Una vez ya escribí aquí sobre mudarme de Asia a Europa , y ahora quiero escribir lo que estoy haciendo en esta Europa. Existe tal profesión: DevOps , o más bien no, pero resultó que esto es exactamente lo que estoy haciendo ahora. Ahora para la orquestación de todo lo que se ejecuta en la ventana acoplable, utilizamos un ranchero , sobre el que también escribí . Pero luego sucedió algo terrible, Rancher 2.0 salió y se mudó a kubernetes (en adelante, simplemente k8s) y dado que k8s ahora es realmente el estándar para administrar el clúster, hubo un deseo de volver a construir toda la infraestructura con blackjack y bibliotecarios. Lo que agrega picante a esto es que la compañía constantemente contrata a diferentes especialistas de diferentes países y con diferentes tradiciones, y alguien trae puppet , alguien es ansible que ansible , y alguien generalmente cree que Makefile + bash es nuestro todo. Por lo tanto, simplemente no hay una opinión inequívoca de cómo debería funcionar todo, pero realmente quiero hacerlo.
Dicho zoológico de tecnologías y herramientas fue ensamblado previamente:

Gestión de infraestructuras
- Minikube
- Rke
- Terraforma
- Kops
- Kubespray
- Ansible
Gestión de aplicaciones
- Kubernetes
- Ranchero
- Kubectl
- Timón
- Confd
- Kompose
- Jenkins
Registro y Monitoreo
- Búsqueda elástica
- Kibana
- Poco fluido
- Telegraf
- Influxdb
- Zabbix
- Prometeo
- Grafana
- Kapacitor
A continuación, intentaré describir brevemente cada punto de este zoológico, describir por qué es necesario y por qué se eligió esta solución. De hecho, casi cualquier artículo puede ser reemplazado por una docena de análogos y aún no estamos completamente seguros de la elección, por lo que si alguien tiene una opinión o recomendaciones, lo leeré en los comentarios con gusto.
Kubernetes será el centro de todo porque ahora realmente es una solución que simplemente no tiene alternativas, que es compatible con todos los proveedores de Amazon y Microsoft para mail.ru. Cómo se consideraron las alternativas
Swarm - que nunca despegóNomad , que parece estar escrita por extraños para depredadoresCattle es el motor del guardabosques 1.x, en el que ahora vivimos, en principio, todo está bien, pero el ranchero ya lo ha abandonado a favor de los k8, por lo que no habrá desarrollo.
Construcción de infraestructura
Primero, necesitamos crear la infraestructura e implementar un clúster k8s en ella. Hay varias opciones, todas funcionan y, por lo tanto, es difícil elegir la mejor.
Minikube es una gran opción para iniciar un clúster en la máquina de un desarrollador, con fines de prueba.
Rke - Motor rancher kubernetes, tan simple como una puerta; configuración mínima para crear un aspecto de clúster
nodes: - address: localhost role: [controlplane,worker,etcd]
Y eso es todo, esto es suficiente para iniciar el clúster en la máquina local, mientras le permite crear clústeres HA listos para producción, cambiar la configuración, actualizar el clúster, volcar la base de datos etcd y mucho más.
Kops : no solo le permite crear un clúster, sino también crear previamente instancias en aws o gce. También le permite generar una configuración para terraform. Una herramienta interesante, pero aún no hemos echado raíces. Se reemplaza completamente por terraform + rke mientras es más simple y más flexible.
Kubespray : de hecho, es solo un rol ansible que crea un clúster k8s, malditamente poderoso, flexible y configurable. Esta es prácticamente la solución predeterminada para implementar k8s.
Terraform es una herramienta para construir infraestructura en aws, azul o en muchos otros lugares. Flexible, estable, lo recomiendo.
Ansible no se trata realmente de k8s, pero lo usamos en todas partes y también aquí: ajustar configuraciones, instalar / actualizar software, distribuir certificados. Barato y alegre.
Gestión de aplicaciones
Entonces, tenemos un clúster, ahora necesitamos comenzar algo útil, todo lo que queda es la cuestión de cómo hacer esto.
Opción uno: use k8s desnudos, todo se despliega usando kubectl . En principio, esta opción tiene derecho a la vida. Kubectl es una herramienta lo suficientemente potente que nos permite hacer todo lo que necesitamos, incluida la implementación, actualización, monitoreo del estado actual, cambio de la configuración sobre la marcha, visualización de registros y conexión a contenedores específicos. Pero a veces quiero que todo sea un poco más conveniente, así que seguimos adelante.
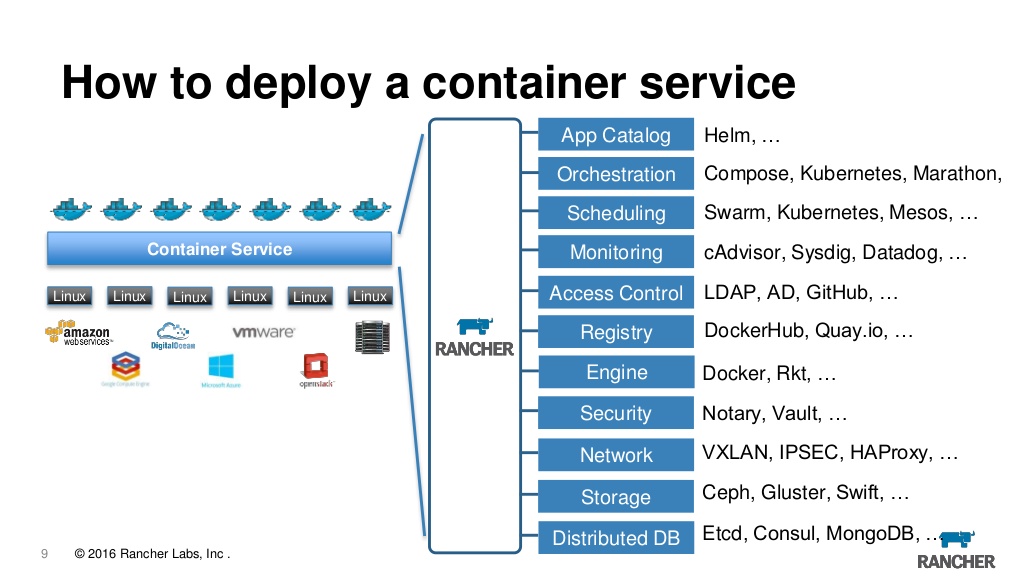
De hecho, ahora el ranchero es un bozal web para administrar k8 y, al mismo tiempo, muchos bollos pequeños que agregan comodidad. Aquí puede ver registros, acceder a la consola y configurar y actualizar aplicaciones y control de acceso basado en roles y un servidor de metadatos incorporado, alarmas, redirección de registros, gestión de secretos y mucho más. Hemos estado usando el primer ranchero de versiones durante varios años y estamos completamente satisfechos con él, aunque debemos admitir que al cambiar a k8s surge la pregunta de si realmente lo necesitamos. Es bueno que pueda importar cualquier clúster creado previamente en el ranchero, y desde cualquier proveedor, es decir, puede importar un clúster desde EKS desde azul y creado localmente y conducirlos de un lugar a un servidor. Además, si de repente se aburre, simplemente puede demoler el servidor y continuar usando el clúster directamente a través de kubeclt o cualquier otra herramienta.
El concepto muy correcto de todo como código ahora es popular. Por ejemplo, la infraestructura como código se implementa usando terraform , el ensamblaje como código se implementa a través de la jenkins pipeline . Ahora ha llegado el turno a la aplicación. La instalación y configuración de la aplicación también debe describirse en algún manifiesto y guardarse en el git. Las versiones de Rancher 1.x utilizaron el estándar docker-compose.yml y todo estuvo bien, pero cuando se trasladaron a k8s cambiaron a helm charts . Helm es, desde mi punto de vista, un intercambio absolutamente terrible con lógica y arquitectura extrañas. Este es uno de esos proyectos a partir del cual persiste la sensación de que fue escrito por depredadores para extraños o viceversa. El único problema es que en el mundo de k8s helm simplemente no hay alternativas y este es de hecho el estándar. Por lo tanto, seremos pinchados para llorar, pero seguiremos usando el timón. En la versión 3.x, los desarrolladores prometen reescribirlo desde cero, eliminando todas las rarezas y simplificando la arquitectura. Es entonces cuando sanaremos, pero por ahora comeremos lo que es.
