Instituto de Tecnología de Massachusetts. Conferencia Curso # 6.858. "Seguridad de los sistemas informáticos". Nikolai Zeldovich, James Mickens. Año 2014
Computer Systems Security es un curso sobre el desarrollo e implementación de sistemas informáticos seguros. Las conferencias cubren modelos de amenazas, ataques que comprometen la seguridad y técnicas de seguridad basadas en trabajos científicos recientes. Los temas incluyen seguridad del sistema operativo (SO), características, gestión del flujo de información, seguridad del idioma, protocolos de red, seguridad de hardware y seguridad de aplicaciones web.
Lección 1: "Introducción: modelos de amenaza"
Parte 1 /
Parte 2 /
Parte 3Lección 2: "Control de ataques de hackers"
Parte 1 /
Parte 2 /
Parte 3Lección 3: “Desbordamientos del búfer: exploits y protección”
Parte 1 /
Parte 2 /
Parte 3Lección 4: “Separación de privilegios”
Parte 1 /
Parte 2 /
Parte 3Lección 5: “¿De dónde vienen los sistemas de seguridad?”
Parte 1 /
Parte 2Lección 6: “Oportunidades”
Parte 1 /
Parte 2 /
Parte 3Lección 7: “Sandbox de cliente nativo”
Parte 1 /
Parte 2 /
Parte 3Lección 8: "Modelo de seguridad de red"
Parte 1 /
Parte 2 /
Parte 3Lección 9: "Seguridad de aplicaciones web"
Parte 1 /
Parte 2 /
Parte 3Lección 10: “Ejecución simbólica”
Parte 1 /
Parte 2 /
Parte 3Lección 11: "Ur / Lenguaje de programación web"
Parte 1 /
Parte 2 /
Parte 3Lección 12: Seguridad de red
Parte 1 /
Parte 2 /
Parte 3Lección 13: "Protocolos de red"
Parte 1 /
Parte 2 /
Parte 3 Entonces, hoy hablaremos de Kerberos, un protocolo criptográficamente seguro diseñado para la autenticación mutua de computadoras y aplicaciones en la red. Este es un protocolo para autenticar el cliente y el servidor antes de establecer una conexión entre ellos.
Así que ahora, finalmente, usaremos criptografía, a diferencia de la última conferencia, donde analizamos la seguridad utilizando solo números de secuencia TCP SYN.

Entonces hablemos de Kerberos. ¿Qué está tratando de soportar este protocolo? Fue creado en nuestro instituto hace 25 o 30 años como parte del proyecto Athena para garantizar la interacción de múltiples servidores y computadoras de múltiples clientes.
Imagina que tienes un servidor de archivos en alguna parte. Quizás este sea un servidor de correo conectado a la red u otros servicios de red, como impresoras. Y todo esto simplemente está conectado a alguna red y no se procesa en una computadora.

El requisito previo para la creación de Athena y Kerberos era que tenía una máquina para compartir simultáneamente, donde todo era un proceso separado, y todos podían simplemente iniciar sesión en el mismo sistema y almacenar sus archivos allí. Por lo tanto, los desarrolladores querían crear un sistema distribuido más conveniente.
