Nota perev. : El artículo original fue escrito por un escritor técnico de Google, trabajando en la documentación para Kubernetes (Andrew Chen) y el director de ingeniería de software de SAP (Dominik Tornow). Su objetivo es explicar clara y claramente los conceptos básicos de la organización e implementación de alta disponibilidad en Kubernetes. Nos parece que los autores tuvieron éxito, por lo que nos complace compartir la traducción.
Kubernetes es un motor de orquestación de contenedores diseñado para ejecutar aplicaciones en contenedores en múltiples nodos, comúnmente conocido como un clúster. En estas publicaciones, utilizamos un enfoque de modelado de sistemas para mejorar la comprensión de Kubernetes y sus conceptos subyacentes. Se alienta a los lectores a que ya tengan una comprensión básica de Kubernetes.
Kubernetes es un motor de orquestación de contenedores escalable y confiable. La escalabilidad aquí está determinada por la capacidad de respuesta en presencia de carga, y la confiabilidad está determinada por la capacidad de respuesta en presencia de fallas.
Tenga en cuenta que la escalabilidad y confiabilidad de Kubernetes no significa la escalabilidad y confiabilidad de la aplicación que se ejecuta en él. Kubernetes es una plataforma escalable y confiable, pero cada aplicación K8 todavía tiene que pasar por ciertas etapas para convertirse en una y evitar cuellos de botella y puntos únicos de falla.
Por ejemplo, si la aplicación se implementa como ReplicaSet o Deployment, Kubernetes (re) planifica y (re) lanza pods afectados por bloqueos de nodos. Sin embargo, si la aplicación se implementa como un pod, Kubernetes no tomará ninguna medida en caso de falla de un nodo. Por lo tanto, aunque Kubernetes se mantiene operativo, la capacidad de respuesta de su aplicación depende de la arquitectura elegida y las decisiones de implementación.
Esta publicación se centra en la fiabilidad de Kubernetes. Ella habla sobre cómo Kubernetes mantiene la capacidad de respuesta en presencia de fallas.
Arquitectura Kubernetes
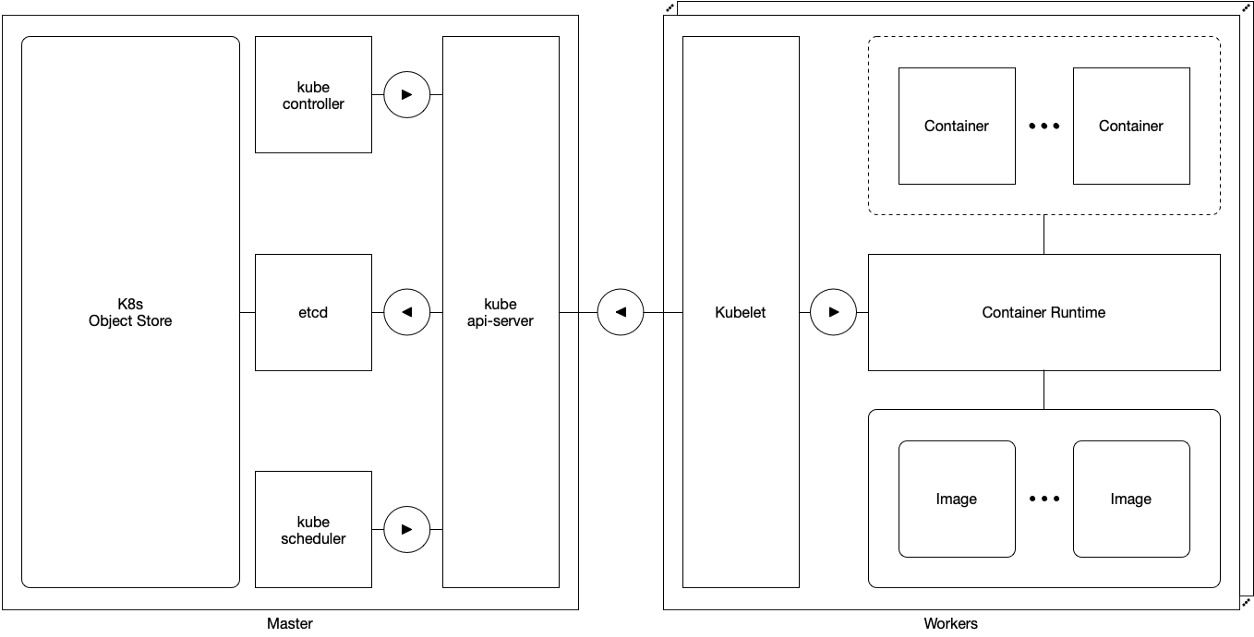
 Esquema 1. Maestro y trabajador
Esquema 1. Maestro y trabajadorA nivel conceptual, los componentes de Kubernetes se agrupan en dos clases distintas: componentes
maestros y componentes
trabajadores .
