El comando de velocidad Yandex optimiza manualmente los resultados de búsqueda. Hacerlo a ciegas es difícil y, a menudo, simplemente inútil. Por lo tanto, la compañía construyó una infraestructura para recopilar métricas, probar la velocidad y analizar los datos.
Acerca de qué métricas deben usarse y cómo optimizar todo, el desarrollador de las interfaces de Yandex
Andrei Prokopyuk (
Andre_487 ) lo
sabe .

El material se basa en el discurso de Andrey en la conferencia
HolyJS . Debajo del corte - y video, y una versión de texto del informe.
Además de este informe sobre mediciones en línea, hay un informe de Alexei Kalmakov (también de Yandex) sobre mediciones fuera de línea, en su caso no hay una versión de texto, pero hay un video disponible.
Los resultados de búsqueda de Yandex consisten en muchos bloques diferentes, clases de respuestas a las consultas de los usuarios. Más de 50 personas trabajan en ellos en la empresa, y para que la tasa de emisión no disminuya, cuidamos constantemente el desarrollo.
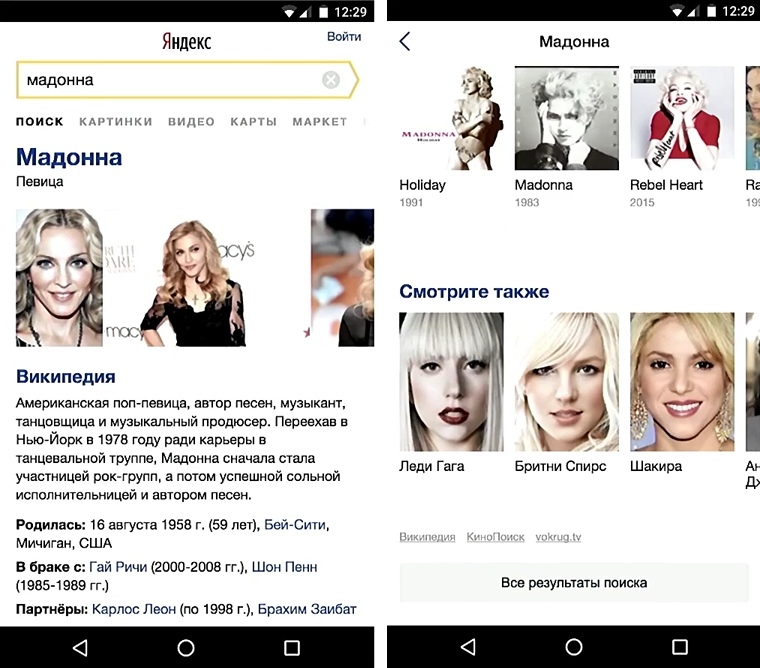
Nadie discutirá que a los usuarios les gusta más la interfaz rápida que la lenta. Pero antes de comenzar a optimizar, es importante comprender cómo afectará esto a su negocio. ¿Los desarrolladores necesitan pasar tiempo acelerando la interfaz si esto no afecta las métricas comerciales?
Para responder a esta pregunta, contaré dos historias.
Historia de la introducción de una fuente web específica en la emisión
Después de establecer un experimento con las fuentes, descubrimos que el tiempo promedio para procesar el contenido se deterioró en un 3%, en 62 milisegundos. No tanto si lo tomas como un delta en el vacío. El retraso notable a simple vista comienza con solo 100 milisegundos, y sin embargo, el tiempo hasta el primer clic aumentó de inmediato en un uno y medio por ciento.

Los usuarios comenzaron a interactuar más tarde con la página. La cantidad de páginas en las que se hizo clic disminuyó en casi medio por ciento. Se redujo el tiempo de presencia en el servicio y se aumentó el tiempo de ausencia.

