 Un recorrido completo de aprendizaje automático en Python: tercera parte
Un recorrido completo de aprendizaje automático en Python: tercera parteA muchas personas no les gusta que los modelos de aprendizaje automático sean
recuadros negros : ponemos datos en ellos y obtenemos respuestas sin ninguna explicación, a menudo respuestas muy precisas. En este artículo intentaremos descubrir cómo el modelo que creamos hace pronósticos y qué puede decir sobre el problema que estamos resolviendo. Y concluimos con una discusión sobre la parte más importante del proyecto de aprendizaje automático: documentamos lo que hemos hecho y presentamos los resultados.
En la
primera parte, examinamos la limpieza de datos, el análisis exploratorio, el diseño y la selección de características. En la
segunda parte, estudiamos el llenado de datos faltantes, la implementación y comparación de modelos de aprendizaje automático, el ajuste hiperparamétrico mediante búsqueda aleatoria con validación cruzada y, finalmente, la evaluación del modelo resultante.
Todo el
código del proyecto está en GitHub. Y el tercer cuaderno Jupyter relacionado con este artículo se encuentra
aquí . ¡Puedes usarlo para tus proyectos!
Por lo tanto, estamos trabajando en una solución al problema utilizando el aprendizaje automático, o más bien, utilizando la regresión supervisada. Con base en
los datos de energía de los edificios en Nueva York, creamos un modelo que predice la calificación Energy Star. Hemos obtenido el modelo de "
regresión basada en el aumento de gradiente ", capaz de predecir dentro del rango de 9.1 puntos (en el rango de 1 a 100) basado en datos de prueba.
Interpretación del modelo
La regresión de aumento de gradiente se encuentra aproximadamente en el medio de
la escala de interpretación del modelo : el modelo en sí es complejo, pero consta de cientos de
árboles de decisión bastante simples. Hay tres formas de entender cómo funciona nuestro modelo:
- Califica la importancia de los síntomas .
- Visualice uno de los árboles de decisión.
- Aplique el método LIME: explicaciones agnósticas del modelo local interpretable, explicaciones locales independientes del modelo interpretado.
