Hola Habr! Mi nombre es Nikolai Izhikov, trabajo para Sberbank Technologies en el equipo de desarrollo de soluciones de código abierto. Detrás de 15 años de desarrollo comercial en Java. Soy un confirmador de Apache Ignite y un colaborador de Apache Kafka.
Debajo del gato encontrará una versión en video y texto de mi informe sobre Apache Ignite Meetup sobre cómo usar Apache Ignite con Apache Spark y qué características hemos implementado para esto.
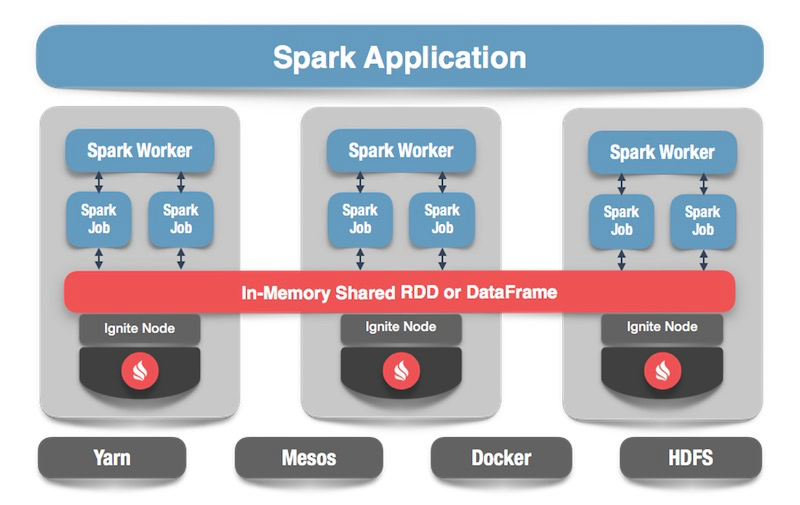
Lo que puede hacer Apache Spark
¿Qué es Apache Spark? Este es un producto que le permite realizar rápidamente consultas informáticas y analíticas distribuidas. Básicamente, Apache Spark está escrito en Scala.
Apache Spark tiene una API rica para conectarse a varios sistemas de almacenamiento o recibir datos. Una de las características del producto es un motor de consulta universal similar a SQL para los datos recibidos de varias fuentes. Si tiene varias fuentes de información, desea combinarlas y obtener algunos resultados, Apache Spark es lo que necesita.
Una de las abstracciones clave que proporciona Spark es Data Frame, DataSet. En términos de una base de datos relacional, esta es una tabla, una fuente que proporciona datos de forma estructurada. Se conoce la estructura, el tipo de cada columna, su nombre, etc. Los marcos de datos se pueden crear a partir de varias fuentes. Los ejemplos incluyen archivos json, bases de datos relacionales, varios sistemas hadoop y Apache Ignite.
Spark admite combinaciones en consultas SQL. Puede combinar datos de varias fuentes y obtener resultados, realizar consultas analíticas. Además, hay una API para guardar datos. Cuando haya completado las consultas, haya realizado un estudio, Spark brinda la capacidad de guardar los resultados en el receptor que admite esta función y, en consecuencia, resolver el problema del procesamiento de datos.
Qué características hemos implementado para integrar Apache Spark con Apache Ignite
- Lectura de datos de tablas Apache Ignite SQL.
- Escribir datos en tablas Apache Ignite SQL.
- IgniteCatalog dentro de IgniteSparkSession: la capacidad de usar todas las tablas existentes de Ignite SQL sin registrarse "a mano".
- Optimización de SQL: la capacidad de ejecutar instrucciones SQL dentro de Ignite.
Apache Spark puede leer datos de tablas Apache Ignite SQL y escribirlos en forma de dicha tabla. Cualquier DataFrame que se forme en Spark se puede guardar como una tabla Apache Ignite SQL.
Apache Ignite le permite utilizar todas las tablas existentes de Ignite SQL en Spark Session sin registrarse "a mano", utilizando IgniteCatalog dentro de la extensión estándar de SparkSession: IgniteSparkSession.
Aquí debes profundizar un poco más en el dispositivo Spark. En términos de una base de datos normal, un directorio es un lugar donde se almacena la metainformación: qué tablas están disponibles, qué columnas están en ellas, etc. Cuando llega una solicitud, la metainformación se extrae del catálogo y el motor SQL hace algo con tablas y datos. De forma predeterminada, en Spark, todas las tablas de lectura (no importa, desde una base de datos relacional, Ignite, Hadoop) deben registrarse manualmente en la sesión. Como resultado, tiene la oportunidad de realizar una consulta SQL en estas tablas. Spark se entera de ellos.
Para trabajar con los datos que cargamos en Ignite, necesitamos registrar las tablas. Pero en lugar de registrar cada tabla con nuestras manos, implementamos la capacidad de acceder automáticamente a todas las tablas de Ignite.
¿Cuál es la característica aquí? Por alguna razón no lo sé, el directorio en Spark es una API interna, es decir un extraño no puede venir y crear su propia implementación de catálogo. Y, dado que Spark salió de Hadoop, solo es compatible con Hive. Y debes registrar todo lo demás con tus manos. Los usuarios a menudo preguntan cómo puede evitar esto e inmediatamente realizan consultas SQL. Implementé un directorio que le permite navegar y acceder a las tablas de Ignite sin registrar ~ y sms ~, e inicialmente propuse este parche en la comunidad de Spark, a lo que recibí una respuesta: dicho parche no es interesante por algunas razones internas. Y no dieron la API interna.
Ahora el catálogo Ignite es una característica interesante implementada usando la API interna de Spark. Para usar este directorio, tenemos nuestra propia implementación de la sesión. Esta es la SparkSession habitual, dentro de la cual puede realizar solicitudes, procesar datos. Las diferencias son que integramos ExternalCatalog en él para trabajar con tablas Ignite, así como IgniteOptimization, que se describirá a continuación.
Optimización de SQL : la capacidad de ejecutar instrucciones SQL dentro de Ignite. De forma predeterminada, al realizar uniones, agrupaciones, cálculos agregados y otras consultas SQL complejas, Spark lee los datos en modo fila por fila. Lo único que puede hacer la fuente de datos es filtrar las filas de manera eficiente.
Si usa unir o agrupar, Spark extrae todos los datos de la tabla a su memoria para el trabajador, utilizando los filtros especificados, y solo luego los agrupa o realiza otras operaciones SQL. En el caso de Ignite, esto no es óptimo, porque Ignite tiene una arquitectura distribuida y tiene conocimiento de los datos almacenados en ella. Por lo tanto, Ignite puede calcular de manera eficiente los agregados y llevar a cabo la agrupación. Además, puede haber una gran cantidad de datos, y para agruparlos, deberá restar todo, aumentar todos los datos en Spark, que es bastante costoso.
Spark proporciona una API con la que puede cambiar el plan inicial de la consulta SQL, realizar la optimización y reenviar la parte de la consulta SQL que se puede ejecutar allí en Ignite. Esto será efectivo en términos de velocidad y consumo de memoria, ya que no lo usaremos para extraer datos que se agruparán inmediatamente.
Como funciona
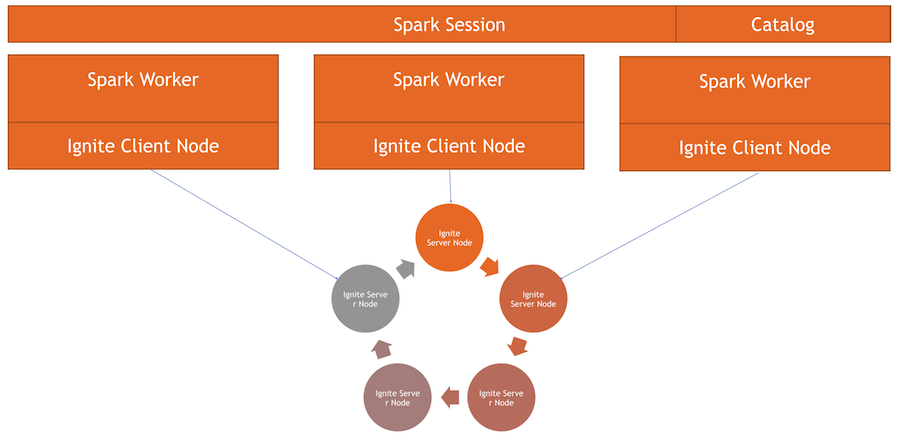
Tenemos un grupo Ignite: esta es la mitad inferior de la imagen. No hay Zookeeper, ya que solo hay cinco nodos. Hay trabajadores de chispa, dentro de cada trabajador se levanta el nodo del cliente Ignite. A través de él, podemos hacer una solicitud y leer los datos, interactuar con el clúster. Además, el nodo del cliente se eleva dentro de IgniteSparkSession para que el directorio funcione.
Encender marco de datos
Pasamos al código: ¿cómo leer datos de una tabla SQL? En el caso de Spark, todo es bastante simple y bueno: decimos que queremos calcular algunos datos, indicar el formato; esta es una constante constante. Además, tenemos varias opciones: la ruta al archivo de configuración para el nodo del cliente, que comienza al leer los datos. Indicamos qué tabla queremos leer y le decimos a Spark que cargue. Obtenemos los datos y podemos hacer lo que queramos con ellos.
spark.read .format(FORMAT_IGNITE) .option(OPTION_CONFIG_FILE, TEST_CONFIG_FILE) .option(OPTION_TABLE, "person") .load()
Después de haber generado los datos, opcionalmente de Ignite, de cualquier fuente, podemos guardarlo fácilmente especificando el formato y la tabla correspondiente. Le ordenamos a Spark que escriba, especificamos un formato. En la configuración, prescribimos a qué clúster conectarse. Especifique la tabla en la que queremos guardar. Además, podemos prescribir opciones de utilidad: especifique la clave principal que creamos en esta tabla. Si los datos simplemente se alteran sin crear una tabla, entonces este parámetro no es necesario. Al final, haga clic en guardar y se escribirán los datos.
tbl.write. format(FORMAT_IGNITE). option(OPTION_CONFIG_FILE, CFG_PATH). option(OPTION_TABLE, tableName). option(OPTION_CREATE_TABLE_PRIMARY_KEY_FIELDS, pk). save
Ahora veamos cómo funciona todo.
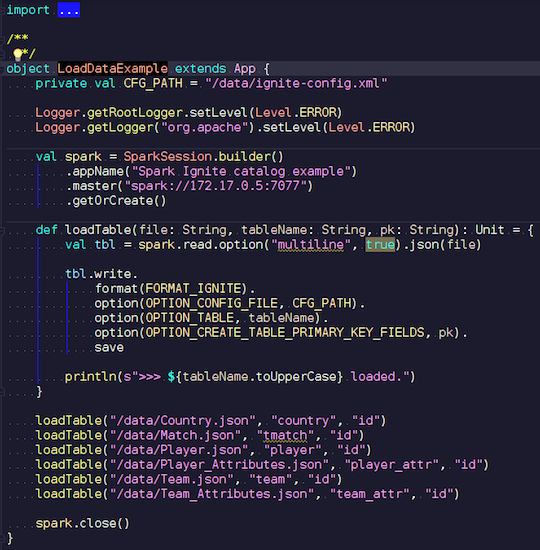 LoadDataExample.scala
LoadDataExample.scalaEsta aplicación obvia primero demostrará las capacidades de grabación. Por ejemplo, elegí los datos de los partidos de fútbol, descargué estadísticas de un recurso conocido. Contiene información sobre torneos: ligas, partidos, jugadores, equipos, atributos de jugador, atributos de equipo: datos que describen partidos de fútbol en ligas de países europeos (Inglaterra, Francia, España, etc.).
Quiero subirlos a Ignite. Creamos una sesión de Spark, especificamos la dirección del asistente y llamamos a la carga de estas tablas, pasando parámetros. El ejemplo está en Scala, no en Java, porque Scala es menos detallado y, por ejemplo, mucho mejor.
Transferimos el nombre del archivo, lo leemos, indicamos que es multilínea, este es un archivo json estándar. Luego escribimos en Ignite. La estructura de nuestro archivo no se describe en ninguna parte: Spark mismo determina qué datos tenemos y cuál es su estructura. Si todo transcurre sin problemas, se crea una tabla en la que hay todos los campos necesarios de los tipos de datos requeridos. Así es como podemos cargar todo dentro de Ignite.
Cuando se cargan los datos, podemos verlos en Ignite y usarlos de inmediato. Como ejemplo simple, una consulta que le permite saber qué equipo jugó más partidos. Tenemos dos columnas: hometeam y awayteam, anfitriones e invitados. Seleccionamos, agrupamos, contamos, sumamos y unimos datos con el comando para ingresar el nombre del comando. Ta-dam - y los datos de json-chiks que obtuvimos en Ignite. Vemos Paris Saint-Germain, Toulouse: tenemos muchos datos sobre los equipos franceses.
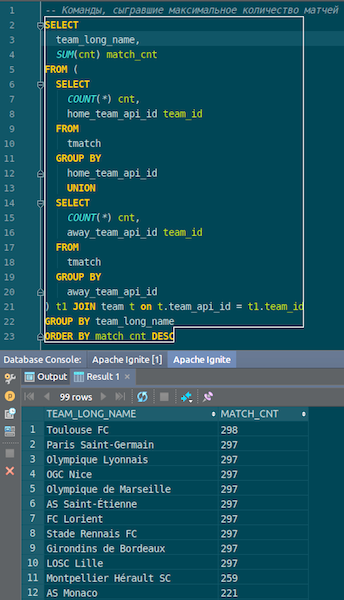
Resumimos Ahora hemos subido datos desde la fuente, el archivo json, a Ignite, y con bastante rapidez. Quizás, desde el punto de vista de big data, esto no es demasiado grande, pero es decente para una computadora local. El esquema de la tabla se toma del archivo json en su forma original. Se creó la tabla, se copiaron los nombres de las columnas del archivo fuente, se creó la clave primaria. La identificación está en todas partes, y la clave principal es la identificación. Estos datos llegaron a Ignite, podemos usarlos.
IgniteSparkSession y IgniteCatalog
Veamos como funciona.
 CatalogExample.scala
CatalogExample.scalaDe una manera bastante simple, puede acceder y consultar todos sus datos. En el último ejemplo, comenzamos la sesión estándar de chispa. Y no había especificidad Ignite allí, excepto que tiene que poner un jar con la fuente de datos correcta, trabajo completamente estándar a través de la API pública. Pero, si desea acceder a las tablas de Ignite automáticamente, puede usar nuestra extensión. La diferencia es que, en lugar de SparkSession, escribimos IgniteSparkSession.
Tan pronto como cree un objeto IgniteSparkSession, verá en el directorio todas las tablas que se acaban de cargar en Ignite. Puedes ver su diagrama y toda la información. Spark ya conoce las tablas que tiene Ignite y puede obtener fácilmente todos los datos.
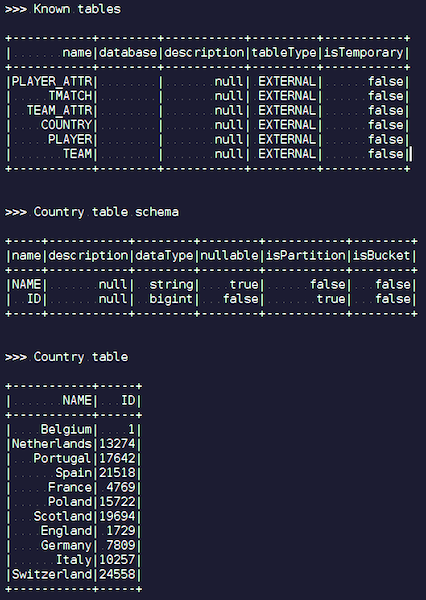
Optimización del encendido
Cuando realiza consultas complejas en Ignite usando JOIN, Spark extrae los datos primero, y solo luego JOIN los agrupa. Para optimizar el proceso, creamos la función IgniteOptimization: optimiza el plan de consulta de Spark y le permite reenviar las partes de la solicitud que se pueden ejecutar dentro de Ignite dentro de Ignite. Mostramos optimización en una solicitud específica.
SQL Query: SELECT city_id, count(*) FROM person p GROUP BY city_id HAVING count(*) > 1
Cumplimos la solicitud. Tenemos una tabla de personas: algunos empleados, personas. Cada empleado conoce la identificación de la ciudad en la que vive. Queremos saber cuántas personas viven en cada ciudad. Filtramos: en qué ciudad vive más de una persona. Aquí está el plan inicial que construye Spark:
== Analyzed Logical Plan == city_id: bigint, count(1): bigint Project [city_id#19L, count(1)#52L] +- Filter (count(1)#54L > cast(1 as bigint)) +- Aggregate [city_id#19L], [city_id#19L, count(1) AS count(1)#52L, count(1) AS count(1)#54L] +- SubqueryAlias p +- SubqueryAlias person +- Relation[NAME#11,BIRTH_DATE#12,IS_RESIDENT#13,SALARY#14,PENSION#15,ACCOUNT#16,AGE#17,ID#18L,CITY_ID#19L] IgniteSQLRelation[table=PERSON]
La relación es solo una tabla Ignite. No hay filtros: simplemente extraemos todos los datos de la tabla Persona a través de la red desde el clúster. Luego, Spark agrega todo esto, de acuerdo con la solicitud y devuelve el resultado de la solicitud.
Es fácil ver que todo este subárbol con filtro y agregación se puede ejecutar dentro de Ignite. Esto será mucho más eficiente que extraer todos los datos de una tabla potencialmente grande en Spark; esto es lo que hace nuestra función IgniteOptimization. Después de analizar y optimizar el árbol, obtenemos el siguiente plan:
== Optimized Logical Plan == Relation[CITY_ID#19L,COUNT(1)#52L] IgniteSQLAccumulatorRelation( columns=[CITY_ID, COUNT(1)], qry=SELECT CITY_ID, COUNT(1) FROM PERSON GROUP BY city_id HAVING count(1) > 1)
Como resultado, obtenemos solo una relación, ya que optimizamos todo el árbol. Y dentro de usted ya puede ver que Ignite enviará una solicitud lo suficientemente cercana a la solicitud original.
Supongamos que estamos uniendo diferentes fuentes de datos: por ejemplo, tenemos un DataFrame de Ignite, el segundo de json, el tercero nuevamente de Ignite y el cuarto de algún tipo de base de datos relacional. En este caso, solo el subárbol se optimizará en el plan. Optimizamos lo que podemos, lo dejamos en Ignite y Spark hará el resto. Debido a esto, obtenemos una ganancia de velocidad.
Otro ejemplo con JOIN:
SQL Query - SELECT jt1.id as id1, jt1.val1, jt2.id as id2, jt2.val2 FROM jt1 JOIN jt2 ON jt1.val1 = jt2.val2
Tenemos dos mesas. Nos mantenemos unidos por valor y seleccionamos de todos ellos: ID, valores. Spark ofrece tal plan:
== Analyzed Logical Plan == id1: bigint, val1: string, id2: bigint, val2: string Project [id#4L AS id1#84L, val1#3, id#6L AS id2#85L, val2#5] +- Join Inner, (val1#3 = val2#5) :- SubqueryAlias jt1 : +- Relation[VAL1#3,ID#4L] IgniteSQLRelation[table=JT1] +- SubqueryAlias jt2 +- Relation[VAL2#5,ID#6L] IgniteSQLRelation[table=JT2]
Vemos que extraerá todos los datos de una tabla, todos los datos de la segunda, los unirá dentro de sí mismo y dará los resultados. Después del procesamiento y la optimización, obtenemos exactamente la misma solicitud que se envía a Ignite, donde se ejecuta con relativa rapidez.
== Optimized Logical Plan == Relation[ID#84L,VAL1#3,ID#85L,VAL2#5] IgniteSQLAccumulatorRelation(columns=[ID, VAL1, ID, VAL2], qry= SELECT JT1.ID AS id1, JT1.VAL1, JT2.ID AS id2, JT2.VAL2 FROM JT1 JOIN JT2 ON JT1.val1 = JT2.val2 WHERE JT1.val1 IS NOT NULL AND JT2.val2 IS NOT NULL)
Te mostraré un ejemplo.
