Comprobar un servidor no es un problema. Usted toma la lista de verificación y verifica en orden: procesador, memoria, discos. Pero con cien servidores, es poco probable que este método funcione bien. Para excluir el factor humano, para hacer que los controles sean más confiables y rápidos, es necesario automatizar el proceso. ¿Quién necesita saber cómo hacerlo mejor que un proveedor de hosting? Artyom Artemyev en HighLoad ++ Siberia dijo qué métodos se pueden usar, qué es mejor ejecutar con las manos y qué funciona muy bien para la automatización. Además, una versión de texto del informe con consejos que cualquier persona que trabaje con hierro y necesite verificar regularmente su rendimiento puede repetir.
 Sobre el orador:
Sobre el orador: Artyom Artemyev (
artemirk ) director técnico en un gran proveedor de hosting FirstVDS, trabaja con hierro.
FirstVDS tiene dos centros de datos. El primero es el suyo, construyeron su propio edificio, trajeron e instalaron sus bastidores, ellos mismos mantienen, se preocupan por la corriente y la refrigeración del centro de datos. El segundo centro de datos es una habitación grande en un gran centro de datos alquilado, todo es más fácil con él, pero también existe. En total son 60 bastidores y unos 3000 servidores de hierro. Había algo para entrenar y probar diferentes enfoques, lo que significa que estamos esperando recomendaciones prácticamente confirmadas. Comencemos a ver o leer el informe.
Hace unos 6-7 años, nos dimos cuenta de que simplemente poner el sistema operativo en el servidor no es suficiente. El sistema operativo está encendido, el servidor está despierto y listo para la batalla. Lo lanzamos en producción: comienzan reinicios y bloqueos incomprensibles. Qué hacer, no está claro: el proceso está en marcha, transferir todo el borrador de trabajo a una nueva pieza de metal es difícil, costoso y doloroso. Donde correr
Los métodos modernos de implementación nos permiten evitar esto y transportar el servidor en 5 segundos, pero nuestros clientes (especialmente hace 6 años) simplemente no volaron en las nubes, caminaron por el suelo y usaron piezas de hierro comunes.

En este artículo, le diré qué métodos probamos, cuáles arraigamos, cuáles no arraigaron, cuáles son buenos para ejecutar con sus manos y cómo automatizar todo esto. Te daré un consejo, y puedes repetirlo en tu empresa si trabajas con hierro y tienes esa necesidad.
Cual es el problema
En teoría, verificar el servidor no es un problema. Inicialmente, tuvimos un proceso, como en la imagen a continuación. Un hombre se sienta, toma una lista de verificación, verifica: procesador, memoria, discos, arruga la frente, toma una decisión.
Luego se instalaron 3 servidores por mes. Pero, cuando hay más y más servidores, esta persona comienza a llorar y a quejarse de que se está muriendo en el trabajo. Una persona se equivoca cada vez más, porque la verificación se ha convertido en una rutina.
Tomamos una decisión: ¡automatizamos! Una persona hará cosas más útiles.
Pequeña excursión
Aclararé a qué me refiero cuando hable sobre el servidor hoy. Nosotros, como todos los demás, ahorramos espacio en el rack y usamos servidores de alta densidad. Hoy son 2 unidades, que pueden caber 12 nodos de servidores de un solo procesador o 4 nodos de servidores de doble procesador. Es decir, cada servidor obtiene 4 discos, todo sinceramente. Además, hay dos fuentes de alimentación en el bastidor, es decir, todo es redundante y a todos les gusta.
¿De dónde es el hierro?
El hierro es llevado a nuestro centro de datos por nuestros proveedores, generalmente Supermicro e Intel. En el centro de datos, nuestros operadores-chicos instalan servidores en un espacio vacío en el rack y conectan dos cables, una red y una fuente de alimentación. También es responsabilidad de los operadores configurar el BIOS en el servidor. Es decir, conecte el teclado, el monitor y configure dos parámetros:
Restore on AC/Power Loss — [Power On] , para que el servidor siempre se encienda tan pronto como aparezca la alimentación. Debería funcionar sin parar. El segundo
First boot device — [PXE] , es decir, colocamos el primer dispositivo de arranque en la red, de lo contrario no podremos llegar al servidor, ya que no es un hecho que tenga discos de inmediato, etc.

