
Badoo ha existido por más de 12 años. Tenemos mucho código PHP (millones de líneas) y probablemente incluso las líneas escritas hace 12 años se conservaron. Tenemos código escrito en los días de PHP 4 y PHP 5. Cargamos el código dos veces al día, y cada diseño contiene alrededor de 10-20 tareas. Además, los programadores pueden publicar parches urgentes, pequeños cambios. Y el día de tales parches, ganamos un par de docenas. En general, nuestro código está cambiando muy activamente.
Constantemente buscamos oportunidades para acelerar el desarrollo y mejorar la calidad del código. Entonces, un día decidimos implementar el análisis de código estático. Lo que salió de eso, leer debajo del corte.
Tipos estrictos: por qué aún no lo estamos usando
Una vez, comenzó una discusión en nuestro chat corporativo de PHP. Uno de los nuevos empleados contó cómo, en el lugar de trabajo anterior, introdujeron las sugerencias obligatorias de
tipo escalar riguroso para todo el código, y esto redujo significativamente la cantidad de errores en la producción.
La mayoría de los veteranos de chat estaban en contra de tal innovación. La razón principal fue que PHP no tiene un compilador que verifica todos los tipos en el código en el momento de la compilación, y si no tiene una cobertura del 100% del código con las pruebas, siempre existe el riesgo de que surjan errores en la producción, lo cual no ocurre. querer permitir.
Por supuesto, los estrictos_tipos encontrarán un cierto porcentaje de errores causados por la falta de coincidencia de tipos y cómo PHP "silenciosamente" convierte los tipos. Pero muchos programadores PHP experimentados ya saben cómo funciona el sistema de tipos en PHP, por qué reglas ocurre la conversión de tipos y, en la mayoría de los casos, escriben código correcto y funcional.
Pero nos gustó la idea de tener un cierto sistema que muestre dónde en el código hay una falta de coincidencia de tipos. Pensamos en alternativas a los estrictos tipos.
Al principio incluso queríamos parchear PHP. Queríamos que si la función toma algún tipo de tipo escalar (digamos int), y entra otro tipo escalar (como float), entonces TypeError (que es una excepción en sí mismo) no se lanzaría, pero ocurriría una conversión de tipo, así como registrar este evento en error.log. Esto nos permitiría encontrar todos los lugares donde nuestras suposiciones sobre los tipos son incorrectas. Pero tal parche nos parecía arriesgado, e incluso podría haber problemas con dependencias externas, que no estaban listas para tal comportamiento.
Abandonamos la idea de parchear PHP, pero con el tiempo todo coincidió con las primeras versiones del analizador estático Phan, las primeras confirmaciones realizadas por el propio Rasmus Lerdorf. Entonces se nos ocurrió la idea de probar analizadores de código estático.
¿Qué es el análisis de código estático?
Los analizadores de código estático solo leen el código e intentan encontrar errores en él. Pueden realizar comprobaciones muy simples y obvias (por ejemplo, para la existencia de clases, métodos y funciones, y otras más complicadas (por ejemplo, buscar desajustes de tipo, condiciones de carrera o vulnerabilidades en el código). La clave es que los analizadores no ejecutan código: ellos analice el texto del programa y verifique si hay errores típicos (y no tan).
El ejemplo más obvio de un analizador de código PHP estático son las inspecciones en PHPStorm: cuando escribe código, resalta las llamadas incorrectas a funciones, métodos, desajustes de tipo de parámetro, etc. Sin embargo, PHPStorm no ejecuta su código PHP, solo lo analiza.
Observo que en este artículo estamos hablando de analizadores que buscan errores en el código. Existe otra clase de analizadores: verifican el estilo de escritura del código, la complejidad ciclomática, los tamaños de los métodos, las longitudes de línea, etc. No consideramos tales analizadores aquí.
