En septiembre, se celebró el sexto Hyperbaton, la conferencia de Yandex sobre todo lo relacionado con la documentación técnica. Publicaremos varias conferencias de Hyperbaton, que, en nuestra opinión, pueden ser de mayor interés para los lectores de Habr.
Svetlana Kayushina, jefa del departamento de documentación y localización:
- Parece que en el mundo no hay más personas que traducen manualmente. Hoy queremos hablar sobre herramientas y enfoques que ayudan a las empresas a organizar un proceso de localización efectivo, y los traductores hacen que sea más fácil resolver sus problemas cotidianos. Hoy hablaremos sobre la traducción automática, sobre la evaluación de la efectividad de los motores automáticos y sobre los sistemas de traducción automática para traductores.
Comencemos con el informe de nuestros colegas. Invito a Irina Rybnikova y Anastasia Ponomareva: hablarán sobre la experiencia de Yandex en la introducción de la traducción automática en nuestros procesos de localización.
Irina Rybnikova:
Gracias. Le informaremos sobre la historia de la traducción automática y cómo la usamos en Yandex.

En el siglo XVII, los científicos pensaban en la existencia de un idioma que conectara otros idiomas, y esto probablemente sea demasiado largo. Volvamos más cerca. Todos queremos entender a las personas que nos rodean, sin importar de dónde venimos, queremos ver lo que está escrito en los carteles, queremos leer anuncios, información sobre conciertos. La idea del pez babilónico surca las mentes de los científicos, se encuentra en la literatura, el cine, en todas partes. Queremos reducir el tiempo durante el cual accedemos a la información. Queremos leer artículos sobre tecnologías chinas, entender cualquier sitio que veamos y queremos obtenerlo aquí y ahora.

En este contexto, es imposible no hablar de traducción automática. Esto es lo que ayuda a resolver este problema.

El punto de partida es 1954, cuando 60 oraciones sobre el tema general de la química orgánica se tradujeron del ruso al inglés en los EE. UU. En una máquina IBM 701, y todo esto se basó en 250 términos del glosario y seis reglas gramaticales. Esto se llamó el experimento de Georgetown, y fue tan impactante que los periódicos estuvieron llenos de titulares que por otros tres a cinco años, y el problema se resolverá por completo, todos estarán felices. Pero como sabes, todo fue un poco diferente.
En los años 70, apareció la traducción automática basada en reglas. También se basó en diccionarios bilingües, pero también en esos conjuntos de reglas que ayudaron a describir cualquier idioma. Cualquiera, pero con limitaciones.

Se requerían expertos lingüísticos serios que establecieran las reglas. Este es un trabajo bastante complicado, todavía no podía tener en cuenta el contexto, cubrir completamente cualquier idioma, pero eran expertos, y luego no se requería una gran potencia de cómputo.

Si hablamos de calidad, un ejemplo clásico es una cita de la Biblia, que luego se traduce así. Aún no es suficiente. Por lo tanto, la gente continuó trabajando en la calidad. En los años 90, apareció un modelo de traducción estadística, SMT, que hablaba sobre la distribución probabilística de palabras, oraciones, y este sistema era fundamentalmente diferente en el sentido de que no sabía nada sobre las reglas y la lingüística. Recibió una gran cantidad de textos idénticos, combinados en un idioma y otro, y luego tomó decisiones por sí misma. Era fácil de mantener, no se necesitaban muchos expertos, no había que esperar. Puede descargar y obtener el resultado.

Los requisitos para los datos entrantes fueron bastante promedio, de 1 a 10 millones de segmentos. Segmentos: oraciones, frases pequeñas. Pero sus dificultades persistieron y el contexto no se tuvo en cuenta; no todo fue muy fácil. Y en Rusia, por ejemplo, aparecieron tales casos.

