Una vez, en una entrevista, un conocido músico ruso dijo: "Estamos trabajando en mentir y escupir en el techo". No puedo dejar de estar de acuerdo con esta declaración, porque no se puede discutir el hecho de que la pereza es la fuerza impulsora en el desarrollo de la tecnología. De hecho, solo en el siglo pasado hemos pasado de las máquinas de vapor a la industrialización digital, y ahora la inteligencia artificial, que fue descrita por escritores de ciencia ficción y futurólogos del siglo pasado, se está convirtiendo en una realidad cada vez mayor de nuestro mundo cada día. Juegos de computadora, dispositivos móviles, relojes inteligentes y mucho más. básicamente utiliza algoritmos asociados con mecanismos de aprendizaje automático.
Hoy en día, debido al crecimiento de las capacidades informáticas de los procesadores gráficos y la gran cantidad de datos que han aparecido, las redes neuronales han ganado popularidad, utilizando las cuales resuelven problemas de clasificación y regresión, capacitándolos en datos preparados. Ya se han escrito muchos artículos sobre cómo entrenar redes neuronales y qué marcos utilizar para esto. Pero hay una tarea anterior que también debe resolverse, y esta es la tarea de formar una matriz de datos, un conjunto de datos, para entrenar aún más la red neuronal. Esto se discutirá en este artículo.
No hace mucho tiempo, era necesario construir un clasificador acústico del ruido del automóvil capaz de extraer datos de un flujo de audio común: vidrios rotos, abrir puertas y operar el motor de un automóvil en varios modos. El desarrollo del clasificador no fue difícil, pero ¿dónde obtener el conjunto de datos para que cumpla con todos los requisitos?
Google acudió al rescate (sin ofender a Yandex; hablaré de sus ventajas un poco más tarde), con la ayuda de la cual fue posible seleccionar varios grupos principales que contienen los datos necesarios. Quiero señalar de antemano que las fuentes indicadas en este artículo incluyen una gran cantidad de información acústica, con varias clases, lo que le permite crear un conjunto de datos para diferentes tareas. Ahora pasamos a una descripción general de estas fuentes.
Freesound.org
Lo más probable es que
Freesound.org proporcione el mayor volumen de datos acústicos, siendo un repositorio conjunto de muestras de música con licencia, que actualmente tiene más de 230,000 copias de efectos de sonido. Cada muestra de sonido se puede distribuir bajo una licencia diferente, por lo tanto, es mejor familiarizarse con el
acuerdo de licencia por adelantado. Por ejemplo, la licencia
cero (cc0) tiene el estado "Sin derechos de autor" y le permite copiar, modificar y distribuir, incluido el uso comercial, y le permite utilizar los datos de manera absolutamente legal.
Para la conveniencia de encontrar elementos de información acústica en una variedad de freesound.org, los desarrolladores han proporcionado una
API diseñada para analizar, buscar y descargar datos de los repositorios. Para trabajar con él, debe obtener acceso, para esto debe ir al
formulario y completar todos los campos necesarios, después de lo cual se generará la clave individual.

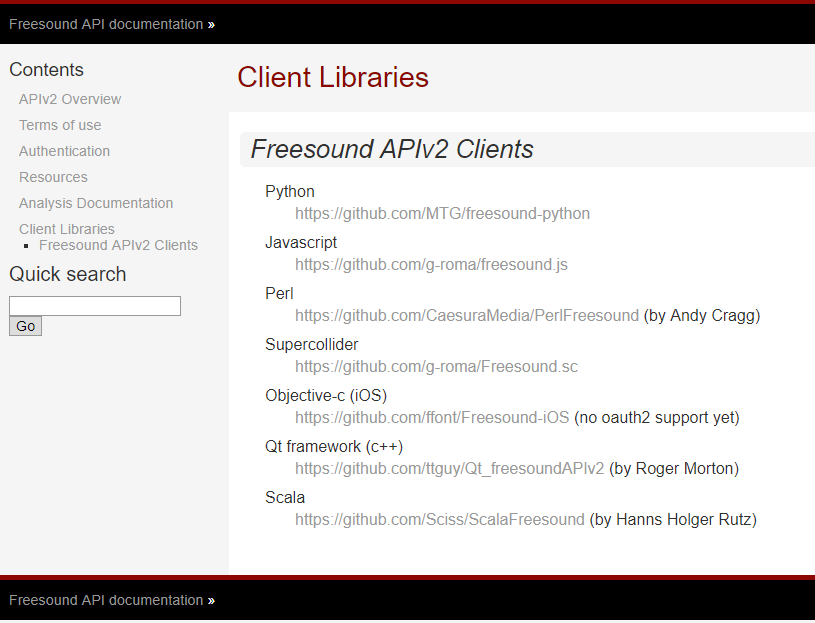
Los desarrolladores de Freesound.org proporcionan
API para varios lenguajes de programación, lo que permite resolver el mismo problema con diferentes herramientas. La lista de idiomas compatibles y enlaces para acceder a ellos en GitHub se enumeran a continuación.
