"Algunas personas nos llaman" Plyushkins ". Me gusta decir que somos archiveros".
El director de Wayback Machine, Mark Graham, describe la escala del archivo favorito de todos
 Vea Wayback Machine en la Online News Association 2018Austin, Texas
Vea Wayback Machine en la Online News Association 2018Austin, Texas No importa cuánto los servicios de suscriptor no quieran convencerlo de esto, pero no todo se puede encontrar en Amazon o Netflix. ¿Quiere, por ejemplo,
leer el libro del juez Brett Cavanaugh (o incluso su
infame anual )? ¿Tienes curiosidad por ver un montón de
carteles publicitarios de fumar vintage ? ¿Qué tal ver
la colección más grande de literatura budista tibetana del mundo ? Hoy en día hay un lugar donde puede hacer todo esto, y no es Google o algunos sitios piratas que visita (a menudo).
"Tengo un video del gobierno sobre cómo lavarnos las manos o prepararnos para una guerra nuclear ", dice Mark Graham, director de Wayback Machine en Internet Archive. "Podríamos hacer fácilmente una lista de archivos .ppt en todos los sitios con el dominio .mil, Military Industrial PowerPoint Complex".
Graham habló recientemente con varios grupos pequeños de participantes en la conferencia Online News Association 2018 y Ars Technica tuvo la suerte de estar allí. Más tarde hizo una presentación completa de la conferencia, que ahora está
disponible en formato de audio . Y la idea básica es que la escala de Internet Archive hoy en día puede ser tan difícil de entender como la escala de Internet en sí.
El espacio físico sin fines de lucro sigue siendo fácil de entender, al menos eso es lo que Graham pretendía que fuera. Hoy, todas las actividades de Internet Archive se llevan a cabo desde una antigua iglesia (incluso los bancos no fueron retirados) en San Francisco por unas doscientas personas. El archivo también contiene el almacén más cercano para almacenar medios físicos, no solo libros, sino también cosas como discos de vinilo. Graham bromea diciendo que allí la unidad de medida principal es el "contenedor para la entrega". El archivo recibe esta cantidad de material cada dos semanas.
La compañía es actualmente el segundo escáner de libros más grande del mundo, después de Google. Graham se ha asegurado de que la cantidad actual de escaneos ascendiera a más de cuatro millones. El archivo incluso tiene una lista de deseos para sus próximos 1,5 millones de escaneos, incluido todo lo que se cita en Wikipedia. Wayback Machine está tratando de protegerlo de que aparezca un
error 404 al hacer clic en los enlaces de Wikipedia (Graham le dijo recientemente a la BBC que los bots de Wayback recuperaron casi seis millones de páginas que se perdieron debido a la falla del enlace). Hoy en día, los libros publicados antes de 1923 se pueden descargar de forma gratuita a través de Internet Archive, y luego puede pedir prestada una copia digital de muchos de estos libros.
Traducción de Tweet:
Archivo de Internet: Se corrigieron más de 9 millones de enlaces incorrectos de Wikipedia
WikiResearch: Estoy muy agradecido por el extraordinario trabajo que nuestros amigos de @internetarchive hacen para lidiar con el error 404 y guardar digitalmente millones de enlaces a sitios y fuentes citados por Wikipedia mientras crean la enciclopedia más grande del mundo.
Por supuesto, en estos días, Internet Archive ofrece mucho más que solo texto. Su colección de noticias cubre más de 1.6 millones de programas de noticias con herramientas como la capacidad de buscar palabras en subtítulos y acceder a las últimas noticias (las transmisiones están disponibles después de 24 horas y luego se proporcionan a los visitantes en forma de pasajes de búsqueda de dos minutos). La creciente porción de audio y música del Archivo de Internet cubre noticias de radio, podcasts y medios físicos (por ejemplo, una colección de
200,000 copias de los 78 recientemente donadas por la biblioteca de Boston). Y, como escribe Ars, la organización cuenta con
una extensa colección clásica de videojuegos que cualquiera puede subir a un emulador basado en navegador para fines de investigación u ocio. Oficialmente, esta sección incluye más de 300,000 títulos, "para que pueda jugar Oregon Trail en su vieja computadora Apple C en su navegador en este momento, sin anuncios, sin seguimiento de usuarios", dice Graham.
"Algunos pueden llamarnos Plyushkins", dice. "Me gusta decir que somos archiveros".
En general, Graham dice que se agregan cuatro petabytes de información por año al Archivo de Internet (es decir, cuatro millones de gigabytes por contexto). Los datos actuales de la organización son 22 petabytes, pero Internet Archive posee 44 petabytes. "Porque somos paranoicos", dice Graham. "Los automóviles pueden fallar, y tenemos una reputación". Este credo inspirado en la
NASA ayudó a una organización sin fines de lucro a sobrevivir al daño causado por el fuego, que
costó casi $ 600,000 , todo sin perder datos de archivo.
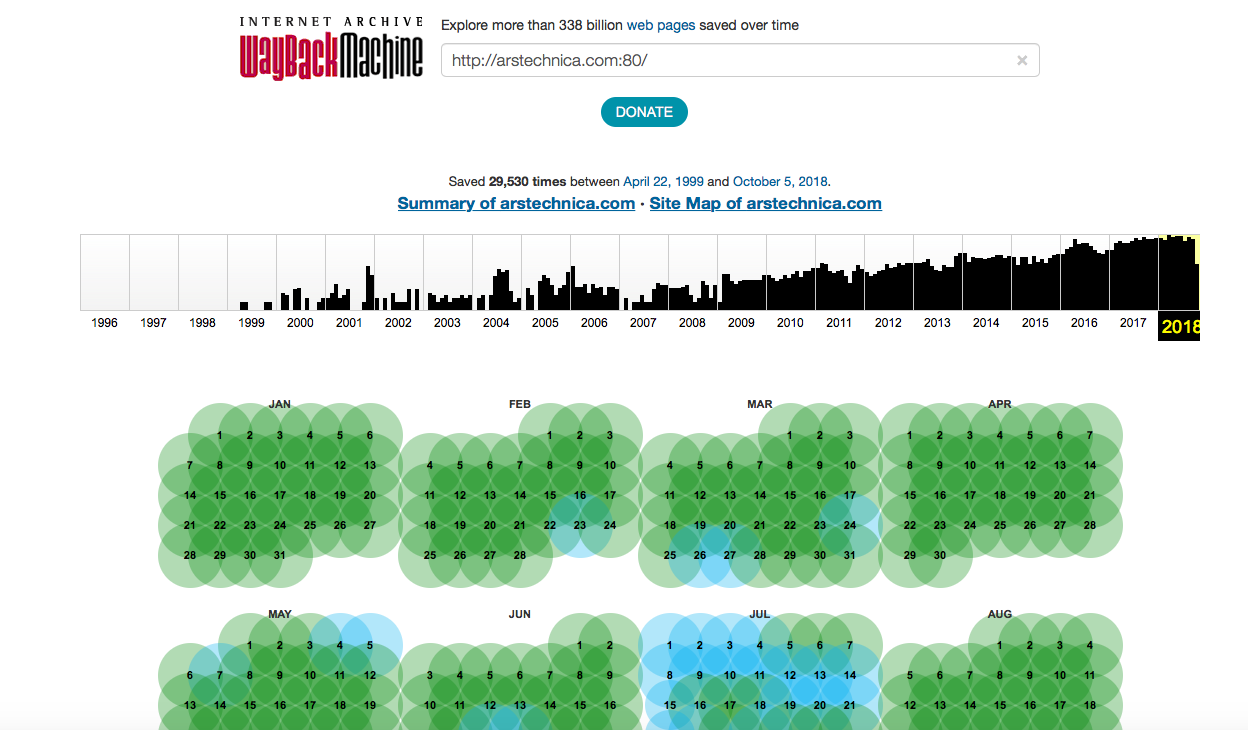 30,000 de entrada? No está mal, y parece que los robots de Wayback Machine ciertamente han aumentado su afecto por Ars.
