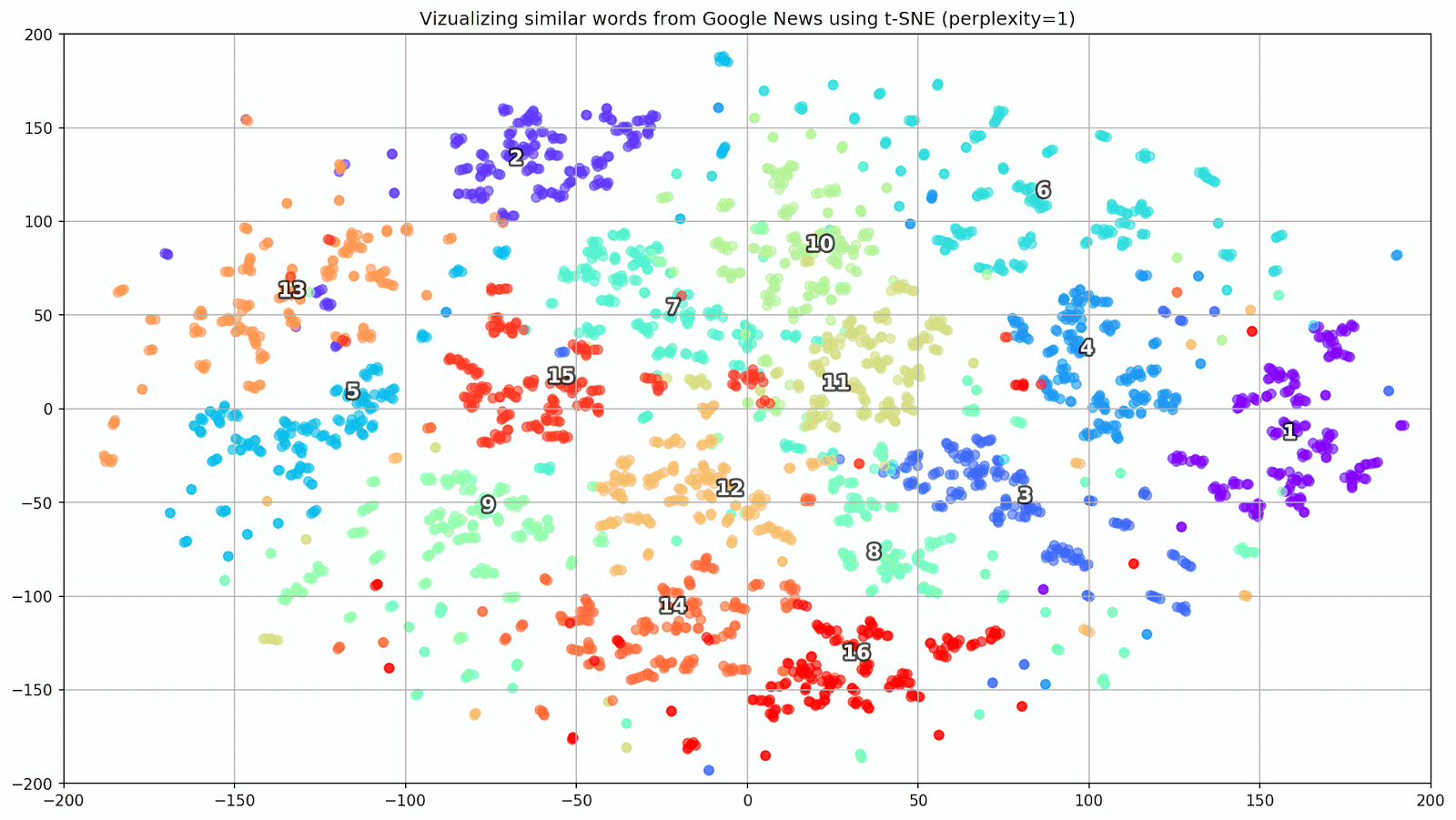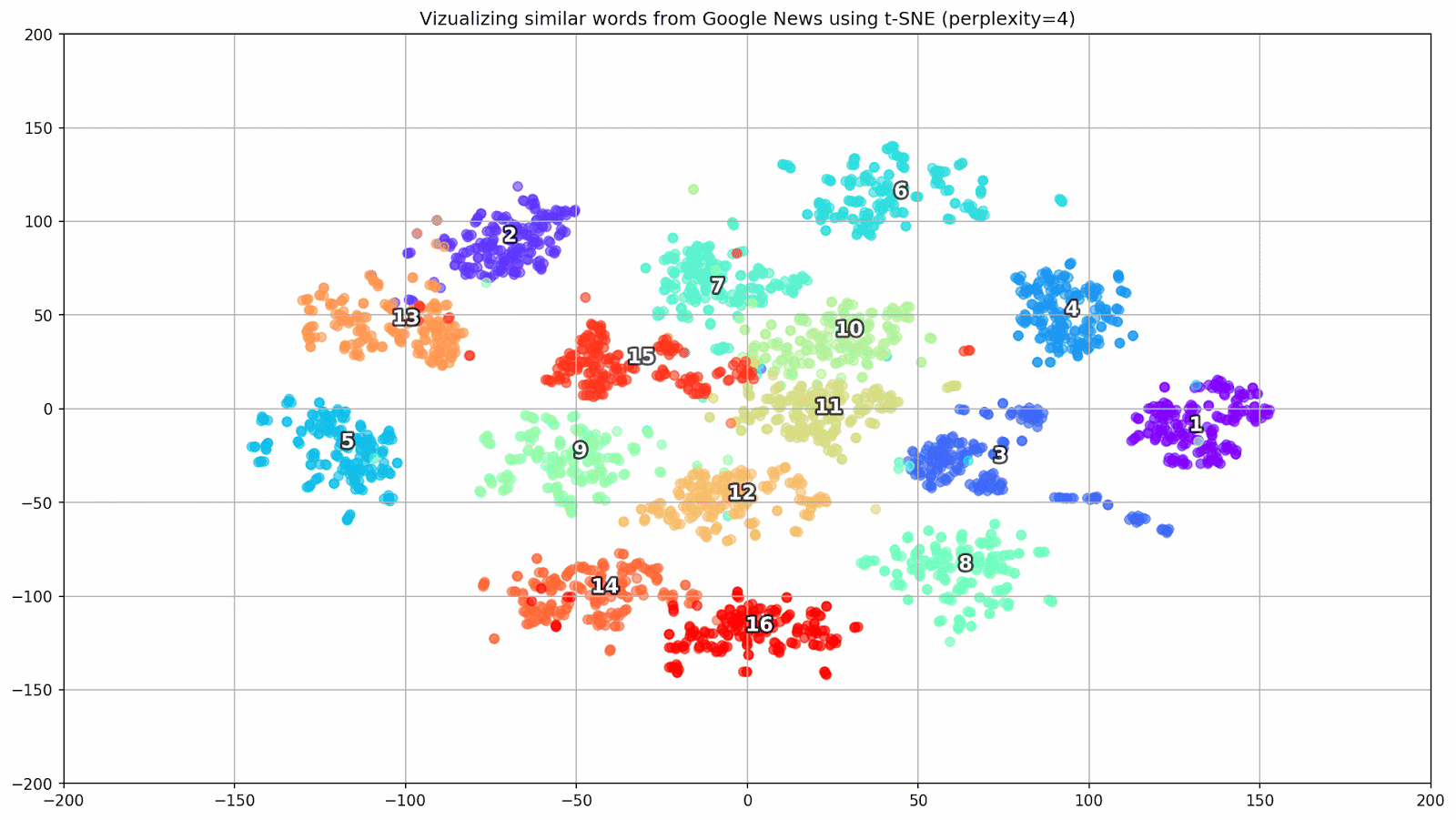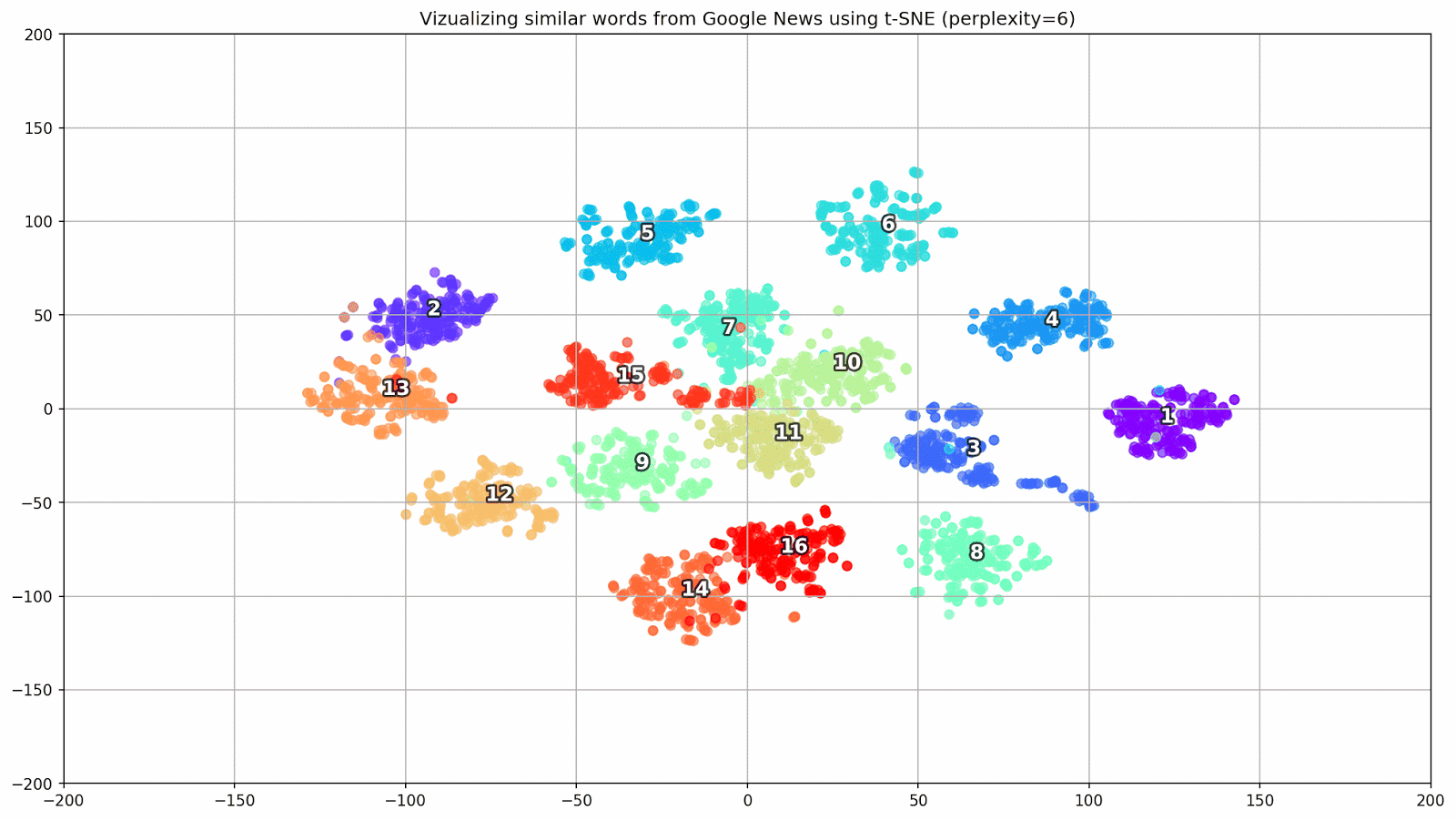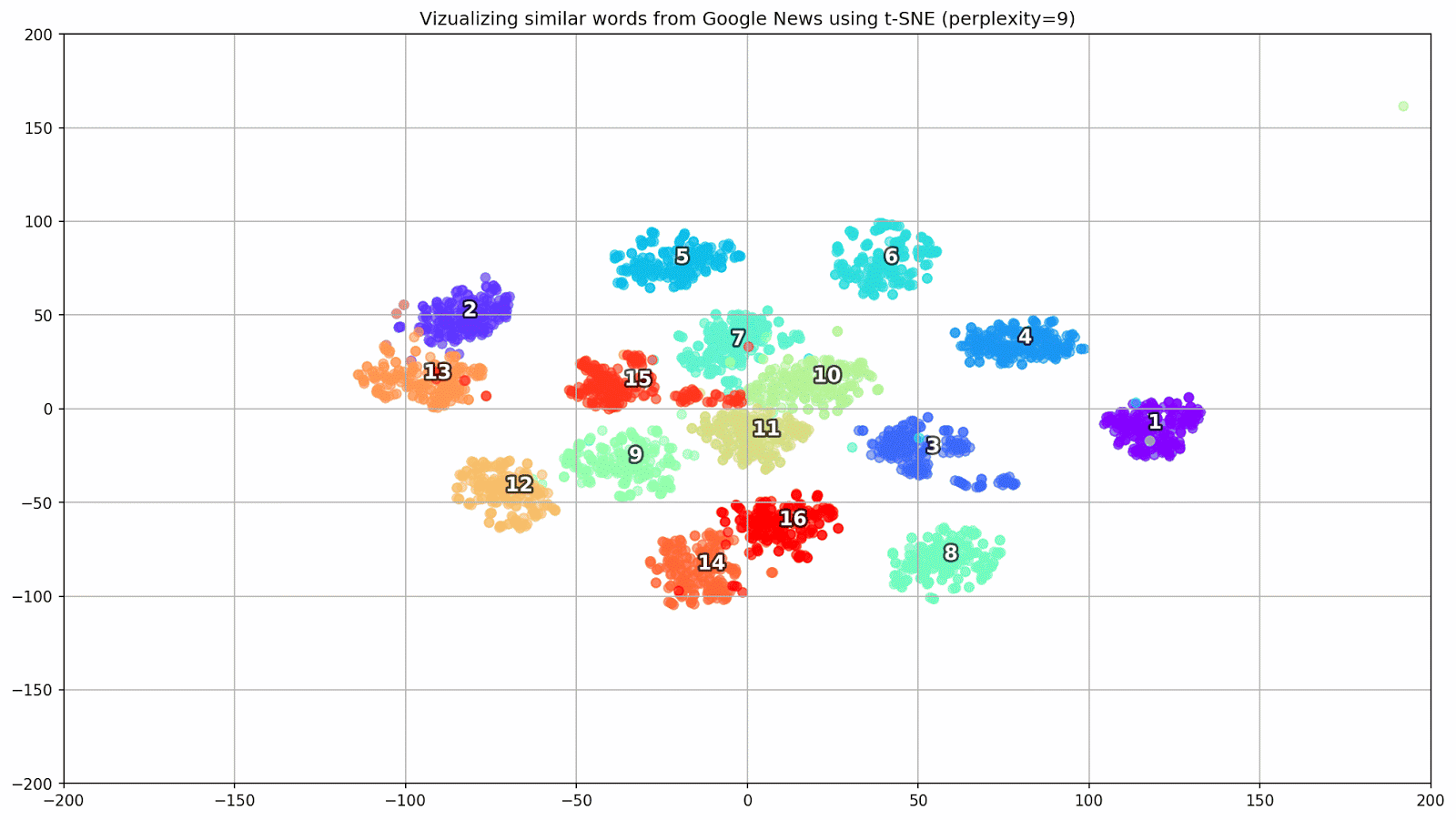 Figura 1. Grupos de palabras similares de Google Noticias con diferentes valores de preplejidad.
Figura 1. Grupos de palabras similares de Google Noticias con diferentes valores de preplejidad.A continuación, pasamos al fragmento más notable del artículo, la configuración t-SNE. Aquí, en primer lugar, debe prestar atención a los siguientes hiperparámetros:
- n_componentes : el número de componentes, es decir, la dimensión del espacio de valores;
- perplejidad : perplejidad, cuyo valor en t-SNE puede equipararse al número efectivo de vecinos. Está relacionado con el número de vecinos más cercanos, que se utiliza en otros modelos de aprendizaje en función de las variedades (ver la imagen de arriba). Se recomienda que su valor [1] se establezca en el rango de 5-50;
- init - tipo de inicialización inicial de vectores.
tsne_model_en_2d = TSNE(perplexity=15, n_components=2, init='pca', n_iter=3500, random_state=32) embedding_clusters = np.array(embedding_clusters) n, m, k = embedding_clusters.shape embeddings_en_2d = np.array(tsne_model_en_2d.fit_transform(embedding_clusters.reshape(n * m, k))).reshape(n, m, 2)
A continuación se muestra un script para construir un gráfico bidimensional usando Matplotlib, una de las bibliotecas más populares para visualizar datos en Python.
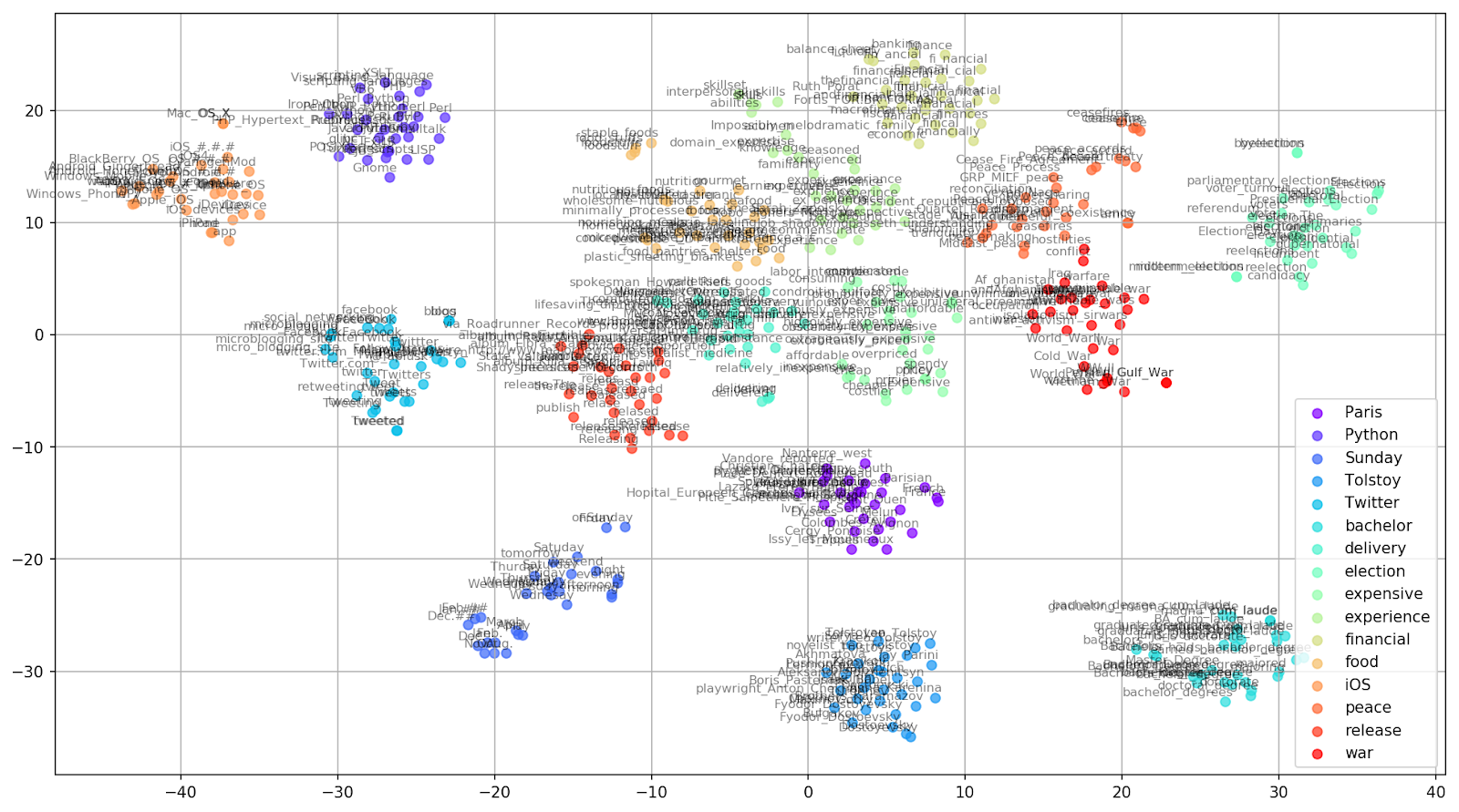 Figura 2. Grupos de palabras similares de Google News (preplejidad = 15).
Figura 2. Grupos de palabras similares de Google News (preplejidad = 15). from sklearn.manifold import TSNE import matplotlib.pyplot as plt import matplotlib.cm as cm import numpy as np % matplotlib inline def tsne_plot_similar_words(labels, embedding_clusters, word_clusters, a=0.7): plt.figure(figsize=(16, 9)) colors = cm.rainbow(np.linspace(0, 1, len(labels))) for label, embeddings, words, color in zip(labels, embedding_clusters, word_clusters, colors): x = embeddings[:,0] y = embeddings[:,1] plt.scatter(x, y, c=color, alpha=a, label=label) for i, word in enumerate(words): plt.annotate(word, alpha=0.5, xy=(x[i], y[i]), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom', size=8) plt.legend(loc=4) plt.grid(True) plt.savefig("f/.png", format='png', dpi=150, bbox_inches='tight') plt.show() tsne_plot_similar_words(keys, embeddings_en_2d, word_clusters)
A veces es necesario construir no grupos separados de palabras, sino todo el diccionario. Para este propósito, analicemos a Anna Karenina, la gran historia de la pasión, la traición, la tragedia y la expiación.
prepare_for_w2v('data/Anna Karenina by Leo Tolstoy (ru).txt', 'train_anna_karenina_ru.txt', 'russian') model_ak = train_word2vec('train_anna_karenina_ru.txt') words = [] embeddings = [] for word in list(model_ak.wv.vocab): embeddings.append(model_ak.wv[word]) words.append(word) tsne_ak_2d = TSNE(n_components=2, init='pca', n_iter=3500, random_state=32) embeddings_ak_2d = tsne_ak_2d.fit_transform(embeddings)
def tsne_plot_2d(label, embeddings, words=[], a=1): plt.figure(figsize=(16, 9)) colors = cm.rainbow(np.linspace(0, 1, 1)) x = embeddings[:,0] y = embeddings[:,1] plt.scatter(x, y, c=colors, alpha=a, label=label) for i, word in enumerate(words): plt.annotate(word, alpha=0.3, xy=(x[i], y[i]), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom', size=10) plt.legend(loc=4) plt.grid(True) plt.savefig("hhh.png", format='png', dpi=150, bbox_inches='tight') plt.show() tsne_plot_2d('Anna Karenina by Leo Tolstoy', embeddings_ak_2d, a=0.1)
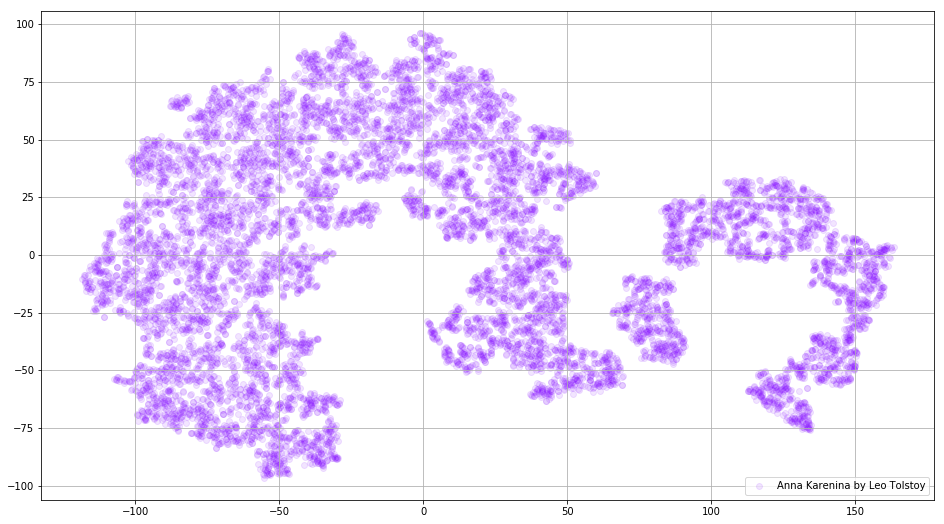
 Figura 3. Visualización del diccionario del modelo Word2Vec, entrenado en la novela "Anna Karenina".