Los maestros son responsables de administrar todo, excepto la ejecución de los hogares. Los componentes del asistente incluyen:
Los trabajadores son responsables de gestionar la ejecución de los hogares. Tienen un componente:
Los trabajadores son trivialmente confiables: una falla temporal o permanente de cualquier trabajador en un grupo no afecta al maestro u otros trabajadores del grupo. Si la aplicación se implementa adecuadamente, Kubernetes (re) planifica y (re) inicia a cualquiera afectado por la falla del trabajador.
Configuración de asistente individual
 Esquema 2. Configuración con un solo maestro
Esquema 2. Configuración con un solo maestroEn una configuración de maestro único, el clúster de Kubernetes consta de un maestro y muchos trabajadores. Estos últimos están directamente conectados al asistente de kube-apiserver e interactúan con él.
En esta configuración, la capacidad de respuesta de Kubernetes depende de:
- el unico maestro
- conectando trabajadores a un solo maestro.
Debido a que el único maestro es un único punto de falla, esta configuración no pertenece a la categoría de alta disponibilidad.
Configuración de asistente múltiple
 Esquema 3. Configuración con muchos maestros
Esquema 3. Configuración con muchos maestrosEn una configuración de varios maestros, el clúster de Kubernetes consta de muchos maestros y muchos trabajadores. Los trabajadores se conectan al kube-apiserver de cualquier maestro e interactúan con él a través de un equilibrador de carga altamente accesible.
En esta configuración, Kubernetes
es independiente de:
- el unico maestro
- conectando trabajadores a un solo maestro.
Como no hay un único punto de falla en esta configuración, se considera altamente accesible.
Líder y seguidor en Kubernetes
En una configuración de múltiples asistentes, intervienen numerosos gestores de controladores de kube y planificadores de kube. Si dos componentes modifican los mismos objetos, pueden surgir conflictos.
Para evitar conflictos potenciales, para kube-controller-manager y kube-Scheduler, Kubernetes implementa el
patrón “
maestro-esclavo ”
(líder / seguidor) . Cada grupo elige un líder
(o líder) , y los miembros restantes del grupo asumen el papel de seguidores. En un momento dado, solo un líder está activo, y los seguidores son pasivos.
 Figura 4. Asistente de componentes de implementación redundante en detalle
Figura 4. Asistente de componentes de implementación redundante en detalleEsta ilustración muestra un ejemplo detallado donde kube-controller-1 y kube-Scheduler-2 son líderes entre kube-controller-managers y kube-Schedulers. Como cada grupo elige a su propio líder, no tienen que estar en el mismo maestro en absoluto.
Selección de plomo
Los miembros del grupo seleccionan un nuevo líder en el momento del lanzamiento o en caso de una caída del líder. Plomo: un miembro con el llamado
arrendamiento de líder (actualmente estado de líder "arrendado").
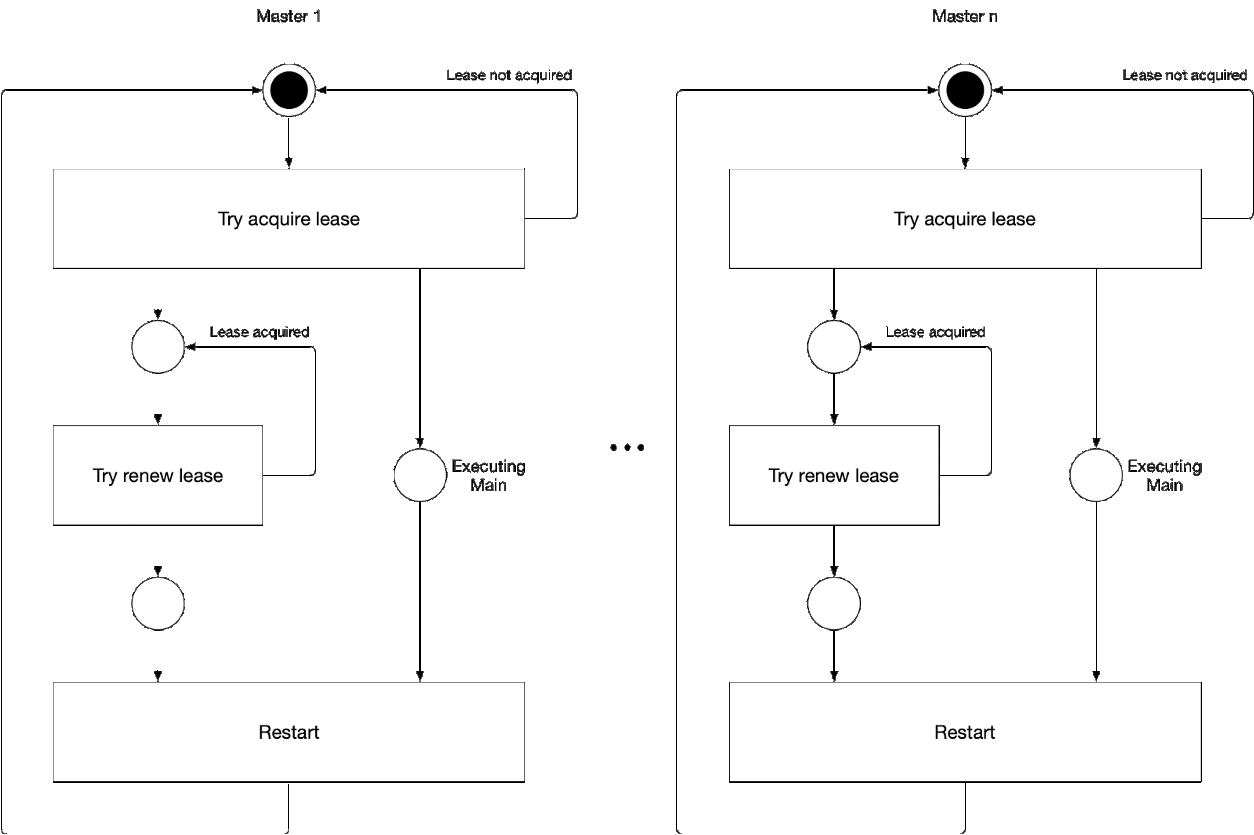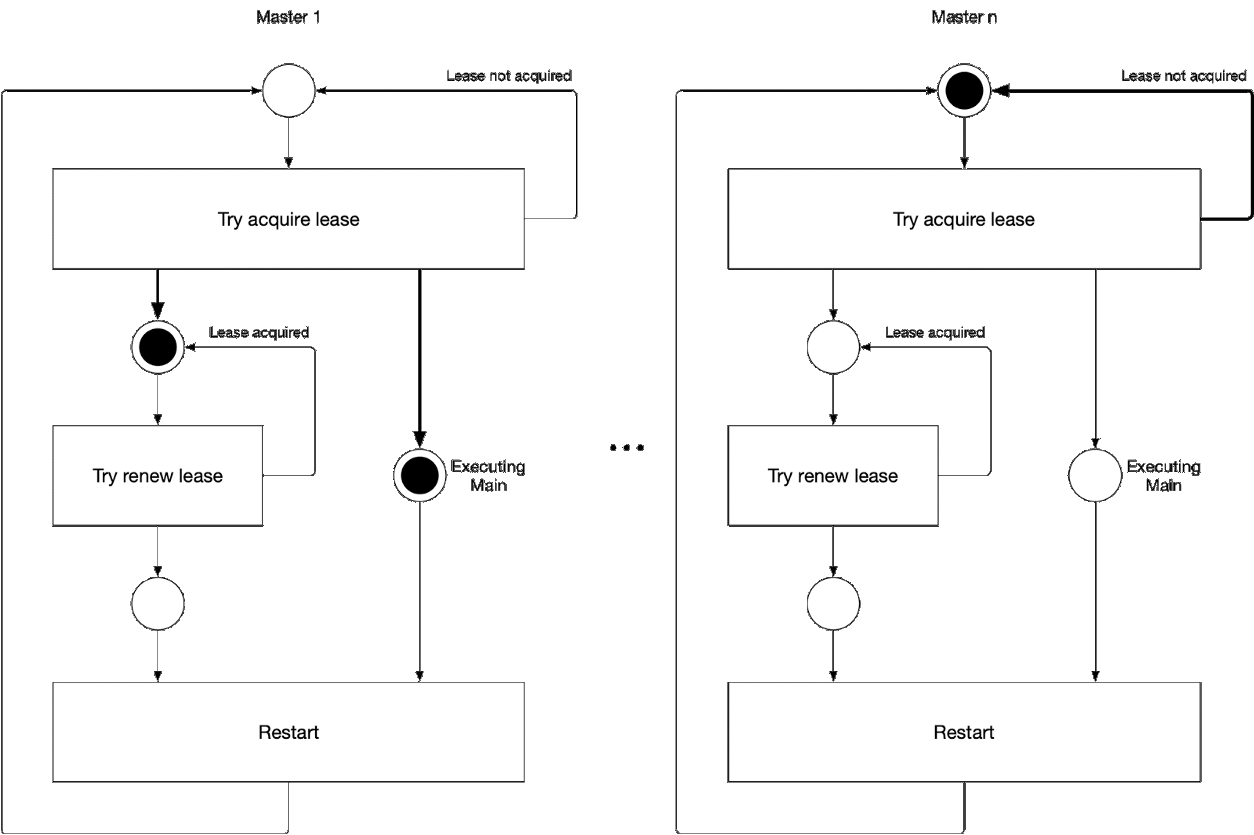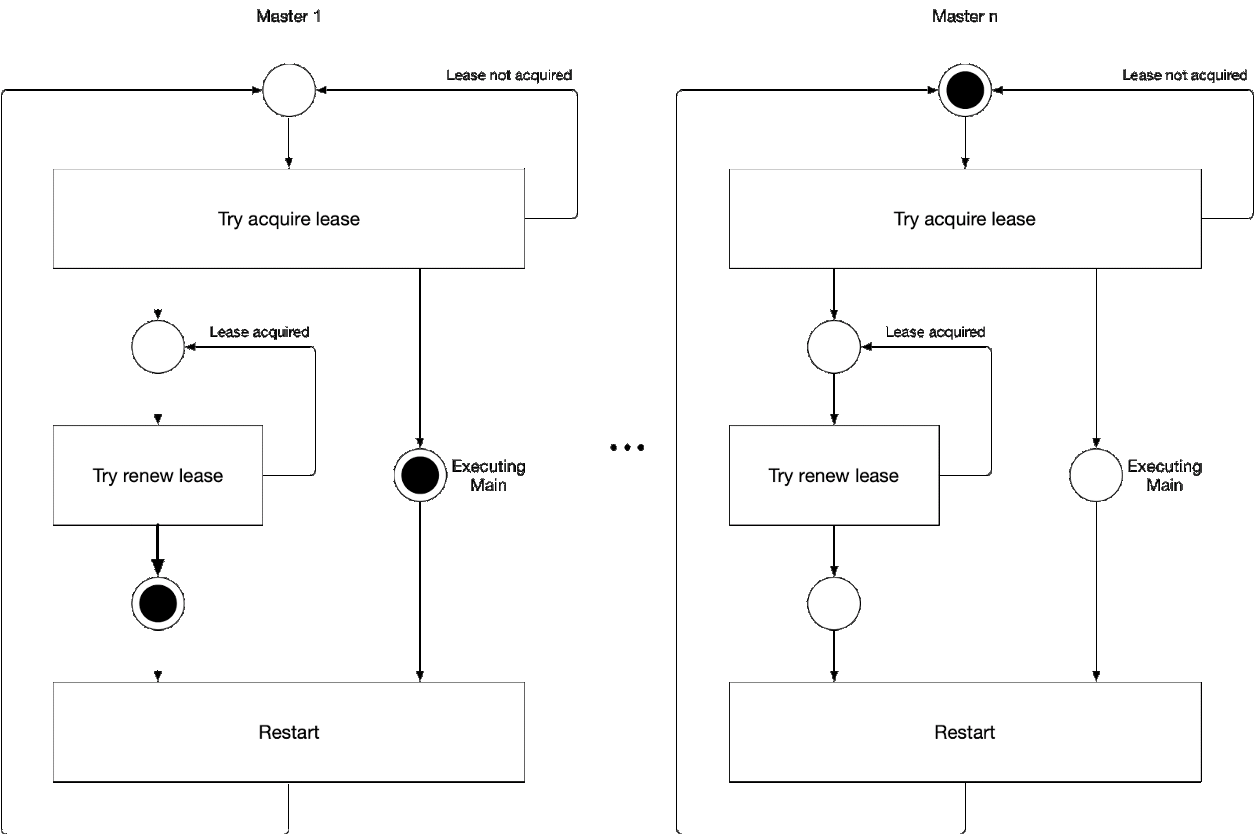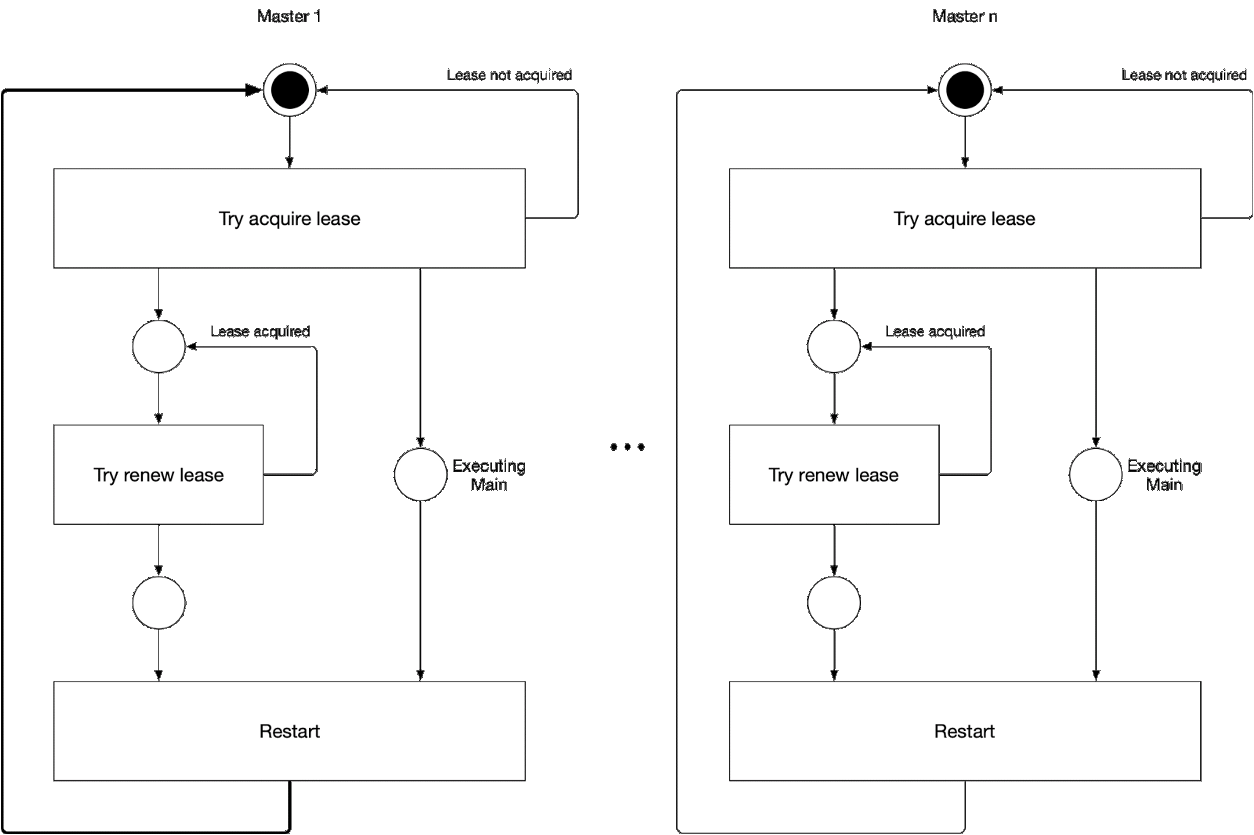 Diagrama 5. El proceso de selección del componente maestro del asistente
Diagrama 5. El proceso de selección del componente maestro del asistenteEsta ilustración muestra el proceso de selección maestra para kube-controller-manager y kube-Scheduler. La lógica de este proceso es la siguiente:
' ' , :
-
-
' ' , :
- leader lease
-
- holderIdentity 'self'Seguimiento líder
Los estados líderes actuales para kube-controller-manager y kube-Scheduler se almacenan permanentemente en el almacenamiento de objetos Kubernetes como
objetos de punto final en el espacio de nombres del
