
Este verano, enseñamos a la red neuronal a determinar si hay un documento presente en la imagen y, de ser así, cuál.
¿Por qué es necesario?
Para descargar empleados y proteger a las personas de los estafadores. Utilizamos la nueva red neuronal en dos áreas: cuando el usuario recupera el acceso a la página y para ocultar documentos personales de la búsqueda general.
Restaurando el acceso a las páginas. Las fotos de los documentos ayudan a devolver las cuentas a sus verdaderos dueños. Por ejemplo, un usuario puede haber perdido el acceso a su número de teléfono o se ha activado la autenticación en dos pasos en la página, y ya no hay ninguna oportunidad de recibir un código único para confirmar la entrada. El nuevo desarrollo acelera la consideración de las aplicaciones: los moderadores ya no tienen que devolver aplicaciones llenadas incorrectamente cada vez. El sistema simplemente no permite que el visitante envíe el formulario sin las imágenes necesarias y solicita reemplazar la imagen aleatoria con un documento. Por supuesto, todavía podemos devolver el acceso a la página en sí solo si tiene fotos reales del propietario. Estamos hablando de la seguridad de las cuentas y la preservación de los datos personales, lo que significa que simplemente no puede haber errores ni accidentes.
Filtrar resultados de búsqueda en la sección " Documentos ". Todos los documentos que los usuarios cargan en esta sección o envían a través de mensajes privados están ocultos de las miradas indiscretas de forma predeterminada y no se incluyen en los resultados de búsqueda. Pero el nivel de privacidad se puede configurar manualmente usted mismo, para cada archivo individual. Antes del advenimiento de la red neuronal, uno podía encontrar una cantidad decente de documentos con datos confidenciales usando palabras clave. Los propios propietarios de estos archivos cambiaron la configuración de privacidad. Aseguramos a los usuarios y comenzamos
a eliminar fotos
de una búsqueda pública en la que podemos determinar la presencia de un documento.
Cómo resolvimos el problema
Parece que la forma más fácil de identificar documentos en una imagen es configurar una red neuronal o entrenarla desde cero en una muestra grande. Pero no tan simple.
La muestra debe ser representativa. Es difícil encontrar un número suficiente de muestras reales para cada opción: no hay bases de datos públicas con estos documentos en el dominio público.
Hay muchos sistemas que reconocen y analizan documentos. Por lo general, su objetivo es obtener información específica de una fotografía y sugerir la calidad ideal de la imagen original. Por ejemplo, se le puede solicitar a un usuario que alinee el pasaporte a lo largo de los bordes de la plantilla, ya que funciona en el portal de Servicios del Estado.
Dichos sistemas no son adecuados para nuestras tareas. Aclaramos por separado que al contactarnos para restablecer el acceso, el usuario
puede cerrar todos los datos del documento, excepto las fotos, el nombre, el apellido y la letra impresa. Al mismo tiempo, aún necesitamos determinar el documento, incluso si la serie y el número están ocultos, si el pasaporte se toma con los alrededores o, por el contrario, solo una parte del documento con la fotografía apareció en la imagen. Todavía necesita considerar diferentes luces y ángulos. La red neuronal debe aceptar todos esos materiales. La pregunta es cómo enseñarle esto.

Hay otras dificultades Por ejemplo, es difícil separar el pasaporte de otros tipos de documentos, así como de varios documentos escritos a mano e impresos.
Intentar ir por el camino fácil no tuvo mucho éxito. El clasificador resultante resultó ser débil, con un pequeño error del primer tipo y un gran error del segundo. Por ejemplo, hubo casos interesantes en los que una persona escribió un nombre y un apellido a mano, dibujó una fotografía, la tapa de un pasaporte, y el sistema aceptó dicho documento con indiferencia.
¿A qué hemos llegado?
En nuestra situación, la mejor solución al problema era usar un conjunto de cuadrículas y detectores faciales para reconocer un documento y determinar su tipo. También agregamos un clasificador diferencial, que incluye un codificador para resaltar las características, y un clasificador de formularios que le permite distinguir las imágenes de documentos de archivos irrelevantes. Además de esto, se lleva a cabo una agrupación preliminar del conjunto de entrenamiento para normalizar el conjunto de datos. De las arquitecturas,
VGG y
ResNet han demostrado ser
las mejores .
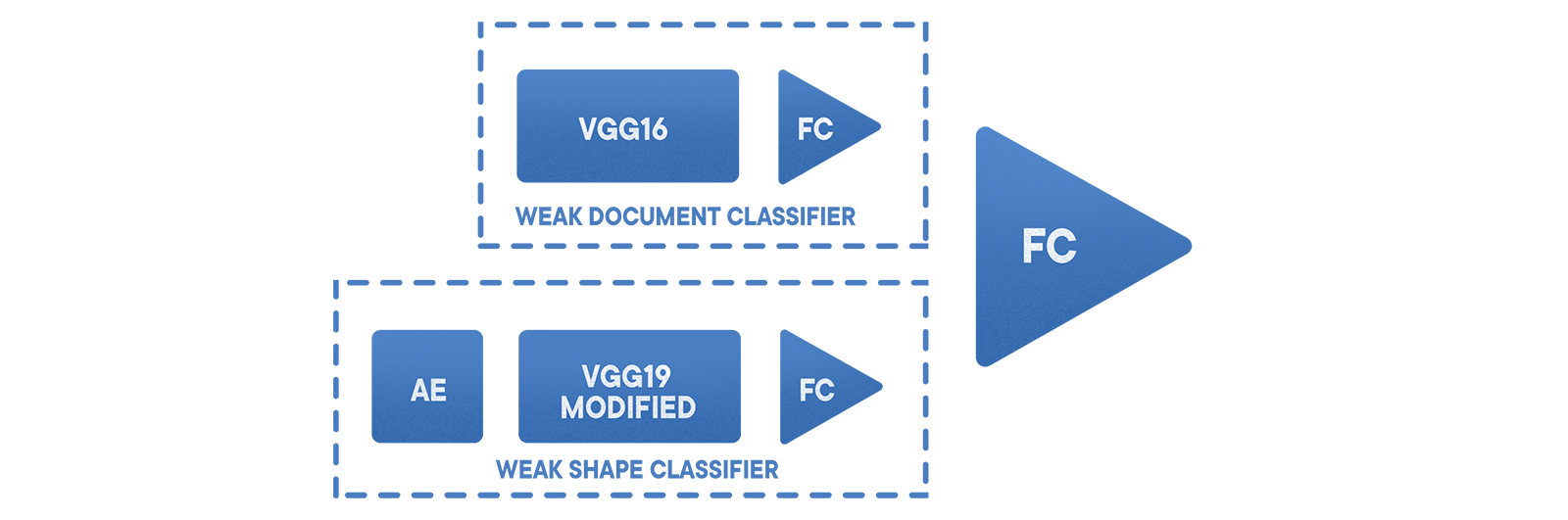
El clasificador básico "documento / no documento" funciona sobre la base de un VGG sintonizado con 19 capas y una muestra dividida en zonas. Además, se utiliza un conjunto combinado de clasificadores, que reducen el error del segundo tipo y diferencian el resultado. Primero viene el
muestreo estratificado , luego un codificador para extraer información del bucle cercano, luego un VGG modificado y finalmente una única cuadrícula. Este enfoque permitió minimizar los errores del primer tipo a un nivel de aproximadamente 0.002. La probabilidad de falso negativo en este caso depende del conjunto de datos seleccionado y la aplicación específica.
Ahora hemos aprendido cómo detectar automáticamente la presencia de pasaportes y licencias de conducir en la imagen. El reconocimiento se realiza con éxito en cualquier ángulo, con cualquier fondo, incluso en condiciones de poca luz; lo principal es que la imagen contiene una parte del documento con una fotografía y un nombre. Sin embargo, para identificar otros tipos de documentos, solo se requerirán conjuntos de datos relevantes. Capacitamos a la red con nuestros propios datos, el tamaño de la muestra de documentos es de cinco a diez mil (pero no es representativo). Para otras imágenes, la muestra es arbitraria, pero hay una agrupación a priori tanto allí como allí.
Desde un punto de vista técnico, el sistema está escrito en python /
keras /
tensorflow /
glib /
opencv . Para una aplicación práctica del nuevo sistema, es suficiente integrarlo en controladores de pitón de la infraestructura de aprendizaje automático. En la misma etapa, se agrega un detector de cambio de foto en editores gráficos, pero este tema merece un artículo separado.
Cual es el resultado
Ahora el 6% de las solicitudes para restaurar el acceso se devuelven automáticamente al autor con una solicitud para agregar o reemplazar una foto del documento, y el 2.5% de las solicitudes se rechazan. Si observa el análisis de las imágenes en su conjunto, incluidas la heurística y la búsqueda facial en una imagen,
automatiza hasta el 20% del trabajo del departamento .
Después del lanzamiento de la red neuronal, también pudimos calcular la cantidad de pasaportes que se cargan en la sección "Documentos". Resultó que en los resultados de búsqueda generales todos los días había alrededor de dos mil tarjetas de identidad. Ahora la probabilidad de que caigan en manos extrañas es mínima.
Las redes neuronales ya nos están ayudando a combatir el spam y todo tipo de fraude. No detenemos los experimentos y seguimos hablando de ellos en nuestro blog.