Experimentando con mejoras para el
modelo de pronóstico de
Guess.js , comencé a mirar de cerca el aprendizaje profundo: redes neuronales recurrentes (RNN), en particular LSTM, debido a su
"efectividad irracional" en el área donde trabaja Guess.js. Al mismo tiempo, comencé a jugar con redes neuronales convolucionales (CNN), que también se usan a menudo para series de tiempo. Las CNN se usan comúnmente para clasificar, reconocer y detectar imágenes.
 Administrar MK.js con TensorFlow.js
Administrar MK.js con TensorFlow.jsEl código fuente de este artículo y MK.js están en mi GitHub . ¡No he publicado un conjunto de datos de entrenamiento, pero puedes construir el tuyo y entrenar el modelo como se describe a continuación!
Después de jugar con CNN, recordé un
experimento que realicé hace varios años cuando los desarrolladores de navegadores lanzaron la API
getUserMedia . En él, la cámara del usuario sirvió como controlador para jugar al pequeño clon JavaScript de Mortal Kombat 3. Puedes encontrar ese juego en
el repositorio de GitHub . Como parte del experimento, implementé un algoritmo de posicionamiento básico que clasifica la imagen en las siguientes clases:
- Golpe izquierdo o derecho
- Patada izquierda o derecha
- Pasos a izquierda y derecha
- Ponerse en cuclillas
- Ninguna de las anteriores
El algoritmo es tan simple que puedo explicarlo en unas pocas oraciones:
El algoritmo fotografía el fondo. Tan pronto como el usuario aparece en el cuadro, el algoritmo calcula la diferencia entre el fondo y el cuadro actual con el usuario. Entonces determina la posición de la figura del usuario. El siguiente paso es mostrar el cuerpo del usuario en blanco sobre negro. Después de eso, se construyen histogramas verticales y horizontales, sumando los valores para cada píxel. Basado en este cálculo, el algoritmo determina la posición actual del cuerpo.
El video muestra cómo funciona el programa. Código fuente de
GitHub .
Aunque el pequeño clon MK funcionó con éxito, el algoritmo está lejos de ser perfecto. Se requiere un marco con un fondo. Para una operación adecuada, el fondo debe ser del mismo color durante la ejecución del programa. Tal limitación significa que los cambios en la luz, la sombra y otras cosas interferirán y darán un resultado inexacto. Finalmente, el algoritmo no reconoce la acción; solo clasifica el nuevo marco como la posición del cuerpo de un conjunto predefinido.
Ahora, gracias al progreso en la API web, es decir, WebGL, decidí volver a esta tarea aplicando TensorFlow.js.
Introduccion
En este artículo, compartiré mi experiencia en la creación de un algoritmo para clasificar las posiciones del cuerpo usando TensorFlow.js y MobileNet. Considere los siguientes temas:
- Recolección de datos de capacitación para la clasificación de imágenes.
- Aumento de datos con imgaug
- Transferir aprendizaje con MobileNet
- Clasificación binaria y clasificación N-primaria
- Entrenamiento del modelo de clasificación de imágenes TensorFlow.js en Node.js y uso en un navegador
- Algunas palabras sobre la clasificación de acciones con LSTM
En este artículo, reduciremos el problema para determinar la posición del cuerpo sobre la base de un cuadro, en contraste con el reconocimiento de acciones por una secuencia de cuadros. Desarrollaremos un modelo de aprendizaje profundo con un maestro, que, según la imagen de la cámara web del usuario, determina los movimientos de una persona: patada, pierna o nada de esto.
Al final del artículo, podremos construir un modelo para jugar
MK.js :

Para una mejor comprensión del artículo, el lector debe estar familiarizado con los conceptos fundamentales de programación y JavaScript. Una comprensión básica del aprendizaje profundo también es útil, pero no necesaria.
Recogida de datos
La precisión del modelo de aprendizaje profundo depende en gran medida de la calidad de los datos. Necesitamos esforzarnos por recopilar un amplio conjunto de datos, como en la producción.
Nuestro modelo debería ser capaz de reconocer golpes y patadas. Esto significa que debemos recopilar imágenes de tres categorías:
En este experimento, dos voluntarios (
@lili_vs y
@gsamokovarov ) me ayudaron a recolectar fotos. Grabamos 5 videos QuickTime en mi MacBook Pro, cada uno con 2-4 patadas y 2-4 patadas.
Luego usamos ffmpeg para extraer cuadros individuales de los videos y guardarlos como imágenes
jpg :
ffmpeg -i video.mov $filename%03d.jpgPara ejecutar el comando anterior, primero debe
instalar ffmpeg en la computadora.
Si queremos entrenar el modelo, debemos proporcionar los datos de entrada y los datos de salida correspondientes, pero en esta etapa solo tenemos un grupo de imágenes de tres personas en diferentes poses. Para estructurar los datos, debe clasificar los marcos en tres categorías: golpes, patadas y otros. Para cada categoría, se crea un directorio separado donde se mueven todas las imágenes correspondientes.
Por lo tanto, en cada directorio debe haber aproximadamente 200 imágenes similares a las siguientes:

Tenga en cuenta que habrá muchas más imágenes en el directorio Otros, porque relativamente pocos cuadros contienen fotos de golpes y patadas, y en los cuadros restantes la gente camina, se da vuelta o controla el video. Si tenemos demasiadas imágenes de una clase, corremos el riesgo de enseñar el modelo sesgado hacia esta clase en particular. En este caso, al clasificar una imagen con un impacto, la red neuronal aún puede determinar la clase "Otro". Para reducir este sesgo, puede eliminar algunas fotos del directorio Otros y entrenar al modelo en un número igual de imágenes de cada categoría.
Para mayor comodidad, asignamos los números en los números de catálogos del
1 al
190 , por lo que la primera imagen será
1.jpg , la segunda
2.jpg , etc.
Si entrenamos el modelo en solo 600 fotografías tomadas en el mismo entorno con las mismas personas, no alcanzaremos un nivel de precisión muy alto. Para aprovechar al máximo nuestros datos, es mejor generar algunas muestras adicionales utilizando el aumento de datos.
Aumento de datos
El aumento de datos es una técnica que aumenta el número de puntos de datos al sintetizar nuevos puntos de un conjunto existente. Por lo general, el aumento se usa para aumentar el tamaño y la diversidad del conjunto de entrenamiento. Transferimos las imágenes originales a la tubería de transformaciones que crean nuevas imágenes. No puede abordar las transformaciones con demasiada agresividad: solo se deberían generar otros golpes de mano a partir de un golpe.
Las transformaciones aceptables son rotación, inversión de color, desenfoque, etc. Existen excelentes herramientas de código abierto para el aumento de datos. Al momento de escribir este artículo en JavaScript, no había demasiadas opciones, así que utilicé la biblioteca implementada en Python -
imgaug . Tiene un conjunto de aumentadores que se pueden aplicar probabilísticamente.
Aquí está la lógica de aumento de datos para este experimento:
np.random.seed(44) ia.seed(44) def main(): for i in range(1, 191): draw_single_sequential_images(str(i), "others", "others-aug") for i in range(1, 191): draw_single_sequential_images(str(i), "hits", "hits-aug") for i in range(1, 191): draw_single_sequential_images(str(i), "kicks", "kicks-aug") def draw_single_sequential_images(filename, path, aug_path): image = misc.imresize(ndimage.imread(path + "/" + filename + ".jpg"), (56, 100)) sometimes = lambda aug: iaa.Sometimes(0.5, aug) seq = iaa.Sequential( [ iaa.Fliplr(0.5),
Este script utiliza el método
main con tres bucles
for , uno para cada categoría de imagen. En cada iteración, en cada uno de los bucles, llamamos al método
draw_single_sequential_images : el primer argumento es el nombre del archivo, el segundo es la ruta, el tercero es el directorio donde guardar el resultado.
Después de eso, leemos la imagen del disco y le aplicamos una serie de transformaciones. He documentado la mayoría de las transformaciones en el fragmento de código anterior, por lo que no lo repetiremos.
Para cada imagen, se crean otras 16 imágenes. Aquí hay un ejemplo de cómo se ven:

Tenga en cuenta que en el script anterior
100x56 imágenes a
100x56 píxeles. Hacemos esto para reducir la cantidad de datos y, en consecuencia, la cantidad de cálculos que nuestro modelo realiza durante el entrenamiento y la evaluación.
Edificio modelo
¡Ahora construya un modelo para la clasificación!
Como estamos tratando con imágenes, utilizamos una red neuronal convolucional (CNN). Se sabe que esta arquitectura de red es adecuada para el reconocimiento de imágenes, detección de objetos y clasificación.
Transferencia de aprendizaje
La imagen a continuación muestra el popular CNN VGG-16, utilizado para clasificar imágenes.
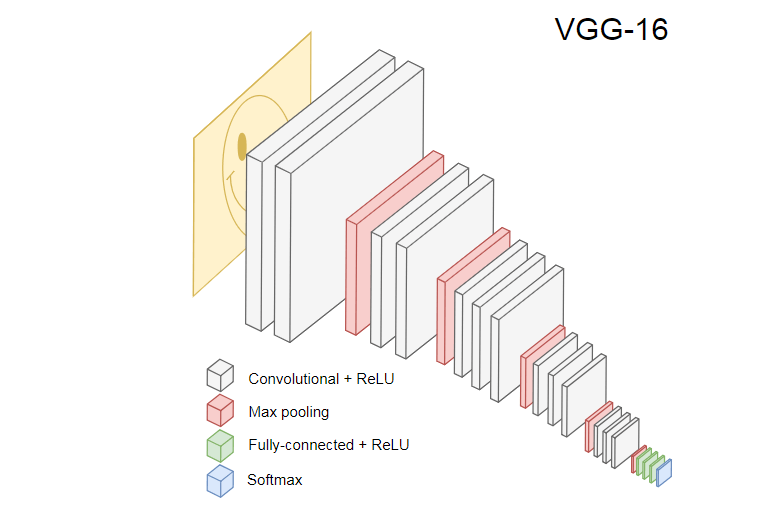
La red neuronal VGG-16 reconoce 1000 clases de imágenes. Tiene 16 capas (sin contar las capas de agrupación y salida). Tal red multicapa es difícil de entrenar en la práctica. Esto requerirá un gran conjunto de datos y muchas horas de capacitación.
Las capas ocultas de CNN entrenado reconocen varios elementos de imágenes del conjunto de entrenamiento, comenzando desde los bordes, pasando a elementos más complejos, como formas, objetos individuales, etc. Una CNN entrenada al estilo de VGG-16 para reconocer un gran conjunto de imágenes debe tener capas ocultas que hayan aprendido muchas características del conjunto de capacitación. Dichas características serán comunes a la mayoría de las imágenes y, en consecuencia, se reutilizarán en diferentes tareas.
La transferencia de aprendizaje le permite reutilizar una red existente y capacitada. Podemos tomar la salida de cualquiera de las capas de la red existente y transferirla como entrada a la nueva red neuronal. Por lo tanto, al enseñar la red neuronal recién creada, con el tiempo se puede enseñar a reconocer nuevas características de un nivel superior y clasificar correctamente las imágenes de clases que el modelo original nunca había visto antes.
Para nuestros propósitos, tome la red neuronal
MobileNet del paquete @ tensorflow-models / mobilenet . MobileNet es tan poderoso como VGG-16, pero es mucho más pequeño, lo que acelera la distribución directa, es decir, la propagación de red (propagación directa) y reduce el tiempo de descarga en el navegador. MobileNet se capacitó en el
conjunto de datos de clasificación de imágenes
ILSVRC-2012-CLS .
Al desarrollar un modelo con una transferencia de aprendizaje, tenemos dos opciones:
- La salida de qué capa del modelo de origen usar como entrada para el modelo de destino.
- ¿Cuántas capas del modelo de destino vamos a entrenar, si hay alguna?
El primer punto es muy significativo. Dependiendo de la capa seleccionada, obtendremos características en un nivel de abstracción más bajo o más alto como entrada a nuestra red neuronal.
No vamos a entrenar ninguna capa de MobileNet.
global_average_pooling2d_1 salida de
global_average_pooling2d_1 y la pasamos como entrada a nuestro pequeño modelo. ¿Por qué elegí esta capa en particular? Empíricamente Hice algunas pruebas, y esta capa funciona bastante bien.
Definición del modelo
La tarea inicial era clasificar la imagen en tres clases: mano, pie y otros movimientos. Primero, solucionemos el problema más pequeño: determinaremos si hay un golpe de mano en el marco o no. Este es un problema típico de clasificación binaria. Para este propósito, podemos definir el siguiente modelo:
import * as tf from '@tensorflow/tfjs'; const model = tf.sequential(); model.add(tf.layers.inputLayer({ inputShape: [1024] })); model.add(tf.layers.dense({ units: 1024, activation: 'relu' })); model.add(tf.layers.dense({ units: 1, activation: 'sigmoid' })); model.compile({ optimizer: tf.train.adam(1e-6), loss: tf.losses.sigmoidCrossEntropy, metrics: ['accuracy'] });
Dicho código define un modelo simple, una capa con
1024 unidades y activación
ReLU , así como una unidad de salida que pasa a través de la
sigmoid activación
sigmoid . Este último da un número de
0 a
1 , dependiendo de la probabilidad de un golpe de mano en este cuadro.
¿Por qué elegí
1024 unidades para el segundo nivel y una velocidad de entrenamiento de
1e-6 ? Bueno, probé varias opciones diferentes y vi que esas opciones funcionan mejor. El Método Spear no parece ser el mejor enfoque, pero en gran medida así es cómo funcionan los ajustes de hiperparámetros en el aprendizaje profundo: en función de nuestra comprensión del modelo, utilizamos la intuición para actualizar los parámetros ortogonales y verificar empíricamente cómo funciona el modelo.
El método de
compile compila las capas juntas, preparando el modelo para capacitación y evaluación. Aquí anunciamos que queremos usar el algoritmo de optimización de
adam . También declaramos que calcularemos la pérdida (pérdida) a partir de la entropía cruzada, e indicamos que queremos evaluar la precisión del modelo. TensorFlow.js luego calcula la precisión utilizando la fórmula:
Accuracy = (True Positives + True Negatives) / (Positives + Negatives)Si transfiere el entrenamiento desde el modelo original de MobileNet, primero debe descargarlo. Como no es práctico entrenar nuestro modelo en más de 3,000 imágenes en un navegador, usaremos Node.js y cargaremos la red neuronal desde el archivo.
Descargue MobileNet
aquí . El catálogo contiene el archivo
model.json , que contiene la arquitectura del modelo: capas, activaciones, etc. Los archivos restantes contienen parámetros del modelo. Puede cargar el modelo desde un archivo usando este código:
export const loadModel = async () => { const mn = new mobilenet.MobileNet(1, 1); mn.path = `file://PATH/TO/model.json`; await mn.load(); return (input): tf.Tensor1D => mn.infer(input, 'global_average_pooling2d_1') .reshape([1024]); };
Tenga en cuenta que en el método
loadModel devolvemos una función que acepta un tensor unidimensional como entrada y devuelve
mn.infer(input, Layer) . El método
infer toma un tensor y una capa como argumentos. La capa determina de qué capa oculta queremos la salida. Si abre
model.json y
global_average_pooling2d_1 , encontrará dicho nombre en una de las capas.
Ahora necesita crear un conjunto de datos para entrenar el modelo. Para hacer esto, debemos pasar todas las imágenes a través del método
infer en MobileNet y asignarles etiquetas:
1 para imágenes con trazos y
0 para imágenes sin trazos:
const punches = require('fs') .readdirSync(Punches) .filter(f => f.endsWith('.jpg')) .map(f => `${Punches}/${f}`); const others = require('fs') .readdirSync(Others) .filter(f => f.endsWith('.jpg')) .map(f => `${Others}/${f}`); const ys = tf.tensor1d( new Array(punches.length).fill(1) .concat(new Array(others.length).fill(0))); const xs: tf.Tensor2D = tf.stack( punches .map((path: string) => mobileNet(readInput(path))) .concat(others.map((path: string) => mobileNet(readInput(path)))) ) as tf.Tensor2D;
En el código anterior, primero leemos los archivos en directorios con y sin aciertos. Luego determinamos el tensor unidimensional que contiene las etiquetas de salida. Si tenemos
n imágenes con trazos
m otras imágenes, el tensor tendrá
n elementos con un valor de 1
m elementos con un valor de 0.
En
xs infer resultados de llamar al método
infer para imágenes individuales. Tenga en cuenta que para cada imagen, llamamos al método
readInput . Aquí está su implementación:
export const readInput = img => imageToInput(readImage(img), TotalChannels); const readImage = path => jpeg.decode(fs.readFileSync(path), true); const imageToInput = image => { const values = serializeImage(image); return tf.tensor3d(values, [image.height, image.width, 3], 'int32'); }; const serializeImage = image => { const totalPixels = image.width * image.height; const result = new Int32Array(totalPixels * 3); for (let i = 0; i < totalPixels; i++) { result[i * 3 + 0] = image.data[i * 4 + 0]; result[i * 3 + 1] = image.data[i * 4 + 1]; result[i * 3 + 2] = image.data[i * 4 + 2]; } return result; };
readInput primero llama a la función
readImage , y luego delega su llamada a
imageToInput . La función
readImage lee una imagen del disco y luego decodifica jpg del búfer utilizando el paquete
jpeg-js . En
imageToInput convertimos la imagen en un tensor tridimensional.
Como resultado, para cada
i de
0 a
TotalImages debería ser
ys[i] igual a
1 si
xs[i] corresponde a la imagen con un hit, y
0 caso contrario.
Entrenamiento modelo
¡Ahora el modelo está listo para entrenar! Llame al método de
fit :
await model.fit(xs, ys, { epochs: Epochs, batchSize: parseInt(((punches.length + others.length) * BatchSize).toFixed(0)), callbacks: { onBatchEnd: async (_, logs) => { console.log('Cost: %s, accuracy: %s', logs.loss.toFixed(5), logs.acc.toFixed(5)); await tf.nextFrame(); } } });
Las llamadas de código anteriores se
fit a tres argumentos:
xs , ys y el objeto de configuración. En el objeto de configuración, establecemos cuántas eras se entrenará el modelo, el tamaño del paquete y la devolución de llamada que generará TensorFlow.js después de procesar cada paquete.
El tamaño del paquete determina
xs e
ys para entrenar al modelo en una era. Para cada era, TensorFlow.js seleccionará un subconjunto de
xs y los elementos correspondientes de
ys , realizará una distribución directa, recibirá la salida de la capa con activación
sigmoid y luego, basándose en la pérdida, realizará la optimización utilizando el algoritmo de
adam .
Después de comenzar la secuencia de comandos de entrenamiento, verá un resultado similar al siguiente:
Costo: 0.84212, precisión: 1.00000
eta = 0.3> ---------- acc = 1.00 pérdida = 0.84 Costo: 0.79740, precisión: 1.00000
eta = 0.2 => --------- acc = 1.00 pérdida = 0.80 Costo: 0.81533, precisión: 1.00000
eta = 0.2 ==> -------- acc = 1.00 pérdida = 0.82 Costo: 0.64303, precisión: 0.50000
eta = 0.2 ===> ------- acc = 0.50 pérdida = 0.64 Costo: 0.51377, precisión: 0.00000
eta = 0.2 ====> ------ acc = 0.00 pérdida = 0.51 Costo: 0.46473, precisión: 0.50000
eta = 0.1 =====> ----- acc = 0.50 pérdida = 0.46 Costo: 0.50872, precisión: 0.00000
eta = 0.1 ======> ---- acc = 0.00 pérdida = 0.51 Costo: 0.62556, precisión: 1.00000
eta = 0.1 =======> --- acc = 1.00 pérdida = 0.63 Costo: 0.65133, precisión: 0.50000
eta = 0.1 ========> - acc = 0.50 pérdida = 0.65 Costo: 0.63824, precisión: 0.50000
eta = 0.0 ===========>
293 ms 14675us / paso - acc = 0,60 pérdida = 0,65
Época 3/50
Costo: 0.44661, precisión: 1.00000
eta = 0.3> ---------- acc = 1.00 pérdida = 0.45 Costo: 0.78060, precisión: 1.00000
eta = 0.3 => --------- acc = 1.00 pérdida = 0.78 Costo: 0.79208, precisión: 1.00000
eta = 0.3 ==> -------- acc = 1.00 pérdida = 0.79 Costo: 0.49072, precisión: 0.50000
eta = 0.2 ===> ------- acc = 0.50 pérdida = 0.49 Costo: 0.62232, precisión: 1.00000
eta = 0.2 ====> ------ acc = 1.00 pérdida = 0.62 Costo: 0.82899, precisión: 1.00000
eta = 0.2 =====> ----- acc = 1.00 pérdida = 0.83 Costo: 0.67629, precisión: 0.50000
eta = 0.1 ======> ---- acc = 0.50 pérdida = 0.68 Costo: 0.62621, precisión: 0.50000
eta = 0.1 =======> --- acc = 0.50 pérdida = 0.63 Costo: 0.46077, precisión: 1.00000
eta = 0.1 ========> - acc = 1.00 pérdida = 0.46 Costo: 0.62076, precisión: 1.00000
eta = 0.0 ===========>
304ms 15221us / paso - acc = 0.85 pérdida = 0.63
Observe cómo la precisión aumenta con el tiempo y la pérdida disminuye.
En mi conjunto de datos, el modelo después del entrenamiento mostró una precisión del 92%. Tenga en cuenta que la precisión puede no ser muy alta debido al pequeño conjunto de datos de entrenamiento.
Ejecutando el modelo en un navegador
En la sección anterior, entrenamos el modelo de clasificación binaria. ¡Ahora ejecútelo en un navegador y conéctese a
MK.js !
const video = document.getElementById('cam'); const Layer = 'global_average_pooling2d_1'; const mobilenetInfer = m => (p): tf.Tensor<tf.Rank> => m.infer(p, Layer); const canvas = document.getElementById('canvas'); const scale = document.getElementById('crop'); const ImageSize = { Width: 100, Height: 56 }; navigator.mediaDevices .getUserMedia({ video: true, audio: false }) .then(stream => { video.srcObject = stream; });
Hay varias declaraciones en el código anterior:
video contiene un enlace al elemento de HTML5 video en la páginaLayer contiene el nombre de la capa de MobileNet de la que queremos obtener la salida y pasarla como entrada para nuestro modelomobilenetInfer- una función que toma una instancia de MobileNet y devuelve otra función. La función devuelta acepta la entrada y devuelve la salida correspondiente de la capa MobileNet especificada.canvasindica el elemento HTML5 canvasque usaremos para extraer fotogramas del videoscale- otro canvasque se usa para escalar cuadros individuales
Después de eso, obtenemos la transmisión de video de la cámara del usuario y la configuramos como la fuente del elemento video.El siguiente paso es implementar un filtro de escala de grises que acepte canvasy convierta su contenido: const grayscale = (canvas: HTMLCanvasElement) => { const imageData = canvas.getContext('2d').getImageData(0, 0, canvas.width, canvas.height); const data = imageData.data; for (let i = 0; i < data.length; i += 4) { const avg = (data[i] + data[i + 1] + data[i + 2]) / 3; data[i] = avg; data[i + 1] = avg; data[i + 2] = avg; } canvas.getContext('2d').putImageData(imageData, 0, 0); };
Como siguiente paso, conectaremos el modelo con MK.js: let mobilenet: (p: any) => tf.Tensor<tf.Rank>; tf.loadModel('http://localhost:5000/model.json').then(model => { mobileNet .load() .then((mn: any) => mobilenet = mobilenetInfer(mn)) .then(startInterval(mobilenet, model)); });
En el código anterior, primero cargamos el modelo que hemos entrenado anteriormente y luego descargamos MobileNet. Pasamos MobileNet al método mobilenetInferpara calcular la salida de la capa de red oculta. Después de eso, llamamos al método startIntervalcon dos redes como argumentos. const startInterval = (mobilenet, model) => () => { setInterval(() => { canvas.getContext('2d').drawImage(video, 0, 0); grayscale(scale .getContext('2d') .drawImage( canvas, 0, 0, canvas.width, canvas.width / (ImageSize.Width / ImageSize.Height), 0, 0, ImageSize.Width, ImageSize.Height )); const [punching] = Array.from(( model.predict(mobilenet(tf.fromPixels(scale))) as tf.Tensor1D) .dataSync() as Float32Array); const detect = (window as any).Detect; if (punching >= 0.4) detect && detect.onPunch(); }, 100); };
¡La parte más interesante comienza en el método startInterval! Primero, ejecutamos un intervalo donde todos 100msllaman a una función anónima. En él, el canvasvideo con el cuadro actual se muestra primero encima . Luego reducimos el tamaño del marco 100x56y le aplicamos un filtro de escala de grises.El siguiente paso es transferir el marco a MobileNet, obtener el resultado de la capa oculta deseada y transferirlo como entrada al método de predictnuestro modelo. Eso devuelve un tensor con un elemento. Usando, dataSyncobtenemos el valor del tensor y lo asignamos a una constante punching.Finalmente, verificamos: si la probabilidad de un golpe de mano excede 0.4, entonces llamamos al método de onPunchobjeto global Detect. MK.js proporciona un objeto global con tres métodos:onKick, onPunchy onStandque podemos usar para controlar uno de los personajes.Hecho
Aquí está el resultado!
Reconocimiento de patadas y brazos con clasificación N
En la siguiente sección, crearemos un modelo más inteligente: una red neuronal que reconoce golpes, patadas y otras imágenes. Esta vez, comencemos preparando el conjunto de entrenamiento: const punches = require('fs') .readdirSync(Punches) .filter(f => f.endsWith('.jpg')) .map(f => `${Punches}/${f}`); const kicks = require('fs') .readdirSync(Kicks) .filter(f => f.endsWith('.jpg')) .map(f => `${Kicks}/${f}`); const others = require('fs') .readdirSync(Others) .filter(f => f.endsWith('.jpg')) .map(f => `${Others}/${f}`); const ys = tf.tensor2d( new Array(punches.length) .fill([1, 0, 0]) .concat(new Array(kicks.length).fill([0, 1, 0])) .concat(new Array(others.length).fill([0, 0, 1])), [punches.length + kicks.length + others.length, 3] ); const xs: tf.Tensor2D = tf.stack( punches .map((path: string) => mobileNet(readInput(path))) .concat(kicks.map((path: string) => mobileNet(readInput(path)))) .concat(others.map((path: string) => mobileNet(readInput(path)))) ) as tf.Tensor2D;
Como antes, primero leemos los catálogos con imágenes de golpes a mano, pies y otras imágenes. Después de esto, a diferencia de la última vez, formamos el resultado esperado en forma de un tensor bidimensional, y no unidimensional. Si tenemos n imágenes con una patada, m imágenes con una patada yk otras imágenes, entonces el tensor ystendrá nelementos con un valor [1, 0, 0], melementos con un valor [0, 1, 0]y kelementos con un valor [0, 0, 1].Un vector de nelementos en el que hay n - 1elementos con un valor 0y un elemento con un valor 1, lo llamamos un vector unitario (vector de un solo hot).Después de eso, formamos el tensor de entradaxsapilando la salida de cada imagen de MobileNet.Aquí debe actualizar la definición del modelo: const model = tf.sequential(); model.add(tf.layers.inputLayer({ inputShape: [1024] })); model.add(tf.layers.dense({ units: 1024, activation: 'relu' })); model.add(tf.layers.dense({ units: 3, activation: 'softmax' })); await model.compile({ optimizer: tf.train.adam(1e-6), loss: tf.losses.sigmoidCrossEntropy, metrics: ['accuracy'] });
Las únicas dos diferencias con respecto al modelo anterior son:- El número de unidades en la capa de salida.
- Activaciones en la capa de salida
Hay tres unidades en la capa de salida, porque tenemos tres categorías diferentes de imágenes:La activación se activa en estas tres unidades softmax, que convierte sus parámetros en un tensor con tres valores. ¿Por qué tres unidades para la capa de salida? Cada uno de los tres valores para tres clases puede ser representado por dos bits: 00, 01, 10. La suma de los valores del tensor creado softmaxes 1, es decir, nunca obtendremos 00, por lo que no podremos clasificar imágenes de una de las clases.Después de entrenar al modelo a lo largo de los 500años, ¡logré una precisión de aproximadamente el 92%! Esto no está mal, pero no olvide que la capacitación se realizó en un pequeño conjunto de datos.¡El siguiente paso es ejecutar el modelo en un navegador! Dado que la lógica es muy similar a ejecutar el modelo para clasificación binaria, eche un vistazo al último paso, donde la acción se selecciona en función de la salida del modelo: const [punch, kick, nothing] = Array.from((model.predict( mobilenet(tf.fromPixels(scaled)) ) as tf.Tensor1D).dataSync() as Float32Array); const detect = (window as any).Detect; if (nothing >= 0.4) return; if (kick > punch && kick >= 0.35) { detect.onKick(); return; } if (punch > kick && punch >= 0.35) detect.onPunch();
Primero llamamos a MobileNet con un marco reducido en tonos de gris, luego transferimos el resultado de nuestro modelo entrenado. El modelo devuelve un tensor unidimensional, que convertimos a Float32Arrayc dataSync. En el siguiente paso, usamos Array.frompara convertir una matriz escrita en una matriz de JavaScript. Luego extraemos las probabilidades de que un disparo con una mano, una patada o nada esté presente en el cuadro.Si la probabilidad del tercer resultado excede 0.4, regresamos. De lo contrario, si la probabilidad de una patada es mayor 0.32, enviamos un comando de patada a MK.js. Si la probabilidad de una patada es mayor 0.32y mayor que la probabilidad de una patada, entonces enviamos la acción de una patada.En general, eso es todo! El resultado se muestra a continuación:
Reconocimiento de la acción
Si recopila un conjunto de datos amplio y variado sobre personas que golpean con las manos y los pies, puede construir un modelo que funcione muy bien en cuadros individuales. ¿Pero es eso suficiente? ¿Qué pasa si queremos ir aún más lejos y distinguir dos tipos diferentes de patadas: desde un giro y desde un retroceso (retroceso).Como se puede ver en los cuadros a continuación, en un cierto punto en el tiempo desde un ángulo determinado, ambos trazos se ven iguales:
 Pero si observa el rendimiento, los movimientos son completamente diferentes:
Pero si observa el rendimiento, los movimientos son completamente diferentes: ¿cómo puede entrenar una red neuronal para analizar la secuencia de cuadros, y no solo un cuadro?Para este propósito, podemos explorar otra clase de redes neuronales, llamadas redes neuronales recurrentes (RNN). Por ejemplo, los RNN son excelentes para trabajar con series de tiempo:
¿cómo puede entrenar una red neuronal para analizar la secuencia de cuadros, y no solo un cuadro?Para este propósito, podemos explorar otra clase de redes neuronales, llamadas redes neuronales recurrentes (RNN). Por ejemplo, los RNN son excelentes para trabajar con series de tiempo:- Procesamiento del lenguaje natural (PNL), donde cada palabra depende de anteriores y posteriores
- Predecir la página siguiente en función de su historial de navegación
- Reconocimiento de cuadros
La implementación de dicho modelo está más allá del alcance de este artículo, pero veamos una arquitectura de ejemplo para tener una idea de cómo funcionará todo esto en conjunto.El poder de RNN
El siguiente diagrama muestra el modelo de reconocimiento de acciones: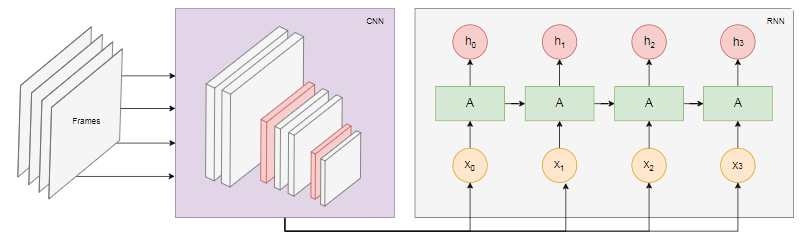 tomamos los últimos
tomamos los últimos ncuadros del video y los transferimos a CNN. La salida CNN para cada trama se transmite como entrada RNN. Una red neuronal recurrente determinará las relaciones entre cuadros individuales y reconocerá a qué acción corresponden.Conclusión
En este artículo, desarrollamos un modelo de clasificación de imágenes. Para este propósito, recopilamos un conjunto de datos: extrajimos cuadros de video y los dividimos manualmente en tres categorías. Luego, los datos se aumentaron agregando imágenes usando imgaug .Después de eso, explicamos qué es la transferencia de aprendizaje y utilizamos el modelo capacitado de MobileNet del paquete @ tensorflow-models / mobilenet para nuestros propios fines . Descargamos MobileNet de un archivo en el proceso Node.js y capacitamos a una capa densa adicional donde los datos se alimentaron desde la capa oculta de MobileNet. ¡Después del entrenamiento, logramos una precisión de más del 90%!Para usar este modelo en un navegador, lo descargamos junto con MobileNet y comenzamos a categorizar marcos de la cámara web del usuario cada 100 ms. Conectamos el modelo con el juego.MK.js y utilizó la salida del modelo para controlar uno de los caracteres.Finalmente, vimos cómo mejorar el modelo combinándolo con una red neuronal recurrente para reconocer acciones.¡Espero que hayas disfrutado este pequeño proyecto no menos que yo!