
Este artículo es parte de
Chronicle of Software Architecture , una serie de artículos sobre arquitectura de software. En ellos escribo sobre lo que aprendí sobre la arquitectura de software, lo que pienso al respecto y cómo uso el conocimiento. El contenido de este artículo puede tener más sentido si lee los artículos anteriores de la serie.
Después de graduarme de la universidad, comencé a trabajar como maestra de secundaria, pero hace unos años renuncié y fui a los desarrolladores de software a tiempo completo.
Desde entonces, siempre he sentido que necesito recuperar el tiempo "perdido" y averiguar lo más posible, lo más rápido posible. Por lo tanto, comencé a involucrarme un poco en los experimentos, a leer y escribir mucho, prestando especial atención al diseño y la arquitectura del software. Es por eso que estoy escribiendo estos artículos para ayudarme en mis estudios.
En los últimos artículos, hablé sobre muchos conceptos y principios que aprendí, y un poco sobre cómo razonar sobre ellos. Pero los imagino como fragmentos de un gran rompecabezas.
Este artículo trata sobre cómo armé todos estos fragmentos. Creo que debería darles un nombre, así que los llamaré
arquitectura explícita . Además, todos estos conceptos se
"prueban en la batalla" y se utilizan en la producción en plataformas altamente confiables. Una de ellas es una plataforma de comercio electrónico SaaS con miles de tiendas en línea en todo el mundo, la otra es una plataforma comercial que opera en dos países con un bus de mensajes que procesa más de 20 millones de mensajes por mes.
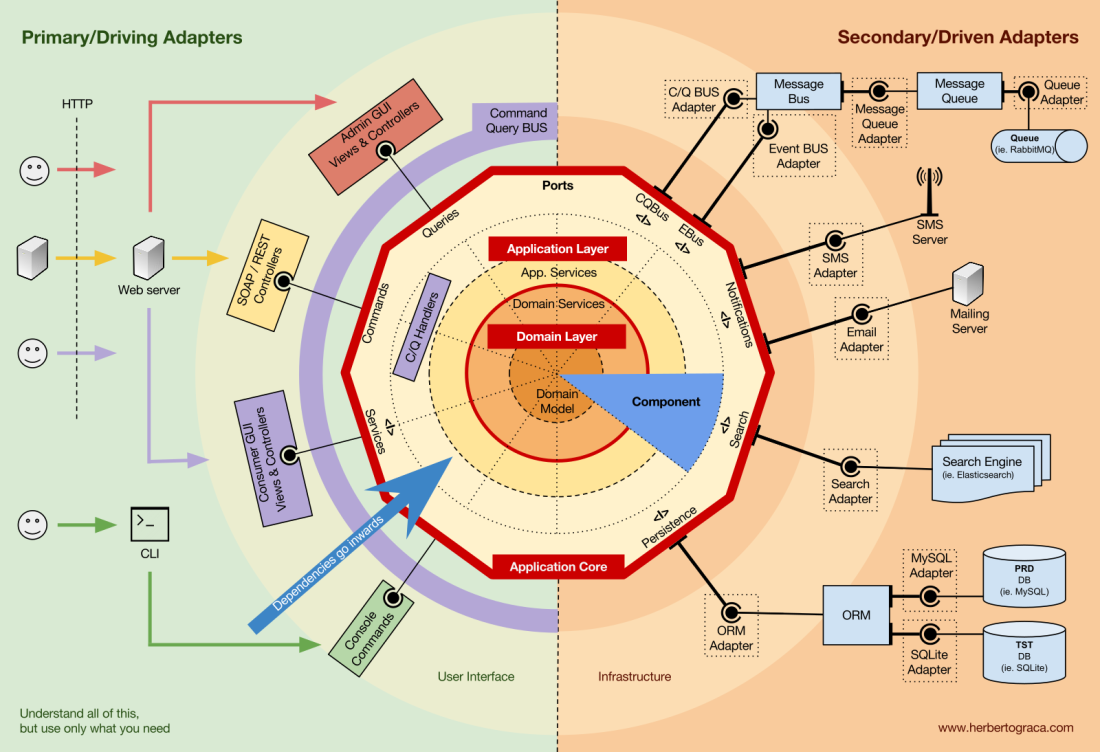
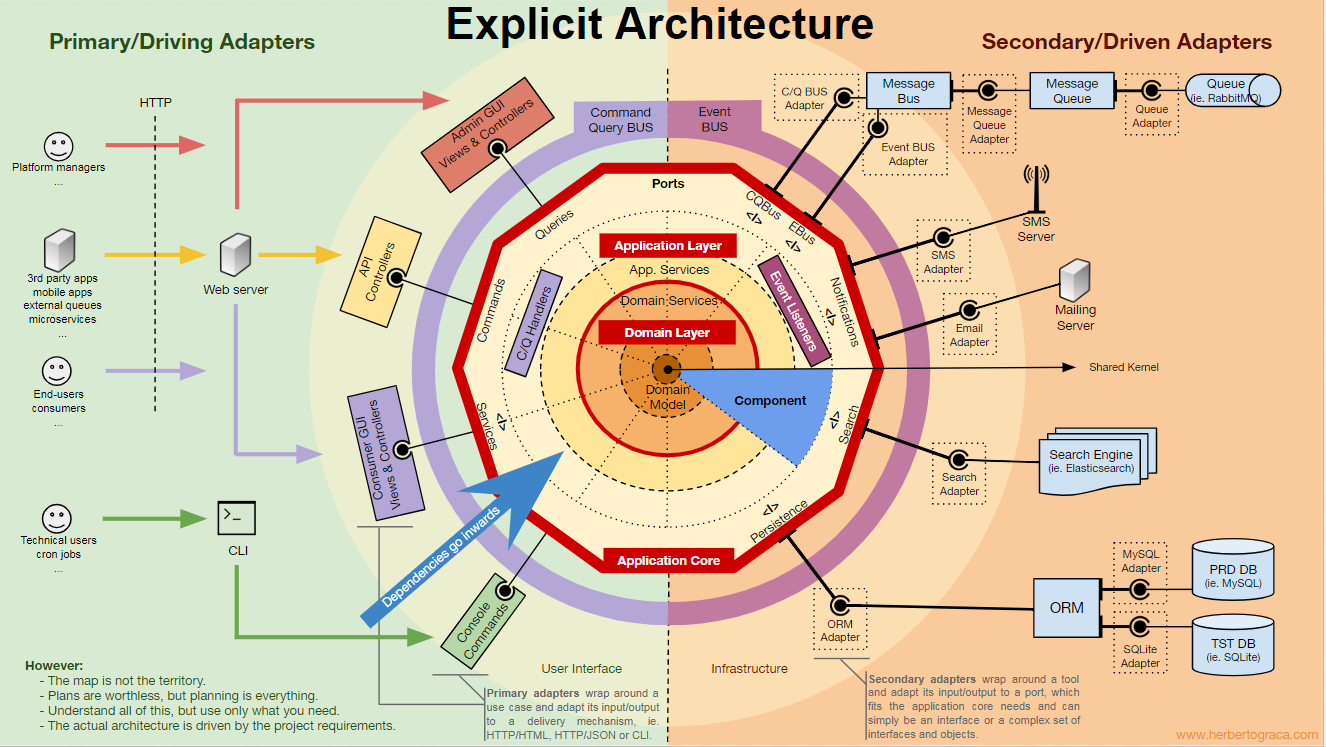
Bloques fundamentales del sistema
Comencemos
recordando las arquitecturas
EBI y
Ports & Adapters . Ambos separan claramente el código interno y externo de la aplicación, así como los adaptadores para conectar el código interno y externo.
Además, la arquitectura de
Puertos y Adaptadores define explícitamente los tres bloques fundamentales de código en el sistema:
- Eso le permite ejecutar la interfaz de usuario , independientemente de su tipo.
- Sistema de lógica de negocios o núcleo de la aplicación . La UI lo utiliza para realizar transacciones reales.
- El código de infraestructura que conecta el núcleo de nuestra aplicación con herramientas como la base de datos, el motor de búsqueda o las API de terceros.
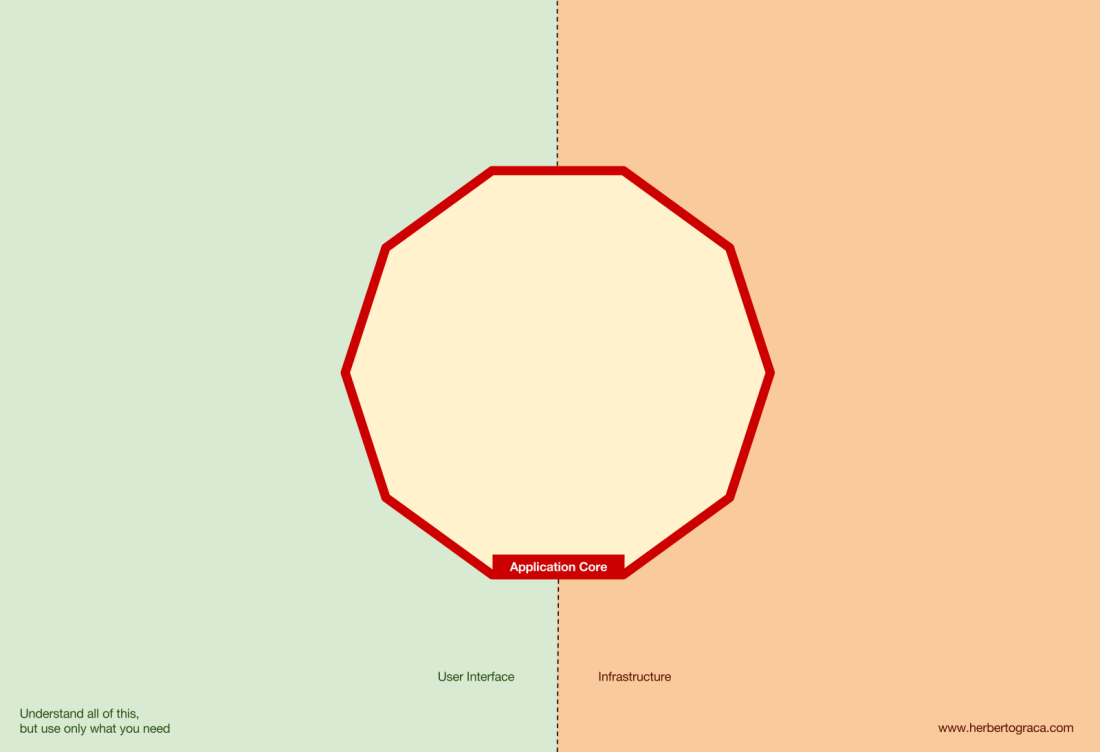
El núcleo de la aplicación es lo más importante para pensar. Este código le permite realizar acciones reales en el sistema, es decir, esta es nuestra aplicación. Varias interfaces de usuario (una aplicación web progresiva, aplicación móvil, CLI, API, etc.) pueden funcionar con ella, todo se ejecuta en un núcleo.
Como puede imaginar, un flujo de ejecución típico va del código en la interfaz de usuario a través del núcleo de la aplicación al código de infraestructura, de regreso al núcleo de la aplicación y, finalmente, la respuesta se entrega a la interfaz de usuario.

Las herramientas
Lejos del código de kernel más importante, todavía hay herramientas que usa la aplicación. Por ejemplo, el motor de base de datos, el motor de búsqueda, el servidor web y la consola CLI (aunque los dos últimos también son mecanismos de entrega).
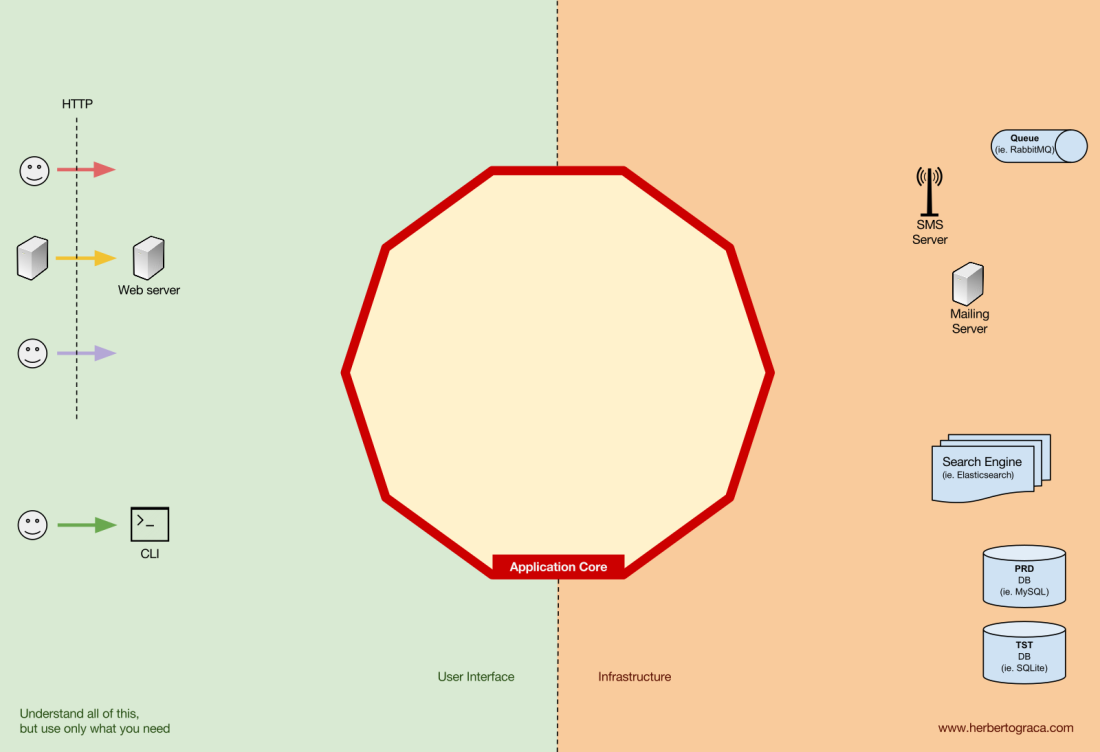
Parece extraño colocar la consola CLI en la misma sección temática que el DBMS, porque tienen un propósito diferente. Pero, de hecho, ambas son herramientas utilizadas por la aplicación. La diferencia clave es que la consola CLI y el servidor web le
dicen a la aplicación que haga algo , el núcleo DBMS, por el contrario,
recibe comandos de la aplicación . Esta es una diferencia muy importante, ya que afecta en gran medida la forma en que escribimos el código para conectar estas herramientas al núcleo de la aplicación.
Conexión de herramientas y mecanismos de entrega al núcleo de la aplicación
Los bloques de herramientas de conexión de código para el núcleo de la aplicación se denominan adaptadores (
arquitectura de puertos y adaptadores ). Permiten que la lógica de negocios interactúe con una herramienta específica, y viceversa.
Los adaptadores que le dicen a la aplicación que haga algo se llaman
adaptadores primarios o de control , mientras que los adaptadores que le dicen a la aplicación que haga algo se llaman
adaptadores secundarios o administrados .
Puertos
Sin embargo, estos
adaptadores no se crean por casualidad, sino que corresponden a un punto de entrada específico en el núcleo de la aplicación, el
puerto . Un puerto
no es
más que una especificación de cómo la herramienta puede usar el núcleo de la aplicación o viceversa. En la mayoría de los idiomas y en su forma más simple, este puerto será una interfaz, pero de hecho puede estar compuesto por varias interfaces y DTO.
Es importante tener en cuenta que los
puertos (interfaces) están dentro de la lógica empresarial y los adaptadores están afuera. Para que esta plantilla funcione correctamente, es extremadamente importante crear puertos de acuerdo con las necesidades del núcleo de la aplicación, y no solo imitar las API de la herramienta.
Adaptadores primarios o de control
Los adaptadores primarios o de control
envuelven un puerto y lo usan para decirle al núcleo de la aplicación qué hacer.
Transforman todos los datos del mecanismo de entrega en llamadas a métodos en el núcleo de la aplicación.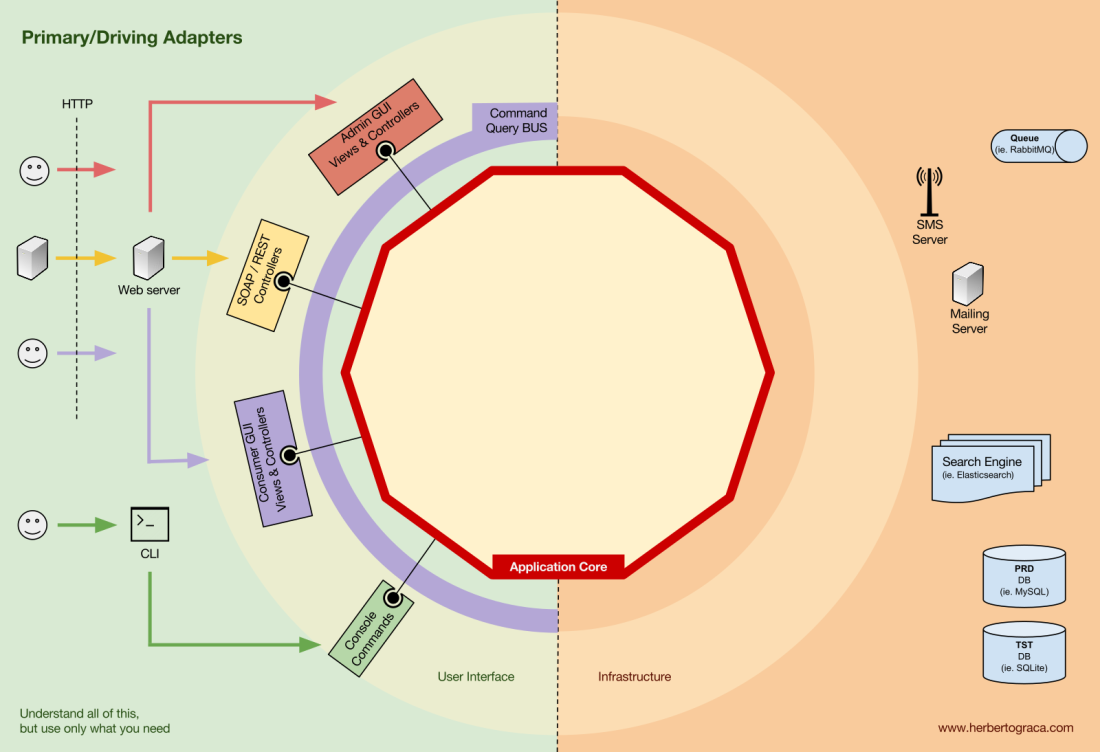
En otras palabras, nuestros adaptadores de control son controladores o comandos de consola, están integrados en su constructor con algún objeto cuya clase implementa la interfaz (puerto) que requiere un controlador o comando de consola.
En un ejemplo más específico, el puerto puede ser la interfaz de servicio o la interfaz de repositorio que requiere el controlador. Luego se implementa y se usa una implementación específica de un servicio, repositorio o solicitud en el controlador.
Además, el puerto puede ser un bus de comando o una interfaz de bus de consulta. En este caso, se ingresa una implementación específica del comando o bus de solicitud en el controlador, que luego crea un comando o solicitud y lo pasa al bus correspondiente.
Adaptadores secundarios o gestionados
A diferencia de los adaptadores de control que se envuelven alrededor de un puerto, los
adaptadores administrados implementan un puerto, una interfaz y luego ingresan al núcleo de la aplicación donde se requiere el puerto (con el tipo).

Por ejemplo, tenemos una aplicación nativa que necesita guardar datos. Creamos una interfaz de persistencia con un método para
guardar una matriz de datos y un método para
eliminar una fila en una tabla por su ID. A partir de ahora, siempre que la aplicación necesite guardar o eliminar datos, necesitaremos en el constructor un objeto que implemente la interfaz de persistencia que definimos.
Ahora cree un adaptador específico de MySQL que implementará esta interfaz. Tendrá métodos para guardar la matriz y eliminar la fila de la tabla, y la presentaremos donde sea que se requiera la interfaz de persistencia.
Si en algún momento decidimos cambiar el proveedor de la base de datos, por ejemplo, a PostgreSQL o MongoDB, solo necesitamos crear un nuevo adaptador que implemente la interfaz de persistencia específica para PostgreSQL e introducir un nuevo adaptador en lugar del anterior.
Inversión de control
Una característica de esta plantilla es que los adaptadores dependen de una herramienta específica y un puerto específico (mediante la implementación de una interfaz). Pero nuestra lógica empresarial depende solo del puerto (interfaz), que está diseñado para satisfacer las necesidades de la lógica empresarial y no depende de un adaptador o herramienta específicos.
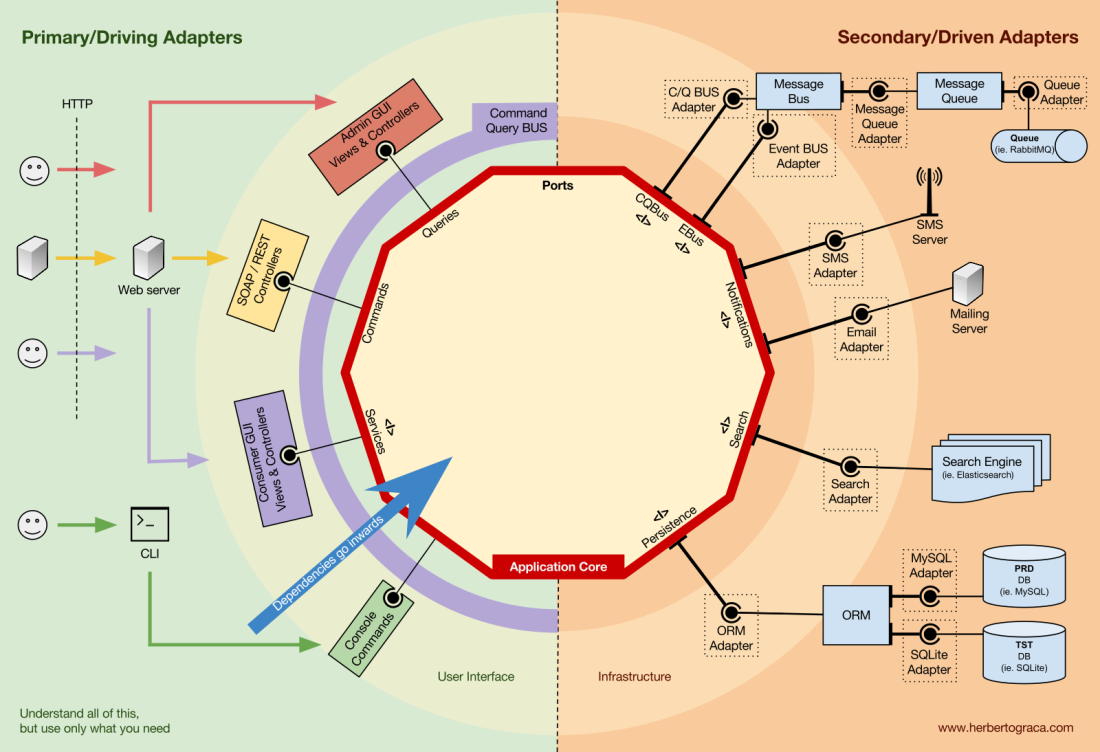
Esto significa que las dependencias se dirigen hacia el centro, es decir, hay una
inversión del principio de control a nivel arquitectónico .
Aunque, de nuevo,
es imperativo que los puertos se creen de acuerdo con las necesidades del núcleo de la aplicación, y no solo imiten las API de la herramienta .
Organización del núcleo de la aplicación.
La arquitectura Onion recoge las capas DDD y las incorpora en la
arquitectura del
puerto y del adaptador . Estos niveles están diseñados para dar cierto orden a la lógica empresarial, el interior del "hexágono" de puertos y adaptadores. Como antes, la dirección de las dependencias es hacia el centro.
Capa de aplicación (capa de aplicación)
Los casos de uso son procesos que pueden iniciarse en el núcleo mediante una o más interfaces de usuario. Por ejemplo, un CMS puede tener una interfaz de usuario para usuarios normales, otra interfaz de usuario independiente para administradores de CMS, otra CLI y una API web. Estas IU (aplicaciones) pueden desencadenar casos de uso únicos o comunes.
Los casos de uso se definen a nivel de aplicación: el primer nivel de DDD y la arquitectura de Onion.
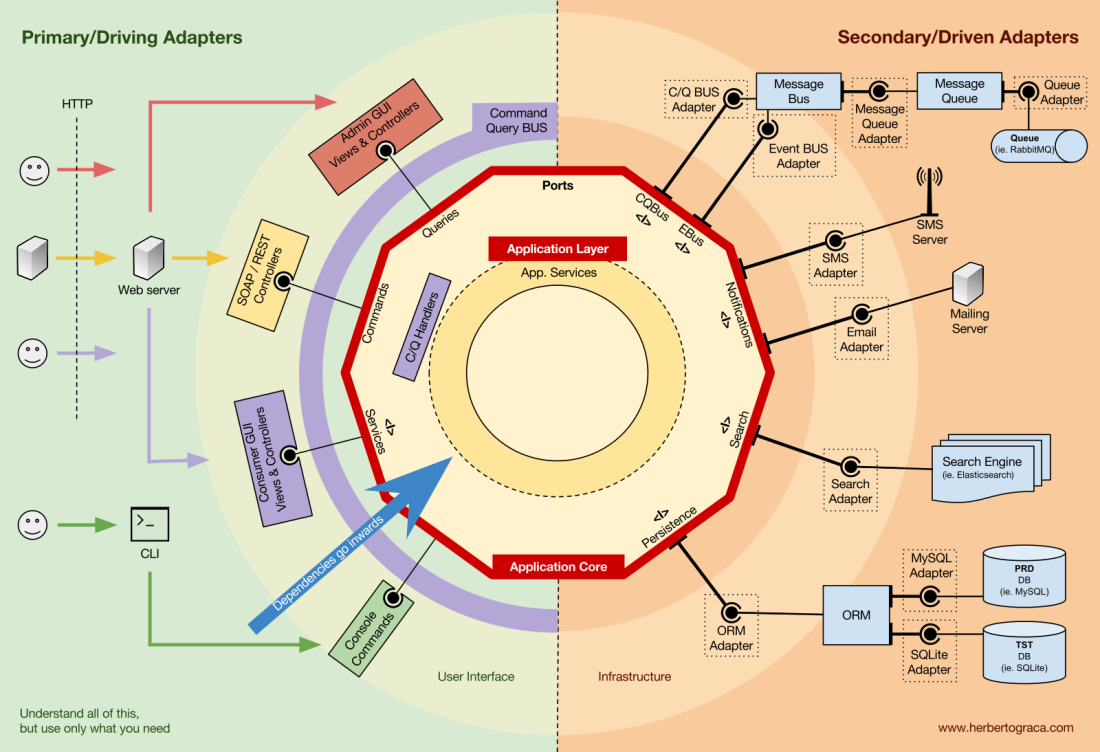
Esta capa contiene servicios de aplicaciones (y sus interfaces) como objetos de primera clase, y también contiene interfaces de puerto y adaptador (puertos), que incluyen interfaces ORM, interfaces de motor de búsqueda, interfaces de mensajería, etc. En el caso en el que usamos el bus de comando y / o el bus de solicitud, en este nivel están los manejadores de comando y solicitud correspondientes.
Los servicios de aplicaciones y / o los controladores de comandos contienen la lógica de implementación de un caso de uso, un proceso empresarial. Como regla, su papel es el siguiente:
- use el repositorio para buscar una o más entidades;
- pedir a estas entidades que ejecuten alguna lógica de dominio;
- y use el almacenamiento para volver a guardar entidades, guardando efectivamente los cambios de datos.
Los manejadores de comandos se pueden usar de dos maneras:
- Pueden contener lógica para ejecutar un caso de uso;
- Se pueden usar como partes simples de una conexión en nuestra arquitectura que reciben un comando y simplemente invocan la lógica que existe en el servicio de la aplicación.
El enfoque a utilizar depende del contexto, por ejemplo:
- Ya tenemos servicios de aplicaciones y ahora se agrega el bus de comandos.
- ¿El bus de comandos le permite especificar una clase / método como controlador, o necesita extender o implementar las clases o interfaces existentes?
Esta capa también contiene
eventos de aplicación de activación que representan algún resultado de un caso de uso. Estos eventos desencadenan una lógica que es un efecto secundario de un caso de uso, como enviar correos electrónicos, notificar a una API de terceros, enviar una notificación push o incluso iniciar otro caso de uso que pertenece a otro componente de la aplicación.
Nivel de dominio
Más adentro hay un nivel de dominio. Los objetos en este nivel contienen datos y lógica para administrar estos datos, que son específicos del dominio en sí y son independientes de los procesos comerciales que desencadenan esta lógica. Son independientes y completamente inconscientes del nivel de la aplicación.
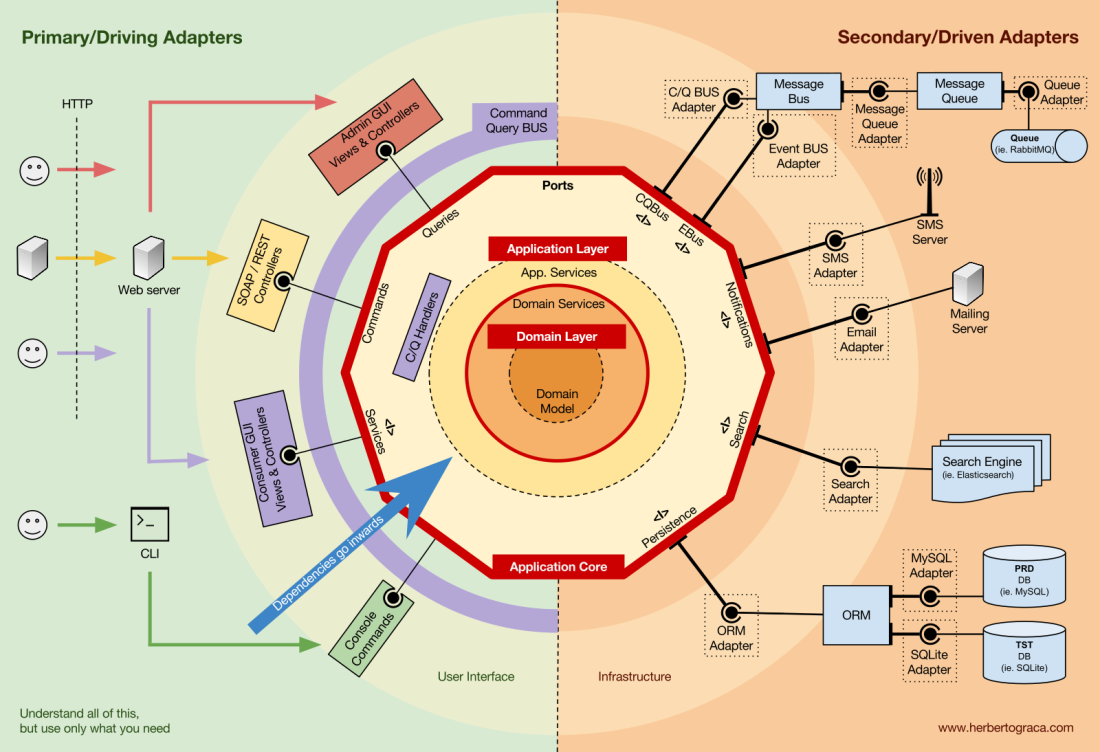
Servicios de dominio
Como mencioné anteriormente, el rol del servicio de aplicación:
- use el repositorio para buscar una o más entidades;
- pedir a estas entidades que ejecuten alguna lógica de dominio;
- y use el almacenamiento para volver a guardar entidades, guardando efectivamente los cambios de datos.
Pero a veces nos encontramos con alguna lógica de dominio, que incluye varias entidades del mismo tipo o de diferentes tipos, y esta lógica de dominio no pertenece a las entidades mismas, es decir, la lógica no es su responsabilidad directa.
Por lo tanto, nuestra primera reacción puede ser colocar esta lógica fuera de las entidades en el servicio de la aplicación. Sin embargo, esto significa que en otros casos la lógica del dominio no se reutilizará: ¡la lógica del dominio debe permanecer fuera del nivel de la aplicación!
La solución es crear un servicio de dominio, cuya función es obtener un conjunto de entidades y ejecutar cierta lógica empresarial en ellas. Un servicio de dominio pertenece a un nivel de dominio y, por lo tanto, no sabe nada sobre las clases a nivel de aplicación, como los servicios de aplicación o los repositorios. Por otro lado, puede usar otros servicios de dominio y, por supuesto, objetos de modelo de dominio.
Modelo de dominio
En el centro mismo está el modelo de dominio. No depende de nada fuera de este círculo y contiene objetos comerciales que representan algo en el dominio. Ejemplos de tales objetos son, en primer lugar, entidades, así como objetos de valor, enumeraciones y cualquier objeto utilizado en el modelo de dominio.
Los eventos de dominio también viven en el modelo de dominio. Cuando cambia un conjunto de datos específico, se desencadenan estos eventos, que contienen nuevos valores de las propiedades modificadas. Estos eventos son ideales, por ejemplo, para usar en el módulo de abastecimiento de eventos.
Componentes
Hasta ahora, hemos aislado código en capas, pero este es un aislamiento de código demasiado detallado. Es igualmente importante mirar la imagen con un aspecto más general. Estamos hablando de dividir el código en subdominios y
contextos relacionados de acuerdo con las ideas de Robert Martin expresadas en la
arquitectura de gritos [es decir, la arquitectura debería "gritar" sobre la aplicación en sí, y no sobre qué marcos usa - aprox. trans.]. Hablan sobre la organización de paquetes por función o componente, no por capa, y Simon Brown lo explicó bastante bien en el artículo
"Paquetes de componentes y pruebas de arquitectura" en su blog:
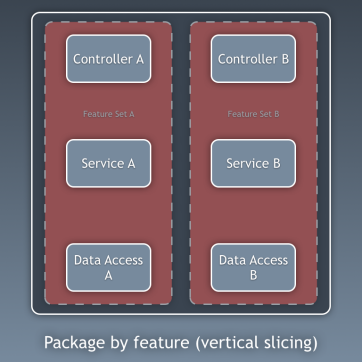
Soy partidario de organizar paquetes de componentes y quiero cambiar descaradamente el diagrama de Simon Brown de la siguiente manera:
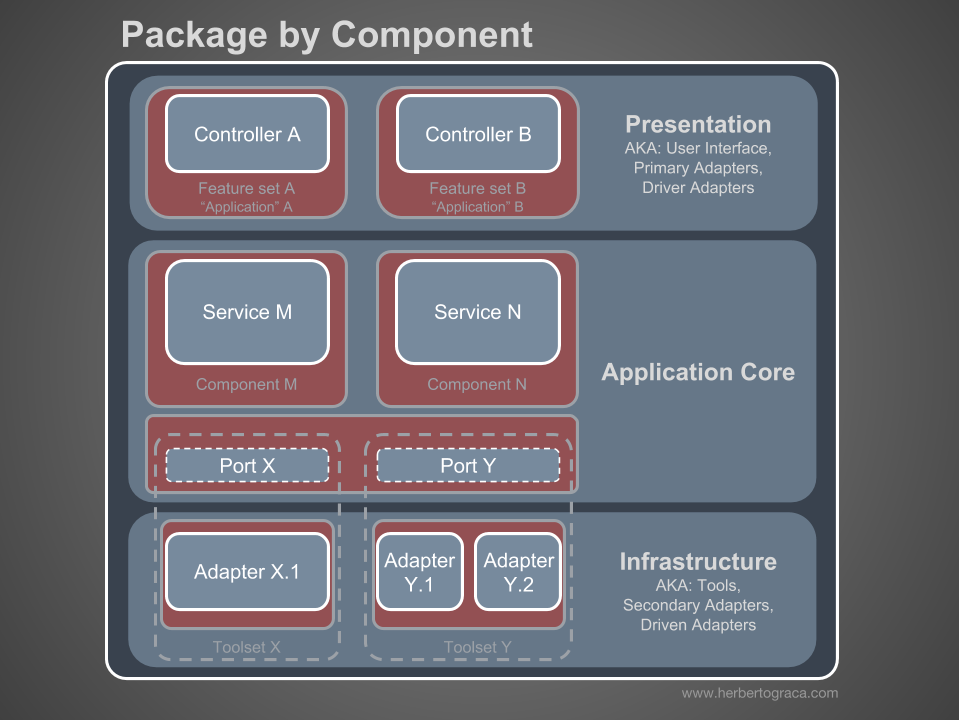
Estas secciones del código son transversales para todas las capas descritas anteriormente, y estos son los
componentes de nuestra aplicación. Ejemplos de componentes son facturación, usuario, verificación o cuenta, pero siempre están asociados con un dominio. Los contextos limitados, como la autorización y / o autenticación, deben considerarse herramientas externas para las cuales creamos un adaptador y nos escondemos detrás de un puerto.
Desconexión de componentes
Al igual que en las unidades de código de grano fino (clases, interfaces, rasgos, mixins, etc.), las unidades grandes (componentes) se benefician de un acoplamiento débil y una conectividad estrecha.
Para separar las clases, utilizamos la inyección de dependencias, introduciendo dependencias en la clase, en lugar de crearlas dentro de la clase, y también invirtiendo las dependencias, haciendo que la clase dependa de abstracciones (interfaces y / o clases abstractas) en lugar de clases específicas. Esto significa que la clase dependiente no sabe nada sobre la clase específica que usará, no tiene una referencia al nombre completo de las clases de las que depende.
Del mismo modo, en componentes completamente desconectados, cada componente no sabe nada sobre ningún otro componente. En otras palabras, ¡no tiene ningún enlace a ningún bloque de código de otro componente, ni siquiera a la interfaz! Esto significa que la inyección de dependencia y la inversión de dependencia no son suficientes para separar los componentes, necesitaremos algún tipo de construcción arquitectónica. ¡Es posible que se necesiten eventos, un núcleo común, consistencia eventual e incluso un servicio de descubrimiento!
Lógica de activación en otros componentes.
Cuando uno de nuestros componentes (componente B) necesita hacer algo cada vez que ocurre algo más en otro componente (componente A), no podemos simplemente hacer una llamada directa desde el componente A a la clase / método del componente B, porque entonces A estará conectado a B.
Sin embargo, podemos usar el administrador de eventos para enviar el evento de la aplicación, que se entregará a cualquier componente que lo escuche, incluido B, y el escucha de eventos en B activará la acción deseada. Esto significa que el componente A dependerá del administrador de eventos, pero estará separado del componente B.
Sin embargo, si el evento en sí "vive" en A, esto significa que B sabe acerca de la existencia de A y está asociado con él. Para eliminar esta dependencia, podemos crear una biblioteca con un conjunto de funcionalidades del núcleo de la aplicación que serán compartidas por todos los componentes, un
núcleo común . Esto significa que ambos componentes dependerán del núcleo común, pero estarán separados el uno del otro. Un núcleo común contiene funcionalidades tales como eventos de aplicación y dominio, pero también puede contener objetos de especificación y cualquier cosa que tenga sentido compartir. Al mismo tiempo, debe tener un tamaño mínimo, ya que cualquier cambio en el núcleo común afectará a todos los componentes de la aplicación. Además, si tenemos un sistema políglota, por ejemplo, un ecosistema de microservicios en diferentes idiomas, entonces el núcleo común no debería depender del idioma para que todos los componentes lo entiendan. Por ejemplo, en lugar de un núcleo común con una clase de evento, contendrá una descripción del evento (es decir, un nombre, propiedades, quizás incluso métodos, aunque serían más útiles en el objeto de especificación) en un lenguaje universal como JSON para que todos los componentes / microservicios puedan interpretarlo y quizás incluso generen automáticamente sus propias implementaciones específicas.
Este enfoque funciona tanto en aplicaciones monolíticas como distribuidas, como los ecosistemas de microservicios. Pero si los eventos se pueden entregar solo de forma asíncrona, entonces este enfoque no es suficiente para contextos donde la lógica de activación en otros componentes debería funcionar de inmediato. Aquí, el componente A necesitará realizar una llamada HTTP directa al componente B. En este caso, para desconectar los componentes, necesitamos un servicio de descubrimiento. El componente A le preguntará dónde enviar la solicitud para iniciar la acción deseada. Alternativamente, haga una solicitud al servicio de descubrimiento, que la reenviará al servicio apropiado y finalmente devolverá una respuesta al solicitante.
Este enfoque asocia componentes con un servicio de descubrimiento, pero no los asocia entre sí.Recuperando datos de otros componentes
Tal como lo veo, el componente no puede modificar datos que no "posee", pero puede solicitar y usar cualquier dato.Almacenamiento de datos compartidos para componentes
Si el componente debe usar datos que pertenecen a otro componente (por ejemplo, el componente de facturación debe usar el nombre del cliente que pertenece al componente de cuentas), entonces contiene el objeto de solicitud para el almacenamiento de datos. Es decir, el componente de facturación puede conocer cualquier conjunto de datos, pero debe usar datos de solo lectura de otros países.Almacenamiento de datos separado para el componente
En este caso, se aplica la misma plantilla, pero el nivel de almacenamiento de datos se vuelve más complicado. La presencia de componentes con su propio almacén de datos significa que cada almacén de datos contiene:- Un conjunto de datos que un componente posee y puede cambiar, lo que lo convierte en la única fuente de verdad;
- Un conjunto de datos que es una copia de los datos de otros componentes que no puede cambiar por sí mismo, pero que son necesarios para la funcionalidad del componente. Estos datos deben actualizarse siempre que cambien en el componente propietario.
Cada componente creará una copia local de los datos que necesita de otros componentes, que se utilizarán según sea necesario. Cuando los datos cambian en el componente al que pertenece, este componente propietario desencadena un evento de dominio que lleva cambios de datos. Los componentes que contienen una copia de estos datos escucharán este evento de dominio y actualizarán su copia local en consecuencia.Flujo de control
Como dije anteriormente, el flujo de control va del usuario al núcleo de la aplicación, a las herramientas de infraestructura, luego nuevamente al núcleo de la aplicación y de regreso al usuario. Pero, ¿cómo funcionan exactamente las clases juntas? ¿Quién depende de quién? ¿Cómo los componimos?Al igual que el tío Bob, en mi artículo sobre Arquitectura limpia, intentaré explicar el flujo de la administración de esquemas UMLish ...Sin comando / bus de solicitud
Si no usamos el bus de comandos, los controladores dependerán del servicio de aplicación o del objeto de consulta.[Suplemento 18/11/2017] Omití completamente el DTO, que utilizo para devolver datos de la solicitud, así que lo agregué ahora. Gracias a MorphineAdministered , que indicó un espacio. En el diagrama anterior, utilizamos la interfaz para el servicio de aplicaciones, aunque podemos decir que realmente no es necesario, ya que el servicio de aplicaciones es parte de nuestro código de aplicación. Pero no queremos cambiar la implementación, aunque podemos realizar una refactorización completa. El objeto Consulta contiene una consulta optimizada que simplemente devuelve algunos datos sin procesar que se mostrarán al usuario. Estos datos se devuelven al DTO, que está incrustado en el ViewModel. Este ViewModel puede tener algún tipo de lógica de Vista y se usará para llenar la Vista.Por otro lado, el servicio de aplicación contiene lógica de casos de uso que se activa cuando queremos hacer algo en el sistema, y no solo ver algunos datos. El servicio de aplicación depende de repositorios que devuelven entidades que contienen la lógica que debe iniciarse. También puede depender del servicio de dominio para coordinar el proceso del dominio en varias entidades, pero este es un caso raro.Después de analizar el caso de uso, el servicio de aplicación puede notificar a todo el sistema que se ha producido un caso de uso, luego dependerá del despachador de eventos para activar el evento.Es interesante observar que alojamos interfaces tanto en el motor de persistencia como en los repositorios. Esto puede parecer redundante, pero tienen diferentes propósitos:
El objeto Consulta contiene una consulta optimizada que simplemente devuelve algunos datos sin procesar que se mostrarán al usuario. Estos datos se devuelven al DTO, que está incrustado en el ViewModel. Este ViewModel puede tener algún tipo de lógica de Vista y se usará para llenar la Vista.Por otro lado, el servicio de aplicación contiene lógica de casos de uso que se activa cuando queremos hacer algo en el sistema, y no solo ver algunos datos. El servicio de aplicación depende de repositorios que devuelven entidades que contienen la lógica que debe iniciarse. También puede depender del servicio de dominio para coordinar el proceso del dominio en varias entidades, pero este es un caso raro.Después de analizar el caso de uso, el servicio de aplicación puede notificar a todo el sistema que se ha producido un caso de uso, luego dependerá del despachador de eventos para activar el evento.Es interesante observar que alojamos interfaces tanto en el motor de persistencia como en los repositorios. Esto puede parecer redundante, pero tienen diferentes propósitos:- La interfaz de persistencia es una capa de abstracción sobre ORM, por lo que podemos intercambiar ORM sin cambiar el núcleo de la aplicación.
- persistence-. , MySQL MongoDB. persistence- , ORM, . , , , , , , MongoDB SQL.
C /
Si nuestra aplicación usa el bus de comando / solicitud, el diagrama permanece casi igual, excepto que el controlador ahora depende del bus, así como de los comandos o solicitudes. Aquí se crea una instancia de un comando o solicitud y se pasa al bus, que encontrará el controlador adecuado para recibir y procesar el comando.En el siguiente diagrama, el controlador de comandos utiliza el servicio de la aplicación. Pero esto no siempre es necesario, porque en la mayoría de los casos el controlador contendrá toda la lógica del caso de uso. Todo lo que necesitamos hacer es extraer la lógica del controlador en un servicio de aplicación separado si necesitamos reutilizar la misma lógica en otro controlador.[Suplemento 18/11/2017] Omití completamente el DTO, que utilizo para devolver datos de la solicitud, así que lo agregué ahora. GraciasMorphineAdministered , que indica un espacio. Es posible que haya notado que no hay dependencias entre el bus, el comando, la solicitud y los controladores. De hecho, no necesitan conocerse para garantizar una buena separación. El método de dirigir el bus a un controlador específico para procesar un comando o solicitud se configura en una configuración simple. En ambos casos, todas las flechas, dependencias que cruzan el límite del núcleo de la aplicación, apuntan hacia adentro. Como se explicó anteriormente, esta es la regla fundamental de los puertos y los adaptadores, la cebolla y la arquitectura limpia.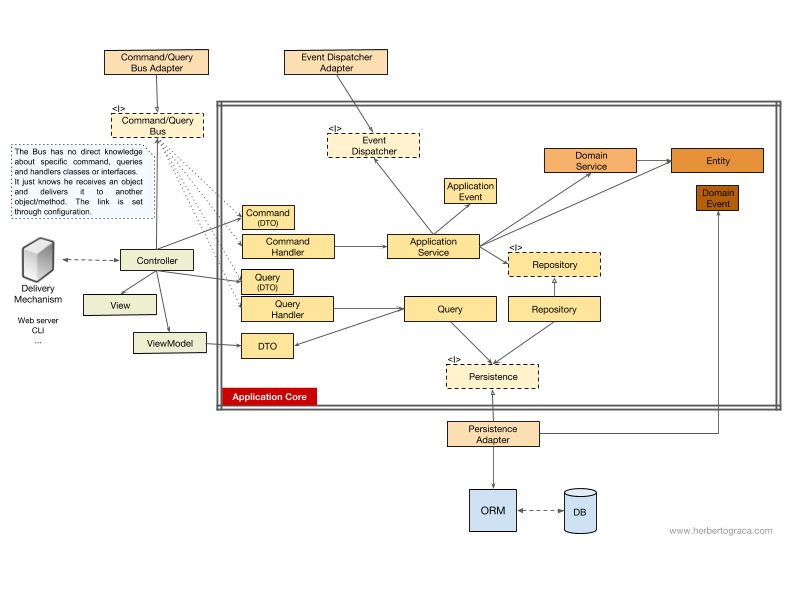

Conclusión
Como siempre, el objetivo es obtener una base de código desconectada con alta conectividad, en la que pueda realizar cualquier cambio de manera fácil, rápida y segura.Los planes son inútiles, pero la planificación lo es todo. - Eisenhower
Esta infografía es un mapa conceptual. Conocer y comprender todos estos conceptos le ayuda a planificar una arquitectura saludable y una aplicación viable.Sin embargo:Un mapa no es un territorio. - Alfred Korzybsky
En otras palabras, ¡ estas son solo recomendaciones! Una aplicación es un territorio, una realidad, un caso de uso específico donde necesitamos aplicar nuestros conocimientos, ¡y determina cómo será la arquitectura real!Debemos comprender todos estos patrones, pero también siempre debemos pensar y comprender qué necesita nuestra aplicación, hasta dónde podemos llegar en aras de la separación y la conexión. Esta decisión depende de muchos factores, que van desde los requisitos funcionales del proyecto hasta el momento del desarrollo de la aplicación, su vida útil, la experiencia del equipo de desarrollo, etc.Así es como me imagino todo esto por mí mismo.Estas ideas se analizan con más detalle en el próximo artículo: "Más que capas concéntricas" .