Para lograr el objetivo, se utilizó python, ya que este hermoso lenguaje de programación de tipeo dinámico ganó popularidad debido a su facilidad de uso, borrando por completo el mito de la complejidad del desarrollo de software.
El módulo para trabajar con freesound.org para python se puede clonar desde el repositorio github.com.
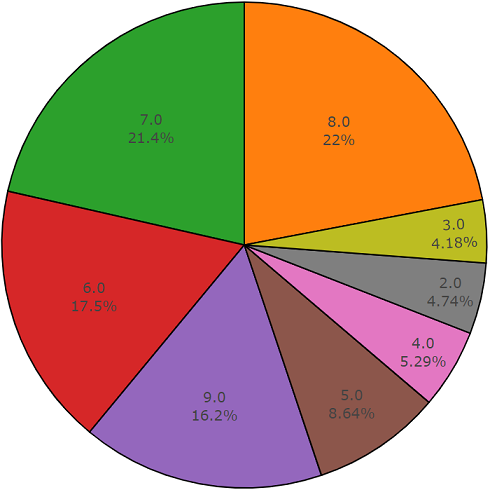
A continuación se muestra el código de dos partes que demuestra la facilidad de uso de esta API. La primera parte del código del programa realiza la tarea de análisis de datos, cuyo resultado es la densidad de distribución de datos para cada clase solicitada, y la segunda parte carga datos de los repositorios de freesound.org para las clases seleccionadas. La densidad de distribución cuando se busca información acústica con las palabras clave
vidrio, motor, puerta se presenta a continuación en un gráfico circular como ejemplo.
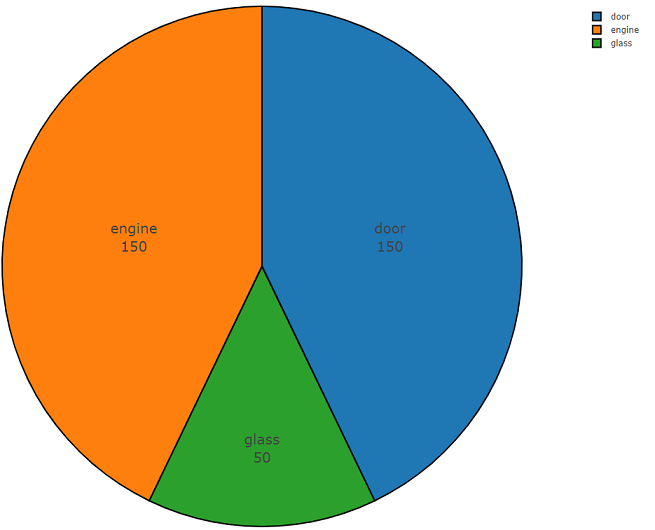
Código de muestra de análisis de datos de Freesound.org
import plotly import plotly.graph_objs as go import freesound import os import termcolor
Código de muestra para descargar datos de freesound.org
Una característica de freesound es que el análisis de datos de audio puede llevarse a cabo sin descargar un archivo de audio, lo que le permite obtener MFCC, energía espectral, centroide espectral y otros coeficientes. Lea más sobre información de bajo nivel en la
documentación de freesound.ord .
