El aprendizaje automático le permite hacer que el servicio sea mucho más conveniente para los usuarios. No es tan difícil comenzar a implementar recomendaciones, los primeros resultados se pueden obtener incluso sin tener una infraestructura establecida, lo principal es comenzar. Y solo entonces para construir un sistema a gran escala. Así comenzó todo en Booking.com. Y lo que resultó, qué enfoques se están utilizando ahora, cómo se están introduciendo los modelos en producción, cuáles monitorear, dijo Viktor Bilyk a HighLoad ++ Siberia. Los posibles errores y problemas no se dejaron atrás en el informe, ayudará a alguien a sortear las aguas poco profundas y a alguien se le ocurrirán nuevas ideas.
 Acerca del orador:
Acerca del orador: Victor Bilyk introduce productos de aprendizaje automático en operaciones comerciales en Booking.com.
Primero, veamos dónde utiliza Booking.com el aprendizaje automático en qué productos.
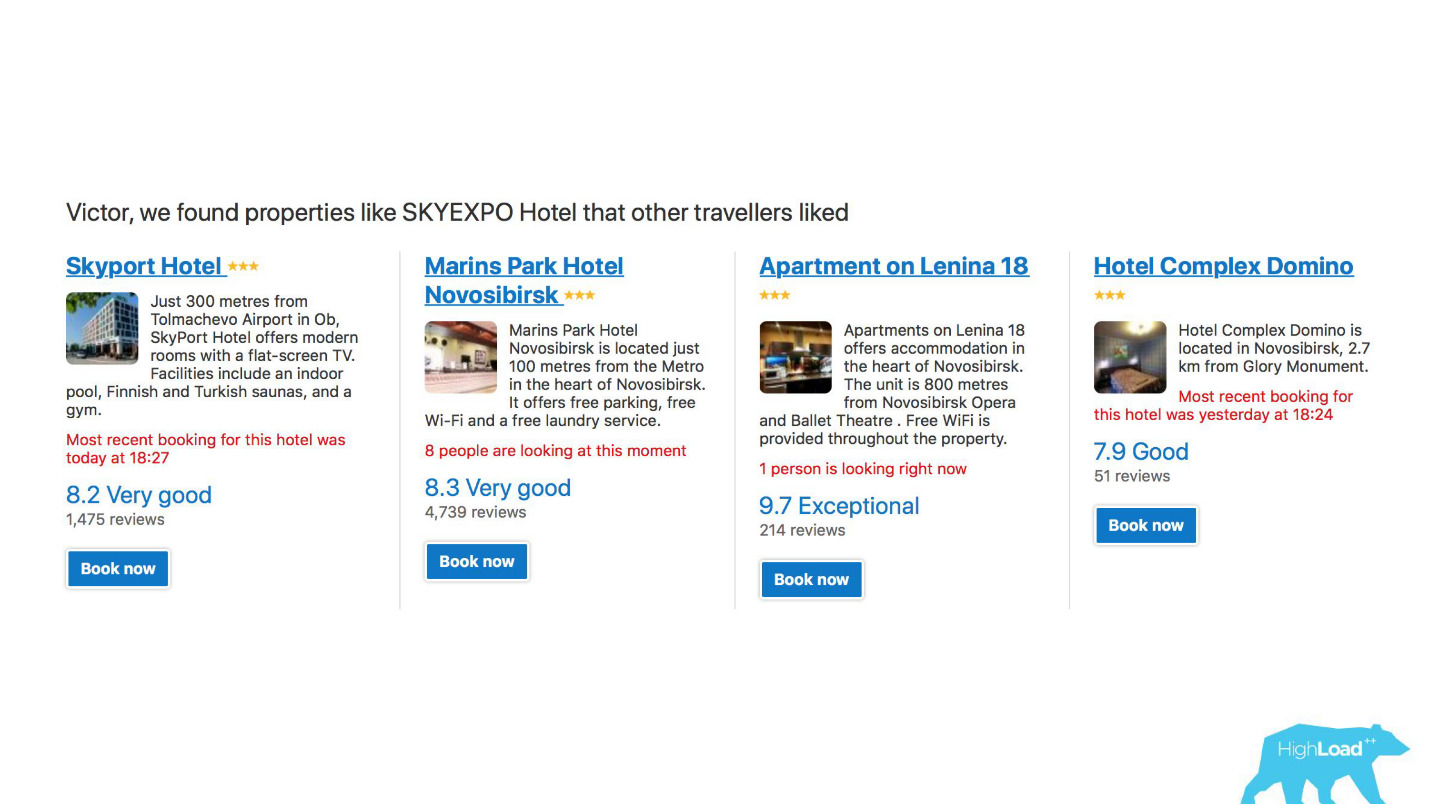
En primer lugar, este es un gran número de sistemas de recomendación para hoteles, destinos, fechas y en diferentes puntos del embudo de ventas y en diferentes contextos. Por ejemplo, estamos tratando de adivinar a dónde irá cuando no haya ingresado nada en la línea de búsqueda.

Esta es una captura de pantalla en mi cuenta, y definitivamente visitaré dos de estas áreas este año.
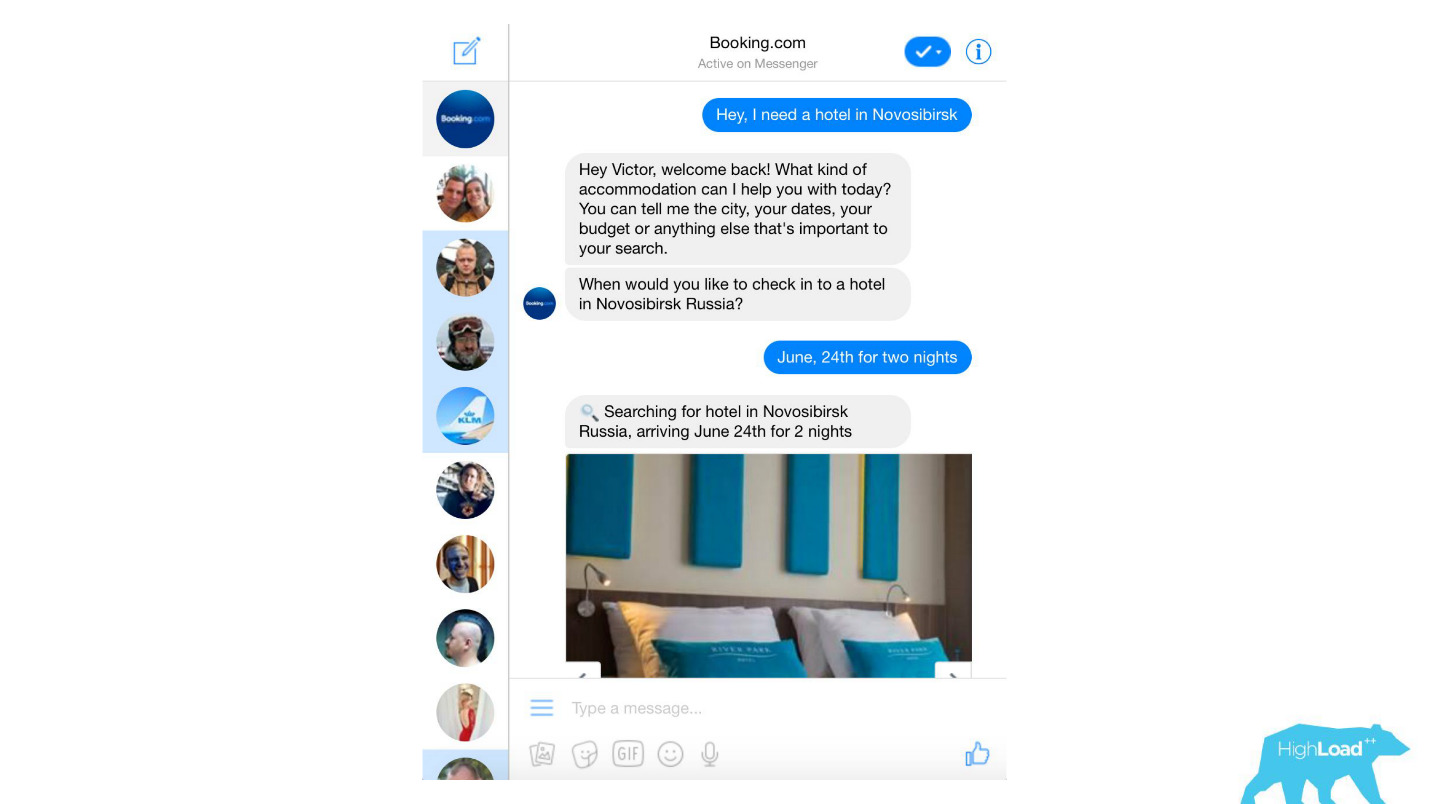
Procesamos casi cualquier mensaje de texto de los clientes, desde filtros de spam banales hasta productos sofisticados como Assistant y ChatToBook, que utilizan modelos para determinar intenciones y reconocer entidades. Además, hay modelos que no son tan notables, por ejemplo, la detección de fraude.
Analizamos opiniones. Las modelos nos dicen por qué la gente va, por ejemplo, a Berlín.
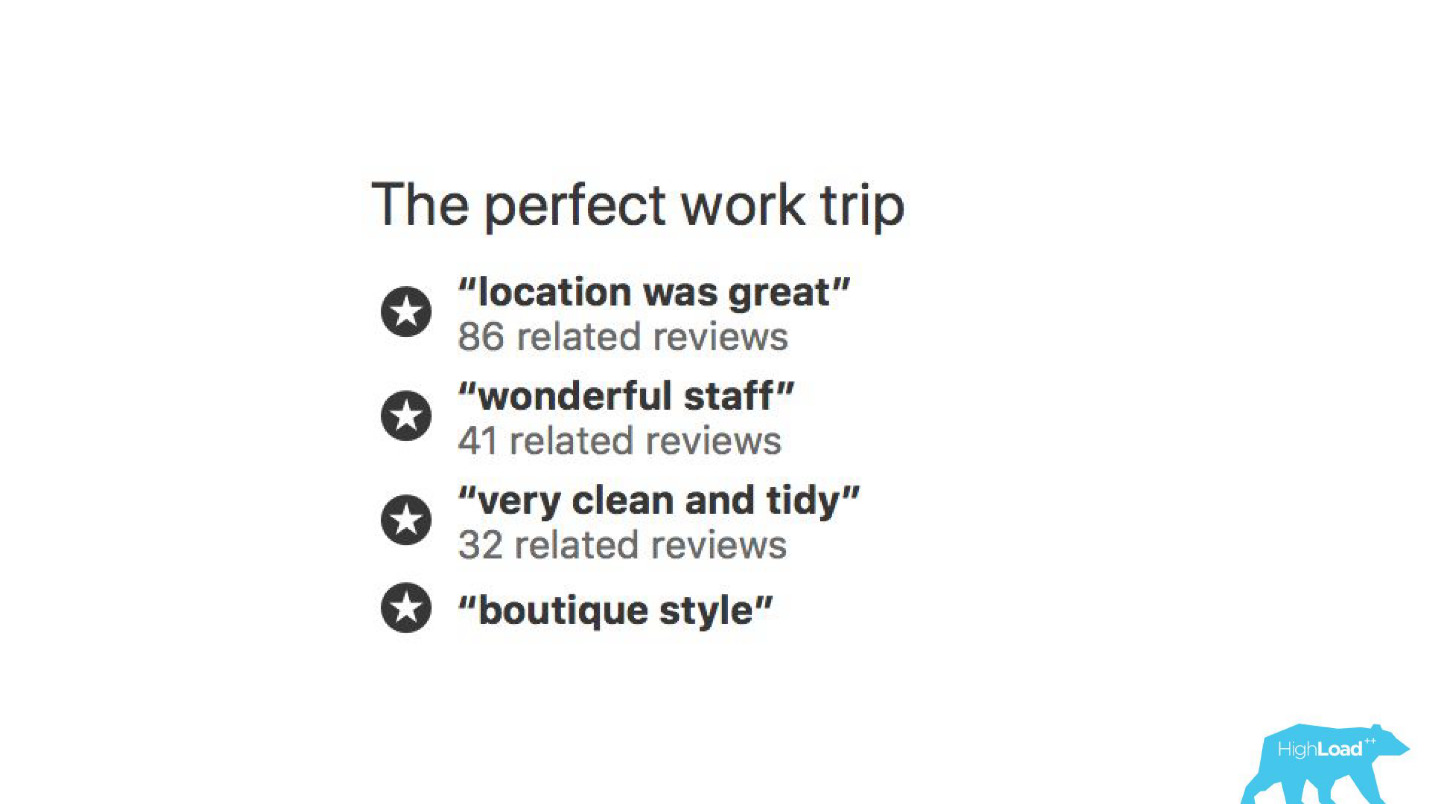
Con la ayuda de modelos de aprendizaje automático, se analiza por qué se elogia al hotel para que no tenga que leer miles de comentarios usted mismo.
En algunos lugares de nuestra interfaz, casi todas las piezas están vinculadas a las predicciones de algunos modelos. Por ejemplo, aquí estamos tratando de predecir cuándo se agotará el hotel.
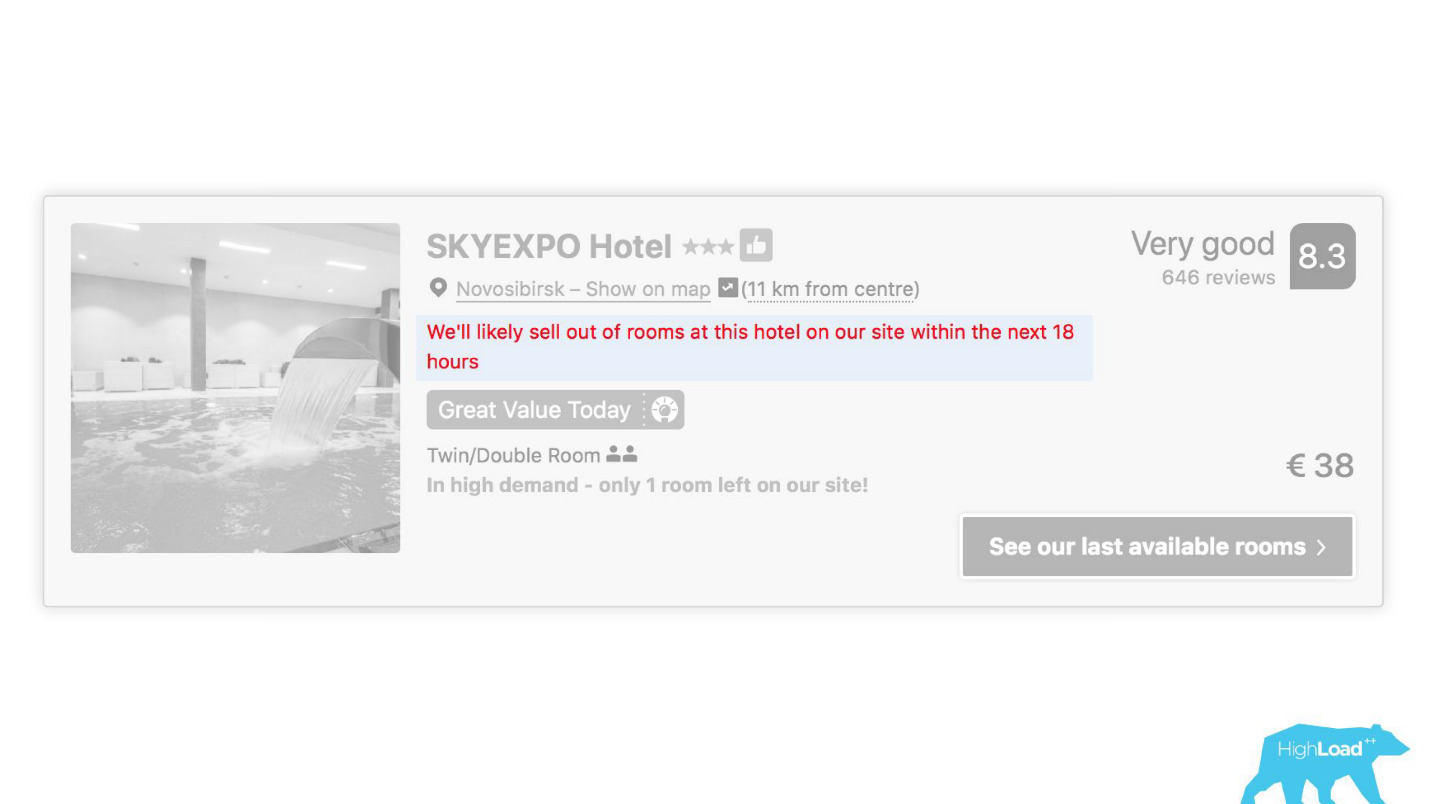
A menudo nos encontramos en lo cierto: después de 19 horas, la última habitación ya está reservada.
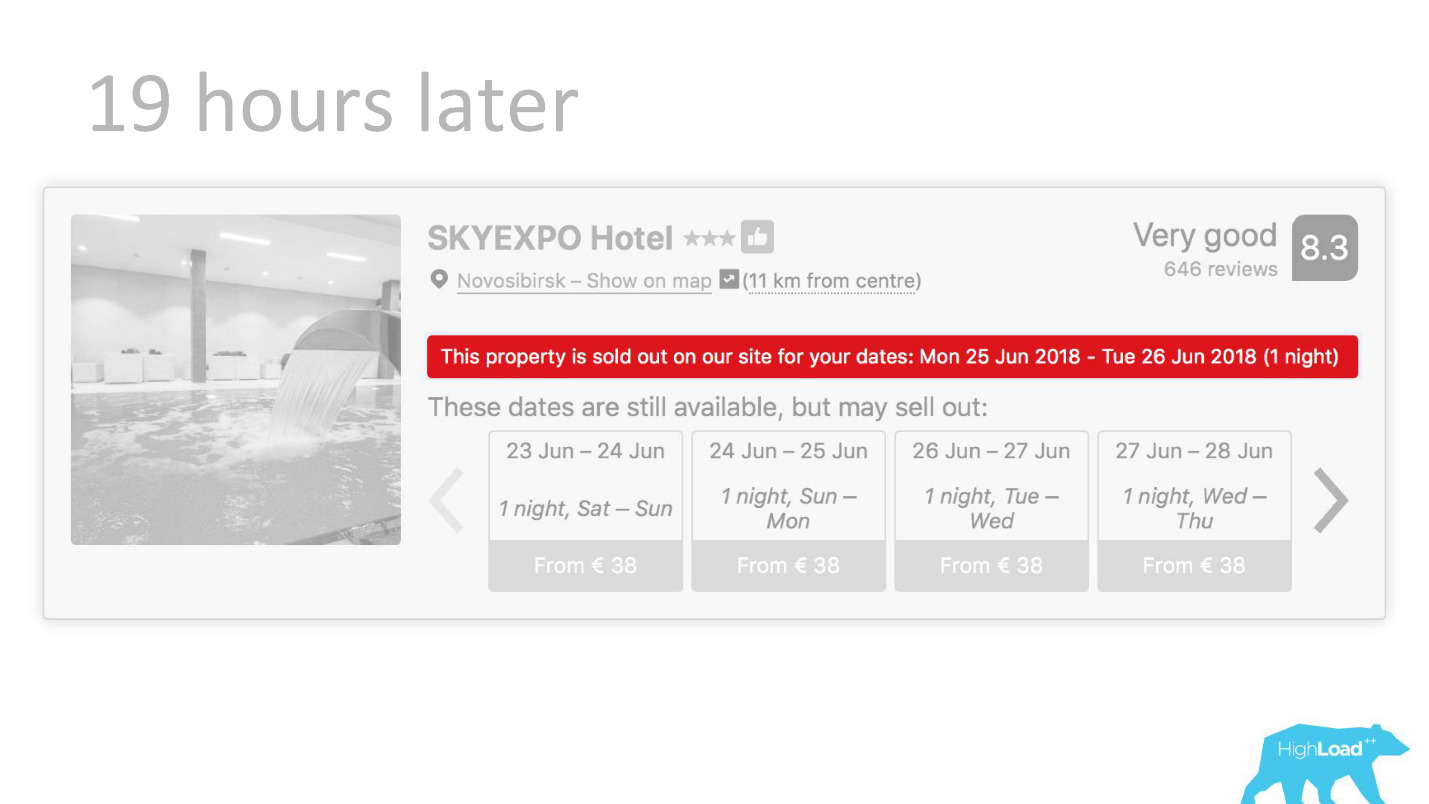
O, por ejemplo, - la insignia "Oferta favorable". Aquí estamos tratando de formalizar lo subjetivo: qué es una oferta tan ventajosa. ¿Cómo entender que los precios establecidos por el hotel para estas fechas son buenos? Después de todo, esto, además del precio, depende de muchos factores, como servicios adicionales y, a menudo, incluso de razones externas, si, por ejemplo, la Copa del Mundo o una gran conferencia técnica se celebra en esta ciudad ahora.
Inicio de implementación
Rebobinemos hace unos años, en 2015. Algunos de los productos de los que hablé ya existen. Además, el sistema del que hablaré hoy todavía no lo es. ¿Cómo se llevó a cabo la implementación en ese momento? Las cosas fueron, francamente, no muy. El hecho es que tuvimos un gran problema, parte del cual es técnico y parte es organizacional.
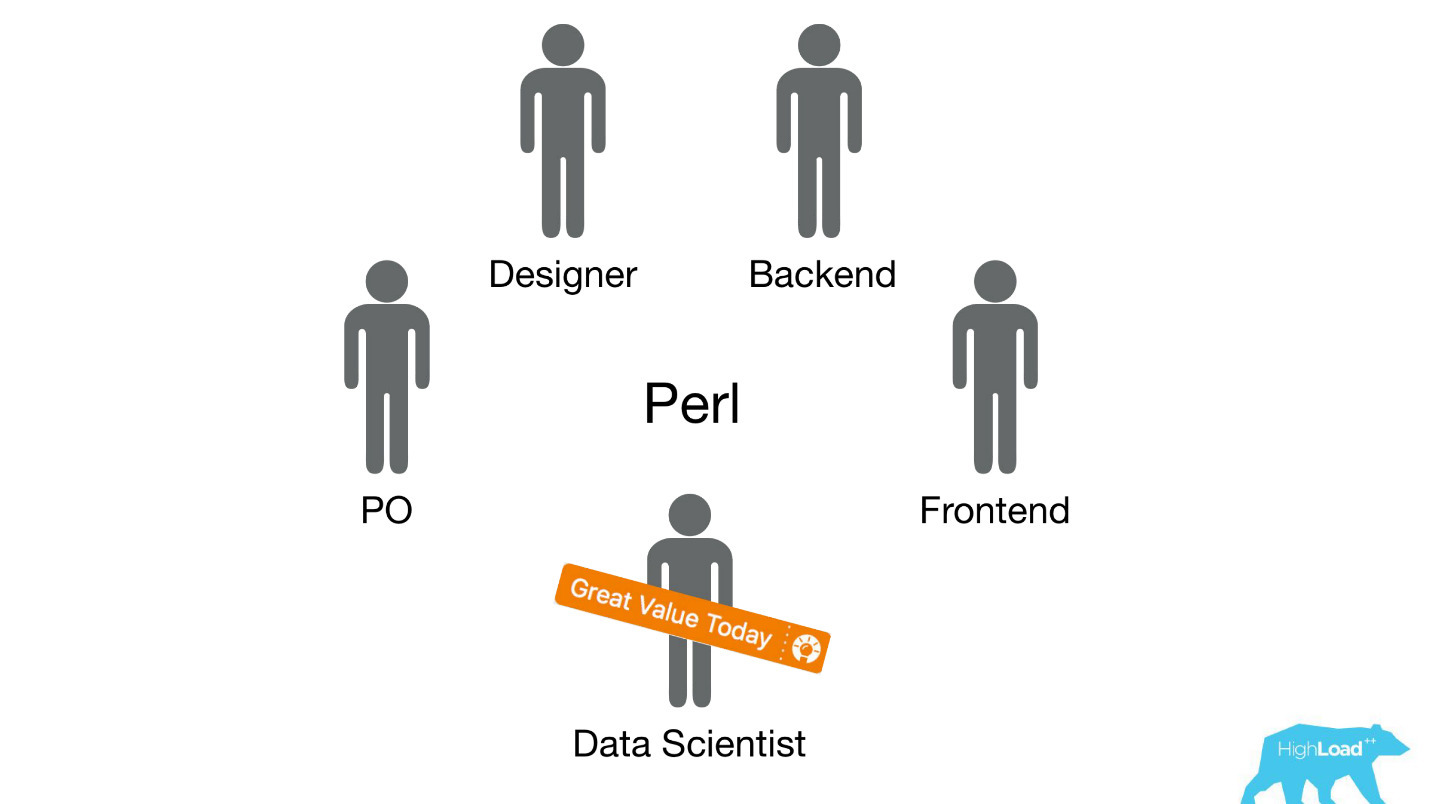
Enviamos científicos de datos a equipos interfuncionales existentes que trabajan en un problema específico del usuario y esperamos que mejoren el producto de alguna manera.
Muy a menudo, estas piezas del producto se construyeron en la pila de Perl. Hay un problema obvio con Perl: no está diseñado para la informática intensiva, y nuestro backend ya está cargado de otras cosas. Además, el desarrollo de sistemas serios que resolverían este problema no podría priorizarse dentro del equipo, porque el enfoque del equipo está en resolver un problema del usuario, y no en resolver un problema del usuario mediante el aprendizaje automático. Por lo tanto, el propietario del producto (PO) se opondría mucho a esto.
Veamos cómo sucedió entonces.
Solo había dos opciones: lo sé con certeza, porque en ese momento solo estaba trabajando en un equipo así y ayudé a los Científicos de Datos a llevar sus primeros modelos a la batalla.
La primera opción era la
materialización de las predicciones . Supongamos que hay un modelo muy simple con solo dos características:
- país donde se encuentra el visitante;
- La ciudad en la que busca un hotel.
Necesitamos predecir la probabilidad de algún evento. Simplemente explotamos todos los vectores de entrada: por ejemplo, 100,000 ciudades, 200 países, un total de 20 millones de líneas en MySQL. Parece una opción totalmente funcional para la producción de algunos sistemas de clasificación pequeños u otros modelos simples.

Otra opción es
incrustar las predicciones directamente en el código de fondo . Existen grandes limitaciones (cientos, quizás miles de coeficientes), eso es todo lo que podemos permitirnos.

Obviamente, ni una ni la otra manera le permite sacar al menos algún tipo de modelo complejo en producción. Esto limitó el centro de datos y los éxitos que pudieron lograr al mejorar los productos. Obviamente, este problema tuvo que resolverse de alguna manera.
Servicio de predicción
Lo primero que hicimos fue un servicio de predicción. Probablemente, la arquitectura más simple que se haya mostrado en Habré y HighLoad ++ es más baja.
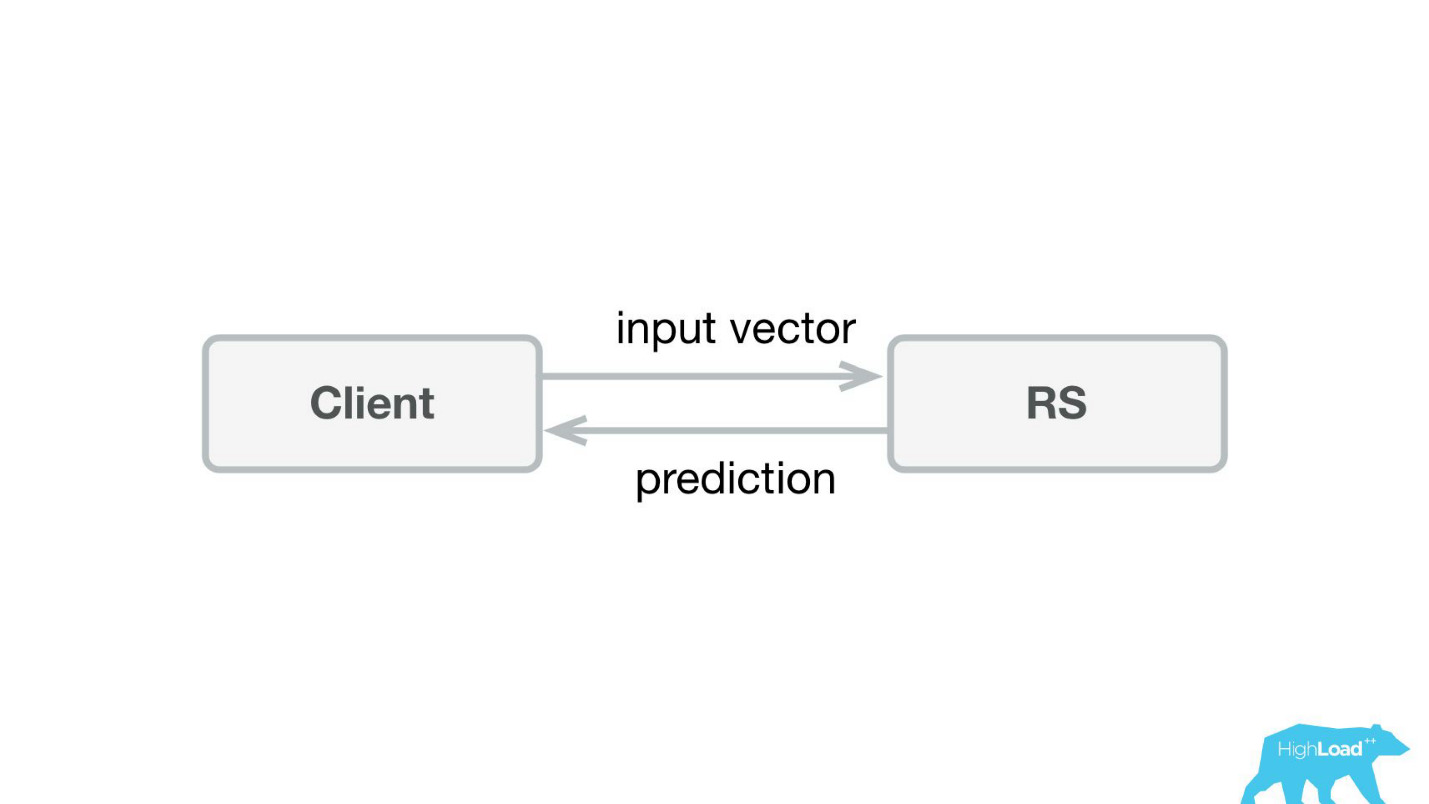
Escribimos una pequeña aplicación en Scala + Akka + Spray que simplemente tomó los vectores entrantes y devolvió la predicción. De hecho, estoy un poco astuto: el sistema era un poco más complicado, porque de alguna manera necesitábamos monitorearlo y desplegarlo. En realidad, todo se veía así:
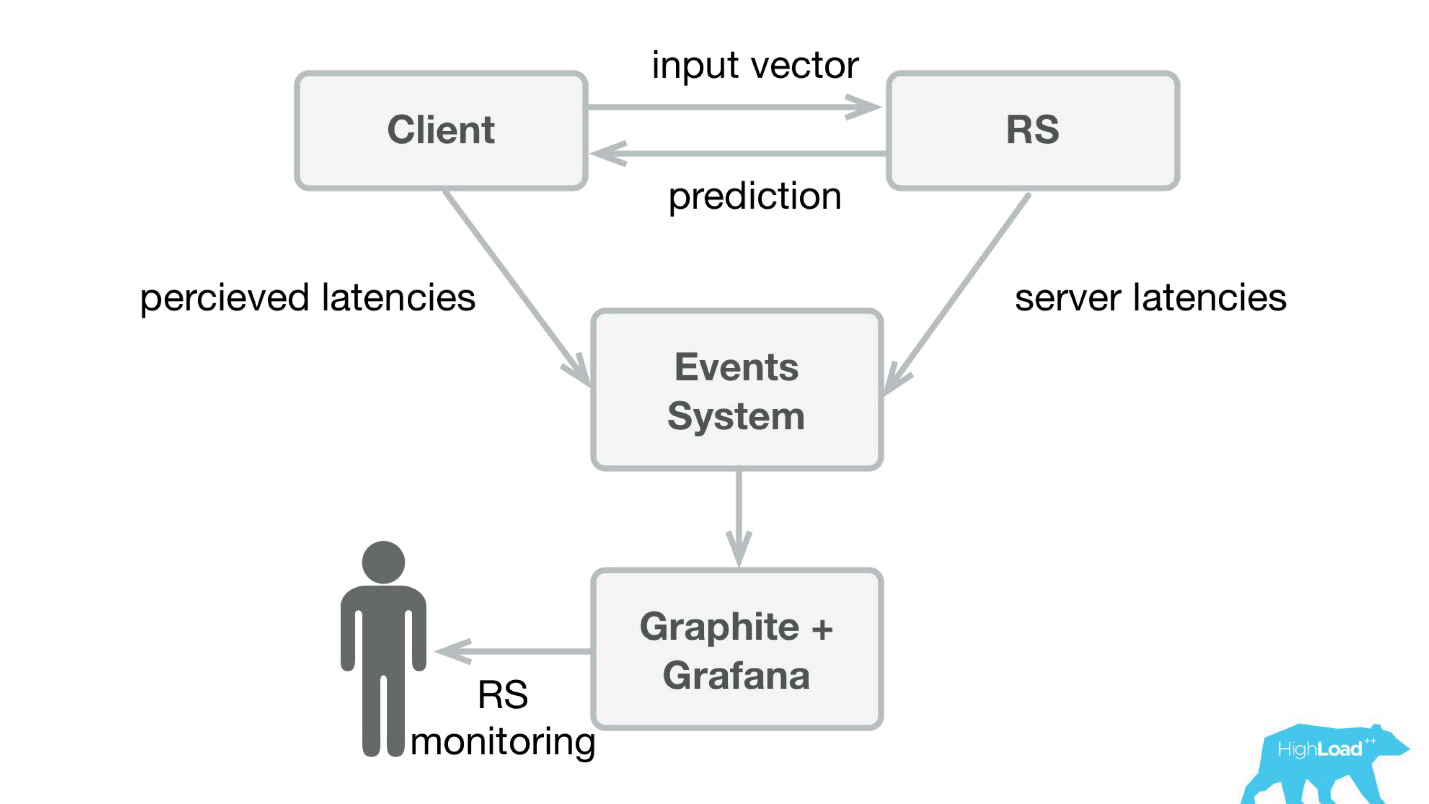
Booking.com tiene un sistema de eventos, algo así como una revista para todos los sistemas. Es muy fácil escribir allí, y esta secuencia es muy fácil de redirigir. Al principio, necesitábamos enviar telemetría de clientes a Graphite y Grafana con latencias percibidas e información detallada del lado del servidor.

Creamos bibliotecas de clientes simples para Perl: ocultamos el RPC completo en una llamada local, pusimos varios modelos allí y el servicio comenzó a despegar. Vender dicho producto fue bastante simple, porque tuvimos la oportunidad
de presentar modelos más complejos y pasar mucho menos tiempo .
Los científicos de datos comenzaron a trabajar con muchas menos restricciones, y en algunos casos el trabajo de los back -ders se redujo a una sola línea.
Predicciones de producto
Pero volvamos brevemente a cómo usamos estas predicciones en el producto.
Hay un modelo que hace predicciones basadas en hechos conocidos. Según esta predicción, de alguna manera estamos cambiando la interfaz de usuario. Este, por supuesto, no es el único escenario para el uso del aprendizaje automático en nuestra empresa, sino que es bastante común.
¿Cuál es el problema de lanzar tales funciones? La cuestión es que estas son dos cosas en una botella: un modelo y un cambio en la interfaz de usuario. Es muy difícil separar los efectos de ambos.
Imagine que lanza la insignia de "Oferta favorable" como parte de un experimento AB. Si no despega (no hay un cambio estadísticamente significativo en las métricas objetivo), no se sabe cuál es el problema: una insignia incomprensible, pequeña, discreta o un mal modelo.
Además, los modelos pueden degradarse, y puede haber muchas razones para esto. Lo que funcionó ayer no necesariamente funciona hoy. Además, estamos constantemente en modo de arranque en frío, conectando constantemente nuevas ciudades y hoteles, personas de nuevas ciudades vienen a nosotros. Necesitamos entender de alguna manera que el modelo aún se generaliza bien en estas partes del espacio entrante.

El caso más probable de degradación del modelo más recientemente conocido fue la historia con Alex. Lo más probable es que, como resultado del reentrenamiento, ella comenzó a comprender ruidos aleatorios, como una solicitud para reírse, y comenzó a reírse por la noche, asustando a los propietarios.
Monitoreo de predicciones
Para monitorear las predicciones, modificamos ligeramente nuestro sistema (diagrama a continuación). Del mismo modo, desde el sistema de eventos, redirigimos la transmisión a Hadoop y comenzamos a guardar, además de todo lo que guardamos antes, todos los vectores de entrada y todas las predicciones hechas por nuestro sistema. Luego, usando Oozie, los agregamos en MySQL y desde allí los mostramos con una pequeña aplicación web a aquellos que estén interesados en algún tipo de características cualitativas de los modelos.
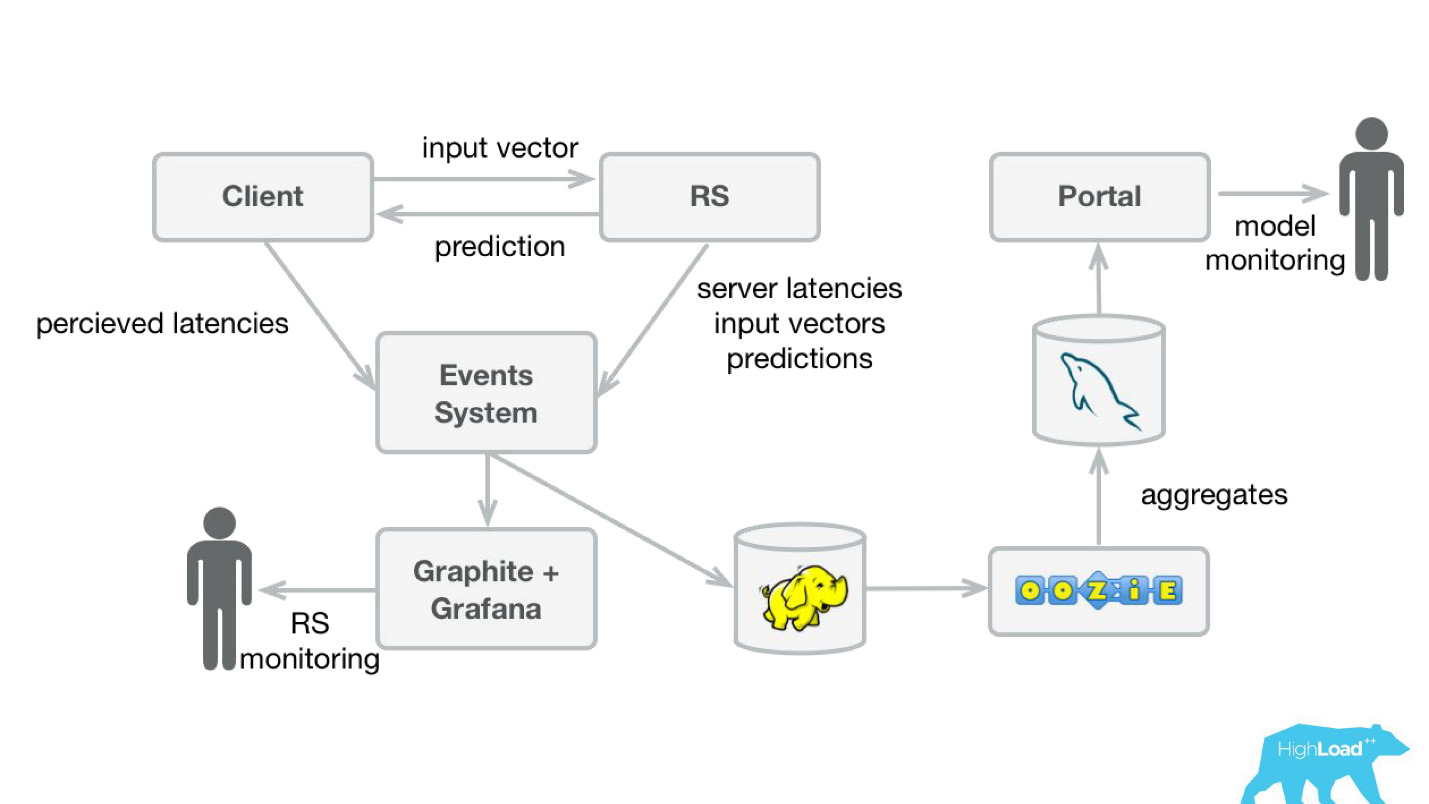
Sin embargo, es importante averiguar qué mostrar allí. El caso es que en nuestro caso es muy difícil calcular las métricas habituales utilizadas en el entrenamiento de modelos, porque a menudo tenemos un gran retraso en las etiquetas.
Considera esto como un ejemplo. Queremos predecir si el usuario se va de vacaciones solo o con su familia. Necesitamos esta predicción cuando una persona elige un hotel, pero solo podemos descubrir la verdad en un año. Después de irse de vacaciones, el usuario recibirá una invitación para dejar una reseña, donde, entre otras cosas, habrá una pregunta si estuvo allí solo o con su familia.
Es decir, debe almacenar en algún lugar todas las predicciones hechas durante el año, e incluso para poder encontrar coincidencias rápidamente con las etiquetas entrantes. Parecía una inversión muy seria, tal vez incluso una gran inversión. Por lo tanto, hasta que resolvamos este problema, decidimos hacer algo más simple.
Este "más simple" resultó ser solo un
histograma de predicciones hechas por el modelo.
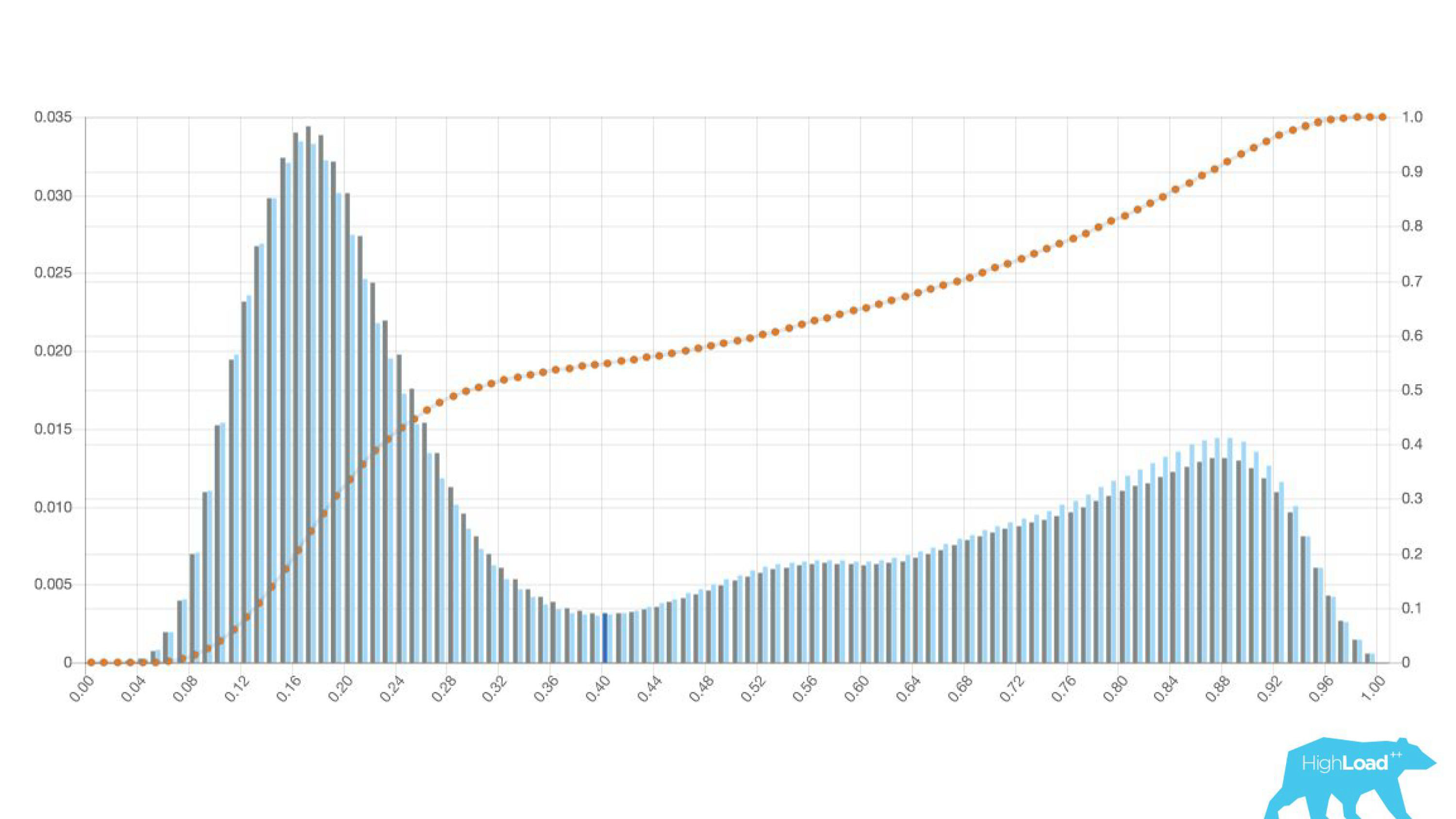
Arriba en el gráfico hay una regresión logística que predice si el usuario cambiará la fecha de su viaje o no. Se puede ver que divide a los usuarios en dos clases: a la izquierda, la colina es la que no hará esto; la colina a la derecha son quienes lo hacen.
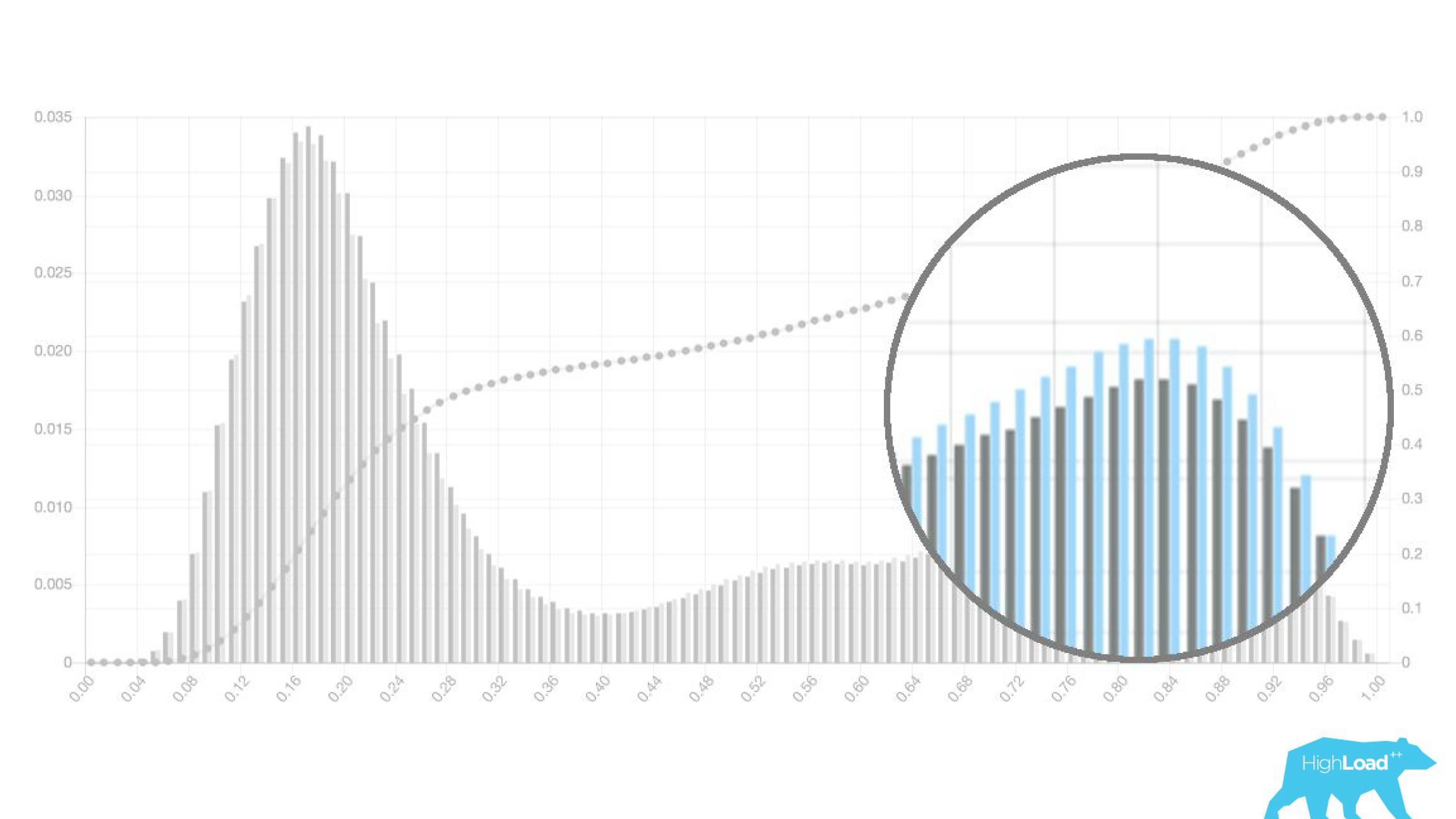
De hecho, incluso mostramos dos gráficos: uno para el período actual y el otro para el anterior. Se ve claramente que esta semana (este es un gráfico semanal) el modelo predice un cambio de fechas un poco más a menudo. Es difícil decir con certeza si es estacionalidad o esa misma degradación con el tiempo.
Esto condujo a un cambio en el trabajo de datacientes, que dejaron de involucrar a otras personas y comenzaron a iterar sus modelos más rápido. Enviaron modelos a producción en seco junto con ingenieros de back-end. Es decir, se recolectaron los vectores, el modelo hizo una predicción, pero estas predicciones no se utilizaron de ninguna manera.
En el caso de una insignia, simplemente no mostramos nada, como antes, sino que recopilamos estadísticas. Esto nos permitió no perder tiempo en proyectos fallidos por adelantado. Hemos liberado tiempo para front-end y diseñadores para otros experimentos.
Mientras el centro de datos no esté seguro de que el modelo funciona de la manera que desea, simplemente no involucra a otros en este proceso.Es interesante ver cómo cambian los gráficos en diferentes secciones.
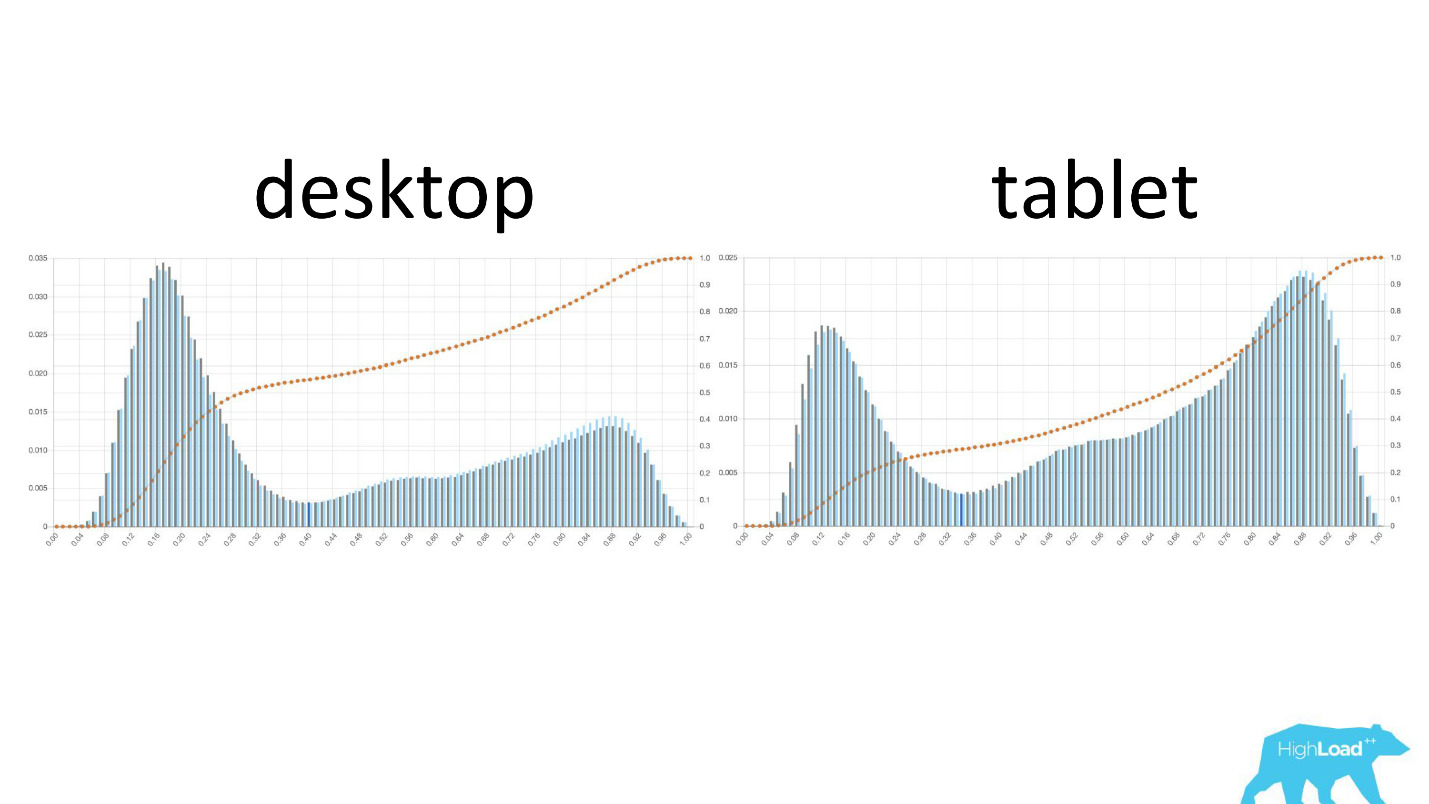
A la izquierda está la probabilidad de cambiar las fechas en el escritorio, a la derecha está en las tabletas. Se ve claramente que en tabletas el modelo predice un cambio más probable de fechas. Esto se debe probablemente al hecho de que la tableta se usa a menudo para planificar viajes y con menos frecuencia para reservas.
También es interesante ver cómo cambian estos gráficos a medida que los usuarios se mueven a través del embudo de ventas.
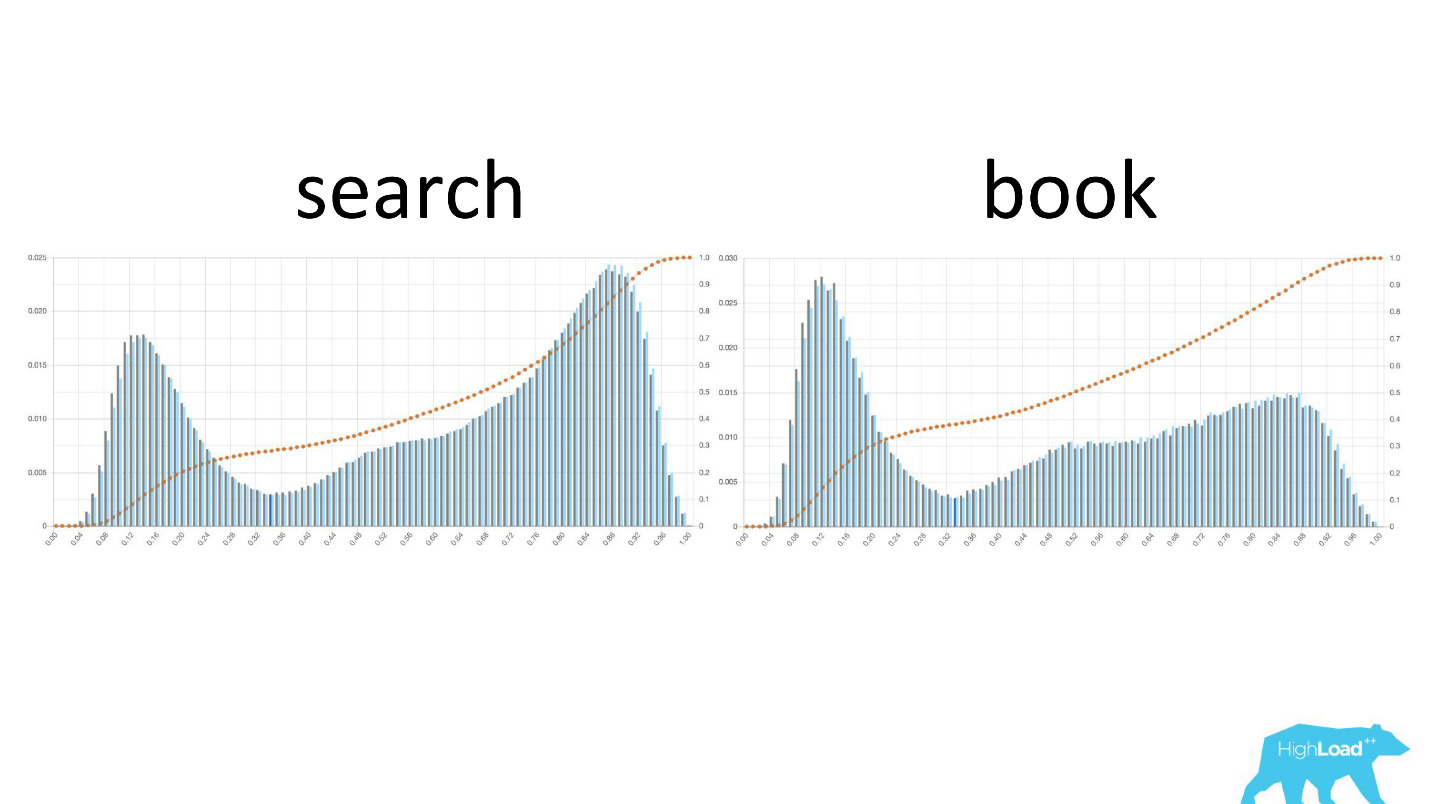
A la izquierda está la probabilidad de cambiar las fechas en la página de búsqueda, a la derecha está en la primera página de reserva. Se puede ver que un número mucho mayor de personas que ya han decidido sus fechas llegan a la página de reserva.
Pero estos fueron buenos gráficos. ¿Cómo son los malos? De maneras muy diferentes. A veces es solo ruido, a veces es una colina enorme, lo que significa que el modelo no puede separar efectivamente dos clases de predicciones.

A veces estos son picos enormes.
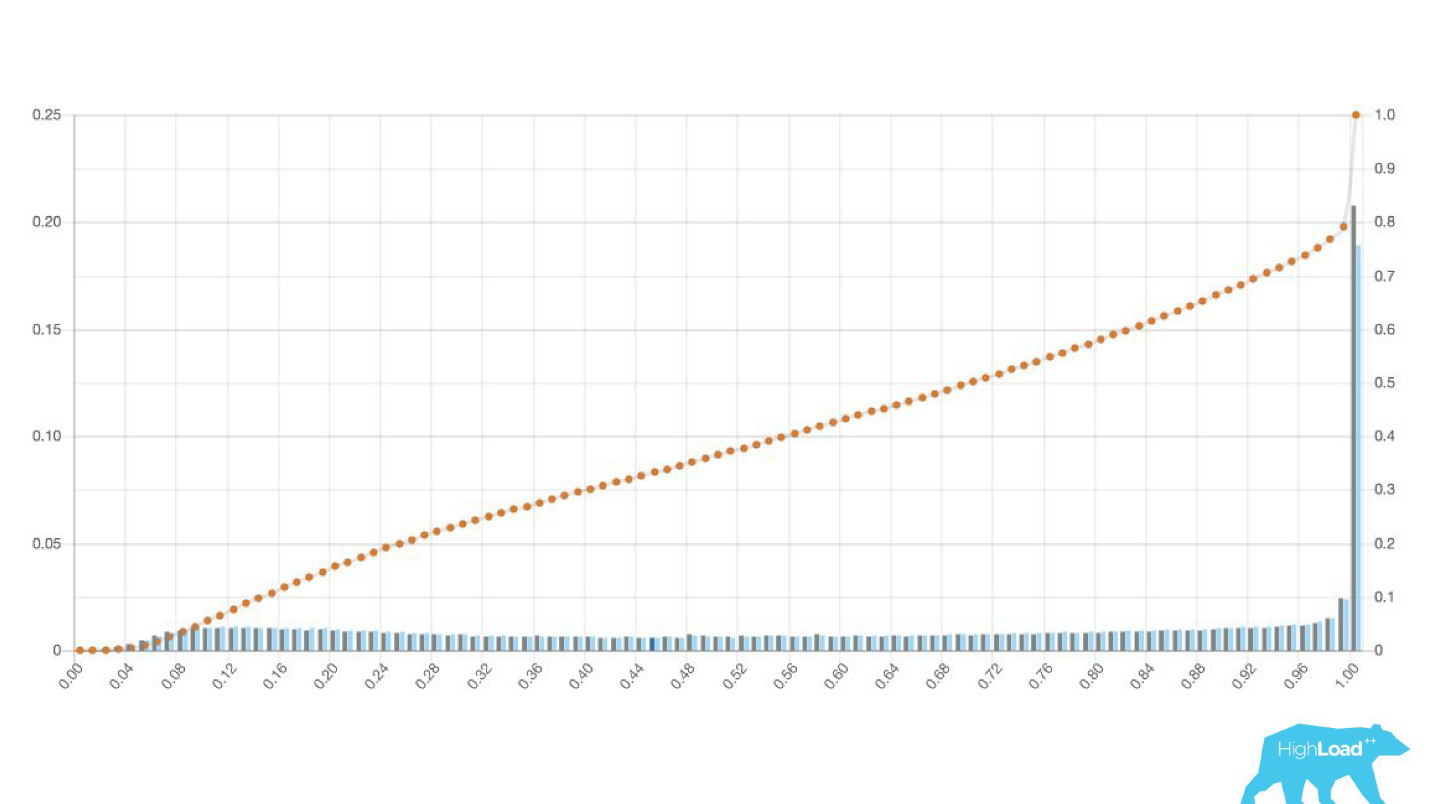
Esto también es una regresión logística, y hasta cierto punto mostró una hermosa imagen con dos colinas, pero una mañana se volvió así.
Para comprender lo que sucedió dentro, debe comprender cómo se calcula la regresión logística.
Referencia rápida
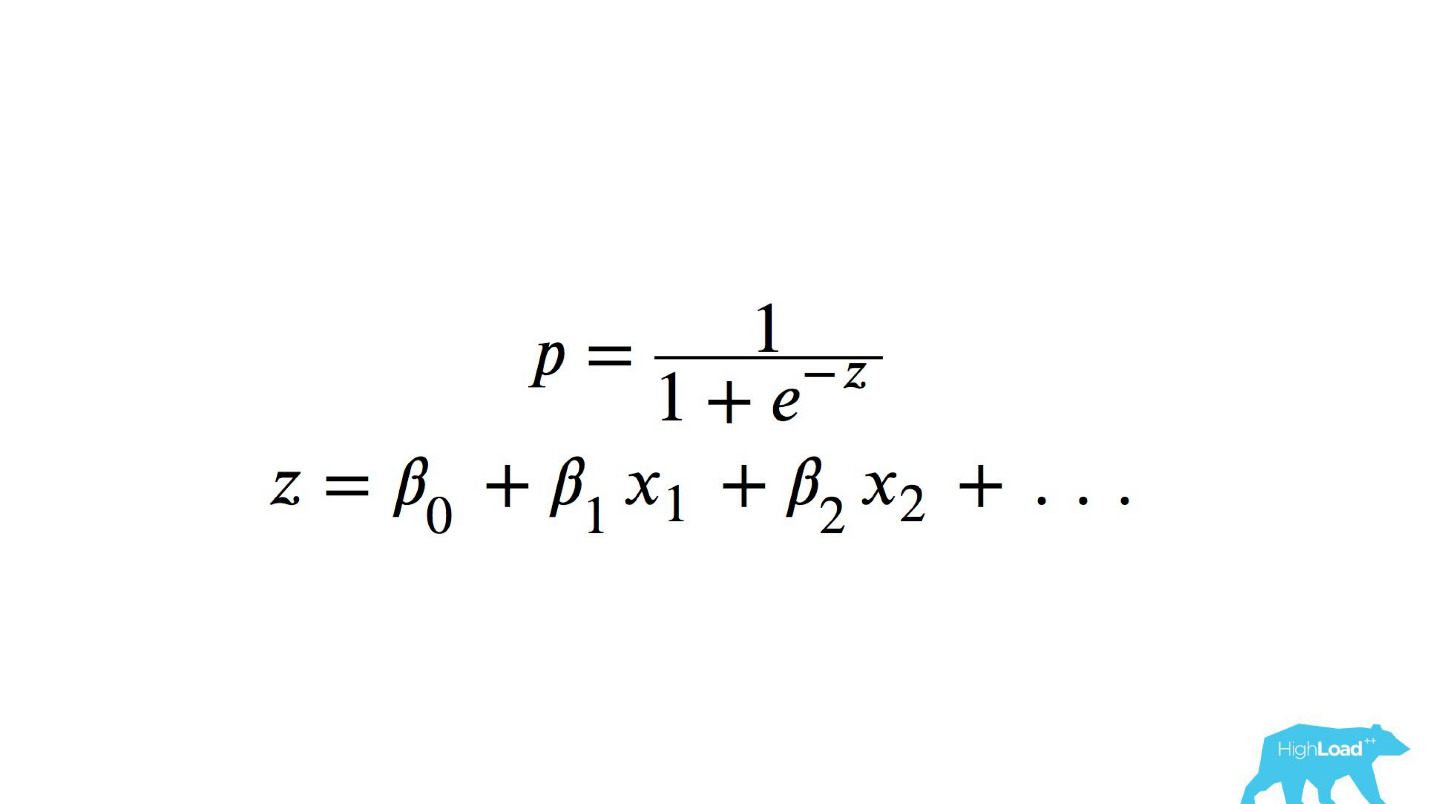
Esta es una función logística del producto escalar, donde x
n son algunas características. Una de estas características era el precio de una noche en un hotel (en euros).
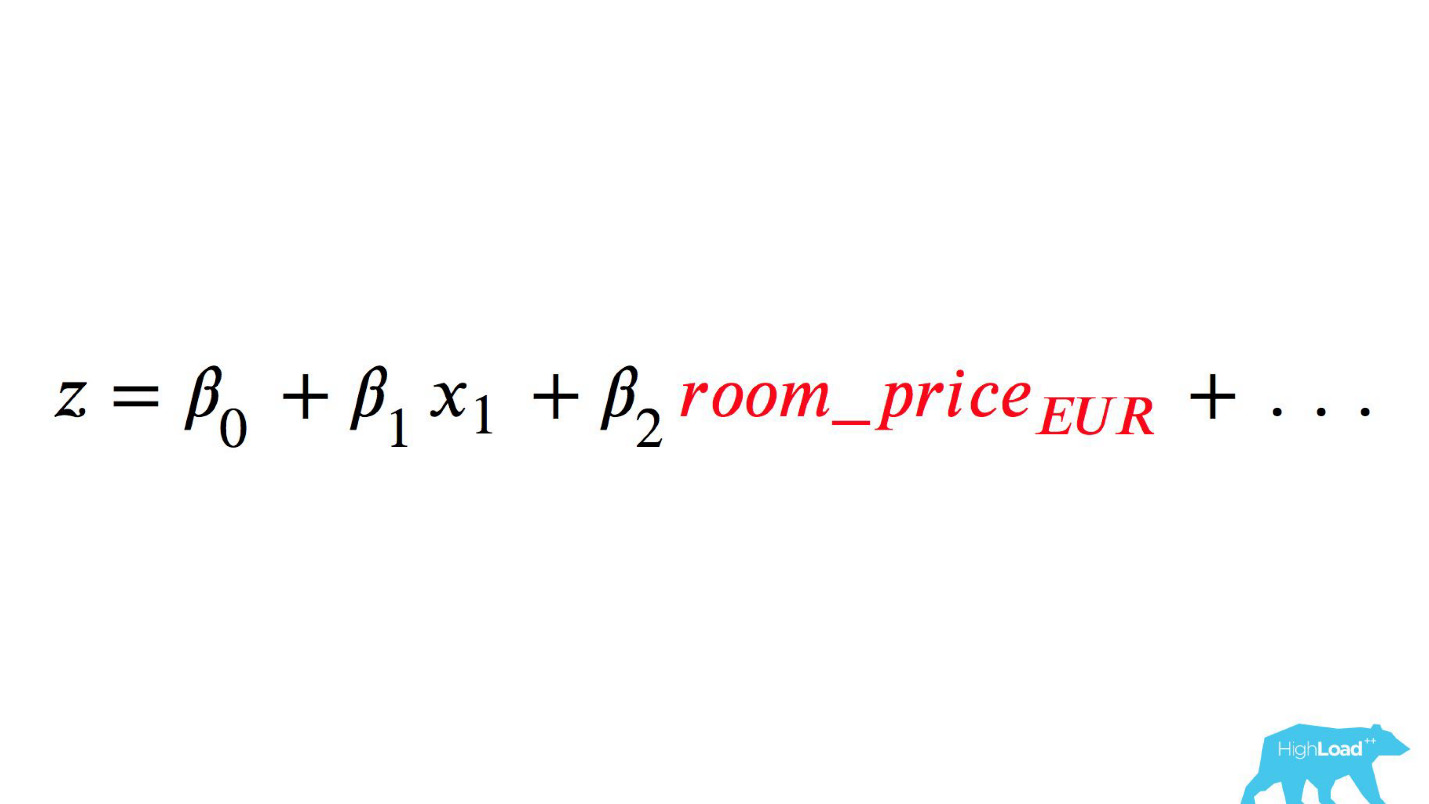
Llamar a este modelo sería algo como esto:
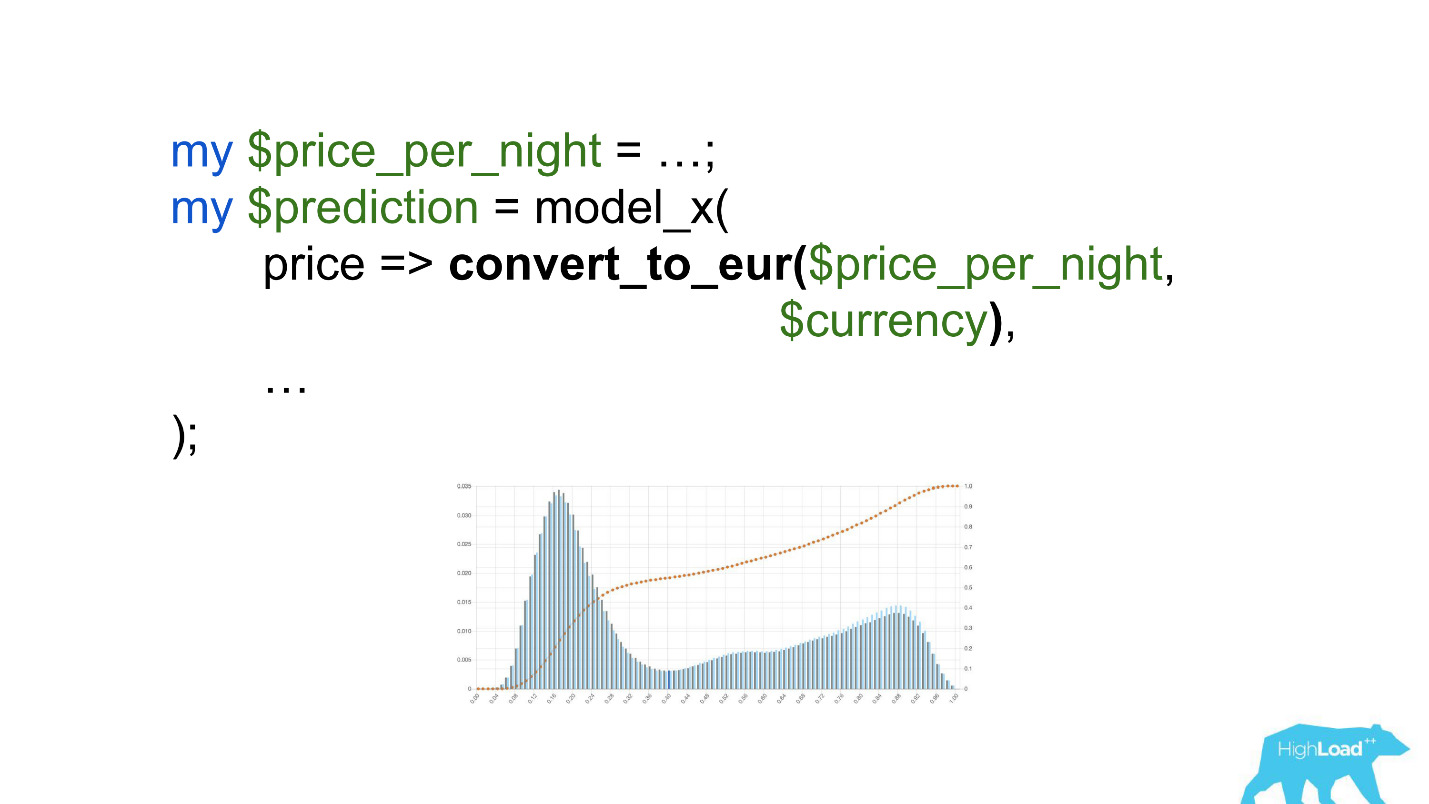
Presta atención a la selección. Era necesario convertir el precio a euros, pero el desarrollador olvidó hacerlo.
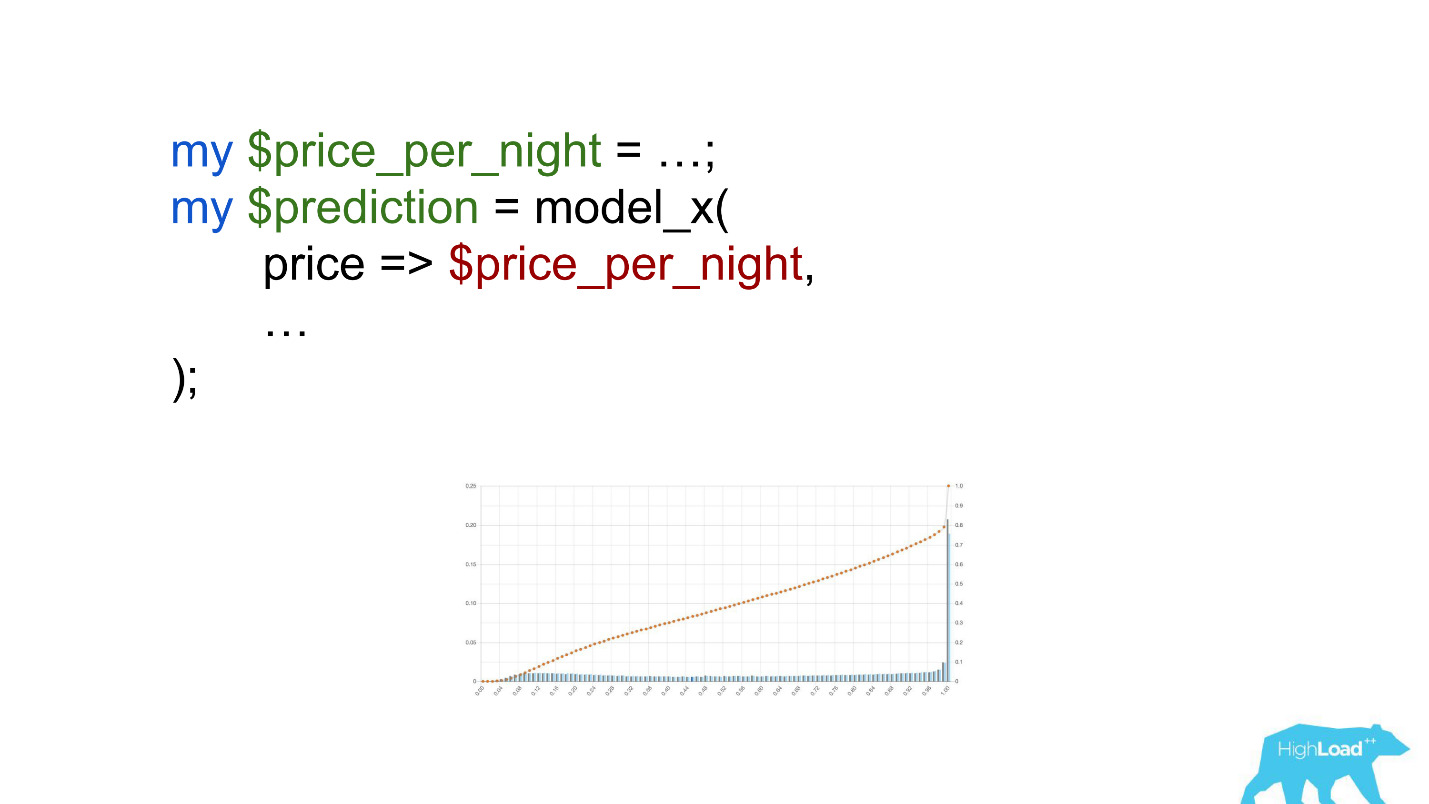
Las monedas como rupias o rublos multiplicaron el producto escalar muchas veces y, por lo tanto, obligaron a este modelo a producir un valor cercano a la unidad, mucho más a menudo, que vemos en el gráfico.
Valores umbral
Otra característica útil de estos histogramas fue la posibilidad de una elección consciente y óptima de los valores umbral.
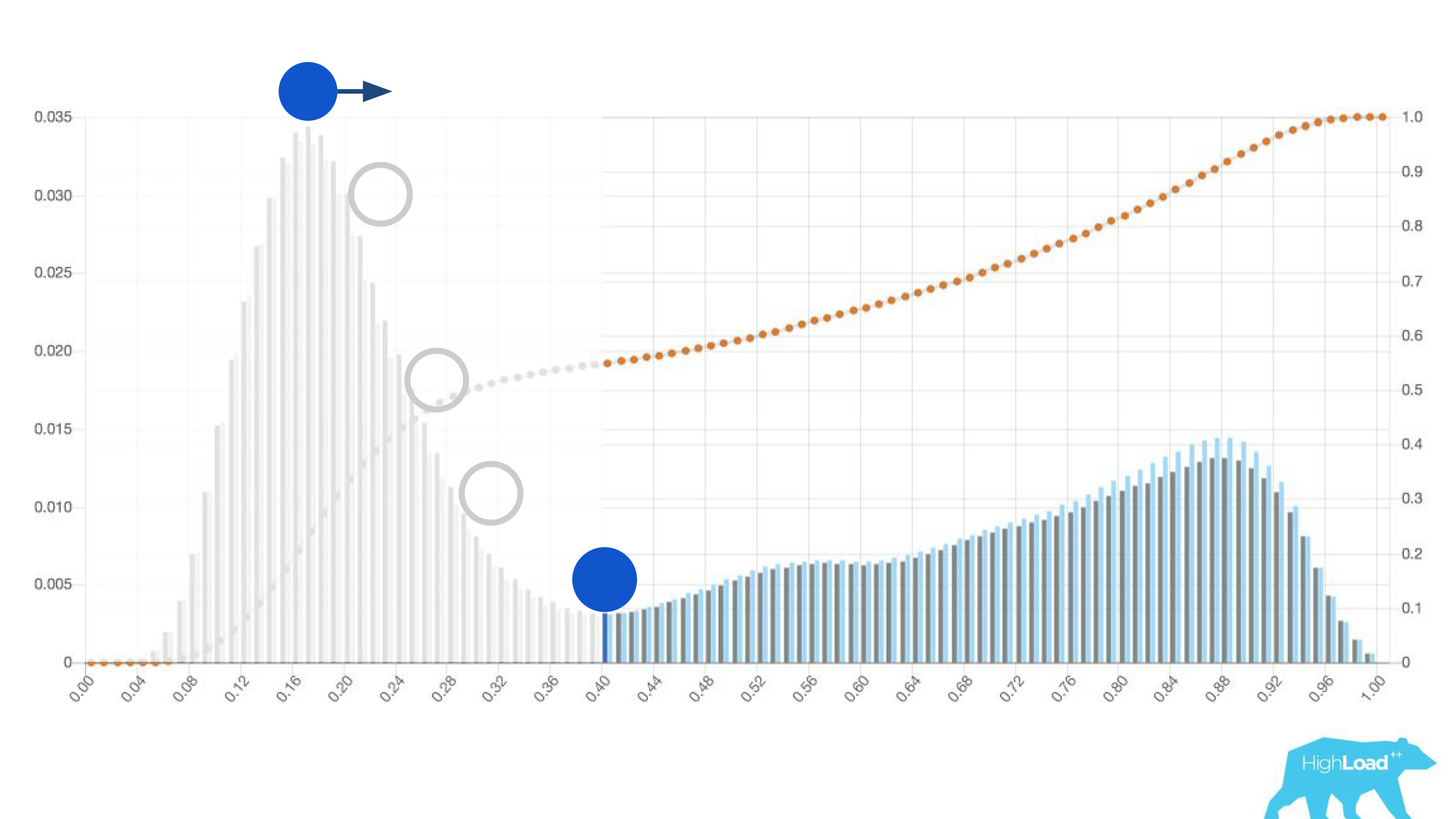
Si coloca la pelota en la colina más alta de este histograma, empújela e imagine dónde se detendrá, este será el punto óptimo para la separación de clases. Todo a la derecha es una clase, todo a la izquierda es otra.
Sin embargo, si comienza a mover este punto, puede lograr efectos muy interesantes. Supongamos que queremos ejecutar un experimento que, si el modelo dice que sí, de alguna manera cambia la interfaz de usuario. Si mueve este punto a la derecha, la audiencia de nuestro experimento se reduce. Después de todo, el número de personas que recibieron esta predicción es el área bajo la curva. Sin embargo, en la práctica, la precisión de las predicciones es mucho mayor. Del mismo modo, si no hay suficiente potencia estática, puede aumentar la audiencia de su experimento, pero disminuir la precisión de las predicciones.
Además de las predicciones en sí, comenzamos a monitorear los valores de entrada en los vectores.
Una codificación activa
La mayoría de las características en nuestros modelos más simples son categóricas. Esto significa que no se trata de números, sino de ciertas categorías: la ciudad de la que es el usuario o la ciudad en la que busca un hotel. Utilizamos One Hot Encoding y convertimos cada uno de los valores posibles en una unidad en un vector binario. Como al principio solo utilizamos nuestro propio núcleo informático, fue fácil identificar situaciones en las que no hay lugar para la categoría entrante en el vector entrante, es decir, el modelo no vio estos datos durante el entrenamiento.
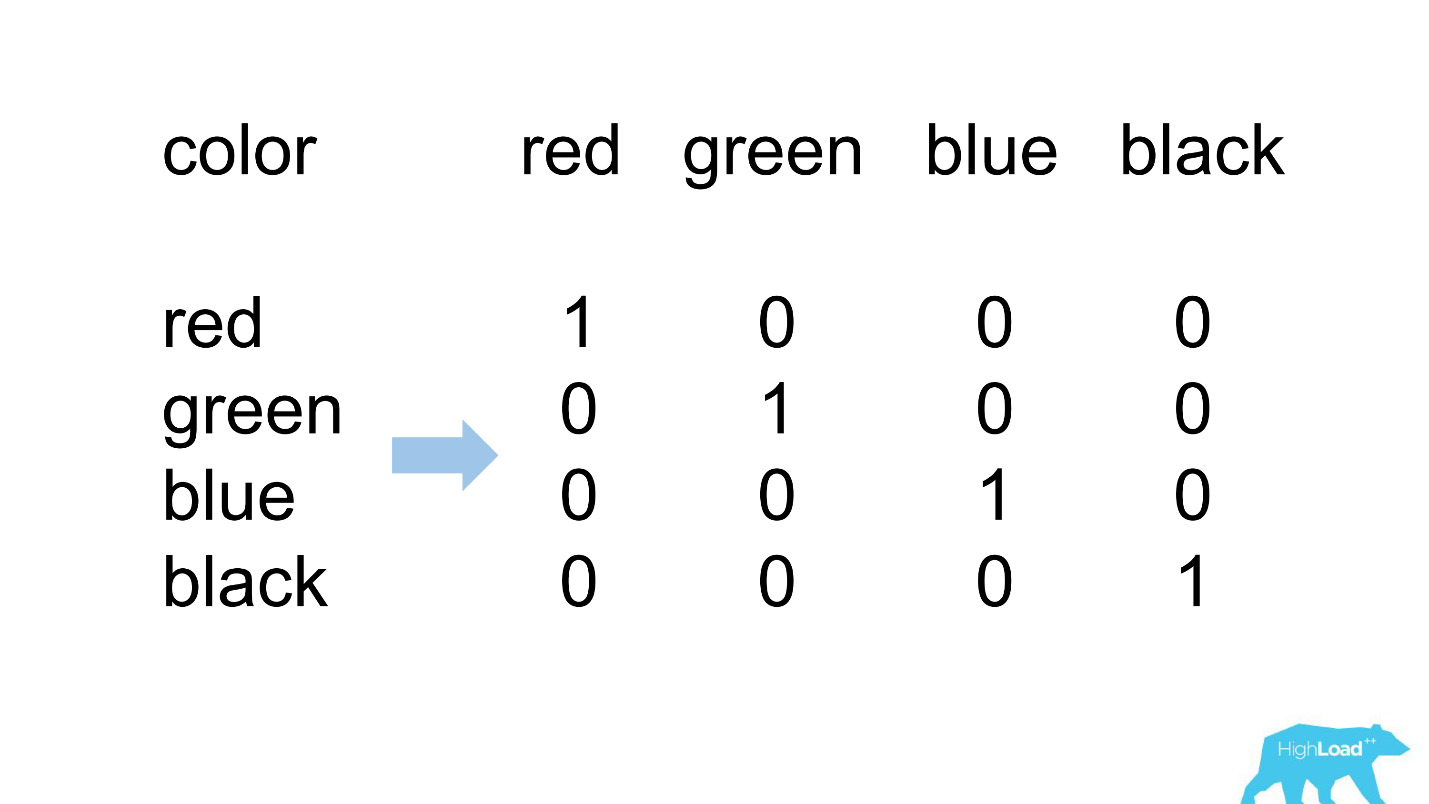
Esto es lo que generalmente parece.

destination_id: la ciudad en la que el usuario busca un hotel. Naturalmente, el modelo no vio alrededor del 5% de los valores, ya que constantemente estamos conectando nuevas ciudades. visitor_cty_id = 23.32%, porque los científicos de datos a veces omiten conscientemente ciudades menos comunes.
En un mal caso, podría verse así:

Inmediatamente 3 propiedades, el 100% de los valores que el modelo nunca ha visto. La mayoría de las veces esto ocurre debido al uso de formatos distintos a los utilizados en el entrenamiento, o simplemente errores tipográficos banales.
Ahora, con la ayuda de paneles, detectamos y corregimos tales situaciones muy rápidamente.
Escaparate de aprendizaje automático
Hablemos de otros problemas que hemos resuelto. Después de crear bibliotecas y monitoreo de clientes, el servicio comenzó a ganar impulso muy rápidamente. Estábamos literalmente abrumados con aplicaciones de diferentes partes de la compañía: “¡Conectemos también este modelo! ¡Actualicemos el viejo! Acabamos de coser, de hecho, cualquier nuevo desarrollo se ha detenido.
Salimos de la situación haciendo
un quiosco de autoservicio para científicos de datos . Ahora puede ir a nuestro portal, el mismo que usamos al principio solo para monitorear, y literalmente al hacer clic en el botón cargar el modelo en producción. En unos minutos ella trabajará y dará predicciones.
Hubo un problema más.
Booking.com tiene aproximadamente 200 equipos de TI. ¿Cómo hacer que el equipo sepa en una parte completamente diferente de la compañía que hay un modelo que podría ayudarlos? Es posible que simplemente no sepa que tal equipo incluso existe. ¿Cómo saber qué modelos hay y cómo usarlos? Tradicionalmente, las comunicaciones externas en nuestros equipos se dedican a PO (Product Owner). Esto no significa que no tengamos otras conexiones horizontales, solo PO lo hace más que otras. Pero es obvio que a tal escala, la comunicación uno a uno no escala. Necesitas hacer algo al respecto.
¿Cómo se puede facilitar la comunicación?De repente nos dimos cuenta de que el portal, que creamos exclusivamente para monitoreo, gradualmente comienza a convertirse en un escaparate de aprendizaje automático dentro de nuestra empresa.
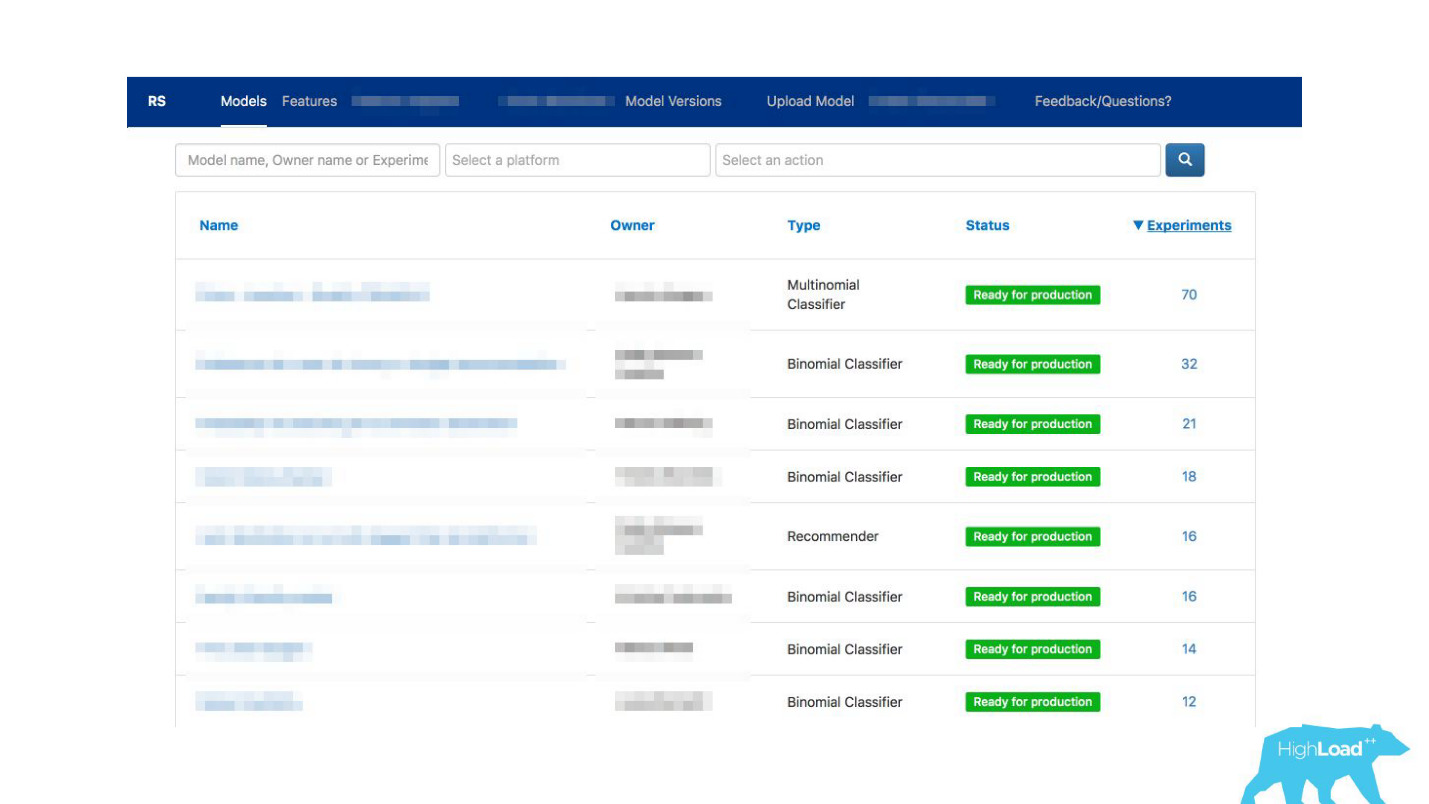
Hemos permitido que los científicos de datos describan sus modelos en detalle. Cuando había muchos modelos, agregamos etiquetas de tema y área para una agrupación conveniente.
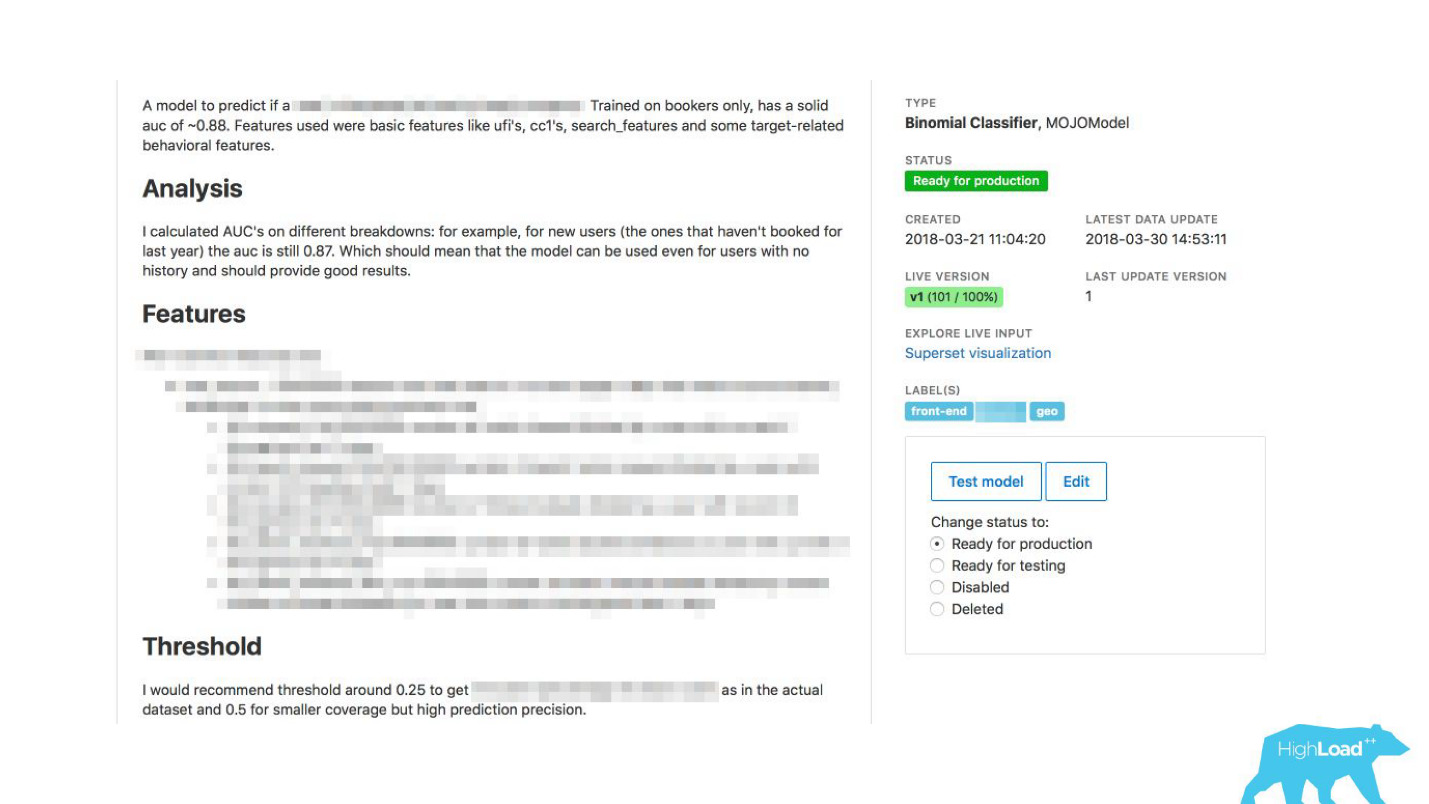
Vinculamos nuestra herramienta con ExperimentTool. Este es un producto dentro de nuestra empresa que proporciona experimentos A / B y almacena toda la historia de la experimentación.

Ahora, junto con la descripción del modelo, también puede ver lo que otros equipos han hecho con este modelo antes y con qué éxito. Ha cambiado todo.
En serio, esto ha cambiado la forma en que funciona la TI, porque incluso en situaciones en las que no hay un científico de datos en el equipo, puede usar el aprendizaje automático.
Por ejemplo, muchos equipos usan esto durante las sesiones de lluvia de ideas. Cuando se les ocurren nuevas ideas de productos, simplemente seleccionan los modelos que les convienen y los utilizan. No se necesita nada complicado para esto.
¿Qué derramó por nosotros? En este momento, en el pico, entregamos alrededor de 200 mil predicciones por segundo, con latencia de menos de 20-30 ms, incluido el viaje de ida y vuelta de HTTP, y la colocación de más de 200 modelos.
Puede parecer que fue una caminata tan fácil en el parque: hicimos un trabajo maravilloso, todo funciona, ¡todos están felices!
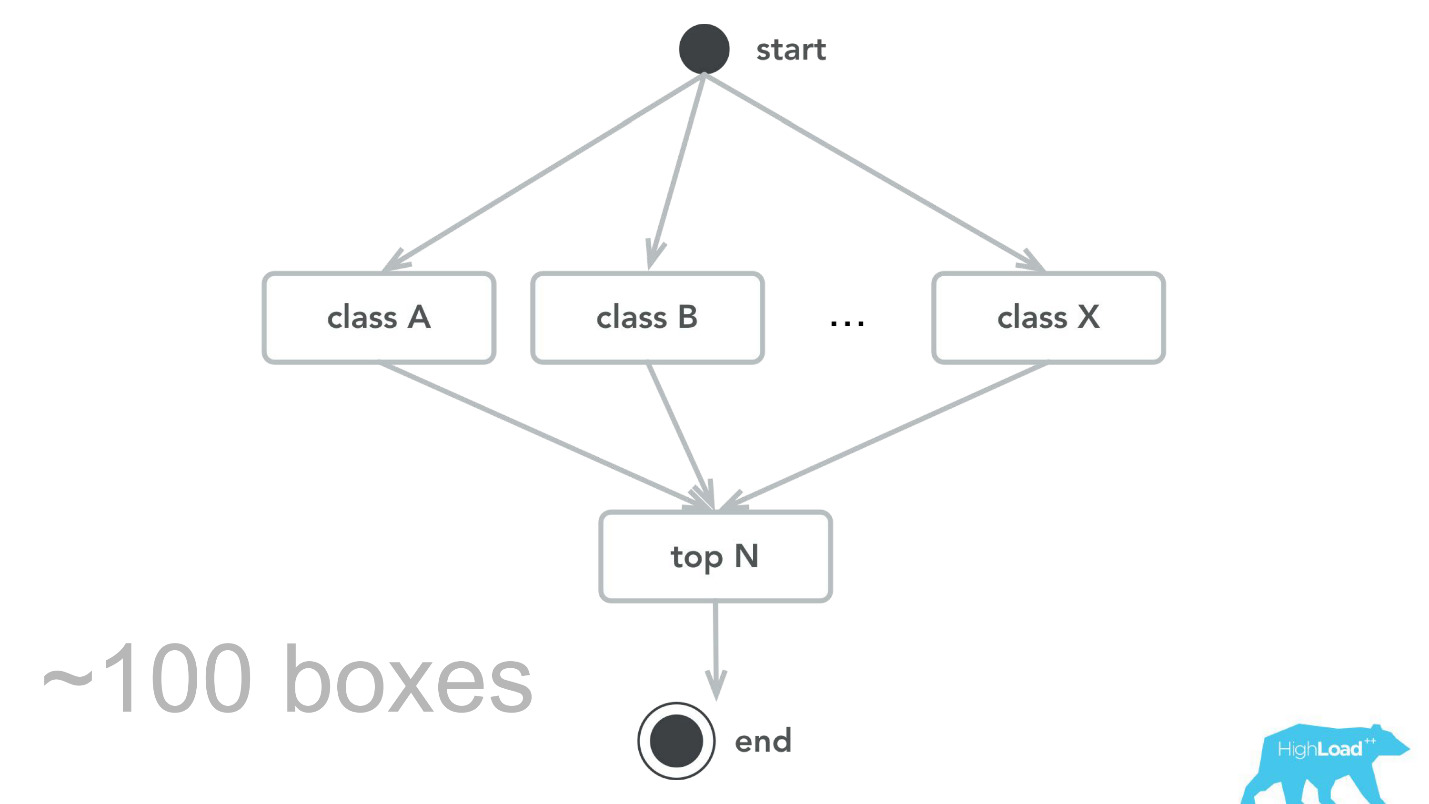
Esto, por supuesto, no sucede. Hubo errores Al principio, por ejemplo, plantamos una pequeña bomba de tiempo. Por alguna razón, asumimos que la mayoría de nuestros modelos serán sistemas de recomendación con vectores de entrada pesados, y la pila Scala + Akka fue elegida precisamente porque es muy fácil organizar cálculos paralelos con su ayuda. Pero, en realidad, la sobrecarga de toda esta paralelización, para reunirse, resultó ser mayor que la ganancia posible. En algún momento, nuestras 100 máquinas procesaron solo 100,000 RPS, y las fallas ocurrieron con síntomas bastante característicos: la utilización de la CPU es baja, pero se obtienen tiempos de espera.
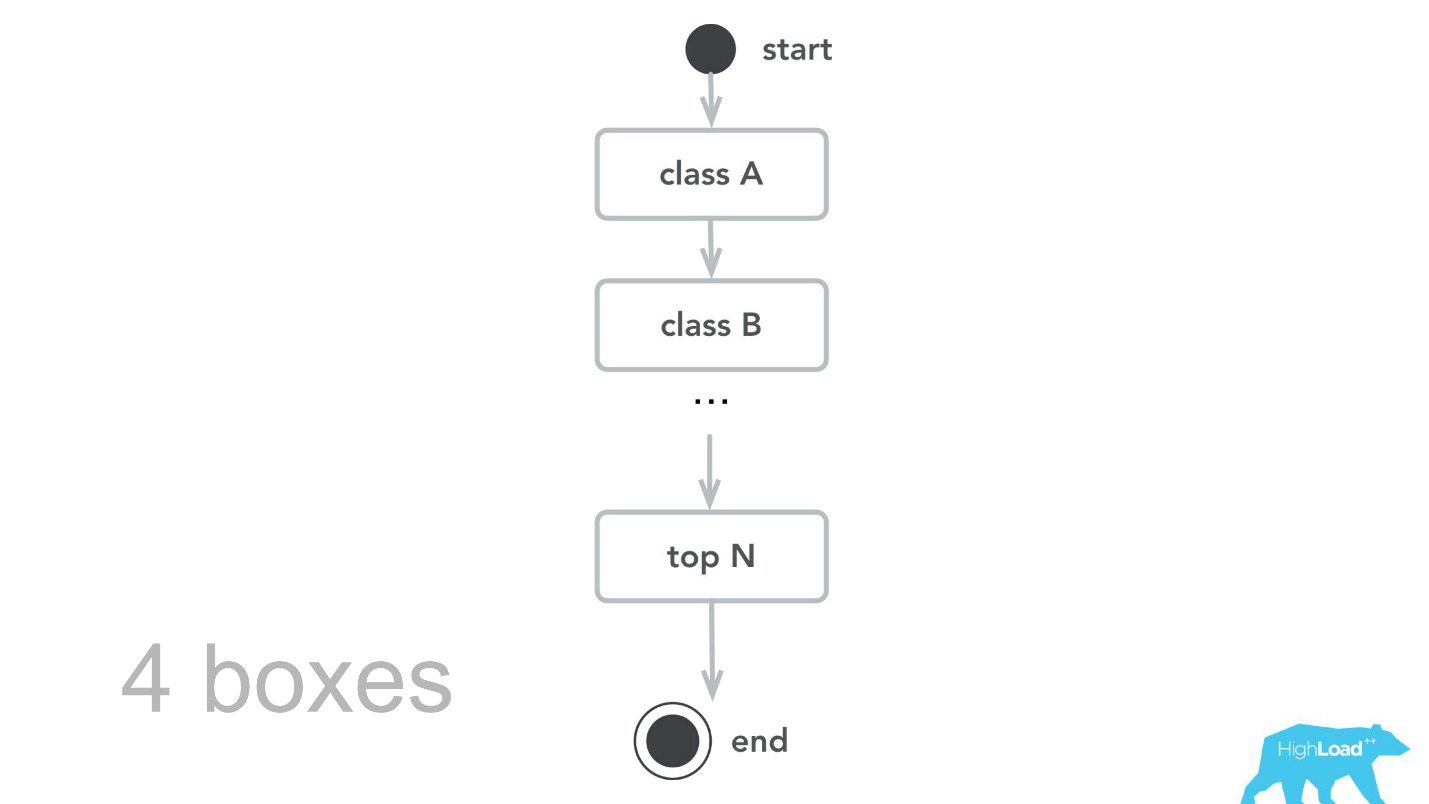
Luego volvimos a nuestro núcleo de computación, revisamos, hicimos puntos de referencia y, como resultado de las pruebas de capacidad, aprendimos que para el mismo tráfico solo necesitamos 4 máquinas. , , -, , , , 100 000 RPS 4 .
- , , . - , , , .
— , . , ID , . , 0.
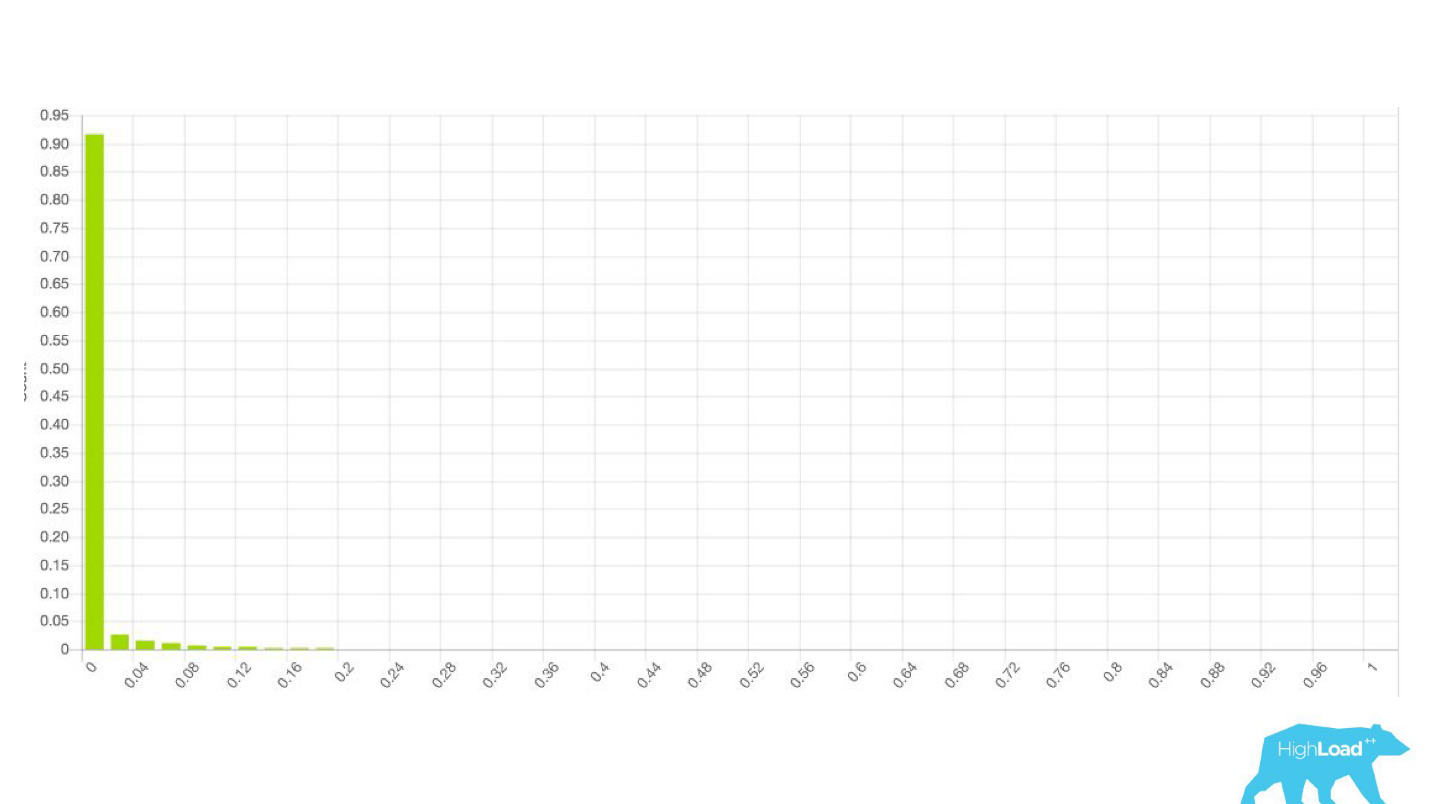
— , — .
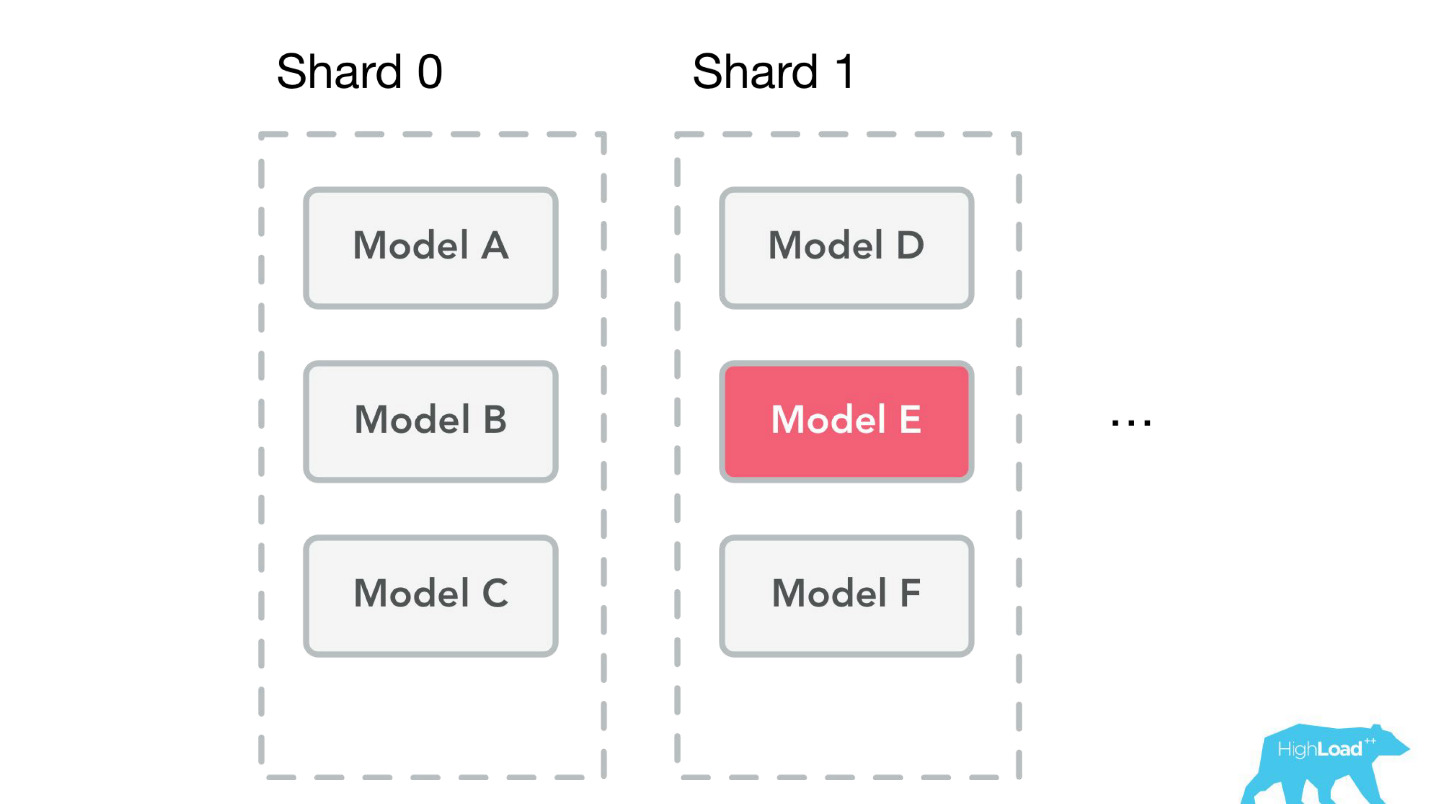
, . , . , — , . , , , - .
, — ID . — 49-51%. , . , , . , .
Planes futuros
- , . Label based metrics, precision recall .
- More tools & integrations
, . , Perl Java, , , . Spark, .
- Reusable training pipelines
.
, -. , , , , ,
steaming — - , , .
. pipeline, , . , , .
. ,
, 50 , . , . , , .
Start small
, , Booking.com, , , — !
, , MySQL. , , . - . B . , , - — .
, ?
Monitor
— , -, .
— . — , . , , , . : , . , , , — !
Organization footprint
, . , . , .
(Don't) Follow our steps
- , , , . , - , . , . — , , ? , , , ?
, , !HighLoad++ 2018, 8 9 , 135 , . 9 - . , .