Hola, mi nombre es Maxim, soy administrador del sistema. Hace tres años, mis colegas y yo comenzamos a transferir productos a microservicios, y decidimos usar Openstack como plataforma, y encontramos varios rastrillos no obvios al automatizar los circuitos de prueba. Esta publicación trata sobre los matices de configurar OpenStack, que apenas se encuentran en la quinta página de resultados de los motores de búsqueda (o mejor, son fácilmente en la primera).
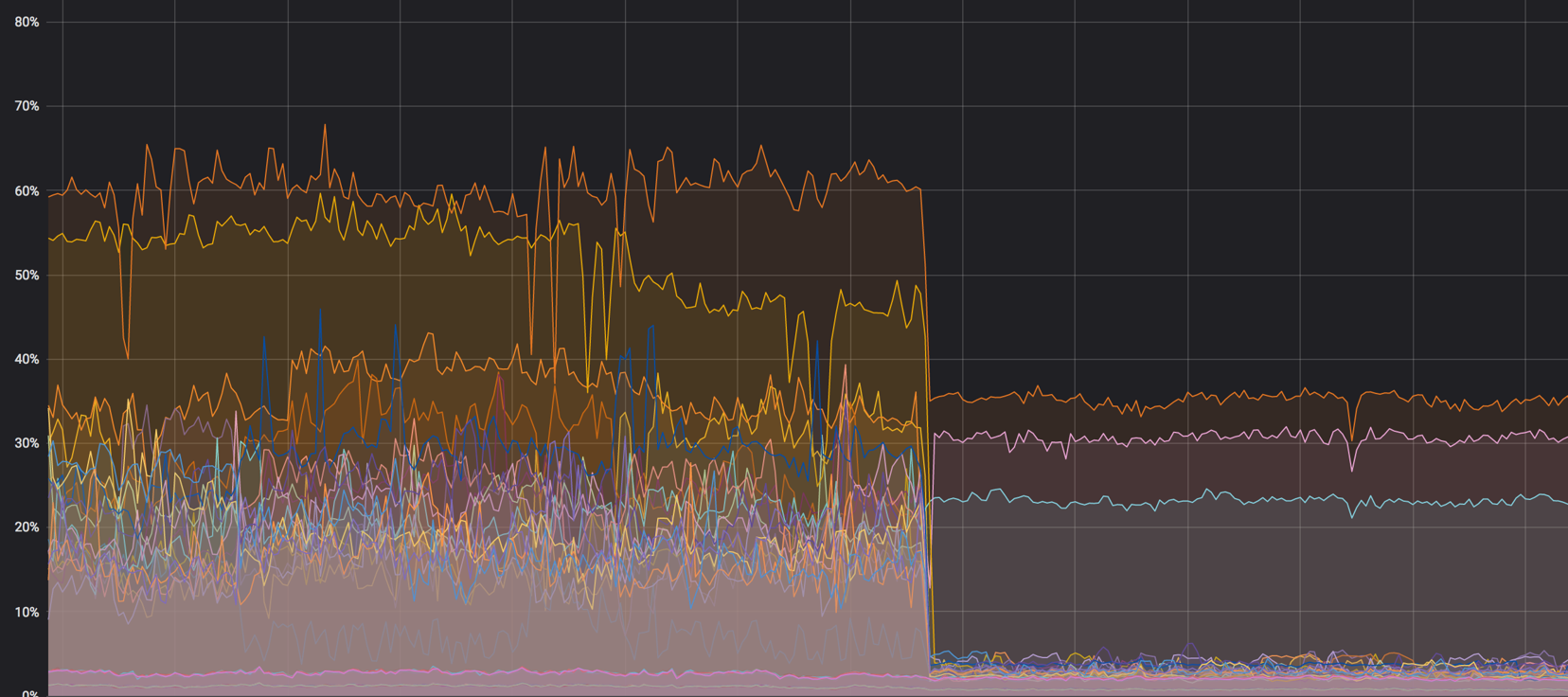
La carga en los núcleos: fue - se convirtió
NAT
En algunos casos usamos dualstack. Esto es cuando la máquina virtual recibe dos direcciones a la vez: IPv4 e IPv6. Primero, nos aseguramos de que la dirección v4 “flotante” fuera asignada en la red interna a través de NAT, y que la máquina recibiera v6 a través de BGP, pero hay un par de problemas con esto.