Usando la API freesound.org, se minimiza el tiempo dedicado a buscar y descargar datos, lo que le permite ahorrar horas de trabajo estudiando otras fuentes de información, ya que los clasificadores acústicos de alta precisión requieren un gran conjunto de datos con gran variabilidad, que representa datos con diferentes armónicos en uno y la misma clase de eventos
YouTube-8M y AudioSet
Creo que youtube no es particularmente necesario en la presentación, pero sin embargo, wikipedia nos dice que youtube es un sitio de alojamiento de video que brinda a los usuarios servicios de visualización de video, olvidando decir que youtube es una gran base de datos, y esta fuente debe usarse en el aprendizaje automático , y Google Inc nos proporciona un proyecto llamado
Conjunto de datos YouTube-8M .
YouTube-8M Dataset es un conjunto de datos que incluye más de un millón de archivos de video de YouTube en alta calidad, para brindar información más precisa, a partir de mayo de 2018, había 6.1 millones de videos con 3862 clases. Este conjunto de datos está licenciado bajo
Creative Commons Attribution 4.0 International (CC BY 4.0) . Dicha licencia le permite copiar y distribuir material en cualquier medio y formato.
Probablemente se pregunte: ¿de dónde provienen los datos de video cuando se necesita información acústica para la tarea? El hecho es que Google proporciona no solo contenido de video, sino que también asigna por separado un subproyecto con datos de audio llamado
AudioSet .
 AudioSet
AudioSet : proporciona un conjunto de datos obtenido de videos de YouTube, donde se presentan muchos datos en una jerarquía de clases utilizando
un archivo de ontología , su representación gráfica se encuentra a continuación.
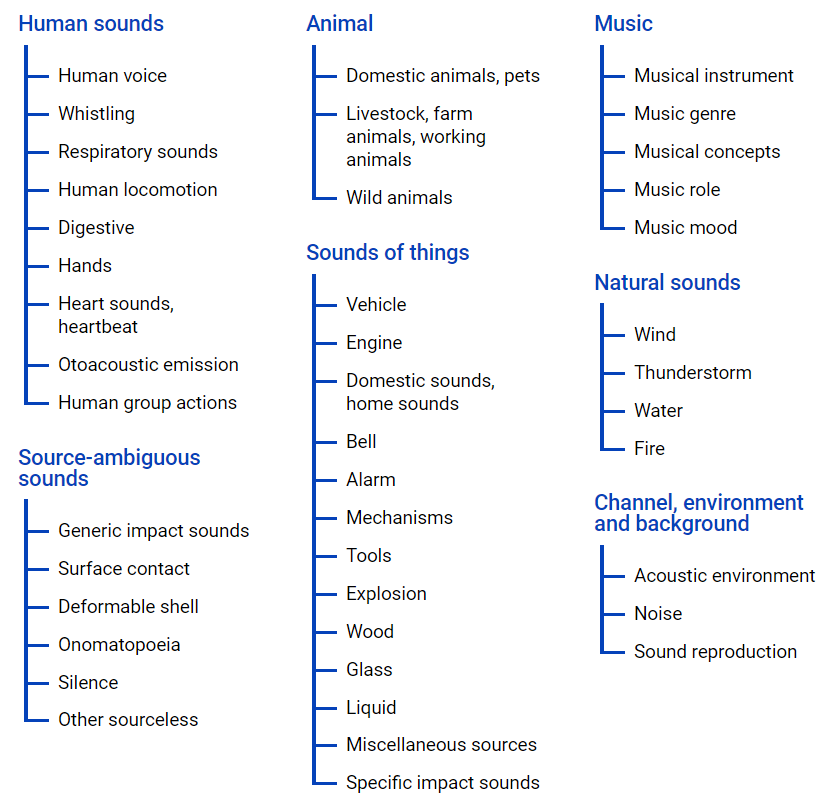
Este archivo le permite tener una idea de la anidación de clases, así como el acceso a videos de youtube. Para cargar datos desde el espacio de Internet, puede usar el módulo python - youtube-dl, que le permite descargar contenido de audio o video, según la tarea requerida.
AudioSet representa un grupo dividido en tres conjuntos: conjunto de datos de prueba, entrenamiento (balanceado) y entrenamiento (no balanceado).