kube-system . Dado que dos objetos Kubernetes no pueden tener el mismo nombre, tipo
(tipo) y espacio de nombres al mismo tiempo, solo puede haber un
punto final para kube-Scheduler y para Kube-controller-manager.
Demostración con la utilidad de consola
kubectl :
$ kubectl get endpoints -n kube-system NAME ENDPOINTS AGE kube-scheduler <none> 30m kube-controller-manager <none> 30m
El programador de kube y el administrador de controlador de kube almacenan información del líder en la anotación
control-plane.alpha.kubernetes.io/leader :
$ kubectl describe endpoints kube-scheduler -n kube-system Name: kube-scheduler Annotations: control-plane.alpha.kubernetes.io/leader= { "holderIdentity": "scheduler-2", "leaseDurationSeconds": 15, "acquireTime": "2018-01-01T08:00:00Z" "renewTime": "2018-01-01T08:00:30Z" }
Aunque Kubernetes garantiza que habrá un maestro a la vez, Kubernetes no garantiza que dos o más componentes del asistente no
crean erróneamente que están liderando actualmente; este estado se conoce como
cerebro dividido .
Se puede encontrar una discusión instructiva sobre el tema del cerebro dividido y las posibles soluciones en el artículo
Cómo hacer bloqueo distribuido de Martin Kleppmann.
Kubernetes no utiliza contramedidas cerebrales divididas. En cambio, confía en su capacidad para luchar por el estado deseado a lo largo del tiempo, lo que mitiga las consecuencias de las decisiones de conflicto.
Conclusión
En una configuración multimaestro, Kubernetes es un motor de orquestación de contenedores escalable y confiable. En esta configuración, Kubernetes proporciona confiabilidad utilizando una variedad de asistentes y muchos trabajadores. Muchos maestros trabajan en el patrón maestro / esclavo, y los trabajadores trabajan en paralelo. Kubernetes tiene su propio proceso de selección de host, en el que la información del host se almacena como
objetos de punto final .
Para obtener información sobre cómo preparar un clúster de alta disponibilidad de Kubernetes para su funcionamiento, consulte la
documentación oficial .
Sobre la publicación
Esta publicación es parte de una iniciativa conjunta de CNCF, Google y SAP para mejorar la comprensión de Kubernetes y sus conceptos subyacentes.PD del traductor
Lea también en nuestro blog: