Mi nombre es Andrey Polyakov, soy el jefe del grupo de documentación API y SDK en Yandex. Hoy me gustaría compartir con ustedes un informe que yo y mi colega, la desarrolladora senior de documentación Julia Pivovarova, leímos hace unas semanas en el sexto Hyperbaton.
Svetlana Kayushina, jefa del departamento de documentación y localización:
- Los volúmenes de código de programa en el mundo en los últimos años han crecido significativamente, continúan creciendo, y esto afecta el trabajo de los escritores técnicos, que se enfrentan a más y más tareas en el desarrollo de documentación de programas y documentación de código. No pudimos ignorar este tema, le dedicamos una sección completa. Estos son tres informes relacionados sobre la unificación del desarrollo de software. Invito a nuestros especialistas en documentación de interfaces y bibliotecas de software a Andrei Polyakov y Julia Pivovarova. Les doy la palabra.
- Hola a todos! Hoy, Julia y yo te diremos cómo en Yandex obtuvimos una nueva visión de la documentación de la API y el SDK. El informe constará de cuatro partes, el informe del reloj, lo discutiremos, hablaremos.
Hablemos sobre la unificación de la API y el SDK, cómo llegamos a ella, qué hicimos allí. Compartiremos la experiencia de usar un generador universal, uno para todos los idiomas, y le diremos por qué no nos conviene, cuáles fueron las trampas y por qué cambiamos a la generación de documentación por parte de generadores nativos.
Al final, describiremos cómo se construyeron nuestros procesos.
Comencemos con la unificación. Todos piensan en la unificación cuando hay más de dos personas en un equipo: todos escriben de manera diferente, todos tienen sus propios enfoques, y esto es lógico. Es mejor discutir todas las reglas en la playa antes de comenzar a escribir documentación, pero no todos pueden hacerlo.
Reunimos un grupo de expertos para analizar nuestra documentación. Hicimos esto para sistematizar nuestros enfoques. Todos escriben de diferentes maneras, y aceptemos escribir en el mismo estilo. Este es el segundo punto, para el que íbamos a tratar de uniformar la documentación, de modo que el usuario tuviera una experiencia de usuario en toda la documentación de Yandex, es decir, técnica.
El trabajo se dividió en tres etapas. Hemos recopilado una descripción de las tecnologías que utilizamos en Yandex, tratamos de identificar aquellas que de alguna manera podemos unificar. Y también formó la estructura general de documentos y plantillas estándar.