30,000 de entrada? No está mal, y parece que los robots de Wayback Machine ciertamente han aumentado su afecto por Ars.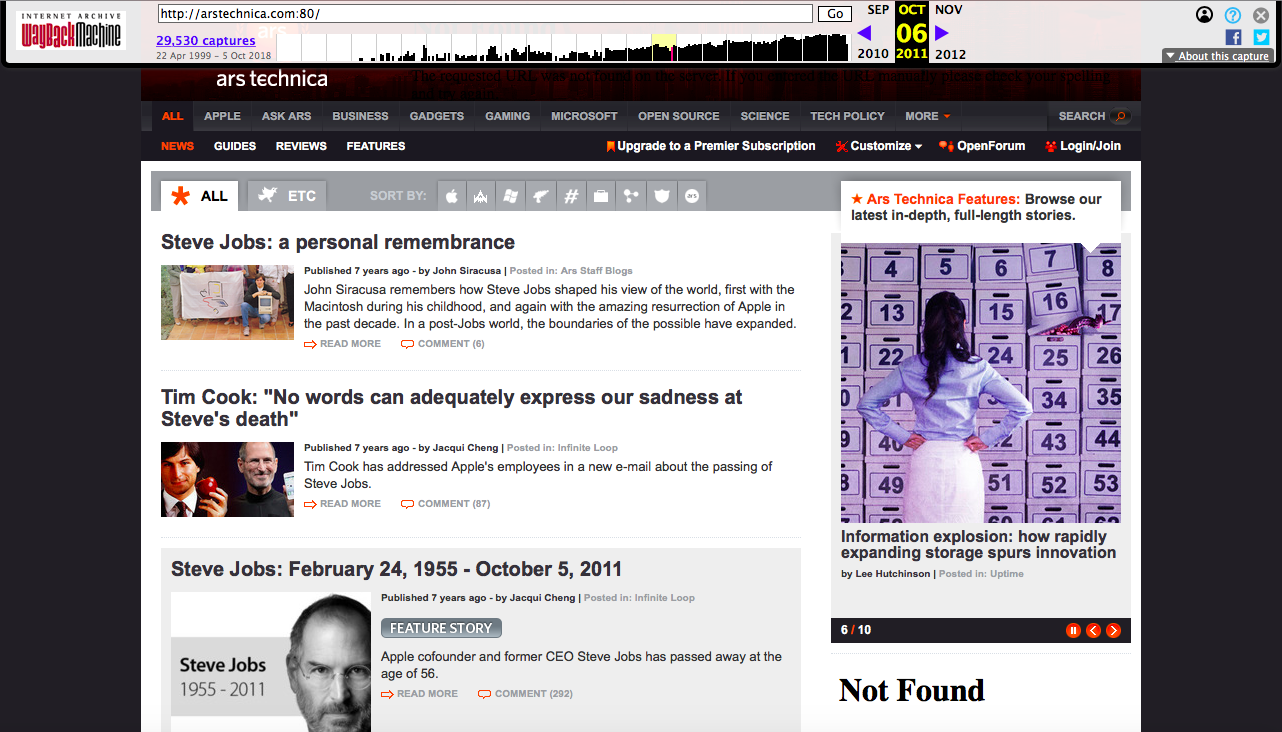 Con Wayback Machine, puedes recordar y pensar cómo Ars escondió la muerte de Steve Jobs en octubre de 2011.
Con Wayback Machine, puedes recordar y pensar cómo Ars escondió la muerte de Steve Jobs en octubre de 2011. Hmm ... tal vez todavía tengo la oportunidad de convertirme en Arsian / Arsian para descargar el PDF número 1000 capturado por Internet Archive.
Hmm ... tal vez todavía tengo la oportunidad de convertirme en Arsian / Arsian para descargar el PDF número 1000 capturado por Internet Archive.Acceso universal al conocimiento (y a los hechos, a una gran cantidad de hechos)
El concepto general de Internet Archive en los últimos 22 años ha sido simple:
"acceso universal a todo el conocimiento" . En la era de Internet, esto significa, por supuesto, la introducción de un pequeño ejército de bots, y Graham señala que Internet Archive siempre tiene un software que recopila contenido. Aproximadamente 7,000 procesos concurrentes abarcan toda la red para finalmente recibir 1,5 mil millones de artículos diferentes por semana. Algunas cosas, como la página de inicio de Google o The New York Times, se pueden ver muchas veces al día; otros se pueden ver con menos frecuencia.
"Estamos tratando de obtener todo, pero es difícil", señala Graham. "Incrustaciones, Javascripts, aplicaciones interactivas: no podemos obtener algunos de estos materiales, pero estamos trabajando en ello".
La memoria caché de las cosas en las que estamos trabajando incluye medios efímeros como los grupos públicos de Snapchat o Telegram, y Wayback Machine mantiene contactos locales en lugares donde algunos archivos o servidores de medios pueden estar en riesgo (Graham recientemente señala socios en Egipto, por ejemplo).