Aunque no todo lo que los analizadores que estamos considerando encuentra es precisamente un error. Por error, me refiero al código que Fatal creará en producción. Muy a menudo, lo que los analizadores encuentran es más probable que sea una inexactitud. Por ejemplo, se puede especificar un tipo de parámetro incorrecto en PHPDoc. Esta inexactitud no afecta el funcionamiento del código, pero posteriormente el código evolucionará; otro programador puede cometer un error.
Analizadores de código PHP existentes
Hay tres analizadores de código PHP populares:
- PHPStan .
- Salmo
- Phan
Y está
Exakat , que no hemos probado.
En el lado del usuario, los tres analizadores son iguales: los instala (probablemente a través de Composer), los configura, después de lo cual puede comenzar el análisis de todo el proyecto o grupo de archivos. Como regla general, el analizador puede mostrar bellamente los resultados en la consola. También puede generar los resultados en formato JSON y usarlos en CI.
Los tres proyectos ahora se están desarrollando activamente. Sus mantenedores son muy activos en responder a problemas en GitHub. A menudo, el primer día después de crear un ticket, reaccionan al menos (comentar o poner una etiqueta como error / mejora). Muchos errores que encontramos fueron reparados en un par de días. Pero me gusta especialmente el hecho de que los encargados del proyecto se comuniquen activamente entre sí, se denuncien entre sí y envíen solicitudes de extracción.
Hemos implementado y utilizado los tres analizadores. Cada uno tiene sus propios matices, sus propios errores. Pero el uso de tres analizadores al mismo tiempo facilita la comprensión de dónde está el problema real y dónde está el falso positivo.
¿Qué pueden hacer los analizadores?
Los analizadores tienen muchas características comunes, por lo que primero veremos qué pueden hacer todos y luego pasaremos a las características de cada uno de ellos.
Cheques estándar
Por supuesto, los analizadores realizan todas las comprobaciones de código estándar por el hecho de que:
- El código no contiene errores de sintaxis;
- todas las clases, métodos, funciones, constantes existen;
- existen variables;
- en PHPDoc, las sugerencias son ciertas.
Además, los analizadores comprueban el código en busca de argumentos y variables no utilizados. Muchos de estos errores conducen a fatalidades reales en el código.
A primera vista, puede parecer que los buenos programadores no cometen tales errores, pero a veces tenemos prisa, a veces copiamos y pegamos, a veces simplemente estamos desatentos. Y en tales casos, estos cheques ahorran mucho.
Verificaciones de tipo de datos
Por supuesto, los analizadores estáticos también llevan a cabo verificaciones estándar con respecto a los tipos de datos. Si está escrito en el código que la función acepta, digamos, int, entonces el analizador verificará si hay lugares donde se pasa un objeto a esta función. Para la mayoría de los analizadores, puede configurar la gravedad de la prueba y simular estrictos_tipos: verifique que no se pasen cadenas ni booleanos a esta función.
Además de los controles estándar, los analizadores aún tienen mucho que hacer.
Tipos de uniónTodos los analizadores apoyan el concepto de tipos de unión. Supongamos que tiene una función como:
function isYes($yes_or_no) :bool { if (\is_bool($yes_or_no)) { return $yes_or_no; } elseif (is_numeric($yes_or_no)) { return $yes_or_no > 0; } else { return strtoupper($yes_or_no) == 'YES'; } }
Su contenido no es muy importante: el tipo de parámetro de entrada
string|int|bool es importante. Es decir, la variable
$yes_or_no es una cadena, un entero o un
Boolean .
Usando PHP, este tipo de parámetro de función no se puede describir. Pero en PHPDoc, esto es posible, y muchos editores (como PHPStorm) lo entienden.
En los analizadores estáticos, este tipo se llama
tipo de unión , y son muy buenos para verificar dichos tipos de datos. Por ejemplo, si escribimos la función anterior de esta manera (sin verificar
Boolean ):
function isYes($yes_or_no) :bool { if (is_numeric($yes_or_no)) { return $yes_or_no > 0; } else { return strtoupper($yes_or_no) == 'YES'; } }
los analizadores verían que una cadena o un booleano pueden llegar a strtoupper y devolver un error: no se puede pasar un booleano a strtoupper.