No comenzamos a implementar la función con fuentes. Después de todo, estos números parecen pequeños hasta que recuerdas la escala del servicio. En realidad, uno y medio por ciento: cientos de miles de personas.
Además, la velocidad tiene un efecto acumulativo. Para una actualización con una participación de no reclamada: 0.4% seguirá más y más. En Yandex, tales características se implementan en docenas por día, y si no lucha por cada acción, no durará mucho y alcanzará el 10%.
Historial de almacenamiento en caché de LS
Esta historia está relacionada con el hecho de que incorporamos una gran cantidad de contenido estático en la página.
Debido a su alta variabilidad, no podemos compilarlo en un solo paquete o entregarlo con recursos externos. La práctica ha demostrado que con la entrega en línea, la representación e inicialización de JavaScript es la más rápida.
Una vez que decidimos que usar un repositorio del navegador sería una buena idea. Ponga todo en localStorage y, en las entradas posteriores a la página, cárguelo desde allí y no lo transmita a través de la red.
Luego nos centramos principalmente en las métricas "tamaño HTML" y "tiempo de entrega HTML" y obtuvimos buenos resultados en ellas. A medida que pasó el tiempo, inventamos nuevos métodos para medir la velocidad, adquirimos experiencia y decidimos hacer una doble verificación, realizar un experimento inverso y desactivar la optimización.

El tiempo promedio de entrega de HTML (la métrica clave en el momento del desarrollo de la optimización) aumentó en un 12%, que es mucho. Pero al mismo tiempo, el tiempo hasta que se dibujó el encabezado, antes de que comenzara el análisis del contenido y antes de que se inicializara JavaScript. También redujo el tiempo hasta el primer clic. El porcentaje es pequeño: 0.6, pero si recuerda la escala ...

Al deshabilitar la optimización, obtuvimos un empeoramiento en la métrica, notable solo para los especialistas, y al mismo tiempo, una mejora notable para el usuario.
Se pueden extraer las siguientes conclusiones de esto:
Primero, la velocidad realmente afecta los negocios y las métricas comerciales.
En segundo lugar, las optimizaciones deben ir precedidas de mediciones. Si implementa algo, después de haber realizado malas mediciones, es probable que no haga nada útil. La composición de la audiencia, la flota de dispositivos, los escenarios de interacción y las redes son diferentes en todas partes, y debe verificar qué funcionará exactamente para usted.
Una vez, Ash nos enseñó de los muertos siniestros primero a disparar, luego a pensar o no pensar en absoluto. En velocidad, no tienes que hacer esto.
Y el tercer punto: las mediciones deben reflejar la experiencia del usuario. Por ejemplo, el tamaño HTML y el tiempo de entrega son métricas de baja velocidad porque el usuario no se sienta con devTools y no selecciona un servicio con menos retraso. Pero qué métricas son buenas y correctas, le diremos más.
¿Qué y cómo medir?
Las mediciones deben comenzar con algunas métricas clave que, a diferencia, por ejemplo, el tamaño HTML, están cerca de la experiencia del usuario.

Si TTFCP (tiempo para la primera pintura con contenido) y TTFMP (tiempo para la primera pintura con sentido) indican el tiempo hasta la primera representación del contenido y el tiempo antes de la representación del contenido significativo, entonces el tercero es el tiempo antes de que se inicialice el marco, vale la pena explicarlo.
Este es el momento en que el marco ya pasó por la página, recopiló todos los datos necesarios y colgó los controladores. Si el usuario hace clic en algún lugar en ese momento, recibirá una respuesta dinámica.
Y la última, cuarta métrica, el tiempo hasta la primera interactividad, generalmente se conoce como tiempo de interacción (TTI).
Estas métricas, a diferencia del tamaño html o el tiempo de entrega, están cerca de la experiencia del usuario.
Tiempo para la primera pintura completa
Para medir el momento en que el usuario vio el primer contenido en la página, hay una API de sincronización de pintura, hasta ahora solo disponible en cromo. Los datos de él se pueden obtener de la siguiente manera.

