Este artículo se centrará en escribir y respaldar una especificación útil y relevante para un proyecto API REST, que ahorrará mucho código adicional, y mejorará seriamente la integridad, la fiabilidad y la transparencia del proyecto en su conjunto.
¿Qué es una API RESTful?
Esto es un mito
En serio, si crees que tu proyecto tiene una API RESTful, es casi seguro que te equivocas. La idea de RESTful es construir una API que, en todos los aspectos, cumpla con las reglas y restricciones arquitectónicas descritas por el estilo REST, pero en condiciones reales esto es casi imposible .
Por un lado, REST contiene demasiadas definiciones vagas y ambiguas. Por ejemplo, algunos términos de los diccionarios de métodos HTTP y códigos de estado no se usan en la práctica para su propósito previsto, y muchos de ellos no se usan en absoluto.
Por otro lado, REST crea demasiadas restricciones. Por ejemplo, el uso atómico de los recursos en el mundo real no es racional para las API utilizadas por las aplicaciones móviles. Una negativa total a almacenar el estado entre solicitudes es esencialmente una prohibición del mecanismo de las sesiones de usuario utilizadas en muchas API.
Pero espera, ¡no todo es tan malo!
¿Por qué necesitamos la especificación REST API?
A pesar de estas deficiencias, con un enfoque razonable, REST sigue siendo una base excelente para diseñar API realmente geniales. Tal API debería tener uniformidad interna, una estructura clara, documentación conveniente y una buena cobertura de prueba unitaria. Todo esto se puede lograr desarrollando una especificación de calidad para su API.
Muy a menudo, la especificación REST API está asociada con su documentación . A diferencia del primero (que es una descripción formal de su API), la documentación está destinada a ser leída por personas: por ejemplo, por desarrolladores de una aplicación móvil o web que utiliza su API.
Sin embargo, además de crear documentación, una descripción adecuada de la API puede traer muchos beneficios. En el artículo quiero compartir ejemplos de cómo, utilizando el uso competente de la especificación, puede:
- hacer que las pruebas unitarias sean más simples y confiables;
- configurar el preprocesamiento y la validación de los datos de entrada;
- automatizar la serialización y garantizar la integridad de las respuestas;
- e incluso aprovechar la escritura estática.
Openapi
El formato generalmente aceptado para describir la API REST hoy es OpenAPI , que también se conoce como Swagger . Esta especificación es un archivo único en formato JSON o YAML, que consta de tres secciones:
- un encabezado que contiene el nombre, la descripción y la versión de la API, así como información adicional;
- una descripción de todos los recursos, incluidos sus identificadores, métodos HTTP, todos los parámetros de entrada, así como los códigos y formatos del cuerpo de respuesta, con enlaces a definiciones;
- todas las definiciones de objetos en formato de esquema JSON que se pueden usar tanto en parámetros de entrada como en respuestas.
OpenAPI tiene un serio inconveniente: la complejidad de la estructura y, a menudo, la redundancia . Para un proyecto pequeño, el contenido del archivo JSON de especificación puede crecer rápidamente hasta varios miles de líneas. No es posible mantener este archivo manualmente en este formulario. Esta es una seria amenaza para la idea misma de mantener una especificación actualizada a medida que evoluciona la API.
Hay muchos editores visuales que le permiten describir la API y formar la especificación de OpenAPI resultante. A su vez, los servicios adicionales y las soluciones en la nube se basan en ellos, por ejemplo, Swagger , Apiary , Stoplight , Restlet y otros.
Sin embargo, para mí, tales servicios no eran muy convenientes debido a la dificultad de editar rápidamente la especificación y combinarla con el proceso de escritura del código. Otro inconveniente es la dependencia del conjunto de funciones de cada servicio en particular. Por ejemplo, es casi imposible implementar pruebas unitarias completas solo por medio de un servicio en la nube. La generación de código e incluso la creación de "enchufes" para puntos finales, aunque parece muy posible, son prácticamente inútiles en la práctica.
Tinyspec
En este artículo, usaré ejemplos basados en el formato de descripción de la API REST nativa: tinyspec . El formato son archivos pequeños que describen los puntos finales y los modelos de datos utilizados en el proyecto con una sintaxis intuitiva. Los archivos se almacenan al lado del código, lo que le permite consultarlos y editarlos directamente en el proceso de escritura. Al mismo tiempo, tinyspec se compila automáticamente en un OpenAPI completo, que puede usarse inmediatamente en el proyecto. Es hora de decirte exactamente cómo.
En este artículo, daré ejemplos de Node.js (koa, express) y Ruby on Rails, aunque estas prácticas se aplican a la mayoría de las tecnologías, incluidas Python, PHP y Java.
Cuando la especificación es increíblemente útil
1. Pruebas unitarias de puntos finales
El desarrollo impulsado por el comportamiento (BDD) es ideal para desarrollar una API REST. La forma más conveniente de escribir pruebas unitarias no es para clases individuales, modelos y controladores, sino para puntos finales específicos. En cada prueba, emula una solicitud HTTP real y verifica la respuesta del servidor. En Node.js, para emular solicitudes de prueba, hay supertest y chai-http , en Ruby on Rails, en el aire .
Supongamos que tenemos un esquema de User y un punto final GET /users que devuelve todos los usuarios. Aquí está la sintaxis de tinyspec que describe esto:
- Archivo User.models.tinyspec :
User {name, isAdmin: b, age?: i}
- Archivo users.endpoints.tinyspec :
GET /users => {users: User[]}
Así se verá nuestra prueba:
Node.js
describe('/users', () => { it('List all users', async () => { const { status, body: { users } } = request.get('/users'); expect(status).to.equal(200); expect(users[0].name).to.be('string'); expect(users[0].isAdmin).to.be('boolean'); expect(users[0].age).to.be.oneOf(['boolean', null]); }); });
Ruby on Rails
describe 'GET /users' do it 'List all users' do get '/users' expect_status(200) expect_json_types('users.*', { name: :string, isAdmin: :boolean, age: :integer_or_null, }) end end
Cuando tenemos una especificación que describe los formatos de respuesta del servidor, podemos simplificar la prueba y simplemente comparar la respuesta con esta especificación . Para hacer esto, aprovecharemos el hecho de que nuestros modelos tinyspec se transforman en definiciones OpenAPI, que a su vez corresponden al formato de esquema JSON.
Cualquier objeto literal en JS (o Hash en Ruby, un dict en Python, una matriz asociativa en PHP e incluso un Map en Java) se puede probar para verificar el cumplimiento de un esquema JSON. E incluso hay complementos correspondientes para probar marcos, por ejemplo jest-ajv (npm), chai-ajv-json-schema (npm) y json_matchers (rubygem) para RSpec.
Antes de usar los esquemas, debe conectarlos al proyecto. Primero, generaremos el archivo de especificación openapi.json basado en tinyspec (esta acción se puede realizar automáticamente antes de cada ejecución de prueba):
tinyspec -j -o openapi.json
Node.js
Ahora podemos usar el JSON recibido en el proyecto y tomarle la clave de definitions , que contiene todos los esquemas JSON. Los esquemas pueden contener referencias cruzadas ( $ref ), por lo tanto, si tenemos esquemas anidados (por ejemplo, Blog {posts: Post[]} ), entonces necesitamos "expandirlos" para usarlos en las validaciones. Para hacer esto, usaremos json-schema-deref-sync (npm).
import deref from 'json-schema-deref-sync'; const spec = require('./openapi.json'); const schemas = deref(spec).definitions; describe('/users', () => { it('List all users', async () => { const { status, body: { users } } = request.get('/users'); expect(status).to.equal(200);
Ruby on Rails
json_matchers puede manejar enlaces $ref , pero requiere archivos separados con esquemas en el sistema de archivos de cierta manera, así que primero debe "dividir" swagger.json en muchos archivos pequeños (más sobre esto aquí ):
Después de eso, podemos escribir nuestra prueba así:
describe 'GET /users' do it 'List all users' do get '/users' expect_status(200) expect(result[:users][0]).to match_json_schema('User') end end
Nota: escribir pruebas de esta manera es increíblemente conveniente. Especialmente si su IDE admite la ejecución de pruebas y depuración (como WebStorm, RubyMine y Visual Studio). Por lo tanto, no puede utilizar ningún otro software, y todo el ciclo de desarrollo de la API se reduce a 3 pasos consecutivos:
- diseño de especificación (por ejemplo, en tinyspec);
- escribir un conjunto completo de pruebas para puntos finales agregados / modificados;
- desarrollando código que satisfaga todas las pruebas.
2. Validación de entrada
OpenAPI describe el formato de no solo respuestas, sino también datos de entrada. Esto nos permite validar los datos recibidos del usuario directamente durante la solicitud.
Supongamos que tenemos la siguiente especificación que describe la actualización de los datos del usuario, así como todos los campos que se pueden cambiar:
Anteriormente analizamos los complementos para la validación dentro de las pruebas, sin embargo, para casos más generales hay módulos de validación ajv (npm) y json-schema (rubygem), usémoslos y escribamos un controlador con validación.
Node.js (Koa)
Este es un ejemplo para Koa , el sucesor de Express, pero para Express, el código será similar.
import Router from 'koa-router'; import Ajv from 'ajv'; import { schemas } from './schemas'; const router = new Router();
En este ejemplo, si los datos de entrada no cumplen con la especificación, el servidor devolverá una respuesta 500 Internal Server Error al cliente. Para evitar que esto suceda, podemos interceptar el error del validador y formar nuestra propia respuesta, que contendrá información más detallada sobre campos específicos que no han pasado la prueba, y también cumplirá con la especificación .
Agregue una descripción del modelo FieldsValidationError en el archivo FieldsValidationError :
Error {error: b, message} InvalidField {name, message} FieldsValidationError < Error {fields: InvalidField[]}
Y ahora lo indicamos como una de las posibles respuestas de nuestro punto final:
PATCH /users/:id {user: UserUpdate} => 200 {success: b} => 422 FieldsValidationError
Este enfoque le permitirá escribir pruebas unitarias que verifiquen la corrección de la formación de errores con datos incorrectos recibidos del cliente.
3. Serialización de modelos.
Casi todos los marcos de servidores modernos usan ORM de una forma u otra. Esto significa que la mayoría de los recursos utilizados en la API dentro del sistema se presentan en forma de modelos, sus instancias y colecciones.
El proceso de generar una representación JSON de estas entidades para su transmisión en la respuesta API se llama serialización . Hay una serie de complementos para diferentes marcos que realizan funciones de serialización, por ejemplo: sequelize-to-json (npm), act_as_api (rubygem), jsonapi-rails (rubygem). De hecho, estos complementos permiten que un modelo específico especifique una lista de campos que deben incluirse en el objeto JSON, así como reglas adicionales, por ejemplo, para cambiarles el nombre o calcular valores dinámicamente.
Las dificultades comienzan cuando necesitamos tener varias representaciones JSON diferentes del mismo modelo o cuando un objeto contiene entidades anidadas: asociaciones. Es necesario heredar, reutilizar y vincular los serializadores .
Los diferentes módulos resuelven estos problemas de diferentes maneras, pero pensemos, ¿puede la especificación ayudarnos nuevamente? De hecho, de hecho, toda la información sobre los requisitos para las representaciones JSON, todas las combinaciones posibles de campos, incluidas las entidades anidadas, ya están en él. Entonces podemos escribir un serializador automático.
Le traigo a su atención un pequeño módulo de secuenciación-serialización (npm), que le permite hacer esto para los modelos Sequelize. Toma una instancia del modelo o una matriz, así como el circuito requerido, y construye iterativamente un objeto serializado, teniendo en cuenta todos los campos requeridos y utilizando circuitos anidados para las entidades asociadas.
Por lo tanto, supongamos que tenemos que devolver de la API a todos los usuarios que tienen publicaciones de blog, incluidos los comentarios sobre esas publicaciones. Describimos esto usando la siguiente especificación:
Ahora podemos construir la consulta usando Sequelize y devolver un objeto serializado que coincida exactamente con la especificación que se acaba de describir:
import Router from 'koa-router'; import serialize from 'sequelize-serialize'; import { schemas } from './schemas'; const router = new Router(); router.get('/blog/users', async (ctx) => { const users = await User.findAll({ include: [{ association: User.posts, required: true, include: [Post.comments] }] }); ctx.body = serialize(users, schemas.UserWithPosts); });
Es casi mágico, ¿verdad?
4. Mecanografía estática
Si eres tan genial que estás usando TypeScript o Flow, es posible que ya te hayas preguntado: "¿Qué pasa con mis queridos tipos estáticos?" . Usando los módulos sw2dts o swagger-to-flowtype, puede generar todas las definiciones necesarias basadas en esquemas JSON y usarlas para la tipificación estática de pruebas, datos de entrada y serializadores.
tinyspec -j sw2dts ./swagger.json -o Api.d.ts --namespace Api
Ahora podemos usar tipos en controladores:
router.patch('/users/:id', async (ctx) => { // Specify type for request data object const userData: Api.UserUpdate = ctx.request.body.user; // Run spec validation await validate(schemas.UserUpdate, userData); // Query the database const user = await User.findById(ctx.params.id); await user.update(userData); // Return serialized result const serialized: Api.User = serialize(user, schemas.User); ctx.body = { user: serialized }; });
Y en las pruebas:
it('Update user', async () => { // Static check for test input data. const updateData: Api.UserUpdate = { name: MODIFIED }; const res = await request.patch('/users/1', { user: updateData }); // Type helper for request response: const user: Api.User = res.body.user; expect(user).to.be.validWithSchema(schemas.User); expect(user).to.containSubset(updateData); });
Tenga en cuenta que las definiciones de tipo generadas se pueden usar no solo en el proyecto API en sí, sino también en proyectos de aplicación cliente para describir los tipos de funciones en las que funciona la API. Los desarrolladores de clientes angulares estarán especialmente satisfechos con este regalo.
5. Tipo de conversión de cadena de consulta
Si por alguna razón su API acepta solicitudes con el tipo MIME application/x-www-form-urlencoded y no application/json , el cuerpo de la solicitud se verá así:
param1=value¶m2=777¶m3=false
Lo mismo se aplica a los parámetros de consulta (por ejemplo, en solicitudes GET). En este caso, el servidor web no podrá reconocer automáticamente los tipos: todos los datos estarán en forma de cadenas ( aquí hay una discusión en el repositorio del módulo qpm npm), por lo que después del análisis obtendrá el siguiente objeto:
{ param1: 'value', param2: '777', param3: 'false' }
En este caso, la solicitud no se validará de acuerdo con el esquema, lo que significa que será necesario verificar manualmente que cada parámetro tenga el formato correcto y llevarlo al tipo requerido.
Como puede suponer, esto se puede hacer utilizando los mismos esquemas de nuestra especificación. Imagine que tenemos un punto final y un esquema de este tipo:
Aquí hay un ejemplo de una solicitud a dicho punto final
GET /posts?search=needle&offset=10&limit=1&filter[isRead]=true
Escribamos una función castQuery , que castQuery todos los parámetros a los tipos necesarios para nosotros. Se verá más o menos así:
function castQuery(query, schema) { _.mapValues(query, (value, key) => { const { type } = schema.properties[key] || {}; if (!value || !type) { return value; } switch (type) { case 'integer': return parseInt(value, 10); case 'number': return parseFloat(value); case 'boolean': return value !== 'false'; default: return value; } }); }
Su implementación más completa con soporte para esquemas anidados, matrices y tipos null está disponible en cast-with-schema (npm). Ahora podemos usarlo en nuestro código:
router.get('/posts', async (ctx) => {
Observe cómo de las cuatro líneas del código de punto final, los tres usan esquemas de la especificación.
Mejores prácticas
Esquemas separados para crear y modificar
Por lo general, los esquemas que describen la respuesta del servidor son diferentes de los que describen la entrada utilizada para crear y modificar modelos. Por ejemplo, la lista de campos disponibles para las POST y PATCH debe estar estrictamente limitada, mientras que en las solicitudes PATCH , generalmente todos los campos del esquema se hacen opcionales. Los esquemas que determinan la respuesta pueden ser más gratuitos.
La generación automática de puntos finales CRUDL de tinyspec utiliza los postfixes New y Update . User* se pueden definir de la siguiente manera:
User {id, email, name, isAdmin: b} UserNew !{email, name} UserUpdate !{email?, name?}
Intente no usar los mismos esquemas para diferentes tipos de acciones para evitar problemas de seguridad accidentales debido a la reutilización o herencia de esquemas antiguos.
Semántica en nombres de esquema
El contenido de los mismos modelos puede variar en diferentes puntos finales. Utilice los postfixes With* y For* en los nombres de esquema para mostrar en qué se diferencian y para qué sirven. En modelos tinyspec también se pueden heredar unos de otros. Por ejemplo:
User {name, surname} UserWithPhotos < User {photos: Photo[]} UserForAdmin < User {id, email, lastLoginAt: d}
Los postfixes pueden ser variados y combinados. Lo principal es que su nombre refleja la esencia y simplifica la familiaridad con la documentación.
Separación de puntos finales por tipo de cliente
A menudo, los mismos puntos finales devuelven datos diferentes según el tipo de cliente o la función del usuario que accede al punto final. Por ejemplo, los puntos finales de GET /users y GET /messages pueden ser muy diferentes para los usuarios de su aplicación móvil y para los administradores de back office. Al mismo tiempo, cambiar el nombre del punto final en sí puede ser una complicación excesiva.
Para describir el mismo punto final varias veces, puede agregar su tipo entre paréntesis después de la ruta. Además, es útil usar etiquetas: esto ayudará a dividir la documentación de sus puntos finales en grupos, cada uno de los cuales estará diseñado para un grupo específico de clientes de su API. Por ejemplo:
Mobile app: GET /users (mobile) => UserForMobile[] CRM admin panel: GET /users (admin) => UserForAdmin[]
Documentación API REST
Una vez que tenga una especificación en formato tinyspec u OpenAPI, puede generar documentación hermosa en HTML y publicarla para deleite de los desarrolladores que usan su API.
Además de los servicios en la nube mencionados anteriormente, existen herramientas de CLI que convierten OpenAPI 2.0 a HTML y PDF, después de lo cual puede descargarlo a cualquier alojamiento estático. Ejemplos:
¿Sabes más ejemplos? Compártelos en los comentarios.
Desafortunadamente, OpenAPI 3.0, lanzado hace un año, todavía tiene un soporte deficiente y no pude encontrar ejemplos decentes de documentación basados en él: ni entre soluciones en la nube ni entre herramientas de CLI. Por la misma razón, OpenAPI 3.0 aún no es compatible con tinyspec.
Publicar en GitHub
Una de las formas más fáciles de publicar documentación es GitHub Pages . Simplemente habilite el soporte de páginas estáticas para el directorio /docs en la configuración de su repositorio y almacene la documentación HTML en esta carpeta.
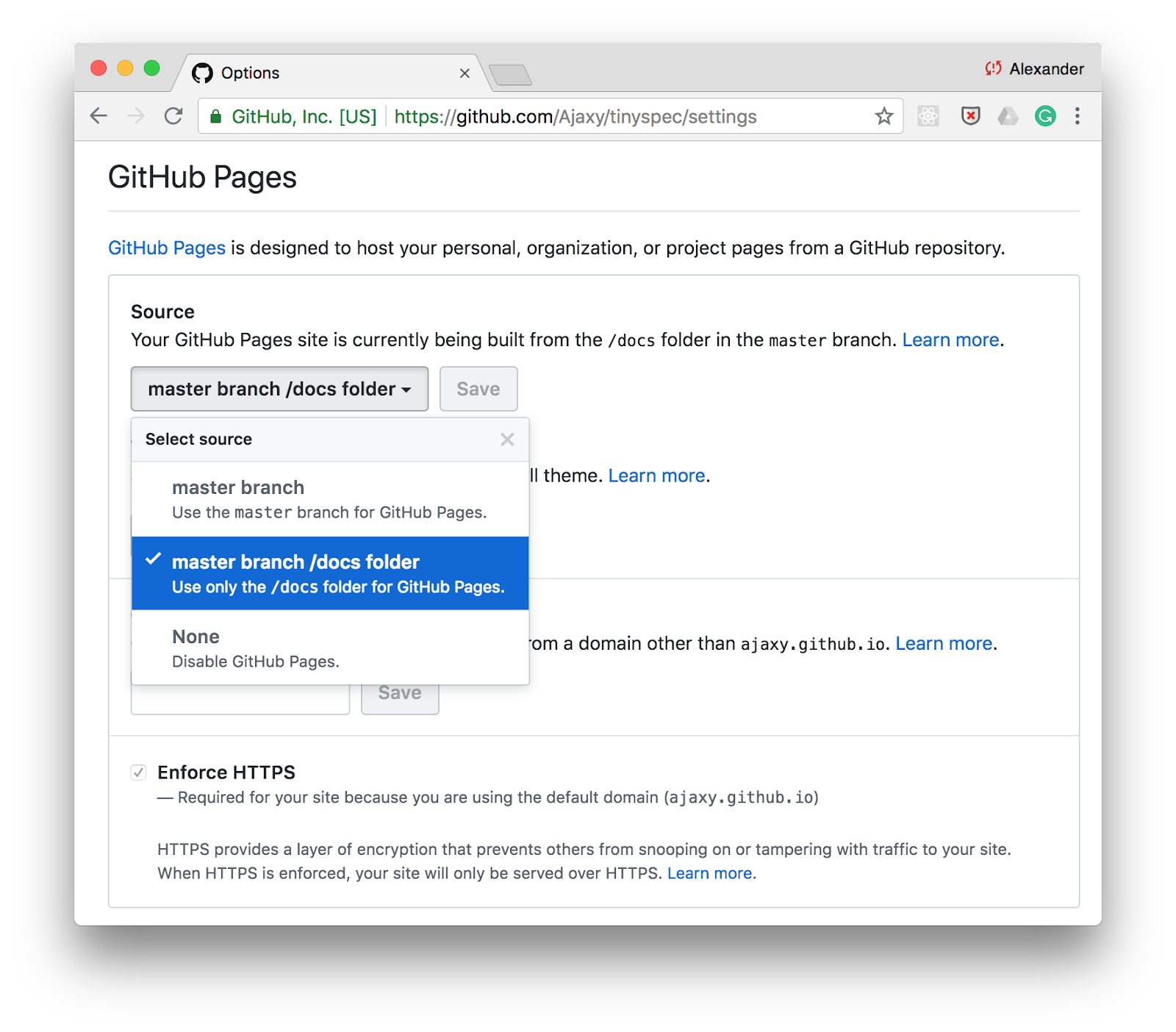
Puede agregar un comando para generar documentación a través de tinyspec u otra herramienta CLI en los scripts en package.json y actualizar la documentación con cada confirmación:
"scripts": { "docs": "tinyspec -h -o docs/", "precommit": "npm run docs" }
Integración continua
Puede incluir la generación de documentación en el ciclo de CI y publicarla, por ejemplo, en Amazon S3 en diferentes direcciones según el entorno o la versión de su API, por ejemplo: /docs/2.0 , /docs/stable , /docs/staging .
Nube Tinyspec
Si le gustó la sintaxis de tinyspec, puede registrarse como uno de los primeros usuarios en tinyspec.cloud . Vamos a construir sobre una base un servicio en la nube y CLI para la publicación automática de documentación con una amplia selección de plantillas y la capacidad de desarrollar nuestras propias plantillas.
Conclusión
Desarrollar una API REST es quizás la actividad más divertida de todas las que existen en el proceso de trabajar en servicios móviles y web modernos. No existe un zoológico de navegadores, sistemas operativos y tamaños de pantalla, todo está completamente bajo nuestro control, "a su alcance".
Mantener la especificación actual y las bonificaciones en forma de varias automatizaciones, que se proporcionan al mismo tiempo, hacen que este proceso sea aún más agradable. Tal API se vuelve estructurada, transparente y confiable.
De hecho, incluso si estamos comprometidos en la creación de un mito, ¿por qué no lo hacemos hermoso?