Miremos este grupo y analicemos cada uno de estos conjuntos por separado para tener una idea de las clases contenidas.
Entrenamiento (equilibrado)Según la documentación, este conjunto de datos consta de
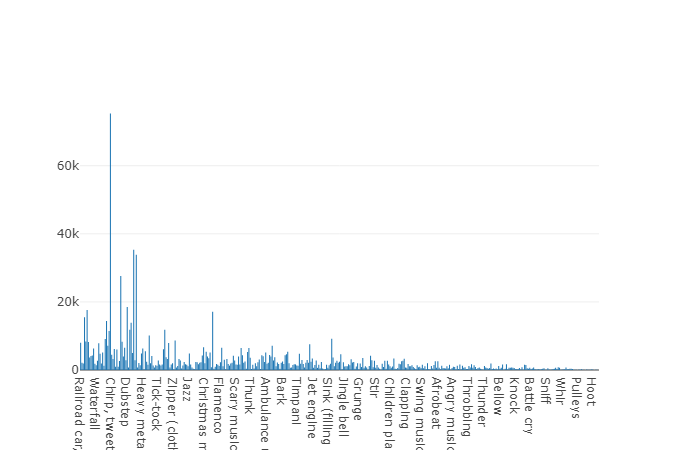
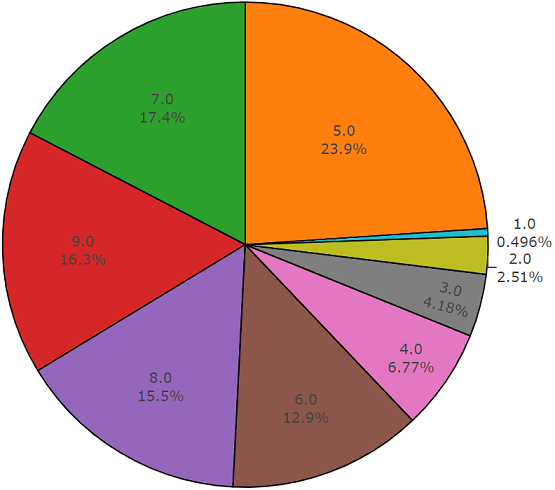
22,176 segmentos obtenidos de varios videos seleccionados por palabras clave, lo que proporciona a cada clase al menos 59 copias. Si observamos la densidad de distribución de las clases raíz en la jerarquía del conjunto, veremos que la clase Música es el grupo más grande de archivos de audio.
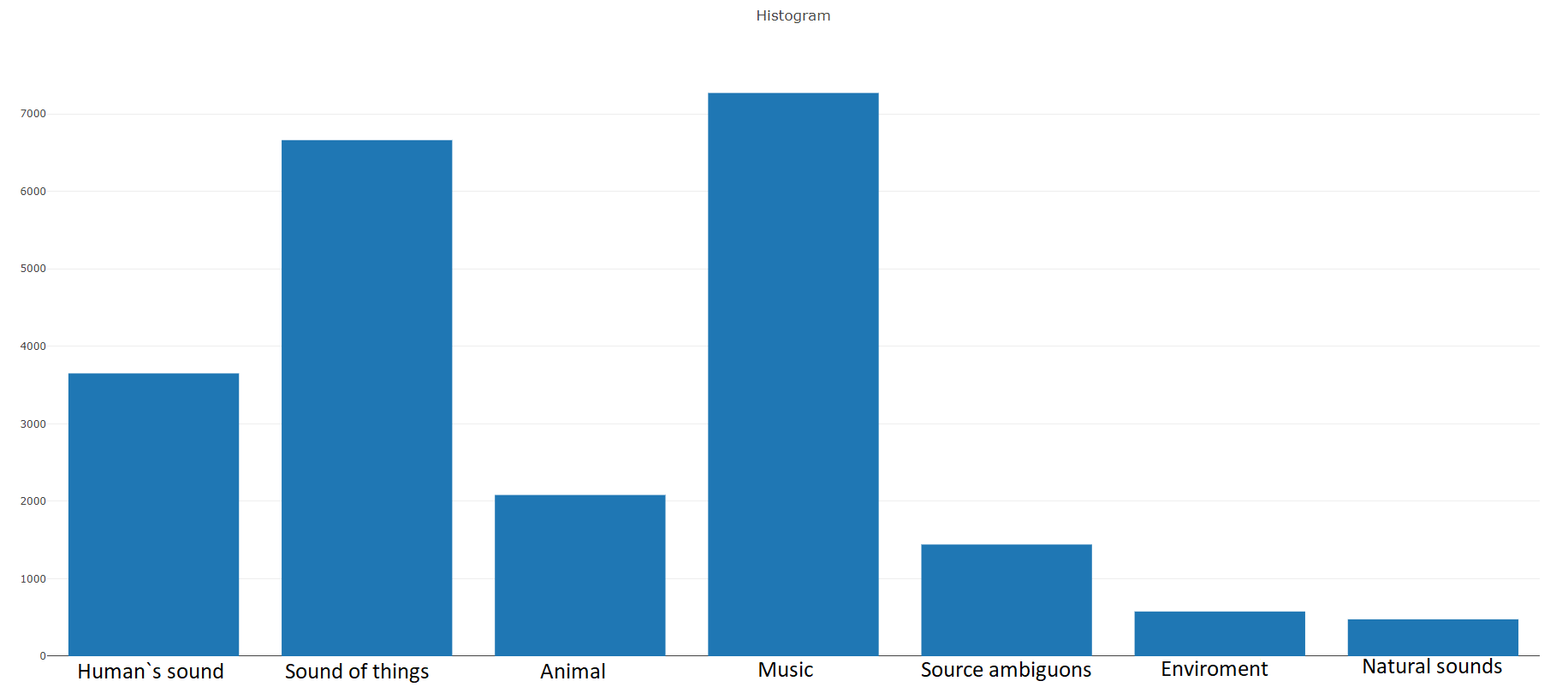
Las clases organizadas se descomponen en subconjuntos de clases, lo que le permite obtener información más detallada al usarla. Este conjunto de entrenamiento equilibrado tiene