Entre las redes sociales, Twitter es más adecuado que otros para la extracción de datos de texto debido a la restricción estricta en la longitud del mensaje en el que los usuarios se ven obligados a colocar todo lo más esencial.
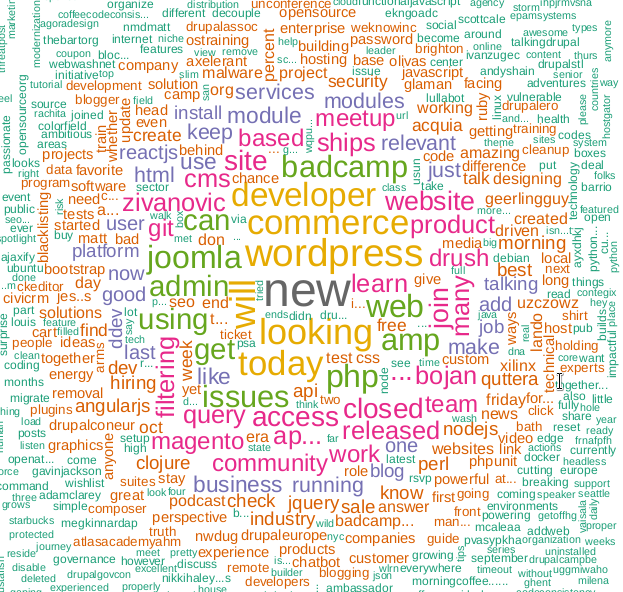
¿Sugiero adivinar qué tecnología enmarca esta nube de palabras?
Con la API de Twitter, puede extraer y analizar una amplia variedad de información. Un artículo sobre cómo hacer esto con el lenguaje de programación R.
Escribir el código no lleva tanto tiempo, pueden surgir dificultades debido a los cambios y el endurecimiento de la API de Twitter, aparentemente la compañía estaba seriamente preocupada por los problemas de seguridad después de ser arrastrada al Congreso de los EE. UU. Después de la investigación de la influencia de los "piratas informáticos rusos" en las elecciones estadounidenses en 2016.
API de acceso
¿Por qué alguien necesitaría recuperar datos industriales de Twitter? Bueno, por ejemplo, ayuda a hacer predicciones más precisas sobre el resultado de los eventos deportivos. Pero estoy seguro de que hay otros escenarios de usuario.
Para comenzar, está claro que debe tener una cuenta de Twitter con un número de teléfono. Esto es necesario para crear la aplicación, es este paso el que da acceso a la API.
Vamos a la página del desarrollador y hacemos clic en el botón Crear una aplicación . A continuación se encuentra la página en la que debe completar la información sobre la solicitud. Actualmente la página consta de los siguientes campos.
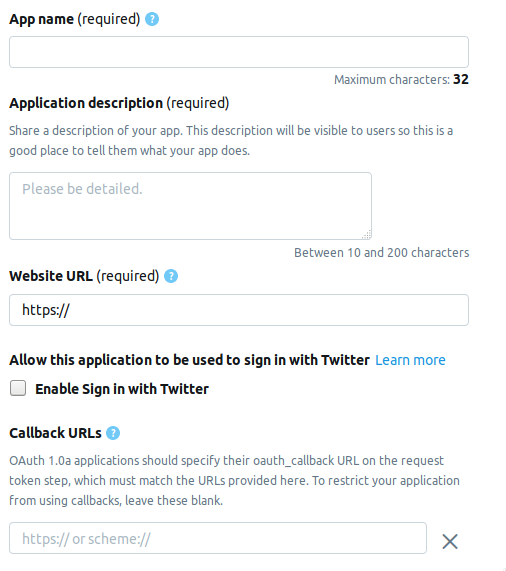
- AppName : nombre de la aplicación (obligatorio).
- Descripción de la aplicación: descripción de la aplicación (obligatorio).
- URL del sitio web : página del sitio web de la aplicación (obligatorio), puede ingresar cualquier cosa que parezca una URL.
- Habilitar Iniciar sesión con Twitter (casilla de verificación): se puede omitir el inicio de sesión desde la página de la aplicación en Twitter.
- URL de devolución de llamada : devolución de llamada de la aplicación durante la autenticación (requerida) y necesaria , puede dejar
http://127.0.0.1:1410 .
Los siguientes son campos opcionales: la dirección de la página para los términos de servicio, el nombre de la organización, etc.
Al crear una cuenta de desarrollador, elija una de las tres opciones posibles.
- Estándar : la versión básica, puede buscar registros a una profundidad de ≤ 7 días, gratis.
- Premium : una opción más avanzada, puede buscar registros a una profundidad de ≤ 30 días y desde 2006. Gratis, pero no dan de inmediato al considerar una solicitud.
- Empresa : tarifa de clase empresarial, pagada y confiable.
Elegí Premium , tardé aproximadamente una semana en esperar la aprobación. No puedo decirles a todos si me lo dan en una fila, pero vale la pena intentarlo de todos modos, y Standard no irá a ninguna parte.
Conexión de Twitter
Después de haber creado la aplicación, aparecerá un conjunto que contiene los siguientes elementos en la pestaña Llaves y tokens . A continuación se encuentran los nombres y las variables correspondientes de R.
Claves API de consumidor
- Clave API -
api_key - Clave secreta API -
api_secret
Token de acceso y secreto de token de acceso
- Token de acceso -
access_token - Secreto de token de acceso -
access_token_secret
Instala los paquetes necesarios.
install.packages("rtweet") install.packages("tm") install.packages("wordcloud")
Este código se verá así.
library("rtweet") api_key <- "" api_secret <- "" access_token <- "" access_token_secret <- "" appname="" setup_twitter_oauth ( api_key, api_secret, access_token, access_token_secret)
Después de la autenticación, R le pedirá que guarde los códigos OAuth en el disco para su uso posterior.