Después de eso, el operador abre el panel de contabilidad de los servidores de hierro, en el que debe registrar el hecho de instalar el servidor, para lo cual se indica:
- estante
- pegatina
- puertos de red
- puertos de alimentación
- número de unidad
Después de eso, el puerto de red donde el operador instaló el nuevo servidor, por razones de seguridad, va a una VLAN de cuarentena especial, que también cuelga DHCP, Pxe, TFtp. A continuación, el servidor carga nuestro Linux favorito, que tiene todas las utilidades necesarias, y comienza el proceso de diagnóstico.
Dado que el servidor todavía tiene el primer dispositivo de arranque en la red, para los servidores que entran en producción, el puerto cambia a otra VLAN. No hay DHCP en otra VLAN, y no tenemos miedo de reinstalar accidentalmente nuestro servidor de producción. Para esto, tenemos una VLAN separada.
Sucede que el servidor se instaló, todo está bien, pero no se inició en el sistema de diagnóstico. Esto sucede, por regla general, debido al hecho de que con un retraso en el cambio de VLAN, no todos los conmutadores de red cambian rápidamente las VLAN, etc.

Luego, el operador recibe la tarea de reiniciar el servidor con sus manos. Anteriormente, no había IPMI, configuramos sockets remotos y arreglamos en qué puerto los sockets del servidor, sacamos el socket a través de la red y el servidor se reiniciaba.
Pero los puntos de venta administrados tampoco siempre funcionan bien, por lo que ahora administramos la potencia del servidor a través de IPMI. Pero cuando el servidor es nuevo, IPMI no está configurado, solo se puede reiniciar subiendo y presionando el botón. Por lo tanto, un hombre se sienta, espera, se enciende la luz, corre y presiona el botón. Tal es su trabajo.
Si después de eso el servidor no se inició, se ingresa en una lista especial para su reparación. Esta lista incluye servidores en los que el diagnóstico no se inició o sus resultados no fueron satisfactorios. Una persona individual, que ama el hierro, se sienta y desmonta todos los días, recoge, mira, por qué no funciona.
CPU
Todo está bien, el servidor ha comenzado, estamos comenzando a probar. Primero probamos el procesador como uno de los elementos más importantes.

El primer impulso fue usar la aplicación del vendedor. Tenemos casi todos los procesadores Intel, fueron al sitio, descargaron la Herramienta de diagnóstico del procesador Intel, todo está bien, muestra mucha información interesante, incluidas las horas de funcionamiento del servidor en horas y el gráfico del consumo de energía.
Pero el problema es que Intel PTD funciona en Windows, lo que ya no nos gustaba. Para comenzar una prueba en él, solo necesita mover el mouse, presionar el botón "INICIAR" y comenzará la prueba. El resultado se muestra en la pantalla, pero no hay forma de exportarlo a ningún lado. Esto no nos conviene, porque el proceso no está automatizado.

Fuimos a leer los foros y encontramos las dos formas más fáciles.
- El bucle eterno cat / dev / zero> / dev / null . Puede verificar en la parte superior: se consume el 100% de un núcleo. Contamos el número de núcleos, ejecutamos el número requerido de cat / dev / zero, multiplicado por el número deseado de núcleos. ¡Todo funciona muy bien!
- Utilidad / bin / stress . Ella construye matrices en la memoria y comienza a volcarlas constantemente. Todo está bien también: el procesador se está calentando, hay una carga.
Entregamos los servidores en producción, los usuarios regresan y dicen que el procesador es inestable. Comprobado: el procesador es inestable. Comenzaron a investigar, tomaron un servidor que pasa las comprobaciones, pero se bloquea en una batalla, enciende el núcleo de depuración en Linux y recopila Core dump. El servidor antes de reiniciar descarga en el archivo todo lo que estaba en la memoria antes del bloqueo.

