El envío de spam en las redes sociales y mensajería instantánea es un dolor. Dolor tanto para usuarios honestos como para desarrolladores. Cómo luchan en Badoo, dijo Mikhail Ovchinnikov en Highload ++, luego la versión de texto de este informe.
Sobre el orador: Mikhail Ovchinnikov ha estado trabajando en Badoo y ha sido antispam durante los últimos cinco años.
Badoo tiene 390 millones de usuarios registrados (datos de octubre de 2017). Si comparamos el tamaño de la audiencia del servicio con la población de Rusia, podemos decir que, según las estadísticas, cada 100 millones de personas están protegidas por 500 mil policías, y en Badoo, solo un empleado de Antispam protege a cada 100 millones de usuarios del correo no deseado. Pero incluso un número tan pequeño de programadores puede proteger a los usuarios de varios problemas en Internet.
Tenemos una gran audiencia y puede tener diferentes usuarios:
- Bueno y muy bueno, nuestros clientes que pagan favoritos;
- Los malos son aquellos que, por el contrario, están tratando de ganar dinero con nosotros: envían spam, engañan dinero y se involucran en fraudes.
Quien tiene que pelear
El spam puede ser diferente, a menudo no se puede distinguir del comportamiento de un usuario común. Puede ser manual o automático: los bots que se dedican al correo automático también quieren comunicarse con nosotros.
Quizás también una vez escribiste bots: estabas creando scripts para la publicación automática. Si está haciendo esto ahora, es mejor no seguir leyendo; de ninguna manera debe averiguar lo que le diré ahora.
Esto, por supuesto, es una broma. El artículo no tendrá información que simplifique la vida de los spammers.

Entonces, ¿con quién tenemos que luchar? Estos son spammers y estafadores.
El spam apareció hace mucho tiempo, desde el comienzo del desarrollo de Internet. En nuestro servicio, los spammers, por regla general, intentan registrar una cuenta cargando una
foto de una chica atractiva allí . En la forma más simple, comienzan a enviar los tipos más obvios de spam: enlaces.
Una opción más complicada es cuando las personas no envían nada explícito, no envían enlaces, no anuncian nada, pero
atraen al usuario a un lugar más conveniente para ellos, por ejemplo, mensajería instantánea : Skype, Viber, WhatsApp. Allí pueden, sin nuestro control, venderle algo al usuario, promocionarlo, etc.
Pero los
spammers no son el mayor problema . Son obvios y fáciles de combatir. Los personajes mucho más complejos e interesantes son los
estafadores que fingen ser otra persona y tratan de engañar a los usuarios de todas las formas que están en Internet.
Por supuesto, las acciones de los spammers y los estafadores no siempre son muy diferentes del comportamiento de los usuarios comunes que también hacen esto a veces. Hay muchos signos formales en ambos que no permiten trazar una línea clara entre ellos. Esto casi nunca es posible.
Cómo lidiar con el spam en la era mesozoica
- Lo más simple que se podía hacer era escribir expresiones regulares separadas para cada tipo de spam e ingresar cada palabra incorrecta y cada dominio separado en este regular. Todo esto se hizo manualmente y, por supuesto, fue lo más inconveniente e ineficiente posible.
- Puede encontrar manualmente direcciones IP dudosas e ingresarlas en la configuración del servidor para que los usuarios sospechosos nunca más accedan a su recurso. Esto es ineficiente porque las direcciones IP se reasignan constantemente, se redistribuyen.
- Escriba scripts únicos para cada tipo de spammer o bot, raspe sus registros, encuentre patrones manualmente. Si algo cambia en el comportamiento del spammer, todo deja de funcionar, también completamente ineficaz.

Primero, le mostraré los métodos más simples para combatir el spam que todos pueden implementar por sí mismos. Luego, le contaré en detalle sobre los sistemas más complejos que desarrollamos utilizando el aprendizaje automático y otras artillería pesada.
Las formas más fáciles de lidiar con el spam
Moderación manual
En cualquier servicio, puede contratar moderadores que verán manualmente el contenido y el perfil del usuario, y decidir qué hacer con este usuario. Por lo general, este proceso parece encontrar una aguja en un pajar. Tenemos una gran cantidad de usuarios, moderadores menos.

Además del hecho de que los moderadores obviamente necesitan mucho, usted necesita mucha infraestructura. Pero, de hecho, lo más difícil es otro: surge un problema: cómo, por el contrario, proteger a los usuarios de los moderadores.
Es necesario asegurarse de que los moderadores no tengan acceso a los datos personales. Esto es importante porque los moderadores teóricamente también pueden intentar hacer daño. Es decir, necesitamos antispam para antispam, de modo que los moderadores estén bajo un estricto control.
Obviamente, no puede verificar a todos los usuarios de esta manera. Sin embargo, la
moderación es necesaria en cualquier caso , porque cualquier sistema en el futuro necesita capacitación y una mano humana que determine qué hacer con el usuario.
Colección de estadísticas
Puede intentar usar estadísticas para recopilar varios parámetros para cada usuario.