Con esta llamada, obtenemos un conjunto de eventos de representación. Hasta ahora se admiten dos tipos de eventos: primera pintura, cualquier representación y primera pintura con contenido, cualquier representación de contenido que no sea el fondo blanco de la pestaña vacía y el contenido de fondo de la página.
Entonces obtenemos una variedad de eventos, filtramos la pintura de primer contenido y enviamos con una determinada ID.
Tiempo para la primera pintura significativa
No hay ningún evento en la API Paint Timing que indique que se haya presentado contenido significativo en la página. Esto se debe al hecho de que dicho contenido en cada página es diferente. Si hablamos del servicio de video, entonces lo principal es el reproductor, en los resultados de búsqueda, el primer resultado no publicitario. Hay muchos servicios y aún no se ha desarrollado una API universal. Pero aquí entran en juego muletas probadas y buenas.
Hay dos escuelas de muletas en Yandex para medir esta métrica: usar RequestAnimationFrame y medir con InterceptionObserver.
En RequestAnimationFrame, la representación se mide utilizando un intervalo.

Supongamos que hay un contenido significativo. Aquí hay un div con clase main-content. Se coloca un script delante de él, donde RequestAnimationFrame se llama dos veces.
En la devolución de llamada de la primera llamada, escriba el límite inferior del intervalo. En la devolución de llamada de la segunda - la parte superior. Esto se debe a la estructura del marco que representa el navegador.

El primero es la ejecución de JavaScript, luego el análisis de estilos, luego el cálculo del diseño, la representación y la composición.
La devolución de llamada, llamando a RequestAnimationFrame, se activa en la misma etapa que JavaScript, y el contenido se representa en la última sección del marco durante la composición. Por lo tanto, en la primera llamada, solo obtenemos el límite inferior, notablemente eliminado a tiempo de la salida de píxeles en la pantalla.
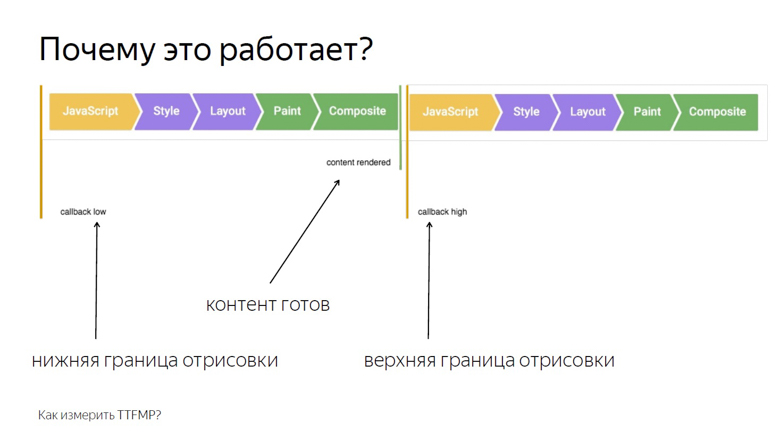
Coloque dos cuadros uno al lado del otro. Se puede ver que al final del primero de ellos el contenido fue procesado. Escribimos el borde inferior de RequestAnimationFrame, llamado dentro de la primera devolución de llamada, y la devolución de llamada en el segundo marco. Por lo tanto, obtenemos el intervalo de JavaScript llamado en el marco donde el contenido se procesó en JavaScript en el segundo marco.
Interceptor Observador
Nuestra segunda muleta con el mismo contenido funciona de manera diferente. Esta vez el guión se coloca a continuación. En él creamos InterceptionObserver y nos suscribimos a domNode.