Se incorporan varias optimizaciones en los procesadores para operaciones frecuentes. Podemos ver banderas que reflejan qué optimizaciones admite el procesador, por ejemplo, optimizaciones para trabajar con números de coma flotante, optimizaciones multimedia, etc. Pero nuestro / bin / stress y el ciclo eterno solo queman el procesador en una operación y no usan funciones adicionales. La investigación mostró que la CPU se bloquea al intentar utilizar la funcionalidad de uno de los indicadores integrados.
El primer impulso fue dejar / bin / stress: dejar que el procesador se caliente. Luego, en un ciclo, atravesamos todas las banderas, tiramos de ellas. Mientras pensamos en cómo implementar esto, qué comandos llamar para invocar las funciones de cada indicador, leemos los foros.
En el foro de overclockers, nos topamos con un proyecto interesante para buscar números primos
Great Internet Mersenne Prime Search . Los científicos han creado una red distribuida a la que cualquiera puede conectarse y ayudar a encontrar un número primo. Los científicos no le creen a nadie, por lo que el programa funciona de manera muy inteligente: primero lo ejecuta, calcula los números primos que ya conoce y compara el resultado con lo que sabe. Si el resultado no coincide, el procesador no funciona correctamente. Realmente nos gustó esta propiedad: con cualquier tontería es propensa a caerse.
Además, el objetivo del proyecto es encontrar tantos números primos como sea posible, por lo tanto, el programa se optimiza constantemente para las propiedades de los nuevos procesadores, como resultado, saca muchas banderas.
Mprime no tiene límite de tiempo, si no se detiene, funciona para siempre. Lo ejecutamos durante 30 minutos.
/usr/bin/timeout 30m /opt/mprime -t /bin/grep -i error /root/result.txt
Después de completar el trabajo, verificamos que no haya errores en result.txt, y miramos los registros del kernel, en particular, en el archivo / proc / kmsg buscamos errores.
Otra excursión

El 3 de enero de 2018, encontraron el número 50 de Mersenne (2
p -1). De este número, solo 23 millones de dígitos. Puede descargarlo para verlo:
este es
un archivo zip de 12 Mb .
¿Por qué necesitamos números primos? Primero, cualquier encriptación RSA usa números primos. Cuantos más números primos sepamos, más confiable será su clave SSH. En segundo lugar, los científicos prueban sus hipótesis y teoremas matemáticos, y no nos importa ayudar a los científicos, no nos cuesta nada. Resulta historia de ganar-ganar.

Entonces, el procesador está funcionando, todo está bien. Queda por descubrir qué tipo de procesador es. Usamos el procesador dmidecode -t y vemos todas las ranuras que están en la placa base y qué procesadores están en estas ranuras. Esta información ingresa a nuestro sistema contable, la interpretaremos más adelante.
Captura
Por lo tanto, sorprendentemente, se pueden encontrar piernas rotas. / bin / stress y el ciclo perpetuo funcionó, y Mprime cayó. Condujeron durante mucho tiempo, buscaron, descubrieron, el resultado en la imagen a continuación, todo está claro aquí.

Tal procesador simplemente no se inició. El operador fue muy fuerte, tomó el procesador equivocado, pero pudo entregarlo.

Otro hermoso caso. La fila negra en la foto de abajo son los ventiladores, la flecha muestra cómo sopla el aire. Vemos: el radiador se encuentra al otro lado de la corriente. Por supuesto, todo se sobrecalentó y se apagó.

El recuerdo
Con la memoria, todo es bastante simple. Estas son celdas en las que escribimos información, y después de un tiempo la leemos nuevamente. Si sigue siendo lo mismo que escribimos, entonces esta celda está funcionando.

Todos conocen el programa
Memtest86 + bueno, directamente clásico, que se ejecuta desde cualquier medio, a través de la red, o incluso desde un disquete. Está hecho para verificar tantas celdas de memoria como sea posible. Las celdas ocupadas ya no se pueden verificar. Por lo tanto, memtest86 + tiene un tamaño mínimo para no ocupar memoria. Desafortunadamente,
memtest86 + solo muestra sus estadísticas en la pantalla . Intentamos expandirlo de alguna manera, pero todo se redujo al hecho de que dentro del programa ni siquiera había una pila de red. Para expandirlo, uno tendría que traer el kernel de Linux y todo lo demás.
Hay una versión paga de este programa que ya sabe cómo colocar información en el disco. Pero nuestros servidores no siempre tienen un disco, y no siempre hay un sistema de archivos en estos discos. Pero la unidad de red, como ya hemos descubierto, no se puede conectar.
Comenzamos a cavar más y encontramos un programa similar de
Memtester . Este programa funciona desde el nivel del sistema operativo desde Linux. Su mayor inconveniente es que el sistema operativo en sí y Memtester ocupan algunas celdas de memoria, y estas celdas no serán verificadas.
Memtester se inicia con el comando: memtester `cat / proc / meminfo | grep MemFree | awk '{print $ 2-1024}' 'k 5
Aquí transferimos la cantidad de memoria libre menos 1 MB. Esto se hace así, porque de lo contrario el Memtester ocupa toda la memoria y el asesino asesino la mata. Llevamos a cabo esta prueba durante 5 ciclos, en la salida tenemos una placa con OK o falla.
| Dirección atascada | ok |
| Valor aleatorio | ok |
| Comparar XOR | ok |
| Comparar SUB | ok |
| Comparar MUL | ok |
| Comparar DIV | ok |
| Comparar OR | ok |
| Compare Y | ok |
Guardamos el resultado final y analizamos más a fondo las fallas.