NAT: un nodo adicional en la red, donde incluso sin él, usted necesita monitorear la distribución de carga normal. La aparición de NAT en la red casi siempre conlleva dificultades con la depuración: en el host una IP, en la base de datos otra, y se hace difícil rastrear la solicitud. Las búsquedas masivas comienzan, y la solución seguirá estando dentro de OpenStack.
Aún así, NAT no permite realizar una segmentación normal del acceso entre proyectos. Todos los proyectos tienen sus propias subredes, las IP flotantes migran constantemente, y con NAT se hace absolutamente imposible administrar esto. Algunas instalaciones hablan sobre el uso de NAT 1 en 1 (la dirección interna no difiere de la externa), pero esto todavía deja enlaces innecesarios en la cadena de interacción con servicios externos. Llegamos a la conclusión de que para nosotros la mejor opción es una red BGP.
Cuanto más simple, mejor
Probamos varias herramientas de automatización, pero nos decidimos por Ansible. Esta es una buena herramienta, pero su funcionalidad estándar (incluso teniendo en cuenta módulos adicionales) puede no ser suficiente en algunas situaciones difíciles.
Por ejemplo, a través del módulo Ansible, no puede especificar desde qué direcciones de subred se asignarán. Es decir, puede especificar una red, pero no puede establecer un grupo de direcciones específico. El comando de shell que crea la IP flotante ayudará aquí:
openstack floating ip create -c floating_ip_address -f value -project \ {{ project name }} —subnet private-v4 CLOUD_NET
Otro ejemplo de funcionalidad faltante: debido a la doble pila, no podemos crear correctamente un enrutador con dos puertos para v4 y v6. Aquí es donde un script bash es útil:
El script crea un enrutador, le agrega subredes v4 y v6 y le asigna una puerta de enlace externa.
Reintentar
En cualquier situación incomprensible, reinicie. Intente nuevamente, cree una instancia, un enrutador o un registro DNS, porque no siempre comprende rápidamente cuál es su problema. Reintentar puede retrasar la degradación del servicio, y en este momento puede resolver el problema con calma y sin nervios.
Todos los consejos anteriores realmente funcionan muy bien con Terraform, Puppet y cualquier otra cosa.
Todo tiene su lugar
Cualquier servicio grande (OpenStack no es una excepción) combina muchos servicios más pequeños que pueden interferir con el trabajo del otro. Aquí hay un ejemplo.
Agente de red Neutron-L2-agent es responsable de la conectividad de red en OpenStack. Si todos los demás agentes están parcialmente en los controladores, entonces L2, debido a los detalles, está presente en todas partes.
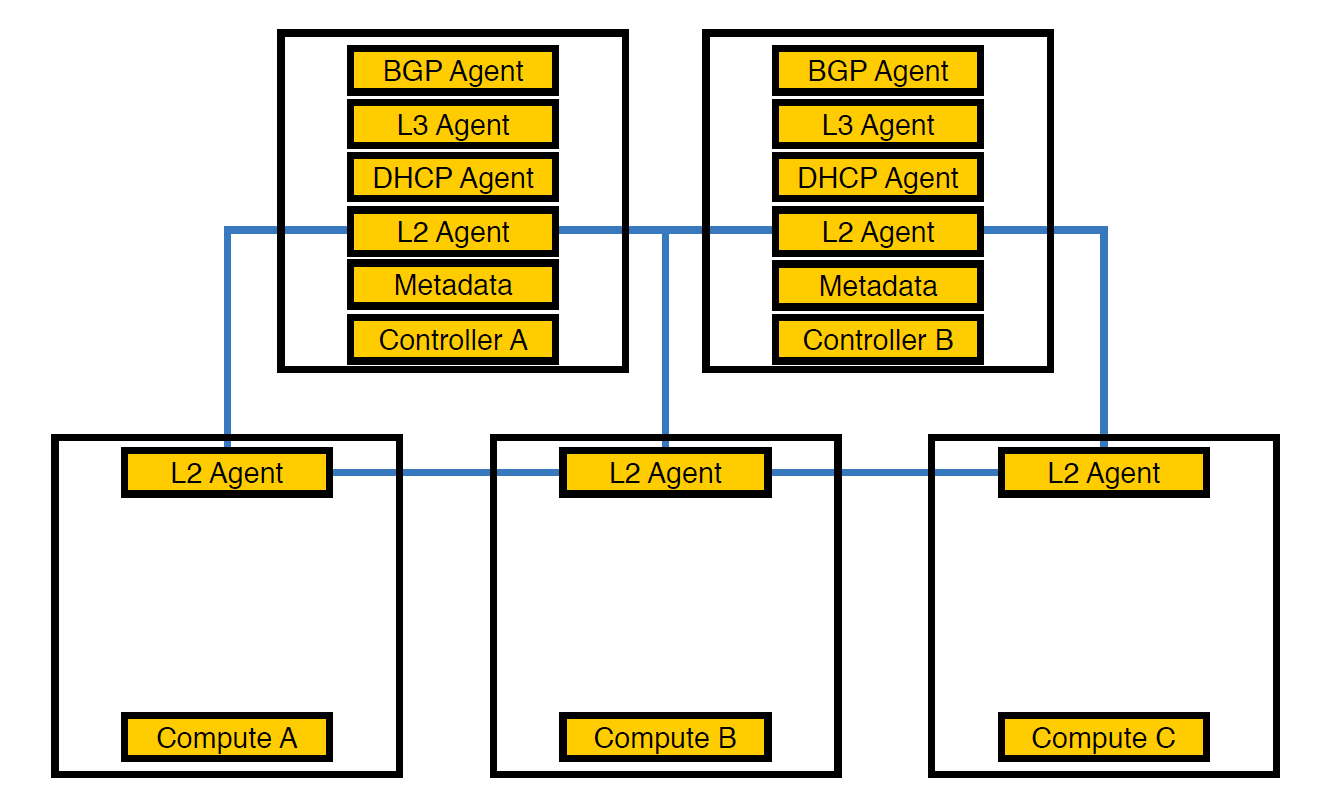
Así es como se veía nuestra infraestructura desde el principio, hasta que el número de esquemas excedió 50
En este punto, nos dimos cuenta de que debido a esta disposición de agentes, los controladores no podían hacer frente a la carga, y transferimos los agentes a los nodos de cómputo. Son más potentes que los controladores y, además, el controlador no tiene que ocuparse del procesamiento de todo: debe asignar la tarea al nodo de ejecución, y el nodo la ejecutará.

Agentes transferidos para calcular nodos
Sin embargo, esto no fue suficiente, porque tal disposición tuvo un efecto negativo en el rendimiento de las máquinas virtuales. Con una densidad de 14 núcleos virtuales por físico, si un agente de red comienza a cargar la transmisión, esto podría afectar a varias máquinas virtuales a la vez.
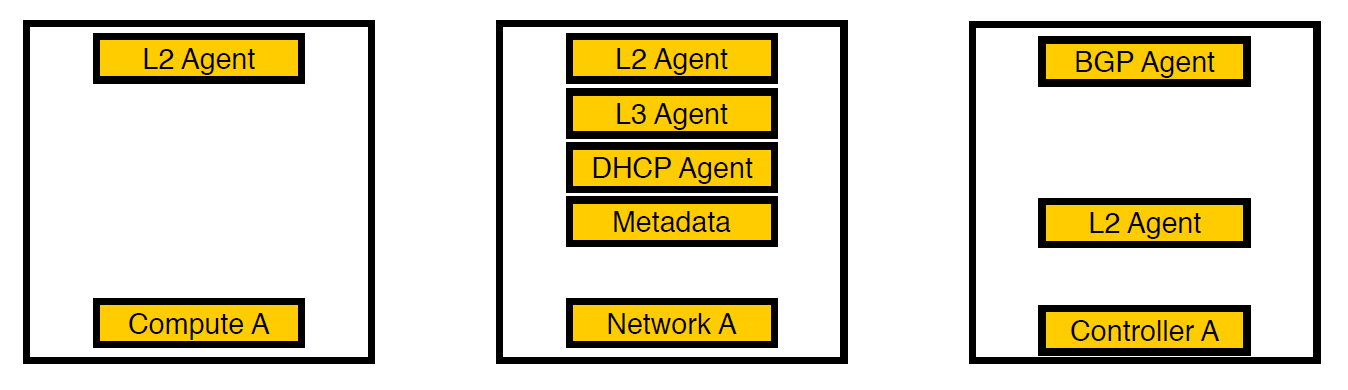
Tercera iteración. Los nodos seleccionados aparecieron.
Pensamos y movimos a los agentes para separar los nodos de la red. Ahora solo los servicios para máquinas virtuales permanecen en los nodos de cómputo, todos los agentes trabajan en los nodos de la red y solo los agentes bgp que se ocupan de la red v6 permanecen en los controladores (ya que un agente bgp solo puede servir un tipo de red). L2 permaneció en todas partes, porque sin él, como escribimos anteriormente, no habría conectividad en la red.
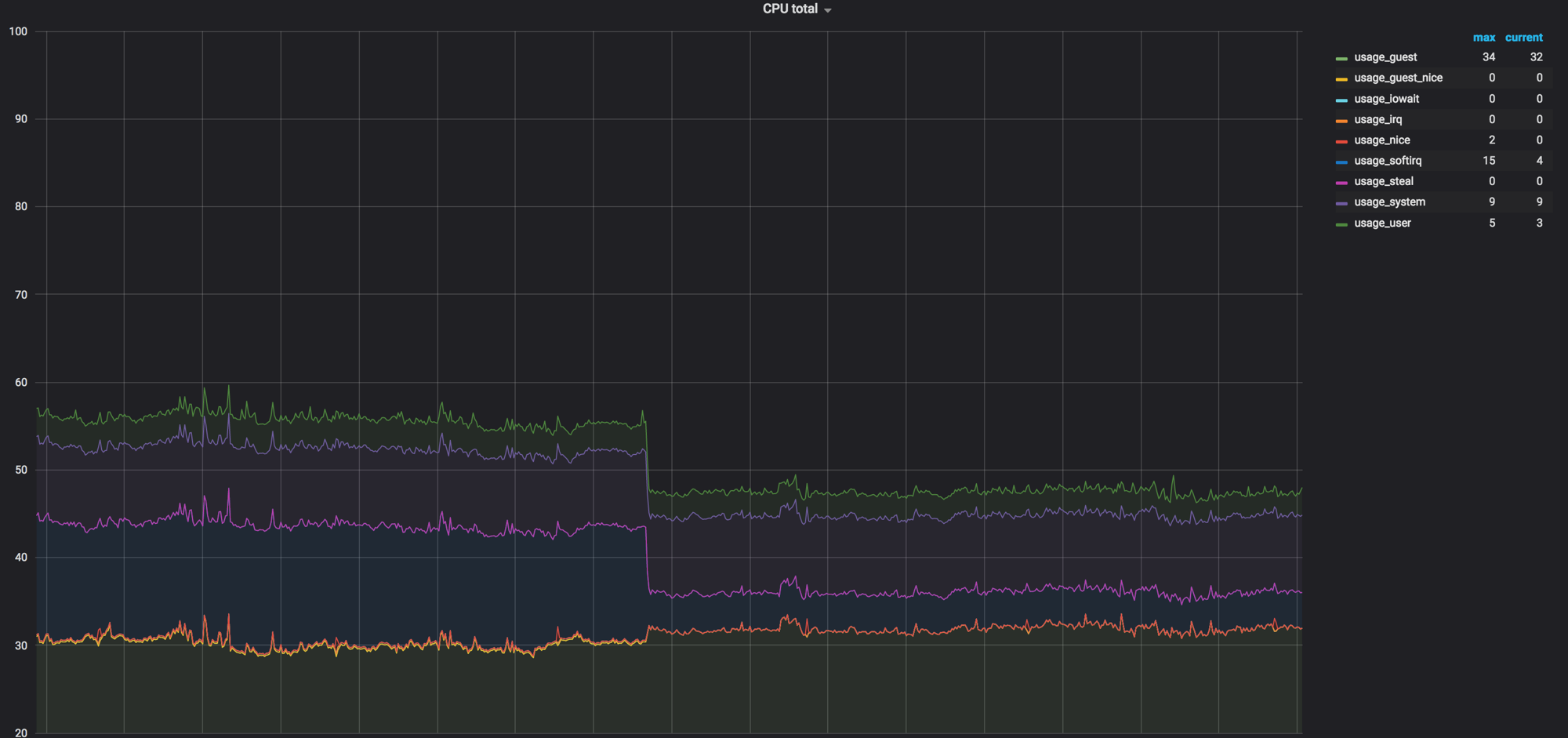
Cargue el gráfico de los nodos de cálculo antes de que todo se mezcle. Fue alrededor del 60%, pero la carga cayó insignificantemente

La carga en softirq antes de que los agentes de red eliminaran los nodos de proceso. Quedaron 3 núcleos cargados. En ese momento, pensamos que era normal
Código como documentación
A veces sucede que el código es la documentación, especialmente en servicios tan grandes como OpenStack. Con un ciclo de lanzamiento de seis meses, los desarrolladores olvidan o simplemente no tienen tiempo para documentar algunas cosas, y resulta como en el ejemplo a continuación.
Sobre tiempos de espera
Una vez que vimos que las llamadas de Neutron para abrir vSwitch no caben en cinco segundos y caen en el tiempo de espera.
127.0.0.1:29696: no response to inactivity probe after 10 seconds, disconnecting neutron.agent.ovsdb.native.commands TimeoutException: Commands [DbSetCommand(table=Port, col_values=(('tag', 11),), record=qtoq69a81c6-e2)] exceeded timeout 5 seconds
Por supuesto, asumimos que en algún lugar de la configuración esto se soluciona. Buscamos en el paquete de configuración, documentación y deb, pero al principio no encontraron nada. Como resultado, la descripción de la configuración deseada se encontró en la quinta página de los resultados de búsqueda: volvimos a mirar el código y encontramos el lugar correcto. La configuración es esta:
ovs_vsctl_timeout = 30
Lo configuramos durante 30 segundos (fueron 5), y todo comenzó a funcionar un poco mejor.
Aquí hay otro obvio: cuando reinicia los componentes de la red, algunas configuraciones de Open vSwitch pueden restablecerse. Esto, por ejemplo, sucede con ovs-vsctl inactivity_probe. Esto también es un tiempo de espera, pero afecta las llamadas de ovs-vsctl a su base de datos. Lo agregamos a systemd init, lo que nos permitió iniciar todos los conmutadores con los parámetros que necesitamos al inicio.
ovs-vsctl set Controller "br-int" inactivity_probe=30000
Acerca de la configuración de la pila de red
También tuvimos que alejarnos un poco de la configuración generalmente aceptada en la pila de red, que usamos en nuestros otros servidores.
Aquí está la configuración de cuánto tiempo lleva almacenar registros ARP en una tabla:
net.ipv4.neigh.default.base_reachable_time = 60 net.ipv4.neigh.default.gc_stale_time=60
El valor predeterminado es 1 día. En general, un esquema puede vivir durante un par de semanas, pero durante un día, los esquemas se pueden recrear de 4 a 6 veces, mientras que la correspondencia de la dirección MAC y la dirección IP cambia constantemente. Para que la basura no se acumule, establecemos el tiempo en un minuto.
net.ipv4.conf.default.arp_notify = 1 net.nf_conntrack_max = 1000000 (default 262144) net.netfilter.nf_conntrack_max = 1000000 (default 262144)
Además, forzamos el envío de notificaciones ARP al elevar la interfaz de red. También aumentamos la tabla conntrack, porque al usar NAT e IP flotante, no teníamos el valor predeterminado. Aumentó a un millón (con un valor predeterminado en 262 144), todo se volvió aún mejor.
Corregimos el tamaño de la tabla MAC de Open vSwitch:
ovs-vsctl set bridge bt-int other-config:mac-table-size=50000 (default 2048)

Después de todas las configuraciones, el 40% de la carga se convirtió en casi cero
rx-flow-hash
Para distribuir el procesamiento del tráfico udp entre todas las colas y subprocesos del procesador, incluimos rx-flow-hash. En las tarjetas de red Intel, es decir, en el controlador i40e, esta opción está deshabilitada de forma predeterminada. Tenemos hipervisores con 72 núcleos en nuestra infraestructura, y si solo uno está ocupado, entonces esto no es muy óptimo.
Se hace así:
ethtool -N eno50 rx-flow-hash udp4 sdfn

Una conclusión importante: puede configurar todo en absoluto. La configuración predeterminada se ajustará en algún momento (como lo hicimos nosotros), pero el problema con los tiempos de espera hizo que fuera necesario buscar. Y esto es normal.
Reglas de seguridad
De acuerdo con los requisitos del servicio de seguridad, todos los proyectos dentro de la empresa tienen reglas personales y globales; hay muchos de ellos. Cuando nos mudamos al extranjero de 300 máquinas virtuales a un hipervisor, todo esto se convirtió en 80 mil reglas para iptables. Para iptables en sí, esto no es un problema, pero Neutron carga estas reglas de RabbitMQ en un hilo (porque está escrito en Python, y todo es triste con el multihilo allí). El agente de neutrones se congela, pierde la conexión con RabbitMQ y una reacción en cadena por los tiempos de espera, y después de la recuperación, Neutron vuelve a solicitar todas las reglas, comienza la sincronización y todo comienza de nuevo.
Junto con esto, el tiempo para crear stands aumentó de 20-40 minutos a, en el mejor de los casos, una hora.
Al principio, simplemente envolvimos todo con recuperaciones (ya en esta etapa nos dimos cuenta de que el problema no podía resolverse tan rápido), y luego comenzamos a usar FWaaS . Con él, sacamos reglas de seguridad con nodos de cómputo para separar los nodos de la red donde se encuentra el enrutador.

Fuente: docs.openstack.org
Por lo tanto, dentro del proyecto hay acceso completo a todo lo que se necesita y se aplican reglas de seguridad para conexiones externas. Así que redujimos la carga en Neutron y volvimos a 20-30 minutos de crear un entorno de prueba.
Resumen
OpenStack es algo genial en el que puedes reciclar hierro, crear una nube interna y crear otra cosa basada en ella. Además de esto, hay una gran comunidad y un grupo activo en Telegram , donde nos informaron sobre los tiempos de espera.
Eso es todo Haga preguntas, mis colegas y yo estamos listos para responder y compartir nuestra experiencia.