¿Por qué algunas API son más convenientes de usar que otras? ¿Qué podemos hacer como proveedores front-end de nuestro lado para trabajar con una API de calidad aceptable? Hoy les contaré a los lectores de Habr las opciones técnicas y las medidas organizativas que ayudarán a los proveedores de servicios de fondo y de fondo a encontrar un lenguaje común y establecer un trabajo efectivo.

Este otoño, Yandex.Market cumple 18 años. Todo este tiempo, la interfaz de socios del mercado se ha desarrollado. En resumen, este es el panel de administración con el que las tiendas pueden cargar catálogos, trabajar con el surtido, monitorear estadísticas, responder a revisiones, etc. Los detalles del proyecto son tales que debe interactuar mucho con varios backends. Sin embargo, los datos no siempre se pueden obtener en un lugar, desde un backend específico.
Síntomas de un problema
Entonces, imagina, había algún tipo de problema. El gerente va con la tarea a los diseñadores: ellos dibujan el diseño. Luego va al back-end: hacen algunos
bolígrafos y escriben una lista de parámetros y el formato de respuesta en el wiki interno.
Luego, el gerente pasa al front-end con las palabras "Te traje la API" y se ofrece a escribir rápidamente todo, porque, en su opinión, casi todo el trabajo ya está hecho.
Miras la documentación y ves esto:
№ | ---------------------- 53 | feed_shoffed_id 54 | fesh 55 | filter-currency 56 | showVendors
¿No notas nada extraño? Camel, Snake y Kebab Estuche en un bolígrafo. No estoy hablando del parámetro fesh. ¿Qué es fesh en absoluto? Tal palabra ni siquiera existe. Intenta adivinar antes de abrir el spoiler.
SpoilerFesh es un filtro por ID de tienda. Puede pasar varios identificadores separados por comas. Una identificación puede estar precedida por un signo menos, lo que significa que esta tienda debe excluirse de los resultados.
Al mismo tiempo, desde JavaSctipt, por supuesto, no puedo acceder a las propiedades de dicho objeto a través de la notación punteada. Sin mencionar el hecho de que si tienes más de 50 parámetros en un lugar, entonces, obviamente, en tu vida te volviste a otro lado.
Hay muchas opciones para una API inconveniente. Un ejemplo clásico: la API busca y devuelve resultados:
result: [ {id: 1, name: 'IPhone 8'}, {id: 2, name: 'IPhone 8 Plus'}, {id: 3, name: 'IPhone X'}, ] result: {id: 1, name: 'IPhone 8'} result: null
Si se encuentran los bienes, obtenemos una matriz. Si se encuentra un producto, obtenemos un objeto con este producto. Si no se encuentra nada, entonces, en el mejor de los casos, seremos nulos. En el peor de los casos, el backend responde con 404 o incluso 400 (Solicitud incorrecta).
Las situaciones son más fáciles. Por ejemplo, necesita obtener una lista de tiendas en un back-end y configuraciones de tienda en otro. En algunos corrales no hay suficientes datos, en algunos datos hay demasiados. Filtrar todo esto en el cliente o realizar múltiples solicitudes ajax es una mala idea.
Entonces, ¿cuáles pueden ser las soluciones a este problema? ¿Qué podemos hacer como proveedores front-end de nuestro lado para trabajar con una API de calidad aceptable?
Interfaz de usuario
Usamos el cliente React / Redux en la interfaz del socio. Debajo del cliente se encuentra Node.js, que hace muchas cosas auxiliares, por ejemplo, lo arroja a la página InitialState para Editors. Si tiene una representación del lado del servidor, no importa con qué marco de cliente, lo más probable es que sea representada por un nodo. Pero, ¿qué sucede si va un paso más allá y no se contacta directamente con el cliente en el back-end, sino que realiza su API proxy en el nodo, adaptada al máximo para las necesidades del cliente?
Esta técnica se llama BFF (Backend For Frontend). Este término fue introducido por primera vez por SoundCloud en 2015, y la idea se puede representar esquemáticamente de la siguiente manera:
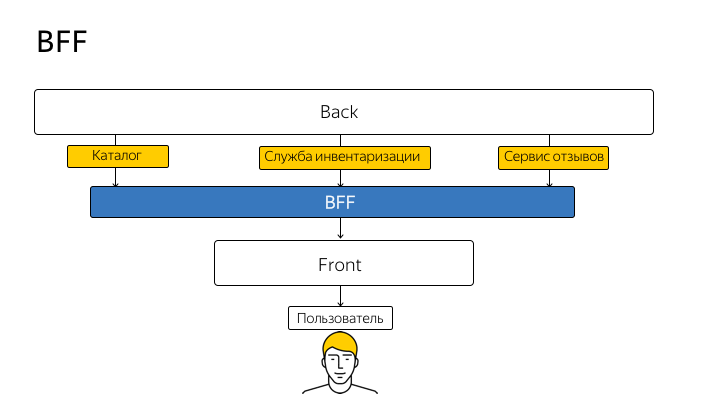
Por lo tanto, deja de pasar del código del cliente directamente a la API. Cada identificador, cada método de la API real que duplica en el nodo y desde el cliente van exclusivamente al nodo. Y el nodo ya envía la solicitud a la API real y le devuelve una respuesta.
Esto se aplica no solo a las solicitudes get primitivas, sino también a todas las solicitudes, incluso con datos multiparte / formulario. Por ejemplo, una tienda carga un archivo .xls con su catálogo a través de un formulario en un sitio. Por lo tanto, en esta implementación, el directorio no se carga directamente en la API, sino en su identificador Nod, que transmite los proxies a un back-end real.
¿Recuerdas ese ejemplo con resultado cuando el backend devolvió nulo, una matriz o un objeto? Ahora podemos volver a la normalidad, algo como esto:
function getItems (response) { if (isNull(response)) return [] if (isObject(response)) return [response] return response }
Este código se ve horrible. Porque es terrible Pero aún necesitamos hacer esto. Tenemos una opción: hacerlo en el servidor o en el cliente. Elijo un servidor.
También podemos asignar todos estos casos de kebab y serpiente en un estilo conveniente para nosotros e inmediatamente poner el valor predeterminado si es necesario.
query: { 'feed_shoffer_id': 'feedShofferId', 'pi-from': 'piFrom', 'show-urls': ({showUrls = 'offercard'}) => showUrls, }
¿Qué otras ventajas obtenemos?
- Filtrado El cliente recibe solo lo que necesita, ni más, ni menos.
- Agregación No es necesario desperdiciar la red y la batería del cliente para realizar múltiples solicitudes ajax. Una ganancia de velocidad notable debido al hecho de que abrir una conexión es una operación costosa.
- Almacenamiento en caché Su llamada agregada repetida no atraerá a nadie nuevamente, sino que simplemente devolverá 304 No modificado.
- Ocultación de datos. Por ejemplo, es posible que tenga tokens que se necesitan entre backends y que no deberían ir al cliente. Es posible que el cliente no tenga derecho a saber siquiera sobre la existencia de estos tokens, sin mencionar su contenido.
- Microservicios Si tiene un monolito en la parte posterior, BFF es el primer paso para microservicios.
Ahora sobre los contras.
- Dificultad creciente Cualquier abstracción es otra capa que necesita ser codificada, implementada y soportada. Otra parte móvil del mecanismo que puede fallar.
- Duplicación de asas. Por ejemplo, varios puntos finales pueden realizar el mismo tipo de agregación.
- BFF es una capa límite que debe admitir enrutamiento general, restricciones de derechos de usuario, registro de consultas, etc.
Para nivelar estas desventajas, es suficiente cumplir con reglas simples. El primero es separar el front-end y la lógica empresarial. Su BFF no debe cambiar la lógica empresarial de la API principal. En segundo lugar, su capa solo debe convertir datos si es absolutamente necesario. No estamos hablando de una API completa e independiente, sino solo de un proxy que llena el vacío, corrigiendo los defectos del backend.
GraphQL
GraphQL resuelve problemas similares. Con GraphQL, en lugar de muchos puntos finales "estúpidos", tiene un lápiz inteligente que puede trabajar con consultas complejas y generar datos en la forma en que el cliente lo solicita.
Al mismo tiempo, GraphQL puede funcionar sobre REST, es decir, la fuente de datos no es la base de datos, sino el resto de la API. Debido a la naturaleza declarativa de GraphQL, debido al hecho de que todo esto es amigo de React y Editors, su cliente se vuelve más fácil.
De hecho, veo GraphQL como una implementación de BFF con su protocolo y lenguaje de consulta estricto.
Esta es una excelente solución, pero tiene varios inconvenientes, en particular con la tipificación, con la diferenciación de derechos, y en general es un enfoque relativamente nuevo. Por lo tanto, aún no lo hemos cambiado, pero en el futuro me parece la forma más óptima de crear una API.
Mejores amigos para siempre
Ninguna solución técnica funcionará correctamente sin cambios organizativos. Todavía necesita documentación, garantiza que el formato de respuesta no cambiará repentinamente, etc.
Debe entenderse que todos estamos en el mismo bote. Para un cliente abstracto, ya sea un gerente o su gerente, en general, no hay diferencia: tiene GraphQL allí o BFF. Es más importante para él que se resuelva el problema y que no surjan errores en el producto. Para él, no hay mucha diferencia debido a la falla de quién ocurrió un error en el producto, ya sea por la parte frontal o posterior. Por lo tanto, debe negociar con los patrocinadores.
Además, las fallas en la parte posterior de las que hablé al comienzo del informe no siempre surgen debido a las acciones maliciosas de alguien. Es posible que el parámetro fesh también tenga algún significado.

Presta atención a la fecha del compromiso. Resulta que más recientemente fesh celebró su decimoséptimo cumpleaños.
¿Ves algunos identificadores extraños a la izquierda? Esto es SVN, simplemente porque no hubo gita en 2001. No es un github como servicio, sino un gith como sistema de control de versiones. Apareció solo en 2005.
La documentación
Entonces, todo lo que necesitamos no es pelear con el back-end, sino estar de acuerdo. Esto solo se puede hacer si encontramos una sola fuente de verdad. Esa fuente debería ser la documentación.
Lo más importante aquí es escribir documentación antes de comenzar a trabajar en la funcionalidad. Al igual que con un acuerdo prenupcial, es mejor ponerse de acuerdo sobre todo en la orilla.
Como funciona Relativamente hablando, tres van a: gerente, front-end y back-end. Fronteder está bien versado en el área temática, por lo que su participación es muy importante. Se reúnen y comienzan a pensar en la API: de qué manera, qué respuestas deben devolverse, hasta el nombre y el formato de los campos.
Swagger
Una buena opción para la documentación de la API es el formato Swagger , ahora llamado OpenAPI. Es mejor usar Swagger en el formato YAML, porque, a diferencia de JSON, los humanos lo leen mejor, pero no hay diferencia para la máquina.
Como resultado, todos los acuerdos se arreglan en formato Swagger y se publican en un repositorio común. La documentación para el backend de ventas debe estar en el asistente.
El maestro está protegido de confirmaciones, el código ingresa solo a través del grupo de solicitudes, no puede ingresarlo. El representante del equipo frontal está obligado a realizar una revisión del grupo de solicitudes, sin su actualización, el código no pasa al maestro. Esto lo protege de cambios inesperados en la API sin previo aviso.
Entonces se juntaron, escribió Swagger, así que en realidad firmaron el contrato. A partir de este momento, usted como front-end puede comenzar su trabajo sin esperar la creación de una API real. Después de todo, ¿cuál fue el punto de separación entre el cliente y el servidor, si no podemos trabajar en paralelo y los desarrolladores del cliente tienen que esperar a los desarrolladores del servidor? Si tenemos un "contrato", podemos paralelizar este asunto con seguridad.
Faker.js
Faker es genial para estos propósitos. Esta es una biblioteca para generar una gran cantidad de datos falsos. Puede generar diferentes tipos de datos: fechas, nombres, direcciones, etc., todo esto está bien localizado, hay soporte para el idioma ruso.
Al mismo tiempo, el falsificador es amigo del fanfarrón, y puede levantar con calma el servidor Mock, que, según el esquema Swagger, le generará respuestas falsas a lo largo de los caminos necesarios.
Validación
Swagger se puede convertir en un esquema json, y con la ayuda de herramientas como ajv puede validar las respuestas de back-end directamente en tiempo de ejecución, en su BFF, e informar a los probadores, a los mismos backenders, en caso de discrepancias, etc.
Supongamos que un probador encuentra algún tipo de error en el sitio, por ejemplo, cuando se hace clic en un botón, no sucede nada. ¿Qué hace el probador? Pone un boleto en el front-end: "este es su botón, no está presionado, repare".
Si hay un validador entre usted y la parte posterior, el probador sabrá que el botón está presionado, solo el backend envía la respuesta incorrecta. Incorrecto: esta es una respuesta que el frente no espera, es decir, no corresponde al "contrato". Y aquí ya es necesario reparar la parte posterior o cambiar el contrato.
Conclusiones
- Estamos activamente involucrados en el diseño de la API. Diseñamos la API para que sea conveniente usarla después de 17 años.
- Requerimos documentación de Swagger. Sin documentación: la operación de fondo no se completó.
- Existe documentación: la publicamos en git, y cualquier cambio en la API debe ser actualizado por el representante del equipo frontal.
- Levantamos el servidor falso y comenzamos a trabajar en el frente sin esperar la API real.
- Ponemos el nodo debajo de la interfaz y validamos todas las respuestas. Además, tenemos la capacidad de agregar, normalizar y almacenar en caché los datos.
Ver también
→ Cómo construir una API tipo REST en un proyecto grande
→ Backend en la interfaz
→ Uso de GraphQL como implementación de patrones BFF