Continúo cargando informes con Pixonic DevGAMM Talks, nuestra reunión de septiembre para desarrolladores de sistemas altamente cargados. Compartieron muchas experiencias y casos, y hoy publico una transcripción del discurso del desarrollador de back-end de Sabre Interactive Roman Rogozin. Habló sobre la práctica de aplicar el modelo de actor utilizando el ejemplo de la gestión de jugadores y sus estados (se pueden encontrar otros informes al final del artículo, la lista se complementa).
Nuestro equipo está trabajando en un back-end para el juego Quake Champions, y hablaré sobre cuál es el modelo de actor y cómo se usa en el proyecto.
Un poco sobre la pila de tecnología. Escribimos código en C #, respectivamente, todas las tecnologías están vinculadas a él. Quiero señalar que habrá algunas cosas específicas que mostraré en el ejemplo de este lenguaje, pero los principios generales permanecerán sin cambios.

Por el momento, alojamos nuestros servicios en Azure. Hay algunas primitivas muy interesantes que no queremos renunciar, como Table Storage y Cosmos DB (pero tratamos de no ponernos demasiado apretados por el bien del proyecto multiplataforma).
Ahora me gustaría contar un poco sobre qué es un modelo de actor. Y para empezar, apareció, como principio, hace más de 40 años.
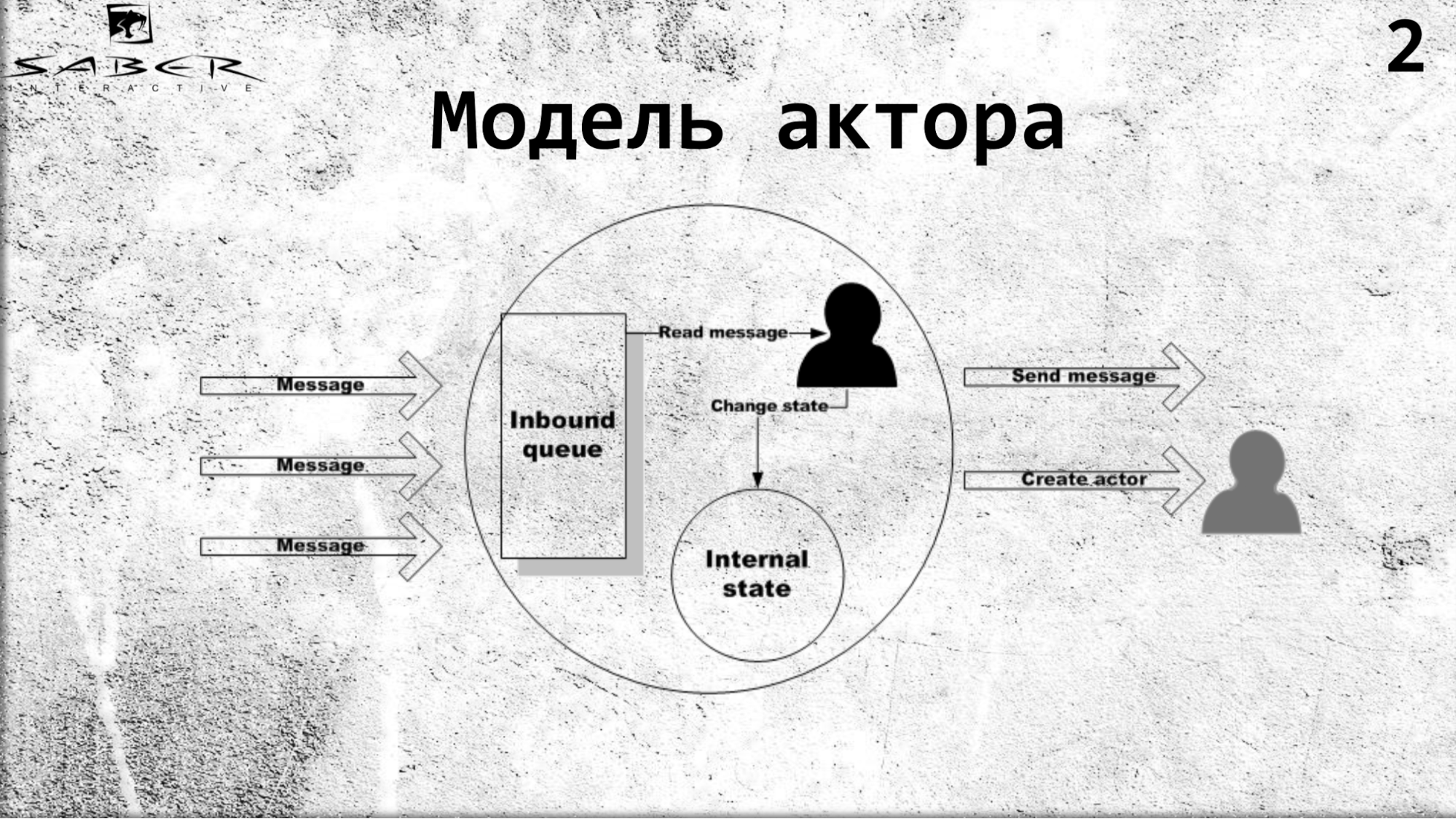
Un actor es un modelo de computación paralela que establece que hay un cierto objeto aislado que tiene su propio estado interno y acceso exclusivo para cambiar este estado. Un actor puede leer mensajes y, además, secuencialmente, ejecutar algún tipo de lógica de negocios, si quiere cambiar su estado interno, y enviar mensajes a servicios externos, incluidos otros actores. Y él sabe cómo crear otros actores.
Los actores se comunican entre sí de forma asíncrona, lo que le permite crear sistemas de nube distribuidos altamente cargados. En este sentido, el modelo de actor ha sido ampliamente utilizado recientemente.
Resumiendo un poco, imaginemos que tenemos una nube donde hay algún tipo de clúster de servidores, y nuestros actores están girando en este clúster.