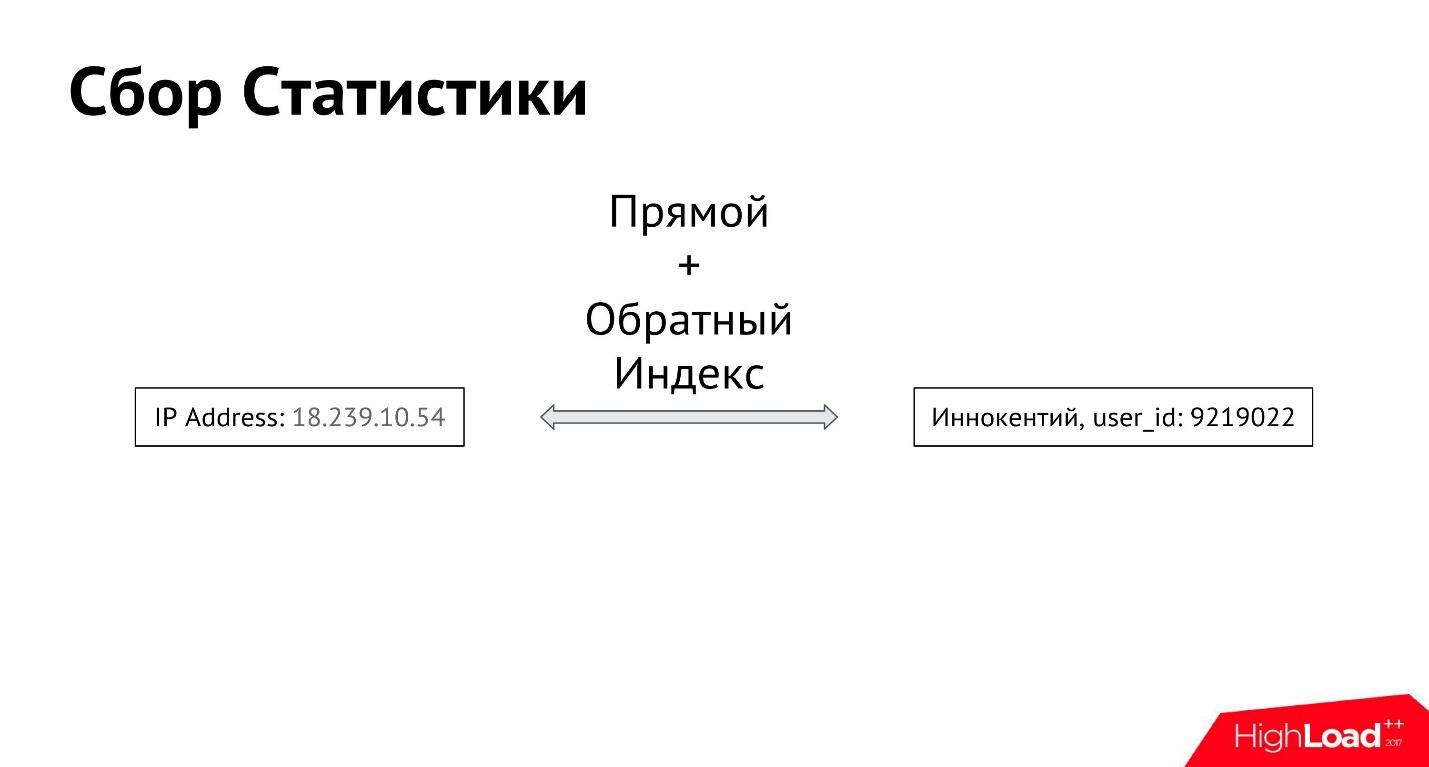
Innokenty de usuario inicia sesión desde su dirección IP. Lo primero que hacemos es iniciar sesión en la dirección IP que ingresó. A continuación, creamos un índice directo e inverso entre todas las direcciones IP y todos los usuarios, para que pueda obtener todas las direcciones IP desde las que un usuario específico inicia sesión, así como todos los usuarios que inician sesión desde una dirección IP específica.
De esta forma obtenemos la conexión entre el atributo y el usuario. Puede haber muchos de esos atributos. Podemos comenzar a recopilar información no solo sobre las direcciones IP, sino también fotos, dispositivos desde los que entró el usuario, sobre todo lo que podemos determinar.
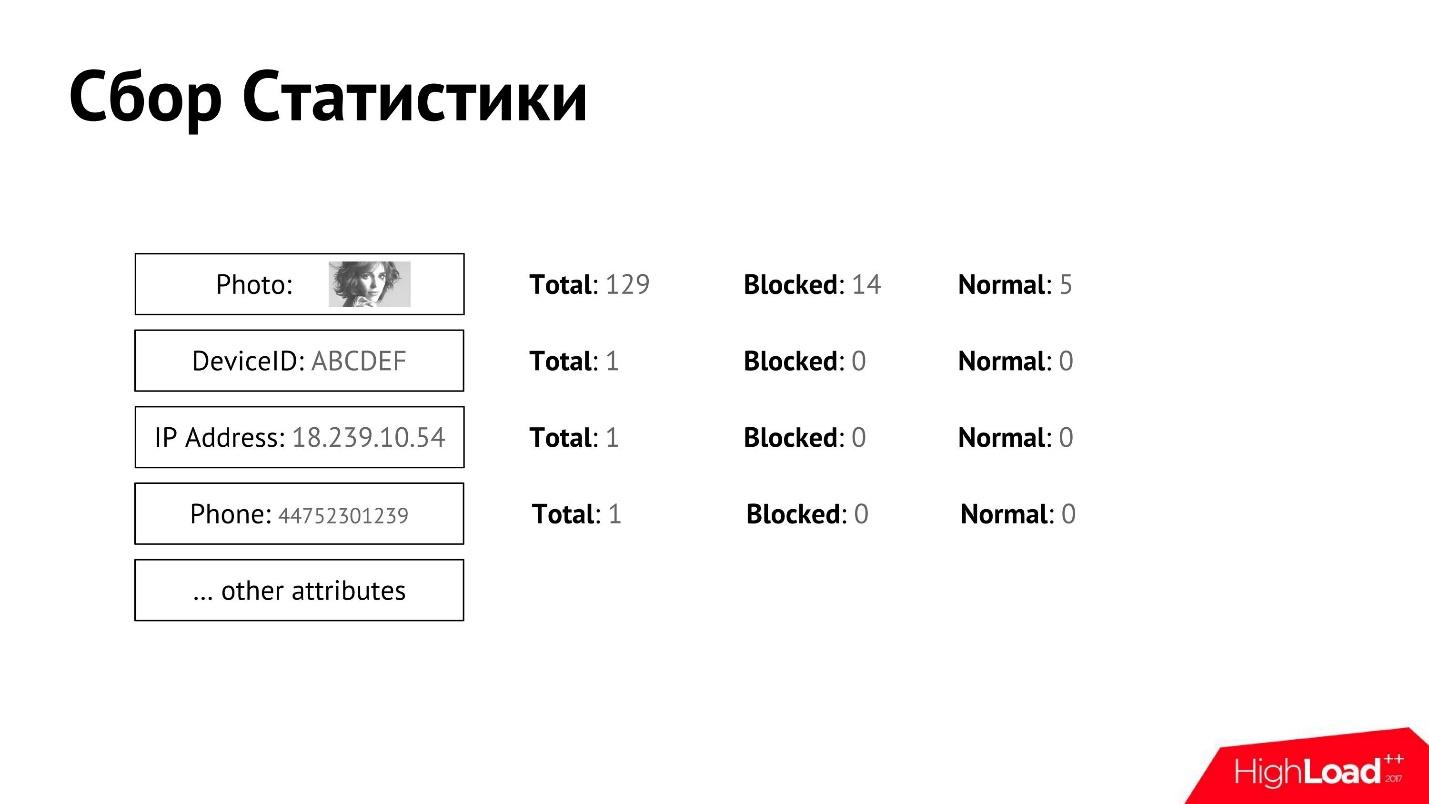
Recopilamos tales estadísticas y las asociamos con el usuario. Para cada uno de los atributos podemos recopilar contadores detallados.
