
Esta publicación es una traducción del
artículo original
de Paid Nidrinhouse, ingeniero de software de pila completa. Su especialidad principal es JavaScript, pero Paige también estudia otros lenguajes y marcos. Y comparte su experiencia con sus lectores. Por cierto, el artículo será interesante para principiantes.
Recientemente, me enfrenté a una tarea que me interesaba: era necesario extraer ciertos datos del gran volumen de archivos no estructurados de la Comisión Federal de Elecciones de EE. UU. No trabajé demasiado con datos en bruto, así que decidí asumir el desafío y asumir esta tarea. Como herramienta para resolverlo, elegí Node.js.
Skillbox recomienda: El curso en línea de Frontend Developer Profession .
Le recordamos: para todos los lectores de "Habr": un descuento de 10.000 rublos al registrarse en cualquier curso de Skillbox con el código de promoción "Habr".
La tarea se describió en cuatro puntos:
- El programa debe calcular el número total de líneas en el archivo.
- Cada octava columna contiene el nombre de una persona. Necesita cargar estos datos y crear una matriz con todos los nombres contenidos en el archivo. Es necesario mostrar los nombres 432 y 43.243.
- Cada quinta columna contiene la fecha de donación de los voluntarios. Cuente cuántas donaciones totales se hacen cada mes e imprima el resultado total.
- Cada octava columna contiene el nombre de una persona. Cree una matriz seleccionando solo el nombre, sin el apellido. ¿Averigua qué nombre se encuentra con mayor frecuencia y cuántas veces?
(La tarea original se puede
ver aquí en este enlace ).
El archivo con el que necesita trabajar es un .txt normal de 2.55 GB. También hay una carpeta que contiene partes del archivo principal (puede depurar el programa en ellas sin tener que analizar toda la gran matriz).
Dos posibles soluciones en Node.js
En principio, trabajar con archivos grandes no asusta a un especialista en JavaScript. Además, esta es una de las principales funciones de Node.js. Hay varias soluciones posibles para leer y escribir en archivos.
El familiar es fs.readFile (). Le permite leer todo el archivo, guardarlo en la memoria y luego usar Nodo.
Una alternativa es fs.createReadStream (), una función que pasa datos similares a cómo está organizada en otros idiomas, por ejemplo, en Python o Java.
La solución que elegí
Como necesitaba calcular el número total de líneas y analizar los datos para analizar nombres y fechas, decidí detenerme en la segunda opción. Aquí podría usar la función rl.on ('línea', ...) para obtener los datos necesarios de las líneas.
