Este artículo es una traducción del artículo de Kevin Goldberg "Un análisis de rendimiento de los servidores Python WSGI: Parte 2" dzone.com/articles/a-performance-analysis-of-python-wsgi-servers-part con algunas adiciones del traductor.
Introduccion
En la
primera parte de esta serie, te
reuniste con
WSGI y los seis servidores más populares según el autor de
WSGI . En esta parte, se le mostrará el resultado del análisis del rendimiento de estos servidores. Para este propósito, se creó un sandbox de prueba especial.
Concursantes
Debido a limitaciones de tiempo, la investigación se limitó a seis servidores WSGI. Todas las instrucciones de inicio para este proyecto
están alojadas en GitHub . Quizás con el tiempo, el proyecto se ampliará y se presentarán análisis de rendimiento para otros servidores WSGI. Pero por ahora, hablaremos de seis servidores:
- Bjoern se describe a sí mismo como un "servidor WSGI ultrarrápido" y se jacta de que es "el servidor WSGI más rápido, pequeño y ligero". Creamos una pequeña aplicación que utiliza la mayoría de las configuraciones predeterminadas de la biblioteca.
- CherryPy es un framework y servidor WSGI extremadamente popular y estable. Este pequeño script se utilizó para servir nuestra aplicación de muestra a través de CherryPy .
- Gunicorn se inspiró en el servidor Ruby's Unicorn (de ahí el nombre). Él modestamente afirma que es "simplemente implementado, fácil de usar y bastante rápido". A diferencia de Bjoern y CherryPy , Gunicorn es un servidor independiente. Lo creamos usando este comando . El parámetro "WORKER_COUNT" se configuró en dos veces el número de núcleos de procesador disponibles, más uno. Esto se hizo en base a las recomendaciones de la documentación de Gunicorn .
- Meinheld es un servidor web compatible con WSGI de alto rendimiento que dice ser ligero. Según el ejemplo que se muestra en el sitio del servidor, creamos nuestra aplicación .
- mod_wsgi fue creado por el mismo creador que mod_python . Al igual que mod_python , solo está disponible para Apache. Sin embargo, incluye una herramienta llamada "mod_wsgi express" que crea la instancia de Apache más pequeña posible. Configuramos y utilizamos mod_wsgi express con este comando . Para que coincida con Gunicorn , ajustamos mod_wsgi para crear el doble de trabajadores que núcleos de procesador.
- uWSGI es un servidor de aplicaciones con todas las funciones. Normalmente, uWSGI está emparejado con un servidor proxy (por ejemplo: Nginx). Sin embargo, para evaluar mejor el rendimiento de cada servidor, intentamos usar solo servidores desnudos y creamos dos trabajadores para cada núcleo de procesador disponible.
Punto de referencia
Para que la prueba sea lo más objetiva posible, se creó un contenedor
Docker para aislar el servidor bajo prueba del resto del sistema. Además, el uso del contenedor Docker aseguró que cada lanzamiento comience desde cero.
Servidor:
- Aislado en un contenedor acoplable.
- 2 núcleos de procesador asignados.
- La RAM del contenedor estaba limitada a 512 MB.
Prueba:
- wrk , una moderna herramienta de evaluación comparativa HTTP, realizó pruebas.
- Los servidores se probaron en orden aleatorio con un aumento en el número de conexiones simultáneas en el rango de 100 a 10,000.
- wrk estaba limitado a dos núcleos de CPU no utilizados por Docker.
- Cada prueba duró 30 segundos y se repitió 4 veces.
Métrica:
- Wrk proporcionó el número promedio de solicitudes persistentes, errores y demoras.
- Integrado en Docker, el monitoreo mostró niveles de uso de CPU y RAM.
- Se descartaron las lecturas más altas y más bajas, y se promediaron los valores restantes.
- Para los curiosos, enviamos el guión completo a GitHub .
Resultados
Todos los indicadores de rendimiento iniciales
se incluyeron en el repositorio del proyecto , y también se proporcionó un
archivo CSV de resumen. Además, para la visualización, se crearon gráficos en el entorno
Google-doc .