También me gusta el ejemplo de traducir juegos de GTA, el resultado fue excelente. Todo no se detuvo. 2016 fue un hito importante cuando comenzó la traducción automática neuronal. Fue un evento de época que cambió mucho la vida. Mi colega, después de mirar las traducciones y cómo las usamos, dijo: "Genial, habla con mis palabras". Y fue realmente genial.
Que caracteristicas Altos requisitos de entrada, material de capacitación. Es difícil de mantener dentro de la empresa, pero un aumento significativo en la calidad es para lo que fue concebido. Solo una traducción de alta calidad resolverá las tareas y facilitará la vida de todos los participantes en el proceso, los mismos traductores que no desean corregir una mala traducción, quieren realizar nuevas tareas creativas y dar frases rutinarias a la máquina.
Hay dos enfoques para la traducción automática. Evaluación experta / análisis lingüístico de textos, es decir, verificación por parte de lingüistas reales, expertos para el cumplimiento del significado, alfabetización del idioma. En algunos casos, los expertos todavía estaban plantados, se les permitió restar el texto traducido y evaluaron qué tan efectivo era desde este punto de vista.

¿Cuáles son las características de este método? No se requiere traducción de muestra, miramos el texto traducido terminado ahora y lo evaluamos objetivamente para cualquier sección. Pero es caro y largo.

Hay un segundo enfoque: las métricas de referencia automáticas. Hay muchos de ellos, cada uno tiene sus pros y sus contras. No profundizaré más. Puede leer más sobre estas palabras clave más adelante.
Que caracteristica De hecho, esta es una comparación de los textos traducidos de la máquina con alguna traducción ejemplar. Estas son métricas cuantitativas que muestran la discrepancia entre la traducción ejemplar y lo que sucedió. Es rápido, barato y se puede hacer de manera bastante conveniente. Pero hay características.

De hecho, la mayoría de las veces usan métodos híbridos. Esto es cuando algo se evalúa automáticamente inicialmente, luego se analiza una matriz de errores, luego se realiza un análisis lingüístico experto en un cuerpo de textos más pequeño.

Recientemente, la práctica aún está muy extendida cuando no llamamos lingüistas allí, sino simplemente usuarios. Se está creando una interfaz: muestre qué traducción le gusta más. O cuando va a los traductores en línea, ingresa texto y, a menudo, puede votar lo que más le guste, ya sea que este enfoque sea adecuado o no. De hecho, ahora todos entrenamos estos motores, y usan todo para entrenar para entrenar y trabajar en su calidad.
Me gustaría contar cómo utilizamos la traducción automática en nuestro trabajo. Le paso la palabra a Anastasia.
Anastasia Ponomareva:
- En Yandex, en el departamento de localización, nos dimos cuenta rápidamente de que la tecnología de traducción automática tenía un gran potencial y decidimos intentar usarla en nuestras tareas diarias. Por donde empezamos Decidimos realizar un pequeño experimento. Decidimos traducir los mismos textos a través de un traductor regular de redes neuronales, y también reunir un traductor automático capacitado. Para hacer esto, hemos preparado un corpus de textos en un par de ruso-inglés para los años que en Yandex nos dedicamos a la localización de textos en estos idiomas. Luego llegamos con este corpus de textos a nuestros colegas de Yandex.Translate y pedimos entrenar el motor.

Cuando se entrenó el motor, tradujimos el siguiente lote de textos y, como dijo Irina, con la ayuda de expertos, evaluamos los resultados. Les pedimos a los traductores que analizaran la alfabetización, el estilo, la ortografía y la transmisión de significado. Pero el punto de inflexión fue cuando uno de los traductores dijo que "reconozco mi estilo, reconozco mis traducciones".
Para reforzar estas sensaciones, decidimos calcular los indicadores estadísticos. Primero, calculamos el coeficiente BLEU para las transferencias realizadas a través de un motor de red neuronal regular, y obtuvimos esta cifra (0.34). Parece que debe compararse con algo. Nuevamente fuimos a colegas de Yandex.Translator y les pedimos que explicaran qué coeficiente BLEU se considera umbral para las transferencias realizadas por una persona real. Esto es de 0.6.
Luego decidimos verificar cuáles son los resultados de las traducciones capacitadas. Tengo 0.5. Los resultados son realmente alentadores.

Doy un ejemplo. Esta es una verdadera frase rusa de la documentación de Direct. Luego fue transferido a través de un motor de red neuronal regular, y luego a través de un motor de red neuronal entrenado en nuestros textos. Ya en la primera línea notamos que no se reconoce el tipo tradicional de publicidad para Direct. Y ya en el motor de red neuronal entrenado aparece nuestra traducción, e incluso la abreviatura es casi correcta.
Los resultados nos alentaron mucho y decidimos que probablemente valga la pena usar el motor en otros pares, en otros textos, no solo en ese conjunto básico de documentación técnica. Se llevó a cabo una serie de experimentos durante varios meses. Frente a muchas características y problemas, estos son los problemas más comunes que tuvimos que resolver.

