Trabajo como desarrollador en
hh.ru , y quiero ir a las líneas de datos, pero hasta ahora no hay suficientes habilidades. Por lo tanto, en mi tiempo libre, estudio el aprendizaje automático y trato de resolver problemas prácticos de esta área. Recientemente, me lanzaron la tarea de agrupar nuestros currículums. La publicación tratará sobre cómo lo resolví usando el agrupamiento jerárquico aglomerativo. Si no desea leer, pero el resultado es interesante, puede ver la
demostración de inmediato.

Antecedentes
El mercado laboral está en constante dinámica, están surgiendo nuevas profesiones, otras están desapareciendo y quiero tener una categorización relevante de currículums. El catálogo de áreas profesionales y especializaciones en hh.ru ha quedado obsoleto desde hace mucho tiempo: muchas cosas están vinculadas a él, por lo que no se han realizado cambios durante mucho tiempo. Sería útil aprender a editar sin dolor estas categorías. Estoy tratando de identificar automáticamente estas categorías. Espero que en el futuro esto ayude a resolver el problema.
Sobre el enfoque elegido y sobre la agrupación
Al agrupar comprenderé la combinación de objetos con las características más similares en un grupo. En mi caso, debajo del objeto se considera un currículum vitae, y bajo los signos del objeto están los datos resumidos: por ejemplo, la frecuencia de la palabra "gerente" en el currículum o el monto del salario. La similitud de los objetos está determinada por una métrica preseleccionada. Por ahora, puede considerarlo como un cuadro negro que recibe dos objetos en la entrada, y la salida produce un número que refleja, por ejemplo, la distancia entre objetos en el espacio vectorial: cuanto menor es la distancia, más similares son los objetos.
El enfoque que utilicé puede llamarse agrupación jerárquica aglomerativa ascendente. El resultado de la agrupación es un árbol binario, donde en las hojas hay elementos individuales, y la raíz del árbol es una colección de todos los elementos. Se llama ascendente porque la agrupación comienza en el nivel más bajo del árbol, con hojas, donde cada elemento individual se considera como un grupo.

Luego necesita encontrar los dos grupos más cercanos y fusionarlos en un nuevo grupo. Este procedimiento debe repetirse hasta que solo haya un clúster con todos los objetos dentro. Cuando se combinan grupos, se registra la distancia entre ellos. En el futuro, estas distancias se pueden usar para determinar el lugar donde estas distancias son lo suficientemente grandes como para considerar los grupos seleccionados como separados.
La mayoría de los métodos de agrupación suponen que se conoce de antemano el número de agrupaciones, o intentan aislar agrupaciones de forma independiente, dependiendo del algoritmo y los parámetros de este algoritmo. La ventaja de la agrupación jerárquica es que puede intentar determinar el número requerido de agrupaciones examinando las propiedades del árbol resultante, por ejemplo, seleccione subárboles en diferentes grupos cuyas distancias son bastante grandes. Es conveniente trabajar con la estructura resultante para buscar grupos en ella. Convenientemente, dicha estructura se construye una vez y no necesita ser reconstruida cuando se busca el número requerido de clústeres.
Entre las deficiencias, mencionaría que el algoritmo es bastante exigente con la memoria consumida. Y en lugar de asignar una clase específica, me gustaría tener la probabilidad de que el currículum pertenece a la clase para mirar no a la especialidad más cercana, sino a la totalidad.
Recopilación y preparación de datos.
La parte más importante al trabajar con datos es su preparación, selección y recuperación de atributos. Se basa en qué signos darán lugar al final, dependerá de si hay patrones en ellos, si estos patrones corresponden al resultado esperado y si este "resultado esperado" es posible. Antes de alimentar los datos a algún tipo de algoritmo de aprendizaje automático, debe tener una idea de cada signo, si hay huecos, a qué tipo pertenece el signo, qué propiedades tiene este tipo de signo y cuál es la distribución de valores en este signo. También es muy importante elegir el algoritmo correcto con el que se procesarán los datos disponibles.
Tomé hojas de vida que se actualizaron en los últimos seis meses. Resultó 2.7 millones. De los datos en el currículum vitae, elegí los signos más simples, de los cuales, según me pareció, la membresía del currículum debería depender de uno u otro grupo. Mirando hacia el futuro, diré que el resultado de agrupar todos los currículums a la vez no me satisfizo. Por lo tanto, primero tuvimos que dividir el currículum por las 28 áreas profesionales existentes.
Para cada característica, tracé la distribución para tener una idea de cómo se veían los datos. Quizás de alguna manera deberían ser convertidos o completamente abandonados.
Región Para que los valores de esta característica se puedan comparar entre sí, asigné el número total de currículums que pertenecen a esta región a cada región y tomé el logaritmo de este número para suavizar la diferencia entre ciudades muy grandes y pequeñas.
Paul Convertido a un signo binario.
Fecha de nacimiento . Contados en el número de meses. No todos tienen un cumpleaños. Completé los vacíos con los valores promedio de la edad de la especialización a la que pertenece este currículum.
Nivel de educación . Este es un signo categórico. Lo codifiqué con un
LabelBinarizer .
El nombre de la línea de pedido . Conduje a través de
TfidfVectorizer con ngram_range = (1,2), utilicé un
stemmer .
Salario Tradujo todos los valores en rublos. Completé los vacíos de la misma manera que en mi edad. Tomó el logaritmo del valor.
Horario de trabajo . LabelBinarizer codificado.
Tasa de empleo . Lo hice binario, dividiéndolo en dos partes: tiempo completo y todo lo demás.
Dominio del idioma . Elegí el top más usado. Cada idioma se configura como una característica separada. Los niveles de propiedad se corresponden con números del 0 al 5.
Habilidades clave Conduje a través de TfidfVectorizer. Como palabra final, armé un pequeño diccionario de habilidades generales y palabras que, como me pareció, no afectan la especialidad. Todas las palabras se pasan por la raíz. Cada habilidad clave puede consistir no solo en una palabra, sino también en varias. En el caso de varias palabras en la habilidad clave, clasifiqué las palabras y también usé cada palabra como un atributo separado. Esta característica solo funcionó bien en el campo profesional "Tecnologías de la información, Internet, Telecom", porque las personas a menudo indican habilidades relevantes para su especialidad. En otras áreas profesionales, no lo usé debido a la abundancia en las habilidades de las palabras generales.
Especializaciones Establezco cada una de las especializaciones especificadas por el usuario como un atributo binario.
Experiencia laboral Tomó el logaritmo de la cantidad de meses + 1, porque hay personas sin experiencia laboral.
Estandarización
Como resultado, cada currículum comenzó a ser un vector de signos numéricos. El algoritmo de agrupamiento seleccionado se basa en el cálculo de la distancia entre objetos. ¿Cómo determinar cómo cada característica debe contribuir a esta distancia? Por ejemplo, hay un signo binario: 0 y 1, y otro signo puede tomar muchos valores de 0 a 1000.
La estandarización viene al rescate. Usé
StandardScaler . Transforma cada rasgo de tal manera que su valor promedio es cero y la desviación estándar de la media es uno. Por lo tanto, estamos tratando de llevar todos los datos a la misma distribución, la normal estándar. Por supuesto, está lejos de ser un hecho que los datos mismos tengan la naturaleza de una distribución normal. Esta es solo una de las razones para construir gráficos de la distribución de sus parámetros y alegrarse de que parezcan gaussianos.
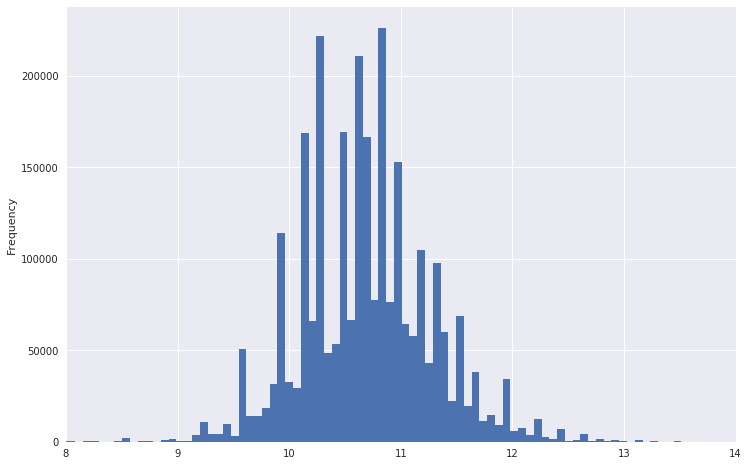
Entonces, por ejemplo, se veía un cuadro de distribución salarial.

Se puede ver que tiene una cola muy pesada. Para que la distribución sea más normal, puede tomar el logaritmo de estos datos. Al mismo tiempo, las emisiones no serán tan fuertes.
Degradar
Ahora tiene sentido transferir los datos a un espacio de menor dimensión, de modo que en el futuro el algoritmo de agrupamiento pueda digerirlos en un tiempo y memoria aceptables. Utilicé
TruncatedSVD ,
porque sabe cómo trabajar con matrices dispersas y en la salida proporciona la matriz densa habitual, que necesitaremos para trabajar más. Por cierto, TruncatedSVD también necesita enviar datos estandarizados.
En la misma etapa, vale la pena intentar visualizar el conjunto de datos resultante, traduciéndolo en un espacio bidimensional usando
t-SNE . Este es un paso muy importante. Si no se ve ninguna estructura en la imagen resultante o, por el contrario, esta estructura se ve muy extraña, entonces sus datos no tienen la regularidad necesaria o se ha cometido un error en alguna parte.
Obtuve muchas imágenes muy sospechosas antes de que todo saliera bien. Por ejemplo, una vez que había una imagen tan hermosa:

La razón de los gusanos resultantes fue obtener identificadores de currículum en el conjunto de datos. Y aquí hay algo más similar a la verdad:

Agrupación
Si todo parece estar en orden con los datos, puede comenzar a agrupar.
Usé el paquete de
agrupación jerárquica de SciPy. Permite la agrupación mediante el
método de vinculación . Probé todas las métricas de distancia de clúster sugeridas en el algoritmo. El mejor resultado fue dado por
el método Ward .
El principal problema que encontré es que el algoritmo de agrupamiento calcula la matriz de distancia entre todos los elementos, lo que significa una dependencia de memoria cuadrática del número de elementos. Por 2.7 millones de currículums, no tuve éxito, porque La cantidad de memoria requerida es de terabytes. Todos los cálculos se realizaron en una computadora normal. No tengo tanta RAM. Por lo tanto, me pareció razonable que primero pueda combinar los currículums que están cerca, tomar los centros de los grupos resultantes y agruparlos con el algoritmo deseado. Tomé
MiniBatchKMeans ,
formé 30,000 grupos con él y los envié a grupos jerárquicos. Funcionó, pero el resultado fue regular. Se destacaron muchos de los grupos de currículums más llamativos, pero los detalles no son suficientes para encontrar especializaciones a un buen nivel.
Para mejorar la calidad de las especializaciones obtenidas, dividí los datos en campos profesionales. Resultó conjuntos de datos de 400 000 currículums y menos. En ese momento, se me ocurrió que agrupar una muestra de datos es mejor que usar dos algoritmos seguidos. Así que renuncié a MiniBatchKMeans y tomé hasta 100,000 currículums para cada especialización para que el método de vinculación pudiera digerirlos. 32 Gb de RAM no fueron suficientes, así que asigné 100 Gb adicionales para el intercambio. Como resultado, el enlace proporciona una matriz con las distancias entre los grupos combinados en cada paso y el número de elementos en el grupo resultante.
Como medida de control de calidad para comparar diferentes versiones de conjuntos de datos y diferentes métodos para calcular la distancia entre grupos, el algoritmo utilizó el coeficiente de correlación cophenetic obtenido de
cophenet . Este coeficiente muestra qué tan bien el dendrograma resultante refleja la disimilitud de los objetos entre sí. Cuanto más cercano sea el valor a la unidad, mejor.
Visualización
La mejor manera de validar la calidad de la agrupación fue la visualización. El método de
dendrograma dibuja los dendrogramas resultantes en los que puede seleccionar grupos por distancia o por nivel en el árbol:

El siguiente gráfico muestra la dependencia de la distancia entre grupos en el número de paso de iteración, en el que los dos grupos más cercanos se combinan en uno nuevo. La línea verde muestra cómo cambia la aceleración: la velocidad de la distancia entre los grupos que se unen.
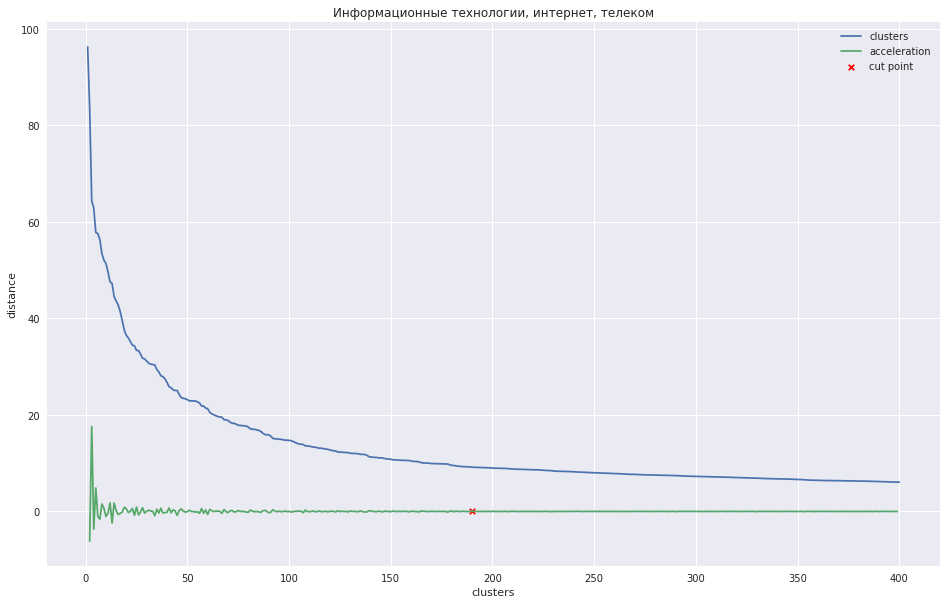
En el caso de un pequeño número de grupos, uno podría intentar podar el árbol en el punto donde la aceleración máxima, es decir, la distancia en ese momento cuando se combinaron los dos grupos fue aún mayor, y ya más pequeña en el siguiente paso. En mi caso, todo es diferente: tengo muchos grupos, y sugerí que es mejor cortar el dendrograma en el punto donde la aceleración comienza a disminuir de manera más monótona, es decir, las distancias entre los grupos en este nivel ya no indican un grupo separado. En el gráfico, este lugar está aproximadamente en el punto donde la línea verde deja de bailar.
Se podría llegar a algún tipo de método programático, pero resultó más rápido marcar estos lugares con 28 manos para 28 dominios profesionales y
pasar el número deseado de grupos al método de
agrupación , que cortará el árbol en el lugar correcto.
Guardé los datos obtenidos anteriormente de t-SNE y noté los grupos resultantes en ellos. Se ve bastante bien:

Como resultado, creé una interfaz web donde puede ver el resumen de cada grupo, su posición en el gráfico y dar un nombre significativo. Por conveniencia, deduje el título más común del currículum: a menudo caracteriza bien el nombre del clúster.
Puede ver el resultado de la agrupación
aquí .
Llegué a la conclusión de que el sistema estaba funcionando. Aunque el desglose en grupos es imperfecto y algunos grupos son muy similares entre sí, algunos podrían, por el contrario, dividirse en partes, pero las principales tendencias del mercado de especialidades son claramente visibles. También puede ver cómo se forman los nuevos grupos. La descarga del currículum se realizó en verano, por lo que los
conductores, que querían trabajar en la Copa del Mundo , se destacaron, por ejemplo. Si aprende a unir grupos entre sí de un lanzamiento a otro, puede observar cómo cambian las áreas principales de especialización con el tiempo. De hecho, las ideas para mejorar la calidad y el desarrollo aún están llenas. Si puedo encontrar la motivación correcta en mí mismo, me desarrollaré más.
Materiales adicionales
Video sobre agrupación jerárquica aglomerativa del curso sobre la búsqueda de una estructura en datos
Sobre la escala y la normalización de los signosTutorial sobre agrupamiento jerárquico de la biblioteca SciPy, que tomé como base para mi tarea
Comparación de diferentes tipos de clustering usando las bibliotecas sklearn como ejemplo
Poca bonificación. Pensé que es interesante para las personas cómo alguien trabaja en una tarea. Quiero decir que en algunos problemas bombeé bien mientras hacía este proyecto. Probé varias opciones, estudié, reflexioné sobre cómo funciona esto o aquello. En muchos lugares, la falta de una buena base matemática fue compensada por el ingenio y una gran cantidad de intentos. Y me gustaría compartir la
hoja de evernote sufrida en la que tomé notas mientras trabajaba en la tarea. Las reflexiones en él fueron solo para mí, hay muchas herejías e incomprensiones, pero creo que eso es normal.
UPD: publiqué computadoras portátiles con
preparación de datos y código de
agrupación . No tenía pensado subir el código, lo siento por la calidad.