Antes de que un cliente pueda hacer transferencias de dinero en ePayments, tendrá que pasar por la verificación. Nos proporciona sus datos personales y carga documentos para verificar su identidad y dirección. Y verificamos si cumplen con los requisitos de nuestro regulador. El flujo de solicitudes de verificación se hizo cada vez más, nos resultó difícil procesar dicho flujo de documentos. Temíamos que el procedimiento llevaría mucho tiempo y excedería todos los términos razonables para los clientes. Luego decidimos crear un sistema de verificación basado en el aprendizaje profundo.

Programa educativo sobre reguladores y sus requisitos.
Para emitir dinero electrónico, debe obtener una licencia de regulador. Si abre un sistema de pago, por ejemplo, en Rusia, el Banco Central de la Federación de Rusia se convertirá en su regulador. ePayments es un sistema de pago en inglés, nuestro regulador es la Financial Conduct Authority (FCA), una autoridad que informa al Tesoro del Reino Unido. FCA garantiza que cumplamos con la política contra el lavado de dinero (AML), que incluye el conjunto de procedimientos Conozca a su cliente (KYC).
Según KYC, estamos comprometidos a verificar quién es nuestro cliente y si está asociado con grupos socialmente peligrosos. Por lo tanto, tenemos dos obligaciones:
- Identificación y confirmación de identidad del cliente.
- Conciliación de sus datos con varias listas: terroristas, personas bajo sanciones, miembros del gobierno y muchos otros.
Cada año, los requisitos de KYC son cada vez más estrictos y detallados. A principios de 2017, los clientes de ePayments aún podían recibir pagos o realizar transferencias sin verificación. Ahora esto no es posible hasta que confirmen su identidad.
Verificación manual
Hace unos años, nos las arreglamos por nuestra cuenta. Los rusos enviaron un escaneo de ciertas páginas del pasaporte para confirmar su identidad, y un escaneo del contrato de arrendamiento, un recibo por el pago de la vivienda y los servicios comunales para confirmar la dirección. ¿Recuerdas el juego Papeles, por favor? En él, jugando como oficial de aduanas, verifica los documentos contra los requisitos cada vez más complejos del gobierno. Nuestro departamento de atención al cliente jugaba en el trabajo todos los días.

Los clientes se verifican de forma remota, sin una visita a la oficina. Para agilizar el procedimiento, contratamos nuevos empleados, pero este es un callejón sin salida. Entonces surgió la idea de confiar parte del trabajo de la red neuronal. Si ella se las arregla bien con el reconocimiento facial, entonces ella hace frente a nuestras tareas. Desde una perspectiva comercial, un sistema de verificación rápida debería ser capaz de:
- Clasifica un documento. Se nos envía una tarjeta de identidad y la confirmación de la dirección de residencia. El sistema debería responder a lo que recibió al ingresar: un pasaporte de un ciudadano de la Federación Rusa, un contrato de arrendamiento u otra cosa.
- Compare la cara en la foto y el documento. Pedimos a los clientes que envíen selfies con una tarjeta de identidad para asegurarse de que ellos mismos estén registrados en el sistema de pago.
- Extraer texto Llenar decenas de campos desde un teléfono inteligente no es muy conveniente. Es mucho más fácil si la aplicación hizo todo por usted.
- Verifique los archivos de imagen para montaje fotográfico. No debemos olvidarnos de los estafadores que quieren ingresar al sistema de manera fraudulenta.
En la salida, el sistema debe indicar un cierto nivel de confianza en el cliente: alto, medio o bajo. Centrándose en tal gradación, verificaremos rápidamente y no enojaremos a los clientes con períodos prolongados.
Clasificador de documentos
La tarea de este módulo es asegurarse de que el usuario envíe un documento válido y dar una respuesta de lo que cargó exactamente: un pasaporte de un ciudadano de Kazajstán, un contrato de arrendamiento o un recibo por el pago de la vivienda y los servicios comunales.
El clasificador recibe los datos de entrada:
- Foto o documento escaneado
- País de residencia
- Tipo de documento indicado por el cliente (documento de identidad o comprobante de domicilio)
- Texto extraído (más sobre eso a continuación)
En la salida, el clasificador informa lo que recibió (pasaporte, licencia de conducir, etc.) y qué tan seguro está de la respuesta correcta.

La solución ahora se ejecuta en la arquitectura de red residual amplia. No acudimos a ella de inmediato. La primera versión del sistema de verificación rápida funcionó sobre la base de la arquitectura a la que nos inspiró VGG. Tenía 2 problemas obvios: una gran cantidad de parámetros (unos 130 millones) e inestabilidad en la posición del documento. Cuantos más parámetros, más difícil es entrenar una red neuronal de este tipo: generaliza poco el conocimiento. El documento en la fotografía debe estar centrado, de lo contrario el clasificador tendría que ser entrenado en las muestras en las que se encuentra en diferentes partes de la fotografía. Como resultado, abandonamos VGG y decidimos cambiar a una arquitectura diferente.
La red residual (ResNet) era más fría que VGG. Gracias a las
conexiones salteadas, puede crear una gran cantidad de capas y lograr una alta precisión. ResNet tiene solo alrededor de 1 millón de parámetros, y ella era indiferente a la posición del documento. No importa dónde se encuentre en la imagen, la solución en esta arquitectura manejó la clasificación.
Mientras estábamos finalizando la solución con un archivo, se lanzó una nueva modificación de arquitectura, la Red Residual Amplia (WRN). La principal diferencia con ResNet es un paso atrás en términos de profundidad. WRN tiene menos capas, pero más filtros convolucionales. Ahora esta es la mejor arquitectura de red neuronal para la mayoría de las tareas y nuestra solución funciona en ella.
Algunas soluciones útiles
Problema número 1. El clasificador necesitaba ser entrenado. Tuvimos que descargar muchos pasaportes y licencias de conducir rusos, kazajos y bielorrusos. Pero, por supuesto, no puede tomar documentos de clientes. Hay muestras en la red, pero hay muy pocas de ellas para entrenar con éxito la red neuronal.
Solución Nuestro departamento técnico generó una muestra de más de 8000 muestras de cada tipo. Creamos una plantilla de documento y la multiplicamos por muchas muestras aleatorias. Luego, generamos una posición aleatoria del documento en el espacio con respecto a la cámara, teniendo en cuenta su modelo matemático y sus características: distancia focal, resolución de la matriz, etc. Al generar una fotografía artificial, se selecciona una imagen aleatoria del conjunto de datos terminado como fondo. Después de eso, se coloca un documento con distorsiones de perspectiva en la imagen al azar. En tal muestra, nuestra red neuronal estaba bien entrenada y definió perfectamente el documento "en batalla". Los resultados están al final del artículo.
Problema número 2. Restricción banal en recursos informáticos y memoria. No tiene sentido enviar una red neuronal profunda a la entrada de imágenes grandes. Y las fotos de los teléfonos inteligentes modernos son solo eso.
Solución Antes de aplicar a la entrada, la foto se comprime a un tamaño de aproximadamente 300x300 píxeles. De la imagen de este permiso, uno puede distinguir fácilmente un documento de identificación de otro. Para resolver este problema, podemos usar la arquitectura estándar Wide ResNet.
Problema número 3. Con los documentos que confirman la dirección de residencia, todo es más complicado. El contrato de arrendamiento o el extracto bancario solo se pueden distinguir por el texto en la hoja. Después de reducir el tamaño de la imagen a los mismos 300x300 píxeles, cualquiera de estos documentos tiene el mismo aspecto, como una hoja A4 con texto ilegible.
Solución Para clasificar documentos arbitrarios, realizamos cambios en la arquitectura de la red neuronal misma. En él apareció una capa de neuronas de entrada adicional, que está conectada con la capa de salida. Las neuronas de esta capa de entrada reciben una entrada vectorial que describe el texto previamente reconocido utilizando el modelo de
Bolsa de palabras .
Primero, capacitamos a una red neuronal para clasificar documentos de identidad. Utilizamos los pesos de la red capacitada cuando inicializamos otra red con una capa adicional para clasificar documentos arbitrarios. Esta solución tenía una alta precisión, pero el reconocimiento de texto tomó algo de tiempo. La diferencia en la velocidad de procesamiento entre diferentes módulos y la precisión de clasificación se puede ver en la tabla No. 2.
Reconocimiento facial
¿Cómo engañar a un sistema de pago que verifica documentos? Puede pedir prestado el pasaporte de otra persona y registrarse con él. Para asegurarse de que el cliente se esté registrando, le pedimos que se tome una selfie con una tarjeta de identidad. Y el módulo de reconocimiento debe comparar la cara en el documento y la cara en la selfie y responder, esta es una persona o dos diferentes.
¿Cómo comparar 2 caras si eres un auto y piensas como un auto? Convierta una foto en un conjunto de parámetros y compare sus valores entre sí. Así es como funcionan las redes neuronales que reconocen caras. Toman una imagen y la convierten en un vector de 128 dimensiones (por ejemplo). Cuando envía otra imagen de cara a la entrada y les pide que comparen, la red neuronal convertirá la segunda cara en un vector y calculará la distancia entre ellas.
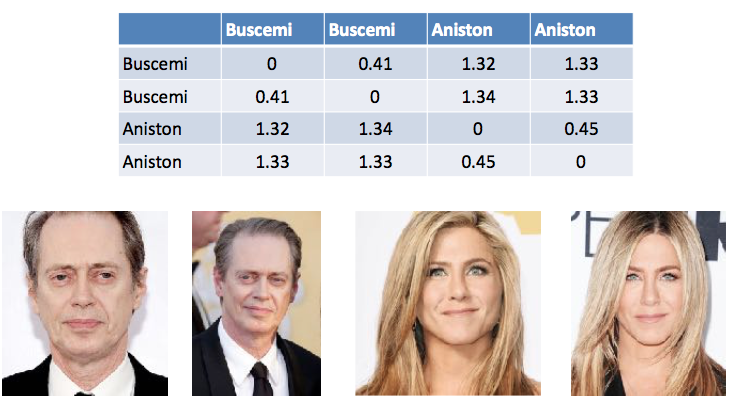 Tabla 1. Un ejemplo de cálculo de la diferencia entre vectores en reconocimiento facial. Steve Buscemi difiere de sí mismo en diferentes fotos en 0.44. Y de Jennifer Aniston, un promedio de 1.33.
Tabla 1. Un ejemplo de cálculo de la diferencia entre vectores en reconocimiento facial. Steve Buscemi difiere de sí mismo en diferentes fotos en 0.44. Y de Jennifer Aniston, un promedio de 1.33.Por supuesto, hay diferencias entre la apariencia de una persona en la vida y el pasaporte. También seleccionamos la distancia entre los vectores y probamos en personas reales para lograr un resultado. En cualquier caso, la decisión final la tomará la persona y un comentario del sistema será solo una recomendación.
Reconocimiento de texto
Hay campos de texto en los documentos que ayudan al clasificador a comprender lo que está frente a él. Será conveniente para el usuario si el texto del mismo pasaporte se transfiere automáticamente y no tiene que escribirse manualmente, por quién y cuándo se emitió. Para hacer esto, creamos el siguiente módulo: reconocimiento y extracción de texto.
En algunos documentos, por ejemplo, nuevos pasaportes de la Federación de Rusia hay una zona legible por máquina (MRZ). Con su ayuda, es fácil tomar información: es fácil leer texto en negro sobre un fondo blanco, lo cual es fácil de reconocer. Además, MRZ tiene un formato bien conocido, gracias al cual es más fácil obtener los datos necesarios.

Si la tarea tiene documentos con MRZ, entonces nos resulta más fácil. Todo el proceso se encuentra en el campo de la visión por computadora. Si esta zona no está allí, entonces, después de reconocer el texto, debe resolver un problema interesante: comprender y ¿qué información reconocimos? Por ejemplo, "15 de mayo de 1999" es la fecha de nacimiento o la fecha de emisión? En esta etapa, también puede cometer un error. MRZ es bueno porque está decodificado de forma única. Siempre sabemos qué información y en qué parte del MRZ buscar. Es muy conveniente para nosotros. Pero MRZ no estaba en el documento más popular con el que trabajará la red: el pasaporte de la Federación Rusa.
Para el reconocimiento de texto, necesitábamos una solución muy efectiva. El texto deberá eliminarse de la imagen tomada por la cámara del teléfono y no por los fotógrafos más profesionales. Probamos Google Tesseract y varias soluciones pagas. No surgió nada, o funcionó mal o fue excesivamente caro. Como resultado, comenzamos a desarrollar nuestra propia solución. Ahora estamos terminando su prueba. La solución muestra resultados decentes: puede leer sobre ellos a continuación. Hablaremos sobre el módulo para verificar el montaje fotográfico un poco más tarde, cuando habrá resultados de investigación precisos en muestras de prueba y en la "batalla".
Resultado
El sistema se está probando actualmente en el segmento de aplicaciones para verificación de Rusia. El segmento se determina mediante muestreo aleatorio, los resultados se guardan y se comparan con las decisiones del operador del departamento del cliente para un cliente en particular.
| Pais | Tipo de clasificador | Precisión | Tiempo de trabajo, s |
| Rusia | Tarjeta de identificación | 99,96% | 0,41 |
| Rusia | Documento personalizado | 98,62% | 6.89 |
| Kazajstán | Tarjeta de identificación | 99,51% | 0,47 |
| Kazajstán | Documento personalizado | 97,25% | 7.66 |
| Bielorrusia | Tarjeta de identificación | 98,63% | 0,46 |
| Bielorrusia | Documento personalizado | 98,63% | 9.66 |
Tabla 2. La precisión del clasificador de documentos (la clasificación correcta del documento en comparación con la evaluación del operador).Una de las grandes ventajas del aprendizaje automático es que la red neuronal realmente aprende y comete menos errores. Pronto terminaremos las pruebas en el segmento y lanzaremos el sistema de verificación en modo "combate". El 30% de las solicitudes de verificación llegan a pagos electrónicos de Rusia, Kazajstán y Bielorrusia. Según nuestras estimaciones, el lanzamiento ayudará a reducir la carga en el departamento del cliente en un 20-25%. En el futuro, la solución puede ampliarse a países europeos.
¿Buscando trabajo?
Estamos buscando empleados para trabajar en una oficina en San Petersburgo. Si está interesado en un proyecto internacional con un gran grupo de tareas ambiciosas, lo estamos esperando. No tenemos suficientes personas que no tengan miedo de realizarlas. A continuación encontrará enlaces a vacantes en hh.ru.