Hola Habr! Te presento la traducción del artículo "Entrena tu primera red neuronal: clasificación básica" .

Esta es una guía de entrenamiento del modelo de red neuronal para clasificar imágenes de ropa como zapatillas y camisas. Para crear una red neuronal, usamos python y la biblioteca TensorFlow.
Instalar TensorFlow
Para el trabajo, necesitamos las siguientes bibliotecas:
- numpy (en la línea de comando escribimos: pip install numpy)
- matplotlib (en la línea de comando escribimos: pip install matplotlib)
- keras (en la línea de comando escribimos: pip install keras)
- jupyter (en la línea de comando escribimos: pip install jupyter)
Usando pip: en la línea de comando, escriba pip install tensorflow
Si obtiene un error, puede descargar el archivo .whl e instalarlo usando pip: pip install file_path \ file_name.whl
Guía de instalación oficial de TensorFlow
Lanza Jupyter. Para comenzar en la línea de comando, escriba jupyter notebook.
Empezando
Esta guía utiliza el conjunto de datos Fashion MNIST, que contiene 70,000 imágenes en escala de grises en 10 categorías. Las imágenes muestran prendas individuales de baja resolución (28 por 28 píxeles):

Utilizaremos 60,000 imágenes para entrenar a la red y 10,000 imágenes para evaluar la precisión con que la red ha aprendido a clasificar las imágenes. Puede acceder a Fashion MNIST directamente desde TensorFlow simplemente importando y descargando datos:
fashion_mnist = keras.datasets.fashion_mnist (train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
La carga de un conjunto de datos devuelve cuatro matrices NumPy:
- Las matrices train_images y train_labels son los datos que utiliza el modelo para la capacitación.
- Las matrices test_images y test_labels se utilizan para probar el modelo.
Las imágenes son matrices NumPy de 28x28 cuyos valores de píxeles varían de 0 a 255. Las etiquetas son una matriz de enteros de 0 a 9. Corresponden a la clase de ropa:
| Etiqueta | Clase |
| 0 0 | Camiseta (camiseta) |
| 1 | Pantalón (pantalones) |
| 2 | Jersey (suéter) |
| 3 | Vestido |
| 4 4 | Abrigo (abrigo) |
| 5 5 | Sandalia |
| 6 6 | Camisa |
| 7 7 | Sneaker (zapatillas de deporte) |
| 8 | Bolsa |
| 9 9 | Botines (Botines) |
Los nombres de clase no están incluidos en el conjunto de datos, por lo que lo prescribimos nosotros mismos:
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
Exploración de datos.
Considere el formato del conjunto de datos antes de entrenar el modelo.
train_images.shape
Preprocesamiento de datos
Antes de preparar el modelo, los datos deben ser preprocesados. Si marca la primera imagen en el conjunto de entrenamiento, verá que los valores de píxeles están en el rango de 0 a 255:
plt.figure() plt.imshow(train_images[0]) plt.colorbar() plt.grid(False)

Escalamos estos valores a un rango de 0 a 1:
train_images = train_images / 255.0 test_images = test_images / 255.0
Mostramos las primeras 25 imágenes del conjunto de entrenamiento y mostramos el nombre de la clase debajo de cada imagen. Asegúrese de que los datos estén en el formato correcto.
plt.figure(figsize=(10,10)) for i in range(25): plt.subplot(5,5,i+1) plt.xticks([]) plt.yticks([]) plt.grid(False) plt.imshow(train_images[i], cmap=plt.cm.binary) plt.xlabel(class_names[train_labels[i]])

Edificio modelo
La construcción de una red neuronal requiere capas de ajuste del modelo.
El bloque de construcción principal de la red neuronal es la capa. La mayor parte del aprendizaje profundo consiste en combinar capas simples. La mayoría de las capas, como tf.keras.layers.Dense, tienen parámetros que se aprenden durante el entrenamiento.
model = keras.Sequential([ keras.layers.Flatten(input_shape=(28, 28)), keras.layers.Dense(128, activation=tf.nn.relu), keras.layers.Dense(10, activation=tf.nn.softmax) ])
La primera capa en la red tf.keras.layers.Flatten convierte el formato de imagen de una matriz 2d (28 por 28 píxeles) en una matriz 1d de 28 * 28 = 784 píxeles. Esta capa no tiene parámetros para estudiar, solo reformatea los datos.
Las siguientes dos capas son tf.keras.layers.Dense. Estas son capas neurales estrechamente conectadas o completamente conectadas. La primera capa densa contiene 128 nodos (o neuronas). El segundo (y último) nivel es una capa con 10 nodos tf.nn.softmax, que devuelve una matriz de diez estimaciones de probabilidad, cuya suma es 1. Cada nodo contiene una estimación que indica la probabilidad de que la imagen actual pertenezca a una de 10 clases.
Compilando un modelo
Antes de que el modelo esté listo para el entrenamiento, necesitará algunas configuraciones más. Se agregan durante la fase de compilación del modelo:
- Función de pérdida: mide la precisión del modelo durante el entrenamiento
- Optimizer es cómo se actualiza el modelo en función de los datos que ve y la función de pérdida.
- Métricas (métricas): se utilizan para controlar las etapas de capacitación y pruebas.
model.compile(optimizer=tf.train.AdamOptimizer(), loss='sparse_categorical_crossentropy', metrics=['accuracy'])
Entrenamiento modelo
Aprender un modelo de red neuronal requiere los siguientes pasos:
- Envío de datos de entrenamiento modelo (en este ejemplo, matrices train_images y train_labels)
- Un modelo aprende a asociar imágenes y etiquetas.
- Le pedimos al modelo que haga predicciones sobre el conjunto de pruebas (en este ejemplo, la matriz test_images). Verificamos la conformidad de los pronósticos de etiquetas de la matriz de etiquetas (en este ejemplo, la matriz test_labels)
Para comenzar a entrenar, llama al método model.fit:
model.fit(train_images, train_labels, epochs=5)
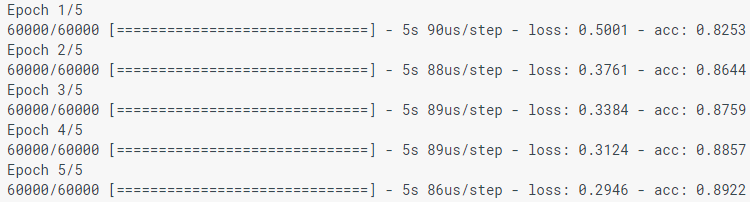
Al modelar el modelo, se muestran los indicadores de pérdida (pérdida) y precisión (acc). Este modelo logra una precisión de aproximadamente 0,88 (o 88%) según los datos de entrenamiento.
Calificación de precisión
Compare cómo funciona el modelo en un conjunto de datos de prueba:
test_loss, test_acc = model.evaluate(test_images, test_labels) print('Test accuracy:', test_acc)

