El desarrollo de redes neuronales profundas para el reconocimiento de imágenes da nueva vida a las áreas ya conocidas de investigación en aprendizaje automático. Una de esas áreas es la adaptación del dominio. La esencia de esta adaptación es entrenar el modelo en los datos del dominio de origen (dominio de origen) para que muestre una calidad comparable en el dominio de destino (dominio de destino). Por ejemplo, un dominio de origen puede ser datos sintéticos que pueden generarse a bajo costo, y un dominio de destino puede ser fotos de usuarios. Entonces, la tarea de la adaptación del dominio es entrenar el modelo en datos sintéticos, que funcionarán bien con objetos "reales".
En el grupo de visión artificial Visionfont>.Ru, estamos trabajando en varios problemas aplicados, y entre ellos a menudo hay aquellos para los que hay pocos datos de capacitación. En estos casos, la generación de datos sintéticos y la adaptación del modelo entrenado en ellos pueden ser de gran ayuda. Un buen ejemplo aplicado de este enfoque es la tarea de detectar y reconocer productos en los estantes de una tienda. Obtener fotos de estos estantes y marcarlos es bastante laborioso, pero se pueden generar de manera bastante simple. Por lo tanto, decidimos profundizar en el tema de la adaptación del dominio.

Los estudios en la adaptación del dominio afectan el uso de la experiencia previa obtenida por una red neuronal en una nueva tarea. ¿Podrá la red extraer algunas características del dominio de origen y usarlas en el dominio de destino? Aunque una red neuronal en el aprendizaje automático solo está relacionada de forma distante con las redes neuronales en el cerebro humano, sin embargo, el santo grial de los investigadores de inteligencia artificial es enseñar a las redes neuronales las capacidades que tiene una persona. Y las personas pueden usar la experiencia previa y el conocimiento acumulado para comprender nuevos conceptos.
Además, la adaptación del dominio puede ayudar a resolver uno de los problemas fundamentales del aprendizaje profundo: para entrenar grandes redes con alta calidad de reconocimiento, se necesita una gran cantidad de datos, que en la práctica no siempre está disponible. Una solución puede ser utilizar métodos de adaptación de dominio en datos sintéticos que pueden generarse en cantidades prácticamente ilimitadas.
Muy a menudo en los problemas aplicados hay un caso en el que los datos de un solo dominio están disponibles para capacitación, y el modelo debe aplicarse en otro dominio. Por ejemplo, la red que determina la calidad estética de la fotografía se puede entrenar en una base de datos disponible en la red, recopilada del sitio web de aficionados. Y está previsto utilizar esta red en fotografías comunes, cuyo nivel de calidad difiere en promedio del nivel de una foto de un sitio especializado en fotografía. Como solución, podemos considerar adaptar el modelo a fotografías ordinarias sin etiqueta.
Tales preguntas teóricas y aplicadas se encuentran en el dominio de la adaptación. En este artículo, hablaré sobre la investigación principal en esta área, basada en el aprendizaje profundo y los conjuntos de datos para comparar diferentes métodos. La idea principal de la adaptación del dominio profundo es entrenar una red neuronal profunda en el dominio fuente, lo que traducirá la imagen en una incrustación (generalmente la última capa de la red) que cuando se usa en el dominio objetivo, se obtendrá una alta calidad.
Puntos de referencia centrales
Como en cualquier campo del aprendizaje automático, una cierta cantidad de investigación se acumula en la adaptación del dominio a lo largo del tiempo, que debe compararse entre sí. Para esto, la comunidad desarrolla conjuntos de datos, en la parte de capacitación de la cual se capacitan los modelos, y en la parte de prueba se comparan. A pesar del hecho de que el dominio de investigación de la adaptación de dominio profundo aún es relativamente joven, ya hay un número bastante grande de artículos y bases de datos que se utilizan en estos artículos. Voy a enumerar los principales, centrándome en adaptar el dominio de datos sintéticos a "real".
Figuras
Aparentemente, según la tradición instituida por Yann LeCun (uno de los pioneros del aprendizaje profundo, director de Facebook AI Research), en la visión por computadora, los conjuntos de datos más simples están asociados con números o letras escritos a mano. Existen varios conjuntos de datos con números que aparecieron originalmente para experimentar con modelos de reconocimiento de imágenes. En los artículos sobre la adaptación del dominio, uno puede encontrar una variedad de sus combinaciones en pares de dominio fuente - destino. Entre estos conjuntos de datos:
- MNIST : números escritos a mano, no necesita presentación adicional;
- USPS : números escritos a mano en baja resolución;
- SVHN : números de casa con Google Street View;
- Los números de sintetizador son números sintéticos, como su nombre indica.