No pasamos parámetros adicionales, por lo que medimos su intersección con la ventana gráfica. Este tiempo se registra como el tiempo exacto de renderizado.
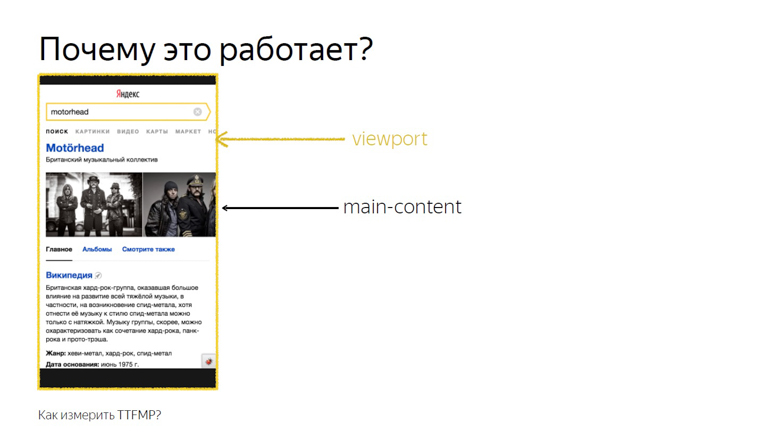
Esto funciona porque la intersección del contenido principal y la ventana gráfica es la intersección exacta que ve el usuario. Esta API fue diseñada para saber exactamente cuándo un usuario vio un anuncio, pero nuestra investigación ha demostrado que esto también funciona en unidades que no son de anuncios.
De estos dos métodos, aún es mejor usar RequestAnimationFrame: su soporte es más amplio y nosotros lo probamos mejor en la práctica.
Js iniciado
Imagine un marco que tenga algún tipo de evento "init" al que pueda suscribirse, pero recuerde que en la práctica JS Inited es una métrica simple y compleja.

Simple: porque solo necesita encontrar el momento en que el marco ha terminado la disposición de los eventos. Complejo: porque debe buscar este punto por su cuenta para cada marco.
Hora de interactuar
TTI a menudo se confunde con la métrica anterior, pero de hecho es un indicador del momento en que se libera la transmisión principal del navegador. Durante la carga de la página, se realizan muchas tareas: desde la representación de varios elementos hasta la inicialización del marco. Solo cuando está descargado llega el momento de la primera interactividad.
El concepto de tareas largas y la API de tareas largas ayuda a medir esto.
Primero sobre las tareas largas.

Entre las tareas cortas indicadas por flechas, el navegador puede obstaculizar fácilmente el procesamiento de un evento de usuario, por ejemplo, entrada, porque tiene una alta prioridad. Pero con las tareas largas indicadas por las flechas rojas, esto no funcionará.
El usuario tendrá que esperar hasta que se agote, y solo después de que el navegador procese su entrada. Al mismo tiempo, el marco ya se puede inicializar y los botones funcionarán, pero lentamente. Tal respuesta diferida es una experiencia de usuario bastante desagradable. En el momento en que se completa la última Tarea larga y el subproceso está vacío durante mucho tiempo, la ilustración aparece en 7 segundos y 300 milisegundos.
¿Cómo medir este intervalo dentro de JavaScript?

El primer paso se designa condicionalmente como la etiqueta del cuerpo de apertura, después de lo cual viene el script. Esto crea un PerformanceObserver que se suscribe al evento Long Task. Dentro de la devolución de llamada PerformanceObserver, la información del evento se recopila en una matriz.