Para comprender el alcance del problema: nuestro servidor más pequeño tiene 32 GB de memoria, nuestra imagen de Linux con Memtester ocupa 60 MB,
no verificamos el 2% de la memoria . Pero según las estadísticas de los últimos 6 años, no ha habido tal cosa que francamente golpeó la memoria entró en producción. Este es el compromiso con el que estamos de acuerdo, y que es costoso para nosotros solucionarlo, y vivimos con él.
En el camino, también recopilamos memoria dmidecode -t, que proporciona todos los bancos de memoria que tenemos en la placa base (generalmente hasta 24 piezas), y qué matrices hay en cada banco. Esta información es útil si queremos actualizar el servidor: sabremos dónde agregar qué, cuántas tiras tomar y a qué servidor ir.
Dispositivos de almacenamiento
Hace 6 años, todos los discos estaban con panqueques que giraban. Una historia separada era reunir solo una lista de todos los discos. Hubo varios enfoques diferentes, ya que no se creía que pudiera simplemente mirar ls / dev / sd. Pero al final, dejamos de mirar ls / dev / sd * y ls / dev / cciss / c0d *. En el primer caso, es un dispositivo SATA, en el segundo - SCSI y SAS.

Literalmente este año, comenzaron a vender discos nvme y agregaron la lista nvme aquí.
Después de compilar la lista de discos, tratamos de leer 0 bytes para comprender que este es un dispositivo de bloque y que todo está bien. Si no pudo leerlo, entonces creemos que se trata de una especie de fantasma, y no tenemos y nunca tuvimos ese disco.
El primer enfoque para verificar discos fue obvio: “Escribamos datos aleatorios en el disco y veamos la velocidad” -
dd -o nocache -o direct if=/dev/urandom of=${disk} . Como regla general, los discos de panqueque dan 130-150 Mb / s. Entrecerramos los ojos y decidimos por nosotros mismos que 90 MB / s es la cifra después de la cual hay discos reparables, todos los más pequeños están funcionando mal.
Pero nuevamente, los usuarios comenzaron a regresar y decir que las unidades son malas. Resultó que la física insidiosa bromeaba con nosotros otra vez.
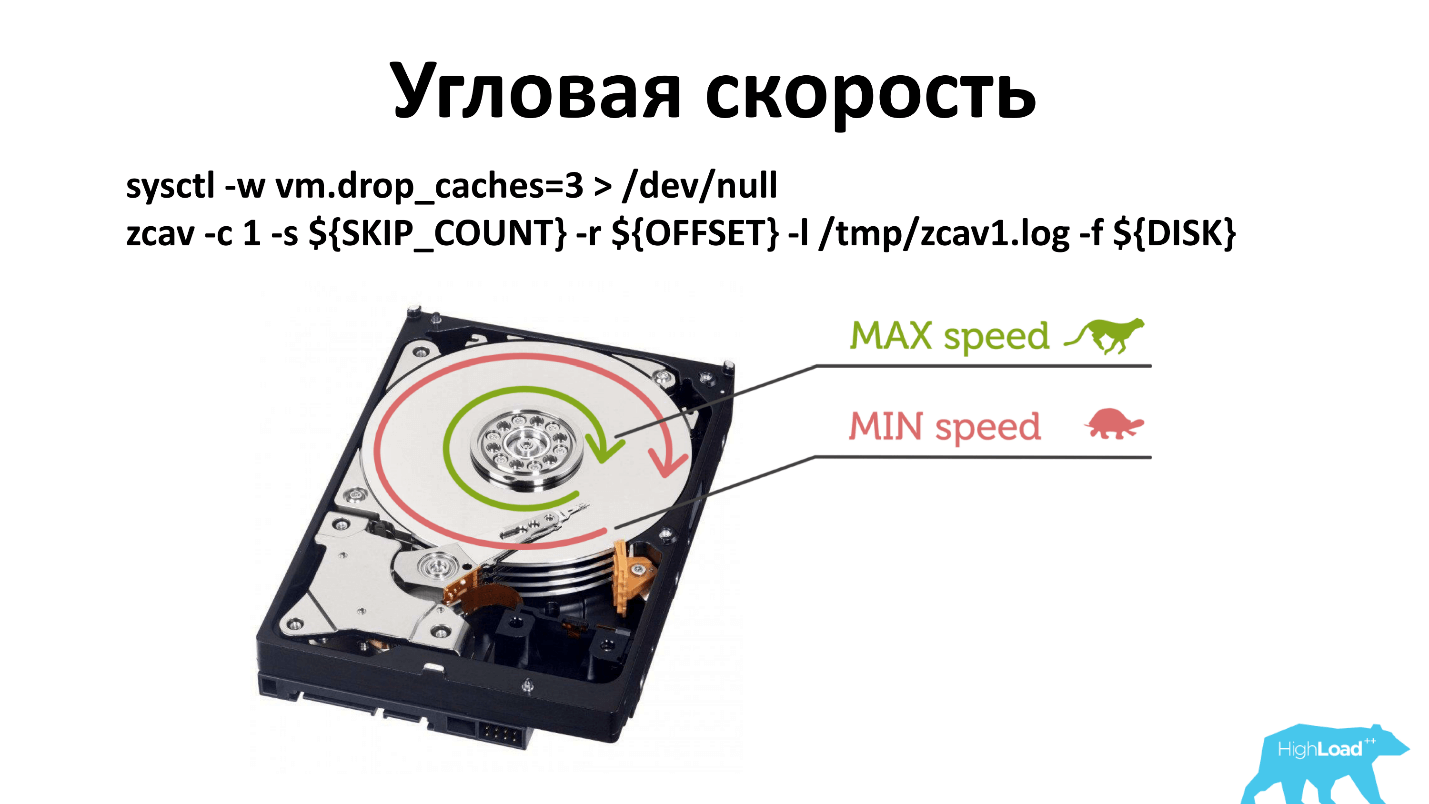
Hay velocidad angular y, como regla, cuando ejecuta -dd, escribe cerca del huso. Si por alguna razón la velocidad del eje se ha degradado, esto es menos notable que si escribe desde el borde del disco.
Tuve que cambiar el principio de verificación. Ahora revisamos en tres lugares: cerca del huso, en el medio y afuera. Probablemente, solo se puede verificar desde el exterior, pero así es como ha sucedido históricamente. Y lo que funciona, no lo toques.
Puede usar
smartctl para preguntarle al disco cómo le está yendo. Creemos que un buen disco:
- No hay sectores reasignados ( recuento de sectores reasignados = 0) , es decir, todos los sectores que han dejado el trabajo de fábrica.
- No utilizamos discos de más de 4 años , aunque funcionan bastante bien. Antes de presentar esta práctica, tuvimos discos durante 7 años. Ahora creemos que después de 4 años el disco ha dado sus frutos, y no estamos listos para aceptar el riesgo de desgaste.
- No hay sectores que se reasignarán ( Current_Pending_Sector = 0 ).
- UltraDMA CRC Error Count = 0 : estos son errores en el cable SATA. Si hay un error, solo necesita cambiar el cable, no necesita cambiar el disco.