Los dos primeros métodos son característicos de los conjuntos de árboles, y el tercero, como se puede entender por su nombre, se puede aplicar a cualquier modelo de aprendizaje automático. LIME es un enfoque relativamente nuevo, es un importante paso adelante en un intento de
explicar el funcionamiento del aprendizaje automático .
La importancia de los síntomas.
La importancia de los signos le permite ver la relación de cada signo con el objetivo de pronosticar. Los detalles técnicos de este método son complejos (
se mide la disminución media de la impureza o la
disminución del error debido a la inclusión de un rasgo ), pero podemos usar valores relativos para comprender qué rasgos son más relevantes. En Scikit-Learn, puede
extraer la importancia de los atributos de cualquier conjunto de "estudiantes" basado en árboles.
En el siguiente código,
model es nuestro modelo entrenado, y usando
model.feature_importances_ puede determinar la importancia de los atributos. Luego los enviamos al marco de datos Pandas y mostramos los 10 atributos más importantes:
import pandas as pd
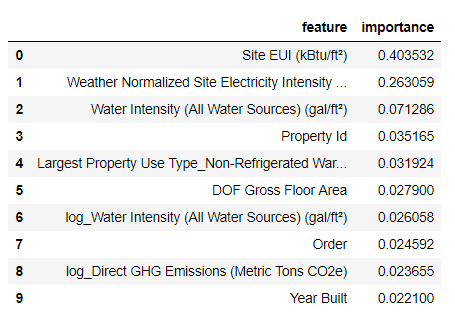
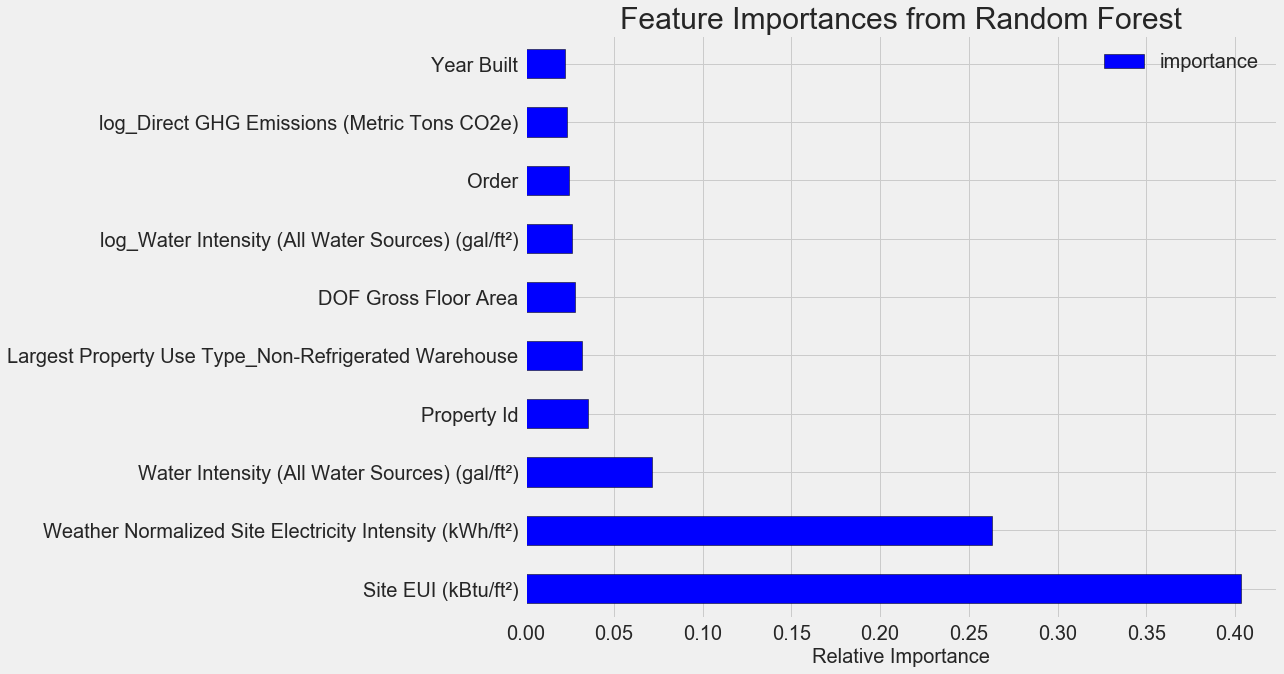
Las características más importantes son la
Site EUI (
Intensidad de consumo de energía ) y la
Weather Normalized Site Electricity Intensity , lo que representa más del 66% de la importancia total. Ya en el tercer atributo, la importancia se reduce enormemente, esto
sugiere que no necesitamos usar los 64 atributos para lograr una alta precisión de pronóstico (en el
cuaderno Jupyter, esta teoría se prueba usando solo los 10 atributos más importantes, y el modelo no era muy preciso).
Con base en estos resultados, una de las preguntas iniciales finalmente puede ser respondida: los indicadores más importantes de Energy Star Score son el EUI del sitio y la intensidad de la electricidad del sitio normalizado por el clima. No
profundizaremos en la jungla de la importancia de los atributos , solo diremos que con ellos puede comenzar a comprender el mecanismo de pronóstico del modelo.
Visualización de un solo árbol de decisión.