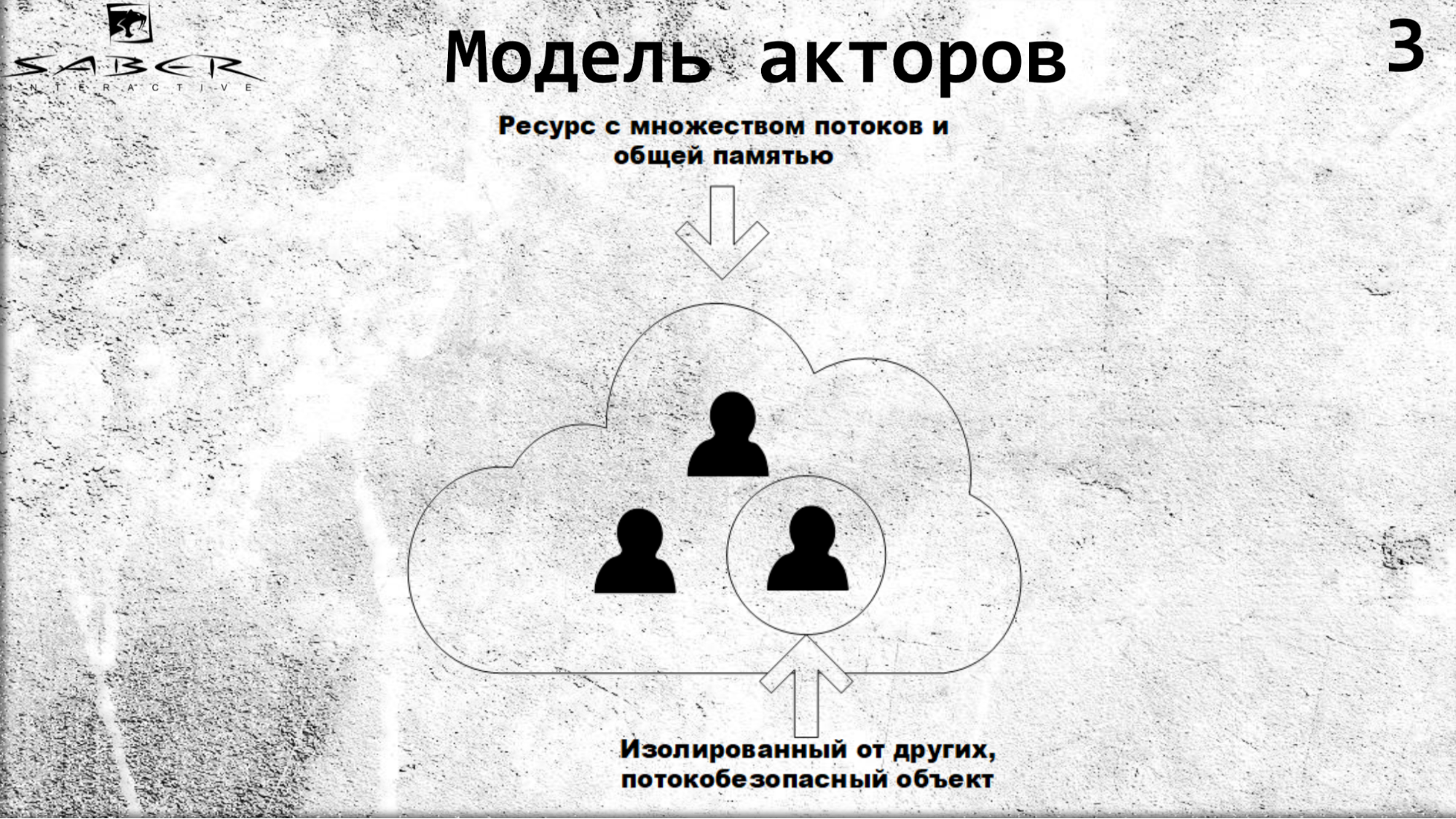
Los actores están aislados unos de otros, se comunican a través de llamadas asincrónicas, y dentro de sí mismos, los actores son seguros para los hilos.
Cómo podría ser. Supongamos que tenemos varios usuarios (no una carga muy grande), y en algún momento entendemos que hay una afluencia de jugadores, y necesitamos urgentemente hacer una mejora.