Este tipo de verificación ayuda a los programadores a manejar correctamente los errores o situaciones en las que una función no puede devolver datos. A menudo escribimos funciones que pueden devolver algunos datos o
null :
En el caso de dicho código, el analizador le dirá que la variable
$User aquí puede ser
null y que este código puede ser fatal.
Escriba falsoEn el lenguaje PHP en sí, hay bastantes funciones que pueden devolver algún valor o falso. Si tuviéramos que escribir tal función, ¿cómo documentaríamos su tipo?
function fopen(...) { … }
Formalmente, todo parece ser cierto aquí: fopen devuelve recurso o
false (que es de tipo
Boolean ). Pero cuando decimos que una función devuelve algún tipo de tipo de datos, significa que puede devolver
cualquier valor de un conjunto que pertenece a este tipo de datos. En nuestro ejemplo, para el analizador, esto significa que
fopen() puede devolver
true . Y, por ejemplo, en el caso de dicho código:
$fp = fopen('some.file','r'); if($fp === false) { return false; } fwrite($fp, "some string");
los analizadores se quejarían de que
fwrite acepta el primer recurso de parámetro y le pasamos
bool (porque el analizador ve que es posible una opción verdadera). Por esta razón, todos los analizadores entienden un tipo de datos "artificial" como
false , y en nuestro ejemplo podemos escribir
@return false|resource . PHPStorm también comprende esta descripción de tipo.
Formas de matrizMuy a menudo, las matrices en PHP se usan como un tipo de
record , una estructura con una lista clara de campos, donde cada campo tiene su propio tipo. Por supuesto, muchos programadores ya usan clases para esto. Pero tenemos mucho código heredado en Badoo, y las matrices se usan activamente allí. Y también sucede que los programadores son demasiado vagos para crear una clase separada para alguna estructura de una sola vez, y en esos lugares también se usan a menudo matrices.
El problema con tales matrices es que no hay una descripción clara de esta estructura (una lista de campos y sus tipos) en el código. Los programadores pueden cometer errores al trabajar con dicha estructura: olvide los campos obligatorios o agregue las teclas "izquierdas", lo que confunde aún más el código.
Los analizadores le permiten ingresar una descripción de tales estructuras:
function showUrl(array $parsed_url) { … }
En este ejemplo, describimos una matriz con tres campos de cadena:
scheme, host y
path . Si dentro de la función pasamos a otro campo, el analizador mostrará un error.
Si no describe los tipos, los analizadores intentarán "adivinar" la estructura de la matriz, pero, como muestra la práctica, en realidad no tienen éxito con nuestro código. :)
Este enfoque tiene un inconveniente. Suponga que tiene una estructura que se usa activamente en el código. No puede declarar un pseudotipo en un lugar y luego usarlo en todas partes. Tendrá que registrar PHPDoc con la descripción de la matriz en todas partes del código, lo cual es muy inconveniente, especialmente si hay muchos campos en la matriz. También será problemático editar este tipo más tarde (agregar y eliminar campos).
Descripción de tipos de clave de matrizEn PHP, las claves de matriz pueden ser enteros y cadenas. Los tipos a veces pueden ser importantes para el análisis estático (y también para los programadores). Los analizadores estáticos le permiten describir claves de matriz en PHPDoc:
$users = UserLoaders::loadUsers($user_ids);
En este ejemplo, usando PHPDoc, agregamos una pista de que en la matriz
$users las claves son enteros, y los valores son objetos de la clase
\User . Podríamos describir el tipo como \ Usuario []. Esto le diría al analizador que hay objetos en la clase
\User en la matriz, pero no nos diría nada sobre el tipo de claves.
PHPStorm admite este formato para describir matrices a partir de la versión 2018.3.