Es difícil comprender todo el modelo de regresión basado en el aumento de gradiente, que no se puede decir sobre los árboles de decisión individuales. Puede visualizar cualquier árbol utilizando la
Scikit-Learn- export_graphviz . Primero, extraiga el árbol del conjunto y luego guárdelo como un archivo de puntos:
from sklearn import tree
Usando el
visualizador Graphviz, convierta el archivo de puntos a png escribiendo:
dot -Tpng images/tree.dot -o images/tree.pngTengo un árbol de decisión completo:

Un poco engorroso! Aunque este árbol tiene solo 6 capas de profundidad, es difícil rastrear todas las transiciones. Cambiemos la
export_graphviz función
export_graphviz y
export_graphviz la profundidad del árbol a dos capas:
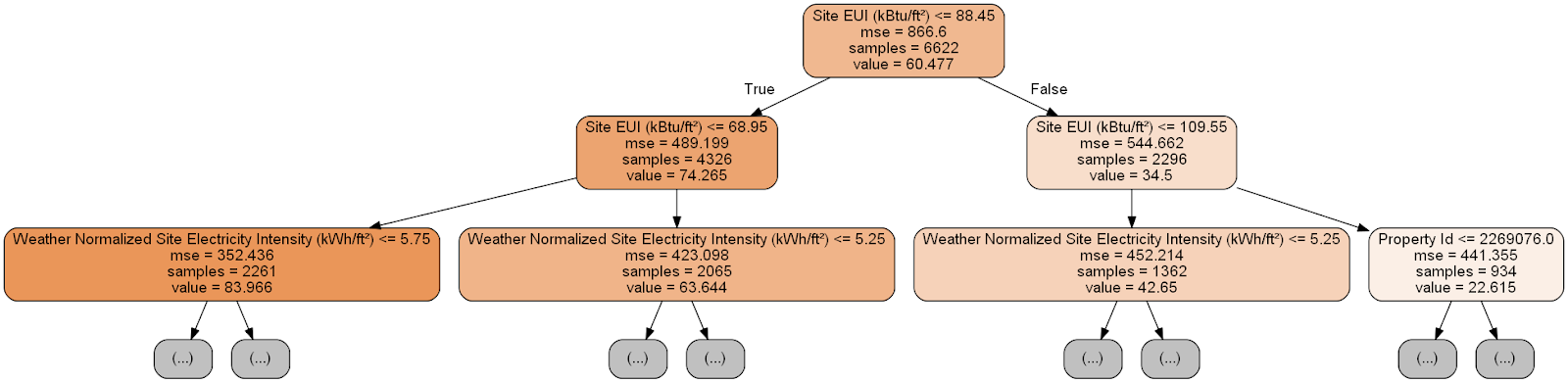
Cada nodo (rectángulo) del árbol contiene cuatro líneas:
- Pregunta formulada sobre el valor de uno de los signos de una dimensión particular: depende de en qué dirección saldremos de este nodo.
Mse es una medida de error en un nodo.Samples : la cantidad de muestras de datos (mediciones) en el nodo.Value : evaluación de objetivos para todas las muestras de datos en el nodo.
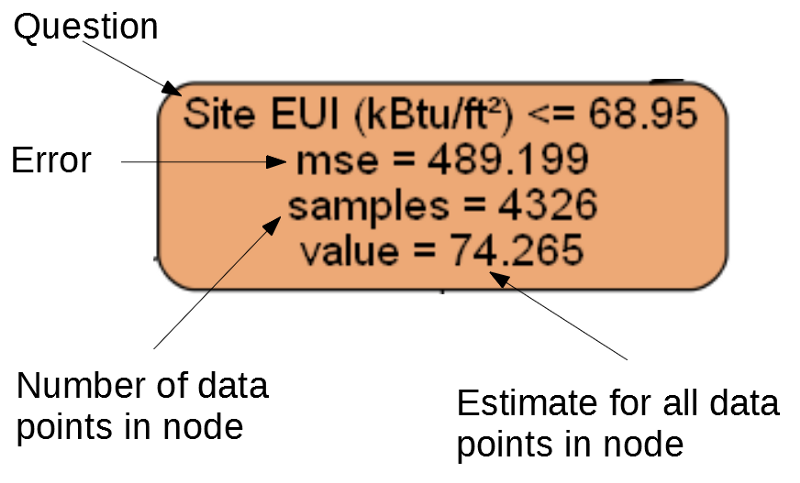 Nodo separado
Nodo separado(Las hojas contienen solo 2. –4., Porque representan la puntuación final y no tienen nodos secundarios).
El pronóstico para una medición determinada en el árbol de decisión comienza desde el nodo superior, la raíz, y luego desciende por el árbol. En cada nodo, debe responder a la pregunta "sí" o "no". Por ejemplo, la ilustración anterior pregunta: "¿El edificio EUI del sitio es inferior o igual a 68.95?" En caso afirmativo, el algoritmo va al nodo secundario derecho, si no, a la izquierda.
Este procedimiento se repite en cada capa del árbol hasta que el algoritmo alcanza el nodo hoja en la última capa (estos nodos no se muestran en la ilustración con el árbol reducido). El pronóstico para cualquier dimensión en la hoja de trabajo es el
value . Si varias mediciones llegan a la hoja, cada una de ellas recibirá el mismo pronóstico. A medida que aumenta la profundidad del árbol, el error en los datos de entrenamiento disminuirá, ya que habrá más hojas y las muestras se dividirán con más cuidado. Sin embargo, un árbol que es demasiado profundo conducirá a
un nuevo entrenamiento en los datos de entrenamiento y no podrá generalizar los datos de las pruebas.
