Este es un tutorial de la biblioteca TensorFlow. Considérelo un poco más profundo que en los artículos sobre el reconocimiento de números escritos a mano. Este es un tutorial sobre métodos de optimización. Aquí no puedes prescindir de las matemáticas. Está bien si lo olvidaste por completo. Recordar. No habrá evidencia formal y conclusiones complejas, solo el mínimo necesario para la comprensión intuitiva. Para comenzar, algunos antecedentes sobre cómo este algoritmo puede ser útil para optimizar una red neuronal.

Hace seis meses, un amigo me pidió que le mostrara cómo hacer una red neuronal en Python. Su empresa produce instrumentos para mediciones geofísicas. Varias sondas diferentes durante la perforación miden un conjunto de señales asociadas con los parámetros del entorno que rodea el pozo. En algunos casos complejos, calcule con precisión los parámetros ambientales de las señales durante mucho tiempo, incluso en una computadora potente, y es necesario interpretar los resultados de las mediciones en el campo. Hubo una idea de contar varios cientos de miles de casos en un clúster y entrenar una red neuronal en ellos. Dado que la red neuronal es muy rápida, puede usarse para determinar parámetros que sean consistentes con las señales medidas, justo en el proceso de perforación. Los detalles están en el artículo:
Kushnir, D., Velker, N., Bondarenko, A., Dyatlov, G. y Dashevsky, Y. (29 de octubre de 2018). Simulación en tiempo real de la herramienta de resistividad azimutal profunda en modelo de fallas 2D utilizando redes neuronales (ruso). Sociedad de Ingenieros de Petróleo. doi: 10.2118 / 192573-RU
Una tarde, mostré cómo los keras podían implementar una red neuronal simple, y un amigo en el trabajo comenzó a entrenar sobre los datos contados. Después de un par de días, discutimos el resultado. Desde mi punto de vista, parecía prometedor, pero un amigo dijo que necesitaba cálculos con la precisión del dispositivo. Y si el error cuadrático medio resultó ser alrededor de 1, entonces se necesitaba 1e-3. 3 pedidos menos. Mil veces
Los experimentos con arquitectura de red neuronal, normalización de datos y enfoques de optimización no arrojaron casi nada. Un par de semanas después, un amigo llamó y dijo que instaló MatLab y resolvió el problema mediante el método Levenberg-Marquardt (en adelante llamaremos a LM ). Se optimizó durante mucho tiempo (varios días), no funcionó en la GPU, pero el resultado fue el correcto. Parecía un desafío.
Falló una búsqueda rápida de un optimizador LM listo para keras o TensorFlow. Me encontré solo con la biblioteca pyrenn, pero su funcionalidad me pareció pobre. Decidí implementarlo yo mismo. A primera vista, todo parecía simple, y dos noches deberían haber sido suficientes. Tomó más tiempo. Hubo dos problemas:
- TensorFlow. Un montón de artículos, pero casi todos los niveles "pero escribamos
hola mundo reconocimiento de dígitos escritos a mano". - Matemáticas Olvidé mucho, y a los autores de artículos matemáticos no les importan las personas como yo: fórmulas sólidas sin explicación, "¡obviamente!" Y así sucesivamente.
Como resultado, escribió un artículo para aquellos que olvidaron las matemáticas y quieren entender TensorFlow un poco más profundo, pero sin hardcore. El artículo tiene mucho texto y poco código. La opción opuesta, cuando hay poco texto y mucho código, es aquí Jupyter Notebook Levenberg-Marquardt .
Conozca la función Rosenbrock
Generaremos datos de entrenamiento mediante la función Rosenbrock , que a menudo se utiliza como punto de referencia para algoritmos de optimización:
f ( x , y ) = ( a - x ) 2 + b ( y - x 2 ) 2
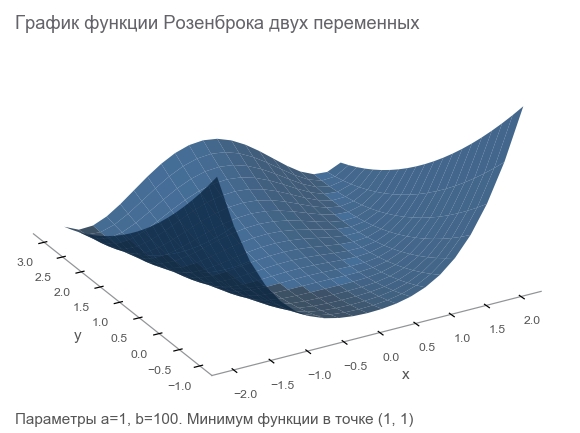
¿Por qué ella es buena?
