Estandarización total
Preparé este material para mi discurso en la conferencia y le pregunté a nuestro director técnico cuál era la característica principal de Kubernetes para nuestra organización. El respondió:
Los propios desarrolladores no entienden cuánto trabajo adicional hicieron.
Aparentemente, se inspiró en el libro recientemente leído "Factfulness" : es difícil notar cambios menores y continuos para mejor, y constantemente perdemos de vista nuestro progreso.
Pero el cambio a Kubernetes definitivamente no es insignificante.

Casi 30 de nuestros equipos ejecutan todas o algunas de las cargas de trabajo en los clústeres. Alrededor del 70% de nuestro tráfico HTTP es generado por aplicaciones en clústeres de Kubernetes. Esta es probablemente la mayor convergencia de tecnologías desde que me uní a la compañía después de que Forward comprara uSwitch en 2010, cuando cambiamos de servidores .NET y físicos a AWS y de un sistema monolítico a microservicios .
Y todo sucedió muy rápido. A finales de 2017, todos los equipos utilizaron su infraestructura de AWS. Configuraron equilibradores de carga, instancias EC2, actualizaciones de clúster ECS y cosas por el estilo. Pasó poco más de un año y todo cambió.
Pasamos un mínimo de tiempo convergiendo y, como resultado, Kubernetes nos ayudó a resolver problemas apremiantes: nuestra nube crecía, la organización se volvía más complicada y estábamos luchando por integrar a las nuevas personas en equipos. No cambiamos la organización para usar Kubernetes. Por el contrario, utilizamos Kubernetes para cambiar la organización.
Es posible que los desarrolladores no hayan notado grandes cambios, pero los datos hablan por sí mismos. Más sobre esto más tarde.
Hace muchos años estuve en una conferencia de Clojure y escuché una conferencia de Michael Nygard sobre arquitectura que no se puede llevar a su estado final . Me abrió los ojos. Un sistema ordenado y ordenado se ve caricaturizado cuando compara las tiendas de TV con productos de cocina y la arquitectura de software a gran escala: el sistema existente se ve como un cuchillo tonto y sale algún tipo de papilla en lugar de incluso rebanadas. Sin un cuchillo nuevo, no hay nada que pensar en ensalada.
Se trata de cómo las organizaciones adoran los proyectos de tres años: el primer año es desarrollo y preparación, el segundo año es implementación, el tercero es retorno. En una conferencia, dice que tales proyectos generalmente se realizan de forma continua y rara vez llegan al final del segundo año (a menudo debido a la adquisición por parte de otra empresa y un cambio de dirección y estrategia), por lo que la arquitectura habitual
estratificación del cambio en cierta apariencia de estabilidad.
Y uSwitch es un gran ejemplo.
Cambiamos a AWS por muchas razones: nuestro sistema no podía hacer frente a las cargas máximas, y la organización se vio obstaculizada por un sistema demasiado rígido y equipos estrechamente relacionados que se formaron para proyectos específicos y se dividieron por especialización.
No íbamos a dejar todo, transferir todos los sistemas y comenzar de nuevo. Creamos nuevos servicios con proxy a través del equilibrador de carga existente y gradualmente bloqueamos la aplicación anterior. Queríamos mostrar de inmediato la devolución y en la primera semana realizamos pruebas A / B de la primera versión del nuevo servicio en producción. Como resultado, tomamos productos a largo plazo y comenzamos a formar equipos para ellos de desarrolladores, diseñadores, analistas, etc. E inmediatamente vimos el resultado. En 2010, esto parecía una verdadera revolución.
Año tras año, agregamos nuevos equipos, servicios y aplicaciones y gradualmente "estrangulamos" el sistema monolítico. Los equipos progresaron rápidamente: ahora trabajaban independientemente el uno del otro y estaban formados por especialistas en todos los campos necesarios. Minimizamos las interacciones de equipo para lanzamientos de productos. Hemos asignado varios comandos solo para la configuración del equilibrador de carga.