Tu espacio de nombres en PHPDocPHPStorm (y otros editores) y analizadores estáticos pueden entender PHPDoc de manera diferente. Por ejemplo, los analizadores admiten este formato:
function showUrl($parsed_url) { … }
Pero PHPStorm no lo entiende. Pero podemos escribir así:
function showUrl($parsed_url) { … }
En este caso, tanto los analizadores como PHPStorm estarán satisfechos. PHPStorm usará
@param , y los analizadores usarán sus propias etiquetas PHPDoc.
Comprobaciones de características de PHP
Este tipo de prueba se ilustra mejor con un ejemplo.
¿Todos sabemos qué puede devolver la función
explotar () ? Si echa un vistazo a la documentación, parece que devuelve una matriz. Pero si lo examina con más cuidado, veremos que también puede devolver falso. De hecho, puede devolver tanto nulo como un error si le pasa los tipos incorrectos, pero pasar el valor incorrecto con el tipo de datos incorrecto ya es un error, por lo que esta opción no es interesante para nosotros ahora.
Formalmente, desde el punto de vista del analizador, si una función puede devolver falso o una matriz, entonces, lo más probable, entonces el código debe verificar si es falso. Pero la función explotar () devuelve falso solo si el delimitador (primer parámetro) es igual a una cadena vacía. A menudo, está escrito explícitamente en el código, y los analizadores pueden verificar que no está vacío, lo que significa que en este lugar la función explotar () devuelve con precisión una matriz y no se necesita una verificación falsa.
PHP tiene algunas características. Los analizadores agregan gradualmente las comprobaciones apropiadas o las mejoran, y nosotros, los programadores, ya no necesitamos recordar todas estas características.
Pasamos a la descripción de analizadores específicos.
PHPStan
Desarrollo de un cierto Ondřej Mirtes de la República Checa. Desarrollado activamente desde finales de 2016.
Para comenzar a usar PHPStan, necesita:
- Instálelo (la forma más fácil de hacerlo es a través de Composer).
- (opcional) Configurar.
- En el caso más simple, simplemente ejecute:
vendor/bin/phpstan analyse ./src(en lugar de
src puede haber una lista de archivos específicos que desea verificar).
PHPStan leerá el código PHP de los archivos transferidos. Si se encuentra con clases desconocidas, intentará cargarlas con carga automática y mediante reflexión para comprender su interfaz. También puede transferir la ruta al archivo
Bootstrap , a través del cual configura la carga automática, y conectar algunos archivos adicionales para simplificar el análisis PHPStan.
Características clave
- Es posible analizar no todo el código base, sino solo una parte: las clases desconocidas PHPStan intentará cargar la carga automática.
- Si por alguna razón algunas de sus clases no están en la carga automática, PHPStan no podrá encontrarlas y dará un error.
- Si está utilizando activamente métodos mágicos a través de
__call / __get / __set , puede escribir un complemento para PHPStan. Ya existen complementos para Symfony, Doctrine, Laravel, Mockery, etc.
- De hecho, PHPStan realiza la carga automática no solo para clases desconocidas, sino en general para todos. Tenemos una gran cantidad de código antiguo escrito antes de la aparición de clases anónimas, cuando creamos una clase en un archivo y luego lo instanciamos instantáneamente y, posiblemente, incluso llamamos a algunos métodos. La carga automática (
include ) de dichos archivos conduce a errores, porque el código no se ejecuta en un entorno normal.
- Configuraciones en formato neón (nunca escuché que tal formato se usara en otro lugar).
- No hay soporte para sus etiquetas PHPDoc como
@phpstan-var, @phpstan-return , etc.
Otra característica es que los errores tienen texto, pero no hay ningún tipo. Es decir, el texto de error se le devuelve, por ejemplo:
Method \SomeClass::getAge() should return int but returns int|null
Method \SomeOtherClass::getName() should return string but returns string|null
En este ejemplo, ambos errores son básicamente lo mismo: el método debe devolver un tipo, pero en realidad devuelve el otro. Pero los textos de los errores son diferentes, aunque similares. Por lo tanto, si desea filtrar cualquier error en PHPStan, hágalo solo a través de expresiones regulares.