También necesitamos al menos mencionar a jenkins aquí, no se relaciona directamente con el tema de kubernetis, pero es con su ayuda que las aplicaciones se implementan en el clúster. Él es, él trabaja y él es un tema para un artículo separado.
Monitoreo
Ahora tenemos un clúster e incluso está girando algún tipo de aplicación, parece que puedes exhalar, pero de hecho, todo está comenzando. ¿Qué tan estable es nuestra aplicación? Que rapido ¿Tiene suficientes recursos? ¿Qué está pasando generalmente en el clúster?
Sí, el siguiente tema es el monitoreo y el registro. Solo hay tres respuestas definitivas. Almacene los registros en kibana través de kibana Dibuje gráficos en grafana Para todas las demás preguntas, hay una docena de respuestas correctas.
Aquí comenzamos con la grafana por sí sola, prácticamente no hace nada, pero puede sujetarse como una cara bonita a cualquiera de los sistemas que se describen a continuación y obtener gráficos hermosos y a veces claros, además, puede configurar alarmas de inmediato, pero es mejor usar otras soluciones para esto, por ejemplo prometheus alertmanager y ElastAlert .
Desde mi punto de vista, en este momento este es el mejor agregador y enrutador de registros, además, desde el primer momento, tiene soporte para k8. También hay Fluentd pero está escrito en rublos y extrae demasiado código heredado, lo que lo hace mucho menos atractivo. Entonces, si necesita algún módulo específico de fluentd que aún no se haya portado a bit fluido, utilícelo, en todo lo demás, el bit es la mejor opción. Es más rápido, más estable, consume menos memoria. Le permite recopilar registros de todos o de contenedores seleccionados, filtrarlos, enriquecerlos agregando datos específicos de kubernetis y enviarlos a Elasticsearch oa muchos otros repositorios. Si lo compara con logstash + docker-bit + file-bit tradicional logstash + docker-bit + file-bit esta solución es definitivamente mejor en todos los aspectos. Históricamente, todavía usamos logspout + logstash pero definitivamente logspout + logstash bit con fluidez.
Un sistema de monitoreo escrito específicamente para la arquitectura de microservicios. El estándar de facto en la industria, además, también existe un proyecto llamado Prometheus Operator , escrito específicamente para k8. Todos deciden qué elegir, pero es mejor comenzar con prometeo simple, solo para comprender la lógica de su trabajo, es bastante diferente de los sistemas habituales. También debemos mencionar node-exporter que le permite recopilar métricas a nivel de máquina y prometheus-rancher-exporter, que le permite recopilar métricas a través de la API de rancher. En general, si tiene un grupo de kubernetes, prometeo es imprescindible.
Uno podría detenerse aquí, pero históricamente, tenemos varios sistemas de monitoreo más. En primer lugar, zabbix muy conveniente para zabbix ver todos los problemas de toda la infraestructura en un panel. La presencia del descubrimiento automático le permite encontrar y agregar rápidamente nuevas redes, nodos, servicios y, en general, casi cualquier cosa a la supervisión, lo que lo convierte en una herramienta más que conveniente para supervisar infraestructuras dinámicas. Además, en la versión 4.0, se agregó una colección de métricas de los exportadores de prometheus a zabbix y resulta que todo esto se puede integrar muy bien en un solo sistema. Aunque todavía no hay una respuesta definitiva sobre si es necesario arrastrar zabbix a un clúster k8s, definitivamente es interesante intentarlo.
Como alternativa, puede usar TIG (telegraf + influxdb + grafana) configurado de manera simple, funciona de manera estable, le permite agregar métricas por contenedores, aplicaciones, nodos, etc., pero esencialmente duplica la funcionalidad de prometheus, y solo debería quedar uno.
Y resulta que antes de comenzar algo útil, necesita instalar y configurar el enlace desde un par de docenas de servicios y herramientas auxiliares. Al mismo tiempo, el artículo no planteó problemas de gestión de datos persistentes, secretos y otras cosas extrañas, cada uno de los cuales se puede llevar a una publicación separada.
¿Y cómo ves la infraestructura ideal?
Si tiene una opinión, por favor escriba los comentarios, o tal vez incluso únase a nuestro equipo y ayude a armar todo.