Después de recopilar los datos, llega el momento del segundo paso. Se designa condicionalmente como una etiqueta de cuerpo de cierre. Tomamos el último elemento de la matriz, la última tarea larga, observamos el momento de su finalización y verificamos si ha pasado suficiente tiempo.
En el trabajo original sobre esta métrica, se tomaron 5 segundos como una constante, pero la elección no se confirmó de ninguna manera. Resultó ser suficiente por 3 segundos. Si pasan 3 segundos, contamos el tiempo hasta la primera interactividad; de lo contrario, configuramos Timeout y verificamos esta constante nuevamente.
¿Cómo procesar los datos?
Los datos deben recibirse de los clientes, procesarse y presentarse de manera conveniente. Nuestro concepto de envío de datos es bastante simple. Se llama un contador.
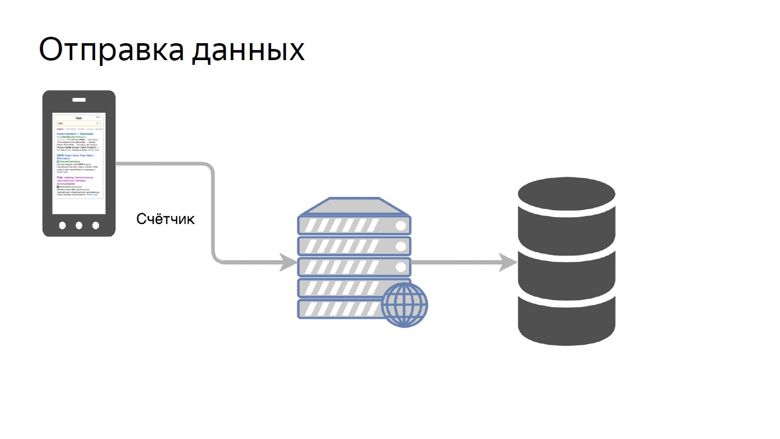
Transferimos los datos de una determinada métrica a un bolígrafo especial en el backend y los recopilamos en el repositorio.

Aquí, la agregación de datos se designa convencionalmente como una consulta SQL. Estas son las principales agregaciones que generalmente consideramos por métricas de velocidad: media aritmética y grupo de percentiles (50, 75, 95, 99).

El promedio aritmético en nuestra serie numérica es casi 1900. Es notablemente más grande que la mayoría de los elementos del conjunto, porque esta agregación es muy sensible a los valores atípicos. Esta propiedad sigue siendo útil para nosotros.

Para calcular los percentiles para el mismo conjunto, ordénelo y coloque el puntero en el índice de percentil. Digamos el 50, que también se llama la mediana. Caemos entre los elementos. En este caso, puede salir de la situación de diferentes maneras, calculamos el promedio entre ellos. Obtenemos 150. Cuando se compara con el promedio aritmético, se ve claramente que los percentiles son insensibles a los valores atípicos.
Tenemos en cuenta y usamos estas características de agregaciones. La sensibilidad aritmética de las emisiones es un inconveniente si intenta evaluar la experiencia del usuario con ella. De hecho, un usuario siempre puede conectarse a la red, por ejemplo, desde un tren, y estropear la selección.
Pero la misma sensibilidad es una ventaja cuando se trata de monitoreo. Para no perder un problema importante, utilizamos la media aritmética. Cambia fácilmente, pero el riesgo de un falso positivo en este caso no es un problema tan grande. Es mejor pasar por alto que pasar por alto.

Además, consideramos la mediana (si adjuntamos esto a las métricas de tiempo, la mediana es un indicador del momento en que se ajusta el 50% de las solicitudes) y el percentil 75. El 75% de las solicitudes se ajustan en este momento, lo tomamos como una estimación de la velocidad general. Se considera que los percentiles 95 y 99 miden la cola larga y lenta. Estos son números muy grandes. El número 95 se considera la solicitud más lenta. El percentil 99 es anormal.
No tiene sentido contar el máximo. Este es el camino a la locura. Después de calcular el máximo, puede resultar que el usuario haya estado esperando que la página se cargue durante 20 años.
Habiendo considerado las agregaciones, solo queda aplicar estos números, y lo más obvio que se puede hacer con ellos es presentarlos en gráficos.
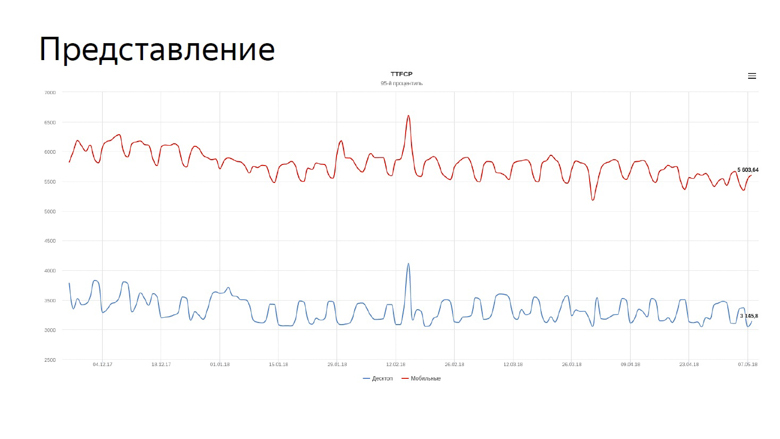
En el gráfico, nuestro tiempo real para las primeras métricas de pintura con contenido para la búsqueda. La línea azul refleja la dinámica de los equipos de escritorio, la roja, para dispositivos móviles.
Tenemos que monitorear constantemente los gráficos de velocidad, y confiamos esta tarea al robot.
Monitoreo
Dado que las métricas de velocidad son volátiles y fluctúan constantemente con diferentes períodos, la supervisión debe ajustarse. Para esto usamos el concepto de frustraciones.
La depuración es el momento en que un proceso aleatorio cambia sus características, como la varianza o la expectativa matemática. En nuestro caso, esta es la muestra promedio. Como se mencionó, la media es sensible a las emisiones y adecuada para el monitoreo.
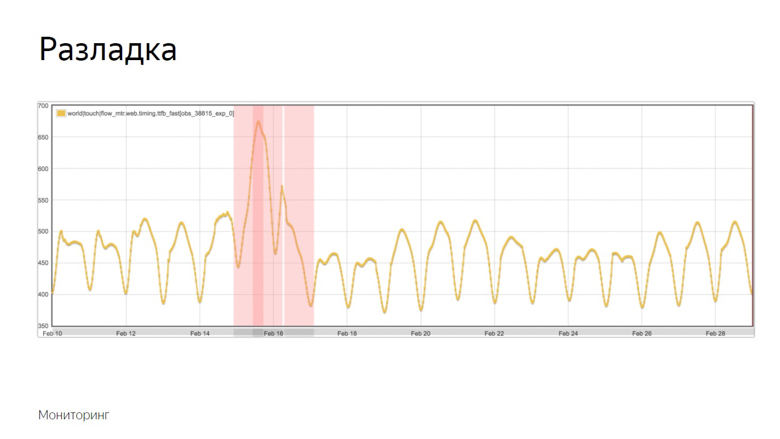
Aquí hay un ejemplo de un gráfico donde ocurrió la alineación y el robot registró el incidente. ¿Cómo aisló este momento de una serie de otras dudas? Para entender esto, imponemos datos adicionales.

