Parte I. R extractos y dibujos
Por supuesto, PostgreSQL fue creado desde el principio como un DBMS universal, y no como un sistema OLAP especializado. Pero una de las grandes ventajas de Postgres es su soporte para lenguajes de programación, con los cuales puedes sacarle provecho. Dada la abundancia de lenguajes de procedimiento incorporados, simplemente no tiene igual. PL / R: implementación de servidor de
R : el lenguaje favorito de los analistas, uno de ellos. Pero más sobre eso más tarde.
R es un lenguaje sorprendente con tipos de datos peculiares: la
list , por ejemplo, puede incluir no solo datos de diferentes tipos, sino también funciones (en general, el lenguaje es ecléctico y no hablaremos sobre su pertenencia a una familia en particular, para no causar discusiones que distraigan). Tiene un tipo de datos bastante
data.frame que imita una tabla RDBMS: es una matriz en la que las columnas contienen diferentes tipos de datos que son comunes a nivel de columna. Por lo tanto (y por otras razones) trabajar con bases de datos en R es bastante conveniente.
Trabajaremos en la línea de comandos en el entorno
RStudio y nos conectaremos a PostgreSQL a través del
controlador ODBC RpostgreSQL . Son fáciles de instalar.
Dado que R se creó como una especie de variante del lenguaje
S para aquellos que se dedican a las estadísticas, también daremos ejemplos de estadísticas simples con gráficos simples. No tenemos el objetivo de introducir el lenguaje, pero existe el objetivo de mostrar la interacción de
R y PostgreSQL .
Hay tres formas de procesar datos almacenados en PostgreSQL.
En primer lugar, puede bombear datos de la base de datos por cualquier medio conveniente, empaquetarlos, digamos, en JSON - R lo entiende - y procesarlos aún más en R. Esto generalmente no es la forma más eficiente y ciertamente no es la más interesante, no lo consideraremos aquí.
En segundo lugar, puede comunicarse con la base de datos, leerla y volcar datos en ella, desde el entorno R como cliente, utilizando el controlador ODBC / DBI, procesando los datos en R. Mostraremos cómo se hace esto.
Y finalmente, puede hacer el procesamiento con las herramientas R que ya están en el servidor de la base de datos, utilizando PL / R como lenguaje de procedimiento integrado. Esto tiene sentido en varios casos, ya que en R existen, por ejemplo, medios convenientes para agregar datos que no están en
pl/pgsql . Mostraremos esto también.
Un enfoque común es usar las opciones segunda y tercera en diferentes fases del proyecto: primero depure el código como un programa externo y luego transfiéralo a la base.
Empecemos R interpretó el lenguaje. Por lo tanto, puede seguir los pasos o puede volcar el código en un script. Una cuestión de gustos: los ejemplos en este artículo son cortos.
Primero, por supuesto, debe conectar el controlador apropiado:
# install.packages("RPostgreSQL") require("RPostgreSQL") drv <- dbDriver("PostgreSQL")
La operación de asignación se ve en R, como puede ver, peculiar. En general, en R a <- b significa lo mismo que b -> a, pero la primera forma de escribir es más común.
Tomaremos la base de datos terminada: la base de datos de
transporte aéreo , que es utilizada por los
materiales de capacitación de Postgres Professional . En
esta página puede elegir la opción de base de datos para probar (es decir, tamaño) y leer su descripción. Reproducimos el esquema de datos por conveniencia:
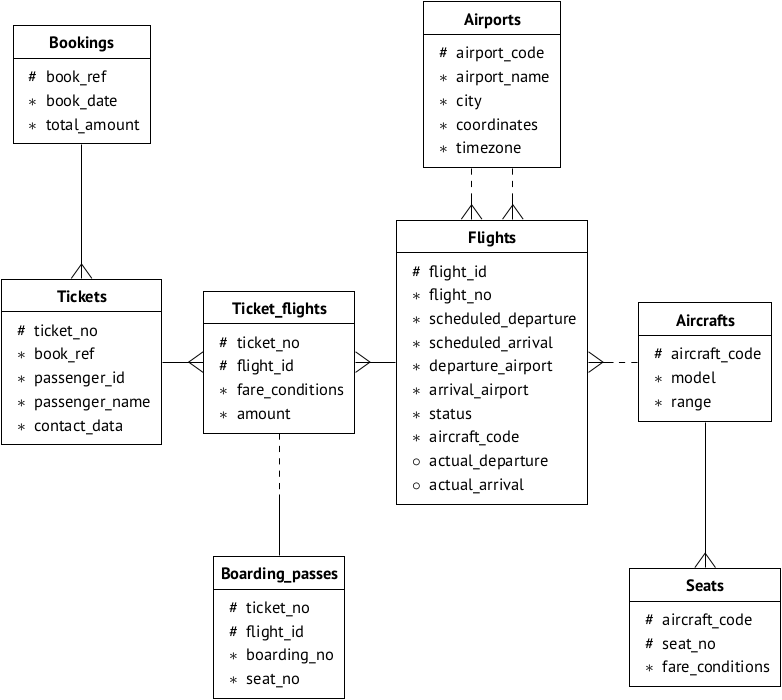
Suponga que la base está instalada en el servidor 192.168.1.100 y se llama
demo . Conectar:
con <- dbConnect(drv, dbname = "demo", host = "192.168.1.100", port = 5434, user = "u_r")
Continuamos Veamos con esa solicitud a qué ciudades los vuelos llegan con mayor frecuencia:
SELECT ap.city, avg(extract(EPOCH FROM f.actual_arrival) - extract(EPOCH FROM f.scheduled_arrival))/60.0 t FROM airports ap, flights f WHERE ap.airport_code = f.departure_airport AND f.scheduled_arrival < f.actual_arrival AND f.departure_airport = ap.airport_code GROUP BY ap.city ORDER BY t DESC LIMIT 10;
Para llegar tarde, utilizamos el constructo de extracto de postgres
extract(EPOCH FROM ...) para extraer los segundos "absolutos" de un campo de
timestamp y dividido por 60.0, en lugar de 60, para evitar descartar el resto al dividir, entendido como entero.
EXTRACT MINUTE no se puede usar, ya que hay demoras por más de una hora. Promediamos la tardanza del operador
avg .
Pasamos el texto a la variable y enviamos la solicitud al servidor:
sql1 <- "SELECT ... ;" res1 <- dbGetQuery(con, sql1)
Ahora descubriremos de qué forma vino la solicitud. Para hacer esto, el lenguaje R tiene una función
class() class (res1)
data.frame que el resultado fue empaquetado en el tipo
data.frame , es decir, recordamos que es un análogo de la tabla base: de hecho, es una matriz con columnas de tipos arbitrarios. Por cierto, ella sabe los nombres de las columnas, y las columnas, si hay algo, se puede acceder, por ejemplo, de esta manera:
print (res1$city)
Es hora de pensar en cómo visualizar los resultados. Para hacer esto, puedes ver lo que tenemos. Por ejemplo, seleccione el horario apropiado de
esta lista :
- Gráficos de barra R (barra)
- R-Boxplots (stock)
- R-Histogramas
- Gráficos de línea R (gráficos)
- Gráficos de dispersión R (punto)
Debe tenerse en cuenta que para cada tipo de entrada, se proporciona un tipo de datos adecuado para la imagen. Elija un gráfico de barras (barras reclinadas). Requiere dos vectores para valores axiales. El tipo "vector" en R es simplemente un conjunto de valores del mismo tipo.
c() es un constructor de vectores.
Puede generar los dos vectores necesarios a partir de un resultado del tipo
data.frame siguiente manera:
Time <- res1[,c('t')] City <- res1[,c('city')] class (Time) class (City)
Las expresiones en el lado derecho se ven raras, pero es una técnica conveniente. Además, se pueden escribir varias expresiones de manera muy compacta en R. Entre corchetes antes de la coma, el índice de la serie, después de la coma, el índice de la columna. El hecho de que la coma no valga nada significa solo que todos los valores serán seleccionados de la columna correspondiente.
La clase Time es
numeric y la clase City es
character . Estas son variedades de vectores.
Ahora puedes hacer la visualización en sí. Debe especificar un archivo de imagen.
png(file = "/home/igor_le/R/pics/bars_horiz.png")
Después de eso, sigue un procedimiento tedioso: establezca los parámetros (
par ) de los gráficos. Y no quiere decir que todo en los paquetes de gráficos R fuera intuitivo. Por ejemplo, el parámetro
las determina la posición de las etiquetas con valores a lo largo de los ejes en relación con los ejes mismos:
- 0 y por defecto paralelo a los ejes;
- 1 - siempre horizontal;
- 2 - perpendicular a los ejes;
- 3 - siempre en posición vertical
No pintaremos todos los parámetros. En general, hay muchos de ellos: campos, escalas, colores: busque, experimente a su gusto.
par(las=1) par(mai=c(1,2,1,1))
Finalmente, construimos un gráfico a partir de las columnas reclinadas:
barplot(Time, names.arg=City, horiz=TRUE, xlab=" ()", col="green", main=" ", border="red", cex.names=0.9)
Eso no es todo. Debo decir una última cosa:
dev.off()

Para variar, dibujaremos aún el diagrama de puntos de la tardanza. Elimine LIMIT de la solicitud, el resto es igual. Pero un gráfico de dispersión necesita un vector, no dos.
Dots <- res2[,c('t')] png(file = "/home/igor_le/R/scripts/scatter.png") plot(input5, xlab="",ylab="",main=" ") dev.off()
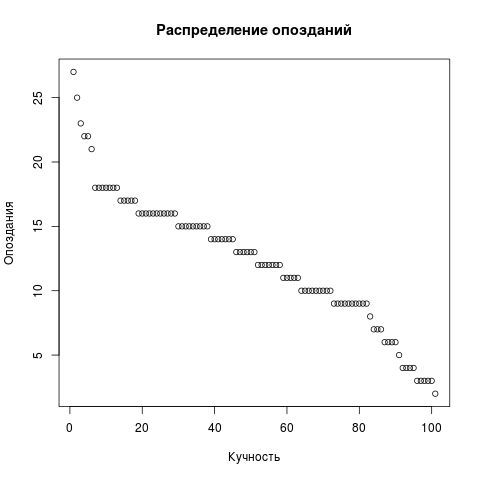
Para la visualización, utilizamos paquetes estándar. Está claro que R es un lenguaje popular y existen paquetes alrededor del infinito. Puede preguntar acerca de los ya instalados como este:
library()
Parte II R genera jubilados
R es conveniente de usar no solo para el análisis de datos, sino también para su generación. Donde hay funciones estadísticas ricas, no puede haber una variedad de algoritmos para crear secuencias aleatorias. En particular, puede usar distribuciones típicas (gaussianas) y no bastante típicas (Zipf) para simular consultas de bases de datos.
Pero más sobre eso en la siguiente parte.