
Con las pruebas para el código, todo está claro (bueno, al menos el hecho de que deben escribirse). Con las pruebas de configuración, todo es mucho menos obvio, comenzando con su propia existencia. ¿Alguien los escribe? ¿Es importante? ¿Es dificil? ¿Qué tipo de resultados se pueden lograr con su ayuda?
Resulta que esto también es muy útil, comenzar a hacerlo es muy simple, y al mismo tiempo hay muchos matices en la prueba de la configuración. Cuáles: pintadas debajo del corte según la experiencia práctica.
El material se basa en una transcripción de un informe de Ruslan cheremin Cheremin (desarrollador de Java en Deutsche Bank). El siguiente es el discurso en primera persona.Mi nombre es Ruslan, trabajo para Deutsche Bank. Comenzamos con esto:

Hay mucho texto, desde lejos puede parecer que es ruso. Pero esto no es cierto. Este es un lenguaje muy antiguo y peligroso. Hice una traducción al ruso simple:
- Todos los personajes están compuestos
- Usar con precaución
- Funeral a su cargo
Describiré brevemente de qué voy a hablar hoy. Supongamos que tenemos un código:

Es decir, inicialmente teníamos algún tipo de tarea, escribimos un código para resolverlo y supuestamente nos genera dinero. Si por alguna razón este código no funciona correctamente, resuelve la tarea incorrecta y nos genera el dinero equivocado. A las empresas no les gusta ese tipo de dinero: se ven mal en los estados financieros.
Por lo tanto, para nuestro código importante, tenemos pruebas:

Por lo general allí. Ahora, probablemente, casi todos lo tienen. Las pruebas verifican que el código resuelve el problema correcto y genera el dinero correcto. Pero el servicio no se limita al código, y al lado del código también hay una configuración:

Al menos en casi todos los proyectos en los que participé, esta configuración fue, de una forma u otra. (Solo puedo recordar un par de casos de mis primeros años en la interfaz de usuario, donde no había archivos de configuración, pero todo estaba configurado a través de la interfaz de usuario) En esta configuración, hay puertos, direcciones y parámetros de algoritmo.
¿Por qué es importante probar la configuración?
Aquí está el truco: los errores en la configuración dañan la ejecución del programa no menos que los errores en el código. Ellos también pueden hacer que el código realice la tarea incorrecta, y vea más arriba.
Y encontrar errores en la configuración es aún más difícil que en el código, ya que la configuración generalmente no se compila. Cité los archivos de propiedades como ejemplo, en general hay diferentes opciones (JSON, XML, alguien almacena en YAML), pero es importante que nada de esto se compile y, en consecuencia, no esté marcado. Si se sella accidentalmente en un archivo Java, lo más probable es que simplemente no pase la compilación. Un error tipográfico aleatorio en la propiedad no entusiasmará a nadie, irá a trabajar.
Y el IDE tampoco resalta el error en la configuración, porque solo conoce lo más primitivo sobre el formato (por ejemplo) de los archivos de propiedades: que debe haber una clave y un valor, y "igual", dos puntos o un espacio entre ellos. Pero el hecho de que el valor debe ser un número, un puerto de red o una dirección, el IDE no sabe nada.
E incluso si prueba la aplicación en un UAT o en un entorno de ensayo, esto tampoco garantiza nada. Debido a que la configuración, como regla, en cada entorno es diferente, y en la UAT solo probó la configuración de UAT.
Otra sutileza es que incluso en la producción, los errores de configuración a veces no aparecen de inmediato. Es posible que un servicio no se inicie en absoluto, y este es un buen escenario. Pero puede comenzar y funcionar durante mucho tiempo, hasta el momento X, cuando será necesario exactamente el parámetro en el que se produjo el error. Y aquí encontrará que un servicio que ni siquiera ha cambiado mucho recientemente ha dejado de funcionar repentinamente.
Después de todo lo que dije, parece que probar las configuraciones debería ser un tema candente. Pero en la práctica se parece a esto:
Al menos ese fue el caso con nosotros, hasta cierto punto. Y una de las tareas de mi informe es dejar de verte así también. Espero poder empujarte a esto.
Hace tres años en nuestro Deutsche Bank, en mi equipo, Andrei Satarin trabajó como líder de control de calidad. Fue él quien trajo la idea de probar configuraciones, es decir, simplemente tomó y cometió la primera prueba de este tipo. Hace seis meses, en el Heisenbug anterior, dio una
charla sobre probar la configuración tal como la ve. Le recomiendo que mire, porque allí dio una mirada amplia al problema: tanto desde el lado de los artículos científicos como desde la experiencia de las grandes empresas que han encontrado errores de configuración y sus consecuencias.
Mi informe será más limitado: sobre la experiencia práctica. Hablaré sobre qué problemas, como desarrollador, encontré cuando escribí las pruebas de configuración, y cómo resolví estos problemas. Mis decisiones pueden no ser las mejores decisiones, estas no son las mejores prácticas: esta es mi experiencia personal, intenté no hacer generalizaciones amplias.
Esquema general del informe:
- "Lo que puede hacer antes del lunes por la tarde": ejemplos simples y útiles.
- "Lunes, dos años después": dónde y cómo hacerlo mejor.
- Soporte para refactorizar la configuración: cómo lograr una cobertura densa; modelo de configuración de software.
La primera parte es motivadora: describiré las pruebas más simples con las que todo comenzó con nosotros. Habrá una gran variedad de ejemplos. Espero que al menos uno de ellos resuene contigo, es decir, verás algún tipo de problema similar y su solución.
Las pruebas en sí mismas en la primera parte son simples, incluso primitivas: desde el punto de vista de la ingeniería no hay ciencia espacial. Pero solo que se puedan hacer rápidamente es especialmente valioso. Esta es una "entrada fácil" en las pruebas de configuración, y es importante porque existe una barrera psicológica para escribir estas pruebas. Y quiero mostrar que "usted puede hacer esto": ahora lo hicimos, funcionó bien para nosotros, y aunque nadie ha muerto, hemos estado viviendo durante tres años.
La segunda parte es sobre qué hacer después. Cuando escribiste muchas pruebas simples, surge la cuestión del soporte. Algunos de ellos comienzan a caer, entiendes los errores que supuestamente resaltaron. Resulta que esto no siempre es conveniente. Y surge la pregunta de escribir pruebas más complejas: después de todo, ya ha cubierto casos simples, quiero algo más interesante. Y aquí nuevamente no hay mejores prácticas, solo describiré algunas de las soluciones que funcionaron para nosotros.
La tercera parte trata sobre cómo las pruebas pueden soportar la refactorización de una configuración bastante compleja y confusa. De nuevo estudio de caso: cómo lo hicimos. Desde mi punto de vista, este es un ejemplo de cómo las pruebas de configuración se pueden escalar para resolver tareas más grandes, y no solo para tapar pequeños agujeros.
Parte 1. "Puedes hacerlo así"
Ahora es difícil entender cuál fue la primera prueba de configuración con nosotros. Andrei está sentado en el pasillo, puede decir que mentí. Pero me parece que todo comenzó con esto:

La situación es esta: tenemos n servicios en el mismo host, cada uno de ellos levanta su propio servidor JMX en su puerto, exporta algunos JMX de monitoreo. Los puertos para todos los servicios se configuran en el archivo. Pero el archivo ocupa varias páginas y hay muchas otras propiedades: a menudo resulta que los puertos de diferentes servicios entran en conflicto. Es fácil cometer un error. Entonces, todo es trivial: algunos servicios no aumentan, después de eso no aumentan para quienes dependen de ellos; los evaluadores están furiosos.
Este problema se resuelve en varias líneas. Esta prueba, que (me parece) fue la primera, se veía así:

No es nada complicado: vamos a través de la carpeta donde se encuentran los archivos de configuración, los cargamos, los analizamos como propiedades, filtramos los valores cuyo nombre contiene "jmx.port" y verificamos que todos los valores sean únicos. No hay necesidad de convertir valores a enteros. Presumiblemente, solo hay puertos.
Mi primera reacción cuando vi esto fue mixta:
Primera impresión: ¿qué hay en mis hermosas pruebas unitarias? ¿Por qué subimos al sistema de archivos?
Y entonces llegó la sorpresa: "¿Qué, podría ser eso?"
Estoy hablando de esto porque parece haber algún tipo de barrera psicológica que hace que sea difícil escribir tales pruebas. Han pasado tres años desde entonces, el proyecto está lleno de tales pruebas, pero a menudo veo que mis colegas, que se topan con un error cometido en la configuración, no escriben pruebas en él. Para el código, todos ya están acostumbrados a escribir pruebas de regresión, por lo que el error encontrado ya no se reproduce. Pero no lo hacen por configuración, algo está interfiriendo. Hay algún tipo de barrera psicológica que debe abordarse; es por eso que menciono tal reacción para que la reconozca usted mismo si aparece.
El siguiente ejemplo es casi el mismo, pero ligeramente modificado: eliminé todos los "jmx". Esta vez verificamos todas las propiedades llamadas algo allí puerto. Deben ser valores enteros y ser un puerto de red válido. Matcher validNetworkPort () oculta nuestro Hamcrest personalizado Matcher, que verifica que el valor esté por encima del rango de puertos del sistema, por debajo del rango de puertos efímeros, bueno, sabemos que algunos puertos en nuestros servidores están ocupados previamente; aquí está la lista completa de ellos oculta en este es matcher
Esta prueba sigue siendo muy primitiva. Tenga en cuenta que no hay ninguna indicación en él de qué propiedad específica estamos verificando: es masiva. Una sola de estas pruebas puede verificar 500 propiedades con el nombre "... puerto", y verificar que todos ellos sean enteros en el rango deseado, con todas las condiciones necesarias. Una vez que escribieron, una docena de líneas, y eso es todo. Esta es una característica muy conveniente, parece porque la configuración tiene un formato simple: dos columnas, una clave y un valor. Por lo tanto, puede ser tan procesado en masa.
Otro ejemplo de prueba. ¿Qué estamos comprobando aquí?

Comprueba que las contraseñas reales no se filtren en la producción. Todas las contraseñas deberían verse así:

Puede escribir muchas pruebas para archivos de propiedades. No daré más ejemplos: no quiero repetirme, la idea es muy simple, entonces todo debería estar claro.
... y después de escribir suficientes de estas pruebas, surge una pregunta interesante: ¿qué queremos decir con configuración, dónde está su borde? Consideramos el archivo de propiedades como una configuración, lo cubrimos, ¿y qué más se puede cubrir con el mismo estilo?
Qué considerar una configuración
Resulta que hay muchos archivos de texto en el proyecto que no se compilan, al menos en el proceso de compilación normal. No se verifican de ninguna manera hasta que se ejecutan en el servidor, es decir, los errores en ellos aparecen tarde. Todos estos archivos, con cierta extensión, se pueden llamar configuración. Al menos, se probarán aproximadamente lo mismo.
Por ejemplo, tenemos un sistema de parches SQL que se incluyen en la base de datos durante el proceso de implementación.