Los propios equipos eligieron métodos de desarrollo, herramientas e idiomas. Les pusimos una tarea, y ellos mismos encontraron una solución, porque eran los más versados en el asunto. Con AWS, estos cambios se han vuelto más fáciles.
Intuitivamente, seguimos los principios de la programación: los equipos que están conectados entre sí serán menos propensos a comunicarse y no tendremos que gastar recursos preciosos en coordinar su trabajo. Todo esto está muy bien descrito en el libro recientemente publicado Accelerate .
Como resultado, como describió Michael Nygard, obtuvimos un sistema de muchas capas de cambios: algunos sistemas se automatizaron con Puppet, algunos con Terraform, en algún lugar donde usamos ECS, en algún lugar EC2.
En 2012, estábamos orgullosos de nuestra arquitectura, que se podía cambiar fácilmente para experimentar , encontrar soluciones exitosas y desarrollarlas.
Pero en 2017, nos dimos cuenta de que muchas cosas han cambiado.
AWS ahora es mucho más complejo que en 2010. Ofrece un montón de opciones y características, pero no sin consecuencias. Hoy, cualquier equipo que trabaje con EC2 tiene que elegir una VPC, configuración de red y mucho más.
Experimentamos esto por nuestra cuenta: los equipos comenzaron a quejarse de que dedicaban cada vez más tiempo a mantener la infraestructura, por ejemplo, actualizando instancias en clústeres ECS de AWS , máquinas EC2, cambiando de equilibradores ELB a ALB, etc.
A mediados de 2017, en un evento corporativo, insté a todos a estandarizar su trabajo para mejorar la calidad general de los sistemas. Utilicé la metáfora del iceberg para mostrar cómo creamos y mantenemos el software:

Dije que la mayoría de los equipos de nuestra empresa deberían crear servicios o productos y centrarse en la resolución de problemas, el código de la aplicación, las plataformas y bibliotecas, etc. En ese orden. Queda mucho trabajo bajo el agua: integración de registros, aumento de la observabilidad, gestión de secretos, etc.
En ese momento, cada equipo de desarrolladores de aplicaciones se ocupó de casi todo el iceberg y tomó todas las decisiones por sí mismo: eligió el idioma, el entorno de desarrollo, la biblioteca y la herramienta de métricas, el sistema operativo, el tipo de instancia y el almacenamiento.
En la base de la pirámide, teníamos la infraestructura de Amazon Web Services. Pero no todos los servicios de AWS son iguales. Tienen un Back-end-as-a-Service (BaaS) , por ejemplo, para autenticación y almacenamiento de datos. Y hay otros servicios de nivel relativamente bajo, como EC2. Quería estudiar los datos y comprender que los equipos tienen motivos para quejarse y que realmente pasan más tiempo trabajando con servicios de bajo nivel y toman muchas decisiones no importantes.
Dividí los servicios en categorías, usando CloudTrail , reuní todas las estadísticas disponibles, y luego usé BigQuery , Athena y ggplot2 para ver cómo ha cambiado la situación para los desarrolladores últimamente. Crecimiento para servicios como RDS, Redshift, etc., lo consideramos deseable (y esperado), y crecimiento para EC2, CloudFormation, etc., por el contrario.

Cada punto del diagrama muestra los percentiles 90 (rojo), 80 (verde) y 50 (azul) para la cantidad de servicios de bajo nivel que nuestra gente usó todas las semanas durante un período determinado. Agregué líneas de suavizado para mostrar la tendencia.
Aunque apuntamos a abstracciones de alto nivel al implementar software, por ejemplo, utilizando contenedores y Amazon ECS , nuestros desarrolladores utilizaron regularmente más y más servicios de AWS y no ignoraron suficientemente las dificultades de administrar sistemas. En dos años, el número de servicios se duplicó para el 50% de los empleados y casi se triplicó para el 20%.
Esto limitó el crecimiento de nuestra empresa. Los equipos buscaron autonomía, pero ¿cómo contratar nuevas personas? Necesitábamos fuertes desarrolladores de aplicaciones y productos y conocimiento del sistema AWS cada vez más sofisticado.
Queríamos expandir nuestros equipos y al mismo tiempo preservar los principios con los que tuvimos éxito: autonomía, coordinación mínima e infraestructura de autoservicio.
Con Kubernetes, logramos esto con abstracciones centradas en la aplicación y la capacidad de mantener y configurar clústeres con una coordinación mínima del equipo.
Abstracciones centradas en la aplicación
Los conceptos de Kubernetes son fáciles de combinar con el lenguaje que usa el desarrollador de la aplicación. Suponga que está administrando versiones de aplicaciones como una implementación . Puede ejecutar múltiples réplicas detrás del servicio y asignarlas a HTTP a través de Ingress . Y a través de los recursos del usuario, puede expandir y especializar este idioma según lo que necesite.
Los equipos trabajan de manera más eficiente con estas abstracciones. Básicamente, este ejemplo tiene todo lo que necesita para implementar y ejecutar una aplicación web. El resto es Kubernetes.
En la imagen con el iceberg, estos conceptos están al nivel del agua y combinan las tareas del desarrollador desde arriba con la plataforma de abajo. El equipo de administración del clúster puede tomar decisiones de bajo nivel e insignificantes (sobre la administración de métricas, el registro, etc.) y al mismo tiempo hablar el mismo idioma con los desarrolladores por encima del agua.
En 2010, uSwitch tenía equipos tradicionales para dar servicio a un sistema monolítico, y más recientemente teníamos un departamento de TI que administraba parcialmente nuestra cuenta de AWS. Me parece que la falta de conceptos comunes obstaculizó seriamente el trabajo de este equipo.
Intente decir algo útil si solo tiene instancias EC2 en su vocabulario, equilibradores de carga y subredes. Fue difícil o incluso imposible describir la esencia de la aplicación. Podría ser un paquete Debian, implementación a través de Capistrano, etc. No pudimos describir la aplicación en un lenguaje común para todos.
A principios de la década de 2000, trabajé en ThoughtWorks en Londres. En la entrevista, me aconsejaron leer el diseño orientado a problemas de Eric Evans. Compré un libro camino a casa y comencé a leer en el tren. Desde entonces, la recuerdo en casi todos los proyectos y sistemas.
Uno de los conceptos principales del libro es un idioma único en el que se comunican los diferentes equipos. Kubernetes solo proporciona un lenguaje unificado para desarrolladores y equipos de mantenimiento de infraestructura, y esta es una de sus principales ventajas. Además, se puede ampliar y complementar con otras áreas temáticas y líneas de negocio.
La comunicación en un lenguaje común es más productiva, pero aún así debemos limitar la interacción entre los equipos tanto como sea posible.
Mínimo necesario de interacción
Los autores de Accelerate destacan las características de una arquitectura débilmente acoplada con la cual los equipos de TI trabajan de manera más eficiente:
En 2017, el éxito de la entrega continua dependía de si el equipo podía:
Cambie seriamente la estructura de su sistema sin el permiso de la administración.
Cambie seriamente la estructura de su sistema, sin esperar a que otros equipos cambien la suya, y sin crear mucho trabajo innecesario para otros equipos.
Realice sus tareas sin comunicar o coordinar su trabajo con otros equipos.
Implemente y publique un producto o servicio a pedido, independientemente de otros servicios asociados con él.
Realice la mayoría de las pruebas a pedido, sin un entorno de prueba integrado.
Necesitábamos software centralizado de clústeres de múltiples inquilinos para todos los equipos, pero al mismo tiempo queríamos mantener estas características. Todavía no hemos alcanzado el ideal, pero estamos haciendo lo mejor que podemos:
- Tenemos varios grupos de trabajo y los equipos mismos eligen dónde ejecutar la aplicación. Todavía no usamos federación (estamos esperando el soporte de AWS), pero tenemos Envoy para balanceo de carga en balanceadores de Ingress en diferentes grupos. Automatizamos la mayoría de estas tareas utilizando la tubería de entrega continua (tenemos Drone ) y otros servicios de AWS.
- Todos los clústeres tienen el mismo espacio de nombres . Aproximadamente uno para cada equipo.
- Controlamos el acceso a los espacios de nombres a través de RBAC (control de acceso basado en roles). Para autenticación y autorización, utilizamos identidad corporativa en Active Directory.
- Los clústeres se escalan automáticamente y hacemos todo lo posible para optimizar el tiempo de inicio del nodo. Todavía lleva un par de minutos, pero, en general, incluso con grandes cargas de trabajo, lo hacemos sin coordinación.
- Las aplicaciones se escalan automáticamente según las métricas de nivel de aplicación de Prometheus. Los equipos de desarrollo controlan la escala automática de su aplicación mediante métricas de consulta por segundo, operaciones por segundo, etc. Gracias a la escala automática del clúster, el sistema prepara los nodos cuando la demanda excede las capacidades del clúster actual.
- Escribimos Go con una herramienta de línea de comandos llamada u que estandariza la autenticación de comandos en Kubernetes, usa Vault , solicita credenciales temporales de AWS, etc.
No estoy seguro de que con Kubernetes tengamos más autonomía, pero definitivamente se mantuvo en un nivel alto, y al mismo tiempo nos deshicimos de algunos problemas.
Cambiar a Kubernetes fue rápido. El diagrama muestra el número total de espacios de nombres (aproximadamente igual al número de comandos) en nuestros grupos de trabajo. El primero apareció en febrero de 2017.
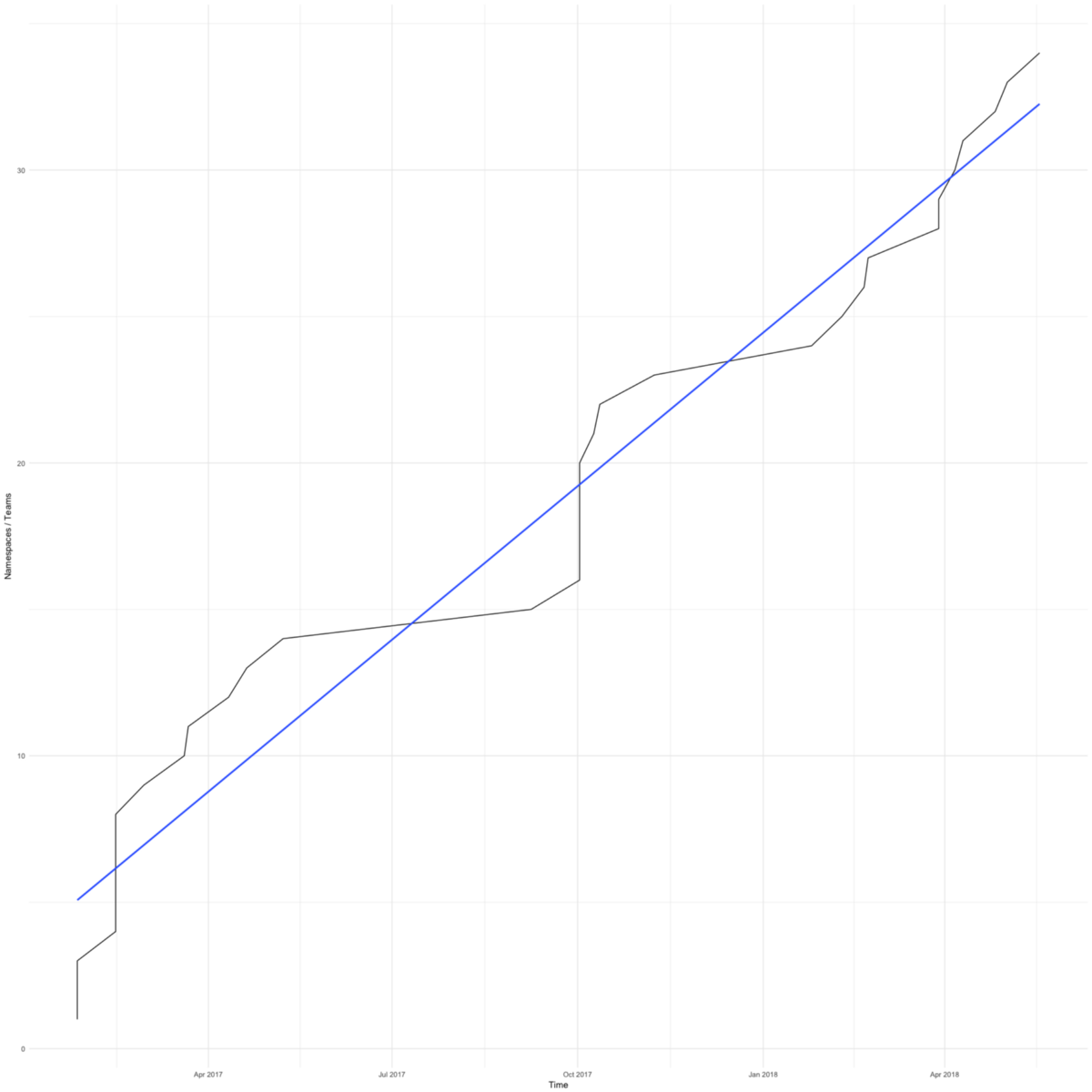
Teníamos razones para apurarnos: queríamos salvar a los pequeños equipos centrados en su producto de las preocupaciones sobre la infraestructura.
El primer equipo acordó cambiar a Kubernetes cuando su servidor de aplicaciones se quedó sin espacio debido a la configuración incorrecta de la rotación de registros. La transición tomó solo unos días, y nuevamente se pusieron manos a la obra.
Recientemente, los equipos se han cambiado a Kubetnetes para mejorar las herramientas. Los clústeres de Kubernetes simplifican la integración con nuestra Bóveda de Hashicorp , Google Cloud Trace y herramientas similares. Todos nuestros equipos obtienen características aún más efectivas.
Ya mostré una tabla con percentiles de la cantidad de servicios que nuestros empleados usaron todas las semanas desde finales de 2014 hasta 2017. Y aquí hay una continuación de este diagrama hasta el día de hoy.
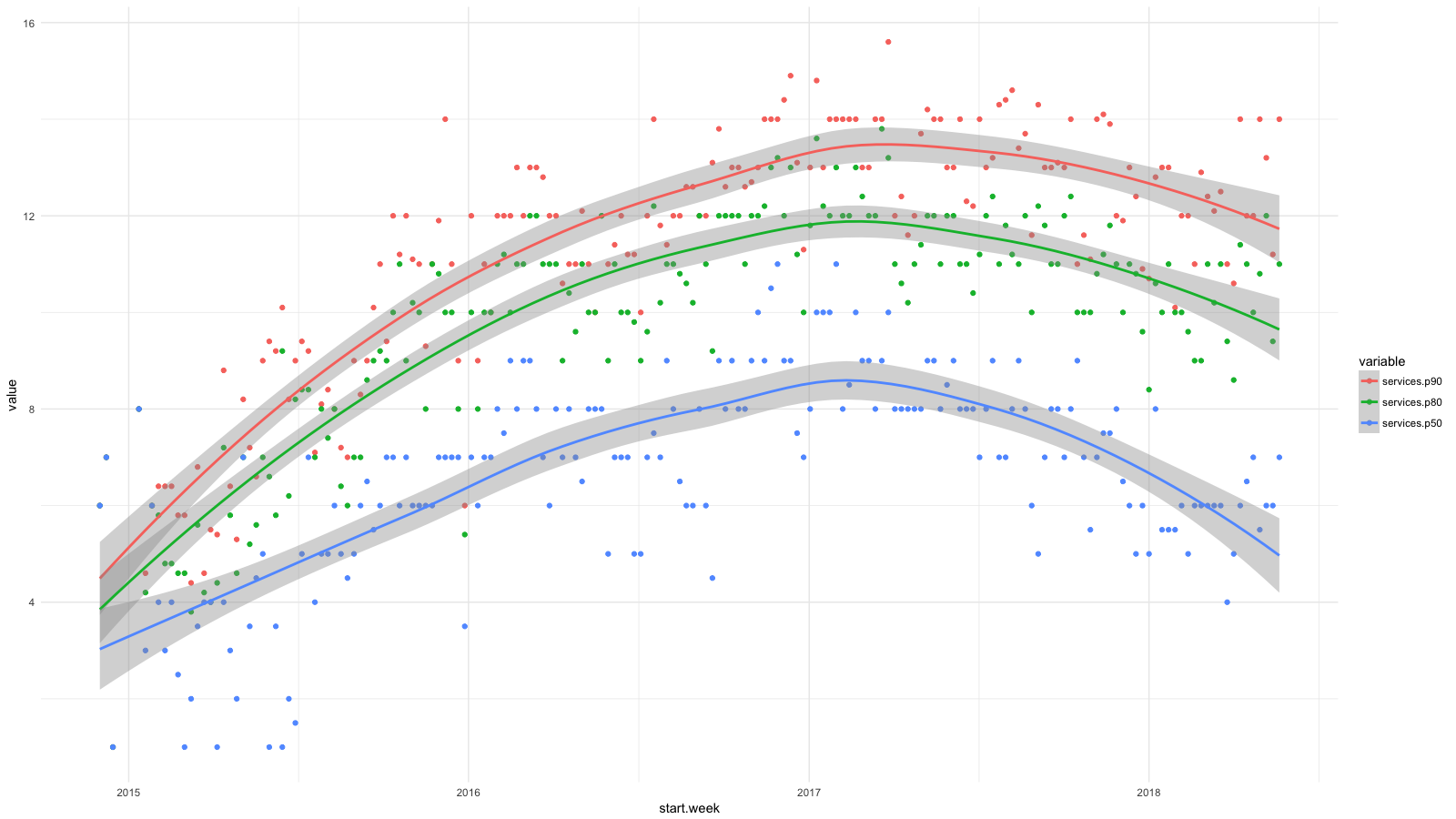
Hemos avanzado en la gestión del complejo marco de AWS. Me alegra que ahora la mitad de los empleados estén haciendo lo mismo que a principios de 2015. Tenemos entre 4 y 6 empleados en el equipo de computación en la nube, alrededor del 10% del número total; no es sorprendente que el percentil 90 casi no se moviera. Pero espero progreso aquí también.
Finalmente, hablaré sobre cómo ha cambiado nuestro ciclo de desarrollo, y nuevamente recordaré el libro de Aceleración recientemente leído.
El libro menciona dos métricas de desarrollo esbelto: tiempo de entrega y tamaño del paquete. El tiempo de entrega se considera desde la solicitud hasta la entrega de la solución final. El tamaño del paquete es la cantidad de trabajo. Cuanto más pequeño es el tamaño del paquete, más eficiente es el trabajo:
Cuanto más pequeño es el paquete, más corto es el ciclo de producción, menos variabilidad del proceso, menos riesgos, costos y costos, recibimos comentarios más rápidamente, trabajamos de manera más eficiente, tenemos más motivación, intentamos terminar más rápido y posponer la entrega con menos frecuencia.
El libro sugiere medir el tamaño de los paquetes según la frecuencia de implementación: cuanto más a menudo es la implementación, más pequeños son los paquetes.
Tenemos datos para algunas implementaciones. Los datos no son del todo precisos: algunos equipos envían comunicados directamente a la rama principal del repositorio, algunos usan otros mecanismos. Esto no incluye todas las aplicaciones, pero los datos de 12 meses pueden considerarse indicativos.
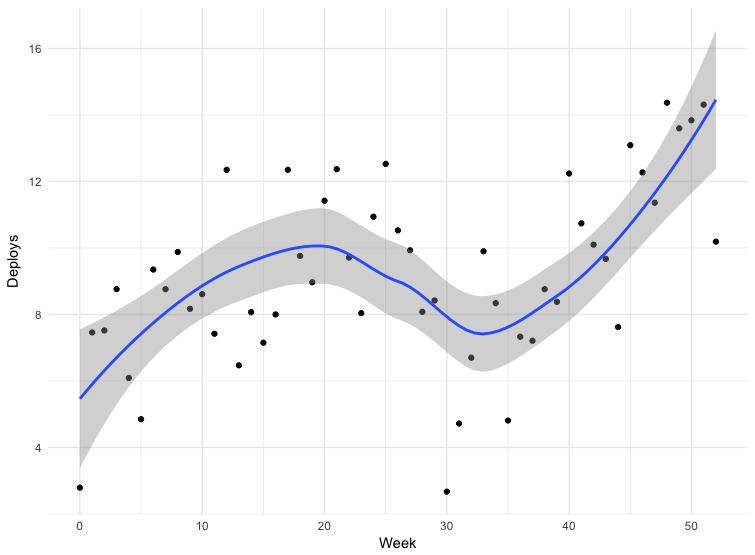
El fracaso en la trigésima semana es Navidad. Por lo demás, vemos que la frecuencia de implementación aumenta, lo que significa que el tamaño del paquete disminuye. De marzo a mayo de 2018, la frecuencia de los lanzamientos casi se duplicó, y recientemente a veces hacemos más de cien números por día.
Cambiar a Kubernetes es solo una parte de nuestra estrategia para estandarizar, automatizar y mejorar las herramientas. Lo más probable es que todos estos factores influyeron en la frecuencia de las emisiones.
Accelerate también habla sobre la relación entre la frecuencia de implementación y el número de empleados, y qué tan rápido puede trabajar una compañía si se aumenta el personal. Los autores enfatizan las limitaciones de la arquitectura y los equipos relacionados:
Tradicionalmente se cree que expandir un equipo aumenta la productividad general, pero disminuye la productividad del desarrollador individual.
Si tomamos los mismos datos sobre la frecuencia de las implementaciones y hacemos un diagrama de la dependencia de la cantidad de usuarios, vemos que podemos aumentar la frecuencia de los lanzamientos, incluso si tenemos más personas.

Al comienzo del artículo, mencioné el libro Factfulness (que inspiró nuestro CTO). La transición a Kubernetes se ha convertido para nuestros desarrolladores en la convergencia tecnológica más significativa y rápida. Nos movemos en pequeños pasos, y es fácil no notar cuánto ha cambiado todo para mejor. Es bueno que tengamos datos, y demuestran que hemos logrado lo que queremos: nuestra gente está comprometida con su producto y toma decisiones importantes en su campo.
Solía ser bueno para nosotros. Teníamos microservicios, AWS, equipos bien establecidos para productos, desarrolladores responsables de sus servicios en producción, equipos y arquitectura débilmente acoplados. Hablé sobre esto en el informe "Nuestra era de la iluminación" ("Nuestra era de la iluminación") en una conferencia en 2012. Pero no hay límite para la perfección.
Al final, quiero citar otro libro: Escala . Lo comencé recientemente, y hay un fragmento interesante sobre el consumo de energía en sistemas complejos:
Para mantener el orden y la estructura en un sistema en desarrollo, se necesita un flujo constante de energía y se crea desorden. Por lo tanto, para mantener la vida, debemos comer todo el tiempo para vencer la inevitable entropía.
Luchamos contra la entropía mediante el suministro de más energía para el crecimiento, la innovación, el mantenimiento y la reparación, que se vuelve más difícil a medida que el sistema envejece, y esta batalla es la base de cualquier discusión seria sobre el envejecimiento, la mortalidad, la sostenibilidad y la autosuficiencia de cualquier sistema, ya sea un organismo vivo. , empresa o sociedad.
Creo que puede agregar sistemas de TI aquí. Espero que nuestros últimos esfuerzos mantengan la entropía incluso por un tiempo.