una densidad de distribución en la que está claro que el equilibrio está presente, pero también las clases individuales se distinguen mucho de la visión general.
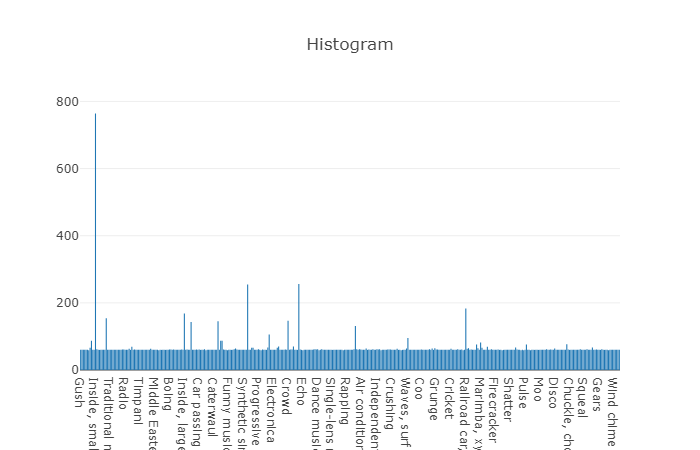
La distribución de clases cuyo número de elementos excede el valor promedio
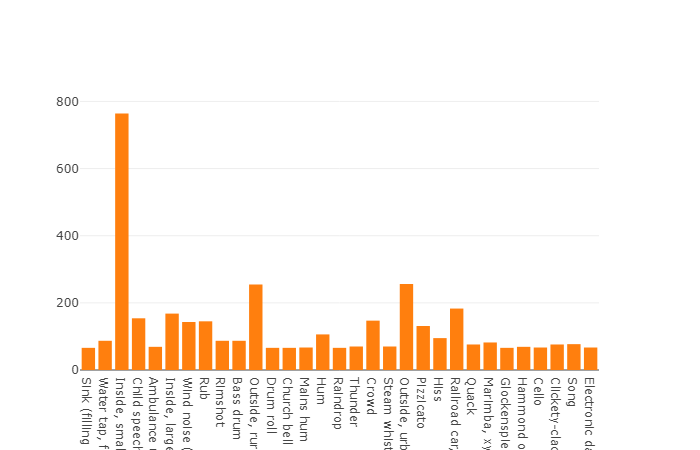
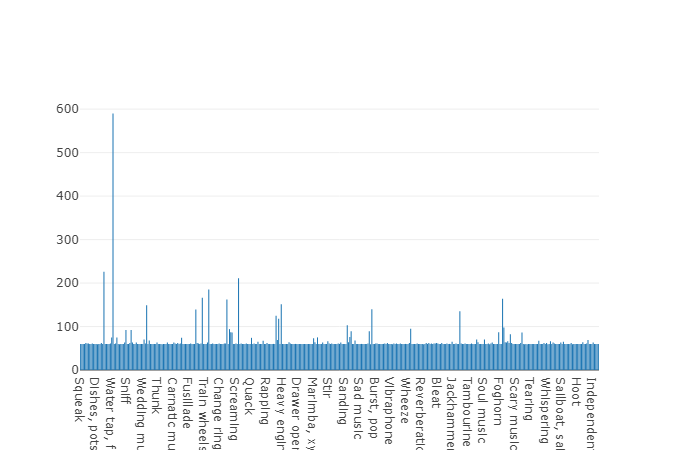
La duración promedio de cada uno de los archivos de audio es de 10 segundos, el diagrama de disco presenta información más detallada, que muestra que la duración de algunos archivos difiere del conjunto principal. Este cuadro también se presenta.
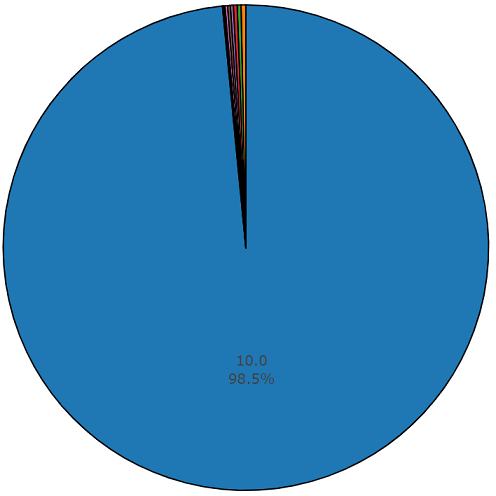
Diagrama de uno y medio por ciento de duración no promedio de un conjunto equilibrado de audioset
 Entrenamiento (desequilibrado)