Están escritos para SQL * Plus. SQL * Plus es una herramienta de los años 60 y requiere todo tipo de cosas extrañas: por ejemplo, para asegurarse de que el final del archivo esté en una nueva línea. Por supuesto, las personas regularmente olvidan poner el final de la línea allí, porque no nacieron en los años 60.
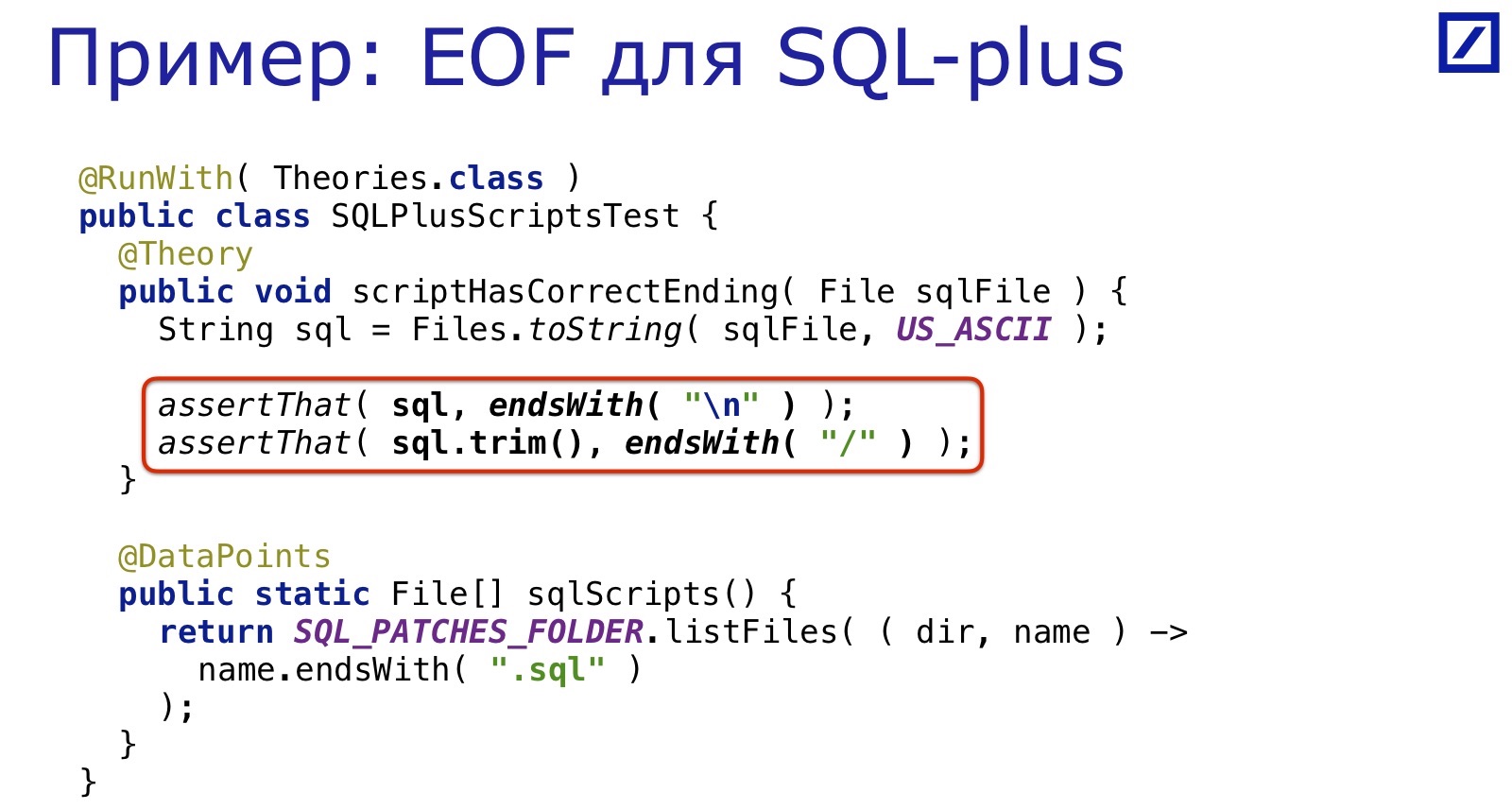
Y nuevamente se resuelve con la misma docena de líneas: seleccionamos todos los archivos SQL, verificamos que haya una barra diagonal al final. Simple, conveniente, rápido.
Otro ejemplo de "como un archivo de texto" es crontabs. Nuestros servicios crontab comienzan y se detienen. Con mayor frecuencia causan dos errores:
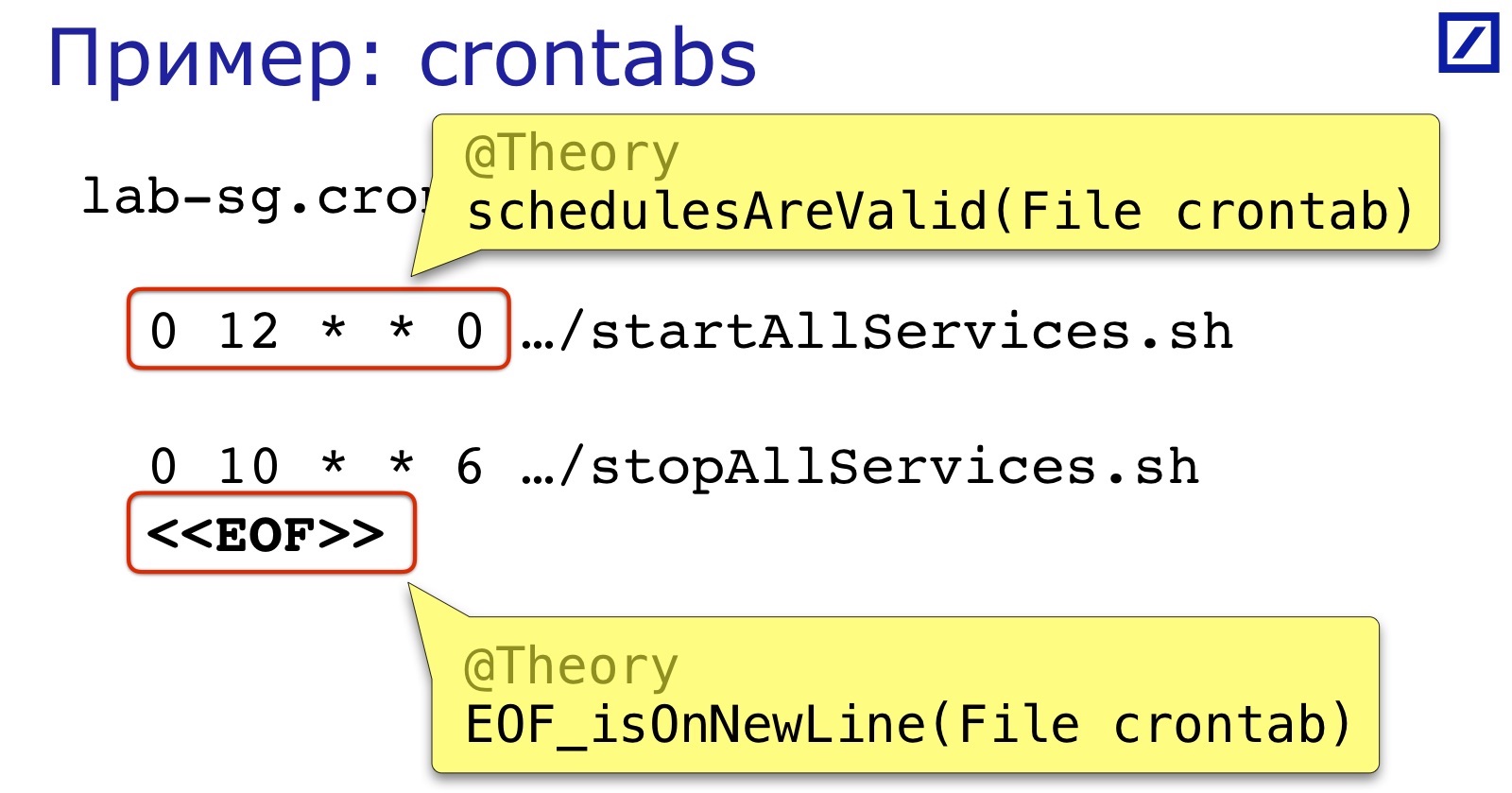
En primer lugar, el formato de expresión de programación. No es tan complicado, pero nadie lo revisa antes del lanzamiento, por lo que es fácil poner un espacio extra, una coma y cosas similares.
En segundo lugar, como en el ejemplo anterior, el final del archivo también debe estar en una nueva línea.
Y todo esto es bastante fácil de verificar. El final del archivo es comprensible, pero para verificar la programación, puede encontrar bibliotecas listas para usar que analizan la expresión cron. Antes del informe, busqué en Google: había al menos seis de ellos. Encontré seis, pero en general puede haber más. Cuando escribimos, tomamos el más simple de los encontrados, porque no necesitábamos verificar el contenido de la expresión, sino solo su corrección sintáctica, de modo que cron la cargó con éxito.
En principio, puede liquidar más cheques: verifique que comience el día correcto de la semana, que no interrumpa los servicios en la mitad del día laboral. Pero esto resultó no ser tan útil para nosotros, y no nos molestamos.
Otra idea que funciona muy bien son los scripts de shell. Por supuesto, escribir en Java un analizador completo de secuencias de comandos bash es un placer para los valientes. Pero la conclusión es que una gran cantidad de estos scripts no son una fiesta completa. Sí, hay scripts de bash donde el código es directo, el infierno y el infierno, donde entran una vez al año y, jurando, huyen. Pero muchos scripts de bash tienen las mismas configuraciones. Hay una serie de variables del sistema y variables de entorno que se establecen en el valor deseado, configurando así otros scripts que usan estas variables. Y tales variables son fáciles de extraer de este archivo bash y verificar algo sobre ellas.

Por ejemplo, verifique que JAVA_HOME esté instalado en cada entorno, o que alguna biblioteca jni que usemos esté ubicada en LD_LIBRARY_PATH. De alguna manera, pasamos de una versión de Java a otra y ampliamos la prueba: verificamos que JAVA_HOME contiene "1.8" en ese mismo subconjunto de entorno, que gradualmente transferimos a la nueva versión.
Aquí hay algunos ejemplos. Permítanme resumir la primera parte de las conclusiones:
- Las pruebas de configuración son confusas al principio, hay una barrera psicológica. Pero después de superarlo, hay muchos lugares en la aplicación que no están cubiertos por cheques y pueden estar cubiertos.
- Luego se escriben fácil y alegremente : hay muchas "frutas bajas" que rápidamente brindan grandes beneficios).
- Reduzca el costo de detectar y corregir errores de configuración. Dado que estas son, de hecho, pruebas unitarias, puede ejecutarlas en su computadora, incluso antes de comprometerse, esto reduce en gran medida la retroalimentación. Muchos de ellos, por supuesto, habrían sido probados en la etapa de implementación de prueba, por ejemplo. Y muchos no serían probados, si esta es una configuración de producción. Y así se verifican directamente en la computadora local.
- Dan una segunda juventud. En el sentido de que existe la sensación de que todavía puedes probar muchas cosas interesantes. De hecho, en el código ya no es tan fácil encontrar lo que puede probar.
Parte 2. Casos más complejos
Pasemos a pruebas más complejas. Después de cubrir la mayoría de los controles triviales, como los que se muestran aquí, surge la pregunta: ¿es posible verificar algo más complicado?
¿Qué significa "más difícil"? Las pruebas que acabo de describir tienen aproximadamente la siguiente estructura:

Comprueban algo contra un archivo específico. Es decir, revisamos los archivos, aplicamos una cierta verificación de condición a cada uno. Por lo tanto, se puede verificar mucho, pero hay escenarios más útiles:
- La aplicación UI se conecta al servidor de su entorno.
- Todos los servicios del mismo entorno se conectan al mismo servidor de administración.
- Todos los servicios en el mismo entorno usan la misma base de datos.
Por ejemplo, una aplicación de IU se conecta a su servidor de entorno. Lo más probable es que la interfaz de usuario y el servidor sean módulos diferentes, si no proyectos, y tienen configuraciones diferentes, es poco probable que usen los mismos archivos de configuración. Por lo tanto, tendrá que vincularlos para que todos los servicios de un entorno estén conectados a un servidor de administración de claves a través del cual se distribuyen los comandos. Una vez más, lo más probable es que estos sean módulos diferentes, servicios diferentes y, en general, equipos diferentes los desarrollen.
O todos los servicios usan la misma base de datos, lo mismo: servicios en diferentes módulos.
De hecho, existe una imagen de este tipo: muchos servicios, cada uno de ellos tiene su propia estructura de configuraciones, debe reducir algunos de ellos y verificar algo en la intersección:

Por supuesto, puede hacer exactamente eso: cargar uno, el segundo, sacar algo en alguna parte, pegarlo en el código de prueba. Pero puedes imaginar qué tan grande será el código y qué tan legible será. Partimos de esto, pero luego nos dimos cuenta de lo difícil que es. ¿Cómo hacerlo mejor?
Si sueñas, sería más conveniente, entonces soñé que la prueba parecería que la explico en lenguaje humano:
@Theory public void eachEnvironmentIsXXX( Environment environment ) { for( Server server : environment.servers() ) { for( Service service : server.services() ) { Properties config = buildConfigFor( environment, server, service );
Para cada entorno, se cumple una condición. Para verificar esto, necesita del entorno encontrar una lista de servidores, una lista de servicios. Luego cargue las configuraciones y verifique algo en la intersección. En consecuencia, necesito tal cosa, lo llamé Diseño de implementación.
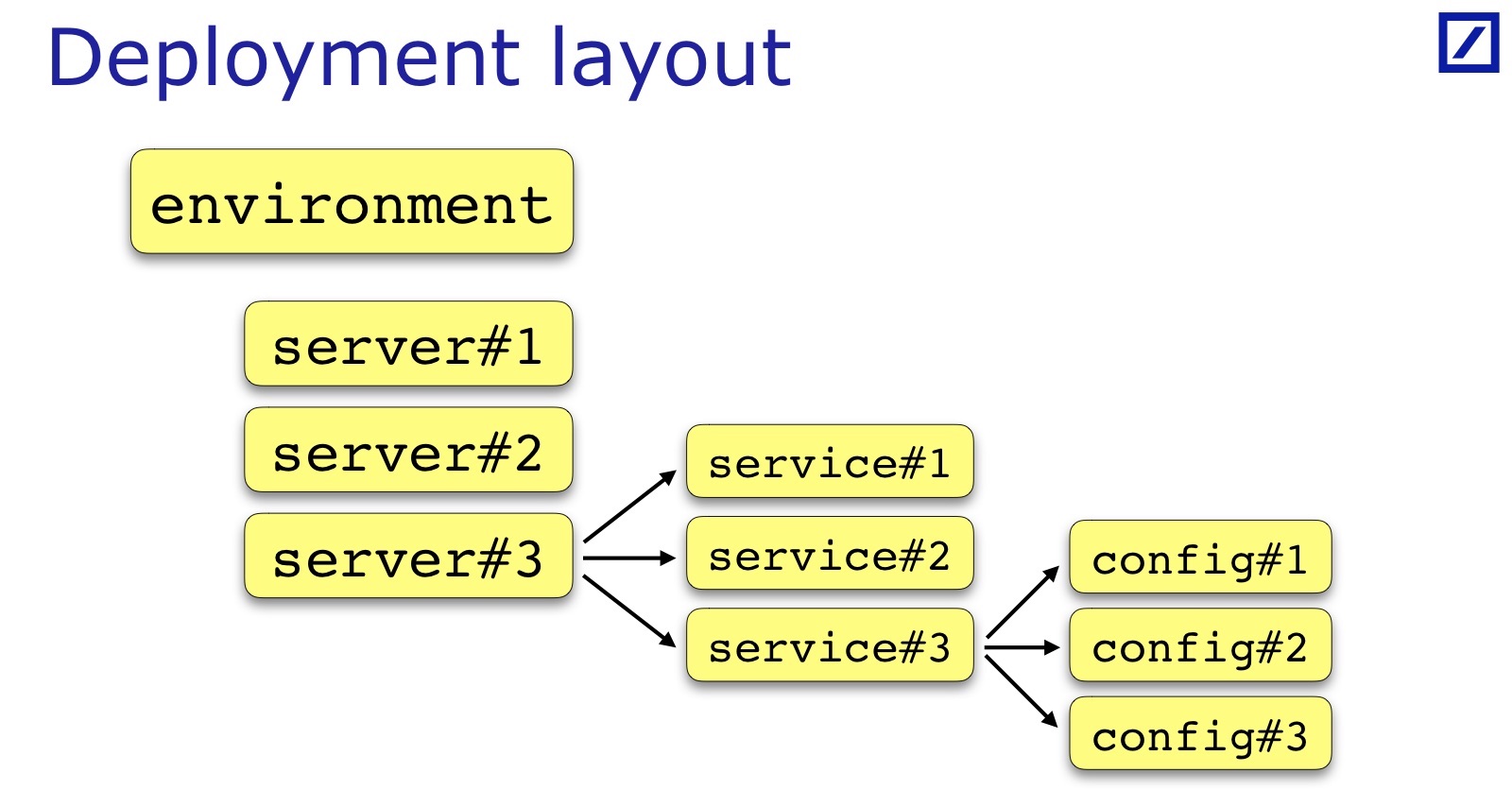
Necesitamos una oportunidad del código para obtener acceso a cómo se implementa la aplicación: en qué servidores se colocan los servicios, dentro de qué entorno, para obtener esta estructura de datos. Y a partir de ello, comienzo a cargar la configuración y procesarla.
El diseño de implementación es específico para cada equipo y cada proyecto. He dibujado: este es un caso general: generalmente hay un conjunto de servidores, servicios, un servicio a veces tiene un conjunto de archivos de configuración, y no solo uno. A veces se requieren parámetros adicionales que son útiles para las pruebas, deben agregarse. Por ejemplo, el bastidor en el que se encuentra el servidor puede ser importante. Andrey en su informe dio un ejemplo cuando era importante para sus servicios que los servicios de respaldo / primario deben estar en diferentes bastidores; para su caso, necesitaría mantener una referencia al bastidor en el diseño de implementación:
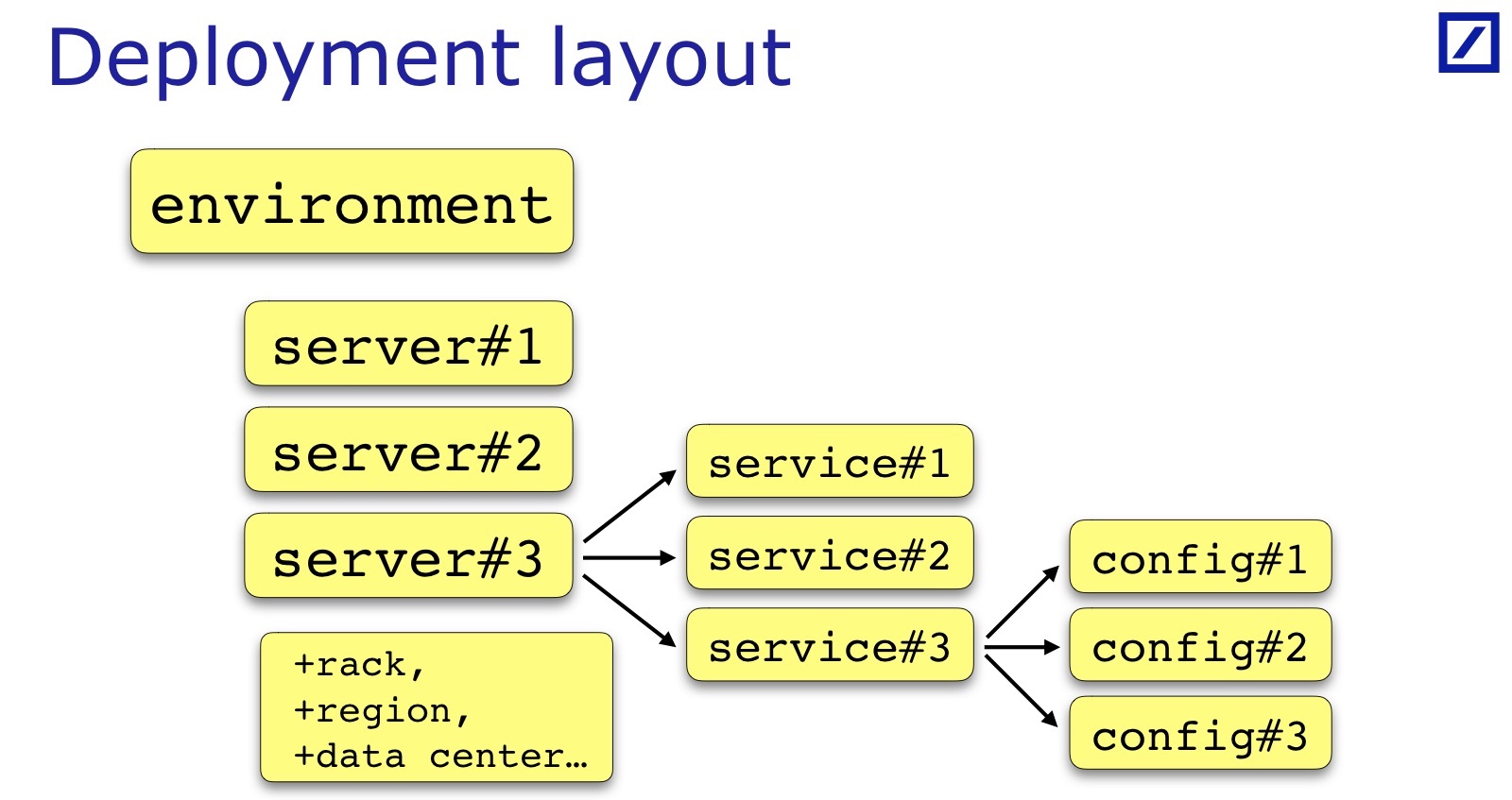
Para nuestros propósitos, la región del servidor es importante, el centro de datos específico, en principio, también, por lo que Backup / Primary está en diferentes centros de datos. Estas son todas las propiedades adicionales del servidor, son específicas del proyecto, pero en la diapositiva es un denominador tan común.
¿Dónde obtener el diseño de implementación? Parece que en cualquier gran empresa hay un sistema de Gestión de Infraestructura, todo se describe allí, es confiable, confiable y todo eso ... en realidad no.
Al menos, mi práctica en dos proyectos ha demostrado que es más fácil codificar primero y luego, después de tres años ... dejar la piel dura.
Llevamos tres años viviendo con este proyecto. Parece que en el segundo todavía nos integramos con la Gestión de Infraestructura en un año, pero todos estos años hemos vivido así. Según la experiencia, tiene sentido posponer la tarea de integración con IM para obtener pruebas listas lo antes posible, lo que demostrará que funcionan y son útiles. Y luego puede resultar que esta integración puede no ser tan necesaria, porque la distribución de servicios entre servidores no se cambia con tanta frecuencia.
El código duro puede ser literalmente así:
public enum Environment { PROD( PROD_UK_PRIMARY, PROD_UK_BACKUP, PROD_US_PRIMARY, PROD_US_BACKUP, PROD_SG_PRIMARY, PROD_SG_BACKUP ) … public Server[] servers() {…} } public enum Server { PROD_UK_PRIMARY(“rflx-ldn-1"), PROD_UK_BACKUP("rflx-ldn-2"), PROD_US_PRIMARY(“rflx-nyc-1"), PROD_US_BACKUP("rflx-nyc-2"), PROD_SG_PRIMARY(“rflx-sng-1"), PROD_SG_BACKUP("rflx-sng-2"), public Service[] services() {…} }
La forma más fácil que utilizamos en nuestro primer proyecto es enumerar Environment con una lista de servidores en cada uno de ellos. Hay una lista de servidores y, al parecer, debería haber una lista de servicios, pero engañamos: tenemos scripts de inicio (que también son parte de la configuración).

Ejecutan servicios para cada entorno. Y el método services () simplemente grep'a todos los servicios del archivo de su servidor. Esto se hace porque no hay tantos entornos, y los servidores también rara vez se agregan o eliminan, pero hay muchos servicios y se barajan con bastante frecuencia. Tenía sentido cargar el diseño real de los servicios desde los scripts para no cambiar el diseño codificado con demasiada frecuencia.
Después de crear dicho modelo de configuración de software, aparecen bonificaciones agradables. Por ejemplo, puede escribir una prueba como esta:

La prueba es que en cada entorno todos los servicios clave están presentes. Supongamos que hay cuatro servicios clave, y el resto puede o no existir, pero sin estos cuatro no tiene sentido. Puede verificar que no los haya olvidado en ninguna parte, que todos tengan copias de seguridad dentro del mismo entorno. En la mayoría de los casos, estos errores se producen al configurar la UAT de estas instancias, pero también puede filtrarse en PROD. Al final, los errores en la UAT también pierden tiempo y nervios de los evaluadores.
Se plantea la cuestión de mantener la relevancia del modelo de configuración. También puedes escribir una prueba para esto.
public class HardCodedLayoutConsistencyTest { @Theory eachHardCodedEnvironmentHasConfigFiles(Environment env){ … } @Theory eachConfigFileHasHardCodedEnvironment(File configFile){ … } }
Hay archivos de configuración y hay un diseño de implementación en el código. Y puede verificar eso para cada entorno / servidor / etc. hay un archivo de configuración correspondiente y, para cada archivo del formato requerido, el entorno correspondiente. Tan pronto como se olvide de agregar algo a un lugar, la prueba caerá.
La conclusión es el diseño de implementación:
- Simplifica la escritura de pruebas complejas que reúnen configuraciones de diferentes partes de la aplicación.
- Los hace más claros y más legibles. Se ven de la manera que piensas sobre ellos a un alto nivel, y no de la forma en que pasan por las configuraciones.
- Durante su creación, cuando las personas hacen preguntas, resultan muchas cosas interesantes sobre la implementación. Las limitaciones, el conocimiento sagrado implícito, surgen, por ejemplo, con respecto a la posibilidad de alojar dos entornos en un servidor. Resulta que los desarrolladores piensan de manera diferente y escriben sus servicios en consecuencia. Y esos momentos son útiles para establecerse entre los desarrolladores.
- Bien complementa la documentación (especialmente si no lo es). Incluso si lo hay, es más agradable para mí, como desarrollador, ver esto en el código. Además, allí puedes escribir comentarios importantes para mí y no para otra persona. Y también puedes codificar. Es decir, si decide que no puede haber dos entornos en el mismo servidor, puede insertar un cheque, y ahora no lo hará. Al menos sabrás si alguien lo intenta. Es decir, esta es documentación con la capacidad de hacerla cumplir. Esto es muy útil
Sigamos adelante. Después de que se escribieron las pruebas, se "asentaron" durante un año, algunas comienzan a caer. Algunos comienzan a caer antes, pero no da tanto miedo. Da miedo cuando cae una prueba escrita hace un año, miras su mensaje de error y no lo entiendes.

Supongamos que entiendo y acepto que este es un puerto de red no válido, pero ¿dónde está? Antes de la charla, analicé el hecho de que tenemos 1,200 archivos de propiedades en el proyecto, dispersos en más de 90 módulos, con un total de 24,000 líneas en ellos. (Aunque me sorprendió, pero si cuenta, entonces este no es un número tan grande, para un servicio para 4 archivos). ¿Dónde está este puerto?
Está claro que afirmar que () tiene un argumento de mensaje, puede ingresar algo que lo ayudará a identificar el lugar. Pero cuando escribes una prueba, no piensas en ello. E incluso si piensas, todavía tienes que adivinar qué descripción será lo suficientemente detallada como para ser entendida en un año. Me gustaría automatizar este momento, para que haya una forma de escribir pruebas con la generación automática de una descripción más o menos clara, mediante la cual pueda encontrar un error.
Nuevamente, soñé y soñé con algo como esto:
SELECT environment, server, component, configLocation, propertyName, propertyValue FROM configuration(environment, server, component) WHERE propertyName like “%.port%” and propertyValue is not validNetworkPort()
Este es un pseudo-SQL, bueno, solo conozco SQL, y el cerebro arrojó la solución de lo que es familiar. La idea es que la mayoría de las pruebas de configuración consisten en varias piezas del mismo tipo. Primero, la condición selecciona un subconjunto de parámetros:

Luego, con respecto a este subconjunto, verificamos algo con respecto al valor:

Y luego, si hubo propiedades cuyos valores no satisfacen el deseo, esta es la "hoja" que queremos recibir en el mensaje de error:

En un momento incluso pensé si podría escribir un analizador sintáctico como SQL, ya que ahora no es difícil. Pero luego me di cuenta de que el IDE no lo admitiría y lo sugeriría, por lo que las personas tendrían que escribir a ciegas en este "SQL" hecho a sí mismo, sin indicaciones del IDE, sin compilación, sin verificar, esto no es muy conveniente. Por lo tanto, tuve que buscar soluciones compatibles con nuestro lenguaje de programación. Si tuviéramos .NET, LINQ ayudaría, es casi como SQL.
No hay LINQ en Java, lo más cerca posible de las transmisiones. Así es como debería verse esta prueba en las transmisiones:
ValueWithContext[] incorrectPorts = flattenedProperties( environment ) .filter( propertyNameContains( ".port" ) ) .filter( !isInteger( propertyValue ) || !isValidNetworkPort( propertyValue ) ) .toArray(); assertThat( incorrectPorts, emptyArray() );
flattenedProperties () toma todas las configuraciones de este entorno, todos los archivos para todos los servidores, servicios y los expande a una tabla grande. Esta es esencialmente una tabla similar a SQL, pero en forma de un conjunto de objetos Java. Y flattenedProperties () devuelve este conjunto de cadenas como una secuencia.

Luego agrega algunas condiciones en este conjunto de objetos Java. En este ejemplo: seleccionamos aquellos que contienen "puerto" en el propertyName y filtramos aquellos donde los valores no se convierten a Integer, o no desde el rango válido. Estos son valores erróneos y, en teoría, deberían ser un conjunto vacío.

Si no son un conjunto vacío, arrojamos un error que se verá así:

Parte 3. Pruebas como soporte para refactorización
Por lo general, la prueba de código es uno de los soportes de refactorización más potentes. La refactorización es un proceso peligroso, hay que rehacer mucho y quiero asegurarme de que después de eso la aplicación siga siendo viable. Una forma de asegurarse de esto es superponer primero todo con pruebas en todos los lados y luego refactorizarlo.
Y ahora, ante mí estaba la tarea de refactorizar la configuración. Hay una aplicación que fue escrita hace siete años por una persona inteligente. La configuración de esta aplicación se ve así:

Este es un ejemplo, hay muchos más. Permutaciones de anidamiento triples, y esto se usa en toda la configuración:

Hay pocos archivos en la configuración en sí, pero están incluidos entre sí. Utiliza una pequeña extensión de Propiedades de iu - Configuración de Apache Commons, que solo admite inclusiones y permisos entre llaves.
Y el autor hizo un trabajo fantástico usando solo estas dos cosas. Creo que construyó una máquina de Turing allí sobre ellos. En algunos lugares, realmente parece que está tratando de hacer cálculos utilizando inclusiones y sustituciones. No sé si este sistema de Turing está completo, pero él, en mi opinión, trató de demostrar que es así.
Y el hombre se fue. Escribió, la aplicación funciona, y dejó el banco. Todo funciona, solo que nadie entiende completamente la configuración.
Si tomamos un servicio por separado, entonces resulta 10 inclusiones, a triple profundidad, y en total, si todo se expande, 450 parámetros. De hecho, este servicio en particular utiliza el 10-15% de ellos, el resto de los parámetros son para otros servicios, porque los archivos son compartidos, son utilizados por varios servicios. Pero lo que exactamente el 10-15% usa este servicio en particular no es tan fácil de entender. El autor aparentemente entendió. Persona muy inteligente, muy.
La tarea, respectivamente, era simplificar la configuración, su refactorización. Al mismo tiempo, quería mantener la aplicación funcionando, porque en esta situación, las posibilidades de que esto sea bajo. Quiero:
- Simplifica la configuración.
- De modo que después de refactorizar, cada servicio todavía tiene todos sus parámetros necesarios.
- Para que no tenga parámetros adicionales. El 85% de los que no están relacionados con él no deben abarrotar la página.
- Que los servicios todavía se conectan con éxito en grupos y realizan la colaboración.
El problema es que no se sabe qué tan bien se conectan ahora, porque el sistema es altamente redundante. Por ejemplo, mirando hacia el futuro: durante la refactorización, resultó que en una de las configuraciones de producción debería haber cuatro servidores en el clip de respaldo, pero en realidad había dos. Debido al alto nivel de redundancia, nadie se dio cuenta de esto: el error surgió accidentalmente, pero de hecho el nivel de redundancia fue durante mucho tiempo más bajo de lo que esperábamos. El punto es que no podemos confiar en el hecho de que la configuración actual es correcta en todas partes.
Llevo al hecho de que no puedes comparar la nueva configuración con la anterior. Puede ser equivalente, pero permanecer al mismo tiempo en algún lugar equivocado. Es necesario verificar el contenido lógico.
Programa mínimo: aísle cada parámetro separado de cada servicio que necesita y verifique que sea correcto, que el puerto es un puerto, la dirección es una dirección, TTL es un número positivo, etc. Y verifique las relaciones clave que los servicios básicamente conectan en los puntos finales principales. Quería lograr esto, al menos. Es decir, a diferencia de los ejemplos anteriores, la tarea aquí no es verificar parámetros individuales, sino cubrir toda la configuración con una red completa de verificaciones.
¿Cómo probarlo?
public class SimpleComponent { … public void configure( final Configuration conf ) { int port = conf.getInt( "Port", -1 ); if( port < 0 ) throw new ConfigurationException(); String ip = conf.getString( "Address", null ); if( ip == null ) throw new ConfigurationException(); … } … }
¿Cómo resolví este problema? Hay algún componente simple, en el ejemplo se simplifica al máximo. (Para aquellos que no se han encontrado con la Configuración de Apache Commons: el objeto de Configuración es como Propiedades, solo que todavía tiene los métodos mecanografiados getInt (), getLong (), etc .; podemos suponer que estos son juProperties en esteroides pequeños). Supongamos que un componente necesita dos parámetros: por ejemplo, una dirección TCP y un puerto TCP. Los sacamos y revisamos. ¿Cuáles son las cuatro partes comunes aquí?

Este es el nombre del parámetro, tipo, valores predeterminados (aquí son triviales: nulo y -1, a veces hay valores razonables) y algunas validaciones. El puerto aquí se valida de manera demasiado simple e incompleta: puede especificar el puerto que lo atravesará, pero no será un puerto de red válido. Por lo tanto, me gustaría mejorar este momento también. Pero antes que nada, quiero convertir estas cuatro cosas en una sola. Por ejemplo, esto:
IProperty<Integer> PORT_PROPERTY = intProperty( "Port" ) .withDefaultValue( -1 ) .matchedWith( validNetworkPort() ); IProperty<String> ADDRESS_PROPERTY = stringProperty( "Address" ) .withDefaultValue( null ) .matchedWith( validIPAddress() );
Tal objeto compuesto es una descripción de una propiedad que conoce su nombre, valor predeterminado, puede hacer la validación (aquí uso de nuevo el emparejador de Hamcrest). Y este objeto tiene algo como esta interfaz:
interface IProperty<T> { FetchedValue<T> fetch( final Configuration config ) } class FetchedValue<T> { public final String propertyName; public final T propertyValue; … }
Es decir, después de crear un objeto específico para una implementación específica, puede pedirle que extraiga el parámetro que representa de la configuración. Y extraerá este parámetro, verificará el proceso, si no hay ningún parámetro, le dará un valor predeterminado, lo llevará al tipo deseado y lo devolverá inmediatamente con el nombre.
Es decir, aquí está el nombre del parámetro y un valor tan real que el servicio verá si lo solicita desde esta configuración. Esto le permite ajustar varias líneas de código en una entidad, esta es la primera simplificación que necesitaré.
La segunda simplificación que necesitaba para resolver el problema era introducir un componente que necesita varias propiedades para su configuración. Modelo de configuración de componentes:

Teníamos un componente que usaba estas dos propiedades, hay un modelo para su configuración: la interfaz IConfigurationModel, que implementa esta clase. IConfigurationModel hace todo lo que hace el componente, pero solo la parte que se relaciona con la configuración. Si el componente necesita parámetros en un cierto orden con ciertos valores predeterminados, IConfigurationModel combina esta información en sí misma, la encapsula. Todas las demás acciones del componente no son importantes para él. Este es un modelo de componente en términos de acceso a la configuración.

El truco de esta vista es que los modelos son combinables. Si hay un componente que usa otros componentes y se combinan allí, de la misma manera, el modelo de este componente complejo puede fusionar los resultados de las llamadas de dos subcomponentes.
Es decir, es posible construir una jerarquía de modelos de configuración paralela a la jerarquía de los propios componentes. En el modelo superior, llame a fetch (), que devolverá la hoja de los parámetros que extrajo de la configuración con sus nombres, exactamente aquellos que el componente correspondiente necesitará en tiempo real. Si escribimos todos los modelos correctamente, por supuesto.
Es decir, la tarea es escribir dichos modelos para cada componente de la aplicación que tiene acceso a la configuración. En mi aplicación, había bastantes componentes de este tipo: la aplicación en sí es bastante frondosa, pero reutiliza activamente el código, por lo que solo se configuran 70 clases principales. Para ellos, tuve que escribir 70 modelos.
Lo que costó:
- 12 servicios
- 70 clases configurables
- => 70 modelos de configuración (~ 60 son triviales);
- 1-2 personas semanas.
Simplemente abrí la pantalla con el código del componente que se configura solo, y en la siguiente pantalla escribí el código para el Modelo de configuración correspondiente. La mayoría de ellos son triviales, como el ejemplo que se muestra. En algunos casos, hay ramas y transiciones condicionales; allí el código se vuelve más ramificado, pero también todo está resuelto. En una y media o dos semanas resolví este problema, para los 70 componentes describí los modelos.
Como resultado, cuando lo juntamos todo, obtenemos el siguiente código:

Para cada servicio / entorno / etc. tomamos el modelo de configuración, es decir, el nodo superior de este árbol, y pedimos obtener todo de la configuración. En este punto, todas las validaciones pasan al interior, cada una de las propiedades, cuando se extrae de la configuración, verifica su valor para verificar que sea correcto. Si al menos uno no pasa, saldrá una excepción. Todo el código se obtiene comprobando que todos los valores son válidos de forma aislada.
Interdependencias de servicio
Todavía teníamos una pregunta sobre cómo verificar la interdependencia de los servicios. Esto es un poco más complicado, debes ver qué tipo de interdependencia hay. Resultó que las interdependencias se reducen al hecho de que los servicios deberían "encontrarse" en los puntos finales de la red. El servicio A debe escuchar exactamente la dirección a la que el servicio B envía paquetes, y viceversa. En mi ejemplo, todas las dependencias entre las configuraciones de diferentes servicios se redujeron a esto. Fue posible resolver este problema de una manera tan directa: obtenga puertos y direcciones de diferentes servicios y verifíquelos. Habría muchas pruebas, serían voluminosas. Soy una persona perezosa y no quería esto. Por lo tanto, hice lo contrario.
En primer lugar, quería abstraer de alguna manera este punto final de la red. Por ejemplo, para una conexión TCP solo necesita dos parámetros: dirección y puerto. Para una conexión de multidifusión, cuatro parámetros. Me gustaría colapsarlo en algún tipo de objeto. Hice esto en el objeto Endpoint, que en su interior oculta todo lo que necesita. La diapositiva es un ejemplo de OutcomingTCPEndpoint, una conexión de red TCP saliente.
IProperty<IEndpoint> TCP_REQUEST = outcomingTCP(
Endpoint matches(), Endpoint, , .
« »? , : , , - , — . , , / . , , .
, , ---, , Endpoint. ConfigurationModels — , . ? :
ValueWithContext[] allEndpoints = flattenedConfigurationValues(environment) .filter( valueIsEndpoint() ) .toArray(); ValueWithContext[] unpairedEndpoints = Arrays.stream( allEndpoints ) .filter( e -> !hasMatchedEndpoint(e, allEndpoints) ) .toArray(); assertThat( unpairedEndpoints, emptyArray() );
environment' endpoint', , , , . . « » O(n^2), , endpoint' , .
Endpoint , , . , , - .
, , , «» — , . . , , . , .
. , , . , , , c, , .
ConfigurationModel :
, . , , , — . : , . , , , , .
. , ConfigurationModels, . , UDP- , , .
, endpoints , .dot. . — .
. Conclusiones:
Si le gustó este informe del Piter Heisenbug 2018, tenga en cuenta: del 6 al 7 de diciembre, el próximo Heisenbug se llevará a cabo en Moscú . La mayoría de las descripciones de los nuevos informes ya están disponibles en el sitio web de la conferencia . Y a partir del 1 de noviembre, los precios de las entradas están aumentando, por lo que tiene sentido tomar una decisión ahora.