Los SSD distribuidos son generalmente unidades excelentes, funcionan rápidamente, no hacen ruido, no se calientan. Creemos que un buen SSD tiene una velocidad de escritura de más de 200 MB / s. A nuestros clientes les encantan los precios bajos, y los modelos de servidores que emiten 320-350 MB / s no siempre nos llegan.
Para los SSD también buscamos smartctl. El mismo reasignado, Power_On_Hours, Current_Pending_Sector. Todos los SSD pueden mostrar el grado de desgaste, muestra el parámetro Media_Wearout_Indicator. Limpiamos los discos hasta el 5% de la vida útil, y solo entonces los sacamos. Tales discos a veces encuentran una segunda vida en las necesidades personales de los empleados. Por ejemplo, recientemente descubrí que en 2 años dicho disco se ha desgastado en otro 1% en la computadora portátil de un empleado, aunque en nuestro país el SSD agota el 95% en aproximadamente 10 meses.
Pero el problema es que no todos los fabricantes de discos estuvieron de acuerdo con los nombres de los parámetros, y este Media_Wearout_Indicator, por ejemplo, se llama Percent_Lifetime_Used para Toshiba, otro Conteo de nivelación de desgaste, Porcentaje restante de por vida para otros fabricantes, o simplemente. * Wear. *.
Crucial no tiene esta opción en absoluto. Luego consideramos la cantidad de reescritura del disco, “byte escrito”, cuántos bytes ya hemos escrito en este disco. Además, de acuerdo con la especificación, estamos tratando de averiguar cuántas reescrituras calcula este disco el fabricante. Por matemática elemental determinamos cuánto más vivirá. Si es hora de cambiar, cambie.
RAID
No sé por qué en el mundo moderno nuestros clientes todavía quieren RAID. La gente compra RAID, coloca 4 SSD allí, que son mucho más rápidos que este RAID (6 Gb). Tienen algún tipo de instrucción y la recopilan. Creo que esto es algo casi innecesario.
Solía haber 3 fabricantes: Adaptec; 3ware; Intel Teníamos 3 utilidades, nos molestamos, pero ejecutamos diagnósticos para todos. Ahora LSI compró a todos: solo queda una utilidad.
Cuando nuestro sistema de diagnóstico ve RAID, analiza el volumen lógico en discos separados para que pueda medir la velocidad de cada disco y leer su Smart. Después de eso, queda para que el RAID verifique la batería. Quién no sabe: hay suficientes baterías en el RAID para hacer girar todos los discos durante otras 2 horas. Es decir, apaga el servidor, lo saca y gira el disco durante otras 2 horas para completar todas las grabaciones.
Red
Con la red, todo es bastante simple: debe haber menos de 300 Mbit dentro del centro de datos. Si es menos, entonces necesitas arreglarlo. También observamos los errores en la interfaz.
Los errores en la interfaz de red no deberían estar en absoluto , y si lo están, entonces todo está mal.
Estamos intentando actualizar el BIOS y el firmware de IPMI en el camino. Resultó que no nos gustan todos los BIOS. Todavía tenemos BIOS que no saben cómo UEFI y otras características que usamos. Intentamos actualizarlo automáticamente, pero esto no siempre funciona, no todo es muy simple allí. Si no funciona, la persona va y actualiza con sus manos.
No le damos IPMI Supermicro al mundo, lo tenemos en direcciones grises a través de OpenVPN. Sin embargo, tememos que algún día surja otra vulnerabilidad y suframos. Por lo tanto, tratamos de mantener el firmware de IPMI siempre el último. Si esto no es así, entonces actualice.
De una cosa extraña, recientemente se supo que Intel en tarjetas de red de 10 y 40 gigabits no incluye arranque PXE. Resulta que si el servidor está en un bastidor en el que solo hay una tarjeta de 40 gigabits, entonces es imposible arrancar a través de la red, ya que necesita arrancar en una tarjeta gigabit. Destellamos por separado las tarjetas de red en 40G para que tengan PXE y puedan continuar funcionando.
Después de verificar todo, el servidor sale inmediatamente a la venta . Se calcula su precio, al cual se coloca en el sitio y se vende.

En total, realizamos aproximadamente 350 comprobaciones por mes, el 69% de los servidores están en servicio, el 31% no están en servicio. Esto se debe al hecho de que tenemos una rica historia, algunos servidores han estado en pie durante 10 años. La mayoría de los servidores que no pasaron la prueba, simplemente los lanzamos.
Para los curiosos: tenemos 3 clientes que aún viven en el Pentium IV y no quieren irse a ningún lado. Tienen 512 MB de RAM.
El futuro ha llegado! Si tuviera que cercar este sistema hoy ...

Se lanzó una utilidad maravillosa,
Hardware Lister (lshw), que puede comunicarse con el kernel, mostrar de manera hermosa qué tipo de hardware hay en el kernel, qué puede detectar el kernel. No todos estos bailes son necesarios. Si repite, le recomiendo que mire esta utilidad y la use. Todo se volverá mucho más simple.
Resumen:
- El compromiso no es malo, es solo una cuestión de precio. Si la solución es muy costosa, debe buscar un nivel donde tanto la confiabilidad como el precio sean aceptables.
- Los programas no básicos a veces son geniales para probar. Solo queda encontrarlos.
- ¡Prueba todo lo que alcances!
El próximo gran HighLoad ++ ya se llevará a cabo el 8 y 9 de noviembre en Moscú. El programa incluye especialistas famosos y nuevos nombres, tareas tradicionales y nuevas. En la sección DevOps, por ejemplo, ya se aceptan los siguientes:
Estudia la lista de informes y date prisa para unirte. O suscríbase a nuestro boletín y recibirá revisiones periódicas de informes, informes sobre nuevos artículos y videos.