RPS versus número de conexiones simultáneas
Este gráfico muestra el número promedio de solicitudes concurrentes; Cuanto mayor sea el número, mejor.
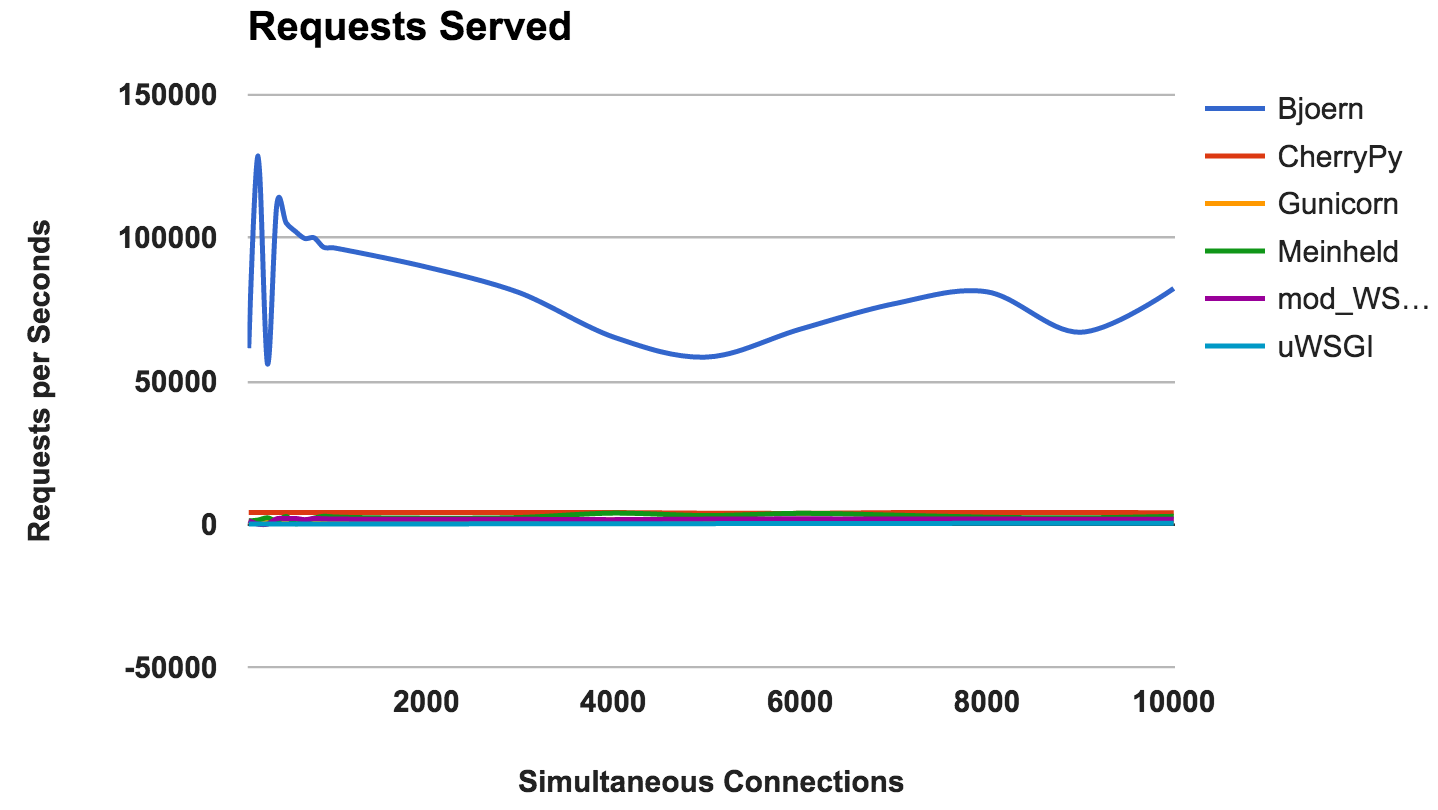
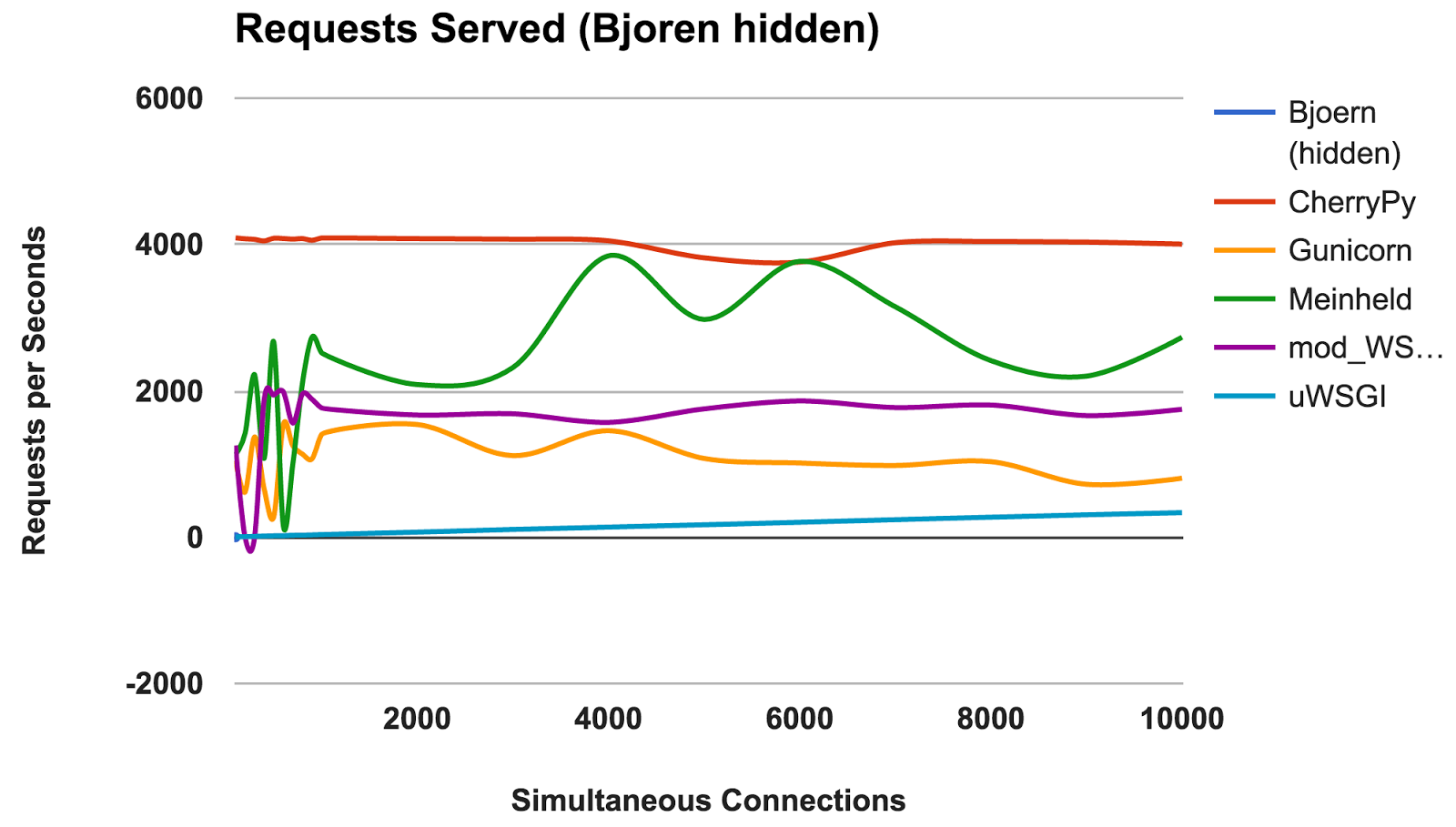
- Bjoern: Un claro ganador.
- CherryPy: A pesar de estar escrito en Python puro, fue el mejor intérprete.