Tenemos una moderación manual que decide qué usuario es bueno, cuál es malo, y en algún momento el usuario es bloqueado o reconocido como normal. Podemos obtener datos por separado para cada atributo, cuántos usuarios totales, cuántos de ellos están bloqueados, cuántos se reconocen como normales.
Teniendo tales estadísticas para cada uno de los atributos, podemos determinar aproximadamente quién es el spammer y quién no.

Digamos que tenemos dos direcciones IP: el 80% de los spammers en una y el 1% en la segunda. Obviamente, el primero es mucho más spam, debe hacer algo con él y aplicar algún tipo de sanciones.
Lo más simple es escribir
reglas heurísticas . Por ejemplo, si los usuarios bloqueados son más del 80% y los que se consideran normales (menos del 5%), esta dirección IP se considera incorrecta. Luego prohibimos o hacemos algo más con todos los usuarios con esta dirección IP.
Recolección de estadísticas de textos.
Además de los atributos obvios que tienen los usuarios, también puede hacer análisis de texto. Puede analizar automáticamente los mensajes de los usuarios, aislar de ellos todo lo relacionado con el correo no deseado: mencionar mensajeros, teléfonos, correo electrónico, enlaces, dominios, etc., y recopilar exactamente las mismas estadísticas de ellos.

Por ejemplo, si un nombre de dominio fue enviado en mensajes por 100 usuarios, de los cuales 50 fueron bloqueados, entonces este nombre de dominio es incorrecto. Puede estar en la lista negra.
Recibiremos una gran cantidad de estadísticas adicionales para cada uno de los usuarios en función de los mensajes de texto. No se necesita aprendizaje automático para esto.
Deja de palabras
Además de las cosas obvias (teléfonos y enlaces), puede extraer frases o palabras del texto que son especialmente comunes para los spammers. Puede mantener esta lista de palabras de detención manualmente.
Por ejemplo, en las cuentas de spammers y estafadores, a menudo se encuentra la frase: "Hay muchas falsificaciones". Escriben que generalmente son los únicos aquí que están preparados para algo serio, todas las demás falsificaciones, que en ningún caso se puede confiar.
En los sitios de citas según las estadísticas, los spammers con más frecuencia que la gente común usan la frase: "Estoy buscando una relación seria". Es poco probable que una persona común escriba esto en un sitio de citas; con una probabilidad del 70%, se trata de un spammer que intenta atraer a alguien.
Buscar cuentas similares
Con estadísticas sobre atributos y palabras de detención encontradas en los textos, puede crear un sistema para buscar cuentas similares. Esto es necesario para encontrar y prohibir todas las cuentas creadas por la misma persona. Un spammer que ha sido bloqueado puede registrar inmediatamente una nueva cuenta.
Por ejemplo, un usuario Harold inicia sesión, inicia sesión en el sitio y proporciona sus atributos más bien únicos: dirección IP, foto, palabra de detención que utilizó. Tal vez incluso se registró con una cuenta falsa de Facebook.
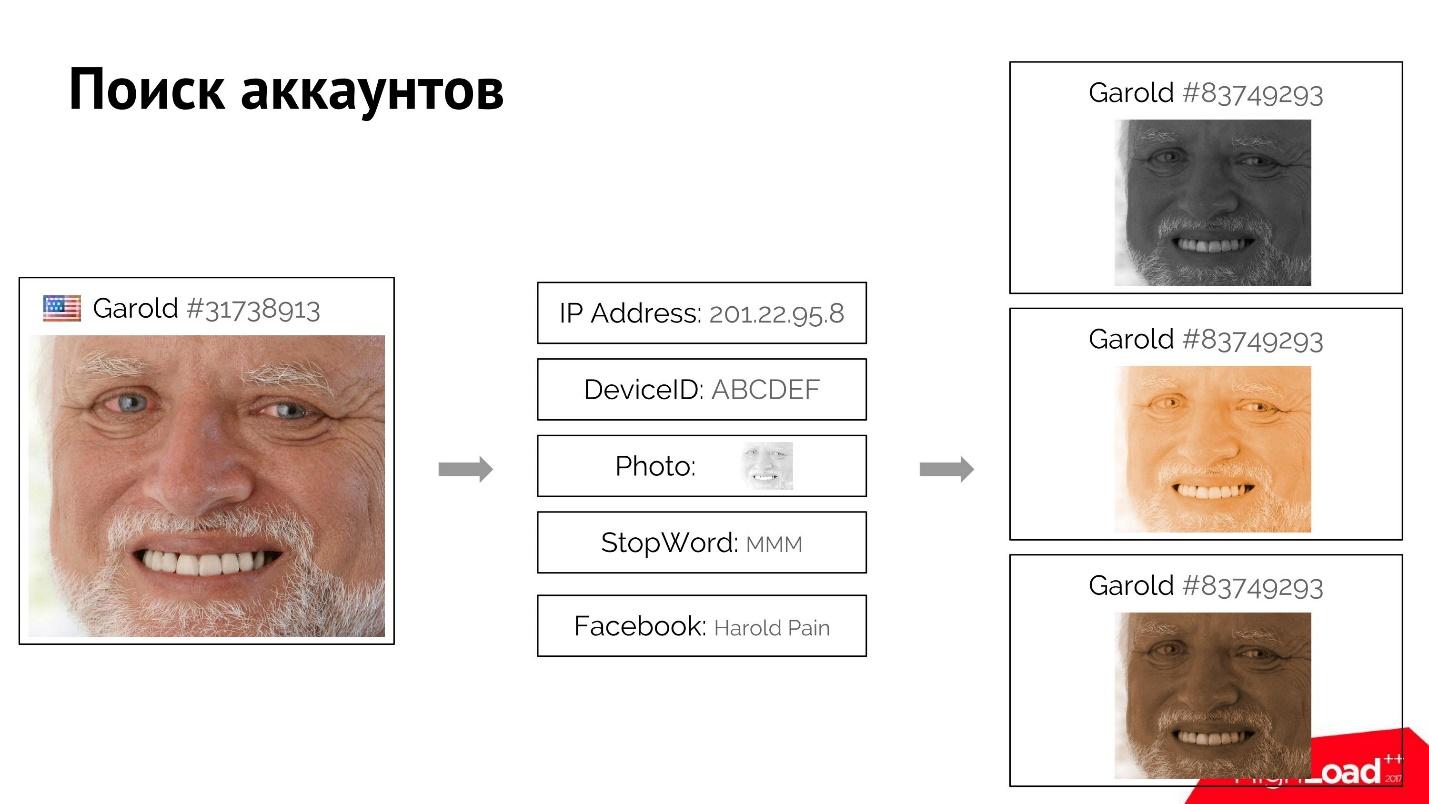
Podemos encontrar a todos los usuarios similares a él que tengan uno o más de estos atributos coincidentes. Cuando sabemos con certeza que estos usuarios están conectados, utilizando el índice directo e inverso, encontramos los atributos, y por ellos de todos los usuarios, y los clasificamos. Si, digamos el primer Harold, bloqueamos, entonces el resto también es fácil de "matar" usando este sistema.
Todos los métodos que acabo de describir son muy simples: es fácil recopilar estadísticas, luego es fácil buscar usuarios que utilicen estos atributos. Pero, a pesar de la facilidad, con la ayuda de cosas tan simples (moderación simple, estadísticas simples, palabras simples), logran
derrotar al 50% del spam .
En nuestra empresa, durante los primeros seis meses de trabajo, el departamento de Antispam derrotó al 50% del spam. El 50% restante, como saben, es mucho más complicado.
Cómo hacer la vida difícil a los spammers
Los spammers están inventando algo, tratando de complicar nuestras vidas, y estamos tratando de luchar contra ellos. Esta es una guerra sin fin. Hay muchos más que nosotros, y en cada paso encontramos su propio camino múltiple.
Estoy seguro de que las conferencias de spammers se llevarán a cabo en algún lugar donde los oradores hablen sobre cómo derrotaron a Badoo Antispam, sobre sus KPI o sobre cómo crear spam escalable con tolerancia a fallas utilizando la última tecnología.
Lamentablemente, no estamos invitados a tales conferencias.
Pero podemos hacer la vida difícil para los spammers. Por ejemplo, en lugar de mostrarle directamente al usuario la ventana "Estás bloqueado", puedes usar la llamada
prohibición de sigilo ; esto es cuando no le decimos al usuario que está prohibido. Ni siquiera debería sospecharlo.

El usuario se mete en el sandbox (Silent Hill), donde todo parece ser real: puede enviar mensajes, votar, pero de hecho todo se va al vacío, a la niebla. Nadie verá y escuchará, nadie recibirá sus mensajes y votos.
Tuvimos un caso cuando un spammer envió spam durante mucho tiempo, promocionó sus bienes y servicios malos, y seis meses después decidió usar el servicio como estaba previsto. Registró su cuenta real: fotos reales, nombre, etc. Naturalmente, nuestro motor de búsqueda de cuentas similares lo descubrió rápidamente y lo puso en prohibición de Stealth. Después de eso, escribió durante seis meses en el vacío que estaba muy solo, nadie respondió. En general, derramó toda su alma en la niebla de Silent Hill, pero no recibió ninguna respuesta.
Los spammers, por supuesto, no son tontos. Intentan de alguna manera determinar que entraron en la caja de arena y que fueron bloqueados, salieron de la cuenta anterior y encontraron una nueva. A veces incluso tenemos la idea de que sería bueno enviar a varios de estos spammers a la caja de arena juntos, para que allí se vendan entre ellos todo lo que quieran y se diviertan como quieran. Pero aunque no hemos llegado a este punto, estamos ideando otros métodos, por ejemplo, verificación de fotos y teléfono.

Como saben, es difícil para un spammer que es un bot y no una persona pasar la verificación por teléfono o foto.
En nuestro caso, la verificación por foto se ve así: se le pide al usuario que tome una foto con cierto gesto, la foto resultante se compara con las fotos que ya están cargadas en el perfil. Si los rostros son iguales, lo más probable es que la persona sea real, haya subido sus fotos reales y pueda quedarse atrás por algún tiempo.
No es fácil para los spammers pasar esta prueba. Incluso tenemos un pequeño juego dentro de la compañía llamado Adivina quién es el spammer. Dadas cuatro fotos, debe comprender cuál de ellas es spammer.
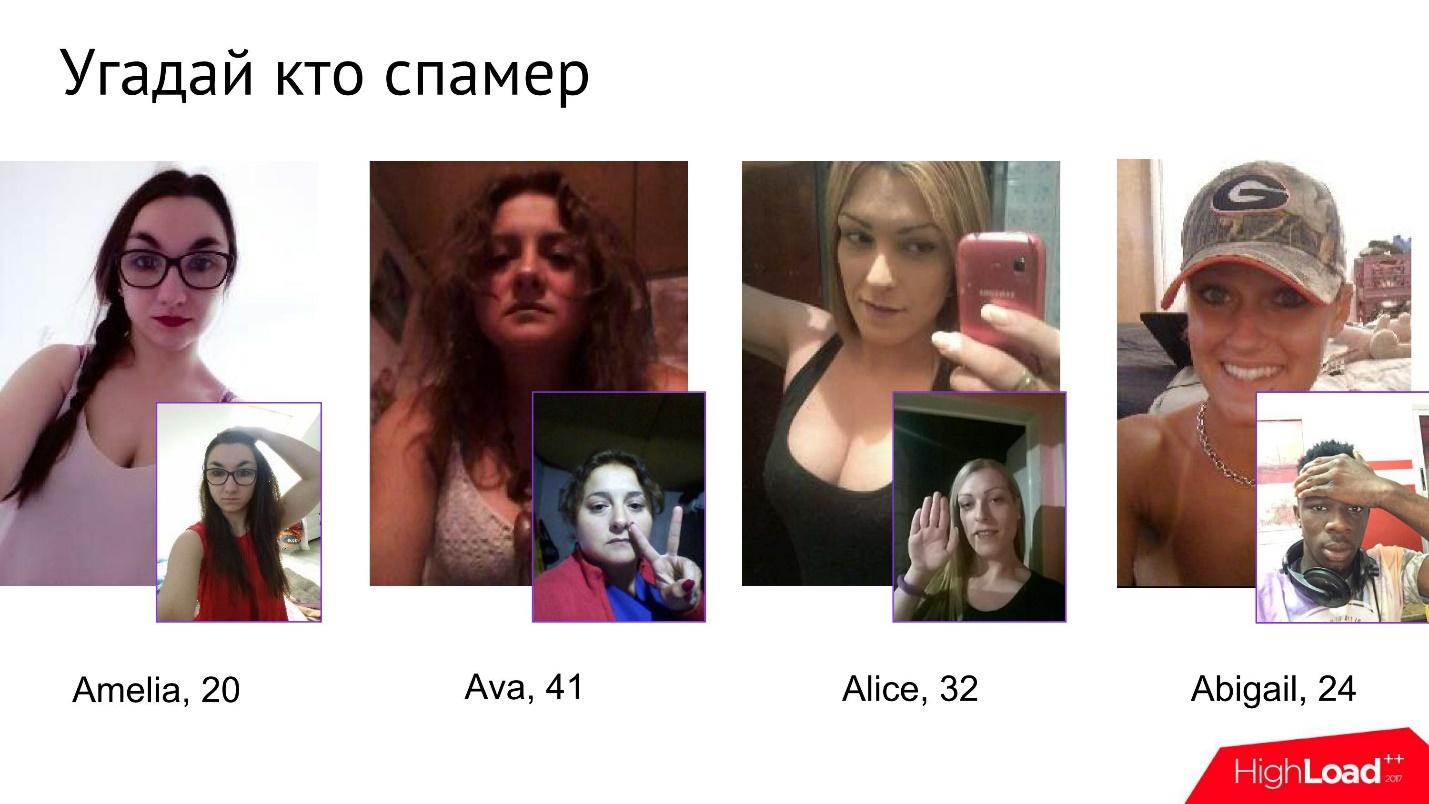
A primera vista, estas chicas se ven completamente inofensivas, pero tan pronto como comienzan a someterse a una verificación de fotos, desde algún punto queda claro que una de ellas no es completamente lo que dice ser.
En cualquier caso, los spammers tienen dificultades para combatir la verificación de fotos. Realmente sufren, intentan de alguna manera evitarlo, engañar y demostrar todas sus habilidades de Photoshop.

Los spammers están haciendo todo lo que pueden, y a veces piensan, probablemente, que todo esto es completamente procesado por algunas tecnologías modernas increíbles que están tan mal construidas que son tan fáciles de engañar.
No saben que cada foto es nuevamente revisada manualmente por los moderadores.
No tiempo
De hecho, a pesar del hecho de que encontramos varias formas de dificultar la vida de los spammers, generalmente no hay suficiente tiempo, porque el anti-spam debería funcionar al instante. Debe encontrar y neutralizar al usuario antes de comenzar su actividad negativa.
Lo mejor que se puede hacer es determinar en la etapa de registro que el usuario no es muy bueno. Esto se puede hacer, por ejemplo, usando clustering.
Agrupación de usuarios
Podemos recopilar toda la información posible justo después del registro. Todavía no tenemos ningún dispositivo con el que el usuario inicie sesión, ni fotografías, no hay estadísticas. No tenemos nada que enviarlo para su verificación, no ha hecho nada sospechoso. Pero ya tenemos información primaria:
- género
- edad
- país de registro;
- país y proveedor de IP;
- Dominio de correo electrónico
- operador telefónico (si lo hay);
- datos de fb (si corresponde): cuántos amigos tiene, cuántas fotos subió, cuánto tiempo se registró allí, etc.