En el
segundo artículo, configuramos el número de hiperparámetros modelo que controlan cada árbol, por ejemplo, la profundidad máxima del árbol y el número mínimo de muestras necesarias para cada hoja. Estos dos parámetros afectan fuertemente el equilibrio entre el aprendizaje excesivo y el aprendizaje insuficiente, y la visualización del árbol de decisiones nos permitirá comprender cómo funcionan estas configuraciones.
Aunque no podemos estudiar todos los árboles del modelo, un análisis de uno de ellos ayudará a comprender cómo predice cada "alumno". Este método basado en un diagrama de flujo es muy similar a cómo una persona toma una decisión.
Conjuntos de árboles de decisión combinan pronósticos de numerosos árboles individuales, lo que le permite crear modelos más precisos con menos variabilidad. Tales conjuntos son
muy precisos y fáciles de explicar.
Explicaciones locales dependientes del modelo interpretable (LIME)
La última herramienta con la que puede intentar averiguar cómo "piensa" nuestro modelo. LIME le permite explicar
cómo se genera un pronóstico único para cualquier modelo de aprendizaje automático . Para hacer esto, localmente, junto a alguna medición, se crea un modelo simplificado sobre la base de un modelo simple como la regresión lineal (los detalles se describen en este trabajo:
https://arxiv.org/pdf/1602.04938.pdf ).
Usaremos el método LIME para estudiar el pronóstico completamente erróneo de nuestro modelo y entender por qué está equivocado.
Primero encontramos este pronóstico incorrecto. Para hacer esto, entrenaremos el modelo, generaremos un pronóstico y seleccionaremos el valor con el mayor error:
from sklearn.ensemble import GradientBoostingRegressor
Predicción: 12.8615
Valor real: 100.0000Luego creamos un explicador y le damos los datos de entrenamiento, información de modo, etiquetas para los datos de entrenamiento y los nombres de los atributos. Ahora puede pasar al explicador los datos de observación y la función de pronóstico, y luego pedirles que expliquen el motivo del error de pronóstico.
import lime
Tabla de explicación de pronósticos:
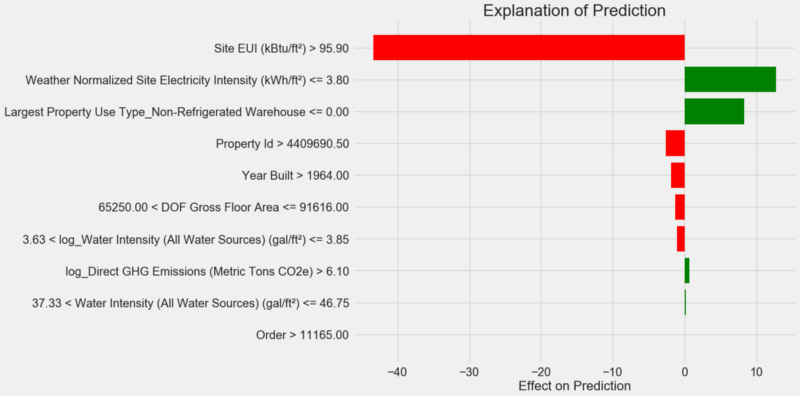
Cómo interpretar el diagrama: cada registro a lo largo del eje Y indica un valor de la variable, y las barras roja y verde reflejan la influencia de este valor en el pronóstico. Por ejemplo, de acuerdo con el registro superior, la influencia del
Site EUI más de 95.90, como resultado, se restan alrededor de 40 puntos del pronóstico. Según el segundo registro, la influencia de la
Weather Normalized Site Electricity Intensity inferior a 3,80 y, por lo tanto, se agregan unos 10 puntos al pronóstico. El pronóstico final es la suma de la intersección y los efectos de cada uno de los valores enumerados.
Miremos de otra manera y llamemos al método
.show_in_notebook() :

El proceso de toma de decisiones por el modelo se muestra a la izquierda: el efecto sobre el pronóstico de cada variable se visualiza visualmente. La tabla de la derecha muestra los valores reales de las variables para una medición dada.
En este caso, el modelo predijo unos 12 puntos, pero en realidad eran 100. Al principio, puede que se pregunte por qué sucedió esto, pero si analiza la explicación, resulta que esta no es una suposición extremadamente audaz, sino el resultado del cálculo basado en valores específicos.