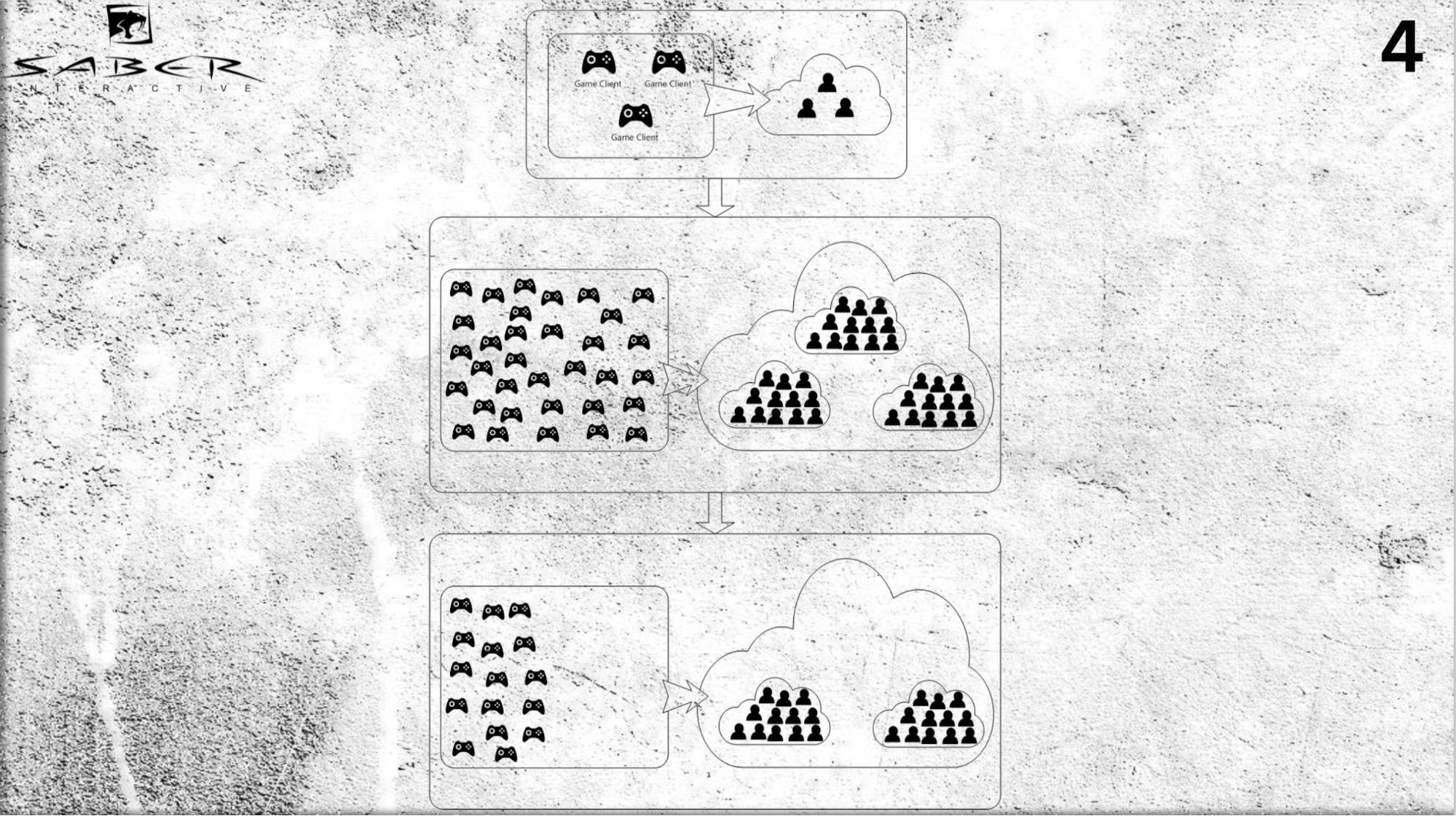
Podemos agregar servidores a nuestra nube y, utilizando el modelo de actor, impulsar a los usuarios individuales: asignar a cada actor individual y asignar espacio para la memoria y el tiempo de procesador para este actor en la nube.
Por lo tanto, el actor, en primer lugar, desempeña el papel de un caché y, en segundo lugar, es un "caché inteligente", que puede procesar algunos mensajes y ejecutar la lógica empresarial. Nuevamente, si necesita hacer una reducción de escala (por ejemplo, los jugadores se han ido), tampoco hay ningún problema para eliminar a estos actores del sistema.
En el backend no utilizamos el modelo de actor clásico, sino que se basa en el marco de Orleans. ¿Cuál es la diferencia? Intentaré decírtelo ahora.

Primero, Orleans introduce el concepto de actor virtual o, como también se le llama, granulado. A diferencia del modelo de actor clásico, donde un servicio es responsable de crear este actor y colocarlo en algunos de los servidores, Orleans se hace cargo del trabajo. Es decir si un determinado servicio de usuario solicita un cierto grado, Orleans comprenderá cuál de los servidores está ahora menos cargado, colocará al actor allí y devolverá el resultado al servicio de usuario.
Un ejemplo Para los granos, es importante conocer solo el tipo de actor, por ejemplo, estados de usuario e ID. Supongamos que la ID de usuario 777, obtenemos el grano de este usuario y no pensamos en cómo almacenar este grano, no controlamos el ciclo de vida del grano. Orleans, sin embargo, en sí misma mantiene el camino de todos los actores de una manera muy astuta. Si no hay actor, los crea, si el actor está vivo, lo devuelve, y para los servicios de usuario todo se ve para que todos los actores estén siempre vivos.
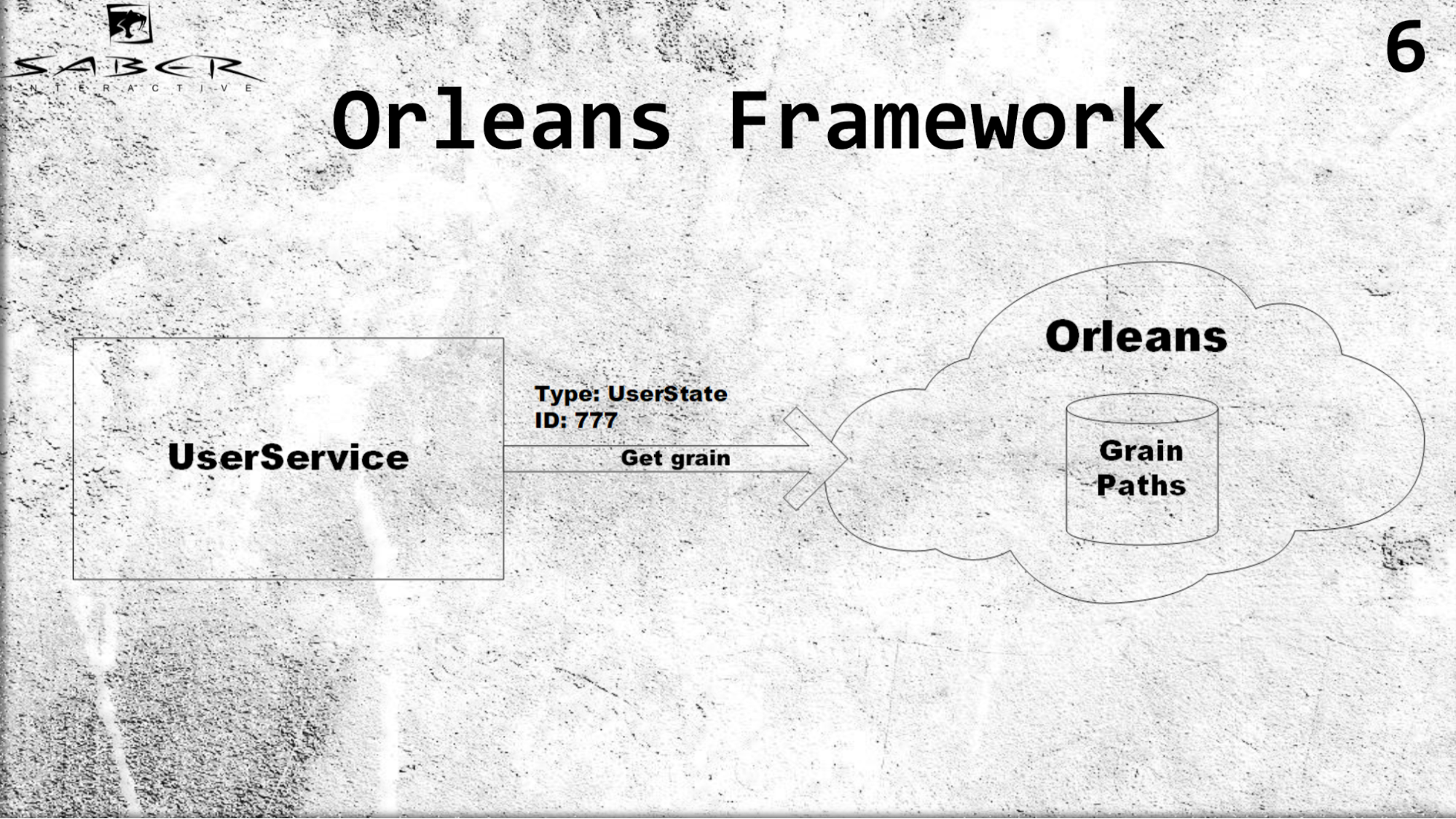
¿Qué beneficios nos brinda esto? En primer lugar, el equilibrio de carga transparente debido al hecho de que el programador no necesita gestionar la ubicación del propio actor. Simplemente dice Orleans, que se implementa en varios servidores: dame un actor de ese tipo desde tus servidores.
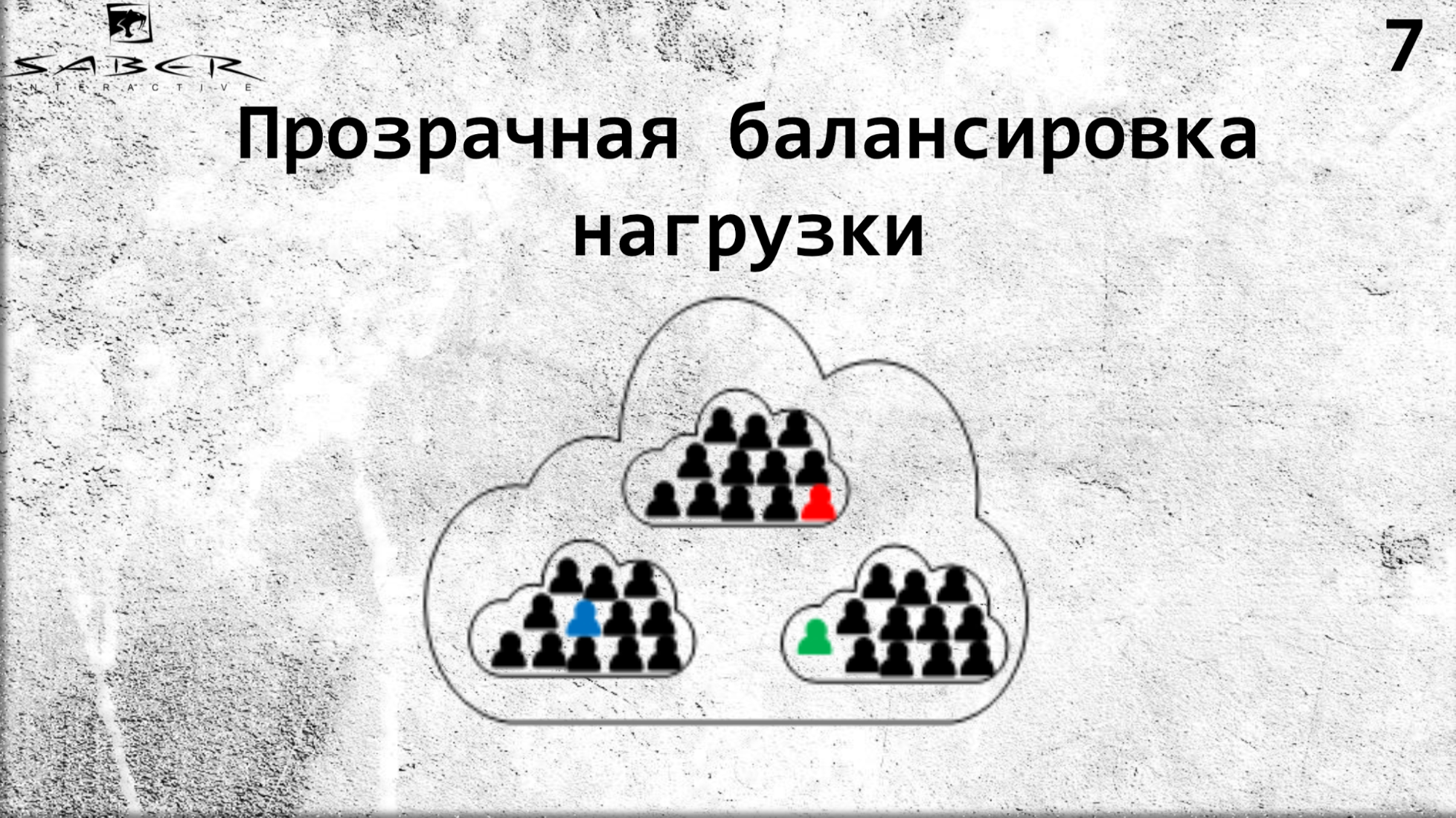
Si lo desea, puede reducir la escala si la carga en el procesador y la memoria es pequeña. Nuevamente, puede hacer la escala en la dirección opuesta. Pero el servicio no sabe nada sobre esto, pide el grano y Orleans le da ese grano. Por lo tanto, Orleans adquiere cuidados de infraestructura para el ciclo de vida de los granos.