 OptimizationExample.scala
OptimizationExample.scalaEstamos creando una sesión IgniteSpark en la que todas nuestras capacidades de optimización ya están incluidas automáticamente. Aquí la solicitud es esta: encuentra a los jugadores con la calificación más alta y muestra sus nombres. En la tabla de jugadores, sus atributos y datos. Nos estamos uniendo, filtrando datos basura y mostrando jugadores con la calificación más alta. Veamos qué tipo de plan tenemos después de la optimización y muestre los resultados de esta consulta.
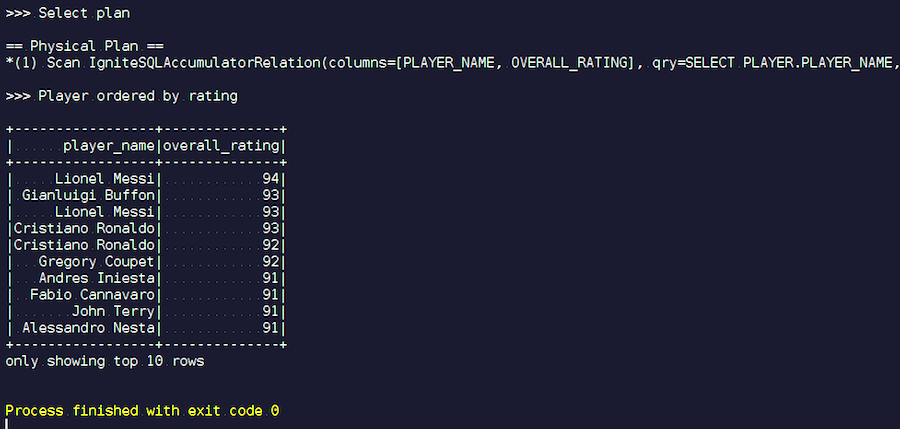
Empezamos Vemos apellidos familiares: Messi, Buffon, Ronaldo, etc. Por cierto, algunos por alguna razón se encuentran en dos formas: tanto Messi como Ronaldo. Los amantes del fútbol pueden encontrar extraño que jugadores desconocidos aparezcan en la lista. Estos son porteros, jugadores con características bastante altas, en el contexto de otros jugadores. Ahora miramos el plan de consulta que se ejecutó. En Spark, casi no se hizo nada, es decir, enviamos toda la solicitud nuevamente a Ignite.
Desarrollo Apache Ignite
Nuestro proyecto es un producto de código abierto, por lo que siempre estamos contentos con los parches y los comentarios de los desarrolladores. Su ayuda, comentarios, parches son muy bienvenidos. Los estamos esperando. El 90% de la comunidad Ignite habla ruso. Por ejemplo, para mí, hasta que comencé a trabajar en Apache Ignite, no el mejor conocimiento del inglés era un elemento disuasorio. No vale la pena escribir en ruso en una lista de desarrolladores, pero incluso si escribes algo mal, te responderán y te ayudarán.
¿Qué se puede mejorar en esta integración? ¿Cómo puedo ayudar si tienes ese deseo? Lista abajo. Los asteriscos indican complejidad.

Para probar la optimización, debe escribir pruebas con consultas complejas. Arriba, mostré algunas consultas obvias. Está claro que si escribes muchas agrupaciones y muchas uniones, entonces algo puede caer. Esta es una tarea muy simple: ven y hazlo. Si encontramos algún error basado en los resultados de la prueba, será necesario corregirlo. Será más difícil allí.
Otra tarea clara e interesante es la integración de Spark con un cliente ligero. Inicialmente puede especificar algunos conjuntos de direcciones IP, y esto es suficiente para unirse al clúster Ignite, lo cual es conveniente en caso de integración con un sistema externo. Si de repente quiere unirse a la solución a este problema, personalmente lo ayudaré.
Si desea unirse a la comunidad Apache Ignite, aquí hay algunos enlaces útiles:
Tenemos una lista de desarrolladores receptiva, que lo ayudará. Todavía está lejos de ser ideal, pero en comparación con otros proyectos, está realmente vivo.
Si conoce Java o C ++, está buscando trabajo y desea desarrollar código abierto (Apache Ignite, Apache Kafka, Tarantool, etc.) escriba aquí: join-open-source@sberbank.ru.