Toda esta información se puede utilizar para localizar grupos de usuarios. Utilizamos el algoritmo de agrupación
K-means simple y popular. Está perfectamente implementado en todas partes, es compatible con cualquier biblioteca de MachineLearning, es perfectamente paralelo, funciona rápidamente. Hay versiones de transmisión de este algoritmo que le permiten distribuir usuarios en clústeres sobre la marcha. Incluso en nuestros volúmenes, todo esto funciona bastante rápido.
Habiendo recibido dichos grupos de usuarios (clusters), podemos hacer cualquier acción. Si los usuarios son muy similares (el clúster está muy conectado), lo más probable es que se trate de un registro masivo, debe detenerse de inmediato. El usuario aún no ha tenido tiempo de hacer nada, simplemente hizo clic en el botón "Registrarse", y eso es todo, ya entró en la caja de arena.
Las estadísticas se pueden recopilar en clústeres: si el 50% del clúster está bloqueado, el 50% restante se puede enviar para verificación, o moderar individualmente todos los clústeres manualmente, ver los atributos con los que coinciden y tomar una decisión. Sobre la base de dichos datos, los analistas pueden identificar patrones.
Patrones
Los patrones son conjuntos de los atributos de usuario más simples que conocemos de inmediato. Algunos de los patrones realmente funcionan de manera muy efectiva contra ciertos tipos de spammers.
Por ejemplo, considere una combinación de tres atributos completamente independientes y bastante comunes:
- El usuario está registrado en los Estados Unidos;
- Su proveedor es Privax LTD (operador de VPN);
- Dominio de correo electrónico: [mail.ru, list.ru, bk.ru, inbox.ru].
Estos tres atributos, que aparentemente no representan nada de sí mismos, en conjunto dan la probabilidad de que sea un spammer, casi el 90%.
Puede extraer dichos patrones tantos como desee para cada tipo de spammer. Esto es mucho más eficiente y más fácil que ver manualmente todas las cuentas o incluso grupos.
Agrupación de texto
Además de agrupar a los usuarios por atributos, puede encontrar usuarios que escriben los mismos textos. Por supuesto, esto no es tan simple. El hecho es que nuestro servicio funciona en muchos idiomas. Además, los usuarios a menudo escriben con abreviaturas, jerga, a veces con errores. Bueno, los mensajes en sí suelen ser muy cortos, literalmente de 3 a 4 palabras (unos 25 caracteres).
En consecuencia, si queremos encontrar textos similares entre los miles de millones de mensajes que escriben los usuarios, debemos encontrar algo inusual. Si intenta utilizar métodos clásicos basados en el análisis de la morfología y el verdadero procesamiento honesto del lenguaje, entonces con todas estas restricciones, jergas, abreviaturas y un montón de idiomas, esto es muy difícil.
Puede hacer un poco más simplemente: aplique el algoritmo
n-gram . Cada mensaje que aparece se divide en n-gramos. Si n = 2, entonces estos son bigramas (pares de letras). Gradualmente, el mensaje completo se divide en pares de letras y se recopilan estadísticas, cuántas veces cada bigram aparece en el texto.

No puede detenerse en bigrams, pero agregue trigrams, skipgrams (estadísticas sobre letras después de 1, 2, etc. letras). Cuanta más información obtengamos, mejor. Pero incluso las bigrams ya funcionan bastante bien.
Luego obtenemos un vector de las bigramas de cada mensaje cuya longitud es igual al cuadrado del alfabeto.
Es muy conveniente trabajar con este vector y agruparlo porque:
- consiste en números;
- comprimido, no hay vacíos;
- Tamaño siempre fijo.
- El algoritmo k-means con tales vectores comprimidos de un tamaño fijo es muy rápido. Nuestros miles de millones de mensajes se agrupan literalmente en unos minutos.
Pero eso no es todo. Desafortunadamente, si simplemente recolectamos todos los mensajes que son similares en frecuencia a los bigrams, obtenemos mensajes que son similares en frecuencia a los bigrams. Sin embargo, no tienen que ser, de hecho, al menos algo similares en significado. A menudo hay textos largos en los que los vectores son muy cercanos, casi iguales, pero los textos en sí son completamente diferentes. Además, a partir de una cierta longitud de texto, este método de agrupación generalmente dejará de funcionar, porque Las frecuencias de los bigrams son iguales.

Por lo tanto, debe agregar filtrado. Como los grupos ya existen, son bastante pequeños, podemos filtrar fácilmente dentro del grupo usando Stemming o Bag of Words. Dentro de un grupo pequeño, puede comparar literalmente todos los mensajes con todos, y obtener el grupo en el que se garantiza que habrá los mismos mensajes, que coinciden no solo en las estadísticas, sino también en la realidad.
, — , , ( ) . , - .
— VPN, TOR, Proxy, . , , , .
, , « IP».

VPN — , IP- , IP- VPN, Proxy .
:
- ISP (Internet Service Provider), IP- . , .
- Whois . IP- Whois : ; ; , IP-; , IP- .. , IP-.
- GeolP. , IP- , , IP- , , , IP- - .
- — IP- , GeolP, Whois, .
, , , IP- VPN .
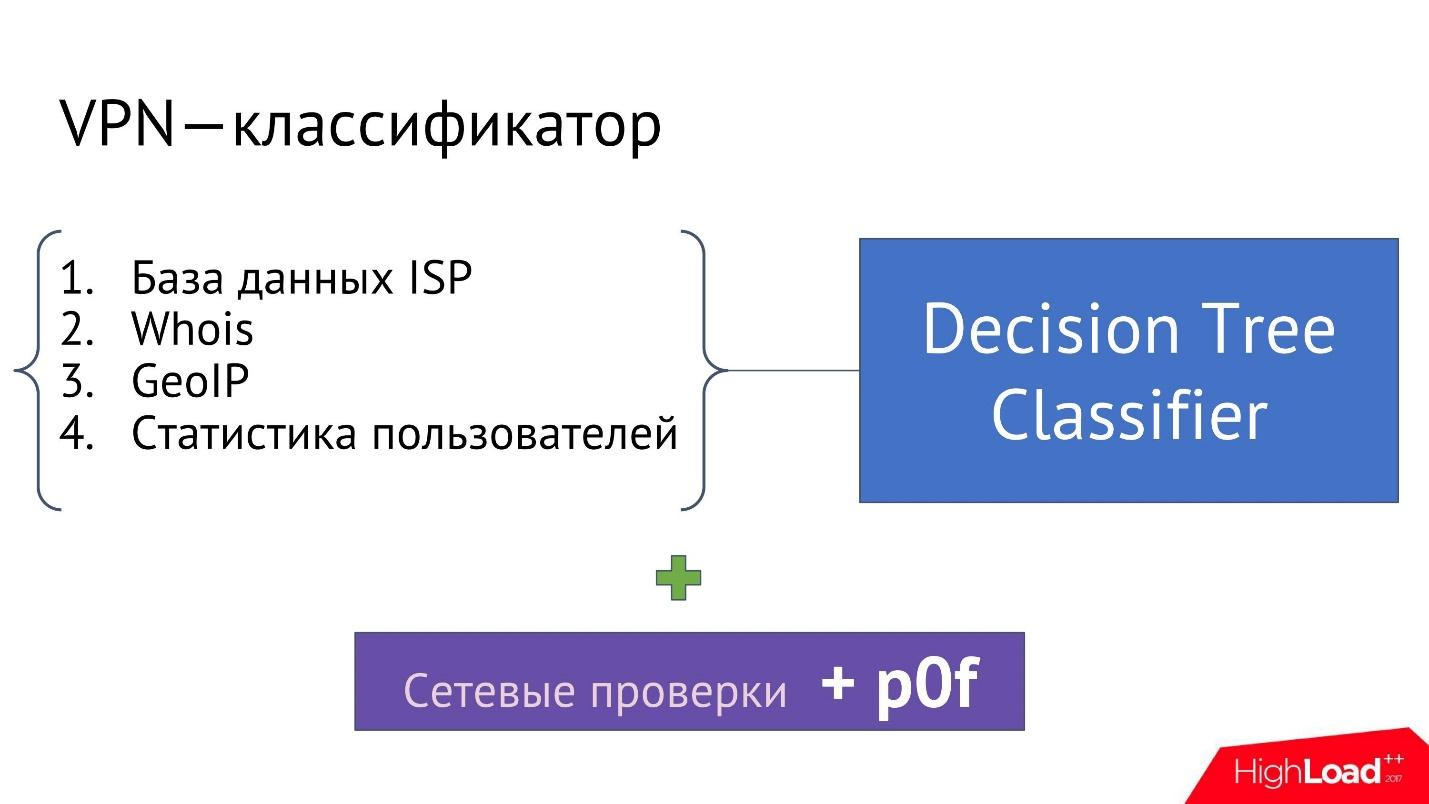
, — , , .., , IP- VPN.
, . , advanced-, 100% . .
, IP- VPN, , IP- . , , . SOCKS-proxy, IP- .
, , ,
p0f . , fingerprinting , : , VPN-, Proxy .. , .
, , , , , : ? — ! , , , .
— ? . 2 , .
, , , , , , , .

, , ?
«User Decency»
— , .
«» :
.
. , , , .
, , «
». , , , , . .
1, , , , — .
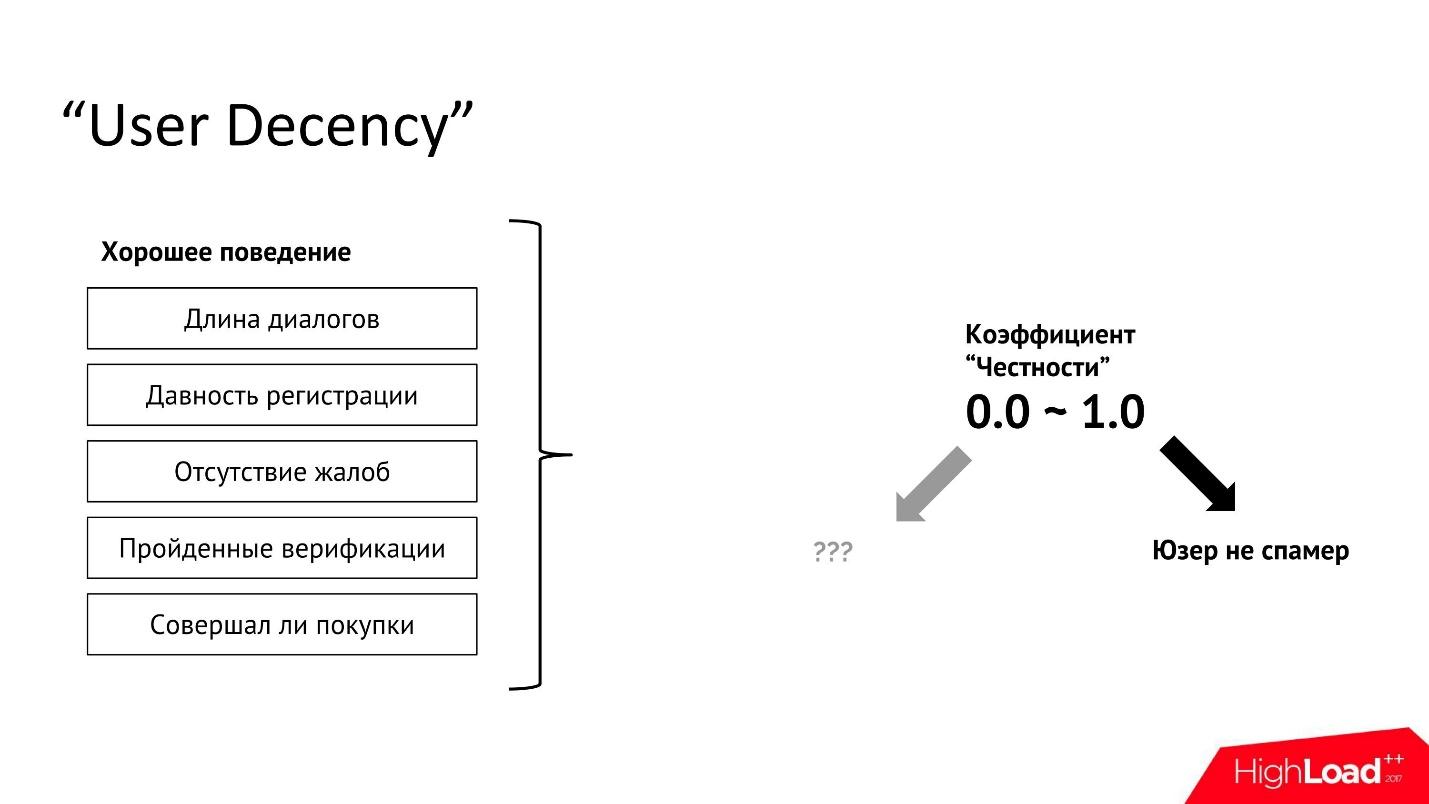
.
False positive
, — . , IP-. , -, . , fingerprint, , , — , , , , - .
: : «, — Pornhub — ?» , - , .
. , , , .
- «Pornhub». - , - .
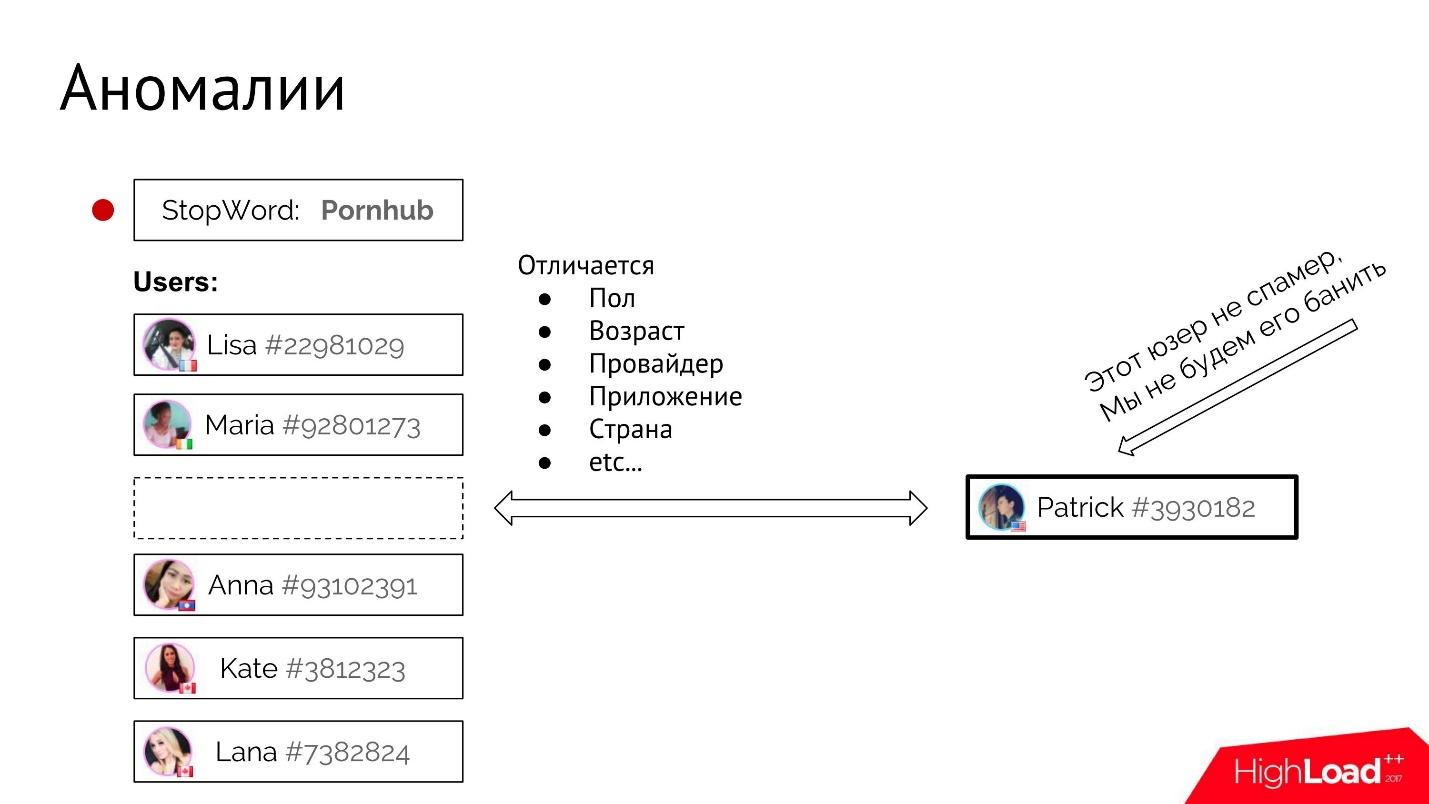
- -, .
, , . : , , , , .. , «» . , , , . , , .
, .
-
— MachineLearning, , 0 1 — .
, ,
, . , , . , - , .
, — . — , .
, ( ) , , . , , , : , , . .
HighLoad++ 2018 , , :
- ML- ,
- NVIDIA , .
- use case .
youtube- , — , .