En segundo lugar, Orleans maneja los bloqueos del servidor.

Esto significa que si en el modelo clásico el programador es responsable de manejar dicho caso por su cuenta (colocaron al actor en algún servidor, pero este servidor se bloqueó, y nosotros mismos debemos criar a este actor en uno de los servidores en vivo), lo que agrega más mecánica o trabajo de red complejo para un programador, luego en Orleans parece transparente. Solicitamos un grano, Orleans ve que no está disponible, lo recoge (lo coloca en algunos de los servidores activos) y lo devuelve al servicio.
Para que quede un poco más claro, echemos un vistazo a un pequeño ejemplo de cómo un usuario lee algo de su estado.
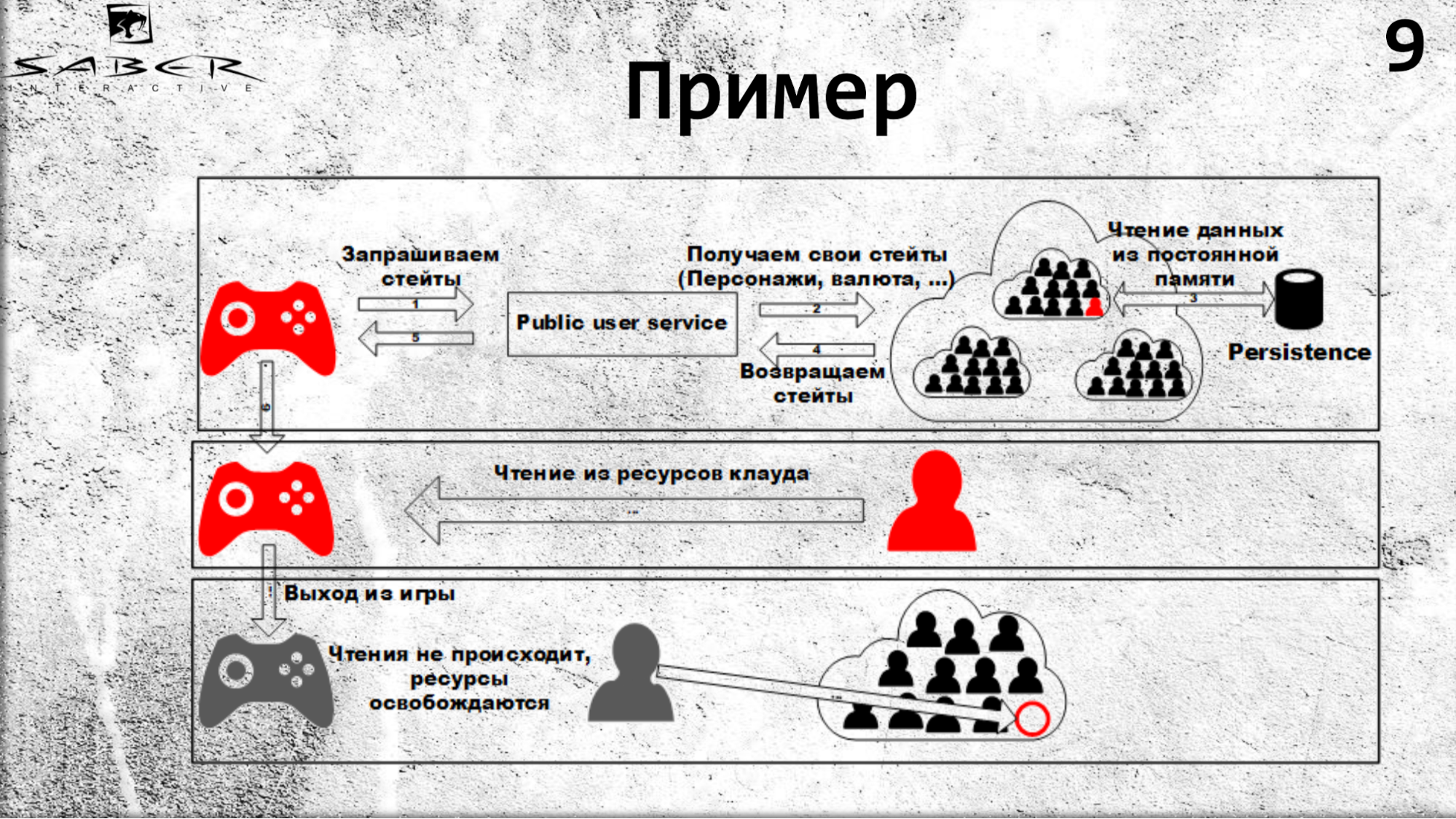
Un estado puede ser su condición económica, que almacena la armadura, las armas, la moneda o los campeones de ese usuario. Para obtener estos estados, llama al PublicUserService, que se dirige a Orleans para obtener el estado. Lo que está sucediendo: Orleans ve que todavía no existe tal actor (es decir, granulado), lo crea en un servidor gratuito y el granulado lee su estado en alguna tienda Persistence.
Por lo tanto, la próxima vez que lea recursos de la nube, como se muestra en la diapositiva, todas las lecturas provendrán de la memoria caché. En el caso de que el usuario abandone el juego, los recursos de lectura no se producen, por lo que Orleans entiende que el grano ya no es utilizado por nadie y puede desactivarse.
Si tenemos varios clientes (cliente de juego, servidor de juego), pueden solicitar estados de usuario, y uno de ellos aumentará este grano. Más precisamente, hará que Orleans lo recoja, y luego todas las llamadas, como ya sabemos, se producen secuencialmente en un hilo seguro. Primero, el cliente recibirá el estado y luego el servidor del juego.
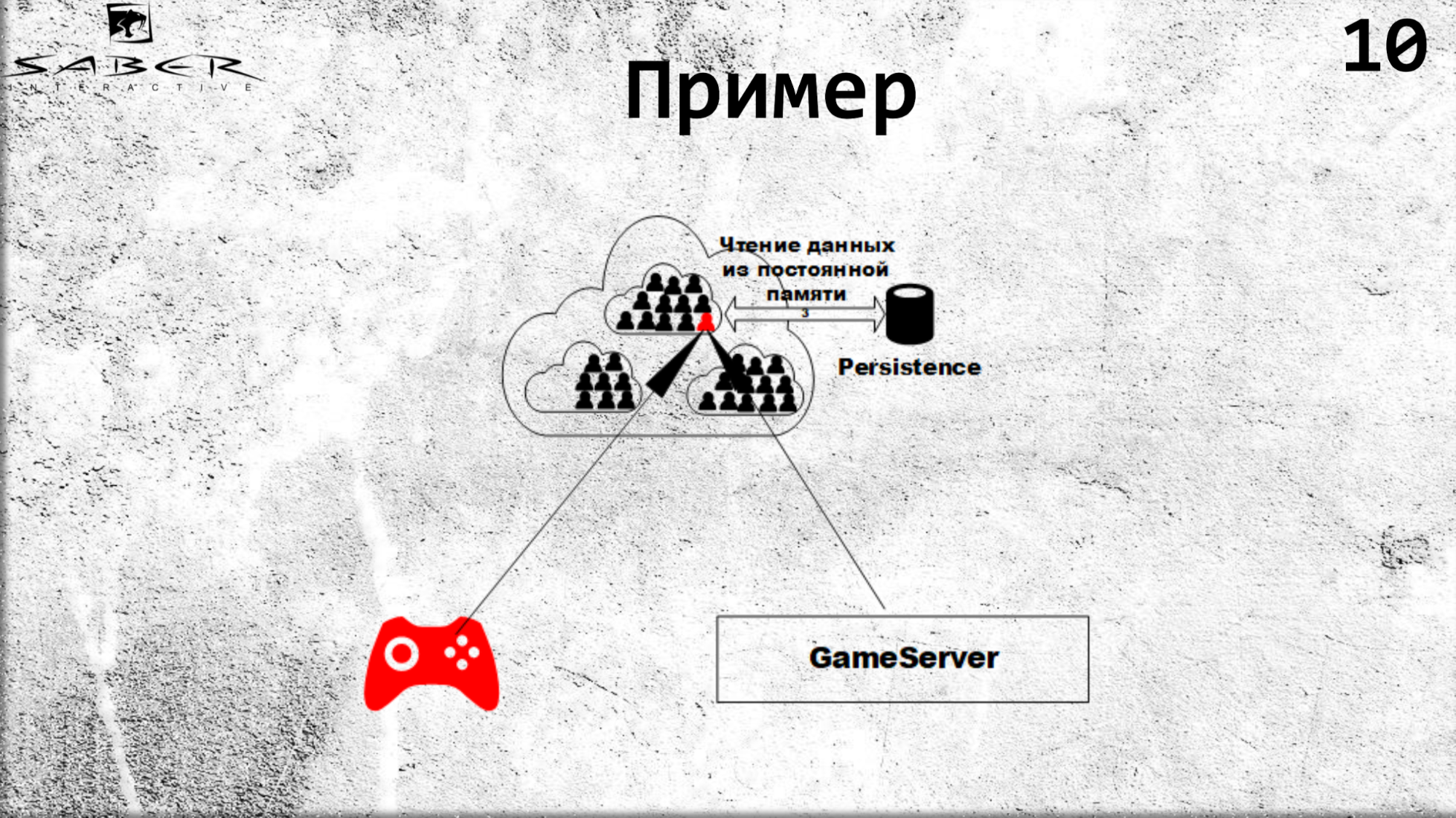
El mismo flujo en la actualización. Cuando un cliente desea actualizar un estado, transferirá esta responsabilidad al grano, es decir le dirá: "dale a este usuario 10 de oro", y el grano sube, procesa este estado con algún tipo de lógica de negocios dentro del grano. Y luego viene la actualización del caché de caché y, si lo desea, la persistencia en Persistencia.

¿Por qué se requiere persistencia aquí? Este es un tema separado y radica en el hecho de que a veces no es particularmente importante para nosotros que el grano mantenga constantemente sus estados en persistencia. Si este es el estado del jugador en línea, estamos listos para arriesgarnos a perderlo en aras de la productividad, si se trata de la economía, entonces debemos estar seguros de que sus estados están preservados.
El caso más simple: para cada llamada de estado de guardar, escriba esta actualización en Persistence. Por lo tanto, si el grayn cae repentinamente inesperadamente, el próximo aumento del grano en algunos de los otros servidores provocará una actualización de la memoria caché con los datos actuales.
Un pequeño ejemplo de cómo se ve.

Como ya dije, un grano consiste en un tipo y una clave (en este caso, el tipo es IPlayerState, la clave es IGrainWithGuidKey, lo que significa que es Guid). Y tenemos una interfaz que implementamos, es decir GetStates devuelve una lista de estados y ApplyState, que se aplica a algún estado. Los métodos de Orleans devuelven Tarea. Lo que esto significa: la tarea es una promesa que nos dice que cuando el estado regrese, la promesa estará en estado resuelto. También tenemos algunos PlayerState que obtenemos con GrainFactory. Es decir aquí obtenemos un enlace, y no sabemos nada sobre la ubicación física de este grano. Al llamar a GetStates, Orleans elevará nuestro graine, leerá el estado del almacén Persistence en su memoria, y cuando ApplyState aplicará un nuevo estado, también actualizará este estado tanto en su memoria como en Persistence.
Me gustaría ver un ejemplo un poco más complejo sobre la arquitectura de alto nivel de nuestro servicio UserStates.
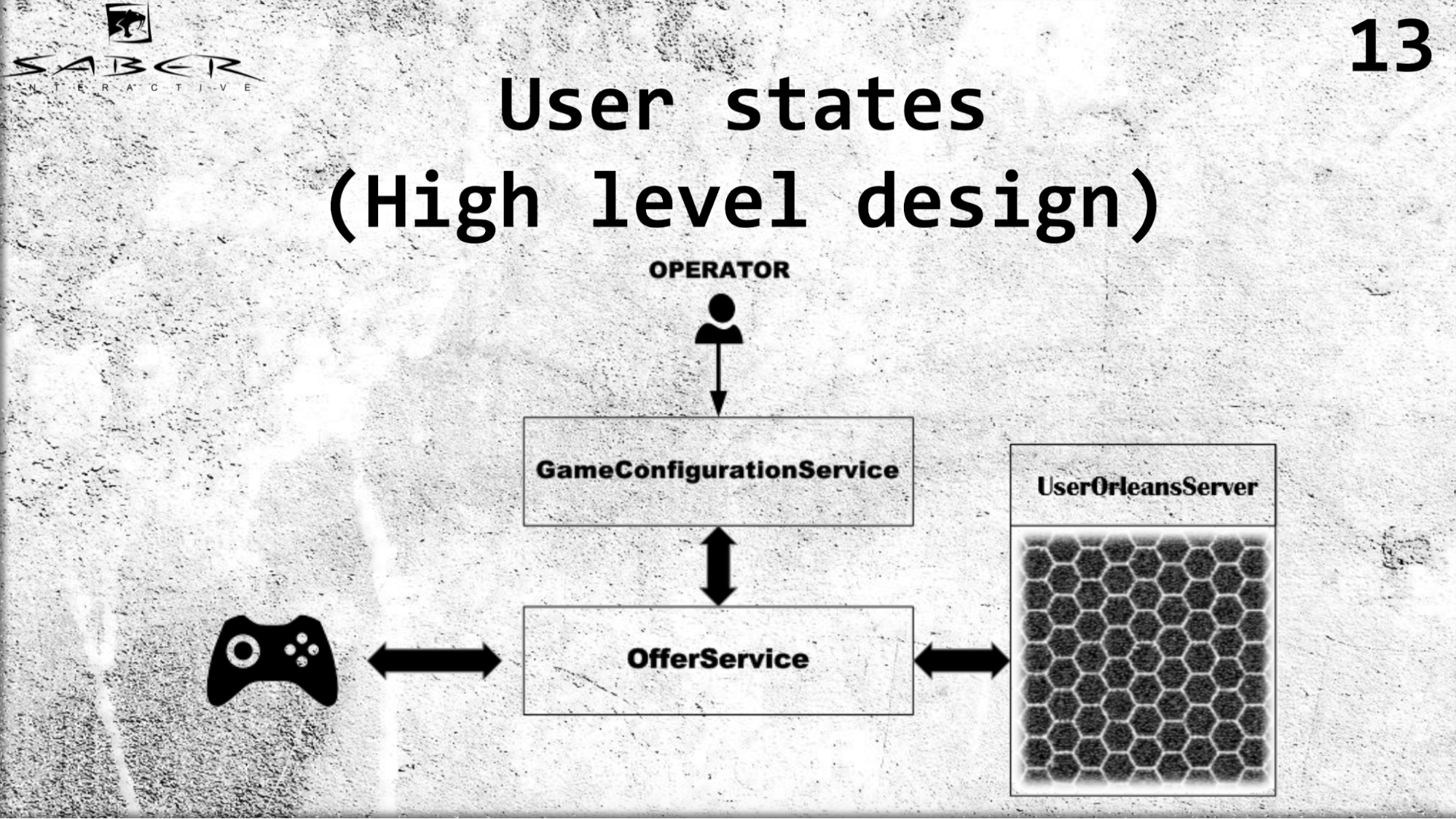
Tenemos algún tipo de cliente de juego que obtiene sus estados a través de OfferSevice. Tenemos un GameConfigurationService, responsable del modelo económico de un grupo de usuarios, en este caso, nuestro usuario. Y tenemos un operador que está cambiando este modelo económico. De acuerdo con esto, el usuario solicita un OfferSevice para recibir sus estados. Y OfferSevice ya está accediendo al servicio UserOrleans, que consiste en estos granos, eleva este estado del usuario en su memoria, posiblemente ejecuta algún tipo de lógica de negocios y devuelve los datos al usuario a través de OfferService.
En general, me gustaría llamar la atención sobre el hecho de que Orleans es buena por su alta capacidad de paralelismo debido al hecho de que los granos son independientes entre sí. Y, por otro lado, dentro del graine, no necesitamos usar primitivas de sincronización, porque sabemos que cada llamada a este graine será de alguna manera consistente.
Aquí me gustaría distinguir algunas de las trampas de este modelo.

El primero es demasiado granulado. Como todas las llamadas en greine son seguras para subprocesos, una tras otra, y si tenemos alguna lógica grasienta sobre la greine, tendremos que esperar demasiado. Nuevamente, se asigna demasiada memoria para uno de esos granos. No existe un algoritmo exacto sobre el tamaño del grano, porque un grano demasiado pequeño también es malo. Aquí es bastante necesario proceder desde el valor óptimo. No diré exactamente cuál, depende del programador decidir.