Desde el punto de vista de la tarea de entrenamiento en datos sintéticos para su uso en el mundo "real", los más interesantes son los pares:
- Fuente: MNIST, Destino: SVHN;
- Fuente: USPS, Meta: MNIST;
- Fuente: Números de sintetizador, Objetivo: SVHN.

La mayoría de los métodos tienen puntos de referencia en conjuntos de datos "digitales". Pero los otros tipos de dominios se pueden encontrar lejos de todos los artículos.
Oficina
Este conjunto de datos contiene 31 categorías de varios elementos, cada uno de los cuales está representado en 3 dominios: una imagen de Amazon, una foto de una cámara web y una foto de una cámara digital.

Es útil para verificar cómo responderá el modelo al agregar fondo y calidad al dominio de destino.
Señales de tráfico
Otro par de conjuntos de datos para entrenar el modelo en datos sintéticos y aplicarlo a datos "reales":
- Fuente: Synth Signs : imágenes de señales de tráfico generadas para que se vean como señales reales en la calle;
- Objetivo: GTSRB es una base de reconocimiento bastante conocida que contiene señales de carreteras alemanas.

Una característica de este par de bases de datos es que los datos de Synth Signs se hacen bastante similares a los datos "reales", por lo que los dominios están bastante cerca.
Desde la ventana del coche
Conjuntos de datos para la segmentación. Una pareja bastante interesante, la más cercana a las condiciones reales. Los datos de origen se obtienen utilizando el motor del juego (GTA 5), y los datos de destino son de la vida real. Se utilizan enfoques similares para entrenar modelos que se utilizan en automóviles autónomos.
- Motor SYNTHIA o GTA 5: imágenes de una vista de la ciudad desde la ventanilla de un automóvil generada con un motor de juego;
- Paisajes urbanos : fotografías de un automóvil tomadas en 50 ciudades diferentes.

VisDA
Este conjunto de datos se utiliza en el desafío de adaptación del dominio visual , que forma parte de un taller sobre ECCV e ICCV. El dominio fuente contiene 12 categorías de objetos etiquetados generados usando CAD, como un avión, un caballo, una persona, etc. El dominio de destino contiene imágenes sin etiquetar de las mismas 12 categorías tomadas de ImageNet. En la competencia, que se celebró en 2018, se agregó la 13a categoría: Desconocida.
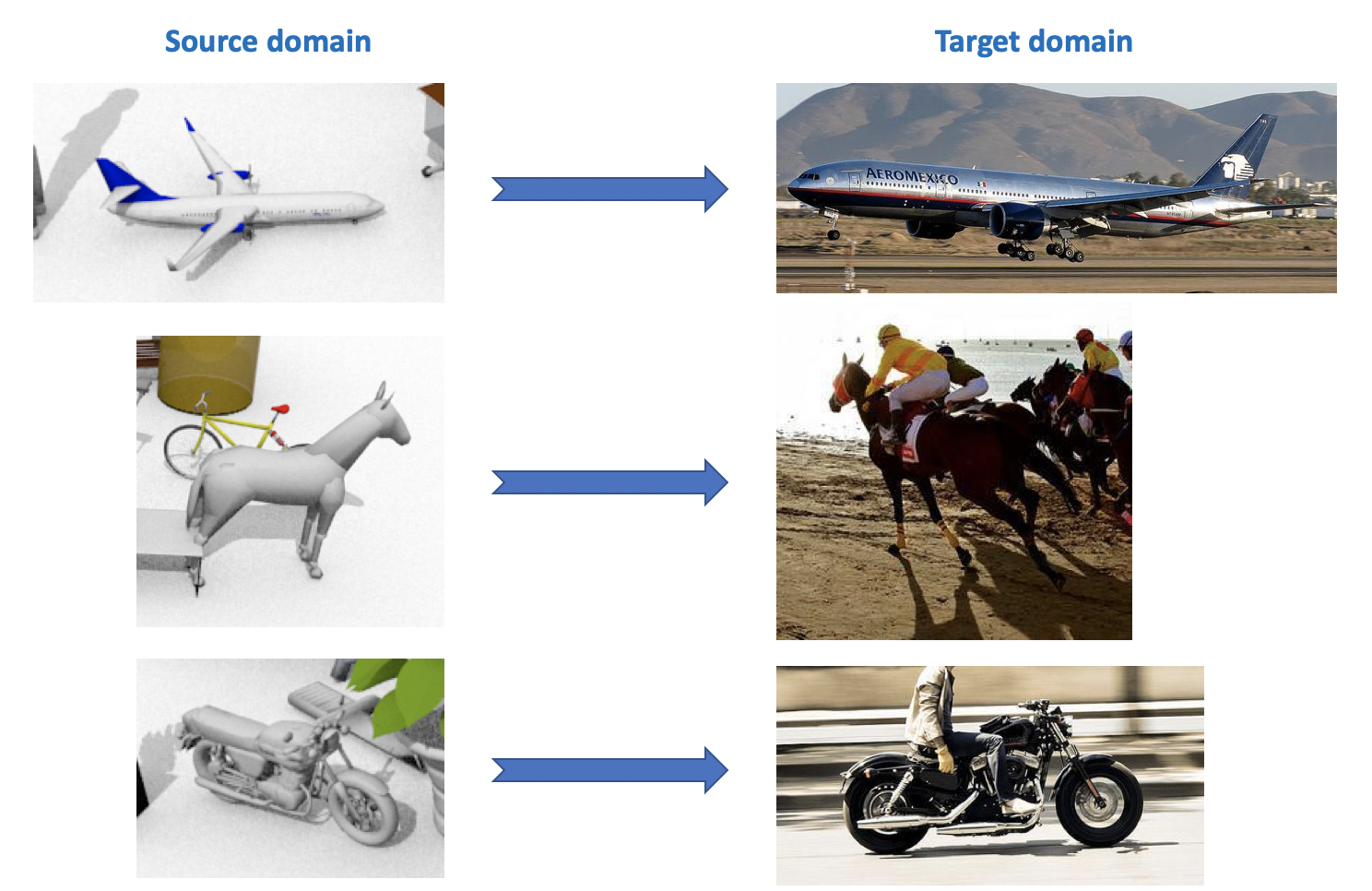
Como puede ver en todo lo anterior, hay muchos conjuntos de datos interesantes y diversos para la adaptación del dominio, puede entrenar y probar modelos para ellos para diversas tareas (clasificación, segmentación, detección) y diversas condiciones (datos sintéticos, fotos, vistas de la calle).
Adaptación profunda del dominio