- Meinheld: Excelente rendimiento dados los escasos recursos del contenedor.
- mod_wsgi: No es el más rápido, pero el rendimiento fue consistente y adecuado.
- Gunicorn: Buen rendimiento con cargas más bajas, pero hay una pelea con una gran cantidad de conexiones.
- uWSGI: Frustrado con malos resultados.
GANADOR: BjoernBjoern
Por el número de solicitudes constantes,
Bjoern es el claro ganador. Sin embargo, dado que los números son mucho más altos que los de los competidores, somos un poco escépticos. No estamos seguros de que
Bjoern sea realmente tan increíblemente rápido. Al principio probamos los servidores alfabéticamente, y pensamos que
Bjoern tenía una ventaja injusta. Sin embargo, incluso después de iniciar los servidores en un orden de servidor aleatorio y volver a probar, el resultado sigue siendo el mismo.
uWSGI
Estábamos decepcionados con los débiles resultados de
uWSGI . Esperábamos que él estuviera a la cabeza. Durante las pruebas, notamos que los registros
uWSGI se imprimen en la pantalla, e inicialmente explicamos la falta de rendimiento con el trabajo adicional que realizó el servidor. Sin embargo, incluso después de agregar la opción "
--disable-logging ",
uWSGI sigue siendo el servidor más lento.
Como se menciona en el manual
uWSGI , generalmente interactúa con un servidor proxy como Nginx. Sin embargo, no estamos seguros de que esto pueda explicar una diferencia tan grande.
Retraso
El retraso es la cantidad de tiempo transcurrido entre la solicitud y su respuesta. Los números más bajos son mejores.
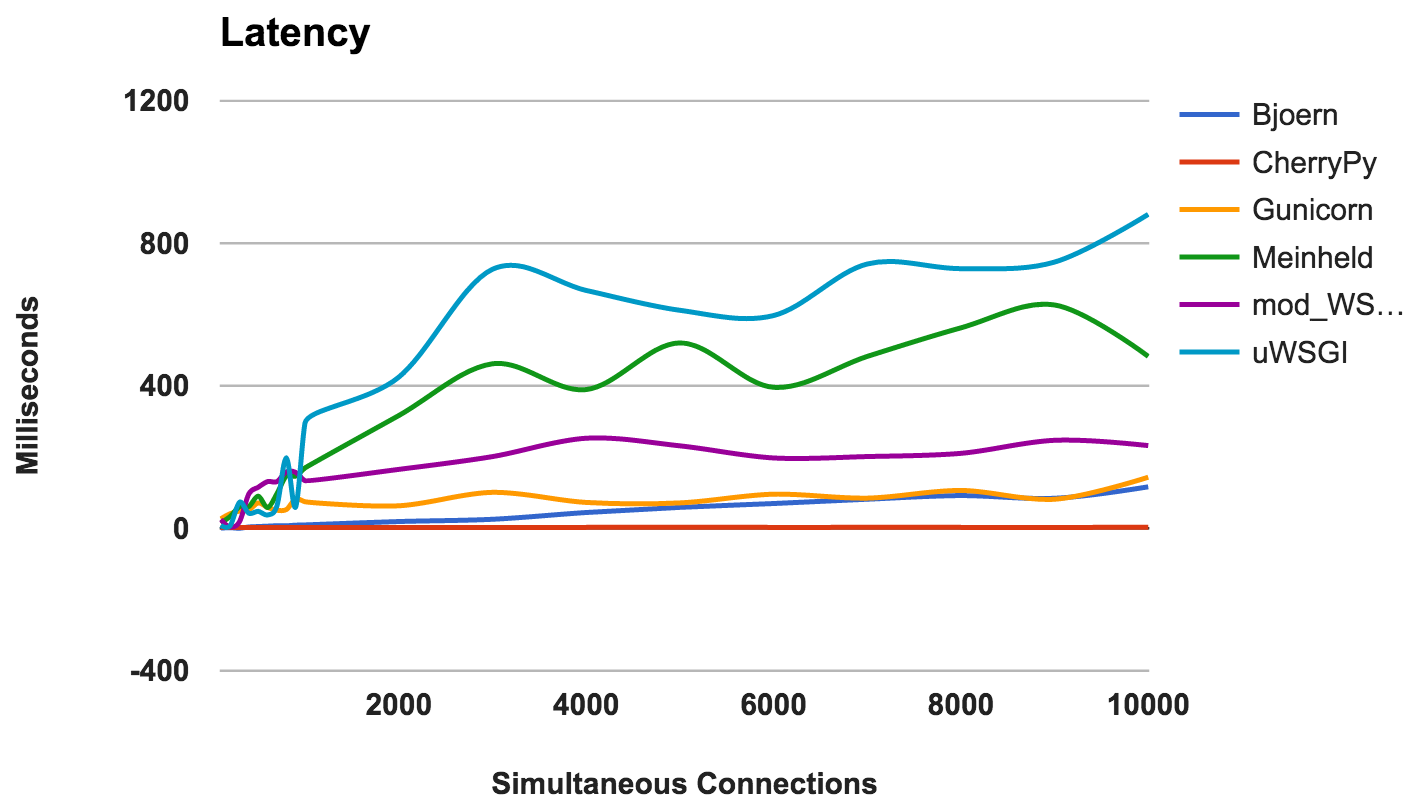
- CherryPy: Manejó bien la carga.
- Bjoern: generalmente baja latencia, pero funciona mejor con menos conexiones concurrentes.
- Gunicorn: bueno y consistente.
- mod_wsgi: rendimiento promedio, incluso con una gran cantidad de conexiones simultáneas.
- Meinheld: En general, rendimiento aceptable.
- uWSGI: uWSGI está nuevamente en el último lugar.
GANADOR: CherryPyUso de RAM
Esta métrica muestra los requisitos de memoria y la "ligereza" de cada servidor. Los números más bajos son mejores.