Pasemos a la descripción de las tecnologías. Comenzamos a estudiar qué tecnologías se usan en Yandex. Hay tantos de ellos que estamos cansados de escribirlos en algún tipo de cuaderno, y como resultado, seleccionamos solo los más básicos que se usan con mayor frecuencia, que los escritores técnicos encuentran con mayor frecuencia, y comenzamos a describirlos.
¿Qué se entiende por descripción tecnológica? Hemos identificado los puntos principales y la esencia de cada tecnología. Si hablamos de lenguajes de programación, entonces esta es una descripción de entidades como una clase, propiedad, interfaces, etc. Si hablamos de protocolos, luego describimos métodos HTTP, hablamos del formato del código de error, código de respuesta, etc. Un glosario que contiene lo siguiente: términos en ruso, términos en inglés, matices de uso. Por ejemplo, no estamos hablando de ningún método SDK, que le permita hacer algo. HACE algo, si el programador saca un bolígrafo, da alguna respuesta.
Además de los matices, la descripción también contenía estructuras estándar, giros de discurso estándar, que usamos en la documentación para que el escritor técnico pueda tomar una redacción específica y usarla más.
Además, los escritores técnicos a menudo escriben fragmentos de código, fragmentos, muestras, y para esto también describimos nuestra guía de estilo para cada tecnología. Nos dirigimos a las guías para desarrolladores que se encuentran en Yandex. Prestamos atención al código de diseño, la descripción de los comentarios, la sangría y todo eso. Hacemos esto para que cuando un escritor técnico venga con un fragmento de código o una muestra escrita a un programador, el programador observe la esencia, y no cómo está diseñado, y esto reduce el tiempo. Y cuando un escritor técnico puede escribir en las guías de estilo Yandex, es genial, tal vez quiera convertirse en programador más tarde. El informe anterior trataba sobre varios exámenes. Por ejemplo, puede pasar a los programadores.
También desarrollamos un inicio rápido para los escritores de tecnología: cómo configurar un entorno de desarrollo cuando se familiarice con las nuevas tecnologías. Por ejemplo, si el SDK de escritor técnico está escrito en C #, entonces él viene, configura el entorno de desarrollo, lee los manuales y se familiariza con la terminología. También dejamos enlaces a documentación oficial y RFC, si corresponde. Hicimos un punto de entrada para escritores técnicos, y se parece a esto.
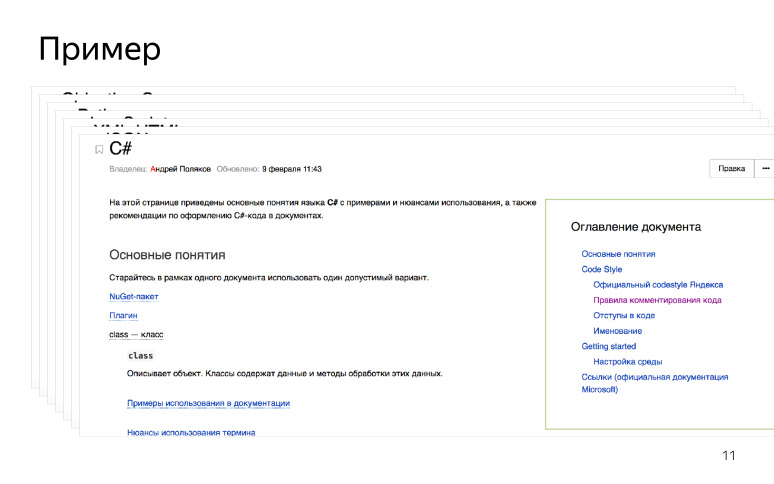
Cuando llega un escritor técnico, aprende una nueva tecnología y comienza a documentarla.
Después de describir las tecnologías, pasamos a describir la estructura de la API HTTP.
Tenemos muchas API HTTP diferentes, y todas se describen de manera diferente. ¡Hagamos un acuerdo y hagamos lo mismo!
Hemos identificado las secciones principales que estarán en cada API HTTP:

"Descripción general" o "Introducción": por qué se necesita esta API, qué le permite hacer, a qué host se debe acceder para obtener algún tipo de respuesta.
"Inicio rápido" cuando una persona realiza algunos pasos y obtiene un resultado exitoso al final para comprender cómo funciona esta API.
"Conexión / Autorización". Muchas API requieren un token de autorización o una clave API. Este es un punto importante, por lo que decidimos que es una parte obligatoria de todas las API.
“Limitaciones / límites” cuando hablamos de límites en el número de solicitudes o en el tamaño del cuerpo de la solicitud, etc.
"Referencia", referencia. Una parte muy grande, que contiene todos los identificadores HTTP que el usuario puede extraer y obtener algún tipo de resultado.
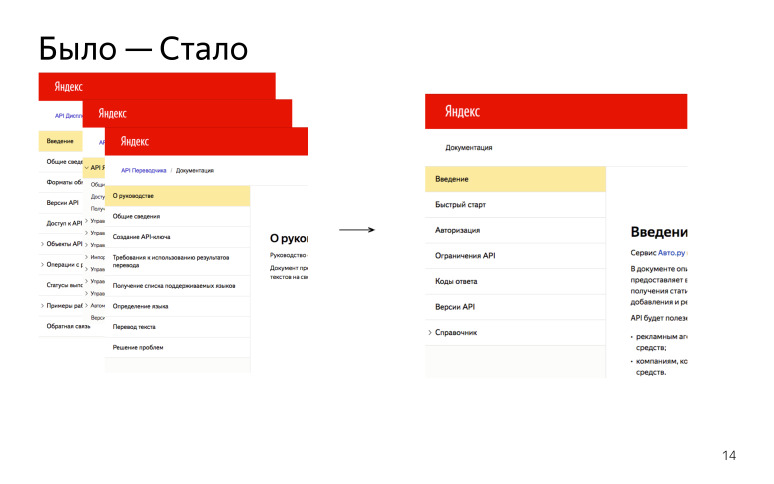
Como resultado, teníamos muchas API diferentes, se describían de manera diferente, ahora intentamos escribir todo de la misma manera. Tal ganancia.
Profundizando en los directorios, nos dimos cuenta de que el identificador HTTP es casi siempre el mismo. Lo sacas, es decir, haces una solicitud, el servidor devuelve una respuesta: voila. Tratemos de unificarlo. Escribimos una plantilla que trató de cubrir todos los casos. El escritor técnico toma la plantilla, y si tiene una solicitud PUT, deja las partes necesarias en la plantilla. Si tiene una solicitud GET, usa solo aquellas partes que son necesarias para la solicitud GET. Una plantilla común para todas las solicitudes que se pueden reutilizar. Ahora no necesita crear una estructura de documento desde cero, pero puede simplemente tomar una plantilla preparada.

Cada pluma describe para qué sirve, para qué sirve. Hay una sección "Formato de solicitud", que contiene parámetros de ruta, parámetros de consulta, todo lo que viene en el cuerpo de la solicitud si se envía. También destacamos la sección "Formato de respuesta": la escribimos si hay un cuerpo de respuesta. Como una sección separada, destacamos "Códigos de respuesta", porque la respuesta del servidor viene independientemente del cuerpo. Y salió de la sección "Ejemplo". Si suministramos algún tipo de SDK con esta API, entonces decimos que use este SDK de esta manera, extraiga dicho identificador, llame a dicho método. Por lo general, dejamos algún tipo de ejemplo de cURL donde el usuario simplemente inserta su token. Y si tenemos un banco de pruebas, solo toma la solicitud y la ejecuta. Y obtiene algún tipo de resultado.

Resulta que había muchos bolígrafos, se describieron de diferentes maneras, y ahora queremos llevarlo todo a una sola forma.
Después de que terminamos con la API HTTP, pasamos al SDK móvil.
Hay una estructura de documento general, es aproximadamente la misma:
- "Introducción", donde decimos que, aquí, este SDK se utiliza para tales fines, integrelo usted mismo para tales fines, es adecuado para dichos sistemas operativos, tenemos tales y tales versiones, etc.
- "Conexión". A diferencia de la API HTTP, no solo estamos hablando de cómo obtener la clave para usar el SDK, si lo necesita, estamos hablando de cómo integrar la biblioteca en nuestro proyecto.
- "Ejemplos de uso". La sección de mayor volumen. En la mayoría de los casos, los desarrolladores quieren llegar a la documentación y no leer mucha información, quieren copiar una pieza, pegarla en sí mismos y todo funcionará para ellos. Por lo tanto, consideramos que esta parte es muy importante y la asignamos a la sección obligatoria.

- "Directorio", referencia, pero a diferencia de la referencia API HTTP, no podemos unificar todo aquí, ya que principalmente generamos directorios y hablaremos de esto más adelante en el informe.
- "Lanzamientos" o historial de cambios, registro de cambios. Los SDK para dispositivos móviles generalmente tienen un ciclo de lanzamiento corto, se lanza una nueva versión cada dos semanas. Y sería mejor para el usuario hablar sobre lo que ha cambiado, valga la pena actualizarlo o no.
Al mismo tiempo, la API tiene las secciones requeridas que vemos y las secciones que recomendamos usar. Si la API se actualiza con frecuencia, decimos que luego inserte también el historial de cambios, que ha cambiado en la API. Y a menudo nuestras API rara vez se actualizan, y no tiene sentido indicar esto como una sección obligatoria.

Entonces, teníamos muchos SDK que se describían de diferentes maneras, tratamos de convertirlos en aproximadamente el mismo estilo. Naturalmente, hay diferencias adicionales inherentes solo a este SDK o esta API HTTP. Aquí tenemos la libertad de elección. No estamos diciendo que, aparte de estas secciones, nadie pueda hacerse. Por supuesto, es posible, simplemente tratamos de hacer las secciones enumeradas en todas partes para que quede claro que si el usuario cambió a otro SDK en la documentación, él sabe lo que se describirá en la sección "Conexión".
Entonces, ideamos plantillas, guías inventadas, ¿cuál es nuestro plan de acción ahora? Decidimos que si escalamos la API, cambiamos las plumas o cambiamos el SDK, tomamos nuevas plantillas, tomamos una nueva estructura y comenzamos a trabajar en ella.
Si escribimos documentación desde cero, entonces, por supuesto, nuevamente tomamos una nueva estructura, tomamos nuevas plantillas y trabajamos en ellas.
Y si la API está desactualizada, rara vez se actualiza o si nadie la admite, pero existe, rehaga un poco de recursos. Simplemente decidimos dejarlo hasta que fuera así, pero luego, cuando aparezcan los recursos, definitivamente volveremos a ellos, haremos todo esto bien y de manera hermosa.
¿Cuáles son los beneficios de la unificación? Deberían ser obvios para todos:
"UX", estamos pensando en hacer que el usuario se sienta como en casa en nuestra documentación. Vino, y sabe lo que se describe en las secciones donde puede encontrar autorización, ejemplos de uso, descripción de la pluma. Esto es genial
Para los escritores de tecnología, la descripción de la tecnología le permite determinar un cierto punto de entrada de dónde viene, y comienza a familiarizarse con esta tecnología, si no la conoce, comienza a comprender la terminología, sumergirse en ella.
El siguiente punto es la intercambiabilidad. Si el escritor técnico se fue de vacaciones o simplemente dejó de escribir, entonces otro escritor técnico, al ingresar el documento, sabe cómo funciona dentro. De inmediato queda claro lo que se describe en la conexión, dónde buscar información sobre la integración del SDK. Comprender y hacer una pequeña revisión de un documento se vuelve más fácil. Está claro que cada proyecto tiene sus propios detalles, no puede venir y documentar algún proyecto sin saberlo completamente. Pero al mismo tiempo, la estructura, es decir, la navegación de archivos, será aproximadamente la misma.
Y, por supuesto, terminología general. Esa terminología que compilamos para los idiomas, la acordamos con los desarrolladores y traductores. Decimos que tenemos C #, existe ese término, lo usamos de esa manera. Les preguntamos a los desarrolladores qué terminología usaron y quisimos lograr la sincronización en este lugar. Tenemos acuerdos, y la próxima vez que vengamos con la documentación, los desarrolladores saben que hemos acordado los términos y guías con ellos, usamos estas plantillas y tenemos en cuenta los matices de su uso. Y los traductores, a su vez, saben que describimos el SDK en C # u Objective-C, por lo que esta terminología corresponderá a lo que se describe en la guía.
Las guías se escribieron en páginas wiki, por lo que si se actualizan idiomas, tecnologías y protocolos, todo esto se agrega fácilmente a un documento existente. Idilio
Cuanto antes comiences a unificarte y estar de acuerdo, mejor. Es mejor que no haya un legado de documentación, que esté escrito en un estilo diferente, que interrumpa el flujo del usuario en la documentación. Mejor hacerlo todo antes.
Atraer desarrolladores. Estas son las personas para quienes está escribiendo documentación. Si usted mismo escribió algún tipo de guía, quizás no les guste. Es mejor estar de acuerdo con ellos para que tenga una comprensión común de la terminología: lo que escribe en la documentación, cómo lo escribe.
Y también negociar con traductores, todos tienen que traducirlo. Si traducen de manera diferente a la que los desarrolladores están acostumbrados, nuevamente habrá conflictos. (
Aquí hay un enlace a un fragmento de video con preguntas y respuestas - aprox. Ed.) Seguimos adelante.
Julia
- Hola, me llamo Julia, llevo cinco años trabajando en Yandex y estoy documentando la API y el SDK en el grupo de Andrey. Por lo general, todo el mundo habla de una buena experiencia, de lo buena que es. Te diré cómo elegimos una estrategia no del todo exitosa. En ese momento, parecía exitoso, pero luego llegó una dura realidad, y tuvimos un poco de mala suerte.
Inicialmente teníamos varios SDK móviles, y estaban escritos principalmente en dos lenguajes: Objective-C y Java. Les escribimos documentación manualmente. Con el tiempo, las clases, protocolos e interfaces crecieron. Había más y más de ellos, y nos dimos cuenta de que necesitábamos automatizar este negocio, observamos qué son las tecnologías.
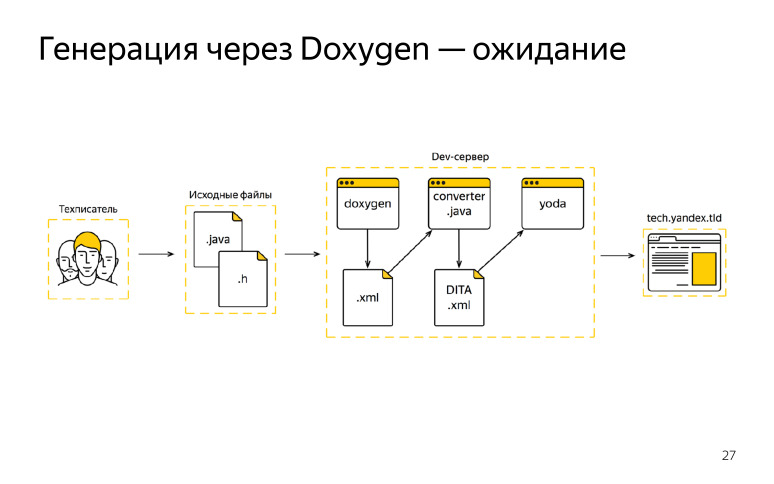
En ese momento, nos gustó Doxygen, satisfizo nuestras necesidades, como nos pareció, y lo elegimos como un generador único. Y dibujamos tal esquema, que esperábamos obtener, queríamos trabajar en ello de alguna manera.
Que tuvimos El escritor técnico vino a trabajar, recibió el código fuente del desarrollador, comenzó a escribir sus comentarios, ediciones, después de eso la documentación tuvo que enviarse a nuestro servidor de servidores, allí ejecutamos Doxygen, recibimos el formato XML, pero no se ajustaba a nuestro estándar DITA XML. Sabíamos de esto de antemano, escribió un cierto convertidor.
Después de obtener el resultado de Doxygen, lo pasamos todo a través del convertidor y ya obtuvimos nuestro formato. Luego se conectó el recopilador de documentación y publicamos todo esto en un dominio externo. Incluso tuvimos suerte un par de iteraciones, todo funcionó para nosotros, estuvimos encantados. Pero entonces algo salió mal. El escritor técnico también se puso a trabajar, recibió tareas y códigos fuente del desarrollador e hizo sus correcciones allí. Después de eso, fue al servidor del servidor, lanzó Doxygen y hubo un incendio.
Decidimos averiguar cuál era el problema. Luego nos dimos cuenta de que Doxygen no se ajusta a todos los idiomas. Tuvimos que analizar el código, en el que tropezó, encontramos construcciones que Doxygen no soportaba y no planeaba soportar.
Decidimos que, dado que estamos trabajando en este esquema, escribiremos un script de preprocesamiento y de alguna manera reemplazaremos estas construcciones con lo que acepta Doxygen, o las ignoraremos de alguna manera.

Nuestro ciclo comenzó a verse así. Recibimos las fuentes, las incluimos en el servidor del servidor, luego conectamos el script de preprocesamiento, recortamos todo el exceso del código, luego Doxygen ingresó al negocio, recibimos el formato de salida Doxygen, también lanzamos el convertidor, recibimos nuestros archivos finales DITA XML, luego se conectó el recopilador de documentación y Publicamos nuestra documentación en un dominio externo. Parece que todo se ve bien. Se agregó un script, ¿qué hay ahí arriba? Inicialmente, no había nada. Había tres líneas en el guión, luego cinco, diez líneas, y todo creció a cientos de líneas. Nos dimos cuenta de que estamos empezando a pasar la mayor parte de nuestro tiempo no escribiendo documentación, sino analizando el código, buscando lo que no rastrea dónde, y simplemente agregando el guión a clientes habituales interminables, sentados en la locura y pensando qué pasa.
Nos dimos cuenta de que necesitábamos cambiar algo, detenernos de alguna manera, antes de que fuera demasiado tarde, y hasta que nuestro ciclo de lanzamiento cayera hasta el final.
Como ejemplo, el script de preprocesamiento se parecía a algo así al principio y era inofensivo.

¿Por qué elegimos inicialmente este camino? ¿Por qué parecía bueno?

Un generador es genial, lo tomó, lo conectó una vez, lo configuró y funciona. Parecía un buen enfoque. Además, puede usar una sintaxis de comentario único para todos los idiomas a la vez. Escribiste algún tipo de guía, úsala una vez, inserta inmediatamente todas estas construcciones en el código y haz tu trabajo, escribe comentarios y no te obsesiones con la sintaxis.

Pero esto resultó ser uno de los grandes inconvenientes. Los desarrolladores no admitían nuestra sintaxis común, están acostumbrados a usar sus IDE, ya hay generadores nativos allí, y su sintaxis no coincide con la nuestra. Este fue un obstáculo.
Doxygen también soportaba mal las nuevas funciones en idiomas. Tiene un enfoque selectivo, ya que él mismo está escrito en C ++, admite principalmente lenguajes tipo C y el resto de acuerdo con el principio residual. Y se están mejorando los idiomas, Doxygen no los está siguiendo y se ha vuelto bastante inconveniente para nosotros.
Entonces sucedió una gran desgracia. Un nuevo equipo vino a nosotros y dijo que estamos escribiendo sobre Swift, y Doxygen no es amigo de él en absoluto. Nos dimos cuenta de que todo es tiempo de detenerse y encontrar algo nuevo. Luego vinieron un par de equipos más y nos dimos cuenta de que nuestro esquema no se puede escalar en absoluto. Y constantemente agregamos algo, tenemos varios de estos scripts, viven en diferentes ramas y eso es todo. Nos dimos cuenta de que debemos aceptar lo que no teníamos suerte, probar nuevos enfoques y soluciones para encontrar. Andrey te contará sobre ellos.
“Nos dimos cuenta de que en nuestro caso, en algún lugar surgió un generador universal, pero en su mayor parte, cuando comenzamos a escalarlo todo, el plan no funcionó. Se presentaron con frialdad, acordaron con todos que lo hagamos, pero no funcionó.
Como resultado, comenzamos a idear un nuevo esquema. Ella estaba con generadores nativos. ¿Qué tenemos ahora en el circuito? ( , ), , Objective-C Java, , .
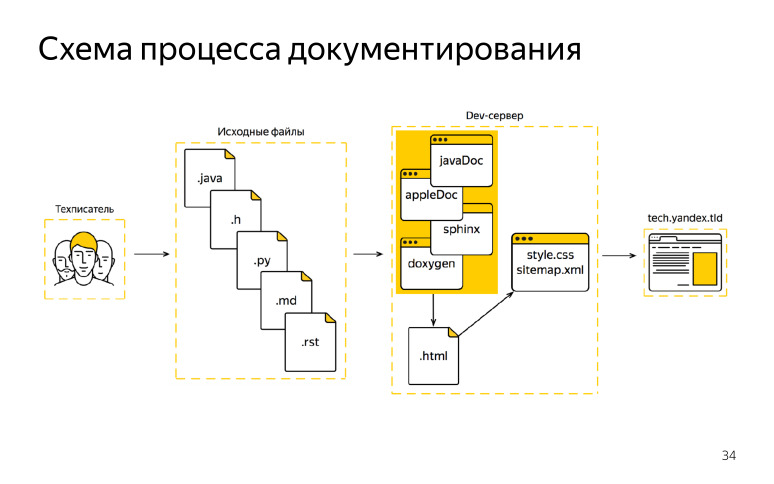
, DITA XML, , , , XML. HTML, . — JavaDoc, AppleDoc, Jazzy. HTML, . HTML, , . , HTML . , , , HTML, . XML , . .
.
— . Doxygen , , . Objective-C, , Java . . , , IDE , IntelliSense, , , , SDK, , . .
, , SDK , , , , HTML, . , , , , , .
. , - , . XML , XML . Doxygen , XML . HTML, XML . . — .
, , . 1500 , : HTML, CSS, .
, , .
. (
— . .)
, , .
— . , . -, . , . ? .
? -, , , , .
- , - , . .
? -, , , , .
. , , , , , , , .
, . , , , , , , .
? — , , , , , . . Bitbucket, - . , .

, . . - , - , , , , , , . , , , , .
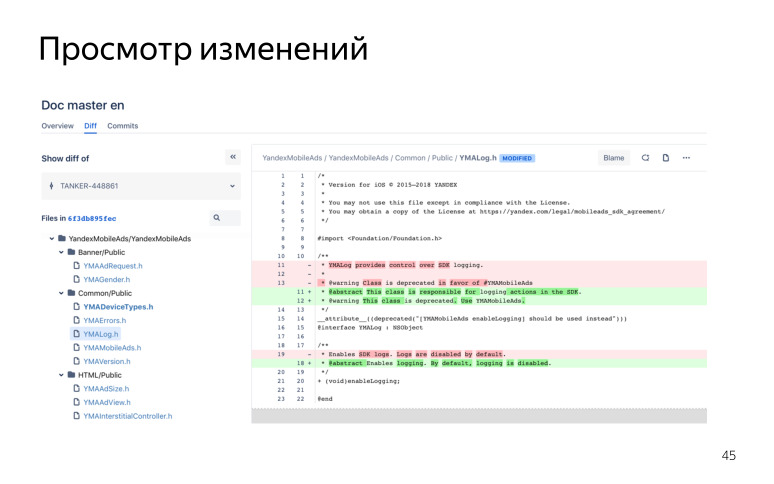
, , .
, SDK , - , , . -, , , , .
, . . — , , .
, . . .
, , , , , , .

, .
. - , . .

, , , , . . , , , - . , . , , .
, .
. , . , , .
, , , — . , , , .
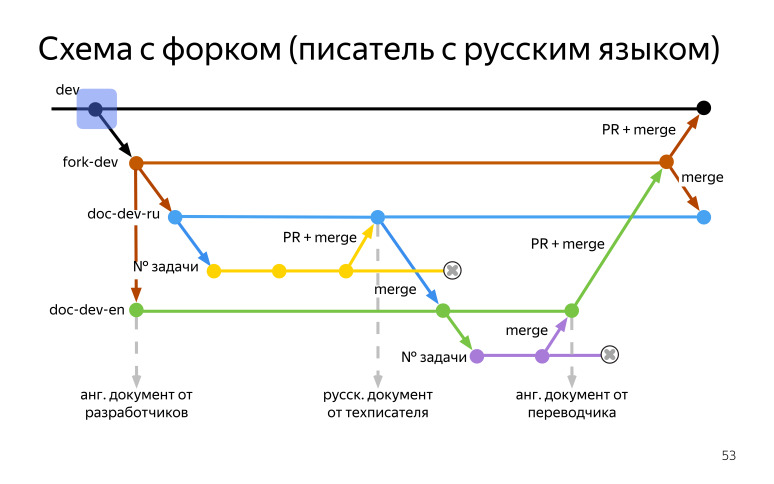
dev , (fork-dev) , . , doc-dev-en, . , , - , , .
(fork-dev) (doc-dev-ru) . , - . . , , doc-dev-ru, . , , - , .
, . (doc-dev-en). , , (doc-dev-en), , . , (fork-dev). , , , , . , , . , dev . , , , .
(fork-dev), , . (fork-dev), , (doc-dev-en), . , , , . , .

, , . dev, (fork-dev) , (doc-dev-ru) (doc-dev-en) . (doc-dev-en), (doc-dev-ru) . , .
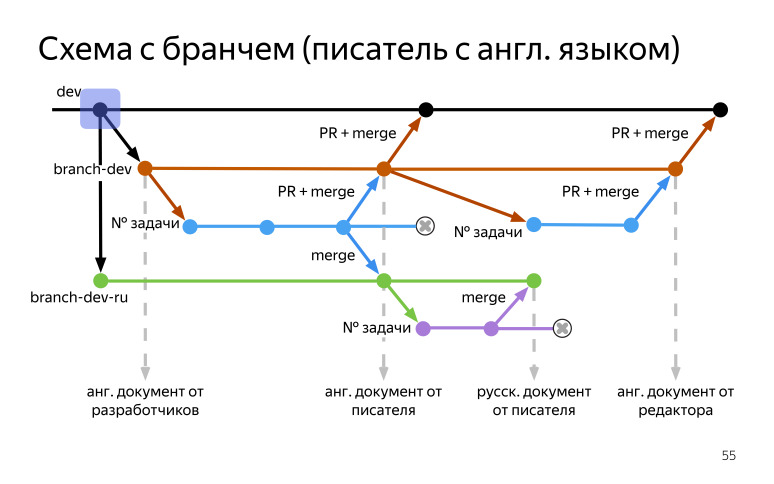
. dev , , (branch-dev). (branch-dev-ru), (branch-dev). , . , . — , — - , , , , .
, , . , , (branch-dev) . , , .
dev. , , , , . .
(branch-dev-ru), , (branch-dev-ru), . .
. (branch-dev), . , , , , , , , , . , , . , , .

, , , , . .
, ? , , . . . , - , . . , .
, , , , , .
, . . . . , , .
— — . — .
. . , . , , , , , , . .
, . . . . , . , . - , . — . .
. , : . , . : , , . , — , — . , — , . .