Entrenamiento (desequilibrado)La ventaja de este conjunto de datos es su tamaño. Solo imagine que, según la documentación, este conjunto incluye 2.042.985 segmentos y, en comparación con los conjuntos de datos equilibrados, representa una gran variabilidad, pero la entropía de este conjunto es mucho mayor.
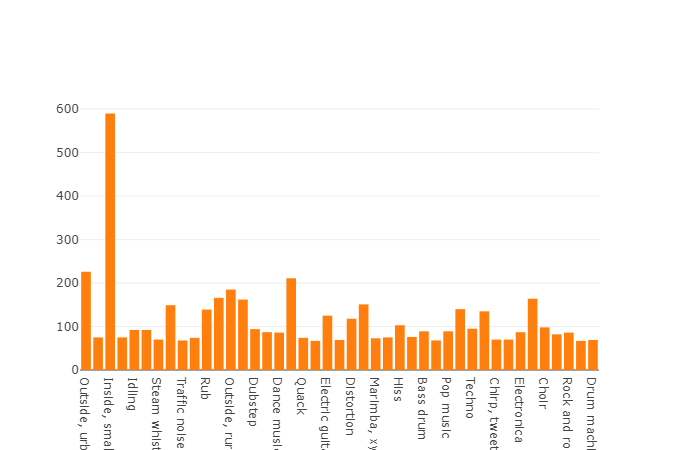
En este conjunto, la duración promedio de cada uno de los archivos de audio también es igual a 10 segundos, el diagrama de disco para este conjunto de datos se presenta a continuación.
Gráfico de duración no promedio de un conjunto desequilibrado de audioset
 Conjunto de prueba
Conjunto de pruebaEste conjunto es muy similar a un conjunto equilibrado con la ventaja de que los elementos de estos conjuntos no se cruzan. Su distribución se presenta a continuación.