A modo de comparación, en otros analizadores, los errores tienen un tipo. Por ejemplo, en Phan, dicho error es del tipo
PhanPossiblyNullTypeReturn , y puede especificar en la configuración que no necesita verificar dichos errores. Además, al tener el tipo de error, es posible, por ejemplo, recopilar fácilmente estadísticas sobre errores.
Dado que no usamos Laravel, Symfony, Doctrine y soluciones similares, y raramente usamos métodos mágicos en nuestro código, la característica principal de PHPStan resultó no ser reclamada para nosotros. ; (Además, debido a que PHPStan incluye
todas las clases que se están verificando, a veces su análisis simplemente no funciona en nuestra base de código.
Sin embargo, PHPStan sigue siendo útil para nosotros:
- Si necesita verificar varios archivos, PHPStan es notablemente más rápido que Phan y un poco (20-50%) más rápido que Psalm.
- Los informes de PHPStan hacen que sea más fácil encontrar
false-positive en otros analizadores. Por lo general, si hay algún fatal explícito en el código, todos los analizadores lo muestran (o al menos dos de los tres).
Actualización:El autor de PHPStan Ondřej Mirtes también leyó nuestro artículo y nos
dijo que PhpStan, como Psalm, tiene un sitio web con un "sandbox":
https://phpstan.org/ . Esto es muy conveniente para los informes de errores: reproduce el error y proporciona un enlace en GitHub.
Phan
Desarrollado por Etsy. Primero comete de Rasmus Lerdorf.
De los tres en cuestión, Phan es el único analizador estático real (en el sentido de que no ejecuta ninguno de sus archivos, analiza su base de código
completa y luego analiza lo que dice). Incluso para analizar varios archivos en nuestra base de código, necesita alrededor de 6 GB de RAM, y este proceso lleva de cuatro a cinco minutos. Pero luego, un análisis completo de toda la base de código lleva entre seis y siete minutos. A modo de comparación, Salmo lo analiza en unas pocas decenas de minutos. Y desde PHPStan no pudimos lograr un análisis completo de toda la base de código porque incluye clases de inclusión.
La experiencia de Phan es doble. Por un lado, es el analizador más estable y de alta calidad, encuentra mucho y tiene menos problemas cuando es necesario analizar todo el código base. Por otro lado, tiene dos características desagradables.
Debajo del capó, Phan usa la extensión php-ast. Aparentemente, esta es una de las razones por las que el análisis de todo el código base es relativamente rápido. Pero php-ast muestra la representación interna del árbol AST tal como aparece en el propio PHP. Y en PHP mismo, el árbol AST no contiene información sobre los comentarios que se encuentran dentro de la función. Es decir, si escribiste algo como:
function doSomething($type) { $obj = MyFactory::createObjectByType($type); … }
luego dentro del árbol AST hay información sobre el PHPDoc externo para la función
doSomething() , pero no hay información de ayuda PHPDoc dentro de la función. Y, en consecuencia, Phan tampoco sabe nada de ella. Esta es la causa más común de
false-positive en Phan. Hay
algunas recomendaciones sobre cómo insertar información sobre herramientas (a través de cadenas o aserciones), pero, desafortunadamente, son muy diferentes de lo que nuestros programadores están acostumbrados. Parcialmente, resolvimos este problema escribiendo un complemento para Phan. Pero los complementos se discutirán a continuación.
La segunda característica desagradable es que Phan no analiza bien las propiedades de los objetos. Aquí hay un ejemplo:
class A { private $a; public function __construct(string $a = null) { $this->a = $a; } public function doSomething() { if ($this->a && strpos($this->a, 'a') === 0) { var_dump("test1"); } } }
En este ejemplo, Phan le dirá que en strpos puede pasar nulo. Puede obtener más información sobre este problema aquí:
https://github.com/phan/phan/issues/204 .
Resumen A pesar de algunas dificultades, Phan es un desarrollo muy bueno y útil. Además de estos dos tipos de
false-positive , casi no comete errores, o comete errores, sino en un código realmente complejo. También nos gustó que la configuración esté en un archivo PHP, esto le da cierta flexibilidad. Phan también sabe cómo trabajar como servidor de idiomas, pero no utilizamos esta función, ya que PHPStorm es suficiente para nosotros.
Complementos
Phan tiene una API de desarrollo de complementos bien desarrollada. Puede agregar sus propios controles, mejorar la inferencia de tipos para su código. Esta API
tiene documentación , pero es especialmente bueno que ya haya complementos que funcionen y que puedan usarse como ejemplos.
Logramos escribir dos complementos. El primero estaba destinado a un chequeo único. Queríamos evaluar qué tan listo está nuestro código para PHP 7.3 (en particular, para averiguar si tiene constantes que no
case-insensitive ). Estábamos casi seguros de que no había tales constantes, pero cualquier cosa podría suceder en 12 años, debería verificarse. Y escribimos un complemento para Phan que juraría si el tercer parámetro se usara en
define() .
El complemento es muy simple. <?php declare(strict_types=1); use Phan\AST\ContextNode; use Phan\CodeBase; use Phan\Language\Context; use Phan\Language\Element\Func; use Phan\PluginV2; use Phan\PluginV2\AnalyzeFunctionCallCapability; use ast\Node; class DefineThirdParamTrue extends PluginV2 implements AnalyzeFunctionCallCapability { public function getAnalyzeFunctionCallClosures(CodeBase $code_base) : array { $define_callback = function ( CodeBase $code_base, Context $context, Func $function, array $args ) { if (\count($args) < 3) { return; } $this->emitIssue( $code_base, $context, 'PhanDefineCaseInsensitiv', 'Define with 3 arguments', [] ); }; return [ 'define' => $define_callback, ]; } } return new DefineThirdParamTrue();
En Phan, se pueden colgar diferentes complementos en diferentes eventos. En particular, los complementos con la interfaz
AnalyzeFunctionCallCapability activan cuando se analiza una llamada de función. En este complemento, lo hicimos de modo que cuando llamamos a la función
define() , se llama a nuestra función anónima, que comprueba que
define() no
define() más de dos argumentos. Luego acabamos de comenzar Phan, encontramos todos los lugares donde se llamaba
define() con tres argumentos, y nos aseguramos de que no tuviéramos
case-insensitive- .
Usando el complemento, también resolvimos parcialmente el problema de
false-positive cuando Phan no ve las sugerencias PHPDoc dentro del código.
A menudo utilizamos métodos de fábrica que toman una constante como entrada y crean un objeto a partir de ella. A menudo, el código se ve así:
$Object = \Objects\Factory::create(\Objects\Config::MY_CONTROLLER);
Phan no comprende tales sugerencias PHPDoc, pero en este código la clase de objeto se puede obtener del nombre de la constante pasada al método
create() . Phan le permite escribir un complemento que se activa cuando analiza el valor de retorno de una función. Y con este complemento, puede decirle al analizador qué tipo de función devuelve esta llamada.
Un ejemplo de este complemento es más complejo. Pero hay un buen ejemplo en el código Phan en
vendor/phan/phan/src/Phan/Plugin/Internal/DependentReturnTypeOverridePlugin.php.En general, estamos muy satisfechos con el analizador Phan. Los
false-positive enumerados anteriormente los aprendimos parcialmente (en casos simples, con código simple) para filtrar. Después de eso, Phan se convirtió en un analizador casi de referencia. Sin embargo, la necesidad de analizar de inmediato todo el código base (tiempo y mucha memoria) aún complica el proceso de su implementación.
Salmo
Psalm es un desarrollo de Vimeo. Honestamente, ni siquiera sabía que Vimeo usa PHP hasta que vi Psalm.