- Hermoso horario. Se llama el valle de Rosenbrock y la función de banana de Rosenbrock no traducible .
- El mínimo global está dentro de un valle plano, parabólico, largo y estrecho. Encontrar un valle es trivial, y un mínimo global es difícil.
- Hay una opción multidimensional. No es tan fácil encontrar una buena función para muchas variables.
Comenzaremos a escribir código a partir de él conectando las bibliotecas necesarias para un trabajo posterior:
import numpy as np import tensorflow as tf import math def rosenbrock(x, y, a, b): return (a - x)**2 + b*(y - x**2)**2
Nosotros planteamos el problema
Como estábamos hablando de un dispositivo de medición, continuemos usando la analogía. Nuestro dispositivo en un mundo ficticio puede medir coordenadas ( x , y ) y altura z . Los físicos estudiaron el mundo y dijeron: " Sí, ¡esta es Rosenbrock! Conociendo las coordenadas, puede calcular con precisión la altura, no necesita medirla ". En otras palabras, los científicos nos dieron un modelo. z = r o s e n b r o c k ( x , y , a , b ) que depende de los parámetros ( a , b ) . Estos parámetros, aunque constantes en un mundo ficticio, son desconocidos. Necesitan ser encontrados.
Llevamos a cabo una serie de experimentos que dieron m puntos (x1,y1,z1),(x2,y2,z2),...,(xm,ym,zm) :
La primera forma de optimizar es intentar adivinar los parámetros. Usamos la biblioteca Numpy:
x, y = data_points[:, 0], data_points[:, 1] z = data_points[:, 2]
¿Cómo entender lo equivocados que estamos? Contar residuos - tamaños de error. m los puntos dan m residuales: necesita un indicador integral. Cuadramos cada residuo en un cuadrado y calculamos el promedio:
MSE(a,b)= frac1m summi=1(zi− widehatzi)2
Esta medida de proximidad se denomina error cuadrático medio (en lo sucesivo denominado mse ):
[Out]: 3868.2291666666665
Al minimizar mse , resolvemos el problema de los mínimos cuadrados ( minimización de cuadrados no lineales ):
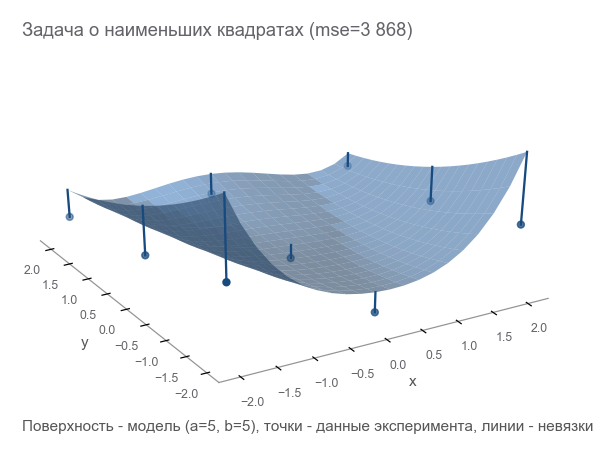
Se puede ver que los parámetros no adivinaron en absoluto.
Formulamos el problema en TensorFlow
El modelo tiene la forma z=rosenbrock(x,y,a,b) . Lo traemos a la forma y=f(x,p) (generalmente las matemáticas escriben beta en lugar de p pero los programadores no usan beta). Ahora el modelo tiene la forma y=rosenbrock(x,p) donde y - altura x Es el vector de coordenadas de dos elementos (componente) y p - vector de parámetros.
Los programadores a menudo piensan en los vectores como matrices unidimensionales. Esto no es del todo correcto. Una matriz de números es un medio de representar un vector. Puede representar un vector como una matriz de dimensión N , matriz bidimensional 1 vecesN e incluso una matriz N por1 En los casos en que el hecho de que el vector sea un vector de columna (por ejemplo, para multiplicar una matriz por él) es importante:
beginbmatrixx1 vdotsxN endbmatrix
TensorFlow utiliza el concepto de tensor . Un tensor , como una matriz, puede ser unidimensional (para representar un vector ), bidimensional (para un vector de matriz o columna ) y cualquier dimensión más grande.
El código de TensorFlow no es diferente en forma del código de Numpy. El contenido es enorme. El código Numpy calcula el valor mse. El código TensorFlow no realiza ningún cálculo en absoluto, forma un gráfico de flujo de datos que puede calcular . Un momento muy tolerante para el cerebro es el trabajo de la función rosenbrock . Lo usamos en ambos casos. Pero cuando pasamos las matrices de Numpy, realiza los cálculos de acuerdo con la fórmula y devuelve los números. Y cuando transferimos los tensores a TensorFlow, forma una subgrafía del flujo de datos y devuelve su borde en forma de tensor. Milagros de polimorfismo, pero no abuses de ellos:
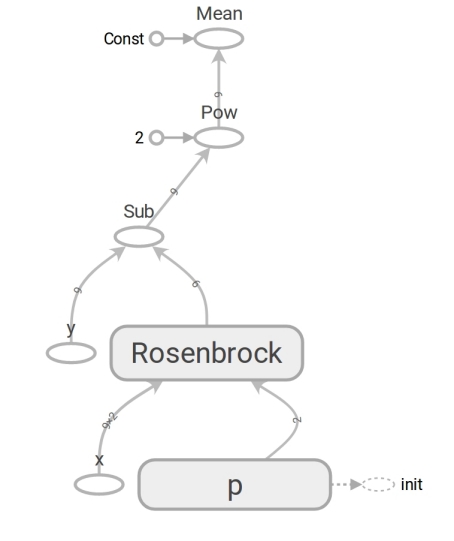
Gracias a la presencia de dicho gráfico de flujo de datos, TensorFlow en particular es capaz de calcular derivados automáticamente (utilizando la técnica de diferenciación automática en modo inverso ).
Un momento de matemática. Los bloques "para los que han olvidado" se esconderán en un spoiler.
Derivada (número ingresado - número restante)Lo más probable es que recuerde la definición de la derivada de una función escalar (que devuelve un número) de una variable: para f: mathbbR rightarrow mathbbR derivada f en el punto x in mathbbR definido como:
f′(x)= limh a0 fracf(x+h)−f(x)h
Los derivados son una forma de medir el cambio . En el caso escalar, la derivada muestra cuánto cambiará la función f si x cambiar a un valor pequeño varepsilon :
f(x+ varepsilon) aprox.f(x)+ varepsilonf′(x)
Por conveniencia, denotamos y=f(x) y la derivada y por x escribiremos cómo frac partialy partialx . Tal registro enfatiza que frac partialy partialx - tasa de cambio entre variables x y y . Más específicamente, si x cambiar a varepsilon entonces y cambiar a aproximadamente varepsilon frac partialy partialx . También puedes escribirlo así:
x rightarrowx+ Deltax Rightarrowy rightarrow aproxy+ frac partialy partialx Deltax
Se lee como: "cambiando x en x+ Deltax cambiar y aproximadamente a y+ Deltax frac partialy partialx ". Tal registro resalta claramente el vínculo entre el cambio x y cambiar y .
Creamos un gráfico de flujo de datos, ejecutemos el cálculo de mse:
[Out]: 3868.2291666666665
El resultado es el mismo que con Numpy. Entonces no se equivocaron.
Comienza a optimizar
Desafortunadamente, no fue posible adivinar los parámetros. Pero luego nosotros:
- Establecemos el criterio de optimización: el valor mínimo de mse.
- Se determinaron parámetros variables: vector p con componentes a , b Funciones de Rosenbrock.
- Todavía no hemos pensado en las limitaciones, pero no están allí.
En el último paso, construimos un gráfico de flujo de datos con un tensor de pérdida finita ( función de pérdida ). El objetivo de la optimización es encontrar el valor del vector de parámetros p en el cual el valor de la función de pérdida es mínimo. Tuvimos suerte, el gráfico de esta función es muy simple (cóncavo y sin mínimos locales):
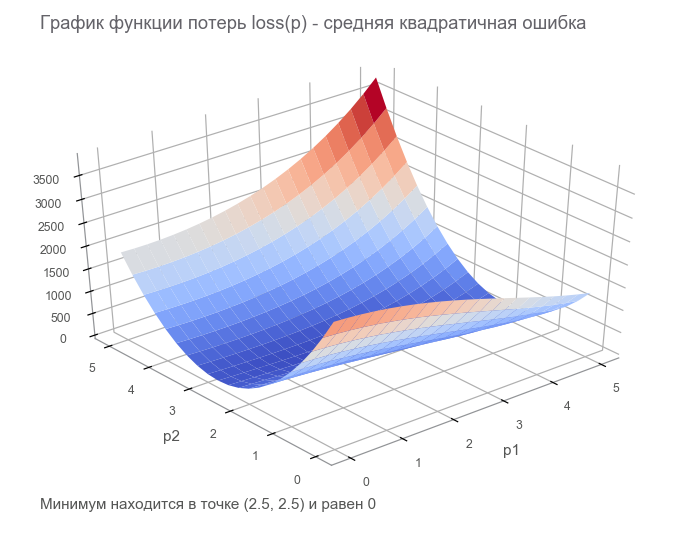
Comenzando con la optimización. Para comenzar, escribimos un ciclo generalizado:
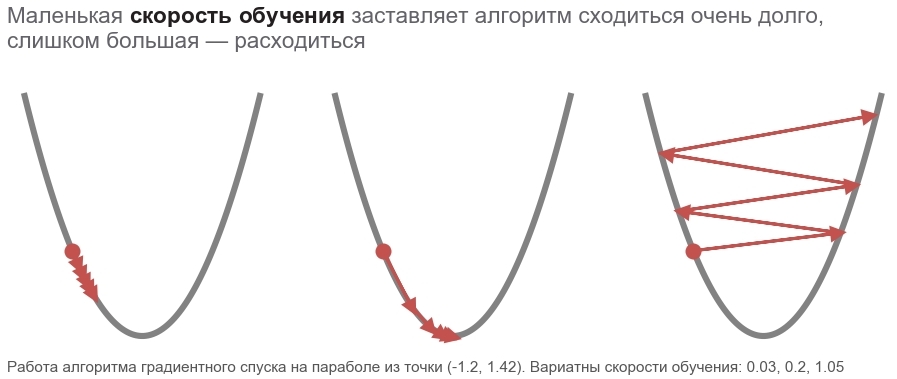
Optimizamos por el método del descenso de gradiente más rápido (SGD)
Las acciones de este método se pueden comparar con montar un esquiador atrevido, que siempre baja la pendiente (en la dirección más empinada). En este caso, solo se tiene en cuenta la pendiente en el punto de ubicación. Y si la pendiente es fuerte, el esquiador vuela una gran distancia antes del próximo cambio. Con una pendiente débil, se mueve en pequeños pasos. Tal vez como volar en un árbol (el algoritmo diverge ) y queda atrapado en un pozo ( mínimo local ).

Puedes escribir de la siguiente manera (cambiar boldsymbolp en boldsymbolp−... ):
boldsymbolp rightarrow boldsymbolp− alpha[ nablaploss( boldsymbolp)]
Grasiento boldsymbolp enfatiza que este es el punto de ubicación real: el valor del vector de parámetros en el paso actual. En el primer paso, esta es nuestra suposición (5, 5). Hay dos puntos interesantes en la fórmula: alpha - tasa de aprendizaje ( tasa de aprendizaje ), nablappérdida - gradiente ( gradiente ) de la función de pérdida por el vector de parámetros.
Gradiente (vector ingresado - número restante)Considere una función que toma un vector como entrada y produce un escalar: f: mathbbRN rightarrow mathbbR . Derivada f en el punto x in mathbbRN ahora se llama gradiente y es un vector [ nablaxf(x)] in mathbbRN (leído como "nabla") compuesto de derivados parciales :
nablaxy=( frac partialy partialx1, frac partialy partialx2,..., frac partialy parcialxN)
Para este caso, el registro de la dependencia del cambio de la función en el cambio del argumento tiene la siguiente forma:
x rightarrowx+ Deltax Rightarrowy rightarrow aproxy+ nablaxy cdot Deltax
El registro ha cambiado bastante para tener en cuenta que x , Deltax y nablaxy - vectores en mathbbRN y y - escalar Al multiplicar vectores nablaxy y Deltax se utiliza el producto escalar (la suma de los productos de los componentes).
[Out]: step: 1, current loss: 3868.2291666666665 step: 2, current loss: 1381.5379689135807 [...] ENDED ON STEP: 582, FINAL LOSS: 9.698531012270816e-11 PARAMETERS: [2.50000205 2.49999959]
Tomó 582 pasos:
Movimiento en la dirección del anti-gradiente¿Por qué nos movemos en la dirección opuesta al gradiente? Recuerde la entrada con el producto escalar: x rightarrowx+ Deltax Rightarrowy rightarrow aproxy+ nablaxy cdot Deltax . Minimizar y . Dado que el comportamiento de la función se conoce solo en un vecindario pequeño a través de la derivada, es necesario moverse en pasos pequeños pero óptimos, minimizando el producto nablaxy cdot Deltax . Por definición escolar, el producto escalar de dos vectores es el número igual al producto de las longitudes de estos vectores por el coseno del ángulo entre ellos : a cdotb= left|a right| left|b right|cos angle(a,b) . Para una longitud fija de vectores, este producto alcanza un mínimo con un coseno de -1, es decir en un ángulo de 180 grados, cuando los vectores se dirigen en direcciones opuestas. En consecuencia, el producto escalar mínimo nablaxy cdot Deltax logrado cuando Deltax en la dirección del anti-gradiente .
Optimizamos por el método de Adam
No iremos más allá en los métodos de gradiente, pero hay muchas variaciones. Puede leer sobre ellos en el artículo Métodos para optimizar las redes neuronales . En TensorFlow, muchos optimizadores ya están implementados. Por ejemplo, Adam:
[Out]: step: 1, current loss: 3868.2291666666665 step: 2, current loss: 34205.72916492336 [...] ENDED ON STEP: 317, FINAL LOSS: 2.424142714263483e-12 PARAMETERS: [2.49999969 2.50000008]
Gestionado en 317 pasos. Mucho más rápido
Optimizamos por el método de Newton
Las acciones de los métodos de segundo orden se pueden comparar a montar en un snowboardista racional de freeride que reflexiona sobre el siguiente punto de su ruta durante mucho tiempo y tiene en cuenta no solo la pendiente en el lugar, sino también la curvatura.
De hecho, tanto los métodos de descenso de gradiente como los métodos de segundo orden intentan adivinar ( aproximar ) la función en el punto actual. Los métodos de gradiente se centran solo en la pendiente de la gráfica de la función en el punto, la primera derivada. Los métodos de segundo orden, además del sesgo, tienen en cuenta la curvatura , la segunda derivada: "si la curvatura persiste, ¿dónde estará el mínimo?" Calculamos y vamos allí:
Para construir tal aproximación y calcular el punto mínimo estimado, puede usar la serie Taylor . Para el caso unidimensional, la aproximación por un polinomio de segundo orden en el punto a se ve así:
f(x) aproxf(a)+ fracf′(a)(x−a)1!+ fracf″(a)(x−a)22!
El mínimo se alcanza a las x=a− fracf′(a)f″(a) . El caso multidimensional parece más serio:
Matriz de arpillera (vector ingresado - número restante)La matriz de Hesse es una matriz cuadrada compuesta de segundas derivadas:
\ boldsymbol {H} y_ {x} = \ begin {bmatrix} \ frac {\ partial ^ 2y} {\ partial x_1 ^ 2} & \ frac {\ partial ^ 2y} {\ partial x_1 \ partial x_2} & \ cdots & \ frac {\ partial ^ 2y} {\ partial x_1 \ partial x_N} \\ \ frac {\ partial ^ 2y} {\ partial x_2 \ partial x_1} & \ frac {\ partial ^ 2y} {\ partial x_2 ^ 2} & \ cdots & \ frac {\ partial ^ 2y} {\ partial x_2 \ partial x_N} \\ \ vdots & \ vdots & \ ddots & \ vdots \\ \ frac {\ partial ^ 2y} {\ partial x_N \ parcial x_1} & \ frac {\ partial ^ 2y} {\ partial x_N \ partial x_2} & \ cdots & \ frac {\ partial ^ 2y} {\ partial x_N ^ 2} \ end {bmatrix}
Aproximación por un polinomio de segundo orden para una función de un vector a través de un gradiente y una matriz de Hesse en un punto a se ve así:
f(x) aprox.f(a)+(xa) intercal[ nablaxf(a)]+ frac12!(xa) intercal[ boldsymbolHfx(a)](xa)
El mínimo se alcanza a las x=a−[ boldsymbolHfx(a)]−1[ nablaxf(a)] . La forma casi coincide con el caso unidimensional: reemplazamos la primera derivada con un gradiente, la segunda con una matriz de Hesse e hicimos una corrección para trabajar con vectores. Es imposible dividir un vector por una matriz, por lo tanto, se usa la multiplicación por la matriz inversa . T significa transposición . La fórmula implica que, por defecto, un vector es una columna. Transponer convierte un vector de columna en un vector de fila . Al implementar en TensorFlow, esto debe tenerse en cuenta, pero en la dirección opuesta: por defecto, el vector es una cadena (tensor unidimensional). Por si acaso: la transposición no es una rotación de 90 grados, es la transformación de filas en columnas en el mismo orden.
Entonces, el paso del método Newton tiene la siguiente forma:
boldsymbolp rightarrow boldsymbolp−[ boldsymbolHlossp( boldsymbolp)]−1[ nablappérdida( boldsymbolp)]
TensorFlow tiene todo para implementar este método:
[Out]: step: 1, current loss: 3868.2291666666665 step: 2, current loss: 105.04357496954218 step: 4, current loss: 9.96663526704236 ENDED ON STEP: 6, FINAL LOSS: 5.882202372519996e-20 PARAMETERS: [2.5 2.5]
Suficientes 6 pasos:
Optimizado por el algoritmo de Gauss-Newton
El método de Newton tiene un inconveniente: la matriz de Hesse. Gracias a TensorFlow podemos contarlo en una línea de código. Según la wiki, Johann Karl Friedrich Gauss hizo la primera mención de su método en 1809. El cálculo de la matriz de Hesse para varios parámetros para el método de mínimos cuadrados podría llevar mucho tiempo. Ahora podemos suponer que el algoritmo de Gauss-Newton usa la aproximación de la matriz de Hesse a través de la matriz de Jacobi para simplificar los cálculos. Pero desde el punto de vista de la historia, esto no es así: Ludwig Otto Hesse (quien desarrolló la matriz que lleva su nombre) nació en 1811, 2 años después de la primera mención del algoritmo. Y Carl Gustav Jacobi tenía 5 años.
El algoritmo de Gauss-Newton no funciona con la función de pérdida. Funciona con la función residual. r(p) . Esta función toma un vector de entrada de parámetros p y devuelve un vector de residuos . En nuestro caso, el vector p consta de 2 componentes (parámetros a y b Funciones de Rosenbrock) y el vector residual de m componente (según el número de experimentos). Se obtiene la función vectorial del argumento vector. Su derivada:
Matriz de Jacobi (vector ingresado - vector liberado)Considere una función que toma un vector como entrada y produce un vector también: f: mathbbRN rightarrow mathbbRM . Derivada f en el punto x ahora tiene talla N vecesM , llamada matriz de Jacobi , y consta de todas las combinaciones de derivadas parciales:
\ boldsymbol {J} y_ {x} = \ begin {pmatrix} \ frac {\ partial y_ {1}} {\ partial x_ {1}} & \ cdots & \ frac {\ partial y_ {1}} {\ parcial x_ {N}} \\ \ vdots & \ ddots & \ vdots \\ \ frac {\ partial y_ {M}} {\ partial x_ {1}} & \ cdots & \ frac {\ partial y_ {M}} {\ parcial x_ {N}} \ end {pmatrix}
Puede notar que las filas de la matriz de Jacobi son los gradientes de los componentes y . Artículo (i,j) matrices frac partialy partialx es igual a frac partialyi partialxj y nos dice cuánto cambiará yi al cambiar xj en un valor pequeño Como en casos anteriores, puedes escribir:
x rightarrowx+ Deltax Rightarrowy rightarrow aproxy+ boldsymbolJyx Deltax
Aqui boldsymbolJyx matriz N vecesM y Deltax vector de tamaño N así el producto boldsymbolJyx Deltax Es el producto de la matriz por el vector, dando como resultado un vector de tamaño M .
Para no confundirse con la abundancia de personajes, asumimos que boldsymbolJr - Matriz de funciones residuales de Jacobi en el punto actual boldsymbolp . Entonces el algoritmo de Gauss-Newton se puede escribir de la siguiente manera:
boldsymbolp rightarrow boldsymbolp−[ boldsymbolJ rintercal boldsymbolJr]−1 boldsymbolJ rintercalr( boldsymbolp)
La grabación en la forma coincide completamente con la grabación del método de Newton. Solo en lugar de la matriz de Hesse se usa boldsymbolJ rintercal boldsymbolJr en lugar del gradiente boldsymbolJ rintercalr( boldsymbolp) . A continuación, veremos por qué se puede usar tal aproximación. Mientras tanto, procedamos a la implementación en TensorFlow:
[Out]: step: 1, current loss: 3868.2291666666665 step: 2, current loss: 14.653025157673625 step: 4, current loss: 4.3918079172783016e-07 ENDED ON STEP: 4, FINAL LOSS: 3.374364957618591e-17 PARAMETERS: [2.5 2.5]
Suficientes 4 pasos. Menos que para el método de Newton.
Como se puede ver en el código, la función de pérdida no se usa en la optimización, solo para detener y registrar criterios. ¿Cómo sabe el algoritmo de optimización qué función minimizar? La respuesta es sorprendente: ¡de ninguna manera! Gauss-Newton minimiza solo el error cuadrático medio .
Repara la parte matemática del artículo
Repetimos todas las matemáticas que necesitábamos. Arreglemos un poco para enfocarnos más en la programación y TensorFlow. Es posible que necesite un lápiz para trazar la secuencia de acciones matemáticas.
Hay un modelo y=f(x,p) donde x - vector p - vector de parámetros de dimensión n y y - escalar De los experimentos recibidos m puntos (x1,y1),...,(xm,ym) ( pares de datos ). La función residual del vector depende solo del vector de parámetros: r(p)=(r1(p),...rm(p)) donde rk(p)=yk− widehatyk=yk−f(xk,p) . , p , xk,yk ? , xk,yk , .
p , ( sum of squared error — sse residual sum-of-squares — rss ) . mse sse , m . . :
loss(p)=r21(p)+⋯+r2m(p)=m∑k=1r2k(p)
p (p) .
, . — . — , r2 2r∂r∂p . :
∇ploss=(m∑k=12rk∂rk∂p1,⋯,m∑k=12rk∂rk∂pn)
. :
. , , .
Genial .
, , , — . , , , . — . , ? -.
:
, , . Tenga en cuenta que:
"" . ( ). , — , .
( ):
, , - — , mse .
. , , . , . , .
, : " . - ! ". , , , ( supervised learning ). , . : ( training set ) — ; — ( prediction model ) ; — , .
( multi-layer perceptron neural network mlp ). , , :
- ( starting values ) . Xavier'a, .
- ( overfitting ). — . , . — .
- ( scaling of the input ). , .
9 . 500:
500 . — ( learner ), ( outcome measurement ) ( features ) .
( network diagram ). MatLab:
( input ). ( weights ) 2x10, ( bias ) 10, ( activation ). () ( hidden layer ) 10 . , , ( output ).
, , ( ):
:
. "" , - . 41 . , .
, . - de :
Adam
Adam . mse :
[Out]: step: 1, current loss: 671.4242576535694 [...] ENDED ON STEP: 40000, FINAL LOSS: 0.22862158574440725 VALIDATION LOSS: 0.29000289644978866
. : , , .
2 . :
:
. , 4 . 4 tf.concat .
. tf.while_loop , , , stack .
: . tf.reshape (-1,) .
. - . — TensorFlow . — - - . -. Levenberg-Marquardt Jupyter Notebook rosenbrock_train.py . , TensorFlow . - , ( ) , , .
-
hess_approx grad_approx -. , . :
- :
- :
, , , . - , :
, - .
[Out]: step: 1, current loss: 548.8468777701685 step: 2, current loss: 49648941.340197295 InvalidArgumentError: Input is not invertible.
- . , . - , .
, .
-
. Matlab trainlm . . MathWorks.
- : . - :
( ). , -. , . , LM -.
:
mu = tf.placeholder(tf.float64, shape=[1]) n = tf.add_n(parms_sizes) I = tf.eye(n, dtype=tf.float64)
? LM - . , . , , . — , mse . , :
[Out]: step: 1, mu: 3.0 current loss: 692.6211687622557 [...] ENDED ON STEP: 100, FINAL LOSS: 0.012346989371823602 VALIDATION LOSS: 0.01859463694102034
100 LM mse 10 , 40 .
. , . , rosenbrock_train.py .
2D . . . , " " ( curse of dimentionality , Bellman, 1961). . .
:
rosenbrock_train.py get_rand_rosenbrock_points .
-
- : " ! 4 , 300! ". , ( ) -. , , . - . . : ? , . . , - :
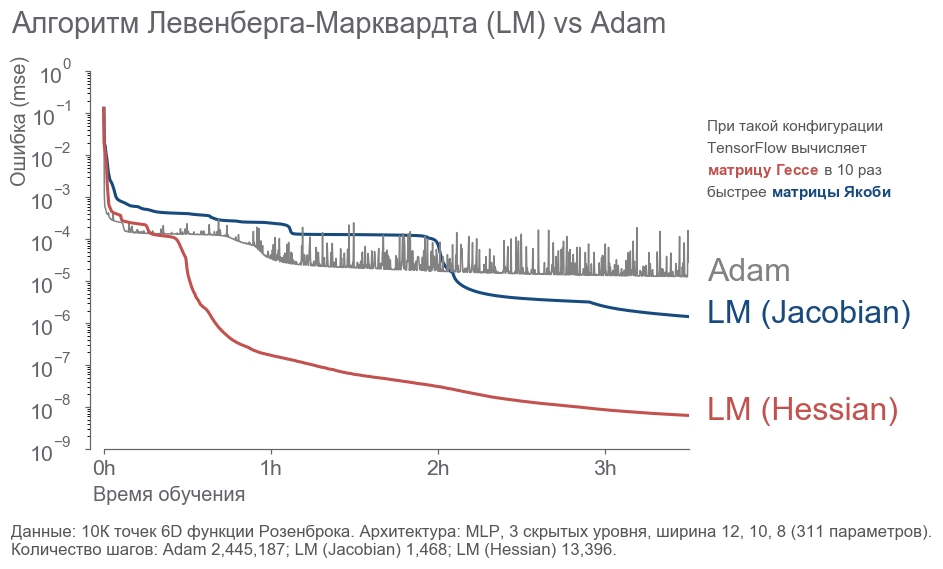
- 10 000 6D .
- 3 12, 10, 8 (311 ).
- .
- 3.5 .
. - 2 . LM . 20 .
rosenbrock_train.py . . , .
Conclusión
, . " ", , . , . , 273 . - , .
, :
- .
- ( ) -:
[1] Petros Drineas, Ravi Kannan, and Michael W. Mahoney. 2006. Fast Monte Carlo Algorithms for Matrices I: Approximating Matrix Multiplication. SIAM J. Comput. 36, 1 (July 2006), 132-157. DOI= http://dx.doi.org/10.1137/S0097539704442684
[2] Adelman, M., & Silberstein, M. (2018). Faster Neural Network Training with Approximate Tensor Operations. CoRR, abs/1805.08079.
, - . , . "".