Hola habr.
En un proyecto donde era necesario almacenar y procesar una lista dinámica bastante grande, los evaluadores comenzaron a quejarse de la falta de memoria. A continuación se describe una manera simple de solucionar el problema con "poca sangre" agregando una sola línea de código. El resultado en la imagen:
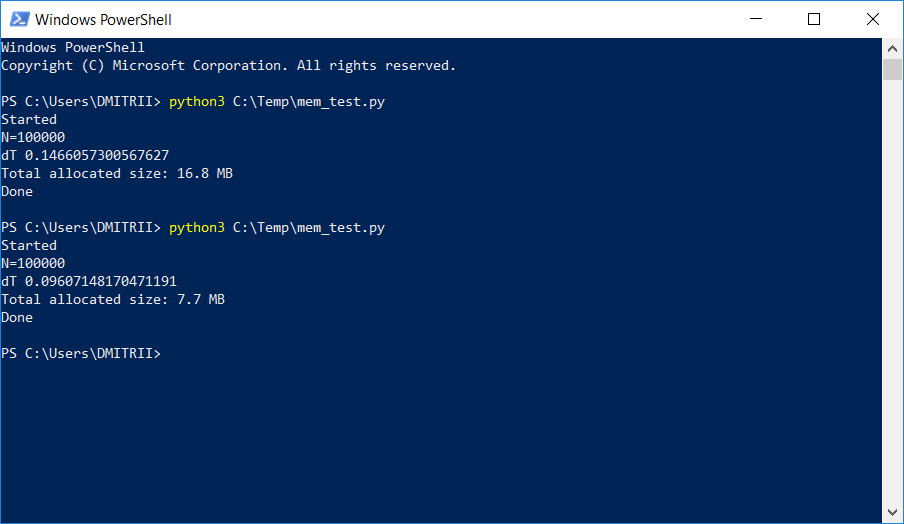
Cómo funciona, continuó debajo del corte.
Considere un ejemplo simple de "capacitación": cree una clase DataItem que contenga datos
personales sobre una persona, por ejemplo, nombre, edad y dirección.
class DataItem(object): def __init__(self, name, age, address): self.name = name self.age = age self.address = address
La pregunta de los "niños" es ¿cuánto tarda ese objeto en la memoria?
Probemos la solución en la frente:
d1 = DataItem("Alex", 42, "-") print ("sys.getsizeof(d1):", sys.getsizeof(d1))
Obtenemos una respuesta de 56 bytes. Parece un poco, bastante satisfecho.
Sin embargo, verificamos otro objeto en el que hay más datos:
d2 = DataItem("Boris", 24, "In the middle of nowhere") print ("sys.getsizeof(d2):", sys.getsizeof(d2))
La respuesta es nuevamente 56. En este punto, entendemos que algo no está bien aquí, y que no todo es tan simple como parece a primera vista.
La intuición no nos falla, y todo no es realmente tan simple. Python es un lenguaje muy flexible con tipeo dinámico, y por su trabajo, almacena muchos datos adicionales. Que por sí mismos ocupan mucho. Solo como ejemplo, sys.getsizeof ("") devolverá 33 - sí, ¡hasta 33 bytes por línea vacía! Y sys.getsizeof (1) devolverá 24-24 bytes para un número entero (le pido a los programadores de C que se alejen de la pantalla y no lean más, para no perder la fe en lo bello). Para elementos más complejos, como un diccionario, sys.getsizeof (dict ()) devolverá 272 bytes, y esto es para un diccionario
vacío . No continuaré más, espero que el principio sea claro,
y los fabricantes de RAM también necesiten vender sus chips .
Pero volvamos a nuestra clase DataItem y a la pregunta "secundaria". ¿Cuánto tiempo dura tal clase en la memoria? Para empezar, mostramos todo el contenido de la clase en un nivel inferior:
def dump(obj): for attr in dir(obj): print(" obj.%s = %r" % (attr, getattr(obj, attr)))
Esta función mostrará lo que está oculto "debajo del capó" para que todas las funciones de Python (mecanografía, herencia y otras cosas) puedan funcionar.
El resultado es impresionante:
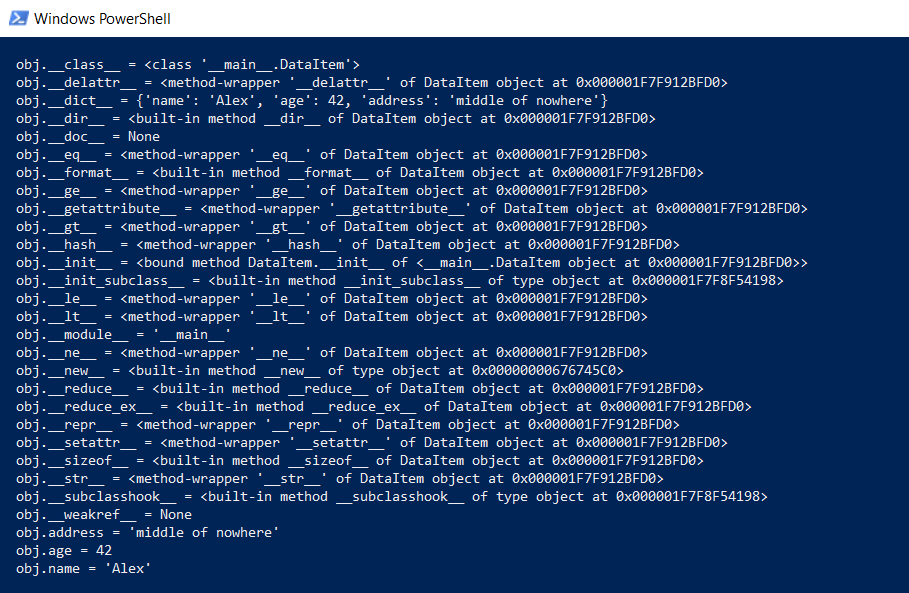
¿Cuánto cuesta todo esto? En github había una función que calcula la cantidad real de datos, llamando recursivamente getsizeof para todos los objetos.
def get_size(obj, seen=None):
Lo intentamos:
d1 = DataItem("Alex", 42, "-") print ("get_size(d1):", get_size(d1)) d2 = DataItem("Boris", 24, "In the middle of nowhere") print ("get_size(d2):", get_size(d2))
Obtenemos 460 y 484 bytes, respectivamente, que es más como la verdad.
Teniendo esta función, se pueden llevar a cabo una serie de experimentos. Por ejemplo, me pregunto cuántos datos ocuparán si coloca las estructuras DataItem en la lista. La función get_size ([d1]) devuelve 532 bytes, aparentemente este es el "mismo" 460 + algo de sobrecarga. Pero get_size ([d1, d2]) devolverá 863 bytes, menos de 460 + 484 por separado. Aún más interesante es el resultado de get_size ([d1, d2, d1]): obtenemos 871 bytes, solo un poco más, es decir Python es lo suficientemente inteligente como para no asignar memoria para el mismo objeto por segunda vez.
Ahora pasamos a la segunda parte de la pregunta: ¿es posible reducir el consumo de memoria? Si puedes. Python es un intérprete, y podemos expandir nuestra clase en cualquier momento, por ejemplo, agregar un nuevo campo:
d1 = DataItem("Alex", 42, "-") print ("get_size(d1):", get_size(d1)) d1.weight = 66 print ("get_size(d1):", get_size(d1))
Esto es genial, pero si
no necesitamos esta funcionalidad, podemos obligar al intérprete a enumerar los objetos de la clase utilizando la directiva __slots__:
class DataItem(object): __slots__ = ['name', 'age', 'address'] def __init__(self, name, age, address): self.name = name self.age = age self.address = address
Puede leer más en la documentación (
RTFM ), que dice que "__slots__ nos permite declarar explícitamente miembros de datos (como propiedades) y negar la creación de __dict__ y __weakref__. El espacio ahorrado usando __dict__
puede ser significativo ".
Comprobación: sí, realmente significativo, get_size (d1) devuelve ... 64 bytes en lugar de 460, es decir 7 veces menos Como beneficio adicional, los objetos se crean aproximadamente un 20% más rápido (vea la primera captura de pantalla del artículo).
Por desgracia, con un uso real, una ganancia tan grande en la memoria no se debe a otros gastos generales. Creemos una matriz para 100,000 simplemente agregando elementos y veamos el consumo de memoria:
data = [] for p in range(100000): data.append(DataItem("Alex", 42, "middle of nowhere")) snapshot = tracemalloc.take_snapshot() top_stats = snapshot.statistics('lineno') total = sum(stat.size for stat in top_stats) print("Total allocated size: %.1f MB" % (total / (1024*1024)))
Tenemos 16.8 MB sin __slots__ y 6.9 MB con él. No 7 veces, por supuesto, pero aún así bastante bien, dado que el cambio de código fue mínimo.
Ahora sobre las deficiencias. La activación de __slots__ prohíbe la creación de todos los elementos, incluido __dict__, lo que significa, por ejemplo, que dicho código para traducir una estructura a json no funcionará:
def toJSON(self): return json.dumps(self.__dict__)
Pero es fácil de solucionar, solo genera tu dict mediante programación, clasificando todos los elementos en el bucle:
def toJSON(self): data = dict() for var in self.__slots__: data[var] = getattr(self, var) return json.dumps(data)
También será imposible agregar dinámicamente nuevas variables a la clase, pero en mi caso esto no fue necesario.
Y la última prueba de hoy. Es interesante ver cuánta memoria ocupa todo el programa. Agregue un bucle sin fin al final del programa para que no se cierre y vea el consumo de memoria en el administrador de tareas de Windows.
Sin __slots__:
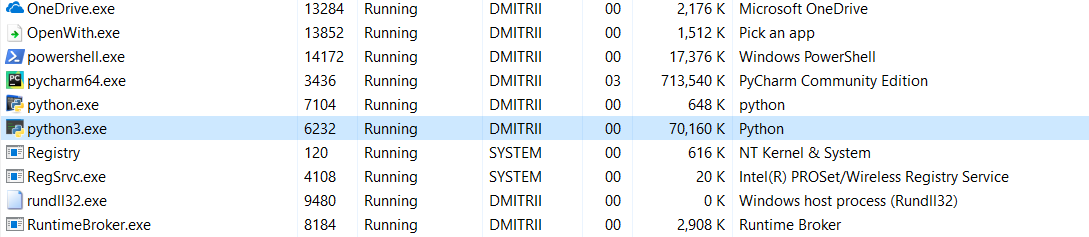
16,8 MB de alguna manera se convirtió milagrosamente (edición - una explicación del milagro a continuación) a 70 MB (¿espero que los programadores de C todavía no hayan regresado a la pantalla?).
Con __slots__ habilitado:

6.9MB se convirtieron en 27MB ... bueno, después de todo, ahorramos memoria, 27MB en lugar de 70 no es tan malo por el resultado de agregar una línea de código.
Editar : en los comentarios (gracias a robert_ayrapetyan para la prueba), sugirieron que la biblioteca de depuración de tracemalloc ocupa mucha memoria adicional. Aparentemente, agrega elementos adicionales a
cada objeto creado. Si lo desactiva, el consumo total de memoria será mucho menor, la captura de pantalla muestra 2 opciones:
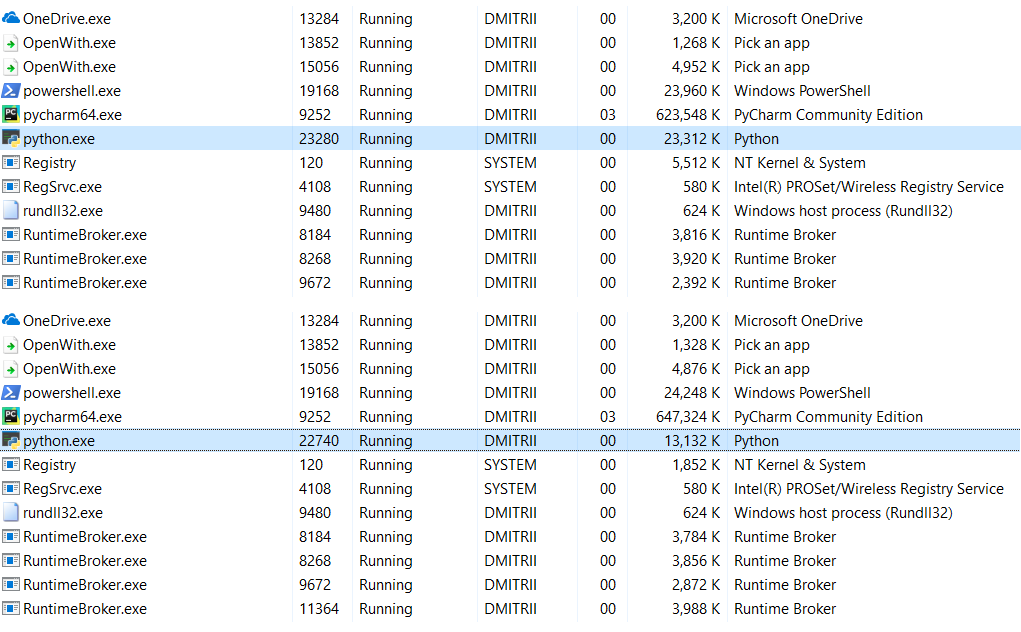
¿Qué hacer si necesita ahorrar aún más memoria? Esto es posible utilizando la biblioteca
numpy , que le permite crear estructuras de estilo C, pero en mi caso requeriría un refinamiento más profundo del código, y el primer método resultó ser suficiente.
Es extraño que el uso de __slots__ nunca haya sido examinado en detalle en Habré, espero que este artículo llene un poco este vacío.
En lugar de una conclusión.
Este artículo puede parecer anti-publicidad de Python, pero no lo es en absoluto. Python es muy confiable (debe esforzarse
mucho para eliminar un programa de Python), un lenguaje que es fácil de leer y fácil de escribir. Estas ventajas son mayores que las desventajas en muchos casos, pero si necesita el máximo rendimiento y eficiencia, puede usar bibliotecas como Numpy escritas en C ++ que funcionan con datos de manera bastante rápida y eficiente.
Gracias a todos por su atención y buen código :)