Otra charla con
Pixonic DevGAMM Talks , esta vez de nuestros colegas de PanzerDog. El ingeniero de software principal de la compañía Pavel Platto desarmó el meta-servidor del juego con una arquitectura orientada al servicio, le dijo qué soluciones y tecnologías fueron elegidas, qué y cómo escalaron, y qué dificultades tuvieron que enfrentar. El texto del informe, diapositivas y enlaces a otros discursos del mitap, como siempre, debajo del corte.
Primero, quiero demostrar un pequeño trailer de nuestro juego:
El informe constará de 3 partes. En el primero, hablaré sobre qué tecnologías elegimos y por qué, en el segundo, cómo está organizado nuestro meta-servidor, y en el tercero, hablaré sobre las diversas infraestructuras de soporte que usamos y cómo implementamos la actualización sin tiempo de inactividad. .
 Pila tecnológica
Pila tecnológicaEl meta servidor está alojado en Amazon y está escrito en Elixir. Es un lenguaje de programación funcional con un modelo de cómputo de actor. Como no tenemos Ops, los programadores están involucrados en la operación, y la mayor parte de la infraestructura se describe como un código que utiliza HashiCorp Terraform.
Tacticool se encuentra actualmente en versión beta abierta, el meta servidor ha estado en desarrollo durante poco más de un año y ha estado en funcionamiento durante casi un año. Veamos cómo empezó todo.

Cuando me uní a la compañía, ya teníamos funcionalidades básicas implementadas como un monolito en una mezcla C / C ++ y almacenamiento PostageSQL. Esta implementación tuvo ciertos problemas.
En primer lugar, debido al bajo nivel de C, hubo bastantes errores esquivos. Por ejemplo, para algunos jugadores, el emparejamiento se bloquea debido a la puesta a cero incorrecta de la matriz antes de su reutilización. Por supuesto, encontrar la relación entre estos dos eventos fue bastante difícil. Y dado que el estado de varios subprocesos se modificó universalmente en el código, las condiciones de carrera no estuvieron exentas.
El procesamiento paralelo de una gran cantidad de tareas también estaba fuera de discusión, porque el servidor comenzó al comienzo de aproximadamente 10 procesos de trabajo, que fueron bloqueados por consultas a Amazon o la base de datos. E incluso si nos olvidamos de estas solicitudes de bloqueo, el servicio comenzó a desmoronarse en un par de cientos de conexiones que no realizaron ninguna operación, excepto ping. Además, el servicio no podía escalarse horizontalmente.
Después de pasar un par de semanas buscando y reparando los errores más críticos, decidimos que era más fácil reescribir todo desde cero que tratar de corregir todas las deficiencias de la solución actual.
Y cuando comienzas desde cero, tiene sentido intentar elegir un idioma que ayude a evitar algunos de los problemas anteriores. Teníamos tres candidatos:

C # estaba en la lista de "conocidos", como el cliente y el servidor del juego están escritos en Unity, y la mayor parte de la experiencia en el equipo fue con este lenguaje de programación. Go y Elixir fueron considerados porque estos son lenguajes modernos y bastante populares creados para desarrollar aplicaciones de servidor.
Los problemas de la iteración anterior nos ayudaron a determinar los criterios para evaluar candidatos.
El primer criterio fue la conveniencia de trabajar con operaciones asincrónicas. En C #, el trabajo conveniente con operaciones asincrónicas no apareció en el primer intento. Esto llevó al hecho de que tenemos un "zoológico" de soluciones que, en mi opinión, todavía se mantienen un poco al margen. En Go y Elixir, este problema se tuvo en cuenta al diseñar estos lenguajes, ambos usan hilos ligeros (en Go son gorutinas, en Elixir son procesos). Estas transmisiones tienen una sobrecarga mucho menor que los subprocesos del sistema, y dado que podemos crearlos en decenas y cientos de miles, no lamentamos bloquearlos.
El segundo criterio fue la capacidad de trabajar con procesos competitivos. C # listo para usar no ofrece nada más que grupos de subprocesos y memoria compartida, cuyo acceso debe protegerse utilizando varias primitivas de sincronización. Go tiene un modelo menos propenso a errores en forma de gorutinas y canales. Elixir, por otro lado, ofrece un modelo de actor sin memoria compartida con mensajes. La falta de memoria compartida permitió implementar tecnologías útiles para un entorno de ejecución competitivo en tiempo de ejecución, como la multitarea honesta y la recolección de basura sin interrupciones en el mundo.
El tercer criterio fue la disponibilidad de herramientas para trabajar con tipos de datos inmutables. Toda mi experiencia en desarrollo ha demostrado que una gran parte de los errores están asociados con cambios de datos incorrectos. Existe una solución a esto hace mucho tiempo: tipos de datos inmutables. En C #, se pueden crear estos tipos de datos, pero a costa de una tonelada de repetitivo. En Go, esto no es posible en absoluto. Y en Elixir, todos los tipos de datos son inmutables.
Y el último criterio fue el número de especialistas. Aquí los resultados son obvios. Al final, optamos por Elixir.
Con la elección del alojamiento, todo fue mucho más simple. Ya alojamos servidores de juegos en Amazon GameLift, además, Amazon ofrece una gran cantidad de servicios que nos permitirían reducir el tiempo de desarrollo.
Nos rendimos completamente a la nube y no implementamos soluciones de terceros nosotros mismos (bases de datos, colas de mensajes), todo esto es administrado por Amazon para nosotros. En mi opinión, esta es la única solución para un equipo pequeño que quiere desarrollar un juego en línea, y no la infraestructura para ello.
Descubrimos la elección de tecnologías, pasemos a cómo funciona el meta servidor.
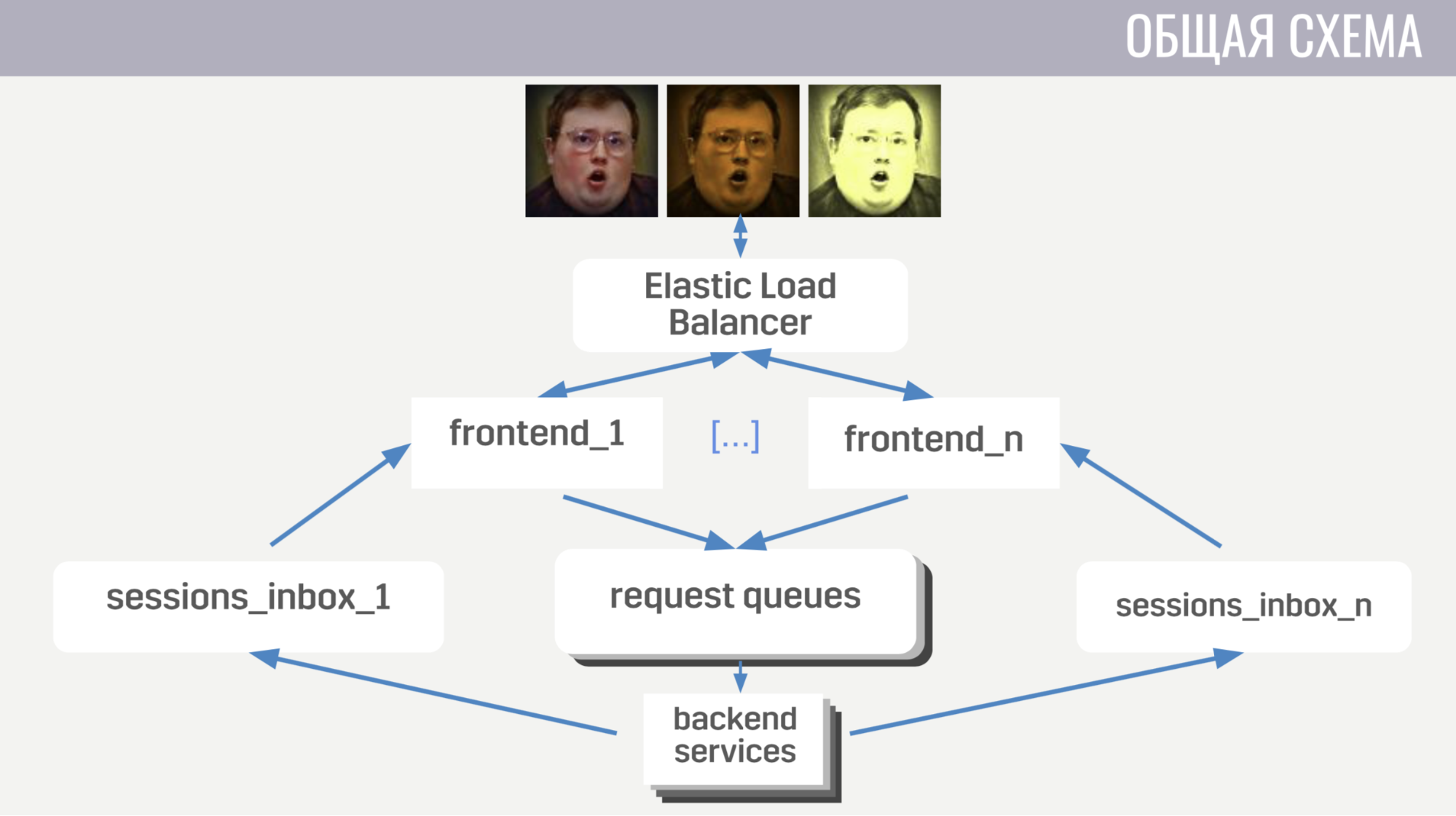
En general: los clientes se conectan al equilibrador de carga de Amazon a través de conexiones de socket web; el equilibrador dispersa estas conexiones entre varias instancias de front-end, el front-end envía solicitudes de cliente a backends. Pero el front-end y el back-end se comunican indirectamente, a través de colas de mensajes. Hay una cola separada para cada tipo de mensaje, y la interfaz por tipo de mensaje determina dónde escribirla, y los servidores escuchan estas colas.
Para que el servidor pueda enviar una respuesta a la solicitud al cliente, o algún tipo de evento, cada interfaz tiene una cola separada (especialmente asignada para ello). Y en cada solicitud, el servidor recibe un identificador de interfaz para determinar en qué cola se debe escribir la respuesta. Si necesita enviar un evento, llama a la base de datos para averiguar a qué instancia frontend está conectado el cliente.
Con el esquema general, pasemos a los detalles.

En primer lugar, hablaré sobre algunas características de la interacción cliente-servidor. Utilizamos nuestro protocolo binario porque es bastante eficiente y permite ahorrar tráfico. En segundo lugar, para cualquier operación con una cuenta que la cambie, el servidor no envía estos cambios al cliente, sino la versión completa (actualizada) de esta cuenta. Esto es un poco menos eficiente, pero de todos modos no ocupa mucho espacio y simplifica enormemente nuestra vida tanto en el cliente como en el servidor. Además, la interfaz garantiza que el cliente no realice más de una solicitud a la vez. Esto le permite detectar errores en el cliente, por ejemplo, cuando cambia a otra pantalla antes de que el jugador vea el resultado de la operación anterior.
Ahora un poco sobre cómo está organizada la interfaz.

Un frontend es esencialmente un servidor web que escucha las conexiones de socket web. Para cada sesión, se crean dos procesos. El primer proceso sirve la conexión de socket web en sí, y el segundo es una máquina de estado que describe el estado actual del cliente. En función de este estado, determina la validez de las solicitudes del cliente. Por ejemplo, casi todas las solicitudes no pueden completarse hasta que se complete la autorización. Dado que no hay estado en la interfaz además de estas sesiones, es muy fácil agregar nuevas instancias de interfaz, pero es un poco más difícil eliminar las antiguas. Antes de desinstalar, debe permitir que todos los clientes completen sus solicitudes actuales y pedirles que se vuelvan a conectar a otra instancia.
Ahora sobre cómo se ve el backend. Por el momento, consta de cinco servicios.
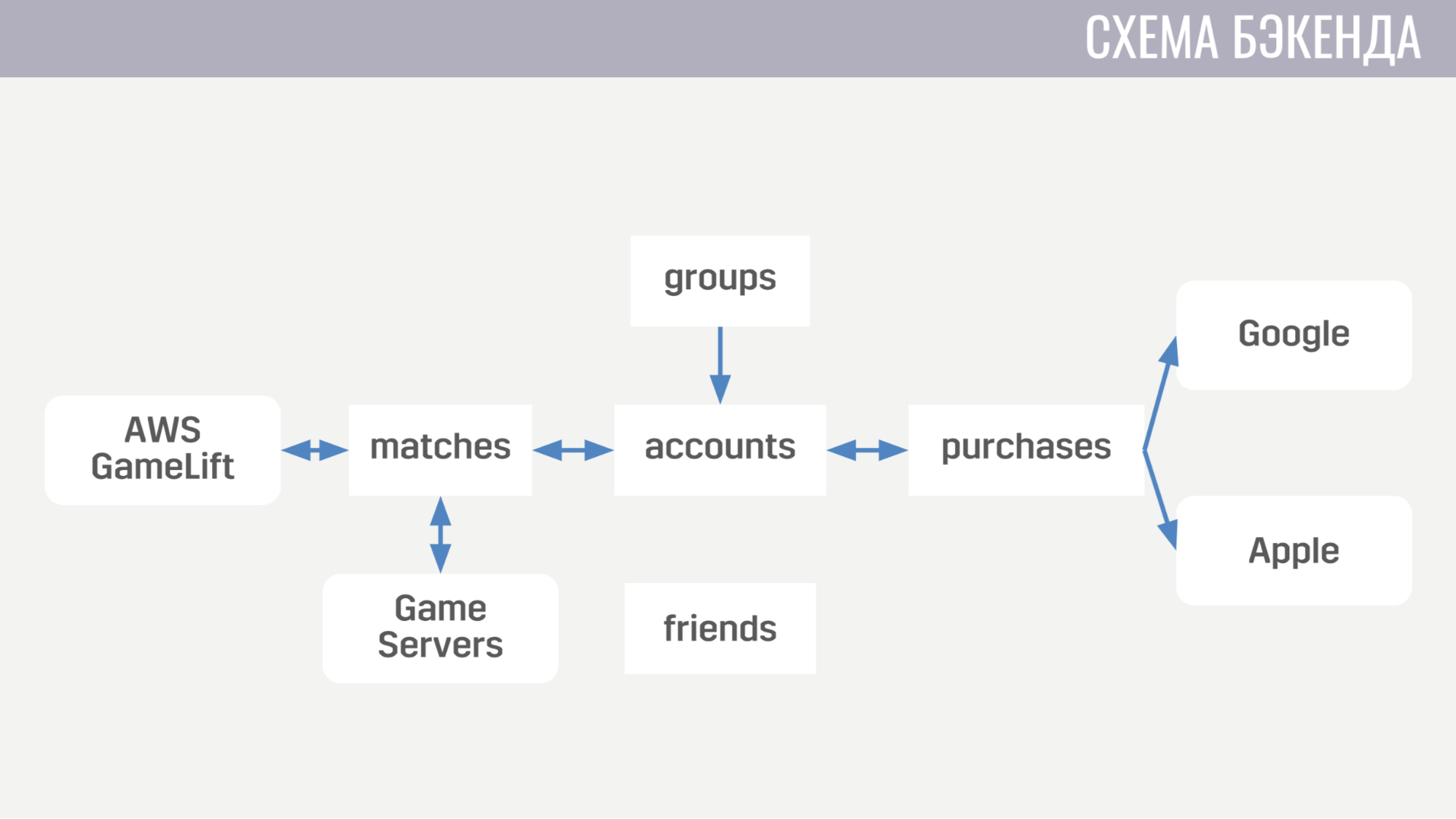
El primero trata de todo lo relacionado con las cuentas, desde compras de divisas en el juego hasta completar misiones. El segundo funciona con todo lo relacionado con los partidos: interactúa directamente con GameLift y los servidores de juegos. El tercer servicio es comprar dinero real. El cuarto y quinto son responsables de las interacciones sociales, una para amigos y otra para un juego de mesa.
Cada uno de los servicios de back-end desde un punto de vista arquitectónico se ve absolutamente idéntico. Son un conjunto de tuberías, cada una de las cuales procesa un tipo de mensaje. La tubería consta de dos elementos: productor y consumidor.

La única tarea del productor es leer los mensajes de la cola. Por lo tanto, se implementa de forma completamente general y para cada canalización solo necesitamos indicar cuántos productores hay, de qué fila leer y cuántos consumidores servirá cada productor. El consumidor, por otro lado, se implementa por separado para cada canalización y es un módulo con la única función obligatoria que acepta un mensaje, realiza todo el trabajo necesario y devuelve una lista de mensajes que deben enviarse a otros servicios al cliente o al servidor del juego. El productor también implementa la contrapresión para que con un fuerte aumento en el número de mensajes no haya sobrecarga, y solicita mensajes no más de lo que tiene consumidores libres.
Los servicios de back-end no contienen ningún estado, por lo que es fácil para nosotros agregar y eliminar instancias antiguas. Lo único que debe hacer antes de eliminar es pedirles a los productores que dejen de leer nuevos mensajes y les den a los consumidores un poco de tiempo para terminar de procesar los mensajes activos.
¿Cómo ocurre la interacción con GameLift? GameLift consta de varios componentes. De los que usamos, este es un emparejador FlexMatch, una cola de ubicación que determina en qué región particular organizar una sesión de juego con estos jugadores, y las flotas mismas, que consisten en servidores de juegos.
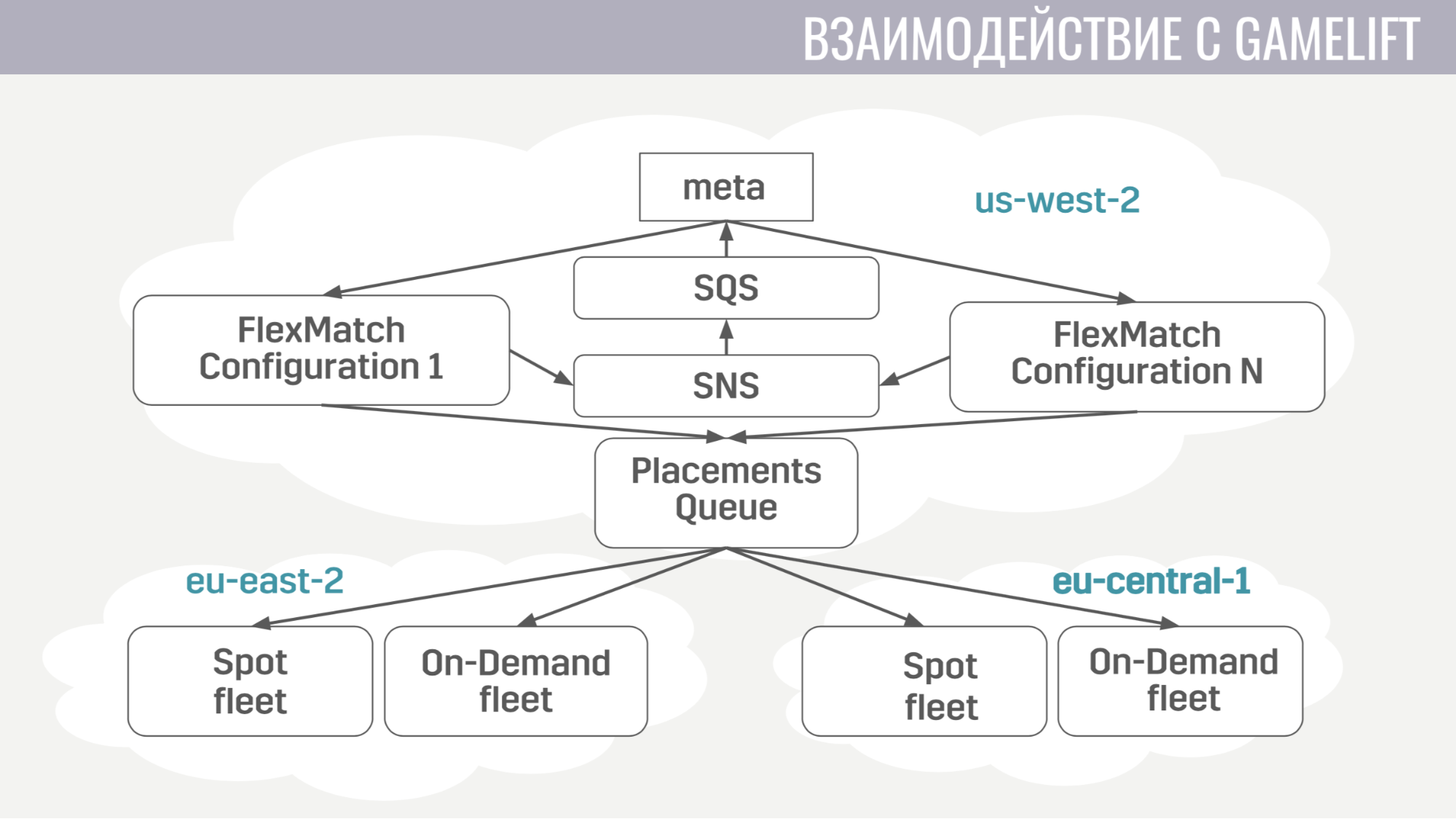
¿Cómo va esta interacción? Meta se comunica directamente solo con el emparejador, le envía solicitudes para encontrar el partido. Y notifica al meta de todos los eventos durante el emparejamiento a través de las mismas colas de mensajes. Y tan pronto como encuentra un grupo adecuado de jugadores para comenzar el partido, envía una solicitud a la cola de ubicación, que a su vez selecciona un servidor para ellos.
La interacción de meta con el servidor del juego es extremadamente simple. El servidor del juego necesita información sobre cuentas, bots y un mapa, y el meta envía toda esta información a la cola creada específicamente para esta coincidencia en un solo mensaje.

Y el servidor del juego, tras la activación, comienza a escuchar esta cola y recibe todos los datos que necesita. Al final del partido, envía sus resultados a la cola general que el meta está escuchando.
Ahora pasemos a la infraestructura adicional que utilizamos.

La implementación de servicios es bastante simple. Todos funcionan en contenedores acoplables, y utilizamos Amazon ECS para la orquestación. Es mucho más simple que Kubernetes, por supuesto, menos sofisticado, pero realiza las tareas que necesitamos de él. A saber: servicios de escalado y lanzamientos continuos, cuando necesitamos completar algún tipo de corrección de errores.
Y el último servicio que también utilizamos es AWS Fargate. Nos ahorra tener que administrar de forma independiente el grupo de máquinas en las que se ejecutan nuestros contenedores acoplables.

Como almacenamiento principal usamos DynamoDB. En primer lugar, lo elegimos porque es muy fácil de operar y escalar. También utilizamos Redis como almacenamiento adicional a través del servicio administrado Amazon ElasiCache. Lo usamos para la tarea de calificación global del jugador y para almacenar en caché los datos básicos de la cuenta en situaciones en las que necesitamos devolver datos de cientos de cuentas de juego al cliente de inmediato (por ejemplo, en la misma tabla de calificación o en la lista de amigos).
Para almacenar configuraciones, mecánicas de meta-juego, descripciones de armas, héroes, etc. Usamos un archivo JSON que adjuntamos a las imágenes de los servicios que lo necesitan. Porque es mucho más fácil para nosotros implementar una nueva versión del servicio con datos actualizados (si se descubrió algún error) que tomar una decisión que actualizará dinámicamente estos datos de algún almacenamiento externo en tiempo de ejecución.
Para iniciar sesión y monitorear, utilizamos bastantes servicios.
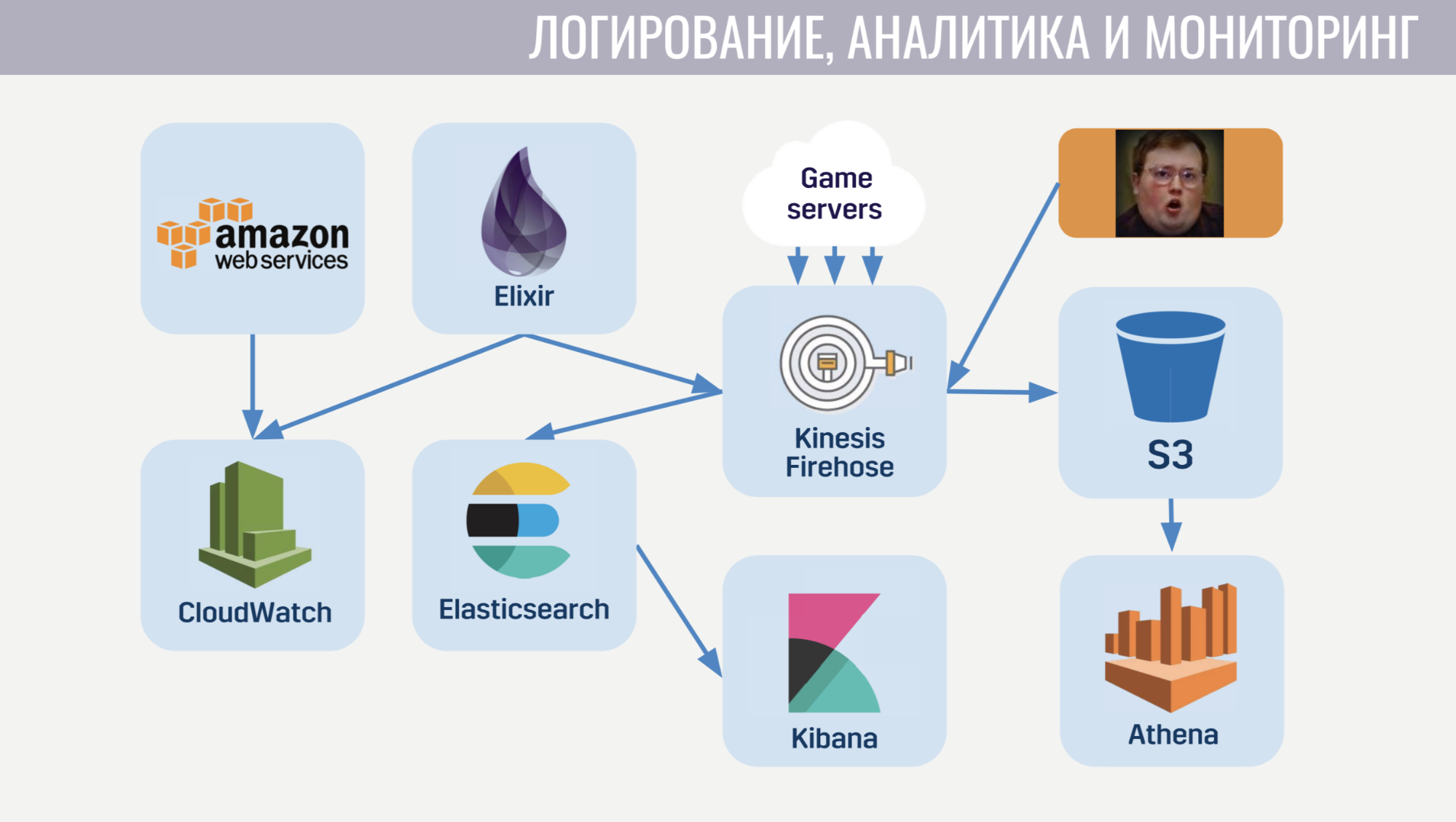
Comencemos con CloudWatch. Este es un servicio de monitoreo en el que se agrupan las métricas de todos los servicios de Amazon. Por lo tanto, decidimos enviar las métricas desde nuestro meta servidor allí también. Y para iniciar sesión, utilizamos un enfoque común tanto en el cliente como en el servidor del juego y en el meta servidor. Enviamos todos los registros al servicio amazónico Kinesis Firehose, que a su vez los transfiere a Elasticseach y S3.
En Elasticseach, solo almacenamos datos relativamente recientes y, con la ayuda de Kibana, buscamos errores, resolvemos algunas de las tareas de análisis de juegos y construimos paneles operativos, por ejemplo, con un horario de CCU y la cantidad de nuevas instalaciones. S3 contiene todos los datos históricos y los usamos a través del servicio Athena, que proporciona una interfaz SQL sobre los datos en S3.
Ahora un poco sobre cómo usamos Terraform.

Terraform es una herramienta que le permite describir declarativamente la infraestructura y, si hay algún cambio en la descripción, determina automáticamente las acciones que debe tomar para llevar su infraestructura a un aspecto actualizado. Por lo tanto, al tener una descripción única, obtenemos un entorno casi idéntico para la puesta en escena y la producción. Además, estos entornos están completamente aislados, ya que se implementan en diferentes cuentas. El único inconveniente significativo de Terraform para nosotros es el soporte incompleto de GameLift.
También hablaré sobre cómo implementamos la actualización sin tiempo de inactividad.

Cuando lanzamos actualizaciones, levantamos una copia de la mayoría de los recursos: servicios, colas de mensajes, algunas etiquetas en la base de datos. Y aquellos jugadores que descarguen la nueva versión del juego se conectarán a este grupo actualizado. Pero aquellos jugadores que aún no se hayan actualizado pueden continuar jugando durante algún tiempo en la versión anterior del juego, conectándose al clúster anterior.
Cómo lo implementamos. En primer lugar, utilizando el motor del módulo en Terraform. Hemos asignado un módulo en el que describimos todos los recursos versionados. Y estos módulos se pueden importar varias veces, con diferentes parámetros. En consecuencia, para cada versión importamos este módulo, indicando el número de esta versión. La falta de un esquema en DynamoDB también nos ayudó, lo que hace posible realizar migraciones de datos no durante la actualización, sino posponerlas para cada cuenta hasta que su propietario inicie sesión en la nueva versión del juego. Y en el equilibrador, simplemente indicamos para cada versión de la regla para que sepa a dónde dirigir a los jugadores con diferentes versiones.
Finalmente, un par de cosas que aprendimos. Primero, la configuración de toda la infraestructura debe ser automatizada. Es decir configuramos algunas cosas con nuestras manos por un tiempo, pero tarde o temprano cometimos un error en la configuración, por lo que hubo fakaps.

Y lo último: debe tener una réplica o una copia de seguridad para cada elemento de su infraestructura. Y si no lo haces por algo, esta cosa en particular nos decepcionará.
Preguntas de la audiencia
- Pero, ¿no le molesta que el autoescalado pueda retrasarse demasiado debido a algún tipo de error y obtendrá mucho dinero?- Para la escala automática, los límites aún están establecidos. No estableceremos un límite demasiado grande para no caer por mucho dinero. Esta es la solución principal + monitoreo. Puede configurar alertas si algo es demasiado fuerte.
- ¿Cuáles son tus límites actuales? Relativo a la infraestructura actual como porcentaje.- Ahora tenemos una fase de prueba beta abierta en 11 países, por lo que no es una CCU tan grande para evaluar al menos de alguna manera. Ahora la infraestructura está demasiado sobreaprovisionada para la cantidad de personas que tenemos.
- ¿Y todavía no hay límites?- Sí, es solo que son 10-100 veces más que nuestra CCU. No hagas menos.
- Dijiste que tienes líneas entre el frente y el backend, esto es muy inusual. ¿Por qué no directamente?- Queríamos servicios sin estado para implementar fácilmente el mecanismo de respaldo, de modo que el servicio no solicite más mensajes de los que tiene controladores gratuitos. Además, por ejemplo, cuando falla un controlador, la cola dará el mismo mensaje a otro controlador, tal vez tenga éxito.
- ¿La cola persiste de alguna manera?- si. Este es un servicio de Amazon SQS.
- En cuanto a las colas: ¿cuántos canales se crean durante el juego? ¿Tienes un cierto número de canales para cada partido?- Crea relativamente poco. La mayoría de las colas, como las colas de solicitud, son estáticas. Hay una cola de solicitudes de autorización, hay una cola para el inicio del partido. De las colas creadas dinámicamente, solo tenemos colas para cada interfaz (se crea para los mensajes entrantes para los clientes al inicio) y para cada coincidencia creamos una cola. En este servicio, no cuesta casi nada, tienen cualquier solicitud facturada de la misma manera. Es decir cualquier solicitud a SQS (crear una cola, leer algo de ella) cuesta lo mismo y, al mismo tiempo, no eliminamos estas colas para guardarlas, se eliminarán más adelante. Y el hecho de que existan no nos cuesta nada.
- En esta arquitectura, ¿esto no será un límite para ti?- No
Más conversaciones con Pixonic DevGAMM Talks