Este analizador es el más joven de nuestros tres. Cuando leí la noticia de que Vimeo lanzó Psalm, me quedé sin palabras: "¿Por qué invertir en Psalm si ya tienes Phan y PHPStan?" Pero resultó que Salmo tiene sus propias características útiles.
Psalm siguió los pasos de PHPStan: también puede darle una lista de archivos para su análisis, y los analizará y conectará clases que no se encuentran con una carga automática. Al mismo tiempo,
solo conecta clases que no se encontraron y los archivos que solicitamos para el análisis no se incluirán (esto es diferente de PHPStan). La configuración se almacena en un archivo XML (para nosotros, es más probable que sea un signo negativo, pero no muy crítico).
Psalm tiene un
sitio de espacio aislado donde puede escribir código PHP y analizarlo. Esto es muy conveniente para los informes de errores: reproduce el error en el sitio y proporciona el enlace en GitHub. Y, por cierto, el sitio describe todos los posibles tipos de errores. A modo de comparación: en PHPStan los errores no tienen tipos, y en Phan sí, pero no se puede encontrar una lista única.
También nos gustó que al generar errores, Psalm muestra inmediatamente las líneas de código donde se encontraron. Esto simplifica
enormemente la lectura de informes.
Pero quizás la característica más interesante de Psalm son sus etiquetas PHPDoc personalizadas, que le permiten mejorar el análisis (especialmente la definición de tipos). Enumeramos los más interesantes de ellos.
@ psalm-ignore-nullable-return
Sucede que formalmente un método puede devolver
null , pero el código ya está organizado de tal manera que esto nunca sucede. En este caso, es muy conveniente que pueda agregar una pista de PHPDoc al método / función, y Psalm considerará que no se devuelve
null .
Existe una pista similar para falso:
@psalm-ignore-falsable-return .
Tipos de cierre
Si alguna vez ha estado interesado en la programación funcional, puede haber notado que a menudo una función puede devolver otra función o tomar alguna función como parámetro. En PHP, este estilo puede ser muy confuso para sus colegas, y una de las razones es que PHP no tiene estándares para documentar tales funciones. Por ejemplo:
function my_filter(array $ar, \Closure $func) { … }
¿Cómo puede un programador entender qué interfaz tiene la función en el segundo parámetro? ¿Qué parámetros debe tomar? ¿Qué debería volver ella?
Psalm admite la sintaxis para describir funciones en PHPDoc:
function my_filter(array $ar, \Closure $func) { … }
Con tal descripción, ya está claro que necesita pasar una función anónima a
my_filter , que aceptará un int y devolverá bool. Y, por supuesto, Psalm verificará que haya pasado exactamente tal función en su código.
Enumeraciones
Supongamos que tiene una función que toma un parámetro de cadena y que solo puede pasar ciertas cadenas allí:
function isYes(string $yes_or_no) : bool { $yes_or_no = strtolower($yes_or_no) switch($yes_or_no) { case 'yes': return true; case 'no': return false; default: throw new \InvalidArgumentException(…); } }
Salmo le permite describir el parámetro de esta función de esta manera:
function isYes(string $yes_or_no) : bool { … }
En este caso, Psalm intentará comprender qué valores específicos se pasan a esta función y arrojará errores si hay valores distintos de
Yes y
NoLea más sobre enum
aquí .
Escriba alias
Anteriormente en la descripción de las
array shapes de la
array shapes mencioné que aunque los analizadores le permiten describir la estructura de las matrices, no es muy conveniente usarla, ya que la descripción de la matriz debe copiarse en diferentes lugares. La solución correcta, por supuesto, es usar clases en lugar de matrices. Pero en el caso de muchos años de legado, esto no siempre es posible.
, , , :
- ;
- closure;
- union- (, );
- enum.
, , PHPDoc , , . Psalm . alias PHPDoc
alias . , : PHP-. . , Psalm.
Generics aka templates
. , :
function identity($x) { return $x; }
? ? ?
, , , —
mixed , .
mixed — . , . ,
identity() / , : , . -. , :
$i = 5;
(int) , ,
$y (
int ).
? Psalm PHPDoc-:
function identity($x) { $return $x; }
templates Psalm , / .
Psalm templates:
—
vendor/vimeo/psalm/src/Psalm/Stubs/CoreGenericFunctions.php ;
—
vendor/vimeo/psalm/src/Psalm/Stubs/CoreGenericClasses.php .
Phan, :
https://github.com/phan/phan/wiki/Generic-Types .
, Psalm . , «» . , Psalm , , Phan PHPStan. .
PHPStorm
: , . , , .
. Phan, language server. PHPStorm, , .
, , PHPStorm ( ), . — Php Inspections (EA Extended). — , , . , . , scopes - scopes.
,
deep-assoc-completion . .
Badoo
?
, .
, . , ,
git diff / , , () . , .
, : -
git diff . . , . . , , , , .
, , :
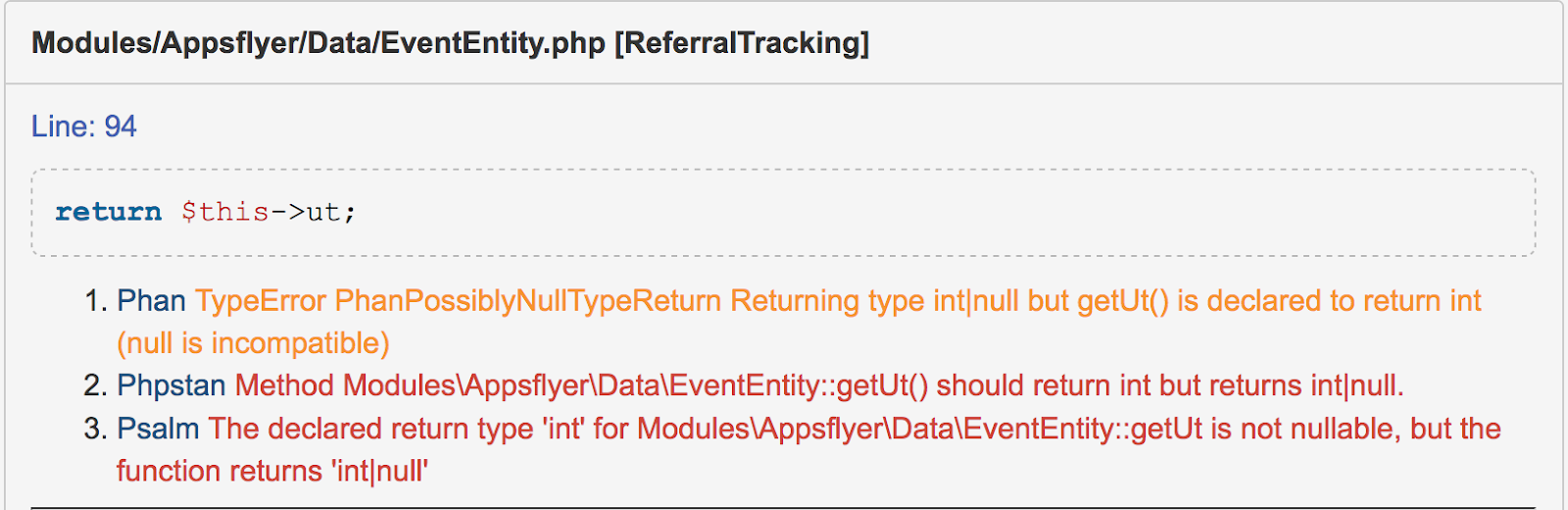
false-positive . , , Phan , , . , - Phan , , .
QA
:
— , , , . :
- 100% ( , );
- , code review;
- , .
strict types . ,
strict types , :
- ,
strict types , ;
- , (, , );
- , PHP (,
union types , PHP);
strict types , .
:
, . .
-, , , - , .
-, , — , , PHPDoc. — .
-, . , - , PHPDoc. :)
, , . , .