Código Node.js CreateReadStream () y ReadFile ()
A continuación se muestra el código que escribí usando Node.js y la función fs.createReadStream ().
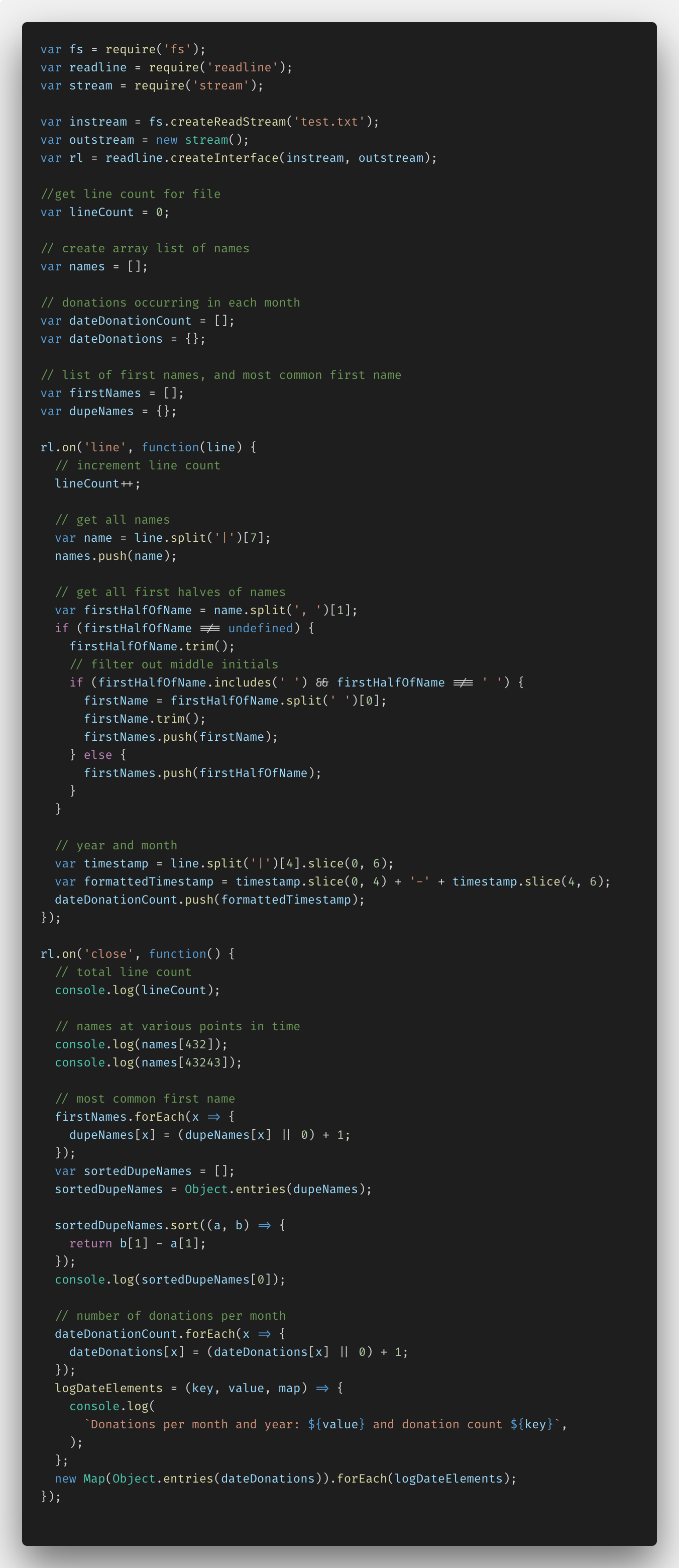
Inicialmente, necesitaba configurar todo, dándome cuenta de que importar datos requiere funciones de Node.js como fs (sistema de archivos), readline y stream. A continuación, pude crear instream y outstream junto con readLine.createInterface (). El código resultante hizo posible analizar el archivo línea por línea, tomando los datos necesarios.
Además, agregué varias variables y comentarios para trabajar con datos específicos. Estos son lineCount, dupeNames y matrices de nombres, donaciones y firstNames.
En la función rl.on ('línea', ...), pude configurar el análisis de archivos línea por línea. Entonces, ingresé la variable lineCount para cada línea. Usé el método JavaScript split () para analizar nombres agregándolos a mi matriz de nombres. A continuación, separé solo los nombres sin apellidos, al tiempo que destaqué las excepciones, como la presencia de nombres dobles, iniciales en el medio del nombre, etc. A continuación, separé el año y la fecha de la columna de datos, convirtiendo todo esto al formato AAAA-MM y agregando dateDonationCount a la matriz.
En la función rl.on ('close', ...), realicé todas las transformaciones de los datos agregados a las matrices, con la información recibida en console.log.
lineCount y nombres son necesarios para determinar los nombres 432 y 43.243; no se requieren conversiones aquí. Pero la identificación del nombre más común en la matriz y la determinación del número de donaciones son tareas más complicadas.
Para identificar el nombre más común, tuve que crear un objeto de pares de valores para cada nombre (clave) y el número de referencias a Object.entries (). (valor) y luego convertirlo todo en una matriz de matrices utilizando la función ES6. Después de eso, la tarea de ordenar nombres e identificar los más duplicados ya no era difícil.
Con las donaciones, hice el mismo truco: creé un objeto de pares de valores y la función logDateElements (), que me permitió, usando la interpolación ES6, mostrar las claves y los valores de cada mes. Luego creé un nuevo Map (), convirtiendo el objeto dateDonations en un metamarray, y recorrí cada matriz usando logDateElements (). (Resultó que no era tan simple como parecía al principio).
Pero funcionó, pude leer un archivo relativamente pequeño de 400 MB, destacando la información necesaria.
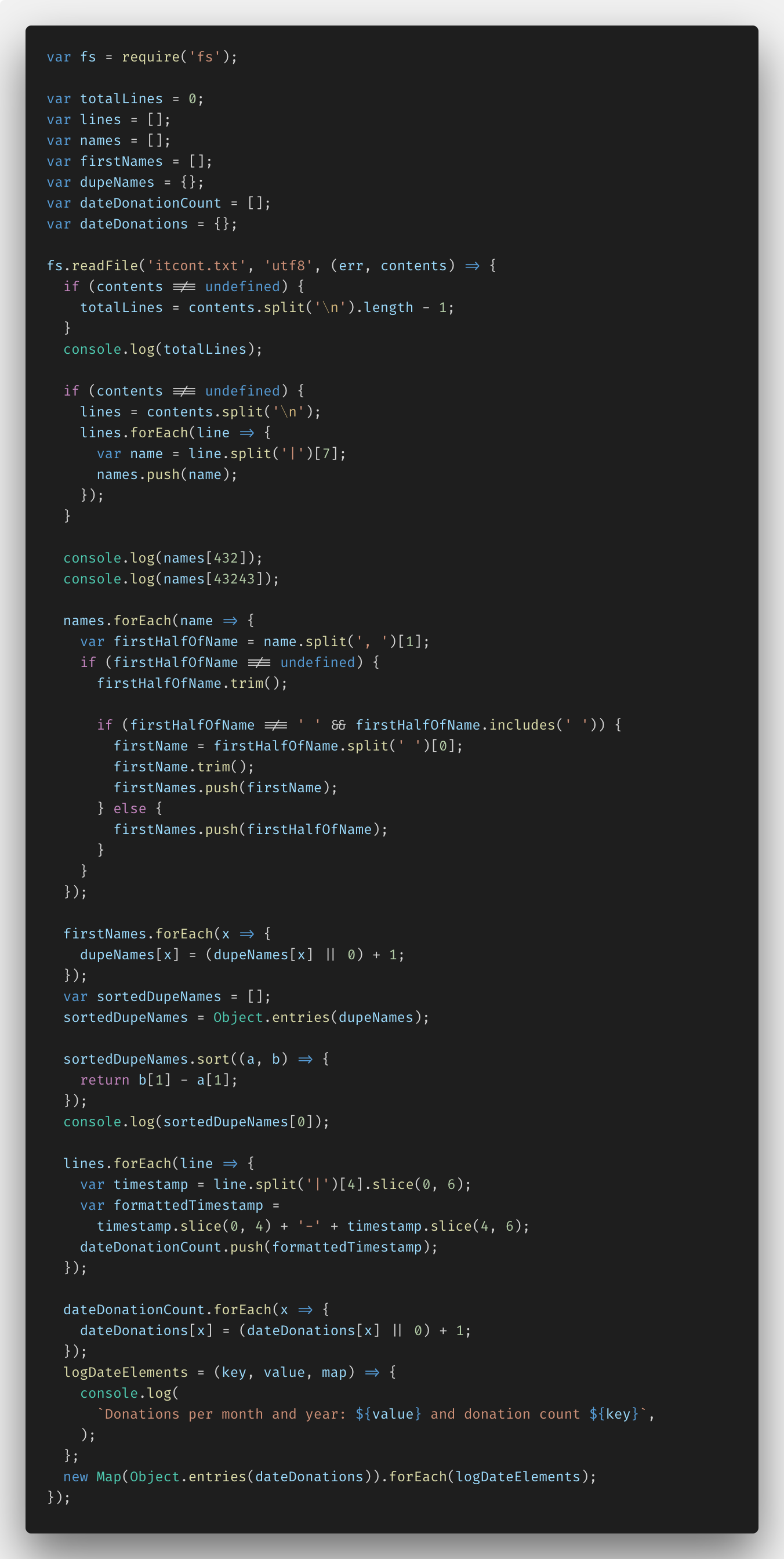
Después de eso probé fs.createReadStream (): implementé la tarea en fs.readFile () para ver la diferencia. Aquí está el código:
Puedes ver la solución completa
aquí .
Resultados del trabajo con Node.js
La solución resultó estar funcionando. Agregué la ruta al archivo readFileStream.js y ... vi el servidor Node bloquearse con un error de memoria de montón de JavaScript.

Resultó que, aunque todo funcionó, pero esta solución intentó transferir todo el contenido del archivo a la memoria, lo que era imposible con una capacidad de 2,55 GB. Nodo puede trabajar simultáneamente con 1,5 GB en memoria, no más.
Por lo tanto, ninguna de mis decisiones surgió. Tomó uno nuevo que podría funcionar incluso con archivos tan voluminosos.
Nueva solución
Al final resultó que, era necesario utilizar el popular módulo NPM EventStream.
Después de estudiar la documentación, pude entender lo que hay que hacer. Aquí está la tercera versión del código del programa.

La documentación para el módulo indicó que la secuencia de datos debe dividirse en elementos separados utilizando el carácter \ n al final de cada línea del archivo txt.
Básicamente, lo único que tuve que cambiar fue la respuesta de los nombres. No pude poner 130 millones de nombres en la matriz; nuevamente apareció el error de falta de memoria. Resolví el problema calculando los nombres 432 y 43.243 y agregándolos a mi propia matriz. Un poco no lo que se preguntó en las condiciones, pero ¿quién dijo que no se puede ser creativo?
Ronda 2. Probamos el programa en el trabajo
Sí, todo el mismo archivo con un volumen de 2.55 GB, cruzamos los dedos y seguimos el resultado.
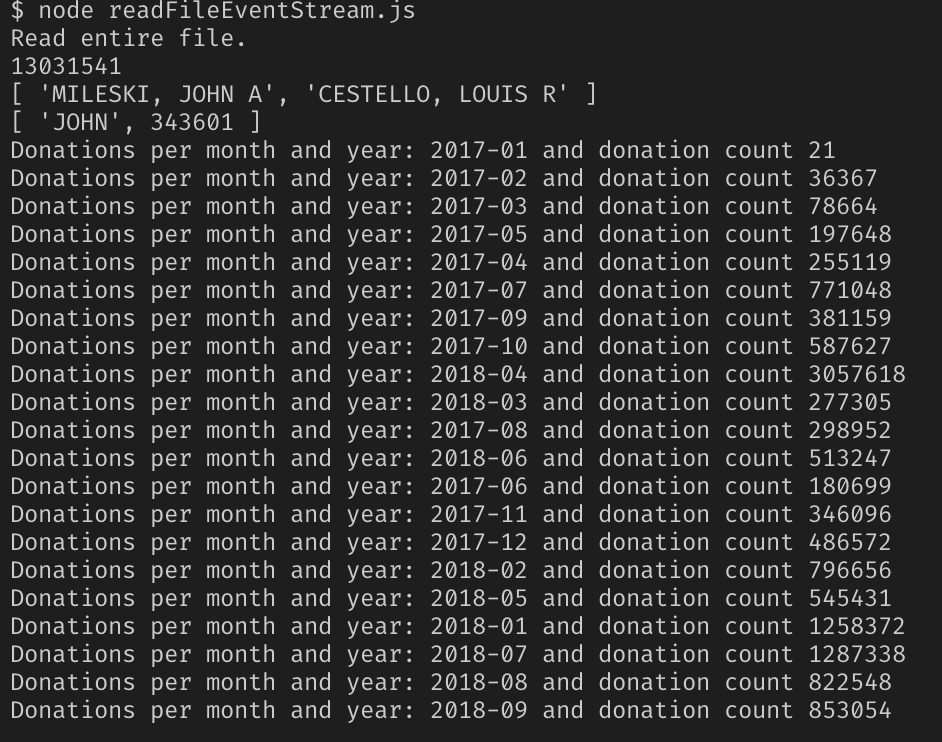
Éxito!
Al final resultó que, solo Node.js no es adecuado para resolver tales problemas, sus capacidades son algo limitadas. Pero expandiéndolos usando módulos, puede trabajar con archivos tan grandes.
Skillbox recomienda: