
Una cosa tan romántica como un cielo estrellado y algo tan duro como optimizar el consumo de memoria mediante una aplicación de iOS bien pueden ir de la mano: vale la pena intentar meter este cielo estrellado en una aplicación AR, y la pregunta sobre el mismo consumo surgirá de inmediato.
Para minimizar el uso de memoria será útil en muchos otros casos. Entonces, este texto en el ejemplo de un pequeño proyecto muestra métodos de optimización que pueden ser útiles en aplicaciones iOS completamente diferentes (y no solo iOS).
La publicación se preparó sobre la base de una transcripción del informe de
Conrad Filer de la conferencia Mobius 2018 Piter. Adjuntamos su video, y luego una versión de texto en primera persona:
Me alegro de dar la bienvenida a todos! Mi nombre es Conrad Filer, y bajo el espectacular nombre de "A Million Stars in One iPhone" discutiremos cómo puede minimizar el tamaño de memoria ocupado por su aplicación iOS. Colorido y en ejemplos.
¿Por qué optimizar?
Lo que generalmente nos anima a hacer la optimización, ¿qué es exactamente lo que nos gustaría lograr? No queremos esto:
No queremos que el usuario espere. Es decir, la primera razón es
reducir el tiempo de arranque .
Otra razón es
mejorar la calidad .

Podemos hablar sobre la calidad de las imágenes, el sonido e incluso la IA. "IA optimizada" significa que puedes lograr más, por ejemplo, calcular el juego para un mayor número de movimientos hacia adelante.
La tercera razón es muy importante:
ahorrar batería . La optimización ayuda a agotar menos la batería. Aquí hay una comparación interesante, aunque del mundo de Android. Aquí comparamos Vulkan y OpenGL ES:

El segundo está peor optimizado para plataformas móviles. Al observar la velocidad del consumo de energía de la batería, puede ver que para una imagen similar, OpenGL ES gastó muchos más recursos que Vulkan.
¿Qué tipo de optimización puede ayudar aquí? Por ejemplo, en un juego por turnos, cuando el usuario piensa en su movimiento, puede reducir el FPS a cero. Si tiene un motor 3D, es completamente aconsejable apagar todo mientras el usuario solo mira la pantalla.
Además, hay momentos en los que sin un enfoque optimizado no podrá implementar una u otra característica avanzada: simplemente no se activará.
Sin fanatismo
Hablando de optimización, uno no puede dejar de recordar la tesis de Donald Knuth: “Deberíamos olvidarnos de la baja eficiencia, por ejemplo, en el 97% de los casos: la optimización prematura es la raíz de todos los males. Aunque no debemos renunciar a nuestras capacidades en estos críticos 3% ".
En el 97% de los casos, no deberíamos preocuparnos por la eficiencia, sino ante todo por cómo hacer que nuestro código sea comprensible, seguro y comprobable. Todavía estamos desarrollando para dispositivos móviles, y no para naves espaciales. Las compañías donde trabajamos no deberían pagar de más por el soporte del código que escribimos. Además, el tiempo de trabajo del desarrollador tiene un costo, y si lo gastas en optimizar algo que no es esencial, entonces gastas el dinero de la empresa. Bueno, el hecho de que el código bien optimizado tiende a ser más difícil de entender, puede ver los ejemplos que le mostraré hoy.
En general, priorice significativamente y optimice según sea necesario.
Los enfoques
Cuando trabajamos en la optimización, generalmente monitoreamos el rendimiento (léase: carga del procesador) o la cantidad de memoria utilizada. A menudo, estas dos opciones entrarán en conflicto, y necesitará encontrar un equilibrio entre ellas.
En el caso del procesador, podemos reducir la cantidad de ciclos de procesador requeridos por nuestras operaciones. Como sabe, menos ciclos de procesador nos dan menos tiempo de carga, menos consumo de batería, la capacidad de proporcionar una mejor calidad, etc.
Para los desarrolladores de iOS, Xcode Instruments tiene una práctica herramienta de perfil de tiempo. Le permite realizar un seguimiento de la cantidad de ciclos de CPU gastados por diferentes partes de su aplicación. Este informe no trata sobre herramientas, por lo que no voy a entrar en detalles ahora, hubo un buen video de WWDC sobre esto.
Puede elegir otro objetivo: la optimización por el bien de la memoria. Intentaremos asegurarnos de que, al inicio, nuestra aplicación se ajuste al menor número posible de celdas RAM. Recuerde que las aplicaciones más voluminosas son los primeros candidatos para un apagado forzado durante la limpieza, que el sistema operativo se ve obligado a llevar a cabo. Por lo tanto, esto afecta el tiempo que su aplicación permanece en segundo plano.
También es importante que el recurso RAM para diferentes dispositivos también sea diferente. Si, por ejemplo, decidió desarrollar para Apple Watch, entonces no hay suficiente memoria, y esto también lo hace optimizar.
Finalmente, a veces una pequeña cantidad de memoria también hace que el programa sea muy rápido. Daré un ejemplo. Aquí están las estructuras de varios tamaños en bytes:

Element8 contiene 8 bytes, Element16 - 16, y así sucesivamente.

Crearemos matrices, una para cada uno de nuestros tipos de estructuras. La dimensión de todas las matrices es la misma: 10.000 elementos. Cada estructura contiene un número diferente de campos (en aumento); El campo n es el primer campo y, en consecuencia, está presente en todas las estructuras.
Ahora intentemos lo siguiente: para cada matriz calcularemos la suma de todos sus campos n. Es decir, cada vez sumaremos el mismo número de elementos (10,000 piezas). La única diferencia es que para cada suma, la variable n se extraerá de estructuras de diferentes tamaños. Nos interesa saber si el resumen lleva el mismo tiempo.
El resultado es el siguiente:
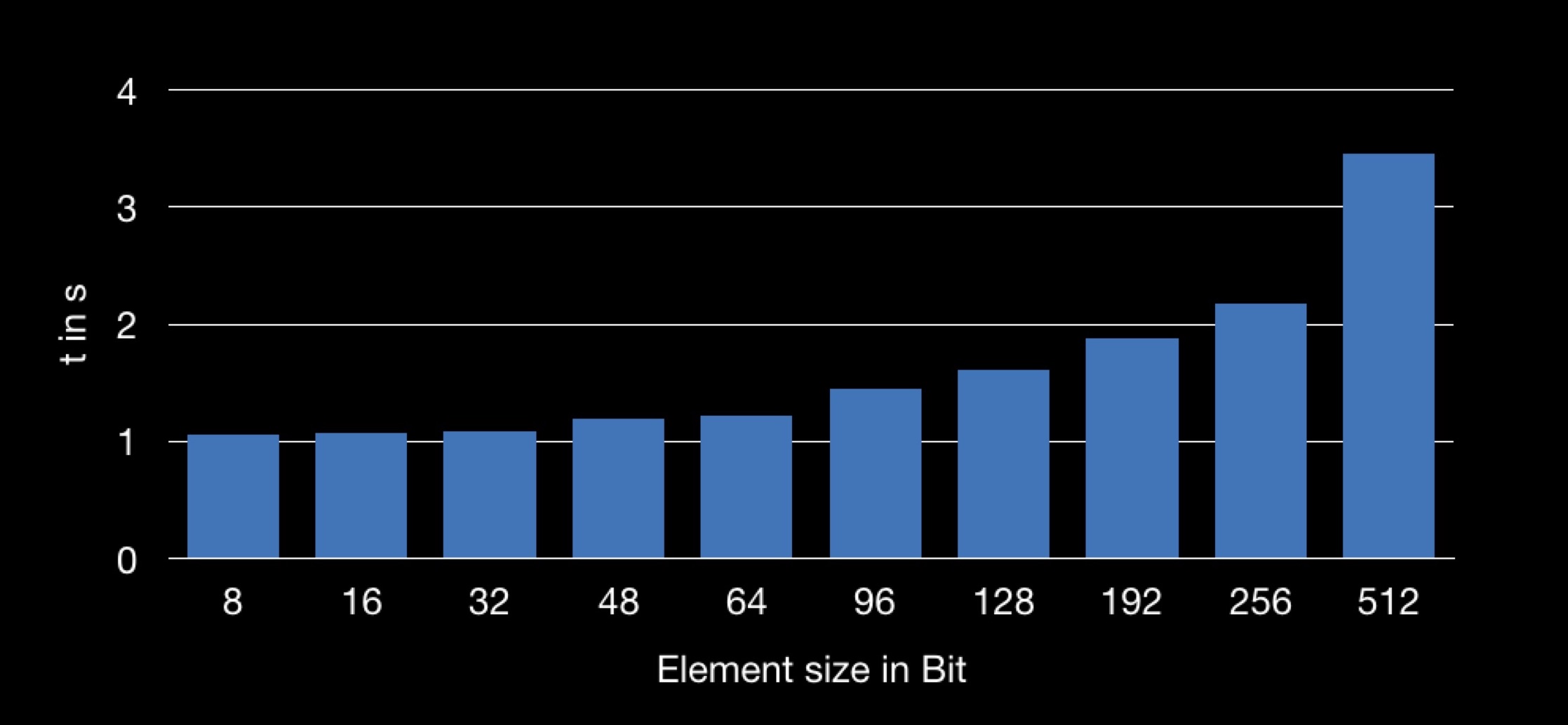
El gráfico muestra la dependencia del tiempo de suma en el tamaño de la estructura utilizada en la matriz. Resulta que obtener el campo n de una estructura más grande es más largo y, por lo tanto, la operación de suma lleva más tiempo.
Muchos de ustedes ya han entendido por qué sucede esto.
El procesador tiene cachés L1, L2 (a veces incluso L3 y L4). El procesador accede a este tipo de memoria de forma directa y rápida.
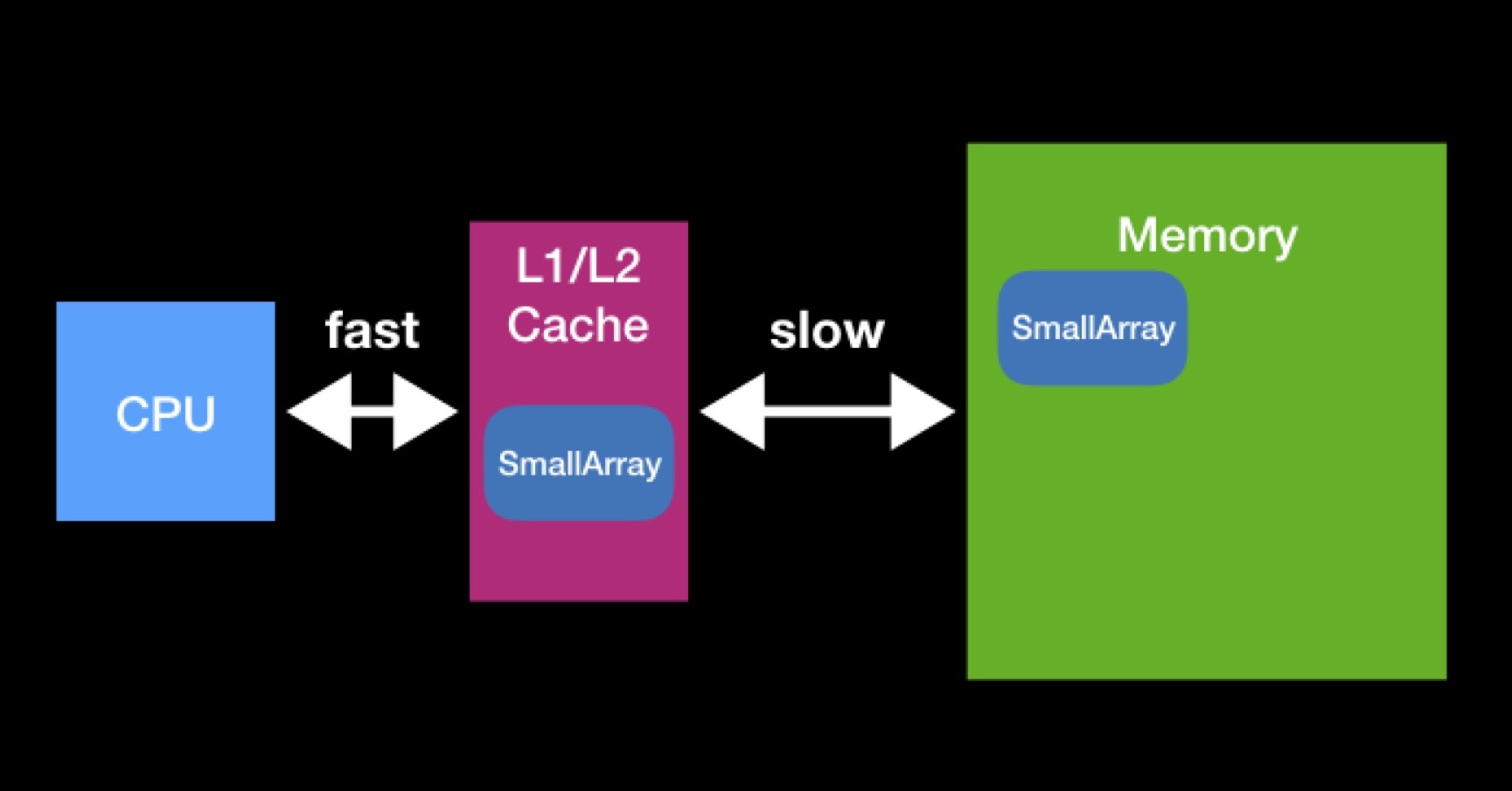
Existen cachés para acelerar la reutilización de datos. Supongamos que estamos trabajando con matrices. Si la matriz que necesita el procesador ya está presente en alguna de las memorias caché, entonces el procesador ya la requería anteriormente. En ese momento, los solicitó de la memoria principal, los colocó en la memoria caché, realizó todas las operaciones necesarias con ellos, después de lo cual estos datos permanecieron mintiendo (no tuvieron tiempo de ser borrados por otros).
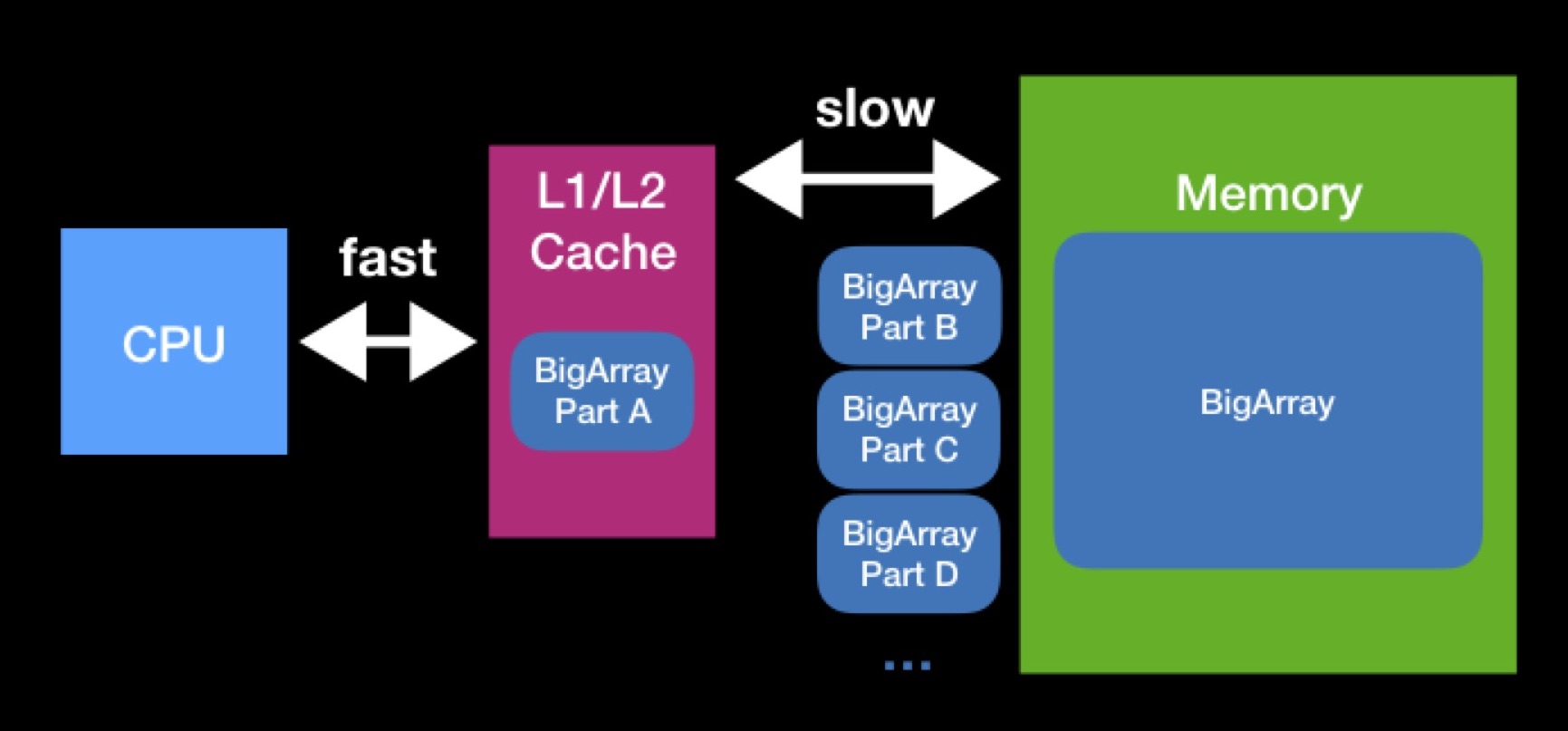
Los tamaños de los cachés L1, L2 no son tan grandes. La matriz que necesita el procesador para funcionar puede ser mayor. Para realizar completamente la operación en una matriz de este tipo, tendremos que descargarla en el caché en partes y operar en estas partes una por una. Debido a las constantes solicitudes a la memoria principal, el procesamiento de nuestra matriz llevará mucho más tiempo.
Cuando programe estructuras de datos, trate de tener en cuenta las memorias caché. Es posible que al reducir el tamaño de su estructura de datos, logre su capacidad de caché exitosa y acelere las operaciones que se realizarán en él en el futuro. La interacción con la memoria principal siempre ha sido, es y probablemente seguirá siendo un factor significativo en la productividad, incluso cuando escribe en Swift para dispositivos modernos de alto rendimiento.
CPU vs RAM: inicialización diferida
Aunque en algunos casos, cuando se reduce la memoria utilizada, el programa comienza a funcionar más rápido, hay casos en que estas dos métricas, por el contrario, entran en conflicto. Daré un ejemplo con el concepto de inicialización perezosa.
Supongamos que tenemos un método makeHeavyObject () que devuelve algún objeto grande. Este método inicializará la variable lazilyCalculated.

El modificador diferido establece la variable lazilyCalculated en inicialización diferida. Esto significa que se le asignará un valor solo cuando se produzca la primera llamada durante la ejecución. Es entonces que el método makeHeavyObject () funcionará y el objeto resultante se asignará a la variable lazilyCalculated.
¿Cuál es la ventaja aquí? Desde el momento de la inicialización (aunque más tarde, pero se ejecutará) tenemos un objeto ubicado en la memoria. Su valor se cuenta, está listo para usar, solo haga una solicitud. Otra cosa es que nuestro objeto es grande y desde el momento de la inicialización ocupará en memoria la mayor parte de las células.
Puede ir hacia otro lado: no almacene el valor del campo en absoluto:

Con cada enlace al campo lazilyCalculated, el método makeHeavyObject () se ejecutará nuevamente. El valor se devolverá al punto de consulta, mientras que no se colocará en la memoria. Como puede ver, almacenar una variable es opcional.
¿Qué es más costoso: almacenar un objeto grande en la memoria, pero no perder el tiempo de la CPU, o llamar al método cada vez que necesitamos nuestro campo, mientras ahorramos memoria? ¿Debería tener un valor listo a mano o calcularlo sobre la marcha? Este tipo de dilema surge con bastante frecuencia, donde sea que realice sus cálculos, en un servidor remoto o en su máquina local, sin importar con qué caché tenga que trabajar. Debe tomar una decisión basada en las limitaciones del sistema en este caso particular.
Ciclo de optimización

Lo que optimice, su trabajo, por regla general, se basará en el mismo algoritmo. Primero, examina el código, perfil / medida (en Xcode usando las herramientas apropiadas), tratando de identificar sus cuellos de botella. Básicamente, organice los métodos según el tiempo que tardan en ejecutarse. Y luego mire las líneas superiores para determinar qué optimizar.
Al elegir un objeto, se establece la tarea (o, hablando científicamente, presenta una hipótesis): al aplicar estos u otros métodos de optimización, puede hacer que el código seleccionado funcione más rápido.
A continuación, intenta optimizar. Después de cada modificación, observa los indicadores de rendimiento, evaluando qué tan efectiva fue la modificación, cuánto logró avanzar.
Al igual que en un trabajo científico: especulación, experimento, análisis de resultados. Pasas por este ciclo de acciones una y otra vez. La práctica muestra que el trabajo construido de esta manera realmente le permite eliminar los botneks uno por uno.
Pruebas unitarias

Brevemente sobre las pruebas unitarias: tenemos algunas funciones que estamos probando, algunas entradas de datos de entrada y salida de datos de salida; Al recibir la entrada como entrada, nuestra función siempre debe devolver la salida, y ninguna de nuestras optimizaciones debe violar esta propiedad.
Las pruebas unitarias nos ayudan a rastrear el desglose. Si, en respuesta a la entrada, nuestra función deja de devolver la salida, entonces, directa o indirectamente, cambiamos el antiguo curso de trabajo de nuestra función.
Ni siquiera intente comenzar a optimizar si no ha escrito una porción generosa de pruebas unitarias en su código. Deberías poder hacer una prueba de regresión. Si miras GitHub my commits en mi aplicación de ejemplo, a la que seguiré, puedes ver que algunas de mis optimizaciones trajeron errores.
Y ahora para la parte divertida, pasemos a las estrellas.
Millones de estrellas
Hay una base de datos grande (enorme) que describe un millón de estrellas. Además de eso, creé varias aplicaciones. Uno de ellos usa realidad aumentada, en tiempo real dibujando estrellas sobre la imagen de la cámara del teléfono. Ahora lo demostraré en acción:
En ausencia de luces de la ciudad, una persona puede distinguir hasta 8,000 estrellas en el cielo. Necesitaría alrededor de 1.8 MB para almacenar 8,000 registros. En principio, aceptable. Pero quería agregar esas estrellas que una persona puede ver a través de un telescopio: resultaron unas 120,000 estrellas (de acuerdo con el llamado catálogo Hipparcos, ahora obsoleto). Esto ya requería 27 MB. Y entre los catálogos modernos de dominio público, puede encontrar uno que contará con unas 2.500.000 estrellas. Dicha base de datos ya ocuparía unos 560 MB. Como puede ver, ya se requiere mucha memoria. Pero no queremos solo una base de datos, sino una aplicación basada en ella, donde habrá ARKit, SceneKit y otras cosas que también requieren memoria.
Que hacer
Optimizaremos las estrellas.
Herramienta de diseño de memoria
Puede evaluar el tamaño del programa en su conjunto. Pero para trabajos de joyería como la optimización, necesitará herramientas para estimar el tamaño de cada estructura de datos individual.
Swift le permite hacer esto de manera bastante simple, utilizando objetos MemoryLayout <>. Usted declara un MemoryLayout <>, especificando la estructura de datos que le interesa como el tipo genérico. Ahora, refiriéndose a las propiedades del objeto recibido, puede recibir una variedad de información útil sobre su estructura.

La propiedad size nos da el número de bytes ocupados por una instancia de la estructura.
Ahora sobre la propiedad de zancada. Es posible que haya notado que el tamaño de la matriz, como regla, no es igual a la suma de los tamaños de sus elementos constitutivos, pero lo excede. Obviamente, queda algo de "aire" entre los elementos en la memoria. Para estimar la distancia entre elementos consecutivos en una matriz adyacente, usamos la propiedad stride. Si lo multiplica por el número de elementos en la matriz, obtendrá su tamaño.
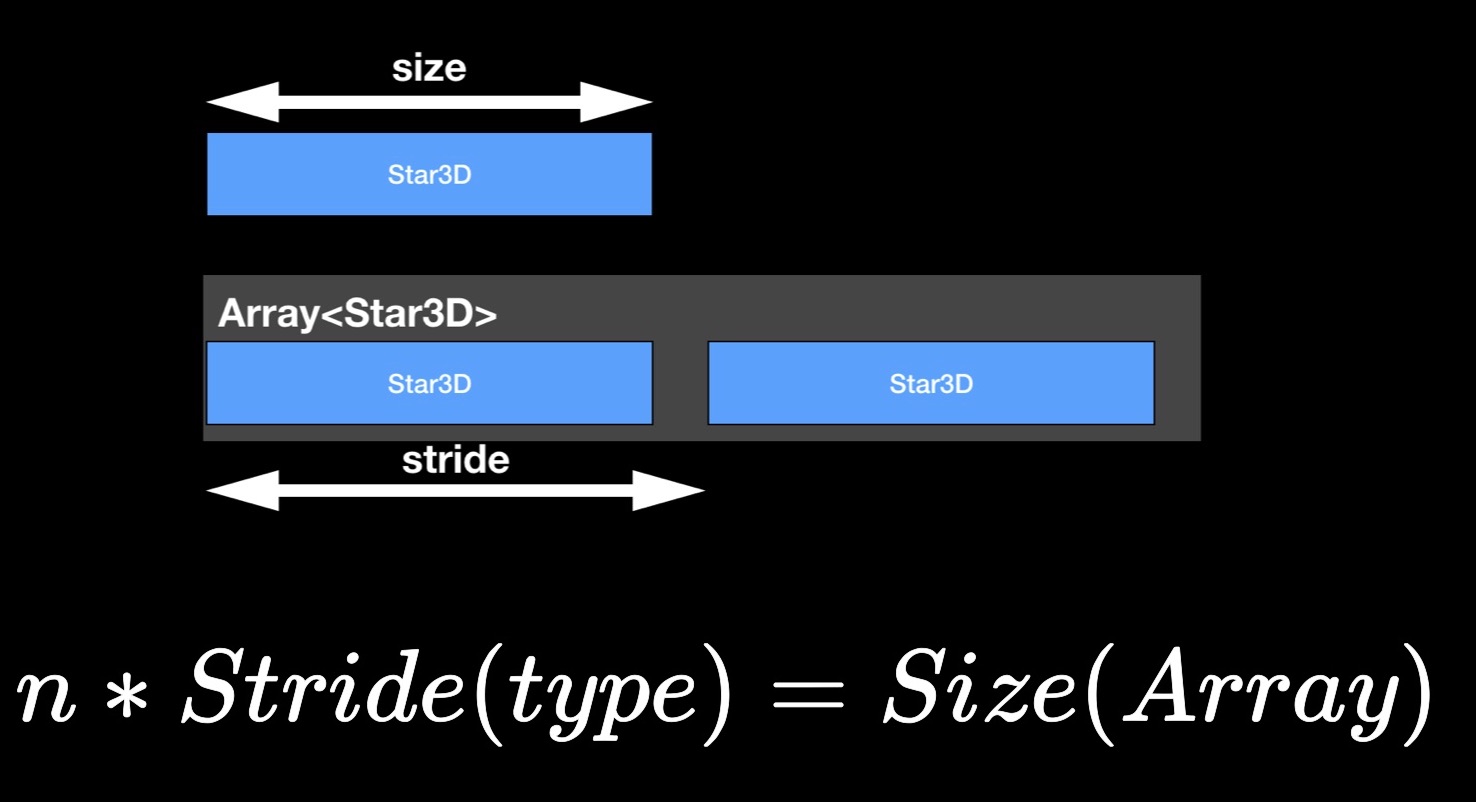
StarData, nuestra estructura experimental, en su estado inicial no optimizado:
Aquí hay una estructura de datos diseñada para almacenar datos sobre una estrella. No tiene que profundizar en lo que significa cada uno de estos elementos. Ahora es más importante prestar atención a los tipos: variables flotantes que almacenan las coordenadas de la estrella (de hecho, latitud y longitud), varias Int32 para diferentes ID, cadenas para almacenar nombres y nombres de varias clasificaciones; Hay una distancia, color y algunas otras cantidades necesarias para la correcta visualización de una estrella.
Solicitamos la propiedad de paso:

Por el momento, nuestra estructura pesa 208 bytes. Un millón de tales estructuras requerirá 250 MB; esto, como saben, es demasiado. Por lo tanto, es necesario optimizar.
Int correcto
El hecho de que hay diferentes variedades de Int se cuenta en las primeras lecciones de programación. El Int más familiar para nosotros en Swift se llama Int8. Ocupa 8 bits (1 byte) y puede almacenar valores de -128 a 127 inclusive. También hay otras Ints:
- Int16 en tamaño de 2 bytes, el rango de valores es de -32,768 a 32,767;
- Int32 en tamaño de 4 bytes, el rango de valores es de -2,147,483,648 a 2,147,483,647;
- Int64 (o solo Int) tiene un tamaño de 8 bytes, el rango de valores es de -9,223,372,036,854,775,808 a 9,223,372,036,854,775,807.
Probablemente aquellos de ustedes que se dedicaron al desarrollo web y se ocuparon de SQL ya están pensando en esto. Pero sí, en primer lugar, elija el Int óptimo. En este proyecto, incluso antes de pensar en la optimización en mi mente, me metí en un poco de optimización prematura (que, como acabo de decir, no es necesario hacerlo).
Veamos, por ejemplo, los campos con ID. Sabemos que tendremos alrededor de un millón de estrellas, no unas pocas decenas de miles, pero no mil millones. Entonces, para tales campos, es mejor elegir Int32. Entonces me di cuenta de que 4 bytes son suficientes para Flotar aquí. Double ocupará 8, String cada 24, agréguelo todo: resulta 152 bytes. Si recuerdas, anteriormente MemoryLayout nos dijo que 208. ¿Por qué? Debemos cavar más profundo.
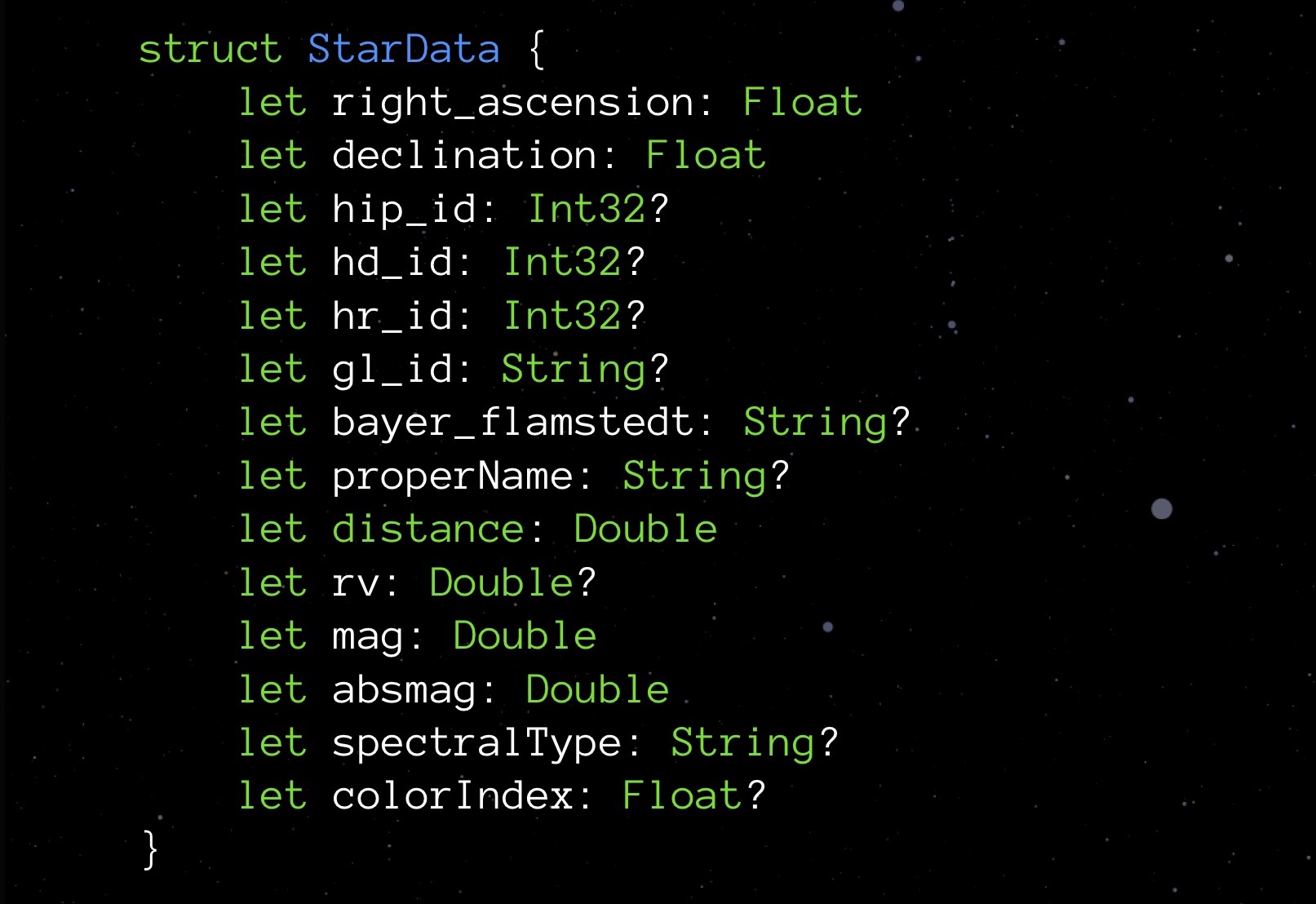
Primero, veamos Opcional. Los tipos opcionales difieren en que si no hay un valor asignado, almacenan nulo. Esto garantiza la seguridad en la interacción con los objetos. Pero como ya sabe, dicha medida no cuesta gratis: al solicitar la propiedad de tamaño de cualquier tipo opcional, verá que dicho tipo siempre toma un byte más. Pagamos por la posibilidad de registrarse en el campo nulo.
No nos gustaría gastar un byte extra en una variable. Al mismo tiempo, nos gusta mucho la idea incorporada en opcional. ¿Qué se te ocurre? Intentemos implementar nuestra estructura.
Elija un valor que pueda considerarse razonablemente "no válido" para un campo determinado, a la vez que sea adecuado para el tipo declarado. Para getHipId (Int32) puede ser, por ejemplo, el valor "-1". Significará que nuestro campo no está inicializado. Aquí hay una bicicleta opcional, que no tiene un byte adicional en cero.
Claramente, con tal truco, también tenemos una vulnerabilidad potencial. Para protegernos de los errores, crearemos un captador para el campo, que gestionará de forma independiente nuestra nueva lógica y verificará la validez del valor del campo.

Tal captador nos abstrae completamente de la complejidad de una solución inventada.
Dirígete a nuestro StarData. Reemplace todos los tipos opcionales con los normales y vea qué muestra el paso:
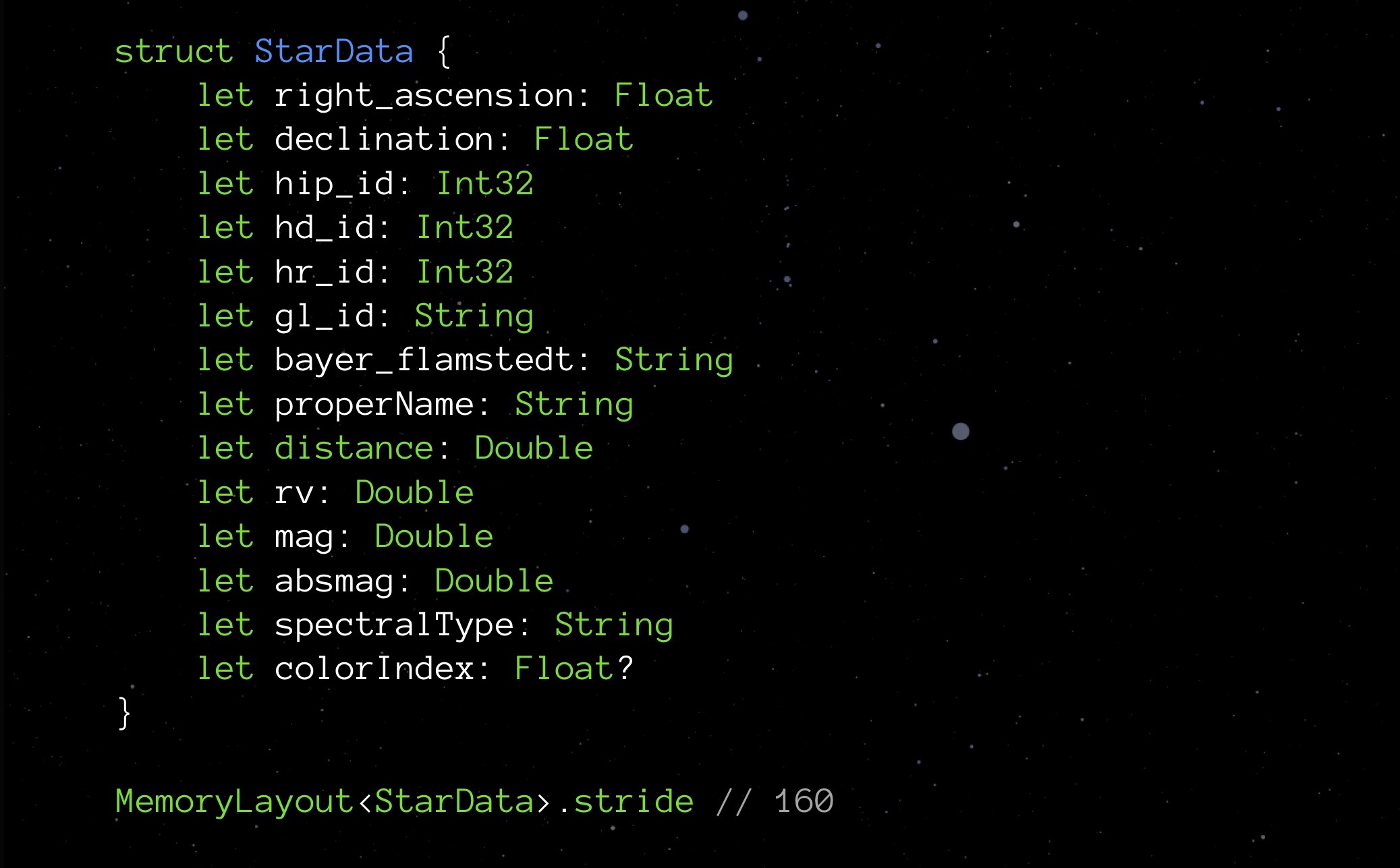
Resulta que al eliminar las opciones, ahorramos no 9 bytes (un byte para cada una de las nueve opciones), sino hasta 48. La sorpresa es agradable, pero me gustaría saber por qué sucedió esto. Y sucedió debido a la alineación de los datos en la memoria.
Alineación de datos
Recuerde que antes de Swift escribimos en Objective-C, y estaba basado en C, y esta situación también se remonta a C.
Al colocar cualquier estructura en la memoria, los procesadores modernos colocan sus elementos no en una corriente continua (no "hombro con hombro"), sino en una cuadrícula inhomogéneamente adelgazada por huecos. Esta es la alineación de datos. Le permite simplificar y acelerar el acceso a los elementos de datos necesarios en la memoria.
Las reglas de alineación de datos se aplican a cada variable según su tipo:
- una variable de tipo char puede comenzar desde 1º, 2º, 3º, 4º, etc. bytes, ya que solo toma un byte en sí mismo;
- una variable corta toma 2 bytes, por lo que puede comenzar desde el 2 °, 4 °, 6 °, 8 °, etc. un byte (es decir, de cada byte par);
- una variable de tipo flotante toma 4 bytes, lo que significa que puede comenzar con cada 4, 8, 12, 16, etc. un byte (es decir, cada cuarto byte);
- Las variables de tipo Double y String ocupan 8 bytes cada una, por lo que pueden comenzar con 8th, 16th, 24th, 32nd, etc. bytes
- etc.
Los objetos MemoryLayout <> tienen una propiedad de alineación que devuelve la regla de alineación correspondiente para el tipo especificado.
¿Podríamos aplicar el conocimiento de las reglas de alineación para optimizar el código? Veamos un ejemplo. Hay una estructura de usuario: para firstName y lastName usamos una cadena regular, para middleName, una cadena opcional (el usuario puede no tener ese nombre). En la memoria, una instancia de dicha estructura se colocará de la siguiente manera:

Como puede ver, dado que el middleName opcional toma 25 bytes (en lugar de múltiplos de 8 24 bytes), las reglas de alineación lo obligan a omitir los siguientes 7 bytes y gastar 80 bytes en toda la estructura. Aquí, no importa cómo intercambie bloques con cadenas, es imposible contar con un número menor de bytes.
Y ahora un ejemplo de alineación fallida:
 La estructura BadAligned primero declara isHidden del tipo Bool (1 byte), luego el tamaño del tipo Double (8 bytes), es Interactable del tipo bool (1 byte) y finalmente la edad del tipo Int (también 8 bytes). Declaradas en este orden, nuestras variables se colocarán en la memoria de tal manera que la estructura total ocupará 32 bytes.Intentemos cambiar el orden de declaración de los campos: los organizaremos en orden ascendente del volumen ocupado y veremos cómo cambia la imagen en la memoria.
La estructura BadAligned primero declara isHidden del tipo Bool (1 byte), luego el tamaño del tipo Double (8 bytes), es Interactable del tipo bool (1 byte) y finalmente la edad del tipo Int (también 8 bytes). Declaradas en este orden, nuestras variables se colocarán en la memoria de tal manera que la estructura total ocupará 32 bytes.Intentemos cambiar el orden de declaración de los campos: los organizaremos en orden ascendente del volumen ocupado y veremos cómo cambia la imagen en la memoria.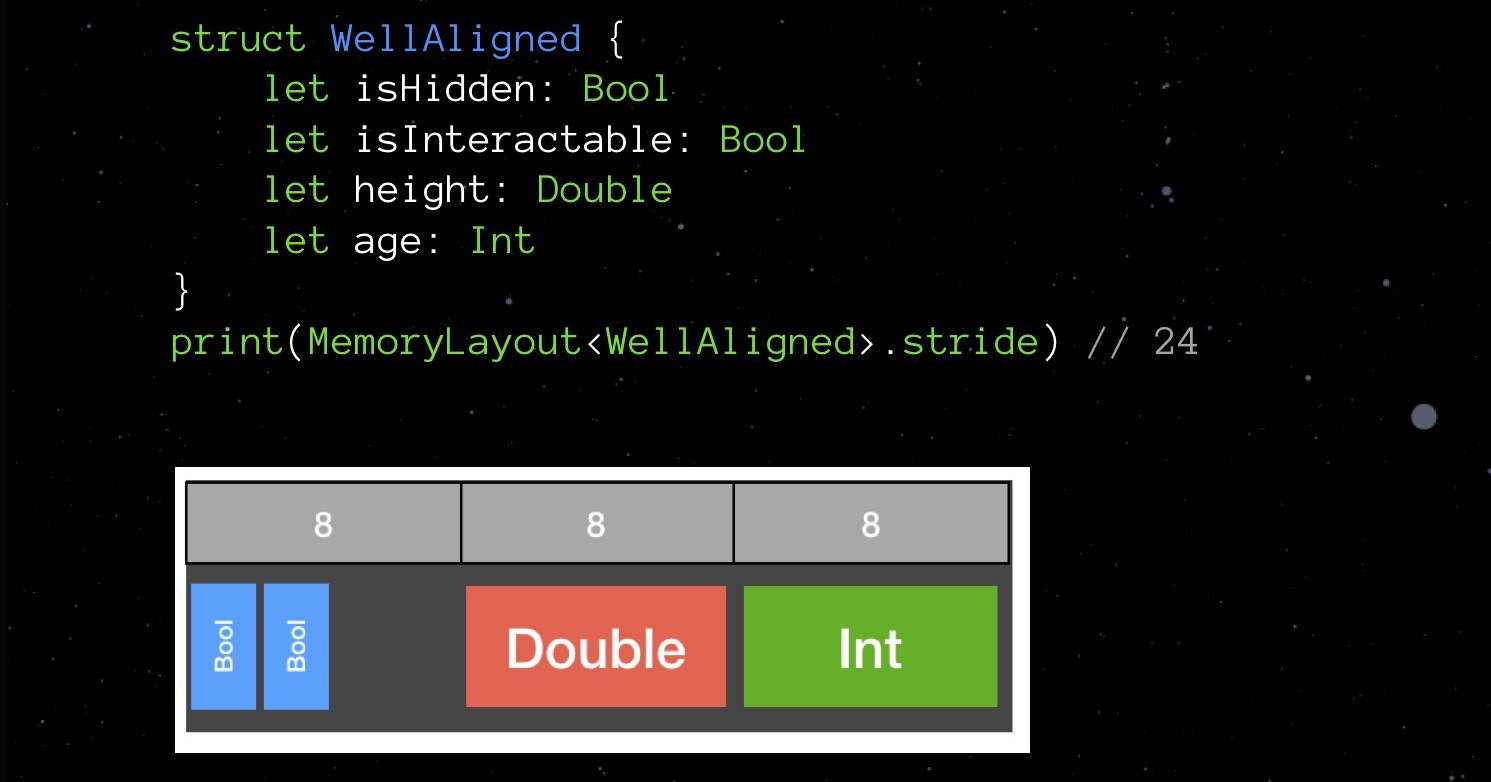 Nuestra estructura no toma 32 bytes, sino 24. Ahorre 25%.Suena como un juego de Tetris, ¿no? A tales cosas de bajo nivel, Swift le debe el lenguaje C a su antepasado. Al declarar campos en una gran estructura de datos al azar, es más probable que use más memoria de la que podría, dadas las reglas de alineación. Por lo tanto, trate de recordarlos y tenga en cuenta al escribir el código, esto no es tan difícil.Volvamos a nuestros StarData nuevamente. Intentemos organizar sus campos en orden de aumentar el volumen ocupado.
Nuestra estructura no toma 32 bytes, sino 24. Ahorre 25%.Suena como un juego de Tetris, ¿no? A tales cosas de bajo nivel, Swift le debe el lenguaje C a su antepasado. Al declarar campos en una gran estructura de datos al azar, es más probable que use más memoria de la que podría, dadas las reglas de alineación. Por lo tanto, trate de recordarlos y tenga en cuenta al escribir el código, esto no es tan difícil.Volvamos a nuestros StarData nuevamente. Intentemos organizar sus campos en orden de aumentar el volumen ocupado.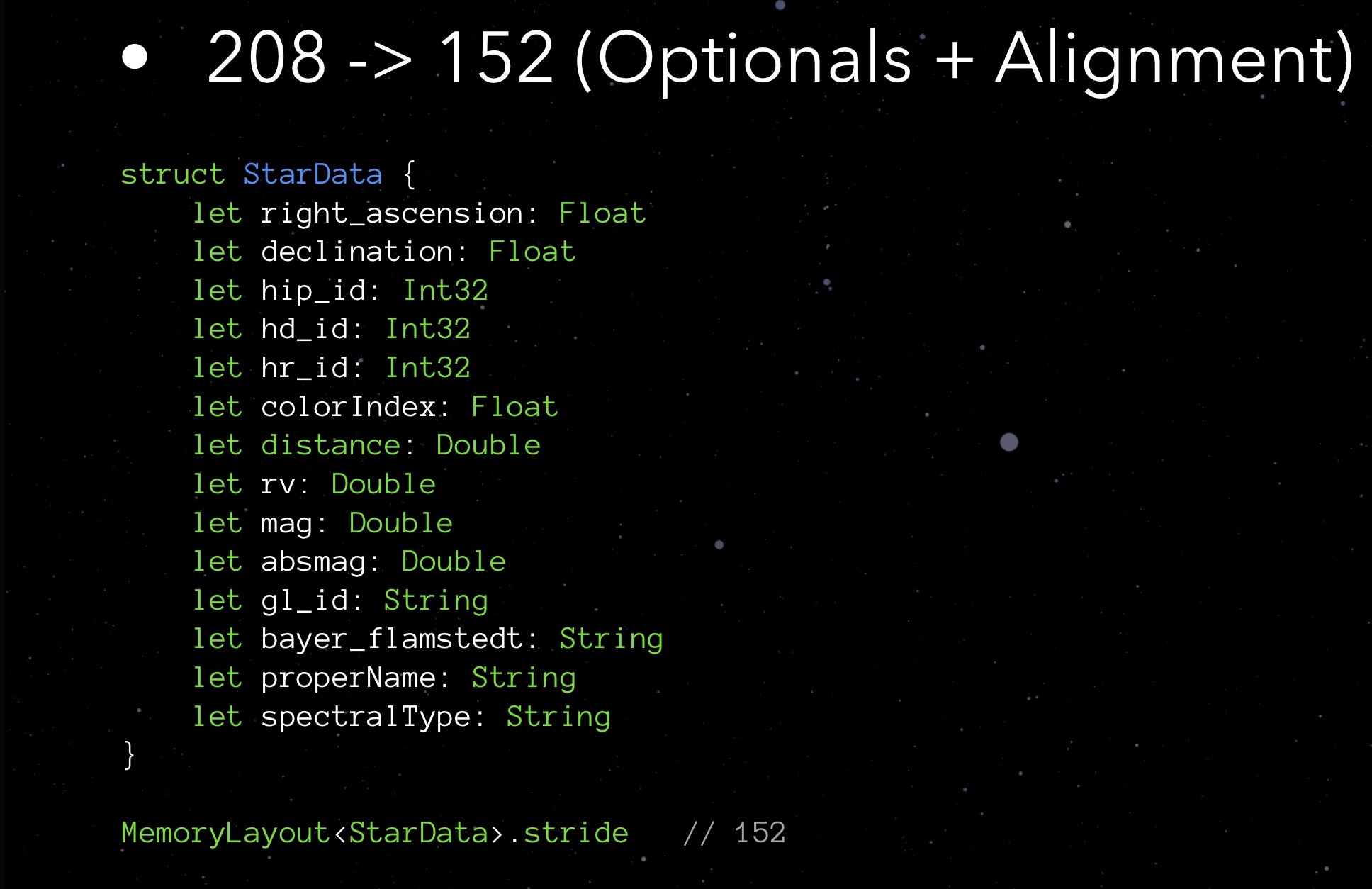 Primero, Float e Int32, luego Double y String. ¡No ese intrincado Tetris!La zancada que recibimos es de 152 bytes. Es decir, al optimizar la implementación de opciones y trabajar con la alineación, pudimos reducir el tamaño de la estructura de 208 a 152 bytes.¿Nos estamos acercando al límite de nuestras capacidades de optimización? Probablemente si. Sin embargo, hay algo más que usted y yo no hemos probado: algo es un orden de magnitud más complicado, pero a veces puede sorprenderlo con su resultado.
Primero, Float e Int32, luego Double y String. ¡No ese intrincado Tetris!La zancada que recibimos es de 152 bytes. Es decir, al optimizar la implementación de opciones y trabajar con la alineación, pudimos reducir el tamaño de la estructura de 208 a 152 bytes.¿Nos estamos acercando al límite de nuestras capacidades de optimización? Probablemente si. Sin embargo, hay algo más que usted y yo no hemos probado: algo es un orden de magnitud más complicado, pero a veces puede sorprenderlo con su resultado.Contabilidad lógica de dominio
Intente concentrarse en los detalles inherentes a su servicio. Recuerda mi ejemplo con el ajedrez: la idea de variar el indicador FPS cuando nada cambia en la pantalla es solo una optimización teniendo en cuenta la lógica de dominio de la aplicación.Echa un vistazo a StarData nuevamente. Nuestro obvio "cuello de botella" son los campos de tipo String, realmente ocupan mucho espacio. Y aquí los detalles son los siguientes: durante el tiempo de ejecución, la mayoría de estas líneas permanecen vacías. Solo 146 estrellas tienen un nombre "real", que se indica en el campo nombreNombre. Y gl_id es la identificación de la estrella según el catálogo de Gliese, que tiene 3801 estrellas, también está lejos de ser un millón. bayer_flamstedt - Las designaciones de Flemstead - serán asignadas a las 3064 estrellas. El tipo espectral spectralType es 4307 mi. Resulta que para la mayoría de las estrellas, las variables de cadena ingresadas estarán vacías, mientras que ocupan 24 bytes cada una.Se me ocurrió la siguiente salida. Consigamos una matriz asociativa como una estructura adicional. Como clave, un identificador numérico único de tipo Int16, como un valor, dependiendo de la presencia de la cadena característica, ya sea su valor o -1.En nuestro StarData opuesto a ownName, gl_id, bayer_flamstedt y spectralType, escribiremos el índice correspondiente a la clave en la matriz. Si es necesario, obtenga una u otra cadena característica, solicitaremos el valor de la matriz a través del índice. No es necesario hacer esto manualmente, implementamos mejor un getter seguro y conveniente: Getter es muy importante aquí, nos oculta la complejidad de nuestra propia implementación. Una matriz se puede registrar como privada, ahora no es necesario saber sobre su existencia.Por supuesto, esta solución tiene un signo menos. El ahorro de memoria no puede sino afectar la carga del procesador. Con este esquema, nos vemos obligados a acceder constantemente a nuestra matriz asociativa; y en la mayoría de los casos, en vano, ya que la mayoría de las líneas permanecerán vacías y las solicitudes devolverán "-1".Por lo tanto, tuve que cambiar ligeramente el concepto de la aplicación. Se decidió proporcionar al usuario información sobre la estrella solo cuando hace clic en esta estrella; solo entonces se ejecutará la consulta a la matriz asociativa y los datos recibidos se mostrarán en la pantalla.A pesar de la abstracción por getter, debemos admitir que al introducir una matriz asociativa, aún complicamos significativamente el código. Esto generalmente ocurre durante la optimización. Por lo tanto, es importante realizar pruebas unitarias de alta calidad, para asegurarse de que nuestra matriz asociativa no nos falle en un momento inesperado.Total: ¡Stride ahora nos da 64 bytes!¿Eso es todo? No, ahora tenemos que pensar nuevamente en las reglas de alineación: reorganizar los campos de tipo Int16 más arriba.
Getter es muy importante aquí, nos oculta la complejidad de nuestra propia implementación. Una matriz se puede registrar como privada, ahora no es necesario saber sobre su existencia.Por supuesto, esta solución tiene un signo menos. El ahorro de memoria no puede sino afectar la carga del procesador. Con este esquema, nos vemos obligados a acceder constantemente a nuestra matriz asociativa; y en la mayoría de los casos, en vano, ya que la mayoría de las líneas permanecerán vacías y las solicitudes devolverán "-1".Por lo tanto, tuve que cambiar ligeramente el concepto de la aplicación. Se decidió proporcionar al usuario información sobre la estrella solo cuando hace clic en esta estrella; solo entonces se ejecutará la consulta a la matriz asociativa y los datos recibidos se mostrarán en la pantalla.A pesar de la abstracción por getter, debemos admitir que al introducir una matriz asociativa, aún complicamos significativamente el código. Esto generalmente ocurre durante la optimización. Por lo tanto, es importante realizar pruebas unitarias de alta calidad, para asegurarse de que nuestra matriz asociativa no nos falle en un momento inesperado.Total: ¡Stride ahora nos da 64 bytes!¿Eso es todo? No, ahora tenemos que pensar nuevamente en las reglas de alineación: reorganizar los campos de tipo Int16 más arriba. Ahora ya está todo. Como puede ver, utilizando una pequeña cantidad de métodos esencialmente simples, pudimos reducir el tamaño de la estructura StarData de 208 a 56 bytes. Un millón de estrellas ahora ocupa no 500 Mb, sino 130. ¡Cuatro veces menos!No te olvides de los peligros de la optimización prematura. Si su estructura de datos de usuario se utilizará para unos 20 usuarios, no ganará allí tanto que tenga sentido hacerlo. Más importante aún, es conveniente para el próximo desarrollador después de que usted mantenga el código. ¡Por favor no digas más tarde "este tipo en la conferencia dijo que la orden debería ser solo eso"! No hagas esto solo por diversión. Bueno, para mí, esas cosas son un buen entretenimiento, no sé cómo para ti.
Ahora ya está todo. Como puede ver, utilizando una pequeña cantidad de métodos esencialmente simples, pudimos reducir el tamaño de la estructura StarData de 208 a 56 bytes. Un millón de estrellas ahora ocupa no 500 Mb, sino 130. ¡Cuatro veces menos!No te olvides de los peligros de la optimización prematura. Si su estructura de datos de usuario se utilizará para unos 20 usuarios, no ganará allí tanto que tenga sentido hacerlo. Más importante aún, es conveniente para el próximo desarrollador después de que usted mantenga el código. ¡Por favor no digas más tarde "este tipo en la conferencia dijo que la orden debería ser solo eso"! No hagas esto solo por diversión. Bueno, para mí, esas cosas son un buen entretenimiento, no sé cómo para ti.Optimización rápida del compilador
La mayoría de los programadores están familiarizados con el dolor de un reensamblaje largo (insoportablemente largo) de un proyecto. Acaba de hacer un pequeño cambio en el código, y ahora siéntese y espere hasta que finalice la compilación.Pero el proceso de compilación puede decirle algo sobre su código. Este es un excelente indicador de botnekov, solo necesita adaptarlo al trabajo.Personalmente, investigué la compilación en Xcode. Como herramienta, utilicé el siguiente comando: Este comando indica a xCode que rastree el tiempo de compilación de cada función y lo escriba en el archivo culprits.txt. Los contenidos del archivo se ordenan por el camino.
Este comando indica a xCode que rastree el tiempo de compilación de cada función y lo escriba en el archivo culprits.txt. Los contenidos del archivo se ordenan por el camino. Usando mi instrumento simple, pude observar cosas interesantes. Algunos métodos pueden compilarse por hasta 2 segundos, mientras que contienen solo tres líneas de código. ¿Cuál podría ser el motivo?Por ejemplo, algo como la salida del compilador de tipos. Si no especifica tipos explícitamente, Swift se ve obligado a detectarlos usted mismo. Esta operación (debo decir que no es trivial) requiere tiempo de procesador, por lo tanto, desde el punto de vista del compilador, siempre es mejor indicar el tipo. Simplemente escribiendo explícitamente los tipos, una vez pude reducir el tiempo de compilación de la aplicación de 5 a 2 (!) Minutos.Pero hay un "pero": el código sin tipos es aún más legible. Y ya hemos hablado de prioridades. No optimice con anticipación: al principio, la legibilidad del código será más costosa.
Usando mi instrumento simple, pude observar cosas interesantes. Algunos métodos pueden compilarse por hasta 2 segundos, mientras que contienen solo tres líneas de código. ¿Cuál podría ser el motivo?Por ejemplo, algo como la salida del compilador de tipos. Si no especifica tipos explícitamente, Swift se ve obligado a detectarlos usted mismo. Esta operación (debo decir que no es trivial) requiere tiempo de procesador, por lo tanto, desde el punto de vista del compilador, siempre es mejor indicar el tipo. Simplemente escribiendo explícitamente los tipos, una vez pude reducir el tiempo de compilación de la aplicación de 5 a 2 (!) Minutos.Pero hay un "pero": el código sin tipos es aún más legible. Y ya hemos hablado de prioridades. No optimice con anticipación: al principio, la legibilidad del código será más costosa.Opción de servidor
Hasta ahora, solo mencioné mi aplicación con realidad aumentada. Pero basado en un millón de estrellas, también creé una aplicación de servidor en Swift. Puedes verlo a él y su código en GitHub . Este es un servicio API que le permite recibir información sobre cualquier estrella de mi enorme base de datos. Pude optimizarlo usando los mismos métodos que usé para la aplicación en ARkit. El resultado en este caso se hizo literalmente tangible para mí: reduciendo el volumen al nivel de 500 MB, tuve la oportunidad de ponerlo en un servidor Bluemix gratuito. Como resultado, mi servicio me cuesta absolutamente gratis.Para resumir
En conclusión, un breve resumen de los pensamientos principales que quería abordar hoy:- . . , , , ?
- , unit-. , unit-. , . Unit- , .
- . , . , : — .
- Trabaja con la lógica de dominio de tu aplicación. La herramienta de optimización más poderosa es el trabajo hábil con la lógica de dominio. Conozca las características del trabajo, los detalles de su aplicación: intente tenerlos en cuenta, busque sus soluciones "personales".
- RAM vs. CPU Haga todo lo posible para mantener el equilibrio de la memoria y la utilización del procesador. Esto siempre es de gran dificultad, pero aún es posible encontrar un cierto óptimo en cada caso particular.
Si le gustó este informe de la conferencia de Mobius, tenga en cuenta que Mobius 2018 Moscú se llevará a cabo del 8 al 9 de diciembre , donde también habrá muchas cosas interesantes. Desde el 1 de noviembre, los precios de las entradas han aumentado, por lo que tiene sentido tomar una decisión ahora.