La distribución de clases cuyo número de elementos excede el valor promedio
La duración promedio de un segmento de este conjunto de datos también es igual a 10 segundos
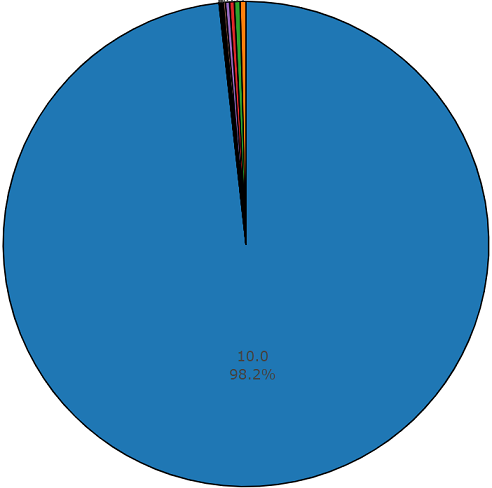
y el resto tiene la duración que se muestra en el diagrama del disco
Código de ejemplo para analizar y descargar datos acústicos de acuerdo con el conjunto de datos seleccionado:
import plotly import plotly.graph_objs as go from collections import Counter import numpy as np import os import termcolor import csv import json import youtube_dl import subprocess
Para obtener información más detallada sobre el análisis de los datos del audioset, o para cargar estos datos desde el espacio del yotubo de acuerdo con el
archivo de ontología y el
conjunto seleccionado
de audioset , el código del programa está disponible gratuitamente en
el repositorio de GitHub .
Urbansound
Urbansound es uno de los conjuntos de datos más grandes con eventos de sonido etiquetados, cuyas clases pertenecen al entorno urbano. Este conjunto se llama taxonómico (categórico), es decir cada clase se divide en sus subclases. Tal multitud puede ser representada como un árbol.
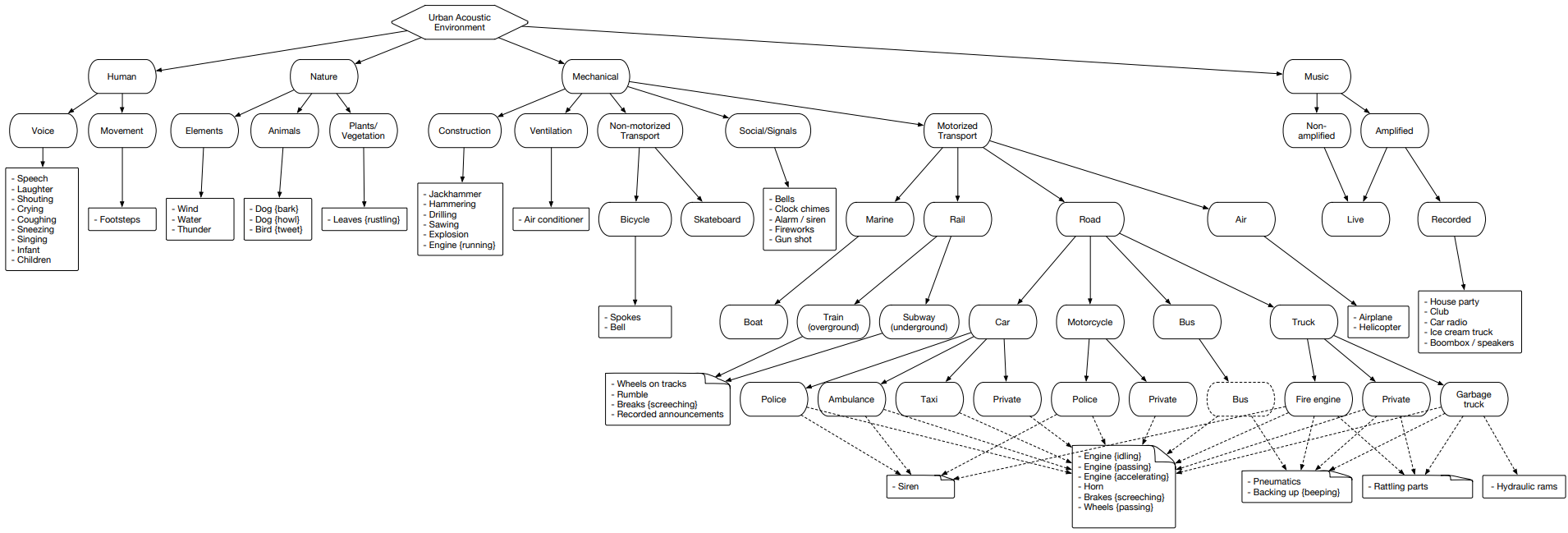
Para cargar datos de urbansound para su uso posterior, solo vaya a la página y haga clic en
descargar .
Dado que la tarea no necesita usar todas las subclases, y solo se necesita una sola clase asociada con el automóvil, primero es necesario filtrar las clases necesarias utilizando el meta archivo ubicado en la raíz del directorio obtenido al descomprimir el archivo descargado.
Después de descargar todos los datos necesarios de las fuentes enumeradas, resultó formar un conjunto de datos que contiene más de 15,000 archivos. Tal volumen de datos nos permite pasar a la tarea de entrenar el clasificador acústico, pero sigue habiendo un problema sin resolver con respecto a la "pureza" de los datos, es decir. El conjunto de capacitación incluye datos no relacionados con las clases necesarias del problema que se está resolviendo. Por ejemplo, cuando escuchas archivos de la clase "romper cristales", puedes encontrar personas hablando de "cómo no es bueno romper el vidrio". Por lo tanto, nos enfrentamos a la tarea de filtrar datos y, como herramienta para resolver este tipo de problema, una herramienta es perfectamente adecuada, cuyo núcleo fue desarrollado por muchachos bielorrusos y recibió el extraño nombre "Yandex.Toloka".
Yandex.Toloka
Yandex.Toloka es un proyecto de crowdfunding creado en 2014 para marcar o recopilar una gran cantidad de datos para su uso posterior en el aprendizaje automático. De hecho, esta herramienta le permite recopilar, marcar y filtrar datos utilizando un recurso humano. Sí, este proyecto no solo le permite resolver problemas, sino que también permite que otras personas ganen dinero. La carga financiera en este caso recae sobre sus hombros, pero debido al hecho de que más de 10,000 trabajadores actúan por parte de los artistas, los resultados del trabajo se recibirán en el futuro cercano. Puede encontrar una buena descripción del funcionamiento de esta herramienta en el
blog de Yandex .
En general, el uso del enamoramiento no es particularmente difícil, ya que la publicación de una tarea solo requiere el registro en el
sitio , una cantidad mínima de 10 dólares estadounidenses y una tarea ejecutada correctamente. Cómo formular correctamente una tarea, puede ver la
documentación de Yandex.Tolok o no hay un mal
artículo sobre Habr . De mi parte a este artículo, quiero agregar que incluso si falta una plantilla adecuada para el requisito de su tarea, su desarrollo no tomará más de unas pocas horas de trabajo, con un descanso para tomar un café y un cigarrillo, y los resultados de los artistas pueden obtenerse al final de la jornada laboral.
ConclusiónEn el aprendizaje automático, al resolver el problema de clasificación o regresión, una de las tareas principales es desarrollar un conjunto de datos confiable: un conjunto de datos. En este artículo, se consideraron fuentes de información con una gran cantidad de datos acústicos que permitieron formar y equilibrar el conjunto de datos necesarios para una tarea específica. El código del programa presentado nos permite simplificar la operación de carga de datos al mínimo, reduciendo así el tiempo para recibir datos y gastar el resto en el desarrollo de un clasificador.
En cuanto a mi tarea, después de recopilar datos de todas las fuentes presentadas en este artículo y el posterior filtrado de los datos, logré formar el conjunto de datos necesario para entrenar el clasificador acústico, que se basa en una red neuronal. Espero que este artículo les permita a usted y a su equipo ahorrar tiempo y gastarlo en el desarrollo de nuevas tecnologías.
PS Un módulo de software desarrollado en python, para análisis y carga de datos acústicos para cada una de las fuentes presentadas, puede encontrarlo en
el repositorio de github