Figura 3. Visualización del diccionario del modelo Word2Vec, entrenado en la novela "Anna Karenina".La imagen puede ser aún más informativa si usamos un espacio tridimensional. Eche un vistazo a Guerra y paz, una de las principales novelas de la literatura mundial.
prepare_for_w2v('data/War and Peace by Leo Tolstoy (ru).txt', 'train_war_and_peace_ru.txt', 'russian') model_wp = train_word2vec('train_war_and_peace_ru.txt') words_wp = [] embeddings_wp = [] for word in list(model_wp.wv.vocab): embeddings_wp.append(model_wp.wv[word]) words_wp.append(word) tsne_wp_3d = TSNE(perplexity=30, n_components=3, init='pca', n_iter=3500, random_state=12) embeddings_wp_3d = tsne_wp_3d.fit_transform(embeddings_wp)
from mpl_toolkits.mplot3d import Axes3D def tsne_plot_3d(title, label, embeddings, a=1): fig = plt.figure() ax = Axes3D(fig) colors = cm.rainbow(np.linspace(0, 1, 1)) plt.scatter(embeddings[:, 0], embeddings[:, 1], embeddings[:, 2], c=colors, alpha=a, label=label) plt.legend(loc=4) plt.title(title) plt.show() tsne_plot_3d('Visualizing Embeddings using t-SNE', 'War and Peace', embeddings_wp_3d, a=0.1)
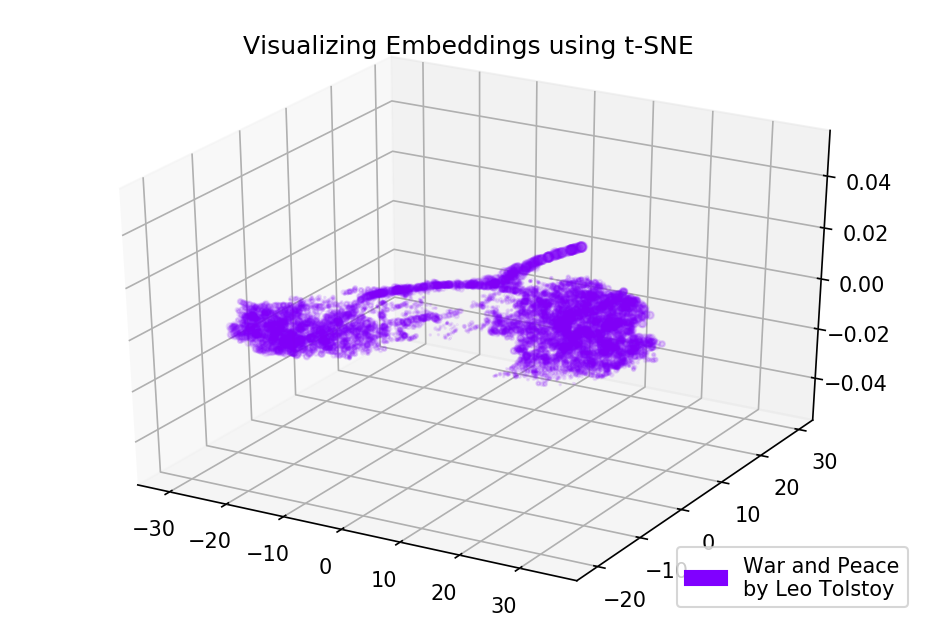 Figura 4. Visualización del diccionario del modelo Word2Vec, entrenado en la novela "Guerra y paz".
Figura 4. Visualización del diccionario del modelo Word2Vec, entrenado en la novela "Guerra y paz".Código fuente
El código está disponible en
GitHub . Allí puede encontrar el código para renderizar animaciones.
Fuentes
- Maaten L., Hinton G. Visualizando datos usando t-SNE // Revista de investigación de aprendizaje automático. - 2008. - T. 9. - S. 2579-2605.
- Representaciones distribuidas de palabras y frases y su composicionalidad // Avances en los sistemas de procesamiento de información neuronal . - 2013 .-- S. 3111-3119.
- Rehurek R., Sojka P. Marco de software para modelar temas con grandes corporaciones // En Actas del Taller LREC 2010 sobre nuevos desafíos para marcos de PNL. - 2010.