El gráfico amarillo es un indicador métrico, y el gráfico azul es un promedio móvil con un período suficientemente grande. El rojo es la media más tres desviaciones estándar. El verde es el mismo, solo que con un signo menos.
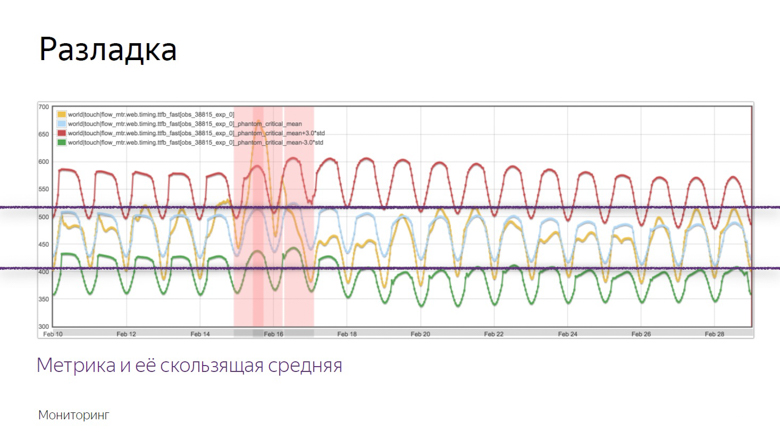
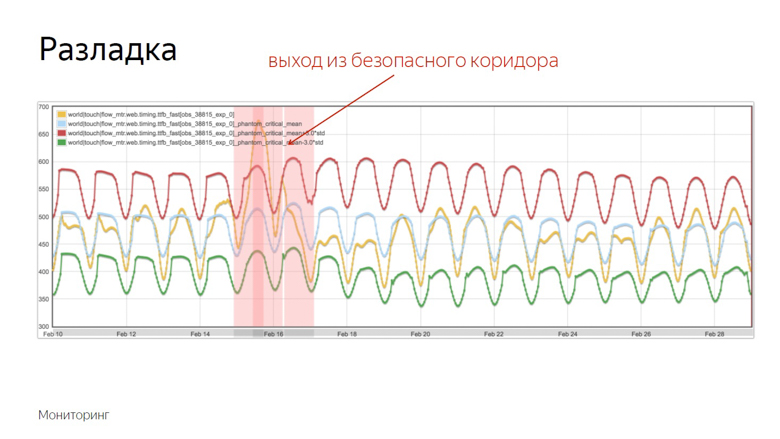
Los indicadores rojos y verdes forman un corredor seguro. Si bien la métrica y el promedio móvil fluctúan entre ellos, todo es normal, estas son fluctuaciones ordinarias. Pero si salen de la zona segura, se activa el monitoreo.
Comprobación de las características de velocidad
Todo lo que se discutió fue trabajar con los datos de velocidad de un proyecto ya lanzado, pero quiero medir la velocidad de las características individuales antes de enviarlas a una gran producción. Para hacer esto, utilizamos pruebas A / B, una comparación de métricas para los grupos de control y experimentales.
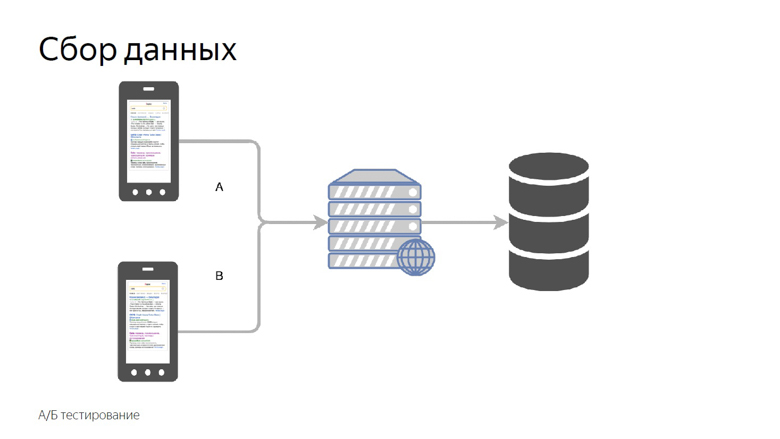
Dividimos a los usuarios en grupos de control y experimentales. Las lecturas de cada ranura se recopilan por separado, agregadas y tabuladas.
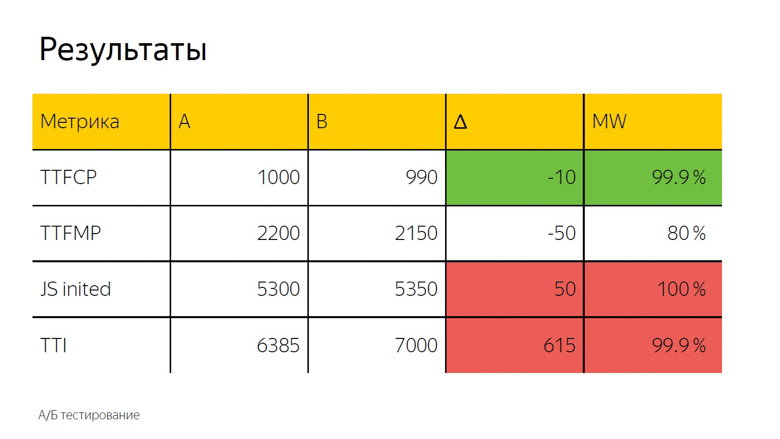
En las pruebas A / B, como regla, también se usa la media aritmética. Aquí vemos un delta y, para determinar con precisión si es un accidente o un resultado significativo, se aplica una prueba estadística.