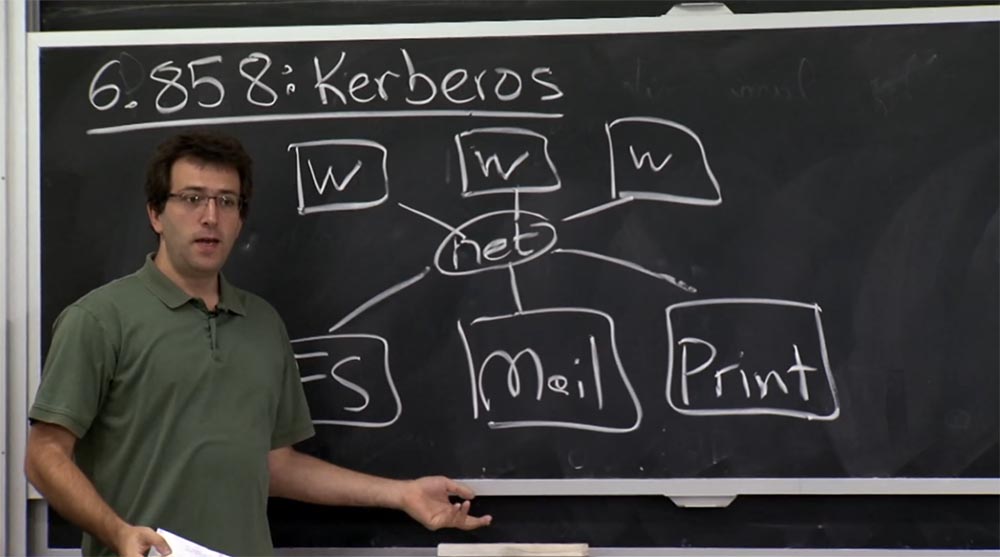
Por lo tanto, esto significaba que tendría estos servidores en un lado y un montón de estaciones de trabajo en el otro lado que los usuarios usarían ellos mismos y en las que se ejecutarían las aplicaciones. Estas estaciones de trabajo se conectarán a estos servidores y almacenarán archivos de usuario, recibirán su correo, etc.
El problema que querían resolver era cómo autenticar a los usuarios que usan estas estaciones de trabajo para todas estas computadoras diferentes en el lado del servidor, sin tener que confiar en la red y verificar su corrección. Esto fue en todos los sentidos un requisito de diseño razonable. Debo mencionar que en ese momento, la alternativa a Kerberos era el equipo de inicio de sesión R, discutido en la última conferencia, que parecía un mal plan, ya que simplemente usan sus direcciones IP para autenticar a los usuarios.
Kerberos ha tenido bastante éxito, en realidad todavía se usa en la red MIT y es la columna vertebral del servidor Active Directory de Microsoft. Casi todos los productos basados en Microsoft Windows Server usan Kerberos de una forma u otra.
Pero este protocolo se desarrolló hace 25 o 30 años, y desde entonces se han requerido cambios, ya que hoy la gente entiende mucho más sobre seguridad. Por lo tanto, la versión actual de Kerberos es notablemente diferente en muchos aspectos de la versión descrita en los materiales para esta conferencia. Consideraremos qué supuestos particulares no son lo suficientemente buenos hoy y qué estaba mal en la primera versión. Esto es inevitable para el primer protocolo que realmente utilizó criptografía para autenticar a los participantes de la red en un sistema completo.
En cualquier caso, el diagrama representado en la placa es una especie de instalación para crear Kerberos. Es interesante descubrir cuál es el modelo de confianza. Por lo tanto, se introduce una estructura adicional en nuestro esquema: el servidor Kerberos, ubicado aquí en el lateral.
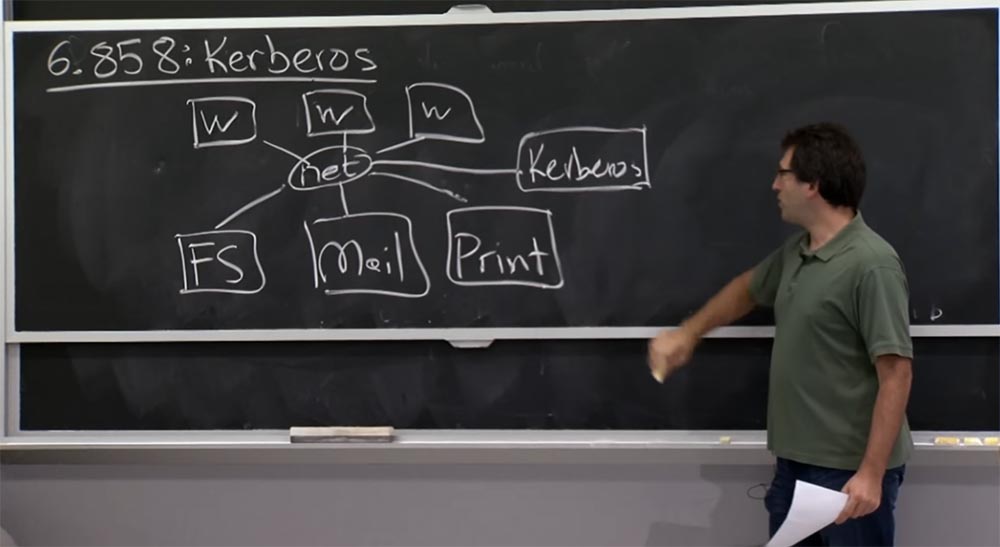
Por lo tanto, nuestro tercer modelo se basa de alguna manera en el hecho de que la red no es confiable, como mencionamos en la última conferencia. ¿En quién deberíamos confiar en este esquema Kerberos? Por supuesto, todos los participantes de la red deben confiar en el servidor Kerberos. Por lo tanto, los creadores del sistema en un momento sugirieron que el servidor Kerberos sería responsable de todas las comprobaciones de autenticación de red de una forma u otra. ¿Qué más tenemos en esta red en la que pueda confiar?
Estudiante: Los usuarios pueden confiar en sus propias máquinas.
Profesor: sí, este es un buen argumento. Hay usuarios aquí que no he dibujado. Pero estos tipos usan algún tipo de estación de trabajo, y de hecho, en Kerberos es muy importante que el usuario confíe en su estación de trabajo. ¿Qué sucede si no confías en tu estación de trabajo? Porque si el usuario no confía en la estación de trabajo, entonces simplemente puede "olfatear" su contraseña y actuar en su nombre.
 Estudiante:
Estudiante: un atacante puede hacer mucho más, por ejemplo, al aprender su ticket para el servidor Kerberos.
Profesor: sí, exactamente. Cuando inicia sesión, ingresa su contraseña, que es aún peor que un ticket. Entonces, en realidad, hay un pequeño problema con Kerberos si no confía en la estación de trabajo. Si usa su propia computadora portátil, no es tan aterrador, pero la seguridad de una computadora pública está en duda. Consideraremos qué puede salir mal exactamente en este caso.
Estudiante: debe confiar en los administradores del servidor y asegurarse de que puedan tener acceso privilegiado a los servidores de los demás.
Profesor: Creo que las máquinas en sí mismas no tienen que confiar entre sí, por ejemplo, el servidor de correo no tiene que confiar en el servidor de impresión o el servidor de archivos.
Estudiante: no confía, pero tiene la capacidad de acceder a un servidor al que no se admite el acceso a través de otro servidor.
Profesor: sí, eso es verdad. Si establece una relación de confianza entre el servidor de correo y el servidor de impresión, pero solo le da acceso al servidor de correo a sus archivos en el servidor de archivos por conveniencia, entonces esto puede ser abusado. Por lo tanto, debe tener cuidado al introducir niveles adicionales de confianza o confianzas redundantes aquí.
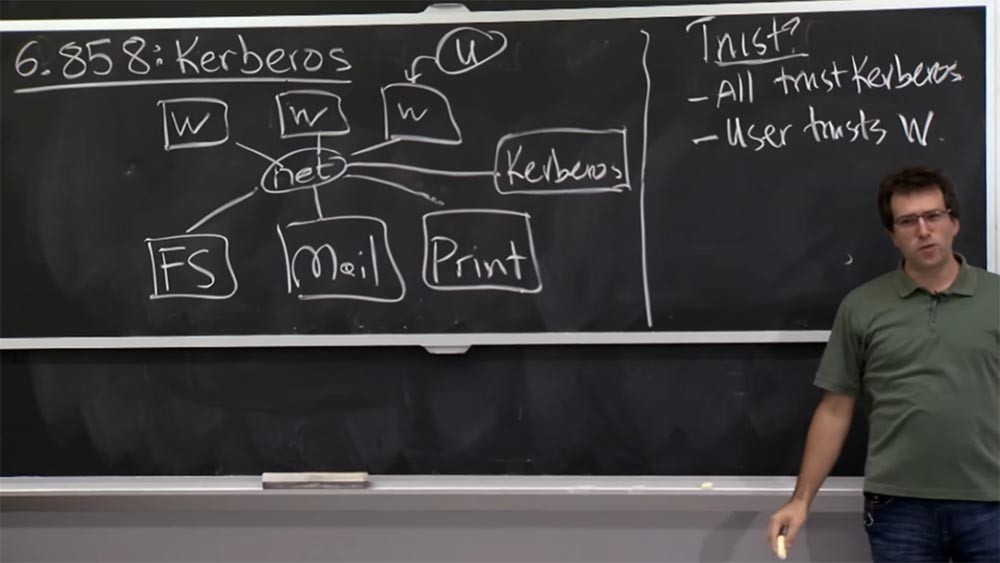
¿Qué más importa aquí? ¿Deben los servidores confiar de alguna manera en los usuarios o estaciones de trabajo? Supongo que no. El objetivo global de Kerberos era que el servidor a priori no debería conocer a todos estos usuarios o estaciones de trabajo, o saber cómo autenticarlos, hasta que estos usuarios puedan demostrar criptográficamente que son usuarios legítimos y deben tener acceso a sus datos o algo más de lo que administra el servidor.
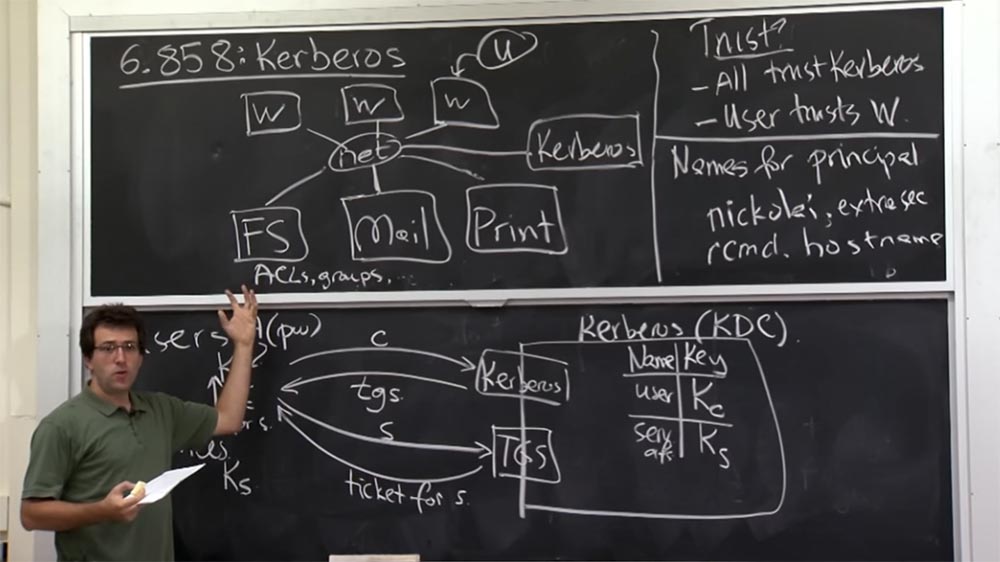
Veamos cómo funciona Kerberos y cuál es su arquitectura general. Dibujemos un servidor Kerberos a mayor escala. Hoy en día, se llama KDC - Centro de distribución de claves o Centro de suministro de claves. En algún lugar hay usuarios y servicios a los que puede conectarse. El plan es que el servidor Kerberos será responsable de almacenar la clave compartida para la comunicación entre el servidor Kerberos y cada entidad informática en el mundo que lo rodea. Por lo tanto, si el usuario tiene algún tipo de clave de cliente Kc, entonces el servidor Kerberos recuerda esta clave y la almacena en algún lugar dentro de sí mismo. Del mismo modo, la clave Ks para un servicio solo será conocida por este servicio en sí, el servidor Kerberos y nadie más. Por lo tanto, puede considerarlo como un uso común de las contraseñas cuando conoce la contraseña y Kerberos la conoce, pero nadie más la conoce.

Así es como se demostrarán el uno al otro que "yo soy ese mismo tipo". Por supuesto, el servidor Kerberos tendrá que hacer un seguimiento de quién posee esta clave, por lo que debe tener una tabla que almacene los nombres de usuario y los nombres de servicio, por ejemplo, serv afs (este es un servidor de archivos) y las claves correspondientes.
Al mismo tiempo, KDC es responsable de almacenar una tabla gigante, no muy grande en términos de número de bytes, pero muy voluminosa en el número de registros, porque tiene en cuenta cualquier entidad informática que viva en la red MIT que el servidor Kerberos debería conocer. Por lo tanto, tenemos dos tipos de interfaz.

Los materiales de la conferencia no hablan de esto con suficiente claridad, es decir, la existencia de estas 2 interfaces está simplemente implícita. De hecho, en realidad hay dos interfaces para una máquina. Uno de ellos se llama Kerberos, y el segundo es TGS, Ticket Granting Service o Ticket Service.
De hecho, al final, estas son solo dos formas de hablar sobre lo mismo, y el protocolo es solo ligeramente diferente para estas dos cosas. Por lo tanto, inicialmente, cuando un usuario inicia sesión, "habla" con la interfaz superior, Kerberos, y le envía su nombre de cliente C, este puede ser su nombre de usuario en la red de la universidad Athena.
El servidor responde a esta solicitud con un tgs ticket o información de ticket, discutiremos los detalles de esta información un poco más tarde. Luego, cuando desee chatear con algún servicio, primero deberá ir a la interfaz de TGS y decirle: "Ya he iniciado sesión a través de la interfaz de Kerberos y ahora quiero hablar con el servidor S, que me proporcionará un determinado servicio".
Entonces le dirá a TGS sobre el servidor con el que desea hablar, después de lo cual le devolverá algo así como un boleto para hablar con el servidor S. Luego, finalmente puede hablar con el servidor que necesita utilizando el boleto recibido para el servidor S.
Este es un tipo de plan de alto nivel. Entonces, ¿por qué se usan 2 interfaces aquí? Se pueden hacer muchas preguntas sobre esto. En el caso del servidor Ks, este servicio probablemente se almacenará en el disco. ¿Y qué pasa con este Kc en el lado del usuario? ¿De dónde viene este Kc en Kerberos?
 Estudiante:
Estudiante: este Kc debe estar en la base de datos, en la tabla del servidor KDC.
Profesor: sí, bueno, la tecla C está aquí en la tabla, en esta gigantesca base de datos. Pero también debe ser conocido por el usuario, porque el usuario debe demostrar que es un usuario.
Estudiante: ¿ es una función unidireccional que luego requiere una contraseña?
Profesor: sí, en realidad tienen un plan tan inteligente, donde Kc se obtiene al descifrar la contraseña del usuario o algún tipo de función de generación de claves, para esto hay varios métodos diferentes. Pero básicamente tomamos la contraseña, la convertimos de alguna manera y obtenemos esta clave Kc. Así que esto parece una buena manera.
Pero, ¿por qué necesitamos dos protocolos? Después de todo, puede imaginar que simplemente solicita un boleto directamente desde la primera interfaz de Kerberos, diciéndole: "¡Hola, quiero un boleto para este nombre en particular!", Él le enviará el boleto de regreso, y usted puede descifrarlo usando Kc.
Estudiante: ¿ tal vez no quieren que el usuario vuelva a ingresar su contraseña cada vez que desea acceder a otro servicio?
Profesor: es cierto, la razón de la diferencia entre las dos interfaces es que desde la primera interfaz todas las respuestas se devuelven cifradas con su clave Kc, y los creadores de Kerberos estaban preocupados por la posibilidad de guardar este Kc durante mucho tiempo. Porque, o bien tiene que pedirle al usuario que ingrese la contraseña cada vez, lo cual es molesto, o de lo contrario él constantemente "se sienta" en la memoria. Básicamente, esto es tan bueno como solo una contraseña de usuario, porque alguien con acceso a Kc puede mantener el acceso a los archivos del usuario hasta que el usuario pueda cambiar su contraseña, o incluso más. Más adelante consideraremos este problema con más detalle.
Así que filtrar esta clave Kc es algo muy peligroso. Por lo tanto, el objetivo de usar la primera y luego la segunda interfaz para todas las solicitudes posteriores es que realmente puede olvidar Kc tan pronto como descifre la respuesta de la interfaz TGS del servidor Kerberos. De ahora en adelante, incluso en el caso de una fuga de clave, la funcionalidad dependerá del ticket recibido. Entonces, en el peor de los casos, alguien tendrá acceso a su cuenta por un par de horas, y no por un período de tiempo ilimitado. Esta es la razón de tal esquema con dos vías de acceso a los mismos recursos.
Entonces, antes de profundizar en la mecánica de cómo se ven estos protocolos en la red, hablemos un poco sobre el aspecto de los nombres de Kerberos. En cierto sentido, Kerberos puede considerarse un registro de nombres. Es responsable de mostrar estas claves criptográficas como nombres en minúsculas. Este es el tipo fundamental de operación que realiza Kerberos. Verá en la próxima conferencia por qué necesitamos una función similar. Se puede implementar de manera diferente que en Kerberos, pero es fundamentalmente muy importante tener algo similar en casi cualquier sistema de seguridad distribuido. Entonces, veamos cómo Kerberos trata con los nombres.
Kerberos tiene algo así como llamadas de sistema para cada entidad de computadora en la base de datos de miembros de la red, y la forma principal de estos datos es solo una cadena. Por lo tanto, puede tener algunos nombres básicos en una forma como nickolai, por ejemplo. Esta es la cadena de nombre.

Es el parámetro principal en alguna área de Kerberos, de hecho, esto es lo que está en la columna izquierda de la tabla KDC. Y también hay algunos parámetros adicionales que admite el protocolo. Podría, por ejemplo, ingresar otro nombre como nickolai.extra sec, que se usaría además del nombre nickolai para acceder a recursos que necesitan seguridad adicional. Entonces quizás tenga una contraseña para cosas realmente seguras y otra contraseña para mi cuenta regular.
Kerberos ha mencionado este aspecto. Por lo tanto, uno puede preguntarse: ¿de dónde viene el impacto? El servicio Kerberos asigna nombres para usted a ciertas teclas, pero ¿cómo sabe qué nombre preguntar o qué nombre esperar en respuesta cuando está hablando con alguna computadora? Es decir, pregunto qué nombres aparecen fuera del servidor Kerberos o dónde aparecen exactamente estos nombres de usuario. ¿Tienes alguna idea?
Estudiante: presumiblemente puede solicitar nombres de usuario del servidor MIT.
Profesor: sí, por supuesto. Así es como puedes enumerar estas cosas. Además, los usuarios simplemente los ingresan cuando inician sesión, que es de donde provienen. ¿Los nombres de usuario aparecen en otro lugar? ¿Deberían aparecer en otro lado?
Estudiante: es posible que el acceso del usuario esté indicado en las listas de varios servicios.
Profesor: sí, este es un punto realmente importante, ¿verdad? El objetivo de Kerberos es simplemente asignar claves a los nombres. Pero esto no le dice a qué debe tener acceso este nombre.
De hecho, la forma en que las aplicaciones suelen usar Kerberos es que uno de estos servidores usa Kerberos para averiguar con qué nombre en minúscula está hablando. Cuando el servidor de correo recibe una conexión desde alguna estación de trabajo, recibe un ticket Kerberos, lo que demuestra que este usuario es Nikolai. Después de eso, el servidor de correo descubre internamente a qué tiene acceso este usuario. El servidor de archivos hace lo mismo.
Por lo tanto, dentro de todos estos servidores hay listas de control de acceso, posiblemente listas de grupos u otras cosas que llevan a cabo la autorización. Entonces Kerberos proporciona autenticación que le muestra con quién está hablando esa persona. El servicio en sí es responsable de la implementación de esa parte de la autorización, que decide qué nivel de acceso debe tener en función de su nombre de usuario. Entonces descubrimos dónde aparecen los nombres de usuario. Hay otros nombres básicos que Kerberos admite para interactuar con los servicios.
De acuerdo con los materiales de la conferencia, los servicios se ven así: rcmd.hostname. La razón por la que necesita un nombre para uno de estos servicios es porque desea, por ejemplo, cuando se conecta a un servidor de archivos, realizar una autenticación mutua. Esto significa que en este procedimiento, no solo el servidor de destino descubrirá quién soy, sino que también yo, el usuario o la estación de trabajo, me aseguraré de estar hablando con el servidor de archivos correcto y no con algún servidor de archivos falso que falsificó el mío. archivos. Porque, tal vez, quiero mirar el archivo con mis calificaciones y enviarlo al registrador. Por lo tanto, sería una lástima que algún otro servidor de archivos pudiera actuar como el servidor correcto y proporcionarme el archivo de calificaciones incorrecto.
Por lo tanto, los servicios también necesitan su propio nombre, y las estaciones de trabajo deben averiguar qué nombre espero ver cuando me conecte al servicio.
Como regla, en algún nivel esto proviene del usuario. Entonces, por ejemplo, si escribo ssh.foo, esto significa que debería esperar que aparezca un nombre principal de Kerberos como rcmd.foo en el otro extremo de esta conexión. Y si hay alguien más allí, entonces el cliente SSH debería desconectarse y no permitir que me conecte, porque entonces me confundirán y comenzaré a hablar con otra máquina.
Esto plantea una pregunta interesante. ¿Cuándo podemos reutilizar nombres en Kerberos? Por ejemplo, todos ustedes tienen cuentas en el sistema del instituto Athena. Cuando te gradúes, ¿puede MIT destruir la entrada de tu base de datos y permitir que otra persona registre el mismo nombre de usuario? ¿Sería una buena idea?
Estudiante: ¿ pero no solo la base de datos Kerberos, sino también los servicios tienen una lista de nombres de usuario?
Profesor: sí, porque estos nombres solo están representados por entradas de cadena en algún lugar de la ACL en un archivo o servidor de correo. Si borramos su entrada en la base de datos del servidor Kerberos, esto no significa que su entrada haya desaparecido por completo. Estas entradas son independientes de la versión.
Por ejemplo, un registro dice que Alice tiene acceso a un casillero Athena. Luego, Alice se gradúa y su registro se elimina, pero alguna nueva Alice ingresa al instituto, que pasa por el proceso de registro en la base de datos Kerberos. Al mismo tiempo, obtiene el nombre principal que es completamente idéntico al nombre de la antigua Alice, por lo que el servidor de archivos puede dar acceso a la nueva Alice a los archivos de la antigua Alice.
, Kerberos , Kerberos . , , , .
. , , , , , . , , , - . , . , , .
, . , , , TGS.

, , Kerberos, «». : s , IP – addr, time stump, life, , , Kc,s, . .

.
, Kerberos «». Ac , IP- , , . , . K,s, , Kerberos Ks. , .
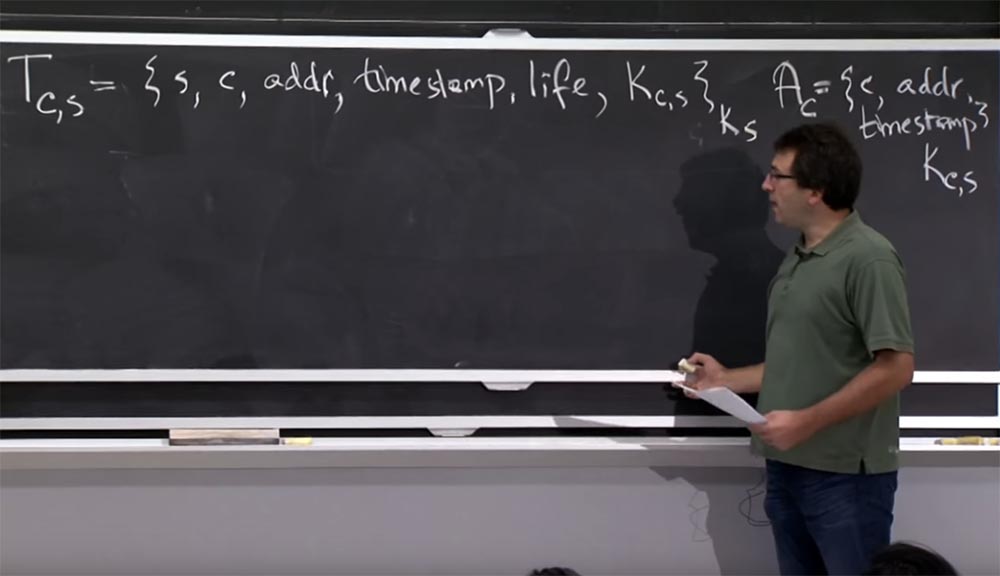
, , Kerberos TGS. , , Kerberos, , . : C, , S, TGS. .
Tc,s, Ks, , Ks, , Kc. .
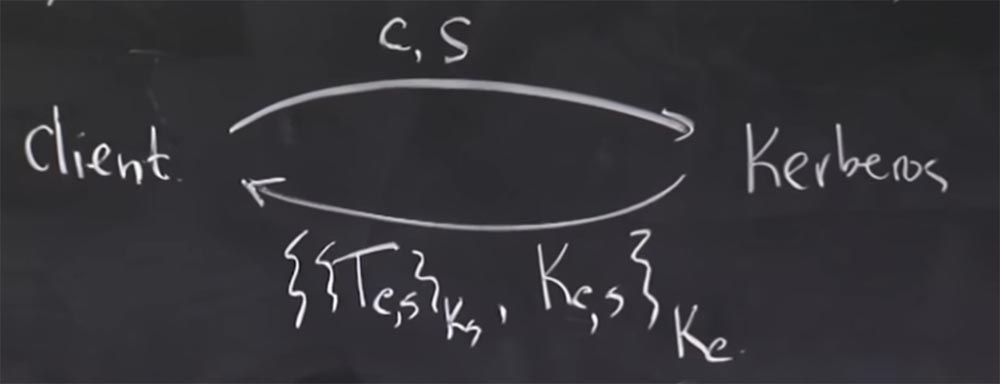
. , Kerberos ? , ?
: , , , Kc.
: , , Kerberos , . : «, , . , , , Kc». , .
, , , Kerberos, Kerberos , . , , - Kerberos, , .
: …
: , , Kerberos, ? , ? , , , , , , , , , .

«», , , , , . , , . . Kerberos, , . , , .
: ? , …
: , . , Kerberos , . , , - , , , . 30 , .
Kerberos 5 : , — . , , , , .
Kerberos 4 , , , . , . , , .
Entonces, este es el plan para decirle al cliente si su boleto es válido. Solo intentan descifrarlo y ver cómo funciona. Otra pregunta interesante: ¿por qué esta clave Kc, s de alguna forma se incluye en el ticket dos veces? Está presente en el ticket por separado como la clave Kc, sy está presente implícitamente en el mismo ticket Tc, s. ¿Por qué tenemos dos copias de la clave Kc, s?27:10 minCurso MIT "Seguridad de los sistemas informáticos". Lección 13: Protocolos de red, parte 2La versión completa del curso está disponible aquí .Gracias por quedarte con nosotros. ¿Te gustan nuestros artículos? ¿Quieres ver más materiales interesantes?
Apóyenos haciendo un pedido o recomendándolo a sus amigos, un
descuento del 30% para los usuarios de Habr en un análogo único de servidores de nivel de entrada que inventamos para usted: toda la verdad sobre VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD 1Gbps de $ 20 o cómo dividir el servidor? (las opciones están disponibles con RAID1 y RAID10, hasta 24 núcleos y hasta 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD 1Gbps hasta diciembre de forma gratuita al pagar por un período de seis meses, puede ordenar
aquí .
Dell R730xd 2 veces más barato? ¡Solo tenemos
2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV desde $ 249 en los Países Bajos y los Estados Unidos! Lea sobre
Cómo construir un edificio de infraestructura. clase utilizando servidores Dell R730xd E5-2650 v4 que cuestan 9,000 euros por un centavo?