Existe una clasificación bastante extensa y variada de los métodos de adaptación de dominio (por ejemplo , ver aquí ). Daré en este artículo una división simplificada de métodos según sus características clave. Los métodos modernos de adaptación de dominio profundo se pueden dividir en 3 grandes grupos:
- Basado en la discrepancia : enfoques basados en minimizar la distancia entre las representaciones de vectores en los dominios de origen y destino mediante la introducción de esta distancia en la función de pérdida.
- Basado en Adversarial : estos enfoques utilizan la función de pérdida de adversario introducida en las GAN para entrenar una red invariante de dominio. Los métodos de esta familia se han desarrollado activamente en los últimos años.
- Métodos mixtos que no utilizan la pérdida de adversarios, pero aplican ideas de la familia basada en discrepancias, así como los últimos desarrollos del aprendizaje profundo: autoensamblaje, nuevas capas, funciones de pérdida, etc. Estos enfoques muestran los mejores resultados en la competencia de VisDA.
De cada sección, se considerarán varios resultados básicos, en mi opinión, obtenidos en los últimos 1-3 años.
Basado en la discrepancia
Cuando surge el problema de adaptar un modelo a nuevos datos, lo primero que viene a la mente es el uso del ajuste fino, es decir reentrenar el modelo en nuevos datos. Para hacer esto, considere la discrepancia entre los dominios. Este tipo de adaptación de dominio se puede dividir en tres enfoques: Criterio de clase, criterio estadístico y criterio de arquitectura.
Criterio de clase
Los métodos de esta familia se utilizan principalmente cuando tenemos acceso a datos etiquetados del dominio de destino. Una de las opciones populares para Criterio de clase es el enfoque de aprendizaje métrico de transferencia profunda . Como su nombre lo indica, se basa en el aprendizaje métrico, cuya esencia es entrenar tal representación vectorial obtenida de una red neuronal que los representantes de una clase estarán cerca uno del otro en esta representación de acuerdo con una métrica dada (uso más frecuente L 2 o métricas de coseno). En el artículo Aprendizaje métrico de transferencia profunda (DTML) , se utiliza una pérdida que consiste en la suma de términos para implementar este enfoque:
- La proximidad de representantes de una clase entre sí (compacidad intraclase);
- Mayor distancia entre representantes de diferentes clases (separabilidad entre clases);
- Métrica de máxima discrepancia media (MMD) entre dominios. Esta métrica pertenece a la familia de criterios estadísticos (ver más abajo), pero también se usa en el criterio de clase.