[1] "Using direct authentication" Use a local file to cache OAuth access credentials between R sessions? 1: Yes 2: No
Ambas opciones son aceptables, elegí la primera.
Buscar y filtrar resultados
tweets <- search_tweets("hadoop", include_rts=FALSE, n=600)
La tecla include_rts permite controlar si los retweets se incluyen o excluyen de la búsqueda. En la salida, obtenemos una tabla con muchos campos en los que hay detalles y detalles de cada registro. Aquí están los primeros 20.
> head(names(tweets), n=20) [1] "user_id" "status_id" "created_at" [4] "screen_name" "text" "source" [7] "display_text_width" "reply_to_status_id" "reply_to_user_id" [10] "reply_to_screen_name" "is_quote" "is_retweet" [13] "favorite_count" "retweet_count" "hashtags" [16] "symbols" "urls_url" "urls_t.co" [19] "urls_expanded_url" "media_url"
Puede componer una cadena de búsqueda más compleja.
search_string <- paste0(c("data mining","#bigdata"),collapse = "+") search_tweets(search_string, include_rts=FALSE, n=100)
Los resultados de búsqueda se pueden guardar en un archivo de texto.
write.table(tweets$text, file="datamine.txt")
Nos fusionamos en el cuerpo de los textos, filtramos de las palabras de servicio, los signos de puntuación y traducimos todo a minúsculas.
Hay otra función de búsqueda: searchTwitter , que requiere la biblioteca twitteR . De alguna manera, es más conveniente que search_tweets , pero de alguna manera inferior a él.
Además , la presencia de un filtro por tiempo.
tweets <- searchTwitter("hadoop", since="2017-09-01", n=500) text = sapply(tweets, function(x) x$getText())
Menos : la salida no es una tabla, sino un objeto de status de tipo. Para usarlo en nuestro ejemplo, necesitamos extraer un campo de texto de la salida. Esto hace que se sapply en la segunda línea.
corpus <- Corpus(VectorSource(tweets$text)) clearCorpus <- tm_map(corpus, function(x) iconv(enc2utf8(x), sub = "byte")) tdm <- TermDocumentMatrix(clearCorpus, control = list(removePunctuation = TRUE, stopwords = c("com", "https", "hadoop", stopwords("english")), removeNumbers = TRUE, tolower = TRUE))
En la segunda línea, la función tm_map necesaria para convertir los caracteres emoji a minúsculas; de lo contrario, la conversión a minúsculas con tolower fallará.
Construyendo una nube de palabras
Las nubes de palabras aparecieron por primera vez en el alojamiento de fotos de Flickr , que yo sepa, y desde entonces han ganado popularidad. Para esta tarea, necesitamos la biblioteca wordcloud .
m <- as.matrix(tdm) word_freqs <- sort(rowSums(m), decreasing=TRUE) dm <- data.frame(word=names(word_freqs), freq=word_freqs) wordcloud(dm$word, dm$freq, scale=c(3, .5), random.order=FALSE, colors=brewer.pal(8, "Dark2"))
La función search_string permite configurar el idioma como parámetro.
search_tweets(search_string, include_rts=FALSE, n=100, lang="ru")
Sin embargo, debido al hecho de que el paquete de PNL para R está poco rusificado, en particular, no hay una lista de servicio o palabras de detención, no logré construir una nube de palabras con una búsqueda en ruso. Estaré encantado si encuentras una mejor solución en los comentarios.
Bueno, en realidad ...
guión completo library("rtweet") library("tm") library("wordcloud") api_key <- "" api_secret <- "" access_token <- "" access_token_secret <- "" appname="" setup_twitter_oauth ( api_key, api_secret, access_token, access_token_secret) oauth_callback <- "http://127.0.0.1:1410" setup_twitter_oauth (api_key, api_secret, access_token, access_token_secret) appname="my_app" twitter_token <- create_token(app = appname, consumer_key = api_key, consumer_secret = api_secret) tweets <- search_tweets("devops", include_rts=FALSE, n=600) corpus <- Corpus(VectorSource(tweets$text)) clearCorpus <- tm_map(corpus, function(x) iconv(enc2utf8(x), sub = "byte")) tdm <- TermDocumentMatrix(clearCorpus, control = list(removePunctuation = TRUE, stopwords = c("com", "https", "drupal", stopwords("english")), removeNumbers = TRUE, tolower = TRUE)) m <- as.matrix(tdm) word_freqs <- sort(rowSums(m), decreasing=TRUE) dm <- data.frame(word=names(word_freqs), freq=word_freqs) wordcloud(dm$word, dm$freq, scale=c(3, .5), random.order=FALSE, colors=brewer.pal(8, "Dark2"))
Materiales usados
Enlaces cortos:
Enlaces originales:
https://stats.seandolinar.com/collecting-twitter-data-getting-started/
https://opensourceforu.com/2018/07/using-r-to-mine-and-analyse-popular-sentiments/
http://dkhramov.dp.ua/images/edu/Stu.WebMining/ch17_twitter.pdf
http://opensourceforu.com/2018/02/explore-twitter-data-using-r/
https://cran.r-project.org/web/packages/tm/vignettes/tm.pdf
Sugerencia de PS: la palabra clave de nube en KDPV no se usa en el programa, está asociada con mi artículo anterior .