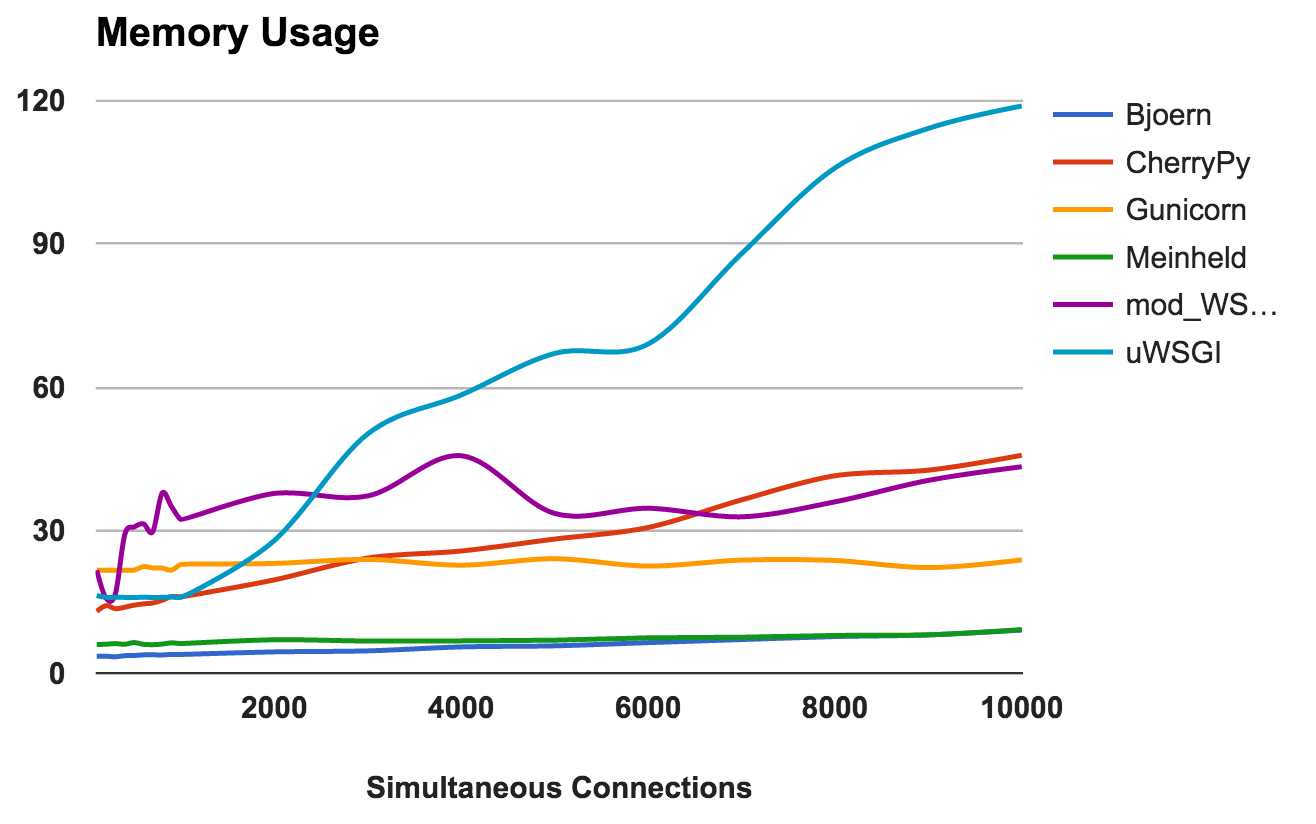
- Bjoern: extremadamente ligero. Utiliza solo 9 MB de RAM para procesar 10,000 solicitudes concurrentes.
- Meinheld: Igual que Bjoern .
- Gunicorn: hábilmente hace frente a altas cargas con un consumo de memoria apenas perceptible.
- CherryPy: inicialmente necesitaba una pequeña cantidad de RAM, pero su uso aumentó rápidamente al aumentar la carga.
- mod_wsgi: En los niveles más bajos, fue uno de los más intensos en la memoria, pero se mantuvo bastante consistente.
- uWSGI: Obviamente, la versión que estamos probando tiene problemas con la cantidad de memoria consumida.
GANADORES: Bjoern y MeinheldNumero de errores
Se produce un error cuando el servidor se bloquea, se interrumpe o se agota el tiempo de espera de la solicitud. Cuanto más bajo, mejor.
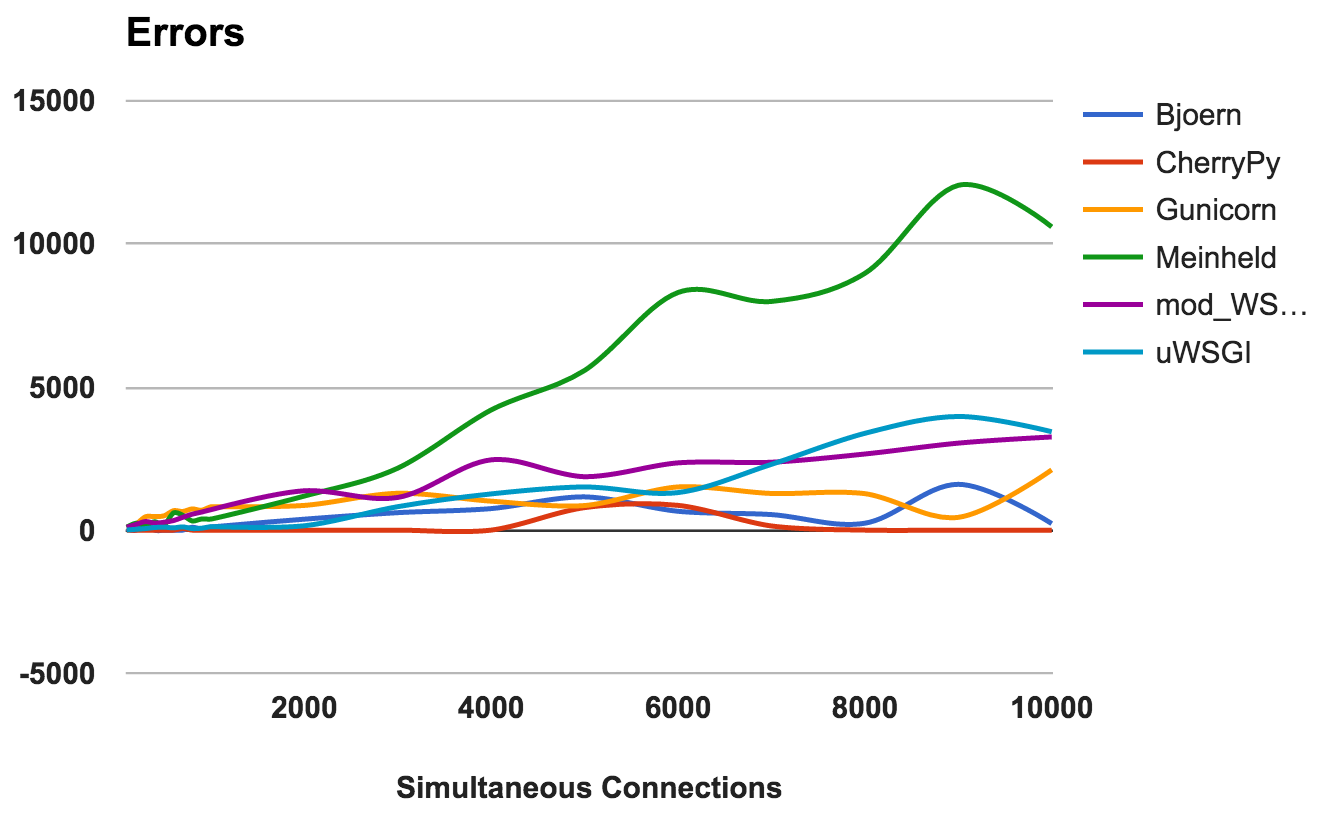
Para cada servidor, calculamos la proporción de la proporción total de la cantidad de solicitudes a la cantidad de errores:
- CherryPy: tasa de error alrededor de 0, incluso con un gran número de conexiones.
- Bjoern: se produjeron errores, pero esto se compensó con la cantidad de solicitudes procesadas.
- mod_wsgi: funciona bien con una tasa de error aceptable del 6%.
- Gunicorn: funciona con una tasa de error del 9 por ciento.
- uWSGI: Dada la baja cantidad de solicitudes que atendió, terminó con una tasa de error del 34 por ciento.
- Meinheld: cayó a cargas más altas, arrojando más de 10,000 errores durante la prueba más exigente.
GANADOR: CherryPyUso de la CPU
La alta utilización de la CPU no es buena o mala si el servidor funciona bien. Sin embargo, esto proporciona información interesante sobre el servidor. Como se usaron dos núcleos de CPU, el uso máximo posible es del 200 por ciento.
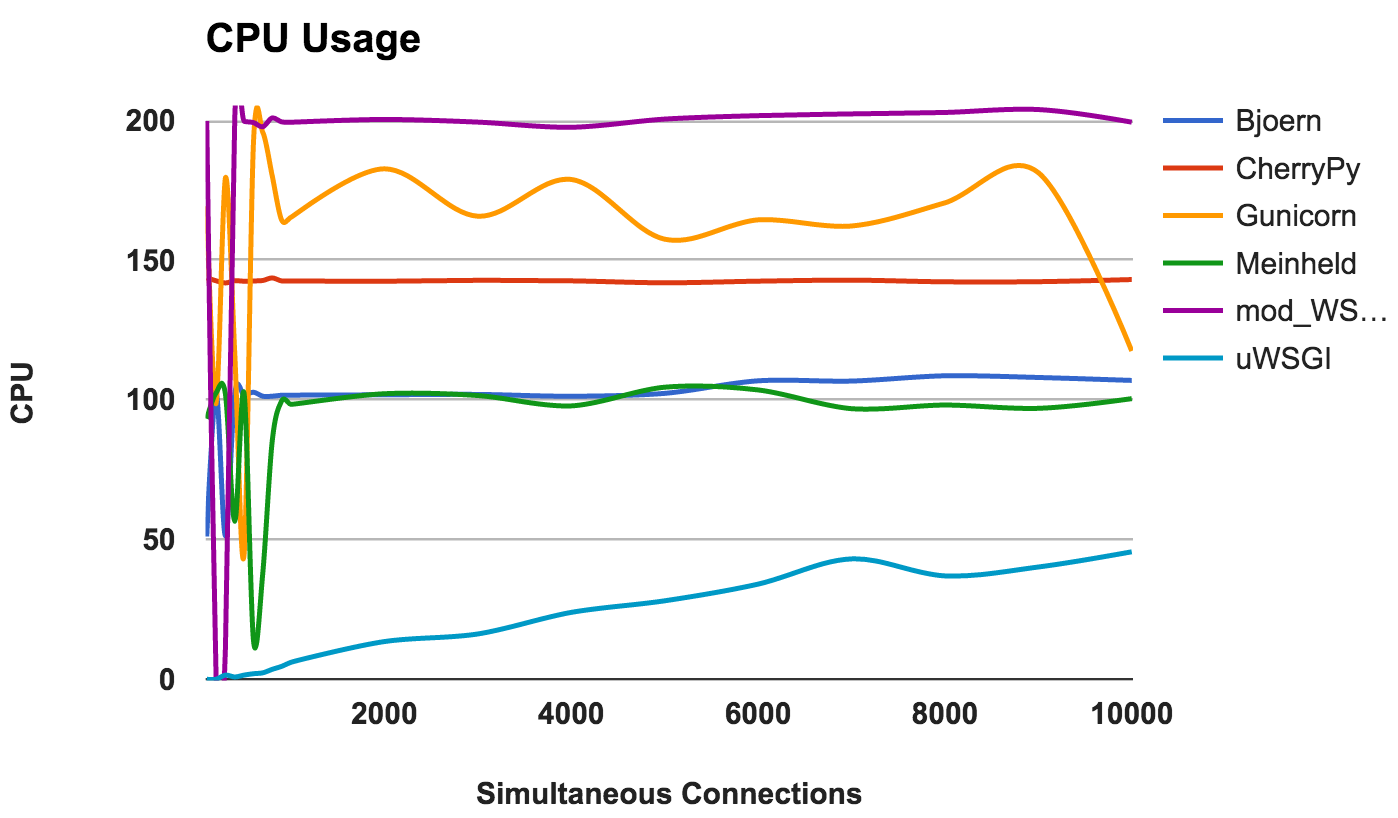
- Bjoern: un servidor de un solo subproceso, como lo demuestra su uso constante del 100% de la CPU.
- CherryPy: multiproceso, pero atascado en 150 por ciento. Esto puede deberse a Python GIL .
- Gunicorn: utiliza varios procesos con el uso completo de los recursos de la CPU en los niveles inferiores.
- Meinheld: un servidor de un solo subproceso que utiliza recursos de CPU como Bjoern.
- mod_wsgi: un servidor multiproceso que utiliza todos los núcleos de CPU en todas las mediciones
- uWSGI: muy bajo uso de CPU. El consumo de CPU no supera el 50 por ciento. Esta es una prueba de que uWSGI no está configurado correctamente.
GANADOR: No, porque esto es más una observación en el comportamiento que una comparación en el rendimiento.Conclusión
Para resumir! Aquí hay algunas ideas generales que puede extraer de los resultados de cada servidor:
- Bjoern: se justifica como un "servidor WSGI ultrarrápido y ultraligero".
- CherryPy: alto rendimiento, bajo consumo de memoria y bajas tasas de error. No está mal para Python puro.
- Gunicorn: un buen servidor para cargas medias.
- Meinheld: funciona bien y requiere recursos mínimos. Sin embargo, luchando con cargas más altas.
- mod_wsgi: se integra con Apache y funciona muy bien.
- uWSGI: Muy decepcionado. O configuramos uWSGI incorrectamente, o la versión que instalamos tiene errores básicos.