Hola guardias. La publicación de hoy tratará sobre cómo no perderse en la naturaleza de la variedad de opciones para usar TensorFlow para el aprendizaje automático y lograr su objetivo. El artículo está diseñado para que el lector conozca los principios básicos de los principios del aprendizaje automático, pero aún no ha intentado hacerlo con sus propias manos. Como resultado, obtenemos una demostración funcional en Android, que reconoce algo con una precisión bastante alta. Pero lo primero es lo primero.

Después de mirar los últimos materiales, se decidió involucrar a Tensorflow , que ahora está ganando un gran impulso, y los artículos en inglés y ruso parecen ser suficientes para no profundizar en todo y poder descubrir qué es qué.
Pasando dos semanas, estudiando artículos y numerosas ex muestras en la oficina. sitio, me di cuenta de que no entendía nada. Demasiada información y opciones sobre cómo se puede usar Tensorflow. Mi cabeza ya está hinchada por cuánto ofrecen diferentes soluciones y qué hacer con ellas, según se aplica a mi tarea.

Luego, decidí probar todo, desde las opciones más simples y listas para usar (en las que debía registrar una dependencia en gradle y agregar un par de líneas de código) a otras más complejas (en las que tendría que crear y entrenar modelos de gráficos nosotros mismos y aprender a usarlos en un móvil aplicación).
Al final, tuve que usar una versión complicada, que se discutirá con más detalle a continuación. Mientras tanto, he compilado para usted una lista de opciones más simples que son igualmente efectivas, cada una se adapta a su propósito.

La solución más fácil de usar: un par de líneas de código que puede usar:
- Reconocimiento de texto (texto, caracteres latinos)
- Detección de rostros (rostros, emociones)
- Escaneo de código de barras (código de barras, código qr)
- Etiquetado de imágenes (un número limitado de tipos de objetos en la imagen)
- Reconocimiento de hitos (atracciones)
Es un poco más complicado. Con esta solución, también puede usar su propio modelo TensorFlow Lite, pero la conversión a este formato causó dificultades, por lo que este elemento no se ha probado.
Como escriben los creadores de esta descendencia, la mayoría de las tareas se pueden resolver utilizando estos desarrollos. Pero si esto no se aplica a su tarea, tendrá que usar modelos personalizados.

Una herramienta muy conveniente para crear y entrenar sus modelos personalizados usando imágenes.
De los profesionales: hay una versión gratuita que le permite mantener un proyecto.
De las desventajas: la versión gratuita limita el número de imágenes "entrantes" a 3.000. Intentar crear una red de precisión mediocre, es suficiente. Para tareas más precisas, necesita más.
Todo lo que se requiere del usuario es agregar imágenes con una marca (por ejemplo, image1 es "mapache", image2 es "sol"), entrenar y exportar el gráfico para uso futuro.
Caring Microsoft incluso ofrece su propia muestra , con la que puede probar su gráfico recibido.
Para aquellos que ya están "en el tema", el gráfico se genera ya en el estado Congelado, es decir no necesitas hacer / convertir nada con él.
Esta solución es buena cuando tienes una muestra grande y (atención) MUCHAS clases diferentes en entrenamiento. Porque de lo contrario, habrá muchas definiciones falsas en la práctica. Por ejemplo, entrenaste en mapaches y soles, y si hay una persona en la entrada, entonces puede definirse con la misma probabilidad por un sistema como uno u otro. Aunque, de hecho, ni lo uno ni lo otro.
3. Crear un modelo manualmente

Cuando necesite ajustar el modelo usted mismo para el reconocimiento de imágenes, entran en juego manipulaciones más complejas con la selección de imágenes de entrada.
Por ejemplo, no queremos tener restricciones en el volumen de la muestra de entrada (como en el párrafo anterior), o queremos entrenar el modelo con mayor precisión estableciendo el número de época y otros parámetros de entrenamiento nosotros mismos.
En este enfoque, hay varios ejemplos de Tensorflow que describen el procedimiento y el resultado final.
Aquí hay algunos ejemplos:
Da un ejemplo de cómo crear un clasificador de tipos de color basado en la base de datos abierta ImageNet de imágenes: preparar imágenes y luego entrenar el modelo. También se hace una pequeña mención de cómo puede trabajar con una herramienta bastante interesante: TensorBoard. De sus funciones más simples, demuestra claramente la estructura de su modelo terminado, así como el proceso de aprendizaje de muchas maneras.
Tensorflow Kodlab para poetas 2 : trabajo continuo con el clasificador de color. Muestra cómo si tiene los archivos de gráficos y sus etiquetas (que se obtuvieron en el codelab anterior), puede ejecutar la aplicación en Android. Uno de los puntos del codelab es la conversión del formato gráfico ".pb" "habitual" al formato lite de Tensorflow (que implica algunas optimizaciones de archivo para reducir el tamaño final del archivo gráfico, porque los dispositivos móviles lo requieren).
Reconocimiento de escritura a mano MNIST .
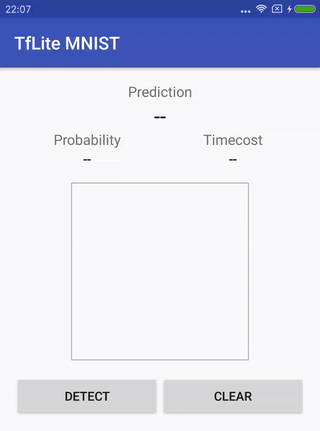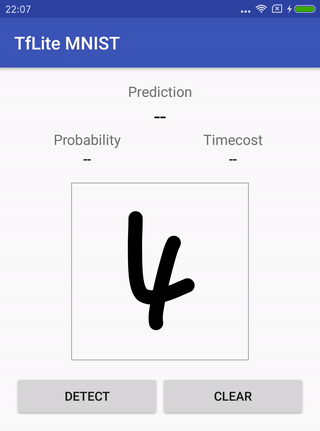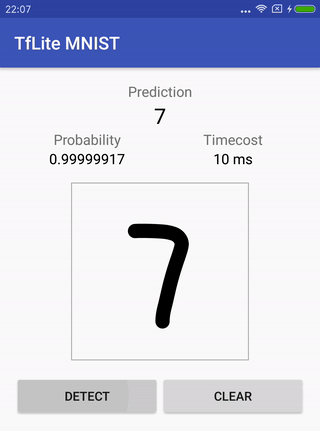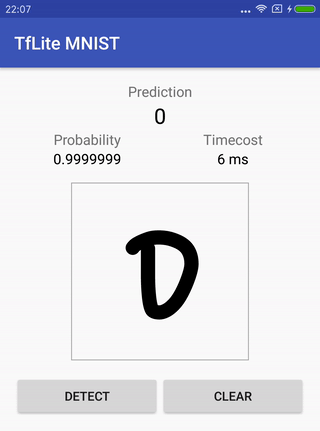
El nabo contiene el modelo original (que ya se ha preparado para esta tarea), instrucciones sobre cómo entrenarlo, convertirlo y cómo ejecutar un proyecto para Android al final para verificar cómo funciona todo.
Con base en estos ejemplos, puede descubrir cómo trabajar con modelos personalizados en Tensorflow e intentar crear uno propio o tomar uno de los modelos previamente entrenados que se ensamblan en un github:
Modelos de Tensorflow
Hablando de modelos "pre-entrenados". Matices interesantes cuando se usan esos:
- Su estructura ya está preparada para una tarea específica.
- Ya están capacitados en muestras de gran tamaño.
Por lo tanto, si su muestra no se llena lo suficiente, puede tomar un modelo previamente capacitado que tenga un alcance cercano a su tarea. Usando este modelo, agregando sus propias reglas de entrenamiento, obtendrá un mejor resultado del que trataría de entrenar el modelo desde cero.
4. Detección de objetos API + creación manual del modelo
Sin embargo, todos los párrafos anteriores no dieron el resultado deseado. Desde el principio fue difícil entender lo que hay que hacer y con qué enfoque. Luego se encontró un artículo interesante sobre la API de detección de objetos , que explica cómo encontrar varias categorías en una imagen, así como varias instancias de la misma categoría. En el proceso de trabajar en esta muestra, los artículos de origen y los tutoriales en video sobre el reconocimiento de objetos personalizados resultaron ser más convenientes (los enlaces estarán al final).
Pero el trabajo no podría haberse completado sin un artículo sobre el reconocimiento de Pikachu , porque se señaló un matiz muy importante, que por alguna razón no se menciona en ninguna parte de una guía o ejemplo. Y sin eso, todo el trabajo realizado sería en vano.
Entonces, ahora finalmente sobre lo que aún tenía que hacerse y lo que sucedió al salir.
- Primero, la harina de la instalación Tensorflow. Quién no puede instalarlo o usar los scripts estándar para crear y entrenar un modelo, solo sea paciente y google. Casi todos los problemas ya se han escrito en problemas en githib o en stackoverflow.
De acuerdo con las instrucciones para el reconocimiento de objetos, necesitamos preparar una muestra de entrada antes de entrenar el modelo. Estos artículos describen en detalle cómo hacerlo utilizando una herramienta conveniente: labelImg. La única dificultad aquí es hacer un trabajo muy largo y meticuloso para resaltar los límites de los objetos que necesitamos. En este caso, sellos en imágenes de documentos.
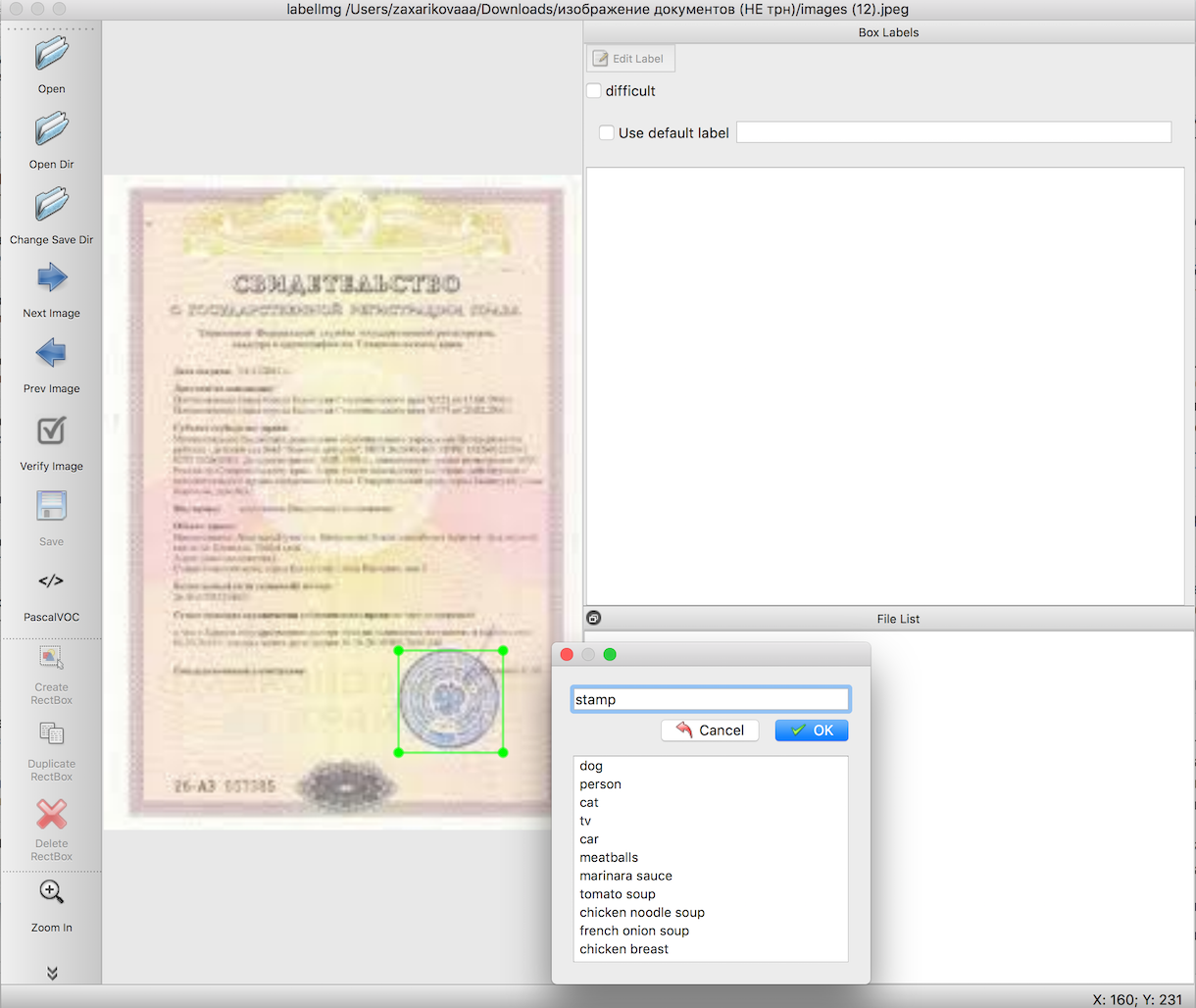
El siguiente paso, utilizando secuencias de comandos listas para usar, exportamos los datos del paso 2 primero a archivos csv, luego a TFRecords, el formato de datos de entrada de Tensorflow. No deben surgir dificultades aquí.
La elección de un modelo pre-entrenado, en base al cual pre-entrenaremos el gráfico, así como el entrenamiento en sí. Aquí es donde puede ocurrir la mayor cantidad de errores desconocidos, cuya causa es la desinstalación (o instalación torcida) de paquetes necesarios para el trabajo. Pero tendrá éxito, no se desespere, el resultado lo vale.

Exporte el archivo recibido después del entrenamiento al formato 'pb'. Simplemente seleccione el último archivo 'ckpt' y expórtelo.
Ejecutando un ejemplo de trabajo en Android.
Descargando la muestra oficial de reconocimiento de objetos del github de Tensorflow -
TF Detect . Inserte su modelo y archivo con etiquetas allí. Pero Nada funcionará

Aquí es donde ocurrió la mayor mordaza en todo el trabajo, por extraño que parezca, bueno, las muestras de Tensorflow no querían funcionar de ninguna manera. Todo ha caído. Solo el poderoso Pikachu con su artículo logró ayudar a que todo funcionara.
La primera línea en el archivo labels.txt debe ser la inscripción "???", porque de manera predeterminada en la API de detección de objetos, los números de identificación de los objetos no comienzan con 0 como de costumbre, sino con 1. Debido al hecho de que la clase nula está reservada, se deben indicar preguntas mágicas. Es decir su archivo de etiqueta se verá así:
??? stamp
Y luego, ejecute la muestra y vea el reconocimiento de los objetos y el nivel de confianza con el que se recibió.
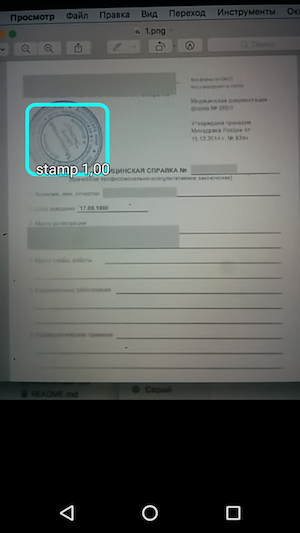
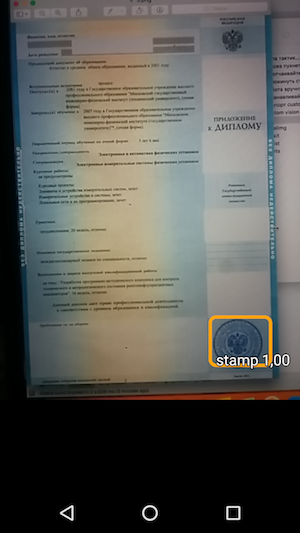
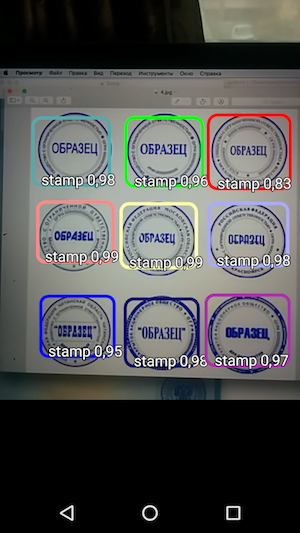
Por lo tanto, el resultado es una aplicación simple que, al pasar el mouse sobre la cámara, reconoce los límites del sello en el documento y los indica junto con la precisión del reconocimiento.
Y si excluimos el tiempo que se dedicó a buscar el enfoque correcto e intentar lanzarlo, entonces, en general, el trabajo resultó ser bastante rápido y realmente no complicado. Solo necesita conocer los matices antes de comenzar a trabajar.
Ya como una sección adicional (aquí ya puede cerrar el artículo si está cansado de la información), me gustaría escribir un par de trucos para la vida que ayudaron a trabajar con todo esto.
muy a menudo los scripts de tensorflow no funcionaban porque se ejecutaban desde los directorios incorrectos. Además, era diferente en diferentes PC: algunos necesitaban ejecutarse desde el tensroflowmodels/models/research para trabajar, y algunos necesitaban un nivel más profundo desde el tensroflowmodels/models/research/object-detection
recuerde que para cada terminal abierto necesita exportar la ruta nuevamente usando el comando
export PYTHONPATH=/ /tensroflowmodels/models/research/slim:$PYTHONPATH
si no está utilizando su propio gráfico y desea obtener información al respecto (por ejemplo, " input_node_name ", que se requiere más adelante), ejecute dos comandos desde la carpeta raíz:
bazel build tensorflow/tools/graph_transforms:summarize_graph bazel-bin/tensorflow/tools/graph_transforms/summarize_graph --in_graph="/ /frozen_inference_graph.pb"
donde " / /frozen_inference_graph.pb " es la ruta al gráfico que desea conocer
Para ver información sobre el gráfico, puede usar Tensorboard.
python import_pb_to_tensorboard.py --model_dir=output/frozen_inference_graph.pb --log_dir=training
donde necesita especificar la ruta al gráfico ( model_dir ) y la ruta a los archivos que se recibieron durante el entrenamiento ( log_dir ). Luego, solo abre localhost en el navegador y mira lo que te interesa.
Y la última parte, sobre cómo trabajar con scripts de Python en las instrucciones de la API de detección de objetos, ha preparado una pequeña hoja de trucos a continuación con comandos y sugerencias.
Hoja de trucosExportar desde labelimg a csv (desde el directorio object_detection)
python xml_to_csv.py
Además, todos los pasos enumerados a continuación deben realizarse desde la misma carpeta de Tensorflow (" tensroflowmodels/models/research/object-detection " o un nivel superior, dependiendo de cómo vaya), es decir, todos las imágenes de la selección de entrada, TFRecords y otros archivos deben copiarse dentro de este directorio antes de comenzar a trabajar.
Exportar desde csv a tfrecord
python generate_tfrecord.py --csv_input=data/train_labels.csv --output_path=data/train.record python generate_tfrecord.py --csv_input=data/test_labels.csv --output_path=data/test.record
* No olvide cambiar las líneas 'train' y 'test' en las rutas del archivo (generate_tfrecord.py), así como
el nombre de las clases reconocidas en la función class_text_to_int (que debe duplicarse en el archivo pbtxt que creará antes de entrenar el gráfico).
Entrenamiento
python legacy/train.py —logtostderr --train_dir=training/ --pipeline_config_path=training/ssd_mobilenet_v1_coco.config
** Antes de entrenar, no olvide verificar el archivo " training/object-detection.pbtxt training/ssd_mobilenet_v1_coco.config " - debe haber todas las clases reconocidas y el archivo " training/ssd_mobilenet_v1_coco.config " - allí debe cambiar el parámetro " num_classes " al número de sus clases.
Exportar modelo a pb
python export_inference_graph.py \ --input_type=image_tensor \ --pipeline_config_path=training/pipeline.config \ --trained_checkpoint_prefix=training/model.ckpt-110 \ --output_directory=output
¡Gracias por su interés en este tema!
Referencias
- Artículo original sobre reconocimiento de objetos.
- Un ciclo de video del artículo sobre el reconocimiento de objetos en inglés
- El conjunto de scripts que se utilizaron en el artículo original.