El segundo problema no es tan obvio: esta es la llamada reacción en cadena. Cuando un usuario levanta algunos granos, y él, a su vez, puede levantar implícitamente otros granos en el sistema. Cómo sucede esto: el usuario recibe sus estados, y el usuario tiene amigos y recibe el estado de sus amigos. Por lo tanto, todo el sistema mantiene todos sus granos en la memoria, y si tenemos 1000 usuarios y cada uno tiene 100 amigos, entonces 100,000 granos pueden estar activos así como así. Este caso también debe evitarse: de alguna manera, almacene los estados de amigos en algún tipo de memoria compartida.

Bueno, qué tecnologías existen para implementar el modelo de actor. Quizás el más famoso es Akka, que nos llegó con Java. Hay una bifurcación llamada Akka.NET para .NET. Está Orleans, que es de código abierto y está en otros idiomas, como implementación. Hay primitivas de Azure, como Service Fabric Actor, hay muchas tecnologías.
Preguntas de la audiencia
- ¿Cómo resuelve problemas clásicos como CICD, actualizando estos actores, utiliza Docker y es necesario?- No estamos usando docker todavía. En general, DevOps participa en la implementación; implementan nuestros servicios en el servicio en la nube de Azure.
- Actualización continua, sin tiempos de inactividad, ¿cómo sucede? Orleans mismo decide a qué servidor irá el servidor, a qué servidor irá la solicitud y cómo actualizar este servicio. Es decir Ha aparecido una nueva lógica de negocios, ha aparecido una actualización del mismo actor: ¿cómo se implementan estas actualizaciones?- Si estamos hablando de actualizar todo el servicio, y si hemos actualizado alguna lógica comercial del actor, podemos implementar un servicio de Nueva Orleans para ello. Por lo general, esto se resuelve con nuestras primitivas llamadas topología. Lanzamos un nuevo servicio de Orleans, que por ahora está, supongamos, vacío y sin un actor, muestra el antiguo servicio y lo reemplaza por uno nuevo. No habrá actores en el sistema, pero en la próxima solicitud del usuario, estos actores ya estarán creados. Probablemente habrá algún tipo de pico al principio. En tales casos, la actualización generalmente se realiza en la mañana, ya que en la mañana tenemos el menor número de jugadores.
"¿Cómo entiende Orleans que el servidor se ha bloqueado?" Dijiste que rápidamente arroja a los actores a otro servidor ...- Tiene un pingator que periódicamente entiende cuáles de los servidores están vivos.
- ¿Hace ping a un actor o servidor específicamente?- Específicamente, el servidor.
- Tal pregunta: se produjo un error dentro del actor, usted dice que va paso a paso, cada instrucción. Pero ocurrió un error y ¿qué le sucede al actor? Supongamos un error que no se procesa. ¿El actor se está muriendo?- No, Orleans lanza una excepción en el esquema estándar de .NET.
- Mira, no manejamos la excepción, el actor aparentemente murió. El jugador no sé cómo se verá, pero entonces, ¿qué pasa? ¿Estás tratando de reiniciar de alguna manera a este actor o hacer algo así?- Depende de qué caso depende de qué caso. Por ejemplo recuperable o no recuperable.
- I.e. ¿Es todo esto configurable?- Más bien, programado. Estamos manejando algunas excepciones. Es decir vemos claramente que dicho código de error, y algunos, como las excepciones no controladas, ya están más avanzados.
- ¿Tiene varias persistencias? ¿Es como una base de datos?- Persistencia, sí, una base de datos con almacenamiento persistente.
- Digamos que una base de datos ha establecido en qué (condicionalmente) dinero del juego. ¿Qué pasa si un actor no puede alcanzarla? ¿Cómo lo manejas?- Primero que nada, es almacenamiento. En este momento, estamos usando Azure Table Storage, y tales problemas realmente suceden: el almacenamiento se bloquea. Por lo general, en este caso, debe reconfigurarlo.
- Si el actor no pudo obtener algo en Almacenamiento, ¿cómo se ve el jugador? ¿Simplemente no tiene este dinero o cierra el juego inmediatamente?- Estos son cambios críticos para el usuario. Como cada servicio tiene su propia gravedad, en este caso, el servicio de usuario es un estado terminal y el cliente simplemente falla.
- Me pareció que los mensajes de los actores ocurren a través de colas asincrónicas. ¿Cómo es esta solución optimizada? ¿No se hincha, no hace que el jugador cuelgue? ¿No es mejor usar un enfoque reactivo?- El problema de las colas en los actores es bastante conocido, porque claramente no podemos controlar el tamaño de la cola, tienes razón. Pero Orleans, en primer lugar, asume algún tipo de trabajo de gestión y, en segundo lugar, creo que simplemente por el tiempo de espera se reducirá el acceso al actor, es decir. no podemos contactar al actor, por ejemplo.
- ¿Y cómo afectará esto al jugador?- Dado que el servicio de usuario contacta al actor, lanzará una excepción de tiempo de espera de excepción y, si es un servicio "crítico", el cliente arrojará un error y se cerrará. Y si es menos crítico, entonces esperará.
- I.e. ¿Tienes una amenaza DDoS? ¿Un gran número de pequeñas acciones pueden poner a un jugador? Digamos que alguien rápidamente comienza a invitar amigos, etc.- No, hay un limitador de solicitudes que no le permitirá acceder a los servicios con demasiada frecuencia.
- ¿Cómo manejas la consistencia de los datos? Supongamos que tenemos dos usuarios, necesitamos tomar algo de uno y cargar algo al otro, para que sea transaccional.Buena pregunta Primero, Orleans 2.0 admite la Transacción de actor distribuido: esta es la primera versión. Más precisamente, ya es necesario hablar sobre la economía. Y como la forma más fácil, en la última Orleans, las transacciones entre actores se implementan sin problemas.
- I.e. ¿Ya sabe cómo garantizar que los datos persistan en integridad?- si.
Más conversaciones con Pixonic DevGAMM Talks