Se designa como "MW" porque la prueba de Mann-Whitney se utiliza en el cálculo. Con su ayuda, se calcula el llamado "porcentaje de corrección". Este indicador tiene un umbral, después del cual tomamos el delta como verdadero. Aquí se establece en 99.9%.
Cuando la prueba alcanza este valor, el delta se resalta en la interfaz. Lo llamamos coloración. Aquí vemos verde, es decir, un buen color a tiempo para la primera pintura completa. El tiempo para la primera pintura significativa no alcanza este valor, es decir, el delta también es bueno, pero no el 99.9%. Es completamente imposible confiar en ella. Tras la inicialización del marco y el tiempo para interactuar, se observa una coloración roja con mala confianza. De esto podemos sacar la misma conclusión que en el caso de las fuentes.

¿Cómo hacerlo tú mismo?
Puede implementar mediciones de velocidad de dos maneras. Lo primero es hacer todo lo tuyo.

Un identificador para recibir datos de clientes, un back-end, que pone todo esto en una base de datos, MongoDB, PostgreSQL, MySQL, cualquier DBMS (tienen agregaciones listas para usar), además de una de las muchas soluciones de código abierto, para dibujar gráficos y organizar el monitoreo.
La segunda solución es utilizar los sistemas de análisis Yandex Metric o Google Analytics. En el ejemplo de Yandex Metrics, se ve así.
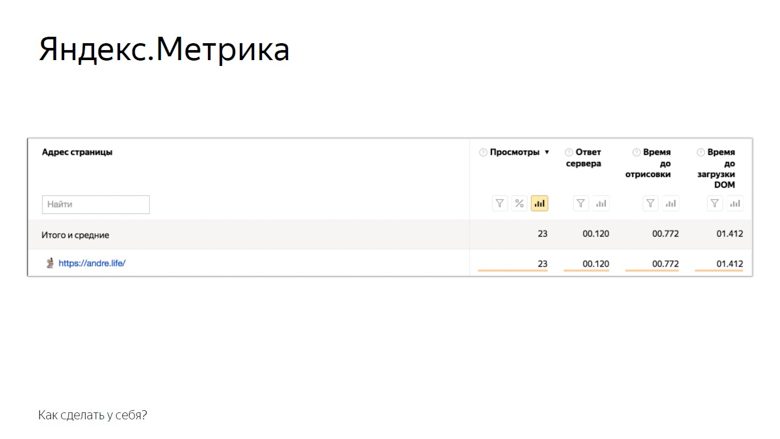
Estas son las métricas que la métrica proporciona al usuario fuera de la caja. Por supuesto, esto no es todo lo anterior, pero ya es algo. El resto se puede agregar manualmente a través de la configuración del usuario. Las pruebas y monitoreo A / B también están disponibles.
Conclusión
El concepto de medición de velocidad en línea del que hablamos se conoce como RUM - Real User Monitoring. La amamos tanto que incluso dibujamos un logotipo con una fantástica diéresis de rock and roll.

Este enfoque es bueno porque se basa en números del mundo real, esos indicadores que tiene la audiencia de su servicio. Usando métricas, parece que recibe comentarios de cada usuario. Así que comienza a optimizar y no te detengas.
El anuncio al final. Si te gustó esta charla con HolyJS 2018 Piter , probablemente te interesará el próximo HolyJS 2018 Moscú , que se llevará a cabo del 24 al 25 de noviembre . Allí no solo puede ver muchos otros informes JS, sino también preguntar a cualquier orador en el área de discusión después del informe. Y mañana, a partir del 1 de noviembre, los precios de los boletos subirán a la final, ¡así que hoy es la última oportunidad de comprarlos con descuento!