El resultado de todo esto es que Wayback Machine se ha convertido en algo mucho más útil que los divertidos viajes pasados a LiveJournals. Ars lo ha usado muchas veces para una variedad de propósitos, desde
capturar cambios en la neutralidad de la
red de Comcast hasta el hecho de que la descripción organizacional de Distributed Defense ha evolucionado. Y Graham señala una
controversia reciente
en 2018 , cuando el presidente Trump tuiteó que Google no está promoviendo buenas relaciones con los Estados Unidos de América en su página de inicio (como lo fue en el pasado). Antes de que Google pudiera responder esto, la compañía recurrió a Internet Archive con una simple pregunta: ¿hay una copia?
"Me encanta Google, pero su trabajo no es hacer copias de la página de inicio cada 10 minutos", dice Graham. "Este es nuestro trabajo".
Graham compartió que Wayback Machine incautó 835 copias de la página de inicio de Google en enero de 2018. “De esta manera, pudimos ayudar a recoger los registros. No estamos tomando partido, pero estamos a favor de la verdad ".
El sitio desempeñó un papel similar cuando la Casa Blanca
eliminó recientemente
todos los archivos de sus boletines , y varias organizaciones (no solo organizaciones de noticias, sino también organizaciones medioambientales o ACLU) los necesitaban. Y los materiales obtenidos de Wayback Machine
se usaron como evidencia en la corte . "Hay muchos eventos que suceden en términos de tiempo", agrega. Como ex vicepresidente de NBC News (de ahí su deseo de asistir a la ONA, tal vez), Graham también señala con orgullo que los medios hacen referencia al sitio aproximadamente cinco veces al día.
Graham dice que Wayback Machine está trabajando duro para mejorar sus herramientas de usuario para mejorar el sitio. En la parte inferior izquierda de la página de inicio de Wayback Machine, encontrará, por ejemplo,
API públicas . Graham señala que las personas los usan para crear cosas como un
diferenciador , donde puede tomar dos escaneos, colocarlos uno al lado del otro y ver los cambios. Otra herramienta creada por el usuario, que atrajo su atención, le permite mirar el sitio y hacer un
diagrama de árbol radial para ver cómo cambia su estructura con el tiempo .
Aunque quizás la herramienta más fácil y efectiva para todos es la tecnología directamente de Wayback Machine: el sitio permite que alguien envíe manualmente un enlace al Internet Archive para archivarlo directamente desde su página de inicio. “Si camino a mi gato en el jardín y veo una historia en Google News, puedes imprimirla. Pero hoy también puede enviarlo a Internet Archive ”, dice Graham. Según sus estimaciones, el resultado puede ser de aproximadamente un millón de disparos por semana.
"Buscamos información en una red realmente grande sin hacer trampa", dice. E independientemente de si los bots o un usuario aficionado dedicado del archivo encuentran algo, todos los demás pueden apreciar la capacidad de encontrar contenido, que por cierto es la
misión original de Ars Technica . (Afortunadamente, después de 20 años, nadie nos ha informado aún de "
cosas muy malas como NT, Linux y contenido de BeOS bajo un mismo techo").
Traducción: Diana Sheremyova

Sobre #philtech#philtech (tecnologías + filantropía) son
tecnologías abiertas, descritas públicamente, que nivelan el nivel de vida de tantas personas como sea posible mediante la creación de plataformas transparentes para la interacción y el acceso a datos y conocimiento. Y satisfaciendo los principios de filtech:
1. Abierto y replicado, no competitivo de propiedad.
2. Construido sobre los principios de autoorganización e interacción horizontal.
3. Sostenible y orientado a la perspectiva, en lugar de buscar beneficios locales.
4. Basado en datos [abiertos], no en tradiciones y creencias
5. No violento y no manipulador.
6. Inclusivo, y no funciona para un grupo de personas a expensas de otros.
PhilTech Accelerator de Social Technology Startups es un programa para el desarrollo intensivo de proyectos en etapas tempranas destinados a igualar el acceso a la información, los recursos y las oportunidades. La segunda transmisión: marzo - junio de 2018.
Chat en TelegramUna comunidad de personas que desarrollan proyectos filtech o simplemente interesados en el tema de la tecnología para el sector social.
#filtech newsCanal de Telegram con noticias sobre proyectos en la ideología #philtech y enlaces a materiales útiles.
Suscríbase al boletín semanal