Resulta que la precisión en el conjunto de datos de prueba es ligeramente menor que la precisión en el conjunto de datos de entrenamiento. Esta brecha entre la precisión del entrenamiento y la precisión de las pruebas es un ejemplo de reentrenamiento. La reentrenamiento es cuando un modelo de aprendizaje automático funciona peor con datos nuevos que con datos de entrenamiento.
Previsión
Usamos el modelo para predecir algunas imágenes.
predictions = model.predict(test_images)
Aquí, el modelo predijo la etiqueta para cada imagen en el caso de prueba. Veamos la primera predicción:
predictions[0]

La predicción es una matriz de 10 números. Describen la "confianza" del modelo de que la imagen corresponde a cada una de las 10 prendas diferentes. Podemos ver qué etiqueta tiene el valor de confianza más alto:
np.argmax(predictions[0])
Por lo tanto, el modelo está más seguro de que esta imagen es Ankle boot (Botines) o class_names [9]. Y podemos verificar la etiqueta de prueba para asegurarnos de que esto sea correcto:
test_labels[0]
Escribiremos funciones para visualizar estas predicciones.
def plot_image(i, predictions_array, true_label, img): predictions_array, true_label, img = predictions_array[i], true_label[i], img[i] plt.grid(False) plt.xticks([]) plt.yticks([]) plt.imshow(img, cmap=plt.cm.binary) predicted_label = np.argmax(predictions_array) if predicted_label == true_label: color = 'blue' else: color = 'red' plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label], 100*np.max(predictions_array), class_names[true_label]), color=color) def plot_value_array(i, predictions_array, true_label): predictions_array, true_label = predictions_array[i], true_label[i] plt.grid(False) plt.xticks([]) plt.yticks([]) thisplot = plt.bar(range(10), predictions_array, color="#777777") plt.ylim([0, 1]) predicted_label = np.argmax(predictions_array) thisplot[predicted_label].set_color('red') thisplot[true_label].set_color('blue')
Veamos la imagen número 0, las predicciones y una serie de predicciones.
i = 0 plt.figure(figsize=(6,3)) plt.subplot(1,2,1) plot_image(i, predictions, test_labels, test_images) plt.subplot(1,2,2) plot_value_array(i, predictions, test_labels)

Construyamos algunas imágenes con sus pronósticos. Las etiquetas de pronóstico correctas son azules y las etiquetas de pronóstico incorrectas son rojas. Tenga en cuenta que esto puede estar mal incluso cuando tiene mucha confianza.
num_rows = 5 num_cols = 3 num_images = num_rows*num_cols plt.figure(figsize=(2*2*num_cols, 2*num_rows)) for i in range(num_images): plt.subplot(num_rows, 2*num_cols, 2*i+1) plot_image(i, predictions, test_labels, test_images) plt.subplot(num_rows, 2*num_cols, 2*i+2) plot_value_array(i, predictions, test_labels)

Finalmente, usamos un modelo entrenado para hacer una predicción sobre una sola imagen.
Los modelos Tf.keras están optimizados para hacer predicciones para paquetes (lote) o colecciones (colección). Por lo tanto, aunque usamos una sola imagen, debemos agregarla a la lista:
Pronóstico para la imagen:
predictions_single = model.predict(img) print(predictions_single)

plot_value_array(0, predictions_single, test_labels) _ = plt.xticks(range(10), class_names, rotation=45)

np.argmax(predictions_single[0])
Como antes, el modelo predice la etiqueta 9.
Si tiene preguntas, escriba en los comentarios o en mensajes privados.