MMD entre dominios se escribe como
MMD2(Ds,Dt)= Vert frac1M sumMi=1 phi(xsi)− frac1N sumNj=1 phi(xtj) Vert2H,
donde phi(x) - este es un núcleo, en nuestro caso - una representación vectorial de la red, xsi,i en1 ldotsM - datos del dominio de origen, xti,i en1 ldotsN - datos del dominio de destino. Por lo tanto, al minimizar la métrica MMD durante el entrenamiento, se selecciona dicha red phi(x) para que sus representaciones vectoriales promedio en ambos dominios estén cercanas. La idea principal de DTML:
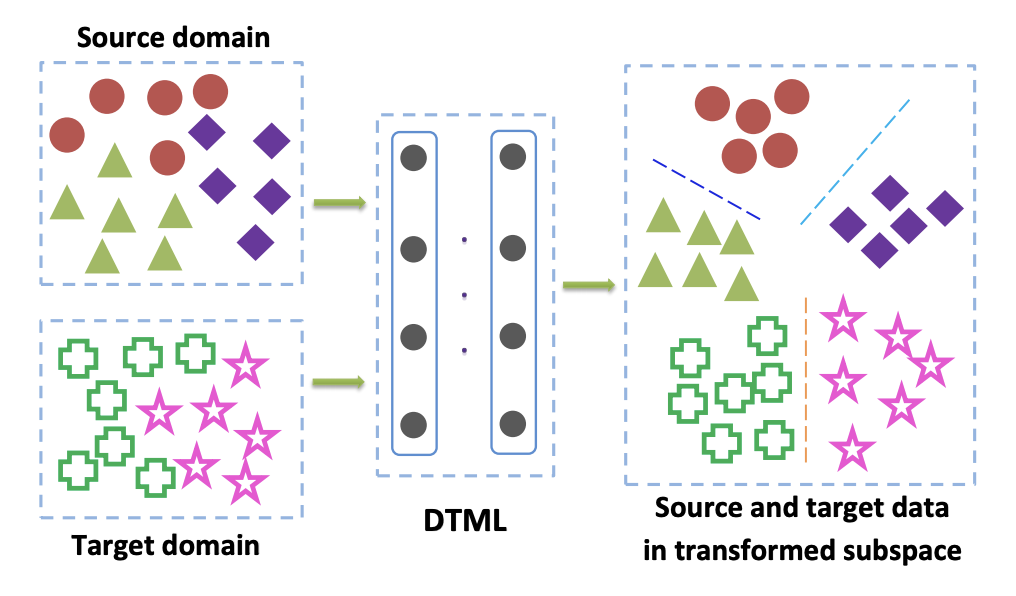
Si los datos en el dominio de destino no están etiquetados (adaptación de dominio sin supervisión), el método descrito en Mind the Class Sesgo de ponderación: Discrepancia media máxima ponderada para la adaptación de dominio sin supervisión ofrece entrenar el modelo en el dominio de origen y usarlo para obtener pseudo-etiquetas (pseudo- etiquetas) en el dominio de destino. Es decir los datos del dominio de destino se ejecutan a través de la red y el resultado se denomina pseudoetiquetas. Luego, se utilizan como marcado para el dominio de destino, lo que permite aplicar el criterio MMD en la función de pérdida (con diferentes pesos para los componentes responsables de los diferentes dominios).
Criterio estadistico
Los métodos relacionados con esta familia se utilizan para resolver el problema de adaptación de dominio no supervisado. El caso cuando el dominio de destino no está asignado se produce en muchas tareas, y todos los métodos de adaptación del dominio, que se discutirán más adelante en este artículo, resuelven exactamente ese problema.
Los enfoques basados en criterios estadísticos intentan medir la diferencia entre las distribuciones de la representación vectorial de la red obtenida de los datos de los dominios de origen y destino. Luego usan la diferencia calculada para unir estas dos distribuciones.
Uno de estos criterios es la máxima discrepancia media (MMD) ya descrita anteriormente. Sus variantes se utilizan en varios métodos:
Los diagramas de estos tres métodos se presentan a continuación. En ellos, las variantes MMD se utilizan para determinar la diferencia entre las distribuciones en las capas de la red neuronal convolucional aplicada a los dominios de origen y destino. Tenga en cuenta que cada uno de ellos utiliza la modificación MMD como una pérdida entre capas de redes de convolución (figuras amarillas en el diagrama).

El criterio CORAL (alineación de correlación) y su extensión con la ayuda de las redes Deep CORAL tienen como objetivo aprender dicha representación de datos para que las estadísticas de segundo orden entre dominios coincidan al máximo. Para esto, se utilizan matrices de covarianza de representaciones vectoriales de la red. La convergencia de estadísticas de segundo orden en ambos dominios en algunos casos permite obtener mejores resultados de adaptación que para MMD.
LCORAL= frac14d2 VertCS−CT Vert2F,
donde ||∗||2F Es el cuadrado de la norma de la matriz de Frobenius, y Cs y Ct - datos de matriz de covarianza de los dominios de origen y destino, respectivamente, d - la dimensión de la representación vectorial.
En el conjunto de datos de Office, la calidad promedio de adaptación con Deep CORAL para pares de dominios de Amazon y Webcam es del 72.1%. En Synth Signs -> GTSRB dominios de señales de tráfico, el resultado también es muy promedio: precisión del 86.9% en el dominio de destino.
El desarrollo de las ideas de MMD y CORAL es el criterio de discrepancia de momento central (CMD) , que compara los momentos centrales de los datos de los dominios de origen y destino de todos los pedidos hasta K inclusivo ( K - parámetro del algoritmo). En el conjunto de datos de Office, la calidad de adaptación CMD promedio para pares de dominios de Amazon y Webcam es 77.0%.
Criterio de arquitectura
Los algoritmos de este tipo se basan en el supuesto de que la información básica que se encarga de adaptarse a un nuevo dominio está incrustada en los parámetros de una red neuronal.
En varios documentos [1] , [2], cuando se entrena redes para los dominios de origen y destino utilizando funciones de pérdida para cada par de capas, se estudia la información que es invariante con respecto al dominio sobre los pesos de estas capas. Un ejemplo de tales arquitecturas se da a continuación.
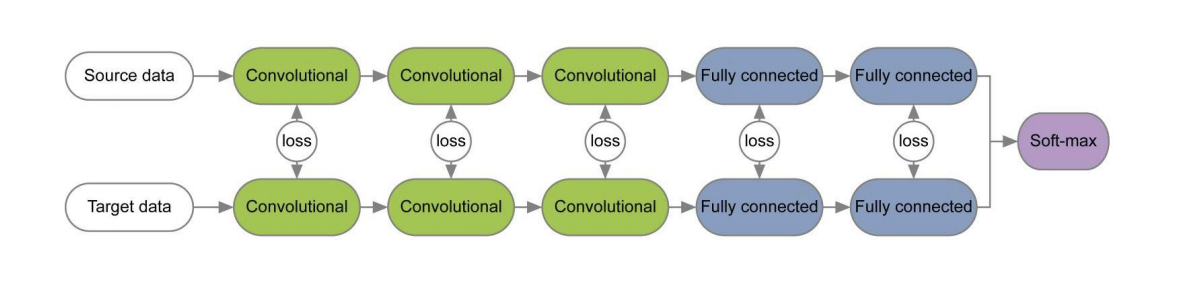
En el artículo " Revisitando la normalización de lotes para la adaptación práctica de dominios", se planteó la idea de que las escalas de la red contienen información relacionada con las clases en las que está estudiando la red, y la información del dominio está incrustada en las estadísticas (media y desviación estándar) de las capas de Normalización de lotes (BN). Por lo tanto, para la adaptación, es necesario volver a calcular estas estadísticas en los datos del dominio de destino. El uso de esta técnica junto con CORAL puede mejorar la calidad de la adaptación en el conjunto de datos de Office para pares de dominios de Amazon y Webcam hasta en un 75.0%. Luego se demostró que el uso de la capa de Normalización de Instancia (IN) en lugar de BN mejora aún más la calidad de la adaptación. A diferencia de BN, que normaliza el tensor de entrada para lotes, IN calcula estadísticas para la normalización por canales y, por lo tanto, no depende del lote.
Enfoques adversarios
En los últimos 1-2 años, la mayoría de los resultados en la adaptación del dominio profundo están relacionados con el enfoque basado en la confrontación. Esto se debe en gran parte al rápido desarrollo y popularidad de las Redes Adversarias Generativas (GAN) , ya que el enfoque basado en la confrontación para la adaptación del dominio utiliza la misma función objetiva de confrontación en la capacitación que la GAN. Al optimizarlo, estos métodos de adaptación de dominio profundo minimizan la distancia entre las distribuciones empíricas de las representaciones de datos vectoriales en los dominios de origen y destino. Al entrenar a la red de esta manera, intentan hacerla invariable con respecto al dominio.
GAN consta de dos modelos: generador G , a la salida de los cuales se obtienen datos de una distribución objetivo determinada; y discriminador D , que determina si los datos del conjunto de entrenamiento o generados usando G . Estos dos modelos se entrenan utilizando la función objetiva adversarial:
minG maxDV(D,G)= mathbbEx simpdata(x)[ logD(x)]+ mathbbEz simp(z)[1− logD(G(z))].
Con dicha capacitación, el generador aprende a "engañar" al discriminador, lo que le permite acercar la distribución de los dominios objetivo y fuente.
Hay dos grandes enfoques en la adaptación del dominio basado en la confrontación que difieren en si se usa o no un generador. G .
Modelos no generativos
Una característica clave de los métodos de esta familia es el entrenamiento de una red neuronal con una representación vectorial que es invariante con respecto a los dominios de origen y destino. Entonces, la red entrenada en el dominio de origen marcado puede usarse en el dominio de destino, idealmente, prácticamente sin pérdida de calidad de clasificación.
Introducido en 2015, el algoritmo ( código ) de Entrenamiento de dominio de redes neuronales (DANN ) consta de 3 partes:
- La red principal, con la ayuda de la cual se obtiene una representación vectorial (extractor de características) (la parte verde en la siguiente ilustración);
- "Jefes" responsables de la clasificación en el dominio de origen (parte azul en la ilustración);
- Una "cabeza" que aprende a distinguir los datos del dominio de origen del dominio de destino (la parte roja en la ilustración).
Cuando se entrena usando el descenso de gradiente (SGD) (flechas para ingresar en la ilustración), las pérdidas de clasificación y dominio se minimizan. Además, durante la propagación hacia atrás de un error de aprendizaje para la "cabeza" responsable de los dominios, se utiliza la capa de inversión de Gradiente (la parte negra en la ilustración), que multiplica el gradiente que lo atraviesa por una constante negativa, aumentando la pérdida de dominio. Esto asegura que las distribuciones de representaciones vectoriales en ambos dominios se vuelvan cercanas.
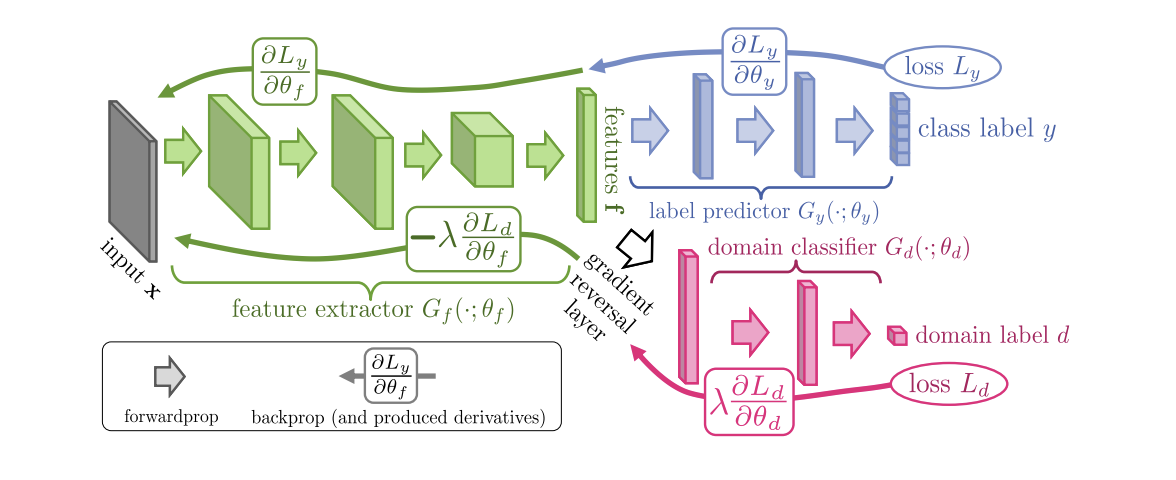
Resultados de referencia de DANN:
- En un par de dominios digitales Números de sintetizador -> SVHN: 91.09%.
- En Synth Signs -> señales de tráfico GTSRB, supera CORAL con un resultado del 88,7%.
- En el conjunto de datos de Office, la calidad de adaptación promedio para pares de dominios de Amazon y Webcam es del 73.0%.
El siguiente representante importante de la familia de modelos no generativos es el método ( código ) de Adaptación de Dominio Discriminatorio Adversario (ADDA ), que implica la separación de la red para el dominio de origen y la red para el dominio de destino. El algoritmo consta de los siguientes pasos:
- Primero, entrenamos la red de clasificación en el dominio de origen. Denotamos su representación vectorial Ms y mathbfXs - dominio fuente.
- Ahora inicialice la red neuronal para el dominio de destino utilizando la red entrenada del paso anterior. Dejala Mt y mathbfXt - dominio de destino.
- Pasemos al entrenamiento de confrontación: entrenaremos al discriminador D en fijo Ms y Mt utilizando la siguiente función objetivo:
minDLadvD( mathbfXs, mathbfXt,Ms,Mt)=− mathbbExs sim mathbfXs[ logD(Ms(xs))]− mathbbExt sim mathbfXt[ log(1−D(Mt(xt)))]
- Congelador discriminador y reciclaje Mt en el dominio de destino:
minMs,MtLadvM( mathbfXs, mathbfXt,D)=− mathbbExt sim mathbfXt[ logD(Mt(xt))]
3 4 . ADDA , , adversarial- , . :
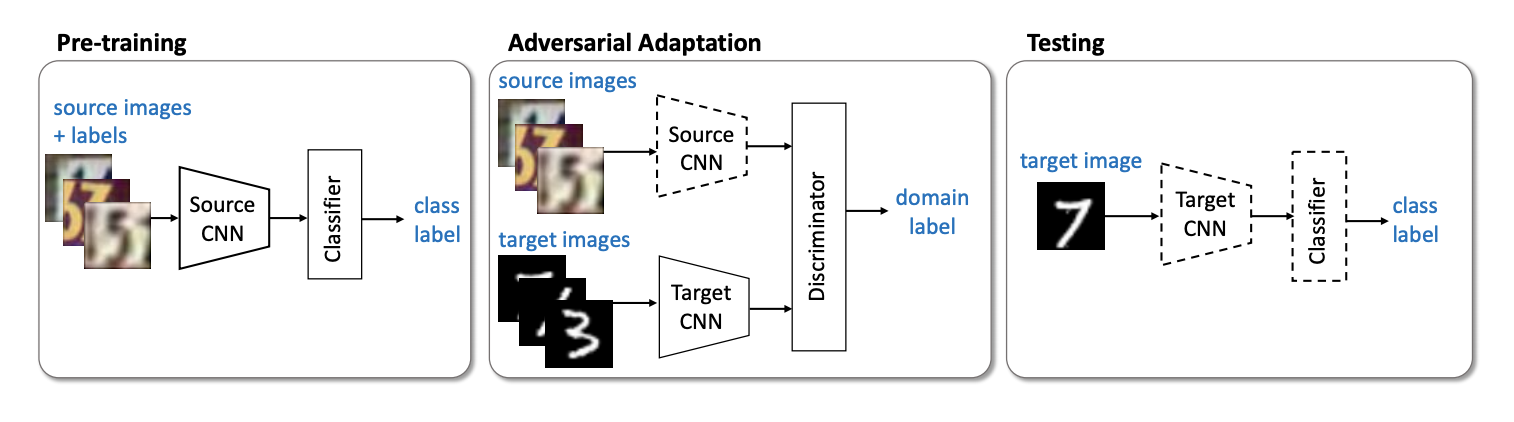
USPS -> MNIST ADDA 90,1 % .
ADDA ICML-2018 M-ADDA: Unsupervised Domain Adaptation with Deep Metric Learning ( ).
, M-ADDA metric learning, L2 -. 1 ADDA - Triplet loss ( ( ) ). , K ( K — ). Cj,j∈1…K .
ADDA, .. 2-4. 4 , Cj , :
Ext∼Xt[minj||Mt(xt)−Cj||2].
.
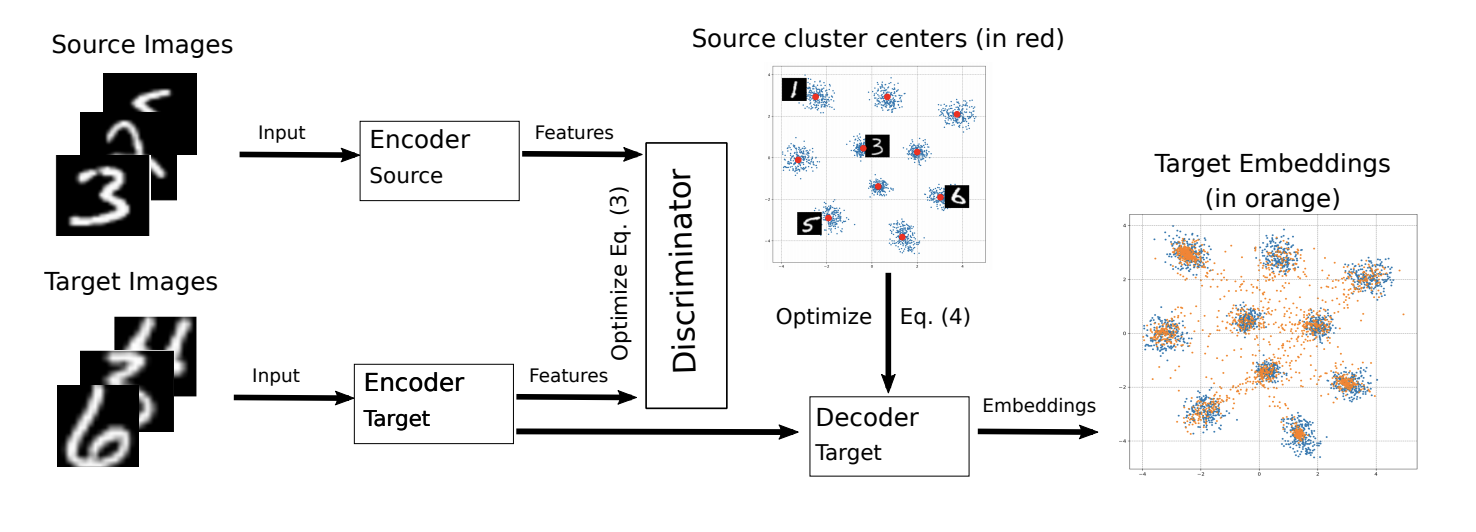
M-ADDA USPS -> MNIST 94,0 %.
non-generative Maximum Classifier Discrepancy for Unsupervised Domain Adaptation ( ). (), . , , .
G — , F1 y F2 — , . , G , F1 y F2 -; , ; , ; F1 y F2 .
, adversarial-, G , .
(Discrepancy Loss)
d(p1,p2)=1KK∑k=1|p1k−p2k|,
K — , p1kp2k — softmax k - F1 y F2 .
3 :
- A. G , F1 y F2 .
- B. , .
- C . , , Discrepancy Loss.
n ( ). B C:
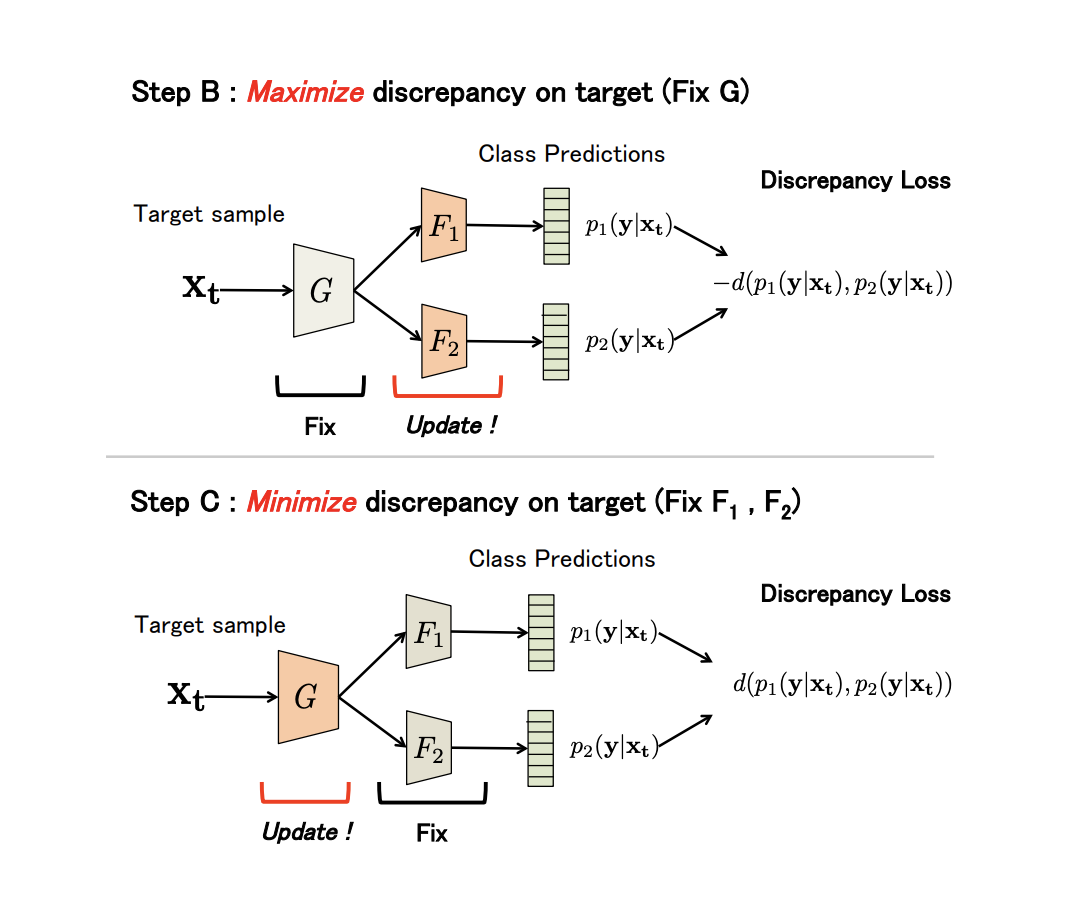
:
- USPS -> MNIST: 94,1 %.
- Synth Signs -> GTSRB : 94,4 %.
- VisDA 12 Unknown: 71,9 %.
- GTA 5 -> Cityscapes: Mean IoU = 39,7 %, Synthia -> Cityscapes: Mean IoU = 37,3 %
non-generative models:
.
Examinamos los principales conjuntos de datos para la adaptación del dominio, los enfoques basados en discrepancias: criterio de clase, criterio estadístico y criterio de arquitectura, así como la primera familia no generativa de métodos basados en confrontaciones. Los modelos de estos enfoques muestran un buen rendimiento en los puntos de referencia y son aplicables a muchas tareas de adaptación. En la siguiente parte, consideraremos los enfoques más complejos y efectivos: modelos generativos y métodos mixtos no basados en adversarios.