Las tareas largas y monótonas a menudo se encuentran en el trabajo, para cuya solución se necesita mucha gente. Por ejemplo, descifre varios cientos de grabaciones de audio, marque miles de imágenes o filtre comentarios, cuyo número aumenta constantemente. Para estos fines, puede mantener docenas de empleados a tiempo completo. Pero todos ellos deben ser encontrados, seleccionados, motivados, controlados, asegurados para el desarrollo y el crecimiento profesional. Y si se reduce la cantidad de trabajo, tendrán que volverse a entrenar o despedir.
En muchos casos, especialmente si no se requiere capacitación especial, los ejecutores de
Toloka , la plataforma de crowdsourcing de Yandex, pueden realizar dicho trabajo. Este sistema es fácilmente escalable: si hay menos tareas de un cliente, los usuarios irán a otro, si el número de tareas aumenta, solo serán felices.
Debajo del corte hay ejemplos de cómo Toloka ayuda a Yandex y otras compañías a desarrollar sus productos. Se puede hacer clic en todos los encabezados: los enlaces conducen a informes.

MIPT utilizó Toloka para evaluar la calidad de los bots de chat como parte del hackathon DeepHack.Chat. Involucró 6 equipos. La tarea consistía en desarrollar un chatbot que pudiera hablar sobre sí mismo en función del perfil que se le proporcionara con una breve descripción de las características personales.

Tolokers y bots recibieron perfiles y tuvieron que fingir ser una persona en el diálogo, cuya descripción se dio allí, contar sobre ellos mismos y aprender más sobre el interlocutor. Los participantes del diálogo no vieron los perfiles de los demás.
Solo los usuarios que pasaron la prueba de conocimiento del idioma inglés pudieron realizar la tarea, ya que todos los bots de chat dentro del hackathon hablaban inglés. Era imposible organizar un diálogo con el bot directamente a través de Toloka, por lo que en la tarea se proporcionó el enlace al canal de Telegram donde se lanzó el bot de chat.
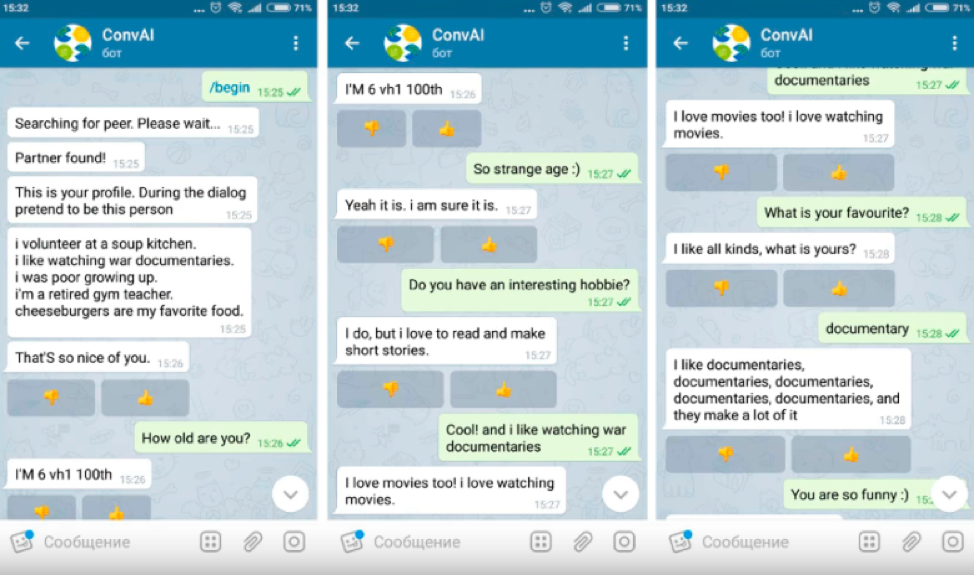
Después de hablar con el bot, el usuario recibió una ID de diálogo que, junto con la evaluación del diálogo, se insertó en el Toloka como respuesta.
Para excluir a los delincuentes deshonestos, fue necesario verificar qué tan bien el usuario habló con el bot. Para hacer esto, creamos una tarea separada, en cuyo marco los intérpretes leen los cuadros de diálogo y evalúan el comportamiento del usuario, es decir, el tirador de la tarea anterior.
Durante el hackathon, los equipos cargaron sus bots de chat. Durante el día, los tolkers los probaron, contaron la calidad e informaron el puntaje a los equipos, después de lo cual los desarrolladores editaron el comportamiento de sus sistemas.
En cuatro días, los sistemas de hackathon han mejorado significativamente. El primer día, los bots tuvieron respuestas inapropiadas y duplicadas; al cuarto día, las respuestas se volvieron más adecuadas y detalladas. Bots aprendió no solo a responder preguntas, sino también a hacer las suyas.
Diálogo de ejemplo el primer día del hackathon:

En el cuarto día:

Estadísticas: la evaluación duró 4 días, participaron alrededor de 200 tolkers y se procesaron 1800 diálogos. Gastaron $ 180 en la primera tarea y $ 15 en la segunda. El porcentaje de diálogos válidos resultó ser mayor que cuando se trabaja con voluntarios.
Una tarea importante del creador del dron es enseñarle a extraer información sobre los objetos circundantes a partir de los datos que recibe de los sensores. Durante el viaje, el automóvil registra todo lo que ve a su alrededor. Estos datos se vierten en la nube, donde se realiza el análisis primario, y luego van al postprocesamiento, que incluye el marcado. Los datos etiquetados se envían a los algoritmos de aprendizaje automático, el resultado se devuelve a la máquina y el ciclo se repite, mejorando la calidad del reconocimiento de objetos.
Hay muchos objetos diferentes en la ciudad, todos ellos deben marcarse. Esta tarea requiere ciertas habilidades y toma mucho tiempo, y se necesitan decenas de miles de imágenes para entrenar una red neuronal. Se pueden tomar de conjuntos de datos abiertos, pero se recopilan en el extranjero, por lo que las imágenes no corresponden a la realidad rusa. Puede comprar imágenes etiquetadas por tan solo $ 4, pero el marcado en Tolok fue aproximadamente 10 veces más barato.
Dado que en Tolok puede incrustar cualquier interfaz y transferir datos a través de API, los desarrolladores han insertado su propio editor visual, que tiene capas, transparencia, selección, ampliación, división en clases. Esto aumentó varias veces la velocidad y la calidad del marcado.
Además, la API le permite dividir automáticamente las tareas en tareas más simples y recopilar el resultado de las piezas. Por ejemplo, antes de marcar una imagen, puede marcar qué objetos hay en ella. Esto le dará una idea de en qué clases marcar la imagen.
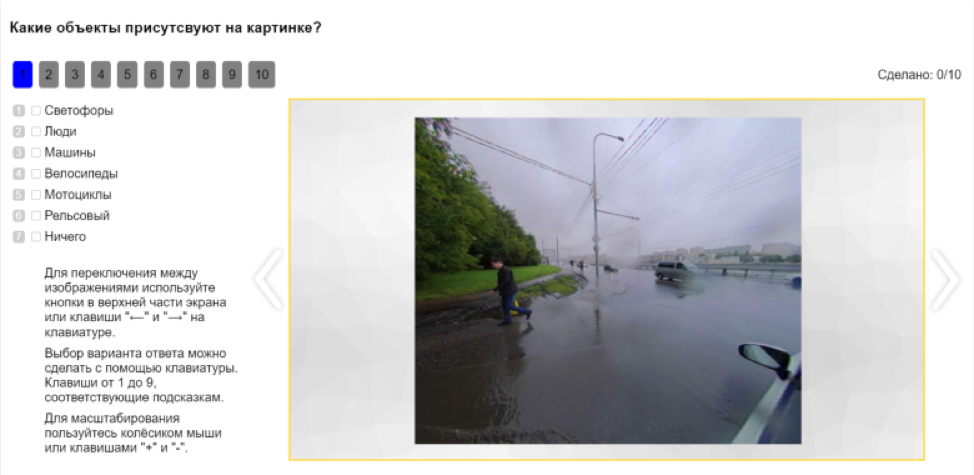
Después de eso, los objetos en la imagen se pueden clasificar. Por ejemplo, para ofrecer a los tiradores una selección de imágenes donde hay personas, y pedirles que aclaren si se trata de peatones, ciclistas, motociclistas u otra persona.

Cuando el tolker ha completado el marcado, debe verificarse. Para hacer esto, se crean tareas de prueba que se ofrecen a otros artistas.

No solo los tolokers, sino también las redes neuronales se dedican al marcado. Algunos de ellos ya han aprendido a hacer frente a esta tarea no peor que las personas. Pero la calidad de su trabajo también necesita ser evaluada. Por lo tanto, en las tareas, además de las imágenes marcadas con tolokers, también están marcadas con una red neuronal.
Por lo tanto, Toloka se integra directamente en el proceso de aprendizaje de las redes neuronales y se convierte en parte de la tubería de todo el aprendizaje automático.
Ozon usa Toloka para crear una muestra de referencia. Esto es para varios propósitos.
• Evaluación de calidad del nuevo motor de búsqueda.
• Determinar el modelo de clasificación más efectivo.
• Mejora de la calidad del algoritmo de búsqueda mediante el aprendizaje automático.
La primera muestra de prueba se realizó manualmente: tomamos 100 solicitudes y las marcamos nosotros mismos. Incluso una muestra tan pequeña ayudó a identificar problemas de búsqueda y determinar los criterios de evaluación. La compañía quería crear su propia herramienta para evaluar la calidad de la búsqueda, contratar asesores y capacitarlos, pero eso tomaría demasiado tiempo, por lo que decidimos elegir una plataforma de crowdsourcing lista para usar.
La etapa más difícil en la preparación de la tarea para los tolokers fue la capacitación, incluso los empleados de la compañía no pudieron hacer la primera tarea de prueba. Tras recibir comentarios del equipo, desarrollamos una nueva prueba: creamos capacitación desde tareas simples a complejas y compiladas teniendo en cuenta las cualidades importantes del artista para la empresa.
Para eliminar errores, Ozon realizó una prueba de funcionamiento. La tarea consistió en tres bloques: capacitación, control con un umbral del 60% de respuestas correctas y la tarea principal con un umbral del 80% de respuestas correctas. Para mejorar la calidad de la muestra, se ofreció una tarea a cinco artistas.
Estadísticas de prueba: 350 tareas en 40 minutos. El presupuesto fue de $ 12. A la primera etapa asistieron 147 artistas, 77 fueron entrenados, 12 obtuvieron la habilidad y realizaron la tarea principal.
El escenario del lanzamiento principal se ha vuelto más complicado: no solo participaron nuevos tokers, sino también aquellos que recibieron la habilidad necesaria en la etapa de prueba. El primero fue a lo largo de la cadena estándar, el segundo fue inmediatamente admitido a las tareas principales. En el lanzamiento principal, se agregaron habilidades adicionales: el porcentaje de respuestas correctas en la muestra principal y la opinión mayoritaria. La asignación todavía se ofreció a cinco artistas.
Principales estadísticas de lanzamiento: 40,000 empleos en un mes. El presupuesto ascendió a 1150 dólares. Vinieron al proyecto 1117 tolkers, 18 obtuvieron habilidades, 6 obtuvieron acceso al grupo principal más grande y lo evaluaron.
Ahora el trabajo de Ozon en Tolok es así:
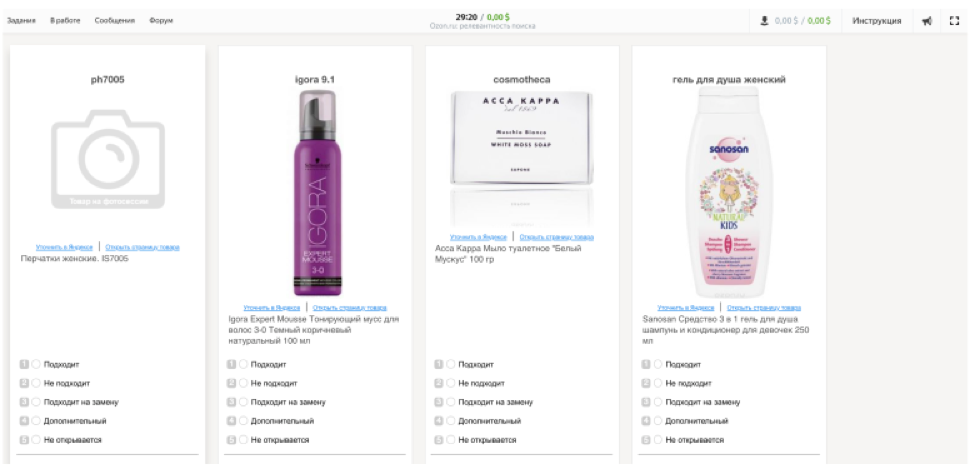
El contratista ve la consulta de búsqueda y 9 productos de los resultados de búsqueda. Su tarea es elegir una de las clasificaciones: "adecuada", "no adecuada", "adecuada para reemplazo", "adicional", "no se abre". Una calificación final ayuda a identificar problemas técnicos en el sitio. Para simular el comportamiento del usuario con la mayor precisión posible, los desarrolladores a través del iframe recrearon la interfaz de la tienda en línea.
Paralelamente al lanzamiento de la tarea en Toloka, el marcado de las consultas de búsqueda se realizó utilizando las reglas. Se hizo hincapié en las consultas populares para mejorar principalmente la emisión de las mismas.
El marcado por las reglas hizo posible obtener rápidamente datos en un pequeño número de consultas y mostró buenos resultados en las principales consultas. Pero también hubo desventajas: las solicitudes ambiguas no se pueden estimar por reglas, hay muchas situaciones controvertidas. Además, a la larga, este método ha sido bastante costoso.
El marcado con la ayuda de personas cubre estas desventajas. En Tolok, puede recopilar las opiniones de un gran número de artistas, la evaluación es más gradual, lo que le permite trabajar más profundamente con la extradición. Después de la configuración inicial, la plataforma funciona de manera estable y procesa grandes cantidades de datos.
El trabajo manual y los mecanismos de inteligencia artificial no se oponen entre sí. Mientras más inteligencia artificial se desarrolle, más trabajo manual se requiere para su entrenamiento. Por otro lado, las redes neuronales mejor entrenadas son, las tareas más rutinarias pueden automatizarse, salvando a una persona de ellas.
Casi cualquier tarea, incluso voluminosa, puede dividirse en muchas pequeñas y construirse sobre la base de crowdsourcing. La mayoría de las tareas que se resuelven en
Tolok son el primer paso hacia modelos de capacitación y procesos automatizados sobre los datos recopilados por las personas.
En la próxima publicación sobre este tema, hablaremos sobre cómo se utiliza el crowdsourcing para capacitar a Alice, moderar comentarios y aplicar reglas en Yandex.Buses.