El aprendizaje reforzado (RL) es una de las técnicas de aprendizaje automático más prometedoras que se está desarrollando activamente. Aquí, el agente de IA recibe una recompensa positiva por las acciones correctas y una recompensa negativa por las acciones incorrectas. Este método de
zanahoria y palo es simple y universal. Con él, DeepMind enseñó el algoritmo
DQN para jugar viejos videojuegos de Atari, y
AlphaGoZero para jugar el antiguo juego Go. Así que OpenAI enseñó el algoritmo
OpenAI-Five para jugar al moderno videojuego Dota, y Google enseñó manos robóticas para
capturar nuevos objetos . A pesar del éxito de RL, todavía hay muchos problemas que reducen la efectividad de esta técnica.
Los algoritmos de RL
tienen dificultades para trabajar en un entorno donde el agente rara vez recibe comentarios. Pero esto es típico del mundo real. Como ejemplo, imagine buscar su queso favorito en un gran laberinto, como un supermercado. Estás buscando un departamento con quesos, pero no lo encuentras. Si en cada paso no obtiene un "palo" o una "zanahoria", entonces es imposible decir si se está moviendo en la dirección correcta. En ausencia de una recompensa, ¿qué le impide deambular para siempre? Nada más que tu curiosidad. Motiva mudarse al departamento de comestibles, que parece desconocido.
El trabajo científico,
"Curiosidad episódica a través de la accesibilidad", es el resultado de una colaboración entre
el equipo de Google Brain ,
DeepMind y
la Escuela Técnica Superior Suiza de Zurich . Ofrecemos un nuevo modelo de recompensa RL episódica basada en memoria. Parece una curiosidad que te permite explorar el entorno. Dado que el agente no solo debe estudiar el entorno, sino también resolver el problema inicial, nuestro modelo agrega una bonificación a la recompensa inicialmente escasa. La recompensa combinada ya no es escasa, lo que permite que los algoritmos RL estándar aprendan de ella. Por lo tanto, nuestro método de curiosidad amplía el rango de tareas que pueden resolverse usando RL.
 Curiosidad ocasional a través del alcance: los datos de observación se agregan a la memoria, la recompensa se calcula en función de cuán lejos está la observación actual de observaciones similares en la memoria. El agente recibe una recompensa mayor por las observaciones que aún no se presentan en la memoria.
Curiosidad ocasional a través del alcance: los datos de observación se agregan a la memoria, la recompensa se calcula en función de cuán lejos está la observación actual de observaciones similares en la memoria. El agente recibe una recompensa mayor por las observaciones que aún no se presentan en la memoria.La idea principal del método es almacenar las observaciones del agente del medio ambiente en la memoria episódica, así como recompensar al agente por ver las observaciones que aún no se presentan en la memoria. "Falta de memoria" es la definición de novedad en nuestro método. La búsqueda de tales observaciones significa la búsqueda de un extraño. Tal deseo de buscar un extraño llevará al agente de IA a nuevas ubicaciones, evitando así deambular en un círculo y, en última instancia, lo ayudará a tropezar con el objetivo. Como discutimos más adelante, nuestra redacción puede disuadir al agente del comportamiento indeseable al que están sujetas otras palabras. Para nuestra gran sorpresa, este comportamiento tiene algunas similitudes con lo que un laico llamaría "procrastinación".
Curiosidad previa
Aunque ha habido muchos intentos de formular curiosidad en el pasado
[1] [2] [3] [4] , en este artículo nos centraremos en un enfoque natural y muy popular: curiosidad a través de la sorpresa basada en pronósticos. Esta técnica se describe en un artículo reciente,
"Investigación de un entorno utilizando la curiosidad prediciendo bajo su propio control" (generalmente denominado ICM). Para ilustrar la conexión entre sorpresa y curiosidad, nuevamente utilizamos la analogía de encontrar queso en un supermercado.
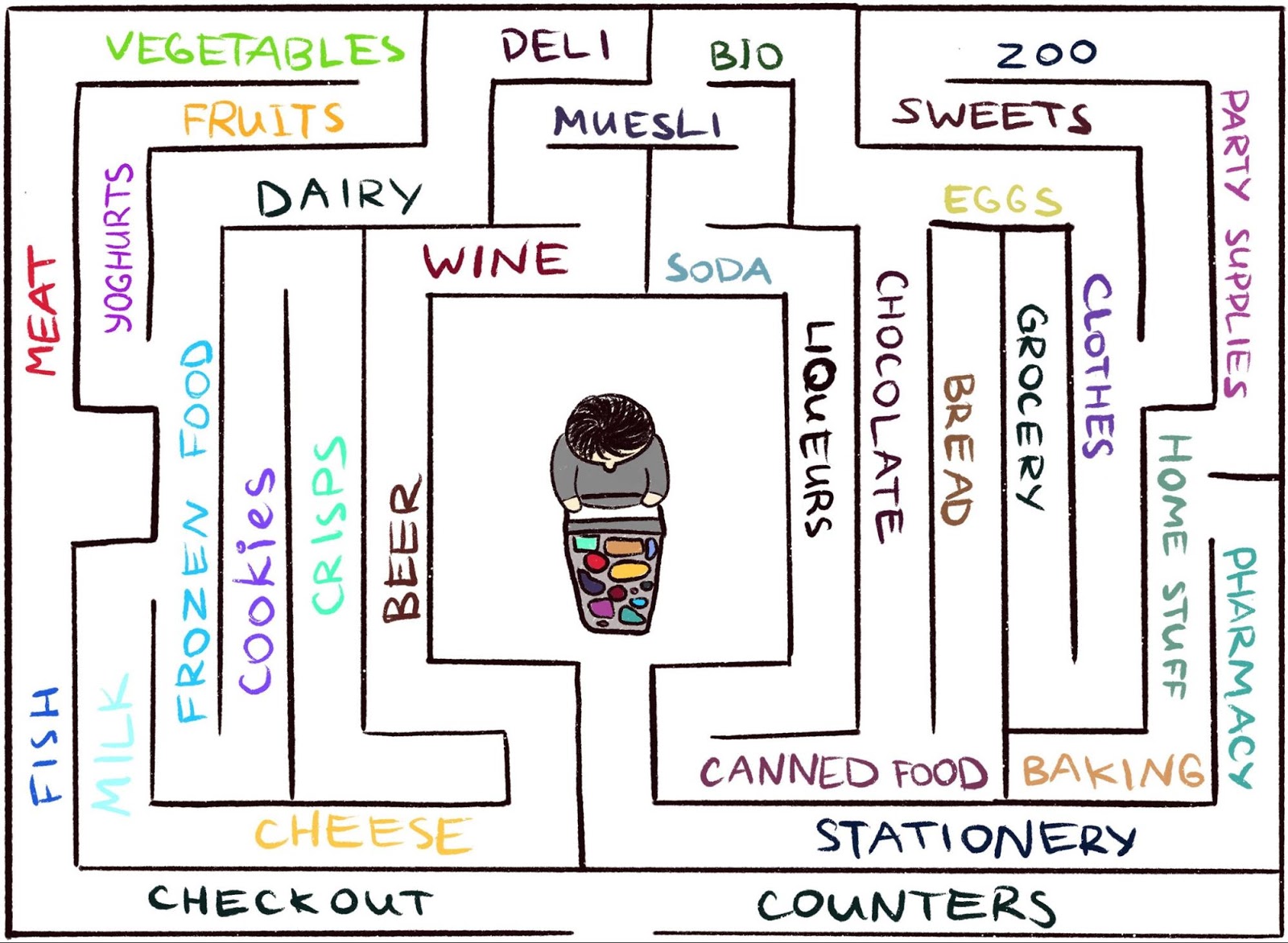 Ilustración de Indira Pasko , bajo licencia CC BY-NC-ND 4.0
Ilustración de Indira Pasko , bajo licencia CC BY-NC-ND 4.0Paseando por la tienda, está tratando de predecir el futuro (
"Ahora estoy en el departamento de carne, así que creo que el departamento a la vuelta de la esquina es el departamento de pescado, generalmente están cerca en esta cadena de supermercados" ). Si el pronóstico es incorrecto, se sorprenderá (
"En realidad, hay un departamento de verduras. ¡No esperaba esto!" ) Y de esta forma se obtiene una recompensa. Esto aumenta la motivación en el futuro para mirar a la vuelta de la esquina, explorar nuevos lugares solo para verificar que sus expectativas sean verdaderas (y posiblemente tropezar con queso).
Del mismo modo, el método ICM crea un modelo predictivo de la dinámica del mundo y le da al agente una recompensa si el modelo no puede hacer buenas predicciones, un marcador de sorpresa o novedad. Tenga en cuenta que explorar nuevos lugares no se articula directamente en la curiosidad de ICM. Para el método ICM, asistir a ellos es solo una forma de obtener más "sorpresas" y así maximizar su recompensa general. Como resultado, en algunos entornos puede haber otras formas de sorprenderse, lo que conduce a resultados inesperados.
Un agente con un sistema de curiosidad basado en sorpresas se congela cuando se reúne con un televisor. Animación del video de Deepak Patak , licenciado bajo CC BY 2.0El peligro de la dilación.
En el artículo,
"Un estudio a gran escala del aprendizaje basado en la curiosidad", los autores del método ICM, junto con los investigadores de OpenAI, muestran un peligro oculto de maximizar la sorpresa: los agentes pueden aprender a darse el gusto en lugar de hacer algo útil para la tarea. Para entender por qué sucede esto, considere un experimento mental que los autores llaman el "problema del ruido de la televisión". Aquí el agente se coloca en un laberinto con la tarea de encontrar un elemento muy útil (como "queso" en nuestro ejemplo). El entorno tiene un televisor y el agente tiene un control remoto. Hay un número limitado de canales (cada canal tiene una transmisión separada), y cada vez que se presiona el control remoto, el televisor cambia a un canal aleatorio. ¿Cómo actuará un agente en ese entorno?
Si la curiosidad se forma sobre la base de la sorpresa, entonces un cambio de canales dará más recompensas, ya que cada cambio es impredecible e inesperado. Es importante tener en cuenta que incluso después de una exploración cíclica de todos los canales disponibles, una selección aleatoria de un canal asegura que cada nuevo cambio seguirá siendo inesperado: el agente hace una predicción de que mostrará TV después de cambiar el canal, y lo más probable es que el pronóstico sea incorrecto, lo que causará sorpresa. Es importante tener en cuenta que incluso si el agente ya ha visto cada transmisión en cada canal, el cambio sigue siendo impredecible. Debido a esto, el agente, en lugar de buscar un elemento muy útil, finalmente permanecerá frente al televisor, de manera similar a la dilación. ¿Cómo cambiar la redacción de la curiosidad para evitar este comportamiento?
Curiosidad episódica
En el artículo
"Curiosidad episódica a través de accesibilidad", exploramos un modelo de curiosidad episódica basado en la memoria que es menos propenso al placer instantáneo. Por qué Si tomamos el ejemplo anterior, luego de algún tiempo cambiando de canal, todas las transmisiones terminarán en la memoria. Por lo tanto, el televisor perderá su atractivo: incluso si el orden en que aparecen los programas en la pantalla es aleatorio e impredecible, ¡todos están en la memoria! Esta es la principal diferencia con el método basado en la sorpresa: nuestro método ni siquiera trata de predecir el futuro, es difícil de predecir (o incluso imposible). En cambio, el agente examina el pasado y verifica si hay observaciones en la memoria
como la actual. Por lo tanto, nuestro agente no es propenso a los placeres instantáneos, lo que produce un "ruido de televisión". El agente tendrá que ir a explorar el mundo fuera del televisor para obtener más recompensas.
Pero, ¿cómo decidimos si un agente ve lo mismo que está almacenado en la memoria? La comprobación de coincidencia exacta no tiene sentido: en un entorno real, un agente rara vez ve lo mismo dos veces. Por ejemplo, incluso si el agente regresa a la misma habitación, seguirá viendo esta habitación desde un ángulo diferente.
En lugar de buscar coincidencias exactas, utilizamos una
red neuronal profunda que está entrenada para medir cuán similares son dos experiencias. Para entrenar esta red, debemos adivinar qué tan cerca ocurrieron las observaciones a tiempo. La proximidad en el tiempo es un buen indicador de si dos observaciones deben considerarse parte de la misma. Tal aprendizaje conduce a un concepto general de novedad a través de la accesibilidad, que se ilustra a continuación.
 El gráfico de accesibilidad define la novedad. En la práctica, este gráfico no está disponible; por lo tanto, entrenamos al aproximador de la red neuronal para estimar el número de pasos entre observaciones
El gráfico de accesibilidad define la novedad. En la práctica, este gráfico no está disponible; por lo tanto, entrenamos al aproximador de la red neuronal para estimar el número de pasos entre observacionesResultados experimentales
Para comparar el rendimiento de diferentes enfoques para describir la curiosidad, los probamos en dos entornos 3D visualmente ricos:
ViZDoom y
DMLab . En estas condiciones, al agente se le asignaron varias tareas, como encontrar un objetivo en el laberinto, recolectar objetos buenos y evitar los malos. En el entorno DMLab, el agente está equipado de manera predeterminada con un dispositivo fantástico como un láser, pero si el dispositivo no es necesario para una tarea específica, el agente no puede usarlo libremente. Curiosamente, basado en la sorpresa, el agente ICM realmente usó el láser con mucha frecuencia, ¡incluso si era inútil completar la tarea! Como en el caso de la TV, en lugar de buscar un objeto valioso en el laberinto, prefería pasar el tiempo disparando en las paredes, ya que daba muchas recompensas en forma de sorpresa. Teóricamente, el resultado de un tiro en la pared debería ser predecible, pero en la práctica es demasiado difícil de predecir. Esto probablemente requiere un conocimiento más profundo de la física que el que está disponible para el agente de IA estándar.

A diferencia de él, nuestro agente ha dominado un comportamiento razonable para estudiar el medio ambiente. Esto sucedió porque no está tratando de predecir el resultado de sus acciones, sino que está buscando observaciones que están "más lejos" de las que están en la memoria episódica. En otras palabras, el agente persigue implícitamente objetivos que requieren más esfuerzo que un simple tiro al muro.
Nuestro método demuestra un comportamiento inteligente de exploración ambiental.Es interesante observar cómo nuestro enfoque de recompensa castiga a un agente que se ejecuta en un círculo, porque después de completar el primer círculo, el agente no encuentra nuevas observaciones y, por lo tanto, no recibe ninguna recompensa:
Visualización de recompensa: el rojo corresponde a la recompensa negativa, el verde a positivo. De izquierda a derecha: tarjeta de premio, mapa con ubicaciones en la memoria, vista en primera personaAl mismo tiempo, nuestro método contribuye a un buen estudio del medio ambiente:
Visualización de recompensa: el rojo corresponde a la recompensa negativa, el verde a positivo. De izquierda a derecha: tarjeta de premio, mapa con ubicaciones en la memoria, vista en primera personaEsperamos que nuestro trabajo contribuya a una nueva ola de investigación que vaya más allá del alcance de la técnica de la sorpresa para educar a los agentes sobre un comportamiento más inteligente. Para un análisis en profundidad de nuestro método, eche un vistazo a la
preimpresión del trabajo científico .
Agradecimientos
Este proyecto es el resultado de una colaboración entre el equipo de Google Brain, DeepMind y la Escuela Técnica Superior Suiza de Zurich. Grupo de investigación principal: Nikolay Savinov, Anton Raichuk, Rafael Marinier, Damien Vincent, Mark Pollefeys, Timothy Lillirap y Sylvain Zheli. Nos gustaría agradecer a Olivier Pietkin, Carlos Riquelme, Charles Blundell y Sergey Levine por discutir este documento. Agradecemos a Indira Pasco por su ayuda con las ilustraciones.
Referencias a la literatura:
[1]
"El estudio del medio ambiente basado en contar con modelos de densidad neural" , Georg Ostrovsky, Mark G. Bellemar, Aaron Van den Oord, Remy Munoz
[2]
“Entornos de aprendizaje basados en conteo
para el aprendizaje profundo con refuerzo” , Khaoran Tan, Rain Huthuft, Davis Foot, Adam Knock, Xi Chen, Yan Duan, John Schulman, Philip de Turk, Peter Abbel
[3]
"Aprender sin un maestro para localizar metas para la investigación motivada internamente", Alexander Pere, Sebastien Forestier, Olivier Sigot, Pierre-Yves Udeye
[4]
"VIME: Inteligencia para maximizar los cambios de información", Rein Huthuft, Xi Chen, Yan Duan, John Schulman, Philippe de Turk, Peter Abbel