Te contaré más sobre cada uno.

Si, como nosotros, está planeando hacer un motor personalizado, necesitará una cantidad bastante grande de datos paralelos de alta calidad. El gran motor puede ser entrenado en la cantidad de 10 mil ofertas, en nuestro caso, hemos preparado 135 mil ofertas paralelas.

No en todos los tipos de texto, su motor mostrará resultados igualmente buenos. En la documentación técnica, donde hay oraciones largas, estructura, documentación del usuario e incluso en la interfaz, donde hay botones cortos pero claros, lo más probable es que esté bien. Pero tal vez, como con nosotros, encuentre problemas de marketing.
Realizamos un experimento, traduciendo listas de reproducción de música, y obtuvimos ese ejemplo.

Eso es lo que piensa un traductor automático sobre los trabajadores de las fábricas estrella. ¿Cuáles son los bateristas del trabajo?

Al traducir a través de un motor de máquina, el contexto no se tiene en cuenta. Este ya no es un ejemplo tan ridículo, sino bastante real, de la documentación técnica de Yandex.Direct. Parece que son comprensibles cuando lees la documentación técnica, esos son los técnicos. Pero no, el motor no golpeó.

También debe tener en cuenta que la calidad y el significado de la traducción dependerán en gran medida del idioma original. Traducimos la frase al francés del ruso, obtenemos un resultado. Obtenemos una frase similar con el mismo significado, pero del inglés, y obtenemos un resultado diferente.

Si, como en nuestro texto, tiene una gran cantidad de etiquetas, marcas, algunas características técnicas, lo más probable es que tenga que rastrearlas, editarlas y escribir algunos scripts.
Aquí hay ejemplos de frases reales del navegador. Entre paréntesis hay información técnica que no debe traducirse, en particular múltiples formas. En inglés están en inglés, y en alemán también deben permanecer en inglés, pero están traducidos. Deberá realizar un seguimiento de estos puntos.
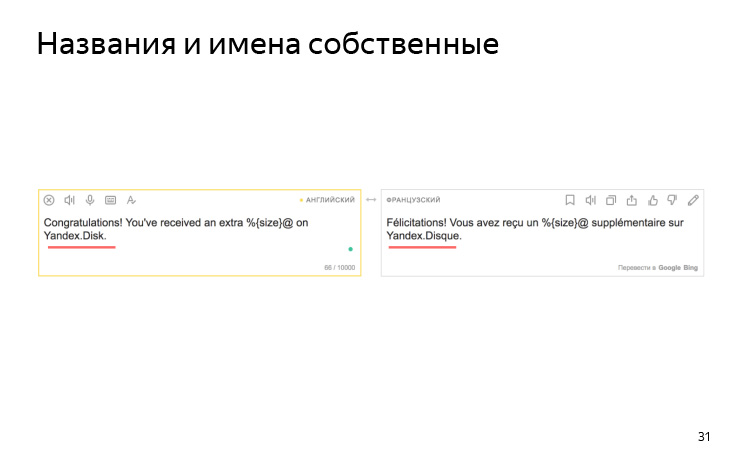
El motor no sabe nada sobre sus convenciones de nomenclatura. Por ejemplo, tenemos un acuerdo que siempre llamamos Yandex.Disk en latín en todos los idiomas. Pero en francés, se convierte en un disco en francés.

Las abreviaturas a veces se reconocen correctamente, a veces no. En este ejemplo, BY, que denota pertenencia a los requisitos técnicos bielorrusos para publicidad, se convierte en una excusa en inglés.

Uno de mis ejemplos favoritos son las palabras nuevas y prestadas. Aquí hay un ejemplo genial, la palabra descargo de responsabilidad, "primordialmente ruso". La terminología tendrá que ser verificada para cada parte del texto.
Y un problema más, no tan significativo: la escritura obsoleta.

Anteriormente, Internet era una novedad, se capitalizaba en todos los textos, y cuando entrenamos nuestro motor, en todas partes se capitalizaba Internet. Ahora es una nueva era, Internet ya se está escribiendo con una letra minúscula. Si desea que su motor continúe escribiendo Internet con una letra minúscula, tendrá que volver a entrenarlo.

No nos desesperamos, resolvimos estos problemas. Primero, cambiaron el cuerpo de textos, intentaron traducir sobre otros temas. Transmitimos nuestros comentarios a colegas de Yandex.Translator, volvimos a entrenar la red neuronal y observamos los resultados, evaluamos y solicitamos finalizar. Por ejemplo, reconocimiento de etiquetas, procesamiento de marcado HTML.
Mostraré casos de uso real. Tenemos una buena traducción automática para la documentación técnica. Este es un caso real.

Aquí está la frase en inglés y en ruso. El traductor que trató con esta documentación fue muy alentado por la elección apropiada de la terminología. Otro ejemplo.

El traductor apreció que la elección de es en lugar de un guión, que la estructura de la frase ha cambiado al inglés, una elección adecuada del término correcto y la palabra usted, que no está en el original, pero hace que esta traducción sea exactamente inglés, natural.

Otro caso es la traducción de interfaces sobre la marcha. Uno de los servicios decidió no molestarse con la localización y traducir textos directamente en el momento del arranque. Pero después de cambiar el motor aproximadamente una vez al mes, la palabra "entrega" cambió en un círculo. Sugerimos que el equipo conecte no un motor de red neuronal ordinario, sino el nuestro, capacitado en documentación técnica, para que siempre se use el mismo término, acordado con el equipo que ya está en la documentación.

¿Cómo funciona todo esto por un momento monetario? Originalmente, sucedió que un par de ruso-ucraniano requiere una edición mínima de la traducción al ucraniano. Por lo tanto, hace un par de meses decidimos cambiar a un sistema de edición posterior. Así es como crecen nuestros ahorros. Septiembre aún no ha terminado, pero pensamos que hemos reducido nuestros costos posteriores a la edición en aproximadamente un tercio en ucraniano, y vamos a editar casi todo excepto los textos de marketing. La palabra Irina para resumir.
Irina
- Para todos es obvio que es necesario usarlo, ya es nuestra realidad y es imposible excluirlo de nuestros procesos e intereses. Pero debes pensar en algunas cosas.

Decida los tipos de documentos, el contexto con el que trabaja. ¿Es esta tecnología adecuada para usted?
Segundo momento Hablamos de Yandex.Translator, porque estamos en una buena relación, tenemos acceso directo a los desarrolladores, etc., pero de hecho debes decidir qué motor será el más óptimo para ti específicamente, para tu idioma, tu tema. El
próximo informe estará dedicado a este tema. Esté preparado para que todavía haya dificultades, los desarrolladores de los motores están trabajando juntos para resolver las dificultades, pero hasta ahora todavía se están encontrando.

Me gustaría entender lo que nos espera en el futuro. Pero, de hecho, esto no es más, sino nuestro tiempo actual, lo que está sucediendo aquí y ahora. Todos necesitamos personalizar nuestra terminología, nuestros textos, y esto es lo que ahora se está haciendo público. Ahora todo el mundo está trabajando para asegurarse de que no ingrese a la empresa, no esté de acuerdo con los desarrolladores de un motor en particular, cómo optimizar esto para usted. Podrá recibirlo en motores abiertos públicos en API.
La personalización no es solo en los textos, sino también en la terminología, para configurar la terminología para sus propias necesidades. Este es un punto importante. El segundo tema es la traducción interactiva. Cuando un traductor traduce un texto, la tecnología le permite predecir las siguientes palabras teniendo en cuenta el idioma fuente, el texto fuente. Esta barrena puede facilitar enormemente el trabajo.
Eso ahora es realmente caro. Todos piensan cómo enseñar algunos motores de manera mucho menos efectiva con menores cantidades de texto. Esto es lo que sucede en todas partes y se ejecuta en todas partes. Creo que el tema es muy interesante, y luego será aún más interesante.
Hemos recopilado varios artículos que pueden interesarle. Gracias
-
Dos modelos son mejores que uno. Experiencia de Yandex.Translator-
Cómo Yandex aplicó la tecnología de inteligencia artificial para traducir páginas web-
Traducción automática. De la guerra fría a la diplomacia