Site EUI era relativamente alto y uno podría esperar un puntaje Energy Star bajo (porque está fuertemente influenciado por el EUI), lo que hizo nuestro modelo. Pero en este caso, esta lógica resultó ser errónea, porque de hecho, el edificio recibió el puntaje Energy Star más alto: 100.
Los errores del modelo pueden molestarlo, pero tales explicaciones lo ayudarán a comprender por qué el modelo estaba equivocado. Además, gracias a las explicaciones, puede comenzar a investigar por qué el edificio obtuvo el puntaje más alto a pesar del alto EUI del sitio. Quizás aprendamos algo nuevo sobre nuestra tarea que elude nuestra atención si no comenzamos a analizar los errores del modelo. Dichas herramientas no son ideales, pero pueden facilitar enormemente la comprensión del modelo y tomar
mejores decisiones .
Documentación del trabajo y presentación de resultados.
Muchos proyectos prestan poca atención a la documentación e informes. Puede hacer el mejor análisis del mundo, pero si no
presenta los resultados correctamente , ¡no importarán!
Al documentar un proyecto de análisis de datos, empaquetamos todas las versiones de los datos y el código para que otras personas puedan reproducir o recopilar el proyecto. Recuerde que el código se lee con más frecuencia que el escrito, por lo tanto, nuestro trabajo debe ser claro para otras personas y para nosotros, si volvemos a él en unos meses. Por lo tanto, inserte comentarios útiles en el código y explique sus decisiones.
Los cuadernos Jupyter son una gran herramienta para documentar; primero le permiten explicar las soluciones y luego mostrar el código.
Además, Jupyter Notebook es una buena plataforma para interactuar con otros especialistas. Usando las
extensiones para portátiles, puede
ocultar el código del informe final , porque no importa lo difícil que sea creerlo, ¡no todos quieren ver un montón de código en el documento!
Es posible que no desee hacer un apretón, pero muestre todos los detalles. Sin embargo, es importante
comprender a su audiencia al presentar su proyecto y
preparar un informe en consecuencia . Aquí hay un ejemplo de un resumen de la esencia de nuestro proyecto:
- Usando datos sobre el consumo de energía de los edificios en Nueva York, puede construir un modelo que prediga el número de puntos Energy Star con un error de 9.1 puntos.
- Site EUI y Weather Normalized Electricity Intensity son los principales factores que influyen en el pronóstico.
Escribimos una descripción detallada y conclusiones en el Jupyter Notebook, pero en lugar de PDF, convertimos el archivo .tex a
Latex , que luego editamos en
texStudio , y la
versión resultante se convirtió a PDF. El hecho es que el resultado de exportación predeterminado de Jupyter a PDF parece bastante decente, pero puede mejorarse enormemente en solo unos minutos de edición. Además, Latex es un poderoso sistema de preparación de documentos que es útil.
En última instancia, el valor de nuestro trabajo está determinado por las decisiones que ayuda a tomar, y es muy importante poder "entregar los productos en persona". Al documentar correctamente, ayudamos a otras personas a reproducir nuestros resultados y a darnos su opinión, lo que nos permitirá tener más experiencia y confiar en los resultados obtenidos en el futuro.
Conclusiones
En nuestra serie de publicaciones, hemos cubierto un tutorial de aprendizaje automático de principio a fin. Comenzamos limpiando los datos, luego creamos un modelo, y al final aprendimos cómo interpretarlo. Recordemos la estructura general del proyecto de aprendizaje automático:
- Limpieza y formateo de datos.
- Análisis exploratorio de datos.
- Diseño y selección de características.
- Comparación de las métricas de varios modelos de aprendizaje automático.
- Ajuste hiperparamétrico del mejor modelo.
- Evaluación del mejor modelo en un conjunto de datos de prueba.
- Interpretación de los resultados del modelo.
- Conclusiones e informe bien documentado.
El conjunto de pasos puede variar según el proyecto, y el aprendizaje automático a menudo es iterativo en lugar de lineal, por lo que esta guía lo ayudará en el futuro. Esperamos que ahora pueda implementar sus proyectos con confianza, pero recuerde: ¡nadie actúa solo! Si necesita ayuda, hay muchas comunidades muy útiles donde se le dará consejos.
Estas fuentes pueden ayudarlo: