Hola a todos! Recientemente, fue necesario escribir código para implementar la segmentación de imágenes usando el método k-means (inglés k-means). Bueno, lo primero que hace Google es ayudar. Encontré mucha información, como desde un punto de vista matemático (todo tipo de garabatos matemáticos complejos allí, comprenderá qué demonios está escrito allí), así como algunas implementaciones de software que están en Internet en inglés. Estos códigos son ciertamente hermosos, sin duda, pero la esencia de la idea es difícil de entender. De alguna manera, todo es complicado allí, confuso, y sin embargo, a mano, a mano, no escribirás el código, no entenderás nada. En este artículo quiero mostrar una implementación simple, no productiva, pero espero que sea comprensible de este maravilloso algoritmo. Ok, vamos!
Entonces, ¿qué es la agrupación en términos de nuestras percepciones? Déjame darte un ejemplo, digamos que hay una bonita foto con flores de la cabaña de tu abuela.

La pregunta es: para determinar cuántas áreas en esta foto se rellenan con aproximadamente el mismo color. Bueno, no es para nada difícil: pétalos blancos, uno, centros amarillos, dos (no soy biólogo, no sé cómo se llaman), tres verdes. Estas secciones se llaman grupos. Un clúster es una combinación de datos que tienen características comunes (color, posición, etc.). El proceso de determinar y colocar cada componente de cualquier dato en dichos grupos - secciones se denomina agrupamiento.
Hay muchos algoritmos de agrupamiento, pero el más simple de ellos es k - medio, que se discutirá más adelante. K-means es un algoritmo simple y eficiente que es fácil de implementar utilizando un método de software. Los datos que distribuiremos en grupos son píxeles. Como sabes, un píxel de color tiene tres componentes: rojo, verde y azul. La imposición de estos componentes y crea una paleta de colores existentes.
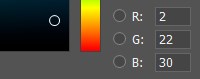
En la memoria de la computadora, cada componente de color se caracteriza por un número de 0 a 255. Es decir, combinando diferentes valores de rojo, verde y azul, obtenemos una paleta de colores en la pantalla.
Usando píxeles como ejemplo, implementamos nuestro algoritmo. K-means es un algoritmo iterativo, es decir, dará el resultado correcto, después de un cierto número de repeticiones de algunos cálculos matemáticos.
Algoritmo
- Debe saber de antemano cuántos clústeres necesita para distribuir los datos. Esta es una desventaja significativa de este método, pero este problema se resuelve con implementaciones mejoradas del algoritmo, pero esto, como dicen, es una historia completamente diferente.
- Necesitamos elegir los centros iniciales de nuestros grupos. Como? Si al azar. Por qué Para que pueda ajustar cada píxel al centro del clúster. El centro es como el Rey, alrededor del cual se reúnen sus sujetos: píxeles. Es la "distancia" desde el centro al píxel lo que determina a quién obedecerá cada píxel.
- Calculamos la distancia desde cada centro a cada píxel. Esta distancia se considera como la distancia euclidiana entre puntos en el espacio y, en nuestro caso, como la distancia entre los tres componentes de color:
$$ display $$ \ sqrt {(R_ {2} -R_ {1}) ^ 2 + (G_ {2} -G_ {1}) ^ 2 + (B_ {2} -B_ {1}) ^ 2} . $$ display $$
Calculamos la distancia desde el primer píxel a cada centro y determinamos la distancia más pequeña entre este píxel y los centros. Para el centro, la distancia a la cual es el más pequeño, recalculamos las coordenadas como la media aritmética entre cada componente del píxel, el rey y el píxel, el sujeto. Nuestro centro cambia en el espacio según los cálculos. - Después de contar todos los centros, distribuimos los píxeles en grupos, comparando la distancia de cada píxel a los centros. Un píxel se coloca en un grupo, al centro del cual está más cerca que a los otros centros.
- Todo comienza de nuevo, siempre y cuando los píxeles permanezcan en los mismos grupos. A menudo esto puede no suceder, ya que con una gran cantidad de datos los centros se moverán en un radio pequeño, y los píxeles a lo largo de los bordes de los grupos saltarán a uno u otro grupo. Para hacer esto, determine el número máximo de iteraciones.
Implementación
Implementaré este proyecto en C ++. El primer archivo es "k_means.h", en el que definí los principales tipos de datos, constantes y la clase principal para trabajar: "K_means".
Para caracterizar cada píxel, cree una estructura que consta de tres componentes de píxel, para los cuales elegí el tipo doble para cálculos más precisos, y también definí algunas constantes para que el programa funcione:
const int KK = 10;
K_means clase en sí:
class K_means { private: std::vector<rgb> pixcel; int q_klaster; int k_pixcel; std::vector<rgb> centr; void identify_centers(); inline double compute(rgb k1, rgb k2) { return sqrt(pow((k1.r - k2.r),2) + pow((k1.g - k2.g), 2) + pow((k1.b - k2.b), 2)); } inline double compute_s(double a, double b) { return (a + b) / 2; }; public: K_means() : q_klaster(0), k_pixcel(0) {}; K_means(int n, rgb *mas, int n_klaster); K_means(int n_klaster, std::istream & os); void clustering(std::ostream & os); void print()const; ~K_means(); friend std::ostream & operator<<(std::ostream & os, const K_means & k); };
Repasemos los componentes de la clase:
vectorpixcel: un vector para píxeles;
q_klaster - número de clusters;
k_pixcel - número de píxeles;
vectorcentr - un vector para centros de agrupamiento, el número de elementos en él está determinado por q_klaster;
Identificar_centros (): un método para seleccionar aleatoriamente los centros iniciales entre los píxeles de entrada;
compute () y compute_s () son métodos integrados para calcular la distancia entre píxeles y centros de recálculo, respectivamente;
tres constructores: el primero es por defecto, el segundo es para inicializar píxeles desde una matriz, el tercero es para inicializar píxeles desde un archivo de texto (en mi implementación, el archivo se llena accidentalmente con datos al principio, y luego los píxeles se leen desde este archivo para que el programa funcione, ¿por qué no directamente en el vector? solo es necesario en mi caso);
agrupamiento (std :: ostream & os) - método de agrupamiento;
método y sobrecarga de la declaración de salida para publicar los resultados.
Implementación del método:
void K_means::identify_centers() { srand((unsigned)time(NULL)); rgb temp; rgb *mas = new rgb[q_klaster]; for (int i = 0; i < q_klaster; i++) { temp = pixcel[0 + rand() % k_pixcel]; for (int j = i; j < q_klaster; j++) { if (temp.r != mas[j].r && temp.g != mas[j].g && temp.b != mas[j].b) { mas[j] = temp; } else { i--; break; } } } for (int i = 0; i < q_klaster; i++) { centr.push_back(mas[i]); } delete []mas; }
Este es un método para seleccionar los centros de agrupación iniciales y agregarlos al vector del centro. Se realiza una verificación para repetir centros y reemplazarlos en estos casos.
K_means::K_means(int n, rgb * mas, int n_klaster) { for (int i = 0; i < n; i++) { pixcel.push_back(*(mas + i)); } q_klaster = n_klaster; k_pixcel = n; identify_centers(); }
Una implementación de constructor para inicializar píxeles desde una matriz.
K_means::K_means(int n_klaster, std::istream & os) : q_klaster(n_klaster) { rgb temp; while (os >> temp.r && os >> temp.g && os >> temp.b) { pixcel.push_back(temp); } k_pixcel = pixcel.size(); identify_centers(); }
Pasamos un objeto de entrada a este constructor para poder ingresar datos tanto del archivo como de la consola.
void K_means::clustering(std::ostream & os) { os << "\n\n :" << std::endl; std::vector<int> check_1(k_pixcel, -1); std::vector<int> check_2(k_pixcel, -2); int iter = 0; while(true) { os << "\n\n---------------- №" << iter << " ----------------\n\n"; { for (int j = 0; j < k_pixcel; j++) { double *mas = new double[q_klaster]; for (int i = 0; i < q_klaster; i++) { *(mas + i) = compute(pixcel[j], centr[i]); os << " " << j << " #" << i << ": " << *(mas + i) << std::endl; } double min_dist = *mas; int m_k = 0; for (int i = 0; i < q_klaster; i++) { if (min_dist > *(mas + i)) { min_dist = *(mas + i); m_k = i; } } os << " #" << m_k << std::endl; os << " #" << m_k << ": "; centr[m_k].r = compute_s(pixcel[j].r, centr[m_k].r); centr[m_k].g = compute_s(pixcel[j].g, centr[m_k].g); centr[m_k].b = compute_s(pixcel[j].b, centr[m_k].b); os << centr[m_k].r << " " << centr[m_k].g << " " << centr[m_k].b << std::endl; delete[] mas; } int *mass = new int[k_pixcel]; os << "\n : "<< std::endl; for (int k = 0; k < k_pixcel; k++) { double *mas = new double[q_klaster]; for (int i = 0; i < q_klaster; i++) { *(mas + i) = compute(pixcel[k], centr[i]); os << " №" << k << " #" << i << ": " << *(mas + i) << std::endl; } double min_dist = *mas; int m_k = 0; for (int i = 0; i < q_klaster; i++) { if (min_dist > *(mas + i)) { min_dist = *(mas + i); m_k = i; } } mass[k] = m_k; os << " №" << k << " #" << m_k << std::endl; } os << "\n : \n"; for (int i = 0; i < k_pixcel; i++) { os << mass[i] << " "; check_1[i] = *(mass + i); } os << std::endl << std::endl; os << " : " << std::endl; int itr = KK + 1; for (int i = 0; i < q_klaster; i++) { os << " #" << i << std::endl; for (int j = 0; j < k_pixcel; j++) { if (mass[j] == i) { os << pixcel[j].r << " " << pixcel[j].g << " " << pixcel[j].b << std::endl; mass[j] = ++itr; } } } delete[] mass; os << " : \n" ; for (int i = 0; i < q_klaster; i++) { os << centr[i].r << " " << centr[i].g << " " << centr[i].b << " - #" << i << std::endl; } } iter++; if (check_1 == check_2 || iter >= max_iterations) { break; } check_2 = check_1; } os << "\n\n ." << std::endl; }
El principal método de agrupamiento.
std::ostream & operator<<(std::ostream & os, const K_means & k) { os << " : " << std::endl; for (int i = 0; i < k.k_pixcel; i++) { os << k.pixcel[i].r << " " << k.pixcel[i].g << " " << k.pixcel[i].b << " - №" << i << std::endl; } os << std::endl << " : " << std::endl; for (int i = 0; i < k.q_klaster; i++) { os << k.centr[i].r << " " << k.centr[i].g << " " << k.centr[i].b << " - #" << i << std::endl; } os << "\n : " << k.q_klaster << std::endl; os << " : " << k.k_pixcel << std::endl; return os; }
La salida de los datos iniciales.
Ejemplo de salida
Ejemplo de salidaPíxeles de inicio:
255 140 50 - No. 0
100 70 1 - No. 1
150 20 200 - No. 2
251 141 51 - No.3
104 69 3 - No. 4
153 22 210 - No. 5
252 138 54 - No. 6
101 74 4 - No. 7
Centros de agrupamiento inicial aleatorio:
150 20 200 - # 0
104 69 3 - # 1
100 70 1 - # 2
Número de grupos: 3
Número de píxeles: 8
Inicio de clúster:
Número de iteración 0
Distancia del píxel 0 al centro # 0: 218.918
Distancia del píxel 0 al centro # 1: 173.352
Distancia desde el píxel 0 al centro # 2: 176.992
Distancia mínima al centro # 1
Recalculando el centro # 1: 179.5 104.5 26.5
Distancia del píxel 1 al centro # 0: 211.189
Distancia del píxel 1 al centro n. ° 1: 90.3369
Distancia desde el píxel 1 al centro # 2: 0
Distancia mínima al centro # 2
Recalculando el centro # 2: 100 70 1
Distancia del píxel 2 al centro 0: 0
Distancia desde el píxel 2 al centro n. ° 1: 195.225
Distancia desde el píxel 2 al centro # 2: 211.189
Distancia mínima al centro # 0
Contando el centro # 0: 150 20200
Distancia desde el píxel 3 al centro # 0: 216.894
Distancia desde el píxel 3 al centro n. ° 1: 83.933
Distancia del píxel 3 al centro n. ° 2: 174.19
Distancia mínima al centro # 1
Contando el centro # 1: 215.25 122.75 38.75
Distancia desde el píxel 4 al centro # 0: 208.149
Distancia del píxel 4 al centro # 1: 128.622
Distancia del píxel 4 al centro n. ° 2: 4.58258
Distancia mínima al centro # 2
Contando el centro # 2: 102 69.5 2
Distancia del píxel 5 al centro # 0: 10.6301
Distancia desde el píxel 5 al centro n. ° 1: 208.212
Distancia del píxel 5 al centro n. ° 2: 219.366
Distancia mínima al centro # 0
Recalculando el centro # 0: 151.5 21 205
Distancia del píxel 6 al centro # 0: 215.848
Distancia desde el píxel 6 al centro n. ° 1: 42.6109
Distancia desde el píxel 6 al centro # 2: 172.905
Distancia mínima al centro # 1
Recalculando el centro # 1: 233.625 130.375 46.375
Distancia desde el píxel 7 al centro # 0: 213.916
Distancia desde el píxel 7 al centro n. ° 1: 150,21
Distancia del píxel 7 al centro # 2: 5.02494
Distancia mínima al centro # 2
Recalculando el centro # 2: 101.5 71.75 3
Clasifiquemos los píxeles:
La distancia desde el píxel n. ° 0 al centro n. ° 0: 221.129
La distancia desde el píxel n. ° 0 al centro n. ° 1: 23.7207
La distancia desde el píxel n. ° 0 al centro n. ° 2: 174.44
Pixel # 0 más cercano al centro # 1
La distancia desde el píxel n. ° 1 al centro n. ° 0: 216.031
La distancia desde el píxel n. ° 1 al centro n. ° 1: 153.492
La distancia desde el píxel n. ° 1 al centro n. ° 2: 3.05164
Pixel # 1 más cercano al centro # 2
La distancia desde el píxel No. 2 al centro # 0: 5.31507
La distancia desde el píxel n. ° 2 al centro n. ° 1: 206.825
La distancia desde el píxel n. ° 2 al centro n. ° 2: 209.378
Pixel # 2 más cercano al centro # 0
La distancia desde el píxel número 3 al centro # 0: 219.126
La distancia desde el píxel n. ° 3 al centro n. ° 1: 20.8847
La distancia desde el píxel n. ° 3 al centro n. ° 2: 171.609
Pixel # 3 más cercano al centro # 1
La distancia desde el píxel n. ° 4 al centro n. ° 0: 212.989
La distancia desde el píxel n. ° 4 al centro n. ° 1: 149.836
La distancia desde el píxel n. ° 4 al centro n. ° 2: 3.71652
Pixel # 4 más cercano al centro # 2
La distancia desde el píxel n. ° 5 al centro n. ° 0: 5.31507
La distancia desde el píxel n. ° 5 al centro n. ° 1: 212.176
La distancia desde el píxel n. ° 5 al centro n. ° 2: 219.035
Pixel # 5 más cercano al centro # 0
La distancia desde el número de píxel 6 al centro # 0: 215.848
La distancia desde el píxel n. ° 6 al centro n. ° 1: 21.3054
La distancia desde el píxel número 6 al centro # 2: 172.164
Pixel # 6 más cercano al centro # 1
La distancia desde el píxel n. ° 7 al centro n. ° 0: 213.916
La distancia desde el píxel n. ° 7 al centro n. ° 1: 150,21
La distancia desde el píxel n. ° 7 al centro n. ° 2: 2.51247
Pixel # 7 más cercano al centro # 2
Una serie de píxeles y centros coincidentes:
1 2 0 1 2 0 1 2
Resultado de agrupamiento:
Cluster # 0
150 20 200
153 22 210
Cluster # 1
255 140 50
251 141 51
252 138 54
Cluster # 2
100 70 1
104 69 3
101 74 4
Nuevos centros:
151.5 21 205 - # 0
233.625 130.375 46.375 - # 1
101.5 71.75 3 - # 2
Iteración número 1
Distancia del píxel 0 al centro # 0: 221.129
Distancia del píxel 0 al centro n. ° 1: 23.7207
Distancia del píxel 0 al centro # 2: 174.44
Distancia mínima al centro # 1
Contando el centro # 1: 244.313 135.188 48.1875
Distancia desde el píxel 1 al centro # 0: 216.031
Distancia del píxel 1 al centro n. ° 1: 165.234
Distancia del píxel 1 al centro n. ° 2: 3.05164
Distancia mínima al centro # 2
Recalculando el centro # 2: 100.75 70.875 2
Distancia del píxel 2 al centro # 0: 5.31507
Distancia del píxel 2 al centro # 1: 212.627
Distancia del píxel 2 al centro n. ° 2: 210,28
Distancia mínima al centro # 0
Recalculando el centro # 0: 150.75 20.5 202.5
Distancia del píxel 3 al centro # 0: 217.997
Distancia del píxel 3 al centro # 1: 9.29613
Distancia del píxel 3 al centro # 2: 172.898
Distancia mínima al centro # 1
Contando el centro # 1: 247.656 138.094 49.5938
Distancia desde el píxel 4 al centro # 0: 210.566
Distancia del píxel 4 al centro n. ° 1: 166.078
Distancia del píxel 4 al centro # 2: 3.88306
Distancia mínima al centro # 2
Contando el centro # 2: 102.375 69.9375 2.5
Distancia desde el píxel 5 al centro # 0: 7.97261
Distancia del píxel 5 al centro # 1: 219.471
Distancia del píxel 5 al centro # 2: 218.9
Distancia mínima al centro # 0
Contando el centro # 0: 151.875 21.25 206.25
Distancia desde el píxel 6 al centro # 0: 216.415
Distancia del píxel 6 al centro n. ° 1: 6.18805
Distancia del píxel 6 al centro n. ° 2: 172.257
Distancia mínima al centro # 1
Recalculando el centro # 1: 249.828 138.047 51.7969
Distancia desde el píxel 7 al centro # 0: 215.118
Distancia desde el píxel 7 al centro # 1: 168.927
Distancia desde el píxel 7 al centro # 2: 4.54363
Distancia mínima al centro # 2
Recalculando el centro # 2: 101.688 71.9688 3.25
Clasifiquemos los píxeles:
La distancia desde el píxel n. ° 0 al centro n. ° 0: 221.699
La distancia desde el píxel n. ° 0 al centro n. ° 1: 5.81307
La distancia desde el píxel n. ° 0 al centro n. ° 2: 174.122
Pixel # 0 más cercano al centro # 1
La distancia desde el píxel n. ° 1 al centro n. ° 0: 217.244
La distancia desde el píxel n. ° 1 al centro n. ° 1: 172.218
La distancia desde el píxel n. ° 1 al centro n. ° 2: 3.43309
Pixel # 1 más cercano al centro # 2
La distancia desde el píxel n. ° 2 al centro n. ° 0: 6.64384
La distancia desde el píxel n. ° 2 al centro n. ° 1: 214.161
La distancia desde el píxel n. ° 2 al centro n. ° 2: 209.154
Pixel # 2 más cercano al centro # 0
La distancia desde el píxel n. ° 3 al centro n. ° 0: 219.701
Distancia desde el píxel n. ° 3 al centro n. ° 1: 3.27555
La distancia desde el píxel n. ° 3 al centro n. ° 2: 171.288
Pixel # 3 más cercano al centro # 1
La distancia desde el píxel n. ° 4 al centro n. ° 0: 214.202
La distancia desde el píxel n. ° 4 al centro n. ° 1: 168.566
La distancia desde el píxel n. ° 4 al centro n. ° 2: 3.77142
Pixel # 4 más cercano al centro # 2
La distancia desde el píxel No. 5 al centro # 0: 3.9863
La distancia desde el píxel n. ° 5 al centro n. ° 1: 218.794
La distancia desde el píxel n. ° 5 al centro n. ° 2: 218.805
Pixel # 5 más cercano al centro # 0
La distancia desde el píxel número 6 al centro # 0: 216.415
La distancia desde el píxel n. ° 6 al centro n. ° 1: 3.09403
La distancia desde el píxel n. ° 6 al centro n. ° 2: 171.842
Pixel # 6 más cercano al centro # 1
La distancia desde el píxel n. ° 7 al centro n. ° 0: 215.118
La distancia desde el píxel n. ° 7 al centro n. ° 1: 168.927
La distancia desde el píxel n. ° 7 al centro n. ° 2: 2.27181
Pixel # 7 más cercano al centro # 2
Una serie de píxeles y centros coincidentes:
1 2 0 1 2 0 1 2
Resultado de agrupamiento:
Cluster # 0
150 20 200
153 22 210
Cluster # 1
255 140 50
251 141 51
252 138 54
Cluster # 2
100 70 1
104 69 3
101 74 4
Nuevos centros:
151.875 21.25 206.25 - # 0
249.828 138.047 51.7969 - # 1
101.688 71.9688 3.25 - # 2
El final de la agrupación.
Este ejemplo está planeado con anticipación, los píxeles se seleccionan específicamente para demostración. Dos iteraciones son suficientes para que el programa agrupe los datos en tres grupos. Mirando los centros de las dos últimas iteraciones, puede ver que prácticamente permanecieron en su lugar.
Más interesantes son los casos de píxeles generados aleatoriamente. Habiendo generado 50 puntos que deben dividirse en 10 grupos, obtuve 5 iteraciones. Habiendo generado 50 puntos que deben dividirse en 3 grupos, obtuve las 100 iteraciones máximas permitidas. Puede notar que cuantos más grupos, más fácil es para el programa encontrar los píxeles más similares y combinarlos en grupos más pequeños, y viceversa: si hay pocos grupos y hay muchos puntos, el algoritmo a menudo termina solo cuando se excede el número máximo de iteraciones, ya que algunos píxeles saltan constantemente de un grupo a otro. Sin embargo, la mayor parte aún se determina en sus grupos por completo.
Bueno, ahora verifiquemos el resultado de la agrupación. Tomando el resultado de algunos grupos del ejemplo de 50 puntos por cada 10 grupos, conduje el resultado de estos datos a Illustrator y esto es lo que sucedió:
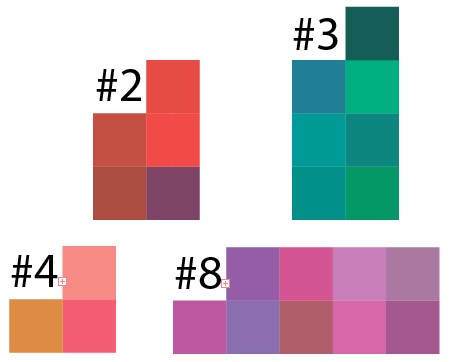
Se puede ver que en cada grupo prevalece cualquier tono de color, y aquí debe comprender que los píxeles se seleccionaron al azar, el análogo de dicha imagen en la vida real es algún tipo de imagen sobre la que se rociaron accidentalmente todos los colores y es difícil seleccionar áreas de colores similares.
Digamos que tenemos una foto así. Podemos definir una isla como un grupo, pero con un aumento vemos que consiste en diferentes tonos de verde.

Y este es el clúster 8, pero en una versión más pequeña, el resultado es similar:

La versión completa del programa se puede ver en mi
GitHub .